Краткое руководство. Подключение и запрос PostgreSQL с помощью Azure Data Studio
В этом кратком руководстве показано, как использовать Azure Data Studio для подключения к PostgreSQL и как с помощью инструкций SQL создать базу данных tutorialdb и выполнять к ней запросы.
Необходимые компоненты
Для работы с этим кратким руководством вам потребуется Azure Data Studio, расширение PostgreSQL для Azure Data Studio, а также доступ к серверу PostgreSQL.
- Установите Azure Data Studio.
- Установите расширение PostgreSQL для Azure Data Studio.
- Установите PostgreSQL. (Кроме того, вы можете создать базу данных Postgres в облаке с помощью команды az postgres up.)
Подключение к PostgreSQL
- Запустите Azure Data Studio.
- При первом запуске Azure Data Studio открывается диалоговое окно Подключение. Если диалоговое окно Подключение не открылось, щелкните значок Создать подключение на странице СЕРВЕРЫ:
- В открывшейся форме перейдите в область Тип подключения и выберите PostgreSQL в раскрывающемся списке.
- Заполните оставшиеся поля, используя имя сервера, имя пользователя и пароль для сервера PostgreSQL.
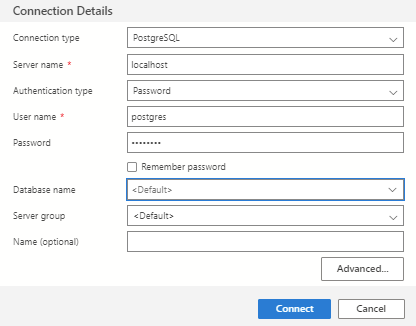
| Параметр | Пример значения | Description |
|---|---|---|
| Имя сервера | localhost | Полное имя сервера |
| Имя пользователя | postgres | Имя пользователя, с которым вы хотите войти. |
| Пароль (имя входа SQL) | пароль | Пароль для учетной записи, в которую выполняется вход. |
| Пароль | Проверка | Установите этот флажок, если не хотите вводить пароль при каждом подключении. |
| Имя базы данных | Заполните этот параметр, если необходимо, чтобы соединение указывало на определенную базу данных. | |
| Группа серверов | Этот параметр позволяет включить создаваемое подключение в определенную группу серверов. | |
| Имя (необязательно) | Не указывайте | Этот параметр позволяет указать понятное имя для сервера. |
После успешного подключения сервер откроется на боковой панели SERVERS (Серверы).
Создание базы данных
Ниже приведены инструкции по созданию базы данных с именем tutorialdb.
- Щелкните сервер PostgreSQL в боковой панели Серверы правой кнопкой мыши и выберите Создать запрос.
- Вставьте эту инструкцию SQL в открывшемся редакторе запросов.
CREATE DATABASE tutorialdb; Для выполнения инструкции вместо элемента Выполнить можно нажать клавишу F5 на клавиатуре.
После завершения запроса щелкните правой кнопкой мыши базы данных и выберите «Обновить«, чтобы просмотреть базу данных tutorialdb в списке в узле «Базы данных«.
Создание таблицы
Следующие шаги создают таблицу в tutorialdb.
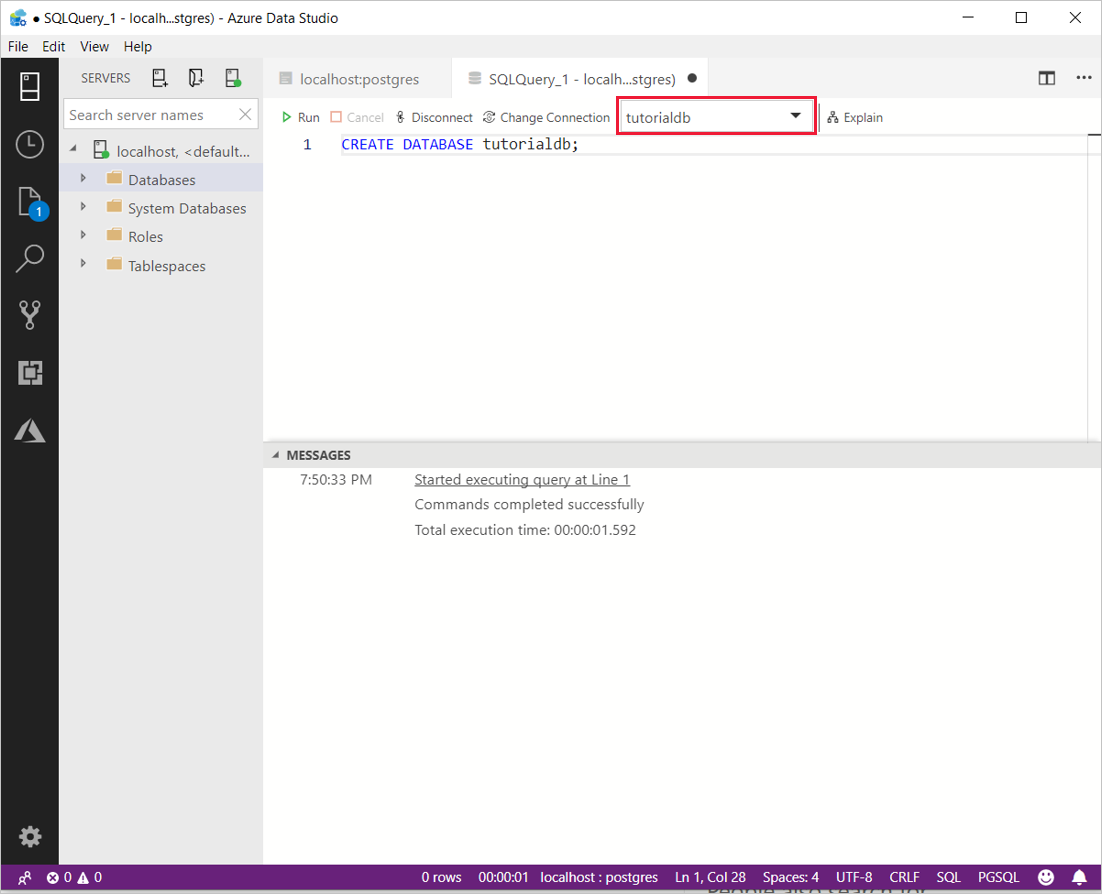
- Измените контекст подключения на tutorialdb с помощью раскрывающегося списка в редакторе запросов.
- Вставьте следующую инструкцию SQL в редактор запросов и выберите «Выполнить«.
Примечание. Ее можно добавить в предыдущий запрос, либо можно перезаписать предыдущий запрос в редакторе. При выборе запуска выполняется только выделенный запрос. Если ничего не выделено, при нажатии кнопки «Выполнить» выполняются все запросы в редакторе.
-- Drop the table if it already exists DROP TABLE IF EXISTS customers; -- Create a new table called 'customers' CREATE TABLE customers( customer_id SERIAL PRIMARY KEY, name VARCHAR (50) NOT NULL, location VARCHAR (50) NOT NULL, email VARCHAR (50) NOT NULL ); Вставка строк
Вставьте следующий фрагмент кода в окно запроса и нажмите кнопку «Выполнить«.
-- Insert rows into table 'customers' INSERT INTO customers (customer_id, name, location, email) VALUES ( 1, 'Orlando', 'Australia', ''), ( 2, 'Keith', 'India', 'keith0@adventure-works.com'), ( 3, 'Donna', 'Germany', 'donna0@adventure-works.com'), ( 4, 'Janet', 'United States','janet1@adventure-works.com'); Запрос данных
- Вставьте в редакторе запросов следующий фрагмент и нажмите кнопку Выполнить.
-- Select rows from table 'customers' SELECT * FROM customers; 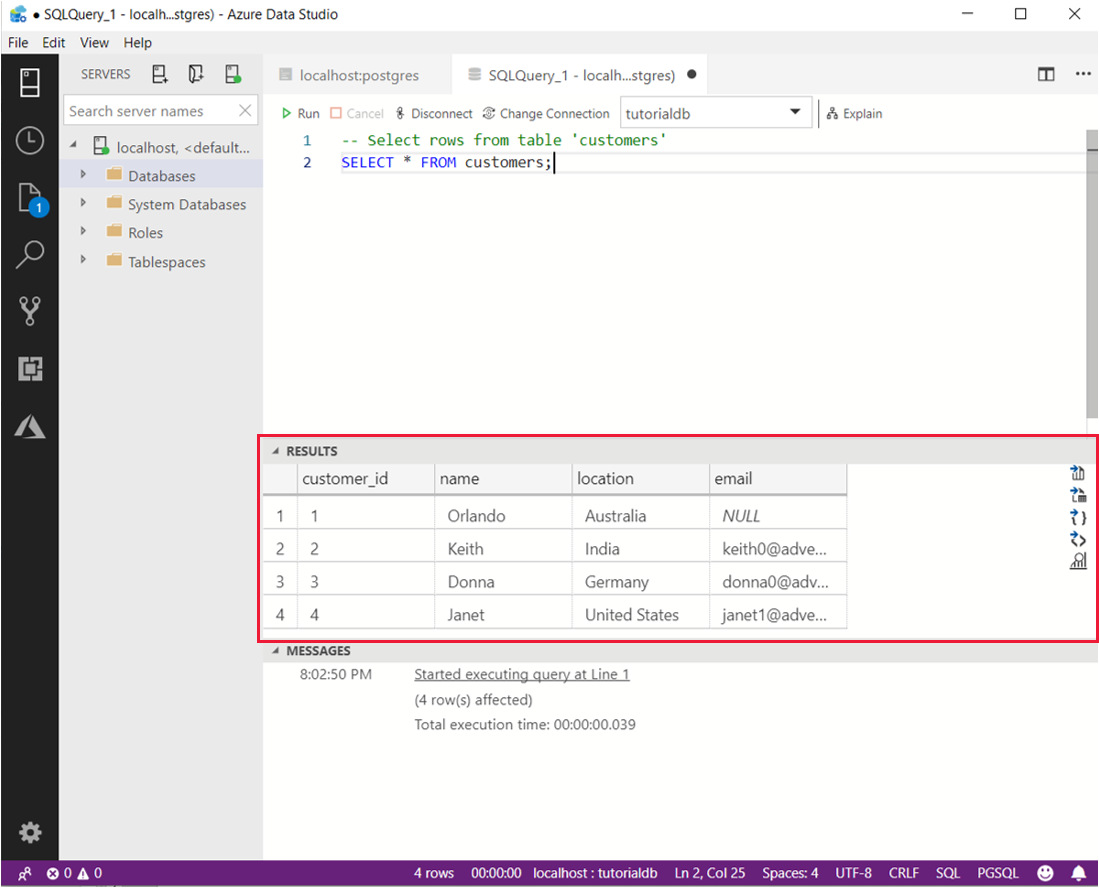
Следующие шаги
- См. сведения о сценариях, доступных для Postgres в Azure Data Studio.
psql — консольная утилита для работы с PostgreSQL¶
Вывод peзультатов запроса не в строку, а столбцом¶
Ключ \x
Покажу на примере, как это выглядит (это очень хорошо работает на запросах со множеством столбцов и «узким» экраном)
denis=# select * from pg_stat_activity; datid | datname | procpid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | xact_start | query_start | waiting | current_query --------+---------+---------+----------+---------+------------------+-------------+-----------------+-------------+-------------------------------+------------------------------+------------------------------+---------+--------------------------------- 629830 | denis | 13205 | 629829 | denis | psql | | | -1 | 2012-11-10 11:57:05.634017+06 | 2012-11-10 11:59:11.27402+06 | 2012-11-10 11:59:11.27402+06 | f | select * from pg_stat_activity; (1 row) -- Включаю альтернативный режим отображения результатов запроса denis=# \x Expanded display is on. denis=# select * from pg_stat_activity; -[ RECORD 1 ]----+-------------------------------- datid | 629830 datname | denis procpid | 20187 usesysid | 629829 usename | denis application_name | psql client_addr | client_hostname | client_port | -1 backend_start | 2012-11-07 23:29:00.264029+06 xact_start | 2012-11-07 23:29:47.653051+06 query_start | 2012-11-07 23:29:47.653051+06 waiting | f current_query | select * from pg_stat_activity;
Выход в шел без прерывания сессии работы с базой данных¶
Ключ \!
denis=# \! denis@server:~$ ls -l total 126172 drwxr-xr-x 2 denis denis 4096 Oct 21 10:28 Desktop drwxr-xr-x 3 denis denis 4096 Nov 5 10:03 Documents drwxr-xr-x 14 denis denis 12288 Nov 7 16:45 Downloads drwx------ 11 denis denis 4096 Nov 7 08:19 Dropbox drwxr-xr-x 19 denis denis 4096 Sep 30 23:03 Music drwxr-xr-x 3 denis denis 4096 Oct 9 12:44 Pictures drwxrwxr-x 11 denis denis 4096 Nov 3 17:27 Projects drwxr-xr-x 2 denis denis 4096 Sep 26 20:03 Public drwxrwxr-x 2 denis denis 4096 Sep 27 10:17 Snapshots drwxr-xr-x 2 denis denis 4096 Sep 26 20:03 Templates denis@server:~$ exit exit denis=# \q denis@server: ~$
Редактирование запросов во внешнем редакторе¶
Многострочные запросы очень неудобно редактировать в стандартной строке psql. Но есть возможность редактировать запросы во внешнем редакторе.
Ключ \e
При вводе ключа \e запускается внешний редактор, в котором уже содержится последний запрос, который был введен в psql. Запрос можно отредактировать или ввести новый, сохранить файл и выйти из редактора. Если в конце запроса стоит точка с запятой, то запрос будет выполнен сразу после закрытия редактора. В противном случае, чтобы запрос выполнился, надо будет ввести точку с запятой уже в psql и нажать ENTER.
За то, какой редактор вызывается, отвечает переменная окружения PSQL_EDITOR, которую можно настроить на vim:
export PSQL_EDITOR="vim"
Прокрутка результата выполнения запроса вперед/назад¶
Довольно часто в дистрибутивах linux в качестве программы для постраничного вывода результатов выполнения запросов используется программа more, которую не всегда удобно использовать для интерактивной работы с результатом запроса (производить поиск, прокручивать результат запрос вверх/вниз, выводить результат запроса с использованием переноса строк).
Выход есть! Можно заменить more на less, которая позволяет интерактивно работать с результатом запроса. Для этого необходимо установить следующие переменные окружения:
export PAGER="less" export LESS="-iMSx4 -FX"
Помимо всего вышеперечисленного опция S отключает перенос длинных строк, что улучшает читабельность результата запроса.
Есть неприятная особенность работы с less, если приходится прокручивать результат запроса вправо/влево — в этом случае, генерируется много пустых экранов, которые занимают много места вверху терминала (опция X). Однако часто эта небольшая неприятность перекрывается остальными преимуществами less
Включить/отключить постраничный вывод результата запроса можно опцией
\pset pager [always|off]
Время выполнения запроса¶
Вывод времени выполнения запрос выключается опцией \timing
denis=# \timing Timing is on. denis=# select 1; ?column? ---------- 1 (1 row) Time: 0.280 ms
Редактирование хранимой процедуры¶
Иногда нужно быстро отредактировать текст хранимой процедуры, но нет возможности воспользоваться привычной программой для этого. psql же практически всегда доступен и отредактировать процедуру можно им.
Для этого служит опция \ef
При использовании этой опции запускается редактор, указанный в переменной окружения PSQL_EDITOR
Сохранения результатов запросов в файл¶
Ключ \copy позволяет импортировать целые таблицы или результаты запросов в файлы и экспортировать данных из файлов в таблицы. Это бывает полезно, если надо переместить данные какой-то таблицы между базами данных.
Есть таблица customers (id int4, first_name varchar(64), last_name varchar(64)). Её нужно перенести в другую базу данных в таблицу temp_customers
Сохраняю содержимое таблицы в файл customers.dump:
db1# \copy customers to 'customers.dump'
Загружаю содержимое файла в другую таблицу:
db2# \copy temp_customers from 'customers.dump'
Важно, чтобы таблицы, которые участвуют в переносе, имели одинаковую структуру
Поиск по прошлым запросам¶
Поиск по запросам под OS linux работает аналогично поиску в BASH’е. Находясь в консоле, надо нажать CTRL+R
Появляется приглашение ввести буквы, по которым будет производиться поиск
denis=# (reverse-i-search)`':
По мере ввода букв уточняется запрос, который вы ищите.
denis=# (reverse-i-search)`dr': drop sequence eobjects_objects_15_id_seq;
Дополнительные горячие клавиши для управления режимом поиска
- ENTER — выполнение найденного запрос
- ESC — переход в режим редактирования найденного запроса
- CTRL+R — циклический перебор sql-запросов, которые соответствуют введенной строке поиска
- CTRL+G — закрытие режима поиска без выполнения запроса
Postgresql как выполнить запрос
Чтобы получить данные из таблицы, нужно выполнить запрос. Для этого предназначен SQL -оператор SELECT . Он состоит из нескольких частей: выборки (в которой перечисляются столбцы, которые должны быть получены), списка таблиц (в нём перечисляются таблицы, из которых будут получены данные) и необязательного условия (определяющего ограничения). Например, чтобы получить все строки таблицы weather , введите:
SELECT * FROM weather;
Здесь * — это краткое обозначение « всех столбцов » . [2] Таким образом, это равносильно записи:
SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
В результате должно получиться:
city | temp_lo | temp_hi | prcp | date ---------------+---------+---------+------+------------ San Francisco | 46 | 50 | 0.25 | 1994-11-27 San Francisco | 43 | 57 | 0 | 1994-11-29 Hayward | 37 | 54 | | 1994-11-29 (3 rows)
В списке выборки вы можете писать не только ссылки на столбцы, но и выражения. Например, вы можете написать:
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
И получить в результате:
city | temp_avg | date ---------------+----------+------------ San Francisco | 48 | 1994-11-27 San Francisco | 50 | 1994-11-29 Hayward | 45 | 1994-11-29 (3 rows)
Обратите внимание, как предложение AS позволяет переименовать выходной столбец. (Само слово AS можно опускать.)
Запрос можно дополнить « условием » , добавив предложение WHERE , ограничивающее множество возвращаемых строк. В предложении WHERE указывается логическое выражение (проверка истинности), которое служит фильтром строк: в результате оказываются только те строки, для которых это выражение истинно. В этом выражении могут присутствовать обычные логические операторы ( AND , OR и NOT ). Например, следующий запрос покажет, какая погода была в Сан-Франциско в дождливые дни:
SELECT * FROM weather WHERE city = 'San Francisco' AND prcp > 0.0;
city | temp_lo | temp_hi | prcp | date ---------------+---------+---------+------+------------ San Francisco | 46 | 50 | 0.25 | 1994-11-27 (1 row)
Вы можете получить результаты запроса в определённом порядке:
SELECT * FROM weather ORDER BY city;
city | temp_lo | temp_hi | prcp | date ---------------+---------+---------+------+------------ Hayward | 37 | 54 | | 1994-11-29 San Francisco | 43 | 57 | 0 | 1994-11-29 San Francisco | 46 | 50 | 0.25 | 1994-11-27
В этом примере порядок сортировки определён не полностью, поэтому вы можете получить строки Сан-Франциско в любом порядке. Но вы всегда получите результат, показанный выше, если напишете:
SELECT * FROM weather ORDER BY city, temp_lo;
Если требуется, вы можете убрать дублирующиеся строки из результата запроса:
SELECT DISTINCT city FROM weather;
city --------------- Hayward San Francisco (2 rows)
И здесь порядок строк также может варьироваться. Чтобы получать неизменные результаты, соедините предложения DISTINCT и ORDER BY : [3]
SELECT DISTINCT city FROM weather ORDER BY city;
[2] Хотя запросы SELECT * часто пишут экспромтом, это считается плохим стилем в производственном коде, так как результат таких запросов будет меняться при добавлении новых столбцов.
[3] В некоторых СУБД, включая старые версии PostgreSQL , реализация предложения DISTINCT автоматически упорядочивает строки, так что ORDER BY добавлять не обязательно. Но стандарт SQL этого не требует и текущая версия PostgreSQL не гарантирует определённого порядка строк после DISTINCT .
| Пред. | Наверх | След. |
| 2.4. Добавление строк в таблицу | Начало | 2.6. Соединения таблиц |
Выполнение запросов в PostgreSQL
Статья будет полезна начинающим разработчикам. Рассматривается внутреннее устройство PostgreSQL. Ниже описана общая картина выполнения запросов в СУБД, а также рассматриваются инструменты профилирования запросов.
Подготовка тестовых данных
Для начала создадим таблицы, к которым будем строить запросы в дальнейшем.
CREATE TABLE Regions ( Id SERIAL PRIMARY KEY, Name CHARACTER VARYING(30) ); CREATE TABLE Cities ( Id Serial Primary KEY, Name CHARACTER VARYING(50), RegionId INTEGER REFERENCES Regions (Id) );Опустим запросы наполнения таблиц данными, будем считать, что в каждой таблице есть по несколько строк записей.
Создадим представление Locations на основе таблиц Regions и Cities:
CREATE OR REPLACE VIEW Locations AS SELECT Cities.Id as CityID, Cities.Name as CityName, Regions.Name AS RegionName FROM Cities LEFT JOIN Regions ON Cities.Id = Regions.Id;Простые SQL-запросы
Теперь рассмотрим работу PostgreSQL на примере простого запроса к представлению Locations:
SELECT CityID, CityName, RegionName FROM Locations WHERE CityID = 1;Общая схема выполнения запроса выглядит так:

Выполнение запроса можно разделить на следующие этапы:
- Установка подключения к серверу СУБД
- Трансформация SQL-запроса
- Планирование запроса
- Исполнение запроса
- Завершение соединения
Установка подключения к серверу СУБД
В PostgreSQL реализуется модель «клиент-сервер». Для взаимодействия клиент отправляет запрос на сервер. На сервере СУБД главный процесс (postmaster) запускает отдельный серверный процесс для нашего клиентского подключения. Далее SQL-запрос передаётся на сервер в виде сообщения в текстовом виде по специальному протоколу PostgreSQL.
Разбор SQL-запроса
На сервере PostgreSQL входящий запрос подвергается лексическому, синтаксическому и семантическому анализу:
- Лексический анализ. Сначала лексический анализатор разбивает текст запроса на ключевые слова (SELECT, FROM, WHERE и т.д.), строковые и числовые литералы и другие идентификаторы. Для каждого найденного ключевого слова или идентификатора будет сгенерирован символ языка, который затем передаётся синтаксическому анализатору.
- Синтаксический анализ. Синтаксический анализатор проверяет полученный набор лексем на соответствие грамматике языка, после чего он строит дерево из лексем запроса.
- Семантический анализ. Семантический анализатор обращается к системным каталогам и дополняет дерево запроса ссылками на конкретные объекты базы данных, с указанием типов данных и другой информацией.
Схематично дерево запроса для нашего примера можно изобразить в следующем виде:

Примечание
Посмотреть подробное дерево запроса после этапа разбора можно в логфайлах сервера, заранее включив необходимые настройки. Включить можно двумя способами:
1. В файле конфигурации postgresql.conf включить параметр debug_print_parse (on).
2. Включить debug_print_rewritten из текущего подключения, использовав команду:
set debug_print_parse to on;
Лог-файл для нашего примера доступен по ссылке: postgresql.log
Трансформация SQL-запроса
На этапе трансформации происходит преобразование имён представлений в узлах дерева запроса в новые поддеревья, которые соответствуют этим представлениям. Для этого применяется система правил, которая ищет в системных каталогах подходящие правила и выполняет преобразование дерева запросов. Трансформация необходима для предоставления планировщику полной информации о таблицах и их связях между собой для построения оптимального плана выполнения запроса.
Дополненное дерево запроса для нашего примера после трансформации будет иметь следующий вид:
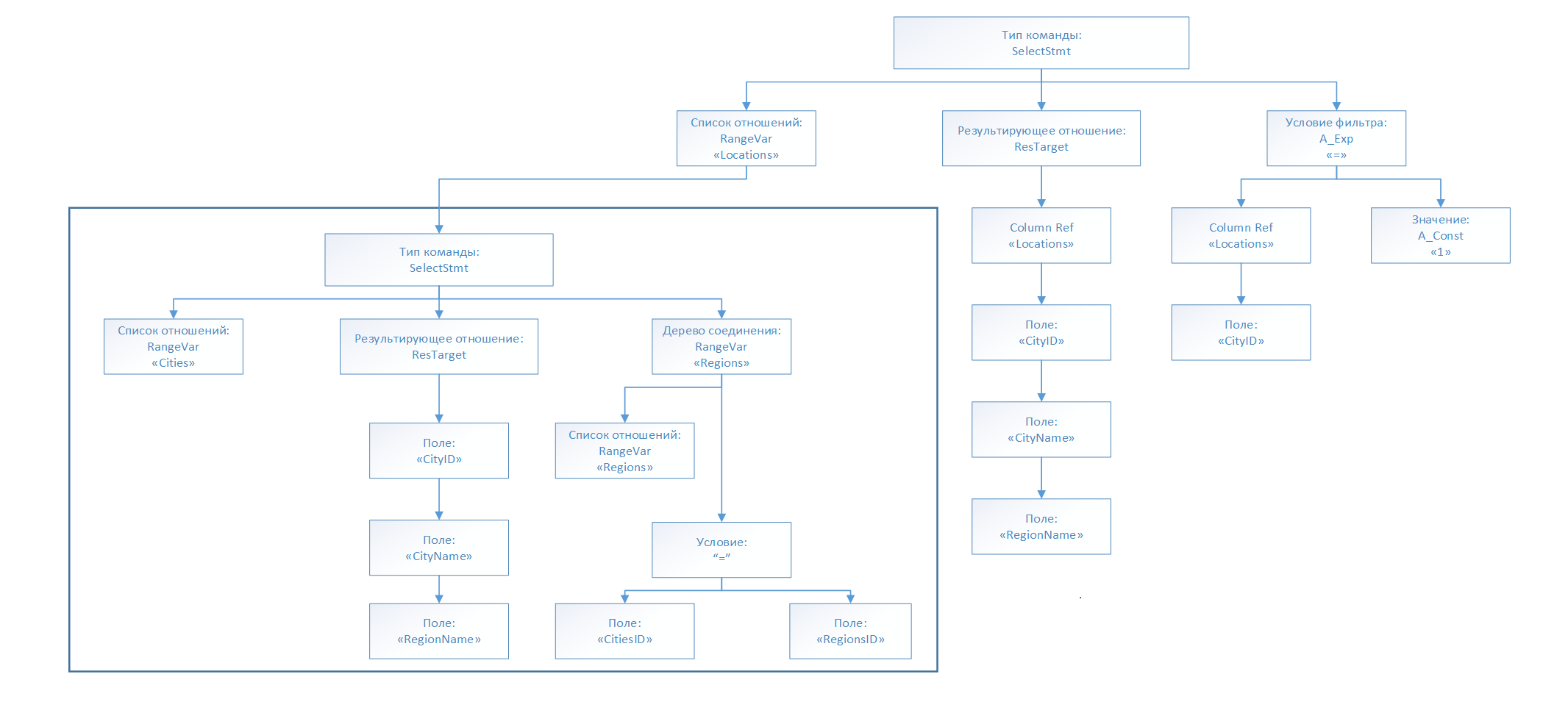
Примечание
Посмотреть преобразованное дерево запроса можно в логфайлах сервера, заранее включив необходимые настройки. Включить можно двумя способами:
1. В файле конфигурации postgresql.conf включить параметр debug_print_rewritten (on).
2. Включить debug_print_rewritten из текущего подключения, использовав команду:
set debug_print_rewritten to on;
Лог-файл для нашего примера доступен по ссылке: postgresql.log
Планирование запроса
На данном этапе выполняется поиск наиболее оптимального способа выполнения нашего запроса. Для этого планировщик осуществляет перебор возможных планов выполнения, оценивает затраты на исполнение и присваивает каждому определённую стоимость. Оценка затрат основывается на математической модели с использованием статистики об обрабатываемых данных, которая накапливается в процессе анализа и при выполнении некоторых DDL-операций, а также уточняется при очистке.
В первую очередь планировщик вырабатывает планы сканирования для таблиц с учётом наличия у них индексов, для которых могут создаваться отдельные планы. Далее происходит выработка планов соединения таблиц, при этом планировщик рассматривает все возможные способы соединения и выбирает самый выгодный. Существует три основных стратегии соединения: соединение с вложенным циклом, соединение слиянием и соединение по хэшу. В конечном итоге планировщик формирует дерево плана, состоящее из отдельных операций. Ниже приведены основные из них:
- Seq Scan – последовательное сканирование;
- Index Scan – индексное сканирование;
- Bitmap Index Scan – сканирование с построением битовых карт;
- Merge Join – соединение слиянием;
- Nested Loop – соединение с вложенным циклом;
- Hash Join – соединение по хэшу;
- Sort – операция сортировки по столбцам;
- Aggregate – вычисление агрегатных функций;
- GroupAggregate – группировка отсортированного набора;
- Unique – удаление повторяющихся данных;
- Limit – прекращение операции, после выбора нужного количества строк.
Для просмотра выбранного плана можно использовать команду EXPLAIN . В её выводе для каждого узла дерева плана отводится строка с описанием базового типа узла, оценки стоимости выполнения (cost), ожидаемое число строк ( rows ), ожидаемый средний размер строк ( width ). Команду EXPLAIN можно использовать с параметром ANALYSE , которая выполнит запрос и выведет фактический план, дополненный информацией о времени планирования и исполнения. Команду можно использовать для оценки фактического времени выполнения запроса, однако не стоит забывать, что использование параметра ANALYSE требует реального выполнения запроса в БД. Команда EXPLAIN ( ANALYZE , BUFFERS ) позволяет проанализировать операции ввода-вывода данных, для каждого узла в итоговом плане будет выведена строчка buffers , содержащая информацию об объёме прочитанных данных:
- Shared hit. Данные были считаны из буфера в оперативной памяти.
- Read. Данные были считаны с диска.
- Dirtied. Объём «грязных» данных, найденных в процессе выполнения.
Визуализацию планов можно посмотреть в pgAdmin или с использованием сторонних сервисов. Примеры таких сервисов: https://explain.tensor.ru/ и https://explain.dalibo.com/ .
В нашем случае планировщик построил следующий план выполнения:

Nested Loop (cost=0.30..16.35 rows=1 width=72) -> Index Scan using cities_pkey on cities (cost=0.15..8.17 rows=1 width=40) Index Cond: (id = 1) -> Index Scan using regions_pkey on regions (cost=0.15..8.17 rows=1 width=8) Index Cond: (id = cities.regionid)Сначала PostgreSQL выполнит обходы по индексам таблиц, чтобы найти удовлетворяющие условию записи, далее СУБД выполнит их соединения с помощью метода соединения вложенными циклами. Можно заметить, что в итоговый план запроса не попало никакой информации о представлении Locations , к которому мы создали запрос на выборку данных.
Для сравнения можно посмотреть на план запроса на получение всех записей из представления Locations :
SELECT Id, CityName, RegionName FROM Locations;Планировщик построил следующий план выполнения:
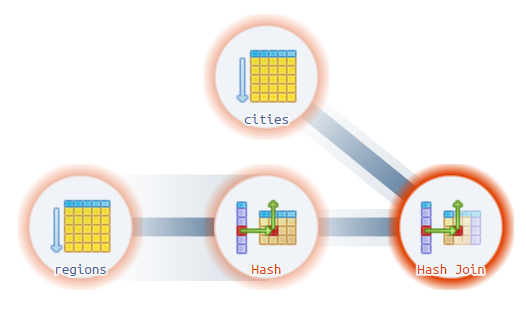
Hash Join (cost=37.00..62.16 rows=1200 width=72) Hash Cond: (cities.regionid = regions.id) -> Seq Scan on cities (cost=0.00..22.00 rows=1200 width=40) -> Hash (cost=22.00..22.00 rows=1200 width=8) -> Seq Scan on regions (cost=0.00..22.00 rows=1200 width=8) Для получения итогового набора СУБД последовательно просканирует таблицу Regions , в узле Hash полученные записи поместятся в хэш-таблицу в оперативной памяти, далее выполнится сканирование записей таблицы cities , которые будут сопоставляться с хэш таблицей при соединении данных в узле Hash Join .
Для нашего запроса фактический план будет выглядеть следующим образом:
Nested Loop (cost=0.30..16.35 rows=1 width=32) (actual time=0.320..0.322 rows=1 loops=1) Buffers: shared hit=2 read=2 -> Index Scan using cities_pkey on cities (cost=0.15..8.17 rows=1 width=36) (actual time=0.107..0.108 rows=1 loops=1) Index Cond: (id = 1) Buffers: shared hit=1 read=1 -> Index Only Scan using regions_pkey on regions (cost=0.15..8.17 rows=1 width=4) (actual time=0.205..0.205 rows=1 loops=1) Index Cond: (id = cities.regionid) Heap Fetches: 1 Buffers: shared hit=1 read=1 Planning Time: 0.196 ms Execution Time: 0.376 ms Исполнение запроса
Исполнение плана выполнения начинается с создания в памяти обслуживающего процесса объекта, который хранит в себе состояние выполняющего запроса в виде дерева, повторяющего структуру плана. Такой объект называется порталом, а его работа происходит по принципу конвейера. Выполнение запроса происходит рекурсивно, каждый корневой узел дерева обращается к дочерним узлам для получения входных данных, далее он производит необходимые преобразования и расчёты, назначенные ему планировщиком, и передаёт их вверх по дереву.
В конце концов исполнитель формирует результирующий набор строк, который возвращается клиенту в виде серии сообщений. Например, для простых запросов на выборку данных PostgreSQL отправляет сообщение RowDescription, описывающее структуру столбцов. Далее СУБД для каждой строки результирующего набора формирует сообщений DataRow и отправляет их последовательно клиенту. Завершается передача результатов выборки сообщением CommandComplete. По готовности безопасно принимать новые команды, PostgreSQL отправляет клиенту сообщение ReadyForQuery.
Завершение соединения
Для завершения работ по текущему клиентскому подключению, клиент отправляет серверу сообщение Terminate и закрывает соединение. Со своей стороны, СУБД также закрывает подключение и завершает обслуживающий процесс.
- Обзор внутреннего устройства PostgreSQL.
- Книга «PostgreSQL изнутри».
- Описание операций плана.
- Использование EXPLAIN.
- Документация по EXPLAIN.
- Сервис для построения диаграмм планов выполнения выполнения PostgreSQL.
- Описание операций плана выполнения запроса.