Как правильно использовать View в PostgreSQL?
Я знаю, как создавать View и как получать данные оттуда. Вопрос вот в чем: эти viewe —
1. это что-то вроде интерпретатора SQL команд? Когда я делаю запрос типа `SELECT * FROM mycustomview` мой запрос просто является оберткой для того запроса, который я написал при создании этого View? В таком случае, это только удобство, но не performance.
2. или View — это реальные таблицы, сформированные из всех данных, которые получены из того запроса, что я использовал при создании View? В таком случае это сильно влияет не только на удобство но и на performance.
Если View работает как интерпритатор (1), есть ли какие-то общепринятые подходы для того, чтобы делать то, что я описал под цифрой 2?
В последних версиях Postgres появляется все больше фишек для работы с json. Есть ли смысл создавать triggers или rules для того, чтобы данные из определенных таблиц складывались в новую специальную таблицу, чтобы избежать необходимости делать сложные запросы для получения этих данных?
CREATE TABLE "public"."user" ( "email" varchar(36) NOT NULL COLLATE "default", "password" varchar(16) NOT NULL COLLATE "default", "id" uuid NOT NULL DEFAULT uuid_generate_v4(), CONSTRAINT "User_pkey" PRIMARY KEY ("id") NOT DEFERRABLE INITIALLY IMMEDIATE ) WITH (OIDS=FALSE); ALTER TABLE "public"."user" OWNER TO "postgres"; CREATE UNIQUE INDEX "users_id_key" ON "public"."user" USING btree("id" ASC NULLS LAST); CREATE TABLE "public"."friend" ( "id" uuid NOT NULL DEFAULT uuid_generate_v4(), "name" varchar(36) NOT NULL COLLATE "default", CONSTRAINT "ability_pkey" PRIMARY KEY ("id") NOT DEFERRABLE INITIALLY IMMEDIATE, ) WITH (OIDS=FALSE); ALTER TABLE "public"."friend" OWNER TO "postgres"; CREATE UNIQUE INDEX "ability_id_key" ON "public"."friend" USING btree("id" ASC NULLS LAST); CREATE TABLE "public"."user_friend" ( "id" uuid NOT NULL DEFAULT uuid_generate_v4(), "owner" uuid NOT NULL, "friend" uuid NOT NULL, CONSTRAINT "ability_relation_pkey" PRIMARY KEY ("id") NOT DEFERRABLE INITIALLY IMMEDIATE, CONSTRAINT "owner" FOREIGN KEY ("owner") REFERENCES "public"."user" ("id") ON UPDATE NO ACTION ON DELETE CASCADE NOT DEFERRABLE INITIALLY IMMEDIATE, CONSTRAINT "friend" FOREIGN KEY ("friend") REFERENCES "public"."friend" ("id") ON UPDATE NO ACTION ON DELETE CASCADE NOT DEFERRABLE INITIALLY IMMEDIATE ) WITH (OIDS=FALSE); ALTER TABLE "public"."user_friend" OWNER TO "postgres";Например, мне необходимо постоянно делать запросы вроде такого:
select row_to_json(t) from ( select public.user.email, ( select array_to_json(array_agg(row_to_json(ability_relations))) from ( select * from public.friend where public.friend.id in ( select public.user_friend.friend from public.user_friend where public.user_friend.owner=public.user.id ) ) ability_relations ) as abilities from public.user ) tЭто не самый сложный запрос, дочерних таблиц привязанных с помощью Foreign Key может быть до 4 штук. следовательно, запрос будет в 4 раза тяжелее.
Запросы на получение этих данных в сотни и тысячи раз чаще чем запросы на изменение этих данных. Имеет ли смысл с помощью triggers или rules создавать специальные таблицы, которые будут наполняться собранными в json объекты данными?
Благодарю за уделенное время!
- Вопрос задан более трёх лет назад
- 4129 просмотров
SQL-Ex blog

Эта статья поможет вам понять, что такое представление в базе данных в общем, и что такое представление конкретно в PostgreSQL. Вы научитесь создавать/писать запросы/удалять представление в PostgreSQL, осваивая соответствующий синтаксис на рабочих примерах, используя для этого терминал Psql или инструмент PgAdmin.
Что такое представление?
Представление в SQL можно рассматривать как виртуальную таблицу, которая основана на результирующем наборе оператора SQL. Подобно реальной таблице представление состоит из строк и столбцов, и оно может включать данные из одной или большего числа таблиц. Представление не содержит каких либо данных, которые нужно было бы физически хранить, т.е. оно не сохраняется в памяти и фактически не занимает места в хранилище. Подобно таблице SQL, имя представления должно быть уникальным в пределах базы данных. Так как представлению назначаются отдельные разрешения, представления могут использоваться для ограничения доступа к таблицам, так что пользователи видят только конкретные строки или столбцы таблицы.
Представление в PostgreSQL удовлетворяет всем упомянутым характеристикам и может быть создано с помощью нижеприведенного синтаксиса:
CREATE [TEMP | TEMPORARY] VIEW имя_представления AS
SELECT столбец1, столбец2.
FROM имя_таблицы
WHERE [условие];
Здесь имя представления указывается после ключевых слов ‘CREATE VIEW’, после чего следуют требуемые столбцы из таблицы, а затем условие WHERE. Ключевое слово ‘Temp/Temporary’ не является обязательным и задается, если создается временное представление. Временное представление прекращает существование в конце текущего сеанса.
Пример:
CREATE VIEW STOCK_VIEW AS
SELECT stock_id, stock_name, stock_price
FROM stocks;

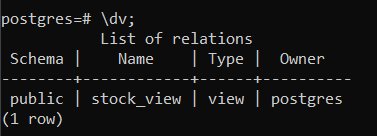
Вывод списка представлений в терминале Psql:
Для вывода всех представлений в схеме PostgreSQL может использоваться команда ‘\dv’.
Создание представления в PgAdmin
Для создания представления в PgAdmin нужно перейти в раздел меню ‘views->Create->View’, как показано ниже:

Список представлений в PgAdmin
После создания представления либо в терминале Psql, либо в PgAdmin, его можно увидеть в списке ‘Views’ готовым для использования, как показано ниже.
Запрос к представлению
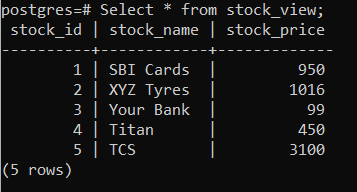
Запрос на выборку данных из представления PostgreSQL подобен запросу из таблицы. Вот синтаксис:
Select * from stock_view;
Запрос к представлению в PgAdmin
Для запроса к представлению в PgAdmin нужно перейти в меню ‘Views->View->View/Edit Data’. Затем пользователю будет предложено несколько вариантов, из которых пользователь может сделать выбор на основе его требований и получить данные. Заметим, что хотя опция здесь читается как ‘View/Edit Data’ (просмотр/редактирование данных), представления не могут редактироваться. Однако если обновляются данные в исходной таблице, это также отражается в представлении.

Удаление представления
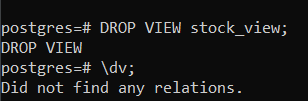
Запрос на удаление представления простой и короткий. Чтобы удалить представление, укажите имя представления сразу после ключевых слов ‘DROP VIEW’.
DROP VIEW имя_представления;
Удаление представления в PgAdmin
Чтобы удалить представление в PgAdmin, необходимо перейти в меню ‘Views->View->Delete/Drop’.
PostgreSQL, как создать VIEW (представление)
В PostgreSQL, view — это виртуальная таблица (представление). Она хранит результат выполнения SELECT запроса. С помощью вьюхи можно сохранить SELECT запрос и получить быстрый доступ к часто используемым данным.
Создание представление (view) — это альтернативное решение. У него есть свои плюсы и минусы.
Как создать вью в PostgreSQL
Создать вьюху в постгрес намного проще, чем хранимую процедуру. Чтобы сохранить результат SELECT запроса в представление, нужно написать
CREATE VIEW view_name AS Замени view_name на что-то, что больше похоже на данные которые ты сохраняешь и после ключевого слова AS напиши свой SELECT запрос.
Если мы представим, что у нас есть таблица users и у каждого юзера есть поле follower_count , то нам может быть полезно создать вью popular_users и включить туда всех пользователей у которых более 1000 подписчиков.
CREATE VIEW influencers AS SELECT name, email, created_at FROM users WHERE follower_count > 1000; Сложность SELECT запроса может быть любой. Тебя никто не ограничивает. Можешь добавить джойны, группировки или еще что-то. Единственное ограничение в том, что команда ORDER BY не может использоваться в PostgreSQL вью.
Вьюха будет выглядеть как таблица в твоей базе данных. Это очень удобно если ты пользуешься GUI клиентом.
Как удалить вью в PostgreSQL
Чтобы удалить представление в PostgreSQL используется похожий на удаление таблицы синтаксис:
DROP view [ IF EXISTS ] view_name; Флаг IF EXISTS не обязателен. Его полезно добавить, чтобы защититься от ошибок, которые появятся если ты случайно сделаешь опечатку в имени вьюхи view_name .
Правила перезаписи PostgreSQL

Представления (Views) — это не совсем то, о чём вы можете подумать. В этой статье мы разберём правила перезаписи PostgreSQL, как они работают, что они могут и чего не могут делать.
Начиная с версии 10, PostgreSQL поддерживает концепцию правил перезаписи, которые позволяют изменять способ выполнения запросов.
Фактически правила перезаписи — это то, как представления реализованы в PostgreSQL. Когда вы обращаетесь к представлению, ваш запрос фактически переписывается в соответствии с правилом, которое было создано при создании представления. По сути, представление — это, как мы сейчас увидим, правило перезаписи.
Однако не стоит расслабляться — некоторые условности всё же есть. Например, эти правила перезаписи сильно отличаются от плагинов перезаписи MySQL и в целом являются более комплексными.
Основные положения
Когда вы определяете правило перезаписи, вы сообщаете PostgreSQL, как обрабатывать определённый тип запроса к определённой таблице или представлению.
Правила перезаписи могут быть определены для SELECT, UPDATE, INSERT и DELETE. Они не существуют для любых других запросов, таких как DDL, SET, FETCH и т. д., по причинам, которые быстро станут очевидными.
Правила SELECT
Правила перезаписи для SELECT сильно ограничены; по сути, они могут определять только представление. На самом деле правила перезаписи для SELECT редко создаются напрямую; с тем же успехом вы можете определить представление, поскольку оператор CREATE VIEW приведёт к тому же результату, а именно к созданию новой строки в таблице pg_catalog.pg_rewrite .
Для этих ограничений есть очень веская причина: PostgreSQL включает правила в свою интерпретацию запросов. В случае правил SELECT он заменит имя отношения на то, что указано в правиле. Это означает, что правило SELECT должно быть простым SELECT, и поэтому правило не может делать ничего такого, что не может делать обычное представление.
Рассмотрим пример. Возьмём простую таблицу:
CREATE TABLE Persons ( id INT PRIMARY KEY, first_name VARCHAR(200) NOT NULL, last_name VARCHAR(200) NOT NULL, dob DATE ); INSERT INTO Persons VALUES (1, 'Amy', 'Adams', '1974/08/20'), (2, 'Brigitte', 'Bardot', '1934/09/28'); Теперь предположим, что мы хотим получить имя и фамилию в объединённом виде. Мы можем создать представление:
CREATE VIEW Persons_v AS SELECT id, CONCAT(first_name, ' ', last_name) AS name, dob FROM Persons Посмотрим, что у нас получилось:

Это, конечно, самый обычный способ создания представления. Но мы можем сделать то же самое, создав таблицу и правило SELECT. Таблица будет превращена в представление путём добавления правила:
CREATE TABLE Persons_t ( id INT, name TEXT, dob DATE ); CREATE RULE "_RETURN" AS ON SELECT TO Persons_t DO INSTEAD SELECT id, CONCAT(first_name, ' ', last_name) AS name, dob FROM Persons; Несколько моментов, на которые следует обратить внимание:
- В таблице Persons_t не определён первичный ключ. Если бы он был, мы не смогли бы создать для него правило SELECT.
- Столбец name в Persons_t имеет тип TEXT, потому что это тип, возвращаемый функцией CONCAT.
- Правило называется _RETURN, потому что все правила SELECT должны иметь такое имя.
Вы почти наверняка никогда не будете этого делать; практически нет причин делать это таким образом, кроме как для удовлетворения собственного любопытства. А вот другие виды правил перезаписи намного интереснее.
Правила UPDATE, INSERT, и DELETE
Мы уже узнали, что правила SELECT фактически ограничены тем, что могут делать представления.
Однако для всех остальных правил перезаписи мы получаем гораздо больше свободы, поскольку они предназначены для определения того, как должны обрабатываться обновления, часто (но не только) в представлениях.
Допустим, мы хотим добавить значения в наше представление Persons_v . Если мы попробуем очевидное:
INSERT INTO Persons_v (id, name, dob) VALUES (3, 'Charlie Chaplin', '1889/04/16') Тогда мы получим ошибку:
[Code: 0, SQL State: 0A000] ERROR: cannot insert into column "name" of view "persons_v" Detail: View columns that are not columns of their base relation are not updatable. В этом есть смысл. PostgreSQL никак не может понять, как обращаться со столбцом name , который выводится с помощью формулы.
Вот тут-то и приходит на помощь правило INSERT:
CREATE RULE PersonsInsert AS ON INSERT TO Persons_v DO INSTEAD INSERT INTO Persons (id, first_name, last_name, dob) VALUES (NEW.id, SPLIT_PART(NEW.name, ' ', 1), SPLIT_PART(NEW.name, ' ', 2), NEW.dob) Теперь мы можем добавить значения в представление Persons_v , и значения для столбцов first_name и last_name будут обработаны правильно:
INSERT INTO Persons_v (id, name, dob) VALUES (3, 'Charlie Chaplin', '1889/04/16') Вот что получилось:

Попробуем заморочиться
Важно отметить, что правила могут включать несколько команд (за исключением правил SELECT). Это необходимо, если мы хотим поддерживать представления, охватывающие несколько таблиц.
Давайте создадим ещё одну таблицу:
CREATE TABLE Addresses ( id INT PRIMARY KEY, street varchar(200) NOT NULL, city varchar(100) NOT NULL, person_id int REFERENCES Persons ON DELETE CASCADE, end_date timestamp ); INSERT INTO Addresses (id, street, city, person_id) VALUES (100, '1428 Elm Street', 'Springwood', 1), (101, '742 Evergreen Terrace', 'Springfield', 2), (102, '221B Baker Street', 'London', 3); Столбец end_date сыграет свою роль позже, поэтому пока не обращайте на него внимания.
Теперь мы создадим новое представление, охватывающее обе таблицы:
CREATE VIEW PersonAddress AS SELECT p.id as pid, CONCAT(first_name, ' ', last_name) AS name, a.id as aid, CONCAT(street, ', ', city) as address FROM Persons p LEFT JOIN Addresses a ON a.person_id = p.id WHERE a.end_date IS NULL Посмотрим, что у нас получилось:

Как и в прошлый раз, если мы попытаемся вставить представление PersonAddress , мы получим ошибку, потому что представление содержит два производных столбца.
Но мы можем создать правило, которое будет обрабатывать это правильно:
CREATE RULE PersonAddressInsert AS ON INSERT TO PersonAddress DO INSTEAD ( INSERT INTO Persons (id, first_name, last_name) VALUES (NEW.pid, SPLIT_PART(NEW.name, ' ', 1), SPLIT_PART(NEW.name, ' ', 2)); INSERT INTO Addresses (id, street, city, person_id) VALUES (NEW.aid, SPLIT_PART(NEW.address, ', ', 1), SPLIT_PART(NEW.address, ', ', 2), NEW.pid) ) Затем мы можем вставить данные в обе таблицы одновременно с помощью представления:
INSERT INTO PersonAddress (pid, name, aid, address) VALUES (4, 'Doris Day', 103, '42 Wallaby Way, Sydney') Теперь у нас есть такое:

Двигаемся в сторону триггеров
Мы уже видели, что правила INSERT, UPDATE и DELETE могут содержать несколько утверждений, а это означает, мы можем подойти к делу творчески.
Например, что если мы не хотим обновлять адрес, а вместо этого пометим старый адрес как устаревший с помощью столбца end_date и вставим новый адрес?
Такие вещи обычно обрабатываются триггером, но если мы просматриваем представление для обновления, мы можем обработать это в правиле UPDATE:
CREATE RULE PersonAddressUpdate AS ON UPDATE TO PersonAddress DO INSTEAD ( UPDATE Persons SET first_name=SPLIT_PART(NEW.name, ' ', 1), last_name=SPLIT_PART(NEW.name, ' ', 2) WHERE INSERT INTO Addresses (id, street, city, person_id) VALUES ((SELECT MAX(id) + 1 FROM Addresses), SPLIT_PART(NEW.address, ', ', 1), SPLIT_PART(NEW.address, ', ', 2), NEW.pid); UPDATE Addresses SET end_date = NOW() WHERE > Пуристы SQL могут немного прищуриться, но это будет работать. Теперь, когда мы выполним обновление представления, мы получим новую строку в таблице Addresses , старая строка будет иметь значение в столбце end_date , а имя человека будет обновлено:
UPDATE PersonAddress SET name = 'Doris Kappelhoff', address = '32 Spooner Street, Quahog' WHERE aid=103 
Добавляем в таблицы параметры поведения
Вы, возможно, заметили DO INSTEAD, когда мы определяли правило. Существует также DO ALSO, который позволяет нам добавить поведение к обычному выполнению запроса.
По большому счёту правила не могут быть рекурсивными. Вы не можете иметь правило INSERT для таблицы T, которое включает INSERT для таблицы T — это просто перейдёт в бесконечную рекурсию.
Но можно изменить (скажем) UPDATE в таблице на (скажем) DELETE. Правила существуют не только для представлений.
Например, мы можем захотеть иметь механизм «сбора мусора», с функционалом автоматического удаления любого человека, у которого больше нет адреса. Это можно сделать с помощью правила, определённого для таблицы Addresses :
CREATE RULE AddressDelete AS ON DELETE TO Addresses DO ALSO DELETE FROM Persons WHERE AND (SELECT COUNT(*) from Addresses WHERE person_id = OLD.person_id) = 1 Теперь, если мы удалим последний адрес человека, то автоматически удалим человека, которому принадлежал этот адрес (в данном случае Чарли Чаплина):
DELETE FROM Addresses WHERE >

Можно определить несколько правил одного типа для одной таблицы; в этом случае они будут выполняться в алфавитном порядке.
Параметры разрешений
Поскольку правила могут затрагивать таблицы, не упомянутые в исходном запросе, возникает вопрос: какие разрешения должна использовать база данных при выполнении этих правил?
Так, в нашем последнем примере мы удалили адрес, что предполагает, имеющиеся у нас для этого соответствующие привилегии в таблице Addresses.
Но, возможно, неизвестно для нас, это удаление также удалило человека. Что, если у нас нет прав DELETE на таблицу Persons?
В PostgreSQL все правила принадлежат владельцу таблицы, к которой эти правила привязаны. Когда правило выполняется, разрешения владельца этой таблицы будут применяться при обращении к таблицам, которые не были непосредственно упомянуты в исходном запросе.
Вам может показаться, что такой подход создаёт серьёзную дыру в безопасности, но на самом деле это не так (скорее всего, документация по PostgreSQL заставит вас передумать).
Верный ли это путь для выполнения подобных задач?
Правила перезаписи полезны, даже незаменимы, когда вы хотите работать с представлениями, и вам нужно определить, что происходит с INSERT, UPDATE и DELETE. Надеюсь, что хотя бы из-за этой информации моё руководство было для вас полезным.
Правила перезаписи также могут быть полезны, если вам нужно изменить поведение некоторых таблиц, в пределах разумного.
Но как далеко вы должны идти в направлении правил перезаписи? То, что вы можете что-то сделать, не означает, что вы должны это делать.
Это непростой вопрос. Триггеры могут иметь больше смысла, поскольку их цель часто более ясна, и у них больше возможностей (BEFORE/AFTER/INSTEAD OF, FOR EACH ROW и т. д.).
Но правила перезаписи иногда проще выразить, чем триггеры. В документации PostgreSQL есть обсуждение этой темы для тех, кто хочет в неё погрузиться.
Моя общая рекомендация — использовать правила перезаписи только для того, чтобы делать нетривиальные представления обновляемыми, и использовать триггеры для всех других целей. Правила перезаписи менее знакомы большинству людей, и они совершенно уникальны для PostgreSQL. Имейте в виду, следующий человек, который будет поддерживать то, что вы делаете, может быть не таким опытным, как вы.
Но, опять же, каждая ситуация уникальна и поэтому, в конце концов, вам придётся полагаться только на своё тщательное усмотрение.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS .