skip connections и симметрия
Некоторое время назад в ходе определенных рассуждений, явно не связанных с архитектурами искусственных нейронных сетей, у меня возникла, скажем так, гипотеза, которая могла бы объяснить, почему в свое время skip connections смогли произвести своего рода революцию в развитии глубокого обучения и позволили строить действительно глубокие нейронные сети. С тех пор много воды утекло, но все современные SOTA архитектуры являются в той или иной степени продолжением развития ResNet архитектур. Чего там говорить, даже в трансформерах есть skip connections. К сожалению, времени и сил на полноценное исследование нет и вряд ли найдется, а между тем идея кажется как минимум интересной с академической точки зрения, так и могущей возыметь практический выхлоп, а потому я бы хотел поделиться ею, по крайней мере, с аудиторией хабра. Буду краток.
Для решения какой проблемы были введены skip connection в residual архитектурах?
Это один из вопросов, который можно услышать на собеседованиях на позицию ML-инженеров. По крайней мере, именно в такой формулировке мы в нашей компании задаем его соискателям на предварительном скрининг-собеседовании, и, согласно их отзывам, это один из весьма популярных и часто встречаемых вопросов. При этом абсолютное большинство соискателей отвечают на него… неправильно. Лишь немногим отличаясь, ответы в большинстве своем звучат примерно следующим образом: «для решения проблемы затухающего градиента». И это действительно неправильный ответ: заглянув в оригинальную статью, мы увидим, буквально на первой же странице во введении, следующие строки:
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
Неказистый перевод
Из важности глубины возникает вопрос: так ли просто обучать более совершенные сети, как составлять большее количество слоев? Препятствием к ответу на этот вопрос стала пресловутая проблема исчезающих/взрывающихся градиентов [1, 9], которая препятствуют сходимости с самого начала. Эта проблема, однако, была в значительной степени решена с помощью нормализованной инициализации [23, 9, 37, 13] и промежуточных нормализационных слоев [16], которые позволяют сетям с десятками слоев начать сходиться в рамках стохастического градиентного спуска (SGD) с обратным распространением [22].
И ведь действительно, если вдуматься, наличие слоев нормализации должно позволять градиенту течь по сети без затухания. И хоть skip connections (a.k.a. shortcut connections) в принципе изначально были предложены еще до появления ResNet архитектуры, в том числе для решения проблемы затухающего градиента (что, возможно, и служит причиной столь широко распространенного заблуждения), в ResNet архитектурах они в действительности помогли решить другую проблему — проблему деградации точности (о чем в статье говориться буквально в следующем абзаце). Проблема деградации точности заключается в том, что при увеличении глубины сети точность сначала возрастает, потом, вопреки ожиданиям, выходит на плато, а после даже начинает снижаться вплоть до полной потери способности сети к обучению. Существует довольно популярное мнение (вероятно, среди тех, кто читал/помнит оригинальную статью и знает, что затухание градиента тут ни при чем), что: skip connection в residual архитектурах помогают модели выучить тождественное преобразование — таким образом, имея возможность пропускать сигнал без трансформаций, модель должна, по крайней мере, быть не хуже, чем ее менее глубокая версия, следовательно, деградировать точность не может. Подобное объяснение действительно имеет место быть, но оно носит, так сказать, симптоматический характер. А что, если копнуть глубже и попытаться разобраться, в чем вообще причина такого явления, как деградация точности глубокой нейронной сети при увеличении ее глубины? Разумеется, можно начать рассуждать про увеличение размерности параметрического пространства, про ухудшение сходимости, про застревание в локальных минимумах в процессе оптимизации и так далее, однако добавление skip connections не снижает размерность параметрического пространства. Стало быть, сама по себе высокая размерность не является причиной деградации точности. А что же тогда.
Симметрия в нейронных сетях
Причиной (многих) проблем глубокого обучения и подсказкой к поиску путей их решения может являться симметрия параметрического пространства. Именно параметрического, а не признакового, т.е. речь не идет о симметрии входных образов, как то симметрии отражения или поворотов, которыми могут обладать, например, некоторые классы изображений. Нет, речь в данном случае идет об инвариантности результата работы сети по отношению к некоторым операциям, действующим в пространстве параметров нейронной сети:
где — некоторое линейное преобразование в пространстве параметров .

Для простоты рассуждений возьмем полносвязную сеть с одним скрытым слоем (рис. 1). Рассмотрим, для начала, случай, когда все веса выходного линейного слоя фиксированы и равны , т.е. последний слой выполняет роль простого арифметического усреднения выходов нейронов скрытого слоя. Параметры же скрытого слоя удобно представить в виде прямоугольной матрицы размера , где — размерность входного слоя, — размерность скрытого слоя (для простоты, но не нарушая общности рассуждений, забудем про смещение, a.k.a. bias). Таким образом, результат работы сети можно представить в виде:
Что произойдет с результатом работы сети, если мы поменяем местами, скажем, первый и второй нейроны скрытого слоя? Очевидно, что при такой перестановке результат работы сети не изменится. При этом такая операция меняет местами первую и вторую строки матрицы весов скрытого слоя. Т.е. до и после перестановки мы имеем две, вообще говоря, разные матрицы весов, дающие один и тот же результат на выходе сети. Более того, переставить местами мы можем любые два нейрона (любые две строки матрицы ) — результат работы сети инвариантен к любым таким перестановкам, а всего вариантов перестановок Таким образом, как минимум наборов весов (точек в параметрическом пространстве) являются эквивалентными в смысле результата работы сети, независимо ни от входных данных, ни от функций активации и т.д. Это утверждение справедливо не только в рассмотренном нами случае, но и в общем случае, с той лишь разницей, что перестановка i-ого и j-ого нейронов l-го слоя представляет собой перестановку i-й и j-й строки матрицы вместе с перестановкой i-го и j-го столбцов матрицы -го слоя. Из этих рассуждений мы можем заключить, что один полносвязный слой задает в пространстве параметров степень симметрии, по крайней мере, не ниже, чем , а степень симметрии параметрического пространства всей сети равна произведению степеней симметрии каждого слоя, т.е. , поскольку перестановки нейронов в двух слоях выполняются независимо друг от друга. Таким образом, мы определили возможный вид преобразования из выражения 1 — перестановочная матрица. Сразу отмечу, что перестановка — не единственная возможная операция симметрии в пространстве параметров, и в зависимости от используемой нелинейности результат работы сети может оказаться инвариантен и к некоторым другим преобразованиям, специфичным для этой нелинейности (особенно широкий простор для симметрий, в т.ч. непрерывных, обеспечивает ReLU).
Проблемы сходимости, связанные с высокой степенью симметрии признакового пространства, могут возникать на гиперповерхностях симметрии — многообразиях в параметрическом пространстве, точки которых инвариантны к соответствующим операциям симметрии. Например, если две строки в матрице весов равны друг другу, то их перестановка местами не приводит к изменению не только результата, но и самого вектора параметров — такая точка в параметрическом пространстве лежит на одной из плоскостей симметрии. Для наглядности рассмотрим наиболее простой возможный пример (пусть и нарочито игрушечный):

Поскольку здесь всего два варьируемых параметра, мы можем изобразить ландшафт функции потерь на плоскости с использованием любого удобного представления, скажем, contour plot (рис. 3).

Как мы видим, функция потерь, имеющая два эквивалентных минимума, симметрична относительно прямой , или, правильнее в угоду общности будет сказать, относительно 1d-гиперплоскости, задаваемой вектором нормали (1, -1). Собственно, это и есть пример гиперповерхности симметрии, упомянутой ранее. Любая точка, принадлежащая этой прямой, является инвариантной относительно операции симметрии, благодаря которой функция потерь имеет два минимума. Так вот, важно здесь то, что на этой самой поверхности, в общем случае, вдоль ортогональных плоскости направлений функция потерь имеет локальный экстремум, который может быть как максимум, так и минимумом. Назовем такой минимум ложным, поскольку в общем случае он не является оптимальной точкой решения задачи оптимизации, а обусловлен свойствами параметрического пространства модели.
Картина усложняется, когда мы имеем множество пересекающихся гиперповерхностей в результате стекинга нескольких слоев — ландшафт функции потерь может усложняться чрезвычайно сильно — вероятность возникновения ложных минимумов повышается с увеличением степени симметрии параметрического пространства, которая, в свою очередь, растет катастрофически с увеличением глубины и ширины сети. Больше локальных минимумов — больше вероятность застрять в этих минимумах в процессе оптимизации. Собственно, основная гипотеза, выдвигаемая на основании всех этих рассуждений, состоит в том, что проблема деградации точности связана с ростом числа локальных минимумов при увеличении глубины сети, обусловленным ростом степени симметрии параметрического пространства.
И тут на помощь приходят skip connections
Так чем же тогда помогают skip connections? Тут все достаточно просто и Вы, возможно, уже догадались сами: skip connections существенно снижают симметрию параметрического пространства, уменьшая, тем самым, число локальных минимумов и облегчая сходимость. Если это утверждение не кажется столь очевидным, достаточно рассмотреть уже знакомый нам пример полносвязной сети, чтобы его понять. Добавим в сеть, изображенную на рисунке 1, skip connections между входом и выходом первого слоя (правда, для этого нам потребуется сделать размерность выхода равной размерности входа, но сути это не меняет).

Поскольку перестановка местами двух нейронов в слое не зависит от его входа, то в этот раз мы уже не можем переставлять местами нейроны в скрытом слое, не меняя выход сети, поскольку он зависит уже не только от весов скрытого слоя, но и входного значения, с которым суммируется активация. Т.е., добавив skip connection, причем, именно аддитивный (подойдет также, например, мультипликативный, но не конкатенативный), мы снизили степень перестановочной симметрии слоя с до 1! Таким образом, добавление skip connections по всей глубине сети позволяет значительно снизить степень симметрии параметрического пространства, а, значит, и число локальных минимумов функции потерь, делая ее ландшафт более «хорошим» для оптимизации.
После проведенных рассуждений не грех задаться вопросом: если skip connections действительно помогает решить проблему деградации точности за счет снижения симметрии параметрического пространства, то что еще может обладать подобным свойством? Рискну предположить, что к приемам, которые исторически помогли решить ту или иную проблему при дизайне новых нейросетевых архитектур, действительно можно отнести несколько, в частности: групповую (в пределе — поканальную) свертку (group and depth-wise convolutions), позиционное кодирование (positional encoding), dropout. Первые два приема, в ретроспективном рассмотрении, обладают тем свойством, что помогают в целом снизить степень симметрии параметрического пространства как и skip connections. Так, например, depth-wise convolution, используемая для факторизации операции свертки, с одной стороны, разумеется, позволяет снизить размерность параметрического пространства (что оказывается важным для инференса на устройствах), но также и снижает степень симметрии, поскольку каждый канал теперь обрабатывается своим фильтром, и, следовательно, результат работы сети уже не инвариантен к перестановкам ядер.
Что касается регуляризации dropout, то ее можно связать с симметрией следующим образом: отключение случайного подмножества нейронов на каждом шаге обучения локально (на данном шаге) нарушает симметрию признакового пространства, т.е. у оптимизатора появляется шанс пройти мимо ложного минимума, обеспеченного симметрией ландшафта функции потерь на гиперповерхностях симметрии или их пересечении.
Что-нибудь еще? Возможно… Предлагаю заинтересовавшимся подумать над этим вместе.
Послесловие
Получилось, на мой взгляд, достаточно кратко. Возможно, изложенная идея кому-то покажется простой, очевидной или незначительной, другого может натолкнет на какие-то интересные мысли. В любом случае, приглашаю к обсуждению.
Трансформер
Трансформер (англ. transformer) — архитектура глубоких нейронных сетей, основанная на механизме внимания без использования рекуррентных нейронных сетей (сокр. RNN). Самое большое преимущество трансформеров по сравнению с RNN заключается в их высокой эффективности в условиях параллелизации. Впервые модель трансформера была предложена в статье Attention is All You Need [1] от разработчиков Google в 2017 году.
Архитектура трансформера
![]()
Архитектура трансформера [2]
Устройство трансформера состоит из кодирующего и декодирующего компонентов. На вход принимается некая последовательность, создается ее векторное представление (англ. embedding), прибавляется вектор позиционного кодирования, после чего набор элементов без учета порядка в последовательности поступает в кодирующий компонент (параллельная обработка), а затем декодирующий компонент получает на вход часть этой последовательности и выход кодирующего. В результате получается новая выходная последовательность.
Внутри кодирующего и декодирующего компонента нет рекуррентности. Кодирующий компонент состоит из кодировщиков, которые повторяются несколько раз, аналогично устроен декодирующий компонент. Трансформер — это поставленные друг за другом модели внимания, которые позволяют исходную последовательность векторов перевести в новую последовательность векторов, которые кодируют информацию о контексте каждого элемента. Трансформер-кодировщик переводит исходные векторы в скрытые, которые правильно сохраняют в себе информацию о контексте каждого элемента. Далее трансформер-декодировщик декодирует результат кодировщика в новую последовательность, которая состоит из эмбедингов элементов выходного языка. После по эмбедингам генерируются сами итоговые элементы с помощью вероятностной языковой модели.
Ниже рассмотрим архитектуру кодировщика и декодировщика подробнее.
Архитектура трансформера-кодировщика
![]()
Архитектура трансформера-кодировщика [3]
Рассмотрим последовательно шаг за шагом этапы работы кодировщика:
1. На вход поступает последовательность элементов [math]w_i[/math] , по ней создается последовательность эмбедингов, где каждый [math]x_i[/math] это векторное представление элемента [math]w_i[/math] .
2. Добавляются позиционные векторы [math]p_i[/math] : [math]h_i = x_i + p_i[/math] , [math]H = (h_1. h_n)[/math] . Это необходимо для того, чтобы отобразить информацию о позиции элемента в исходной последовательности. Основное свойство позиционного кодирования — чем дальше два вектора будут стоять друг от друга в последовательности, тем больше между ними будет расстояние. Более подробное устройство позиционного кодирования будет рассмотрено ниже.
3. Полученный вектор [math]h_i[/math] подается на вход в блок многомерного самовнимания (англ. multi-headed self-attention). [math]h^j_i = \mathrm(Q^j h_i, K^j H, V^j H)[/math] , где обучаемые матрицы: [math]Q[/math] для запроса, [math]K[/math] для ключа, [math]V[/math] для значения. Подробное объяснения работы механизма self-attention будет разобрано ниже.
4. Затем необходима конкатенация, чтобы вернуться в исходную размерность: [math] h’_i = M H_j (h^j_i) = [h^1_i. h^J_i] [/math]
5. Добавим сквозные связи (англ. skip connection) — по факту просто добавление из входного вектора к выходному ( [math]h’_i + h_i[/math] ). После делаем нормализацию слоя (англ. layer normalization): [math]h»_i = \mathrm(h’_i + h_i; \mu_1, \sigma_1)[/math] . У нее два обучаемых параметра, для каждой размерности вектора вычисляется среднее и дисперсия.
6. Теперь добавим преобразование, которое будет обучаемым — полносвязную двухслойную нейронную сеть: [math] h»’_i = W_2 \mathrm (W_1 h»_i + b_1) + b_2 [/math]
7. Повторим пункт 5 еще раз: добавим сквозную связь и нормализацию слоя: [math]z_i = \mathrm(h»’_i + h»_i; \mu_2, \sigma_2)[/math]
После, в кодирующем компоненте пункты кодировщика 3—7 повторяются еще несколько раз, преобразовывая друг за другом из контекста контекст. Тем самым мы обогащаем модель и увеличиваем в ней количество параметров.
Позиционное кодирование
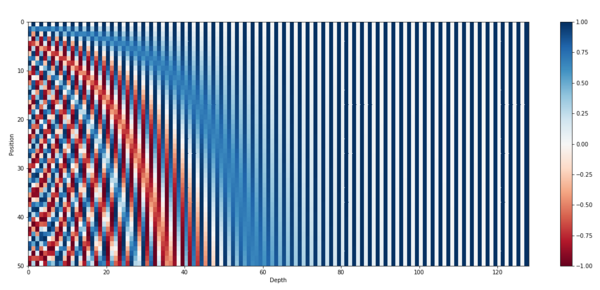
Визуализация работы позиционного кодирования [4]
Так как в архитектуре трансформер обработка последовательности заменяется на обработку множества мы теряем информацию о порядке элементов последовательности. Чтобы отобразить информацию о позиции элемента в исходной последовательности мы используем позиционное кодирование.
Позиционное кодирование (англ. positional encoding) — позволяет модели получить информацию о порядке элементов в последовательности путем прибавления специальных меток к вектору входных элементов. Позиции элементов [math]i[/math] кодируются векторами [math]p_i[/math] , [math]i = 1, 2, . n[/math] , так, что чем больше [math]|i — j|[/math] , тем больше [math]||p_i — p_j||[/math] , и [math]n[/math] не ограничено. Пример такого кодирования:
[math] p_ <(i, s)>= \begin \sin \left(i \cdot 10000^>>\right) & \quad \text s=2k\\ \cos \left(i \cdot 10000^>>\right) & \quad \text s=2k+1 \end [/math]
Self-attention
Self-Attention — разновидность механизма внимания, задачей которой является выявление закономерности между входными данными.
Будем для каждого элемента [math]x_i[/math] получать обучаемым преобразованием три вектора:
- Запрос (query) [math]q_i = Q x_i[/math]
- Ключ (key) [math]k_i = K x_i[/math]
- Значение (value) [math]v_i = V x_i[/math]
Векторы [math]q_i[/math] и [math]k_i[/math] будем использовать, чтобы посчитать важность элемента [math]x_j[/math] для элемента [math]x_i[/math] . Чтобы понять, насколько для пересчета вектора элемента [math]x_i[/math] важен элемент [math]x_j[/math] мы берем [math]k_j[/math] (вектор ключа элемента [math]x_j[/math] ) и умножаем на [math]q_i[/math] (вектор запроса элемента [math]x_i[/math] ). Так мы скалярно перемножаем вектор запроса на все векторы ключей, тем самым понимаем, насколько каждый входной элемент нам нужен, чтобы пересчитать вектор элемента [math]x_i[/math] .
Далее считаем важность элемента [math]x_j[/math] для кодирования элемента [math]x_i[/math] : [math]w_=\frac< \exp \left(\frac<\langle q_i, k_j \rangle>> \right) >< \sum_^n \exp \left(\frac<\langle q_i, k_p \rangle>> \right) >[/math] , где [math]d[/math] — размерность векторов [math]q_i[/math] и [math]k_j[/math] , а [math]n[/math] — число элементов во входной последовательности.
Таким образом, новое представление элемента [math]x_i[/math] считаем как взвешенную сумму векторов значения: [math]z_i = \mathrm(Q x_i, K X, V X) = \sum_^n w_
v_p[/math] , где [math]X = (x_1, x_2, . x_n)[/math] — входные векторы. По факту self-attention — это soft-arg-max с температурой [math]\sqrt[/math] . Мы перемешиваем все входные векторы, чтобы получить новые векторы всех элементов, где каждый элемент зависит от всех входных элементов.
Multi-headed self-attention
Multi-headed self-attention — улучшенная модификация self-attention.
Слой внимания снабжается множеством «подпространств представлений» (англ. representation subspaces). Теперь у нас есть не один, а множество наборов матриц запроса/ключа/значения. Каждый из этих наборов создается случайным образом. Далее после обучения каждый набор используется для отображения входящих векторов в разных подпространствах представлений. Также появляется способность модели фокусироваться на разных аспектах входной информации.
То есть параллельно независимо несколько раз делаем attention. Потом результат каждого attention по элементам конкатенируем, затем сжимаем получившуюся матрицу и получаем для каждого элемента свой вектор той же размерности.
[math]с^j = \mathrm(Q^j q, K^j X, V^j X)[/math] , где [math]j = 1. J[/math] , [math]J[/math] — число разных моделей внимания, [math]X = (x_1, x_2, . x_n)[/math] — входные векторы, а [math]W[/math] — обучаемые матрицы.
Архитектура трансформера-декодировщика
![]()
Архитектура трансформера-декодировщика [5]
На вход декодировщику подается выход кодировщика. Главное отличие архитектуры декодировщика заключается в том, что дополнительно имеется attention к вектору, который получен из последнего блока кодирующего компонента. Компонент декодировщика тоже многослойный и каждому блоку компонента на вход подается вектор именно с последнего блока кодирующего компонента. Разберем по порядку этапы работы декодировщика:
1. Для того, чтобы распараллелить декодировщик и уйти от рекуррентности, но тем не менее генерировать элементы друг за другом, используется прием маскирования данных из будущего. Идея в том, что мы запрещаем себе подглядывать в те элементы, которые еще не сгенерированы с учетом порядка. Когда генерируем элемент под номером [math]t[/math] , имеем право смотреть только первые [math]t-1[/math] элементов: [math]h_t = y_ + p_t[/math] ; [math]H_t=(h_1, . h_t)[/math]
2. Далее идет этап многомерного самовнимания: линейная нормализация и multi-headed self-attention. Особенность в том, что в attention ключи и значения применяются не ко всем векторам, а только к тем, значения которых уже синтезировали ( [math]H_t[/math] ): [math] h’_t = \mathrm \circ M H_j \circ \mathrm(Q^j h_t, K^j H_t, V^j H_t) [/math] , где [math]\circ[/math] — композиция.
3. На следующем этапе мы делаем многомерное внимание на кодировку [math]Z[/math] , результат работы компонента кодировщика: [math] h»_t = \mathrm \circ M H_j \circ \mathrm(Q^j h_t, K^j Z, V^j Z) [/math]
4. Линейная полносвязная сеть (по аналогии с кодировщиком): [math] y_t = \mathrm \circ FNN(h»_t) [/math]
5. В самом конце мы хотим получить вероятностную порождающую модель для элементов. Результат (индекс слова с наибольшей вероятностью): [math]\mathrm(W_y y_t + b_y) [/math] , где [math] W_y [/math] , [math] b_y [/math] — обучаемые параметры линейного преобразования. Для каждой позиции [math]t[/math] выходной последовательности мы строим вероятностную модель языка, то есть все элементы из выходного словаря получают значение вероятности. Эти значения как раз получаются из векторов [math]y_t[/math] из предыдущего пункта, которые мы берем с последнего блока трансформера-декодировщика.
Последний этап выполняется только после того, когда повторились пункты 1—4 для всех декодировщиков. На выходе получаем вероятности классов, по факту для каждой позиции решаем задачу многоклассовой классификации, для того, чтобы понять какие элементы лучше поставить на каждые позиции.
Источники информации
- ↑https://arxiv.org/abs/1706.03762
- ↑https://jalammar.github.io/illustrated-transformer/
- ↑https://arxiv.org/abs/1706.03762
- ↑https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
- ↑https://arxiv.org/abs/1706.03762
Intuitive Explanation of Skip Connections in Deep Learning
Nowadays, there is an infinite number of applications that someone can do with Deep Learning. However, in order to understand the plethora of design choices such as skip connections that you see in so many works, it is critical to understand a little bit of the mechanisms of backpropagation.
If you were trying to train a neural network back in 2014, you would definitely observe the so-called vanishing gradient problem. In simple terms: you are behind the screen checking the training process of your network and all you see is that the training loss stop decreasing but it is still far away from the desired value. You check all your code lines to see if something was wrong all night and you find no clue. Not the best experience in the world, believe me!
The update rule and the vanishing gradient problem
So, let’s remind our self’s the update rule of gradient descent without momentum, given L to be the loss function and λ \lambda λ the learning rate:
w i ′ = w i + Δ w i w_‘ = w_ + \Delta w_ w i ′ = w i + Δ w i
where Δ w i = − λ ∂ L ∂ Δ w i \Delta w_ = — \lambda \frac<\partial L><\partial \Delta w_> Δ w i = − λ ∂ Δ w i ∂ L
What is basically happening is that you try to update the parameters by changing them with a small amount Δ w i \Delta w_ Δ w i that was calculated based on the gradient, for instance, let’s suppose that for an early layer the average gradient 1e-15 (ΔL/δw). Given a learning rate of 1e-4 ( λ in the equation), you basically change the layer parameters by the product of the referenced quantities, which is 1e-19 ( Δ w i \Delta w_ Δ w i ). As a results, you don’t actually observe any change in the model while training your network. This is how you can observe the vanishing gradient problem.
Looking a little bit in the theory, one can easily grasp the vanishing gradient problem from the backpropagation algorithm. We will briefly inspect the backpropagation algorithm from the prism of the chain rule, starting from basic calculus to gain an insight on skip connections.
In short, backpropagation is the “optimization-magic” behind deep learning architectures. Given that a deep network consists of a finite number of parameters that we want to learn, our goal is to iteratively optimize these parameters with respect to the loss function L.
As you have seen, each architecture has some input (i.e. an image) and produces an output (prediction). The loss function is heavily based on the task we want to solve. For now, what you need to know is the loss function is a quantitative measure of the distance between two tensors, that can represent an image label, a bounding box in an image, a translated text in another language etc. You usually need some kind of supervision to compare the network’s prediction with the desired outcome (ground truth). Keep in mind that backpropagation belongs in the supervised machine learning category.
So, the beautiful idea of backpropagation is to gradually minimize this loss by updating the parameters of the network. But how can you propagate the scalar measured loss inside the network? That’s exactly where backpropagation comes into play.
Backpropagation and partial derivatives
In simple terms, backpropagation is about understanding how changing the weights (parameters) in a network changes the loss function by computing the partial derivatives. For the latter, we use the simple idea of the chain rule, to minimize the distance in the desired predictions. In other words, backpropagation is all about calculating the gradient of the loss function while considering the different weights within that neural network, which is nothing more than calculating the partial derivatives of the loss function with respect to model parameters. By repeating this step many times, we will continually minimize the loss function until it stops reducing, or some other predefined termination criteria are met.
Chain rule
The chain rule basically describes the gradient (change) of a loss function i.e. z with respect to some neural network parameter, let’s say x and y which are functions of a previous layer parameter t. Let f, g, h be different layers on the network that perform a non-linear operation in the input vector.
z = f ( x , y ) x = g ( t ) y = h ( t ) z = f(x,y) \quad x = g(t) \quad y = h(t) z = f ( x , y ) x = g ( t ) y = h ( t )
Now, suppose that you are learning calculus and you want to express the gradient of z with respect to the input. This is what you learn in multi-variable calculus:
Interestingly, the famous algorithm does exactly the same operation but in the opposite way: it starts from the output z and calculates the partial derivatives of each parameter, expressing it only based on the gradients of the later layers.
It’s really worth noticing that all these values are often less than 1, independent of the sign. In order to propagate the gradient to the earlier layer’s, backpropagation uses multiplication of the partial derivatives (as in the chain rule). In general, multiplication with absolute value less than 1 is nice because it provides some sense of training stability, although there is not a strict mathematic theorem about that. However, one can observe that for every layer that we go backwards in the network the gradient of the network gets smaller and smaller.
Skip connections for the win
At present, skip connection is a standard module in many convolutional architectures. By using a skip connection, we provide an alternative path for the gradient (with backpropagation). It is experimentally validated that this additional paths are often beneficial for the model convergence. Skip connections in deep architectures, as the name suggests, skip some layer in the neural network and feeds the output of one layer as the input to the next layers (instead of only the next one).
As previously explained, using the chain rule, we must keep multiplying terms with the error gradient as we go backwards. However, in the long chain of multiplication, if we multiply many things together that are less than one, then the resulting gradient will be very small. Thus, the gradient becomes very small as we approach the earlier layers in a deep architecture. In some cases, the gradient becomes zero, meaning that we do not update the early layers at all.
In general, there are two fundamental ways that one could use skip connections through different non-sequential layers:
a) addition as in residual architectures,
b) concatenation as in densely connected architectures.
We will first describe addition which is commonly referred as residual skip connections.
ResNet: skip connections via addition
The core idea is to backpropagate through the identity function, by just using a vector addition. Then the gradient would simply be multiplied by one and its value will be maintained in the earlier layers. This is the main idea behind Residual Networks (ResNets): they stack these skip residual blocks together. We use an identity function to preserve the gradient.
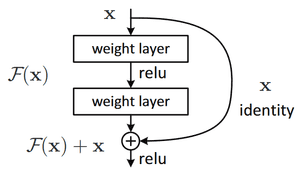
Image is taken from Res-Net original paper
Mathematically, we can represent the residual block, and calculate its partial derivative (gradient), given the loss function like this:
∂ L ∂ x = ∂ L ∂ H ∂ H ∂ x = ∂ L ∂ H ( ∂ F ∂ x + 1 ) = ∂ L ∂ H ∂ F ∂ x + ∂ L ∂ H \frac<\partial L> <\partial x >= \frac<\partial L> <\partial H>\frac<\partial H> <\partial x>= \frac<\partial L> <\partial H>( \frac<\partial F> <\partial x>+ 1 ) = \frac<\partial L> <\partial H>\frac<\partial F> <\partial x>+ \frac<\partial L> <\partial H>∂ x ∂ L = ∂ H ∂ L ∂ x ∂ H = ∂ H ∂ L ( ∂ x ∂ F + 1 ) = ∂ H ∂ L ∂ x ∂ F + ∂ H ∂ L
Apart from the vanishing gradients, there is another reason that we commonly use them. For a plethora of tasks (such as semantic segmentation, optical flow estimation , etc.) there is some information that was captured in the initial layers and we would like to allow the later layers to also learn from them. It has been observed that in earlier layers the learned features correspond to lower semantic information that is extracted from the input. If we had not used the skip connection that information would have turned too abstract.
DenseNet: skip connections via concatenation
As stated, for many dense prediction problems, there is low-level information shared between the input and output, and it would be desirable to pass this information directly across the net. The alternative way that you can achieve skip connections is by concatenation of previous feature maps. The most famous deep learning architecture is DenseNet. Below you can see an example of feature resusability by concatenation with 5 convolutional layers:
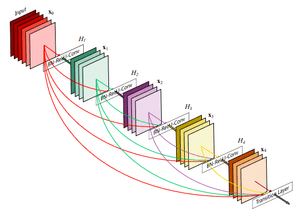
Image is taken from DenseNet original paper
This architecture heavily uses feature concatenation so as to ensure maximum information flow between layers in the network. This is achieved by connecting via concatenation all layers directly with each other, as opposed to ResNets. Practically, what you basically do is to concatenate the feature channel dimension. This leads to
a) an enormous amount of feature channels on the last layers of the network,
b) to more compact models, and
c) extreme feature reusability.
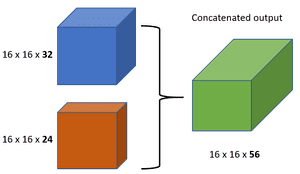
Short and Long skip connections in Deep Learning
In more practical terms, you have to be careful when introducing additive skip connections in your deep learning model. The dimensionality has to be the same in addition and also in concatenation apart from the chosen channel dimension. That is the reason why you see that additive skip connections are used in two kinds of setups:
a) short skip connections
b) long skip connections.
Short skip connections are used along with consecutive convolutional layers that do not change the input dimension (see Res-Net), while long skip connections usually exist in encoder-decoder architectures. It is known that the global information (shape of the image and other statistics) resolves what, while local information resolves where (small details in an image patch).
Long skip connections often exist in architectures that are symmetrical, where the spatial dimensionality is reduced in the encoder part and is gradually increased in the decoder part as illustrated below. In the decoder part, one can increase the dimensionality of a feature map via transpose convolutional layers. The transposed convolution operation forms the same connectivity as the normal convolution but in the backward direction.
U-Nets: long skip connections
Mathematically, if we express convolution as a matrix multiplication, then transpose convolution is the reverse order multiplication (BxA instead of AxB). The aforementioned architecture of the encoder-decoder scheme along with long skip connections is often referred as U-shape (Unet). It is utilized for tasks that the prediction has the same spatial dimension as the input such as image segmentation, optical flow estimation, video prediction, etc.
Long skip connections can be formed in a symmetrical manner, as shown in the diagram below:
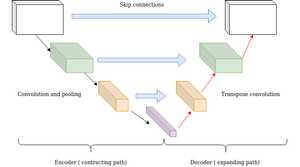
By introducing skip connections in the encoder-decoded architecture, fine-grained details can be recovered in the prediction. Even though there is no theoretical justification, symmetrical long skip connections work incredibly effectively in dense prediction tasks (medical image segmentation).
Conclusion
To sum up, the motivation behind this type of skip connections is that they have an uninterrupted gradient flow from the first layer to the last layer, which tackles the vanishing gradient problem. Concatenative skip connections enable an alternative way to ensure feature reusability of the same dimensionality from the earlier layers and are widely used.
On the other hand, long skip connections are used to pass features from the encoder path to the decoder path in order to recover spatial information lost during downsampling. Short skip connections appear to stabilize gradient updates in deep architectures. Finally, skip connections enable feature reusability and stabilize training and convergence.
As a final note, encouraging further reading , it has been experimentally validated Li et al 2018 the the loss landscape changes significantly when introducing skip connections, as illustrated below:
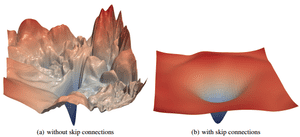
Image is taken from this paper
If you need more information about Skip Connections and Convolutional Neural Networks, the Convolutional Neural Network Course online course by Andrew Ng and Coursera is your best option. It is a very comprehensive material with detailed explanations on how the models are applied in real-world applications, and it will cover everything you want. Besides, it has a 4.9/5 rating. That has to mean something.
@articleadaloglou2020skip,title = "Intuitive Explanation of Skip Connections in Deep Learning",author = "Adaloglou, Nikolas",journal = "https://theaisummer.com/",year = "2020",url = "https://theaisummer.com/skip-connections/">
References
- Çiçek, Ö., Abdulkadir, A., Lienkamp, S. S., Brox, T., & Ronneberger, O. (2016, October). 3D U-Net: learning dense volumetric segmentation from sparse annotation. In International conference on medical image computing and computer-assisted intervention (pp. 424-432). Springer, Cham.
- Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention (pp. 234-241). Springer, Cham.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. nature, 323(6088), 533-536.
- Nielsen, M. A. (2015). Neural networks and deep learning (Vol. 2018). San Francisco, CA, USA:: Determination press.
- Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
- Drozdzal, M., Vorontsov, E., Chartrand, G., Kadoury, S., & Pal, C. (2016). The importance of skip connections in biomedical image segmentation. In Deep Learning and Data Labeling for Medical Applications (pp. 179-187). Springer, Cham.
- Li, H., Xu, Z., Taylor, G., Studer, C., & Goldstein, T. (2018). Visualizing the loss landscape of neural nets. In Advances in Neural Information Processing Systems (pp. 6389-6399).
Deep Learning in Production Book ��
Learn how to build, train, deploy, scale and maintain deep learning models. Understand ML infrastructure and MLOps using hands-on examples.
* Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.
- The update rule and the vanishing gradient problem
- Backpropagation and partial derivatives
- Chain rule
What are Skip Connections in Deep Learning?
The need for deeper networks emerges while handling complex tasks. However, training a deep neural net has a lot of complications not only limited to overfitting and high computation costs but also has some non-trivial problems. In this article, we will solve some complex deep learning problems using skip connections.
Table of contents
- Why Skip Connections?
- What are Skip Connections?
- How do Skip Connections Work?
- Variants of Skip Connections
- Residual Networks (ResNets)
- Densely Connected Convolutional Networks (DenseNets)
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- ResNet – A Residual Block
- DenseNet – A Dense Block
Why Skip Connections?
The beauty of deep neural networks is that they can learn complex functions more efficiently than their shallow counterparts. While training deep neural nets, the performance of the model drops down with the increase in depth of the architecture. This is known as the degradation problem. But, what could be the reasons for the saturation inaccuracy with the increase in network depth? Let us try to understand the reasons behind the degradation problem.
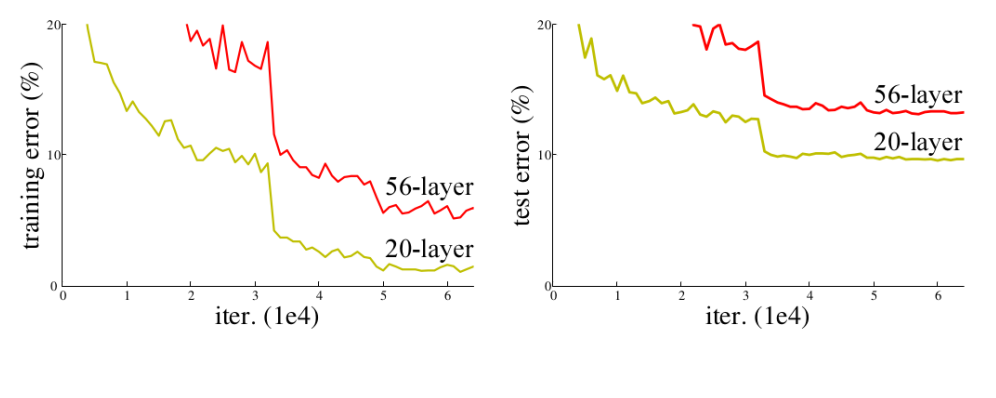
Deeper Network Performance Analysis: Overfitting Discarded
One of the possible reasons could be overfitting. The model tends to overfit with the increase in depth but that’s not the case here. As you can infer from the below figure, the deeper network with 56 layers has more training error than the shallow one with 20 layers. The deeper model doesn’t perform as well as the shallow one. Clearly, overfitting is not the problem here.
Gradient Issues in ResNet Construction
Another possible reason can be vanishing gradient and/or exploding gradient problems. However, the authors of ResNet (He et al.) argued that the use of Batch Normalization and proper initialization of weights through normalization ensures that the gradients have healthy norms. But, what went wrong here? Let’s understand this by construction.
Consider a shallow neural network that was trained on a dataset. Also, consider a deeper one in which the initial layers have the same weight matrices as the shallow network (the blue colored layers in the below diagram) with added some extra layers (green colored layers). We set the weight matrices of the added layers as identity matrices (identity mappings).
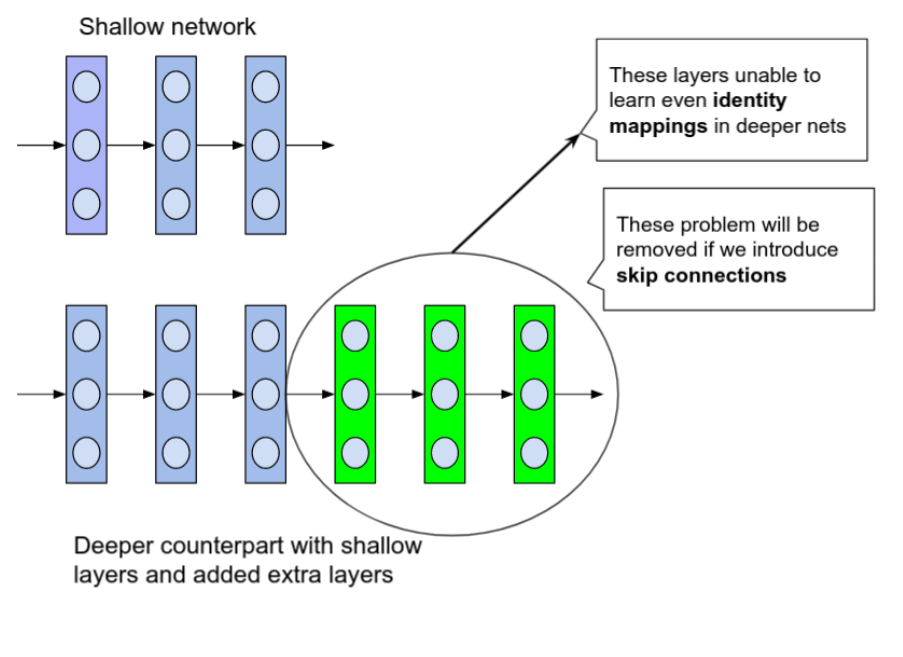
From this construction, the deeper network should not produce any higher training error than its shallow counterpart because we are actually using the shallow model’s weight in the deeper network with added identity layers. But experiments prove that the deeper network produces high training error comparing to the shallow one. This states the inability of deeper layers to learn even identity mappings.
The degradation of training accuracy indicates that not all systems are similarly easy to optimize.
One of the primary reasons is due to random initialization of weights with a mean around zero, L1, and L2 regularization. As a result, the weights in the model would always be around zero and thus the deeper layers can’t learn identity mappings as well.
Here comes the concept of skip connections which would enable us to train very deep neural networks. Let’s learn this awesome concept now.
What are Skip Connections?
Skip Connections (or Shortcut Connections) as the name suggests skips some of the layers in the neural network and feeds the output of one layer as the input to the next layers.
Skip Connections were introduced to solve different problems in different architectures. In the case of ResNets, skip connections solved the degradation problem that we addressed earlier whereas, in the case of DenseNets, it ensured feature reusability. We’ll discuss them in detail in the following sections.
How do Skip Connections Work?
Skip connections were introduced in literature even before residual networks. For example, Highway Networks (Srivastava et al.) had skip connections with gates that controlled and learned the flow of information to deeper layers. This concept is similar to the gating mechanism in LSTM. Although ResNets is actually a special case of Highway networks, the performance isn’t up to the mark comparing to ResNets. This suggests that it’s better to keep the gradient highways clear than to go for any gates – simplicity wins here!
Neural networks can learn any functions of arbitrary complexity, which could be high-dimensional and non-convex. Visualizations have the potential to help us answer several important questions about why neural networks work. And there is actually some nice work done by Li et al. which enables us to visualize the complex loss surfaces. The results from the networks with skip connections are even more surprising! Take a look at them.
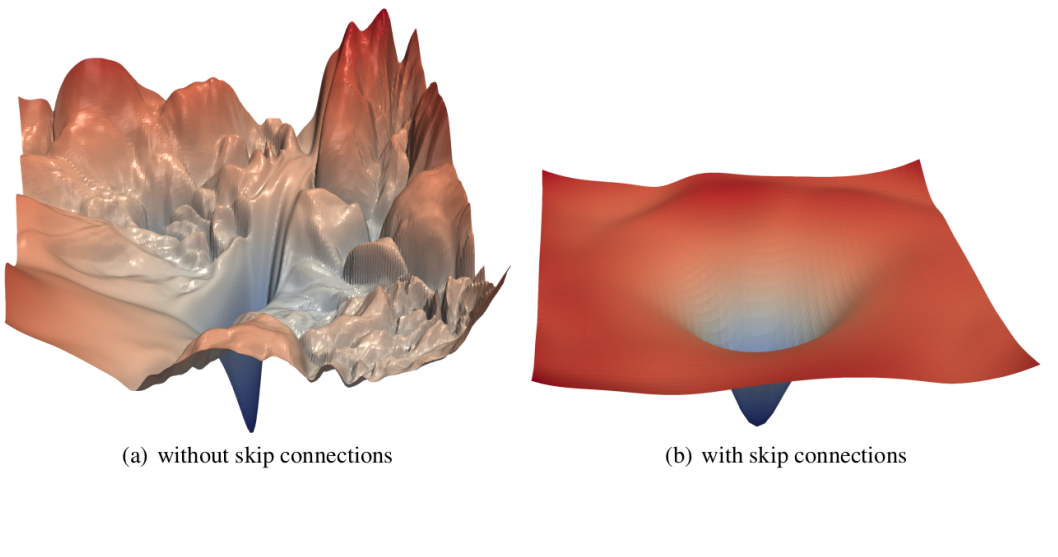
As you can see here, the loss surface of the neural network with skip connections is smoother and thus leading to faster convergence than the network without any skip connections. Let’s see the variants of skip connections in the next section.
Variants of Skip Connections
In this section, we will see the variants of skip connections in different architectures. Skip Connections can be used in 2 fundamental ways in Neural Networks: Addition and Concatenation.
Residual Networks (ResNets)
Residual Networks were proposed by He et al. in 2015 to solve the image classification problem. In ResNets, the information from the initial layers is passed to deeper layers by matrix addition. This operation doesn’t have any additional parameters as the output from the previous layer is added to the layer ahead. A single residual block with skip connection looks like this:

Thanks to the deeper layer representation of ResNets as pre-trained weights from this network can be used to solve multiple tasks. It’s not only limited to image classification but also can solve a wide range of problems on image segmentation, keypoint detection & object detection. Hence, ResNet is one of the most influential architectures in the deep learning community.
Next, we’ll learn about another variant of skip connections in DenseNets which is inspired by ResNets.
I would recommend you to go through the below resources for an in-detailed understanding of ResNets–
Densely Connected Convolutional Networks (DenseNets)
DenseNets were proposed by Huang et al. in 2017. The primary difference between ResNets and DenseNets is that DenseNets concatenates the output feature maps of the layer with the next layer rather than a summation.
Coming to Skip Connections, DenseNets uses Concatenation whereas ResNets uses Summation

The idea behind the concatenation is to use features that are learned from earlier layers in deeper layers as well. This concept is known as Feature Reusability. So, DenseNets can learn mapping with fewer parameters than a traditional CNN as there is no need to learn redundant maps.
U-Net: Convolutional Networks for Biomedical Image Segmentation
The use of skip connections influences the field of biomedical too. U-Nets were proposed by Ronneberger et al. for biomedical image segmentation. It has an encoder-decoder part including Skip Connections. The overall architecture looks like the English letter “U”, thus the name U-Nets.

The layers in the encoder part are skip connected and concatenated with layers in the decoder part (those are mentioned as grey lines in the above diagram). This makes the U-Nets use fine-grained details learned in the encoder part to construct an image in the decoder part.
These kinds of connections are long skip connections whereas the ones we saw in ResNets were short skip connections. More about U-Nets here.
Okay! Enough of theory, let’s implement a block of the discussed architectures and how to load and use them in PyTorch!
Implementation of Skip Connections
In this section, we will build ResNets and DesNets using Skip Connections from the scratch. Are you excited? Let’s go!
ResNet – A Residual Block
First, we will implement a residual block using skip connections. PyTorch is preferred because of its super cool feature – object-oriented structure.
As we have a Residual block in our hand, we can build a ResNet model of arbitrary depth! Let’s quickly build the first five layers of ResNet-34 to get an idea of how to connect the residual blocks.
PyTorch provides us an easy way to load ResNet models with pretrained weights trained on the ImageNet dataset.
DenseNet – A Dense Block
Implementing the complete densenet would be a little bit complex. Let’s grab it step by step.
- Implement a DenseNet layer
- Build a dense block
- Connect multiple dense blocks to obtain a densenet model
Next, we’ll implement a dense block that consists of an arbitrary number of DenseNet layers.
From the dense block, let’s build DenseNet. Here, I’ve omitted the transition layers of DenseNet architecture (which acts as downsampling) for simplicity.
Conclusion
In this article, we’ve discussed the importance of skip connections for the training of deep neural nets and how skip connections were used in ResNet, DenseNet, and U-Net with its implementation. I know, this article covers many theoretical aspects which are not easy to grasp in one go. So, feel free to leave comments if you have any.
Frequently Asked Question
Q1. Why skip connections in ResNet?
A. Skip connections in ResNet prevent the vanishing gradient problem during deep neural network training. These connections enable the direct flow of information from earlier layers to later layers, aiding in preserving gradient and promoting better convergence.
Q2. Why do we use skip connections in unet?
A. Skip connections in U-Net are employed to address the challenge of information loss during down-sampling and up-sampling in image segmentation tasks. These connections help merge features from different resolution levels, enhancing the model’s ability to capture fine details.
Q3. What are the different types of skip connections?
A. Types of skip connections include short and long skip connections. Short skips connect immediately adjacent layers, while long skips connect layers with larger spatial distances between them. These connections contribute to multi-scale feature extraction.
Q5. What is the difference between skip and residual connections?
A. Both skip and residual connections enable gradients to flow better, but skip connections directly concatenate or merge features from different layers, while residual connections add the original input to the transformed output, aiding in better gradient propagation and network training.