persistent mode
настойчивый режим (более известен как р-настойчивый режим пакетной радиосвязи при многостанционный доступ с контролем несущей) ; см. также p-persistent carrier sense multiple access; unpersistent mode
Англо-русский словарь промышленной и научной лексики . 2014 .
- persistent internal polarization photography
- persistent oil spill
Смотреть что такое «persistent mode» в других словарях:
- Persistent Munition Technology Demonstrator — The Persistent Munition Technology Demonstrator or PMTD is an Unmanned aerial vehicle (UAV) developed and produced by the Advanced Weapons and Missile Systems division of Boeing as a test bed in order to further develop and flight test various… … Wikipedia
- PARAPLUIE (histoire de la mode) — PARAPLUIE, histoire de la mode L’homme a toujours cherché à se protéger du soleil et de la pluie au moyen de dispositifs mobiles et portables: parasols, ombrelles, parapluies et en cas ont répondu, au fil des siècles, à cette demande. Le parasol … Encyclopédie Universelle
- Superconducting magnet — A superconducting magnet is an electromagnet made from coils of superconducting wire. They must be cooled to cryogenic temperatures during operation. In its superconducting state the wire can conduct much larger electric currents than ordinary… … Wikipedia
- Carlavirus — Taxobox name = Carlavirus virus group = iv familia = Flexiviridae subfamilia = genus = Carlavirus type species = Carnation latent virus subdivision ranks = Species subdivision = Aconitum latent virus American hop latent virus Blueberry scorch… … Wikipedia
- You’ve Got Mail — Infobox Film name = You ve Got Mail caption = You ve Got Mail poster director = Nora Ephron writer = Nora Ephron Delia Ephron starring = Tom Hanks Meg Ryan Greg Kinnear Parker Posey Dave Chappelle Steve Zahn Jean Stapleton Dabney Coleman |… … Wikipedia
- Jitterlyzer — infobox computer hardware generic name = Jitterlyzer caption = FS5000 invent date = 2007 invent name = FuturePlus conn1 = Host PC conn2 = PCIe x1 and x4 conn3 = SRIO via1 1 = USB via2 1 = Interposer via3 1 = MMCX connector class name = class1 =… … Wikipedia
- Chemical warfare — For other uses, see Chemical warfare (disambiguation). This article forms part of the series Chemical agents Lethal agents Blood agents Cyanogen chloride (CK) … Wikipedia
- BIOS — This article is about the personal computer term. For other uses, see Bios. In IBM PC compatible computers, the basic input/output system (BIOS), also known as the System BIOS or ROM BIOS (pronounced /ˈbaɪ.oʊs/), is a de facto standard… … Wikipedia
- Ubuntu casper — AVERTISSEMENT Cet article est extrêmement technique. Il sera complété prochainement par une vue plus synthétique. Il décrit le fonctionnement prévu pour Ubuntu 9.04, cependant il y a des bugs qui empêchent d utiliser certaines possibilités.… … Wikipédia en Français
- First-person shooter — This article is about the video game genre. For other uses, see First person shooter (disambiguation). A screenshot … Wikipedia
- Rootkit — A rootkit is software that enables continued privileged access to a computer while actively hiding its presence from administrators by subverting standard operating system functionality or other applications. The term rootkit is a concatenation… … Wikipedia
Фаззинг с AFL++. llvm_mode persistent mode

В постоянном режиме AFL++ проверяет цель несколько раз в одном процессе, вместо того, чтобы создавать новый процесс для каждого выполнения фазза. Это самый эффективный способ фаззинга, так как скорость может быть в x10 или x20 раз выше без каких-либо недостатков. Весь профессиональный фаззинг использует этот режим.
Постоянный режим требует, чтобы цель могла быть вызвана в одной или нескольких функциях, и чтобы ее состояние могло быть полностью сброшено, чтобы можно было выполнить несколько вызовов без утечки ресурсов, и чтобы предыдущие запуски не влияли на последующие. Индикатором этого является значение стабильности в пользовательском интерфейсе afl-fuzz. Если это значение уменьшается до меньших значений в постоянном режиме по сравнению с непостоянным режимом, значит, цель фазза сохраняет состояние. Примеры можно найти в utils/persistent_mode.
TL;DR:
#include "what_you_need_for_your_target.h" __AFL_FUZZ_INIT(); main() < // anything else here, e.g. command line arguments, initialization, etc. #ifdef __AFL_HAVE_MANUAL_CONTROL __AFL_INIT(); #endif unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT // and before __AFL_LOOP! while (__AFL_LOOP(10000)) <  int len = __AFL_FUZZ_TESTCASE_LEN; // don't use the macro directly in a // call! if (len < 8) continue; // check for a required/useful minimum input length /* Setup function call, e.g. struct target *tmp = libtarget_init() */ /* Call function to be fuzzed, e.g.: */ target_function(buf, len); /* Reset state. e.g. libtarget_free(tmp) */ >return 0; >afl-clang-fast -o fuzz_target fuzz_target.c -lwhat_you_need_for_your_targetИ все! Прирост скорости обычно составляет от x10 до x20.
Если вы хотите иметь возможность компилировать цель без afl-clang-fast/lto , то добавьте это сразу после include :
#ifndef __AFL_FUZZ_TESTCASE_LEN ssize_t fuzz_len; #define __AFL_FUZZ_TESTCASE_LEN fuzz_len unsigned char fuzz_buf[1024000]; #define __AFL_FUZZ_TESTCASE_BUF fuzz_buf #define __AFL_FUZZ_INIT() void sync(void); #define __AFL_LOOP(x) ((fuzz_len = read(0, fuzz_buf, sizeof(fuzz_buf))) > 0 ? 1 : 0) #define __AFL_INIT() sync() #endifОтложенная инициализация
AFL++ пытается оптимизировать производительность, выполняя целевой двоичный файл только один раз, останавливая его непосредственно перед main() , а затем клонируя этот «главный» процесс, чтобы получить постоянный запас целей для fuzz.
Хотя этот подход устраняет большую часть затрат на выполнение программы на уровне ОС, компоновщика и libc, он не всегда помогает в случае двоичных файлов, которые выполняют другие требующие много времени шаги инициализации — например, разбор большого файла конфигурации, прежде чем добраться до фаззируемых данных.
В таких случаях полезно инициализировать forkserver немного позже, когда большая часть работы по инициализации уже выполнена, но до того, как двоичный файл попытается прочитать входные данные fuzzed и разобрать их; в некоторых случаях это может дать прирост производительности более чем в 10 раз. Вы можете реализовать отложенную инициализацию в режиме LLVM довольно простым способом.
Во-первых, найдите подходящее место в коде, где может происходить отложенное клонирование. Это нужно делать с особой осторожностью, чтобы не сломать двоичный код. В частности, программа, вероятно, будет работать неправильно, если вы выберете место после:
- Создание любых жизненно важных потоков или дочерних процессов — поскольку forkserver не может легко клонировать их.
- Инициализация таймеров с помощью setitimer() или аналогичных вызовов.
- Создание временных файлов, сетевых сокетов, файловых дескрипторов, чувствительных к смещению, и подобных ресурсов с общим состоянием — но только при условии, что их состояние значимо влияет на поведение программы в дальнейшем.
- Любой доступ к входным данным fuzzed, включая чтение метаданных об их размере.
- Выбрав местоположение, добавьте этот код в соответствующее место:
#ifdef __AFL_HAVE_MANUAL_CONTROL __AFL_INIT(); #endifЗащитные #ifdef не нужны, но их включение гарантирует, что программа будет работать нормально при компиляции с помощью инструмента, отличного от afl-clang-fast/ afl-clang-lto/afl-gcc-fast.
Наконец, перекомпилируйте программу с помощью afl-clang-fast/afl-clang-lto/afl-gcc-fast (afl-gcc или afl-clang не будут генерировать двоичный файл с отложенной инициализацией) — и все готово!
Постоянный режим — Persistance mode
Некоторые библиотеки предоставляют API, которые не имеют состояния или состояние которых может быть сброшено между обработкой различных входных файлов. Когда выполняется такой сброс, один долгоживущий процесс может быть повторно использован для опробования нескольких тестовых примеров, устраняя необходимость в повторных вызовах fork() и связанные с этим накладные расходы ОС.
Основная структура программы, которая это делает, будет выглядеть следующим образом:
while (__AFL_LOOP(1000)) < /* Read input data. */ /* Call library code to be fuzzed. */ /* Reset state. */ >/* Exit normally. */
Числовое значение, указанное в цикле, контролирует максимальное количество итераций, прежде чем AFL++ перезапустит процесс с нуля. Это минимизирует влияние утечек памяти и подобных глюков; 1000 является хорошей отправной точкой, а увеличение этого значения увеличивает вероятность зависаний, не давая реального выигрыша в производительности.
Более подробный шаблон показан в utils/persistent_mode. Как и отложенная инициализация, эта функция работает только в afl-clang-fast; для подавления ее при использовании других компиляторов можно использовать защитные символы #ifdef .
Обратите внимание, что, как и в случае с отложенной инициализацией, этой функцией легко злоупотребить; если вы не полностью сбросите критическое состояние, вы можете получить ложные срабатывания или потратить много процессорной мощности, не делая ничего полезного. Будьте особенно внимательны к утечкам памяти и состоянию дескрипторов файлов.
При работе в этом режиме пути выполнения будут немного отличаться в зависимости от того, вводится ли цикл ввода впервые или выполняется повторно.
Фаззинг общей памяти
Вы можете еще больше ускорить процесс фаззинга, получая данные фаззинга через общую память, а не через stdin или файлы. Это еще больше увеличивает скорость примерно в 2 раза.
Настроить это очень просто:
После include установите следующий макрос:
__AFL_FUZZ_INIT();Непосредственно в начале main — или, если вы используете отложенный forkserver с __AFL_INIT() , то после __AFL_INIT() :
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF;Затем в качестве первой строки после цикла __AFL_LOOP while:
int len = __AFL_FUZZ_TESTCASE_LEN;Персистентная очередь
Персистентная очередь (англ. persistent queue) — это очередь, реализующая персистентность, то есть позволяющая получить доступ ко всем своим предыдущим версиям. Как будет показано далее, можно реализовать функциональную персистентность, то есть каждая ячейка памяти в такой структуре будет инициализирована один раз и в дальнейшем не изменится.
Основная идея
Для создания персистентной очереди очень удобно пользоваться ее реализацией на стеках, поскольку стеки легко сделать персистентными, причем в этом случае мы добьемся функциональной персистентности. Реализация на двух стеках не подходит для этого, так как в худшем случае требует [math]O(n)[/math] времени, а значит и [math]O(n)[/math] памяти на операцию в случае персистентности. Покажем сначала, как создать очередь в реальном времени с [math]O(1)[/math] времени на операцию, а затем превратим ее в персистентную.
Реализация очереди на шести стеках
Одним из минусов реализации на двух стеках является то, что в худшем случае мы тратим [math]O(n)[/math] времени на операцию. Если распределить время, необходимое для перемещения элементов из одного стека в другой, по операциям, мы получим очередь без худших случаев с [math]O(1)[/math] истинного времени на операцию.
Сначала будем действовать аналогично случаю с двумя стеками. Пусть у нас есть стек [math]L[/math] для операций [math]\mathtt[/math] и стек [math]R[/math] для операций [math]\mathtt[/math] . К моменту опустошения стека [math]R[/math] нам нужно успеть получить стек [math]R'[/math] , содержащий текущие элементы стека [math]L[/math] в правильном для извлечения порядке. Перекопирование (recopy mode) начнется, когда появится опасность того, что мы не сможем за оставшиеся [math]R.size[/math] операций [math]\mathtt[/math] со стеком [math]R[/math] перекопировать стек [math]L[/math] в новый стек [math]R'[/math] . Очевидно, это ситуация [math]L.size\gt R.size[/math] , пусть такое состояние отражает специальная переменная логического типа [math]\mathtt[/math] .
Понятно, что во время перекопирования могут поступить операции [math]\mathtt[/math] , а стек [math]L[/math] в это время потеряет свою структуру, сложить элементы туда мы уже не сможем, значит нужно завести еще один стек [math]L'[/math] , в который мы и будем складывать новые элементы. После окончания перекопирования мы поменяем ролями [math]L,L'[/math] и [math]R,R'[/math] , на первый взгляд, все станет хорошо.
Однако, если реализовать этот алгоритм, мы получим неприятную вещь: старый стек [math]R[/math] может и не опустошиться за это время, то есть мы получили два стека с выходными данными, а значит, возможен случай (например, если все поступающие операции — [math]\mathtt[/math] ), когда при следующем перекопировании у нас не будет свободного стека для копирования туда элементов [math]L[/math] . Для преодоления этой проблемы мы принудительно будем извлекать все элементы из стека [math]R[/math] во вспомогательный стек [math]S[/math] , затем копировать элементы из стека [math]L[/math] в [math]R[/math] , а затем обратно копировать элементы из стека [math]S[/math] в [math]R[/math] . Легко показать, что приведенный алгоритм как раз получает на выходе в [math]R[/math] все элементы стеков [math]L,R[/math] в правильном порядке.
Но этого еще недостаточно. Если мы принудительно извлекаем элементы из стека [math]R[/math] , появляются следующие проблемы:
- Что вернуть при операции [math]\mathtt[/math] ? Для этого заведем себе стек [math]Rc[/math] — копию стека [math]R[/math] , из которого мы и будем извлекать требуемые элементы.
- Как поддерживать корректность такой копии? Поскольку этот стек нужен только для перекопирования, а во время него он занят, нужна запасная копия [math]Rc'[/math] для копирования всех элементов, которые мы копируем в [math]R[/math] , а по окончании перекопирования поменяем ролями стеки [math]Rc, Rc'[/math] , как мы делали со стеками [math]L, L'[/math] .
- Как учесть, что во время перекопирования часть элементов была извлечена из [math]Rc[/math] ? Для этого заведем специальную переменную [math]\mathtt[/math] , которая показывает, сколько корректных элементов находится в стеке [math]S[/math] , и уменьшается при каждом извлечении из [math]S[/math] или операции [math]\mathtt[/math] . К счастью, все некорректные элементы будут нарастать со дна стека, так что мы никогда не извлечем некорректный элемент, если [math]\mathtt\gt 0[/math] . Если во время операции [math]\mathtt[/math] у нас [math]\mathtt = 0[/math] , это означает, что теперь в стеке [math]R[/math] находится весь правый кусок очереди, так что нам придется извлечь элемент из него.
Теперь может возникнуть проблема с непустым [math]Rc[/math] после завершения перекопирования. Покажем, что мы всегда успеем его опустошить, если будем использовать дополнительное извлечение из него при каждой операции в обычном режиме, для этого полностью проанализируем алгоритм.
Пусть на начало перекопирования в стеке [math]R[/math] содержится [math]n[/math] элементов, тогда в стеке [math]L[/math] находится [math]n + 1[/math] элементов. Мы корректно можем обработать любое количество операций [math]\mathtt[/math] , а также [math]n[/math] операций [math]\mathtt[/math] . Заметим, что операция [math]\mathtt[/math] во время перекопирования всегда возвращает [math]false[/math] , так как мы не можем извлекать элементы из стека [math]L[/math] , который не пустой. Таким образом вместе с операцией, активирующей перекопирование, мы гарантированно можем корректно обработать [math]n + 1[/math] операцию.
Посмотрим на дополнительные действия, которые нам предстоят:
- Переместить содержимое [math]R[/math] в [math]S[/math] , [math]n[/math] действий.
- Переместить содержимое [math]L[/math] в стеки [math]R, Rc'[/math] , [math]n + 1[/math] действий.
- Переместить первые [math]\mathtt[/math] элементов из [math]S[/math] в [math]R, Rc'[/math] , остальные выкинуть, [math]n[/math] действий.
- Поменять ролями стеки [math]Rc, Rc'[/math] , [math]L, L'[/math] , [math]2[/math] действия.
Таким образом, получили [math]3 \cdot n + 3[/math] дополнительных действия за [math]n + 1[/math] операций, или [math]3 = O(1)[/math] дополнительных действий на операцию в режиме перекопирования, что и требовалось.
Теперь рассмотрим, как изменились наши стеки за весь период перекопирования. Договоримся, что операция [math]\mathtt[/math] не меняет очередь, то есть никакие дополнительные действия не совершаются. Пусть за [math]n[/math] следующих за активацией меняющих операций ( [math]\mathtt, \mathtt[/math] ) поступило [math]x[/math] операций [math]\mathtt[/math] , [math]n — x[/math] операций [math]\mathtt[/math] . Очевидно, что после перекопирования в новых стеках окажется: [math]n-x[/math] элементов в [math]L[/math] , [math]2 \cdot n + 1 — x = (n — x) + (n + 1)[/math] элементов в [math]R[/math] , то есть до следующего перекопирования еще [math]n + 2[/math] операции. С другой стороны, стек [math]Rc[/math] содержал всего [math]n[/math] элементов, так что мы можем очистить его, просто удаляя по одному элементу при каждой операции в обычном режиме.
Итак, очередь [math]Q[/math] будет состоять из шести стеков [math]L,L’,R,Rc,Rc’,S[/math] , а также двух внутренних переменных [math]\mathtt, \mathtt[/math] , которые нужны для корректности перекопирования + дополнительная переменная [math]\mathtt[/math] , показывающая, перемещали ли мы элементы из стека [math]L[/math] в стек [math]R[/math] , чтобы не начать перемещать эти элементы в стек [math]S[/math] .
Инвариант очереди (обычный режим):
- Стек [math]L[/math] содержит левую половину очереди, порядок при извлечении обратный.
- Стек [math]R[/math] содержит правую половину очереди, порядок при извлечении прямой.
- [math]L.size \leqslant R.size[/math]
- [math]R.size = 0 \equiv Q.size = 0[/math]
- [math]Rc[/math] — копия [math]R[/math]
- [math]Rc’.size \lt R.size — L.size[/math]
- [math]L’.size = 0, S.size = 0[/math]
Тогда к следующему перекопированию ( [math]L.size=R.size+1[/math] ) мы гарантированно будем иметь пустые стеки [math]L’,S,Rc'[/math] , которые нам понадобятся.
Инвариант очереди (режим перекопирования):
- [math]Rc.size = \mathtt[/math]
- Если [math]L.size = 0[/math] , то:
- При [math]\mathtt \gt 0[/math] первые [math]\mathtt[/math] элементов [math]S[/math] — корректны, то есть действительно содержатся в очереди.
- При [math]\mathtt \leqslant 0[/math] стек [math]R[/math] содержит весь правый кусок очереди в правильном порядке.
Очередь будет работать в двух режимах:
- Обычный режим, кладем в [math]L[/math] , извлекаем из [math]R[/math] и из [math]Rc, Rc'[/math] для поддержания порядка, операция [math]empty = (R.size = 0)[/math] .
- Режим перекопирования, кладем в [math]L'[/math] , извлекаем из [math]Rc[/math] , возможно из [math]R[/math] , [math]\mathtt = \mathtt[/math] , совершаем дополнительные действия.
Также после операции в обычном режиме следует проверка на активацию перекопирования ( [math]\mathtt = (L.size \gt R.size)[/math] ), если это так, [math]\mathtt = R.size, \mathtt = true, \mathtt = false[/math] , совершается первый набор дополнительных действий.
После операции в режиме перекопирования следует проверка на завершение перекопирования ( [math]\mathtt = (S.size == 0)[/math] ), а при завершении меняются ролями стеки [math]Rc, Rc'[/math] , [math]L, L'[/math] .
Следующий псевдокод выполняет требуемые операции:
empty
boolean empty(): return !recopy and R.size == 0
push
function push(x : T): if !recopy L.push(x) if Rc'.size > 0 Rc'.pop() checkRecopy() else L'.push(x) checkNormal()
pop
T pop(): if !recopy T tmp = R.pop() Rc.pop() if Rc'.size > 0 Rc'.pop() checkRecopy() return tmp else T tmp = Rc.pop() if toCopy > 0 toCopy = toCopy - 1 else R.pop() Rc'.pop() checkNormal() return tmp
checkRecopy
function checkRecopy(): recopy = L.size > R.size if recopy toCopy = R.size copied = false checkNormal()
checkNormal
function checkNormal(): additionalOperations() // Если мы не все перекопировали, то у нас не пуст стек S recopy = S.size 0
additionalOperations
function additionalOperations(): // Нам достаточно 3 операций на вызов int toDo = 3 // Пытаемся перекопировать R в S while not copied and toDo > 0 and R.size > 0 S.push(R.pop()) toDo = toDo - 1 // Пытаемся перекопировать L в R и Rc' while toDo > 0 and L.size > 0 copied = true T x = L.pop() R.push(x) Rc'.push(x) toDo = toDo - 1 // Пытаемся перекопировать S в R и Rc' с учетом toCopy while toDo > 0 and S.size > 0 T x = S.pop() if toCopy > 0 R.push(x) Rc'.push(x) toCopy = toCopy - 1 toDo = toDo - 1 // Если все скопировано, то меняем роли L, L' и Rc, Rc' if S.size == 0 swap(L, L') swap(Rc, Rc')
Персистентная очередь на пяти стеках
После того, как мы получили очередь в реальном времени с [math]O(1) = 6[/math] обычными стеками, ее можно легко превратить в персистентную, сделав все стеки персистентными, но на самом деле персистентность позволяет не создавать явной копии стека [math]R[/math] , так что достаточно всего пяти стеков.
Вместо стеков [math]Rc, Rc'[/math] персистентная очередь хранит один стек [math]R'[/math] , в который при активации перекопирования записывается последняя версия стека [math]R[/math] , в дальнейшем все операции [math]\mathtt[/math] обращаются именно к ней. Все замечания о [math]\mathtt[/math] остаются в силе.
Также нам нет необходимости опустошать стек [math]R'[/math] к моменту перекопирования, так как скопировать туда новую версию [math]R[/math] мы можем за [math]O(1)[/math] , а освобождение ячеек памяти бессмысленно, так как они используются в других версиях персистентной очереди.
В качестве версии очереди мы будем использовать запись [math]Q= \langle L, L’, R, R’, S, \mathtt, \mathtt, \mathtt\rangle[/math] , содержащую пять версий персистентных стеков и три переменных.
Пусть персистентный стек возвращает вместе с обычным результатом работы стека новую версию, то есть операция [math]S.pop[/math] возвращает [math]\langle Sn, x\rangle[/math] , а операция [math]S.push(x)[/math] возвращает [math]Sn[/math] .
Аналогично свою новую версию вместе с результатом операции возвращает и персистентная очередь, то есть [math]Q.pop[/math] возвращает [math]\langle Qn, x\rangle[/math] , а [math]Q.push(x)[/math] возвращает [math]Qn[/math] .
Следующий псевдокод выполняет требуемые операции:
empty
boolean empty(): return !recopy and R.size == 0
push
function push(x : T): if !recopy stack Ln = L.push(x) stack , stack , stack , stack , stack , boolean, int, boolean> Q' = return Q'.checkRecopy() else stack Ln' = L'.push(x) stack , stack , stack , stack , stack , boolean, int, boolean> Q' = return Q'.checkNormal()
pop
stack , T> pop(): if !recopy = R.pop() stack , stack , stack , stack , stack , boolean, int, boolean> Q’ = return else = R’.pop() int curCopy = toCopy Rn = R if toCopy > 0 curCopy = curCopy — 1 else = Rn.pop() Q’ = return
checkRecopy
stack , stack , stack , stack , stack , boolean, int, boolean> checkRecopy(): if L.size > R.size stack , stack , stack , stack , stack , boolean, int, boolean> Q’ = return Q’.checkNormal() else return
checkNormal
stack , stack , stack , stack , stack , boolean, int, boolean> checkNormal(): Q' = Q.additionalOperations() // Если мы не все перекопировали, то у нас не пуст стек S return [math] \ne [/math] 0, Q'.toCopy, Q'.copied>additionalOperations
stack , stack , stack , stack , stack , boolean, int, boolean> additionalOperations(): // Нам достаточно 3 операций на вызов int toDo = 3 // Пытаемся перекопировать R в S stack Rn = R stack Sn = S boolean curCopied = copied while not curCopied and toDo > 0 and Rn.size > 0 = Rn.pop() Sn = Sn.push(x) toDo = toDo — 1 Ln = L // Пытаемся перекопировать L в R while toDo > 0 and Ln.size > 0 curCopied = true = Ln.pop() Rn = Rn.push(x) toDo = toDo — 1 curCopy = toCopy // Пытаемся перекопировать S в R с учетом toCopy while toDo > 0 and Sn.size > 0 = Sn.pop() if curCopy > 0 Rn = Rn.push(x) curCopy = curCopy — 1 toDo = toDo — 1 stack Ln’ = L’ // Если все скопировано, то меняем роли L1, L2 if S.size == 0 swap(Ln, Ln’) return
Пример
Пусть мы создали персистентную очередь. Будем изображать ее в виде пяти деревьев версий персистентных стеков, закрашенные вершины — текущие версии стеков, соответствующие текущему состоянию очереди; стрелка от стека [math]R'[/math] указывает на ту версию стека [math]R[/math] , которая там сейчас хранится. В самих вершинах записаны соответствующие этим вершинам значения.

Сделаем операцию [math] \mathtt [/math] , изначально режим обычный, так что элемент пойдет в стек [math]L[/math] . Эта операция активирует режим перекопирования, в результате которого содержимое [math]L[/math] перекопируется в стек [math]R[/math] , после чего перекопирование завершится, стеки [math]L, L'[/math] поменяются местами.
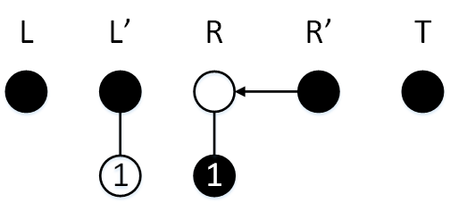
Сделаем операцию [math] \mathtt [/math] , у нас обычный режим, поэтому элемент пойдет в стек [math]L[/math] , перекопирование не активируется.
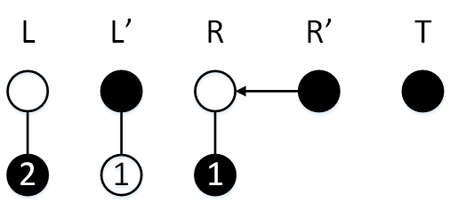
Сделаем операцию [math] \mathtt [/math] , у нас обычный режим, поэтому элемент пойдет в стек [math]L[/math] , активируется перекопирование, [math]R’ = R[/math] , за три операции мы успеваем перекопировать элемент стека [math]R[/math] в стек [math]S[/math] , а также перекопировать два элемента стека [math]L[/math] в стек [math]R[/math] .
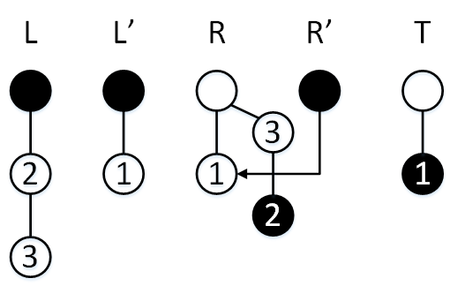
Сделаем операцию [math] \mathtt [/math] , мы в режиме перекопирования, поэтому элемент пойдет в стек [math]L'[/math] , далее мы успеваем перекопировать обратно элемент из стека [math]S[/math] в стек [math]R[/math] , перекопирование завершается, стеки [math]L, L'[/math] меняются местами.
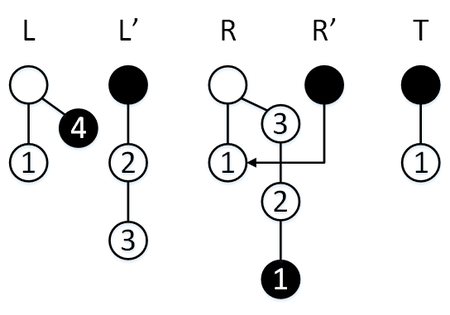
Сделаем операцию [math] \mathtt [/math] , у нас обычный режим, поэтому элемент пойдет в стек [math]L[/math] , перекопирование не активируется.
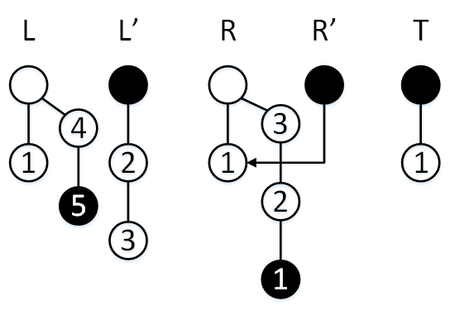
Сделаем операцию [math] \mathtt [/math] , у нас обычный режим, поэтому элемент пойдет в стек [math]L[/math] , перекопирование не активируется.
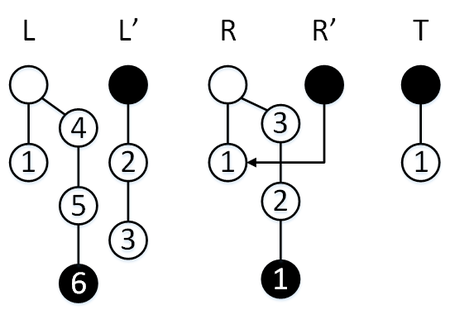
Сделаем операцию [math] \mathtt [/math] , у нас обычный режим, поэтому элемент пойдет в стек [math]L[/math] , перекопирование активируется, [math]R’ = R[/math] , [math]\mathtt = 3[/math] , за три операции мы успеваем перекопировать содержимое стека [math]R[/math] в стек [math]S[/math] .
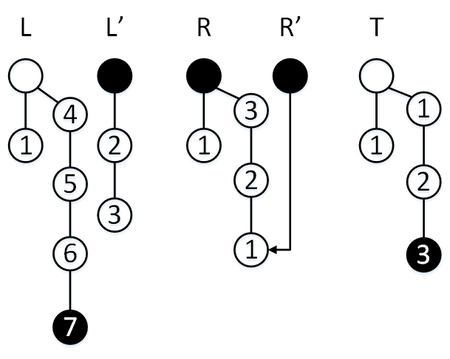
Сделаем операцию [math]\mathtt[/math] , мы находимся в режиме перекопирования, так что элемент извлекается из [math]R'[/math] , [math]\mathtt = 2[/math] . За три операции мы успеваем перекопировать три элемента стека [math]L[/math] в стек [math]R[/math] .
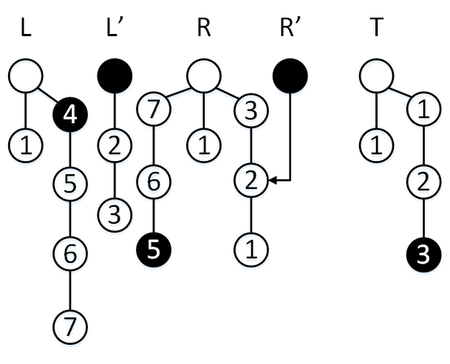
Сделаем операцию [math]\mathtt[/math] , мы находимся в режиме перекопирования, так что элемент извлекается из [math]R'[/math] , [math]\mathtt = 1[/math] . За три операции мы успеваем перекопировать один элемент стека [math]L[/math] в стек [math]R[/math] , а также извлечь два элемента стека [math]S[/math] , с учетом [math]\mathtt[/math] только один элемент попадет в стек [math]R[/math] , [math]\mathtt = 0[/math] .
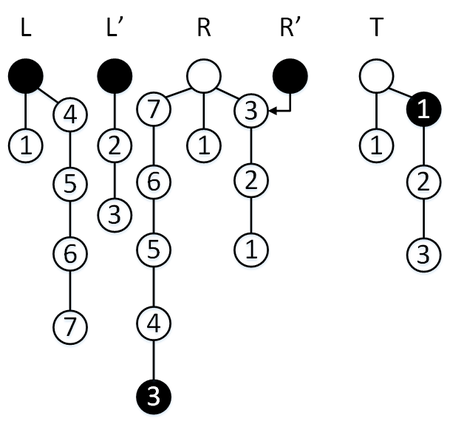
Сделаем операцию [math]\mathtt[/math] , мы находимся в режиме перекопирования, так что элемент извлекается из [math]R'[/math] , но [math]\mathtt = 0[/math] , так что нам приходится извлечь еше один элемент из стека [math]R[/math] . Мы извлекаем один элемент из стека [math]S[/math] , перекопирование заканчивается, стеки [math]L, L'[/math] меняются местами.
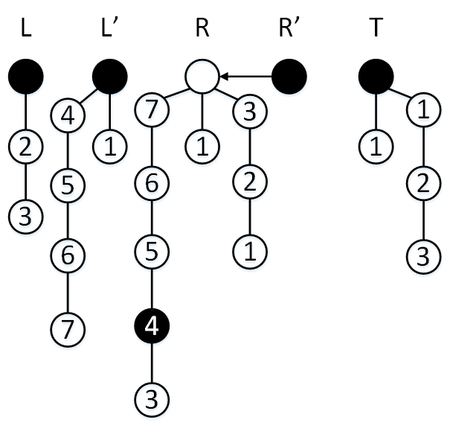
См. также
- Персистентный стек
- Персистентный дек
- Персистентная приоритетная очередь
Источники информации
- Hood R., Melville R. Real Time Queue Operations in Pure LISP. — Cornell University, 1980
- Хабрахабр — Персистентная очередь
- Codeforces — Персистентная очередь и её друзья
Да бл persistence как сделать?
В общем пытаюсь сделать все как в инструкции на codeby, на флешке с образом создаю новый раздел persistence, с параметрами primary и ext4, вставляю загружаю Kali live, в консоли с помощью fdisk -l смотрю на диски. Далее
mount /dev/sda3 /mnt/USB
echo «/ union» >> /mnt/USB/persistence.conf
Kali с оф. сайта, еще если поможет, я еще когда в Окнах сидел, заметил что этот компьютер говорит что флешка 32G свободна на 27кб, а программа для разметки говорит что у меня 27G свободного места, и именно это место занимает созданный мною раздел sda3. Можно на кали без танцев с бубном поработать?
Ah_shit
22.09.19 10:23:49 MSKМожно на кали без танцев с бубном поработать
Можно, если умеешь. А если нет, возьми ubuntu.
Yorween ★
( 22.09.19 10:27:15 MSK )
Ответ на: комментарий от Yorween 22.09.19 10:27:15 MSKСпасибо, научусь когда нибудь и на кали
Ah_shit
( 22.09.19 10:30:10 MSK ) автор топика
Ответ на: комментарий от Ah_shit 22.09.19 10:30:10 MSKВот на это заблуждение тебе все и указывают . На личном опыте отговаривающих это основано . На этом Kali — никогда — ничему не научишься. Он не для этого сделан . Как и что делать — уже писали .
anonymous
( 22.09.19 11:51:31 MSK )
Ну вот зачем ты **** с Кали? Это не принесет _никакой_ выгоды — возня со специализированным глюкодромом не дает никаких профессиональных или житейских навыков.
Не используй Kali Linux, его разрекламированность как «сложный дистрибутив, изучив который станешь профи» является мифом, и разработчики Kali Linux не рекомендуют его как плацдарм для изучения Linux. Для изучения професионального использования Linux предпочтительнее Debian stable/Ubuntu LTS или CentOS.
Не ведись на хайп с ютубчика — читай официальную документацию.
Kali — дистрибутив со специальным ПО для пентестов.
И достаточно долго он оставался известным довольно узкой группе людей — как магазин с отмычками не имеет особой популярности вне своей аудитории.
Но потом произошло событие — выход сериала Mr. Robot. У Kali Linux — достаточно необычный и вычурный дизайн, именно потому его и выбрали сценаристы как десктоп для одного из персонажей, который хакер.
Потом это попало на YouTube — и миф уже было не остановить. Kali Linux действительно используется для пентестов, но как плацдарм для изучения Linux он так себе (ссылку давал). Но сейчас хайп и мифы YouTube популярнее чтения нормальной официальной документации.
Kali как профессиональный дистр лишь миф, порожденный «Mr. Robot».
Но есть такие товарищи, их зовут script kiddies — так называют тех, кто осуществляет взломы готовыми инструментами. В среде IT их _не_ уважают, так как такой взлом не требует ума и навыков.
Потому любой, кто ставит Kali, по умолчанию получает клеймо IT-гопника, тупого и агрессивного подростка, что ломает соседский WiFi ради понтов. Это _не_ круто, это мерзко.
Именно этим и объясняется ушат помоев, что ты получил здесь в лицо.
Vsevolod-linuxoid ★★★★★
( 22.09.19 11:58:20 MSK )
Последнее исправление: Vsevolod-linuxoid 22.09.19 12:01:33 MSK (всего исправлений: 2)