Функция substr
Функция substr вырезает и возвращает подстроку из строки. Сама строка при этом не изменяется. Первым параметром функция принимает строку, вторым — позицию символа, откуда следует начинать вырезание, а третьим — количество символов. Учтите, что нумерация символов строки начинается с нуля.
Второй параметр может быть отрицательным — в этом случае отсчет начнется с конца строки, при этом последний символ будет иметь номер -1 .
Третий параметр можно не указывать — в этом случае отрезание произойдет до конца строки.
Данная функция неправильно работает с кириллицей. Используйте функцию mb_substr (она работает аналогичным образом, но корректно обрабатывает кириллицу).
Синтаксис
substr(строка, откуда, [сколько]);
Пример
Давайте вырежем 3 символа из строки позиции 1 (со второго символа, так как первый имеет номер 0):
Результат выполнения кода:
Пример
Давайте вырежем все символы до конца строки, начиная со второго (он имеет номер 1):
Результат выполнения кода:
Пример
Давайте вырежем третий и второй символы с конца, для этого укажем начало вырезания -3 (это номер третьего символа с конца), а количество символов — 2 :
Результат выполнения кода:
Пример
Давайте вырежем 2 последних символа, для этого укажем позицию предпоследнего символа (это -2), а третий параметр не укажем — в этом случае обрезание будет до конца строки:
Результат выполнения кода:
Пример
Давайте вырежем последний символ:
Результат выполнения кода:
Смотрите также
- функцию substr_replace ,
которая вырезает часть строки и заменяет ее на другую
SQL-Ex blog

Пример применения функции Substring в T-SQL, R и Python
Добавил smois on Суббота, 26 октября. 2019
Проблема
Манипуляция со строками является одним из наиболее фундаментальных элементов работы с данными, используемом почти в каждом примере преобразования данных. Основными целями манипуляции со строками являются форматирование, усечение, набивка, замена и аналогичные функции. Часто для применения этих функций требуется выбрать конкретную часть строки, и затем применить преобразования. В SQL Server имеется три языка, которые часто используются в связке — T-SQL, R и Python. Все эти языки программирования/запросов предоставляют возможность выбора подстроки с помощью функции substring или эквивалентной функции/оператора. Здесь мы научимся использовать функцию substring для выбора строки на всех трех языках.
Решение
Функция substring в T-SQL (SQL Server)
Начнем с функции substring в языке T-SQL. Функция имеет следующий синтаксис:
SUBSTRING (expression, start, length)
Здесь expression означает фактическую строку, имя поля или переменную символьного типа данных. Параметр start — начальная позиция, а length — длина извлекаемой части строки.
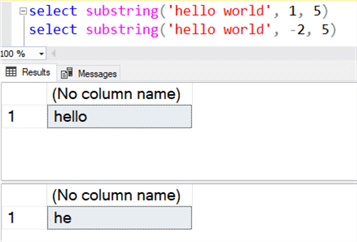
На приведенных ниже примерах первый извлекает часть, которая начинается с позиции 1 длиной 5 символов от начальной позиции индекса. Т.е. первым символом в строке «hello world» является «h», а пять символов от «h» заканчиваются на «o». В результате получим «hello». Второй пример начинает выделение с позиции -2 длиной 5 символов, что эквивалентно стартовой позиции 1 с длиной 3, что в результате дает «he», как показано ниже.
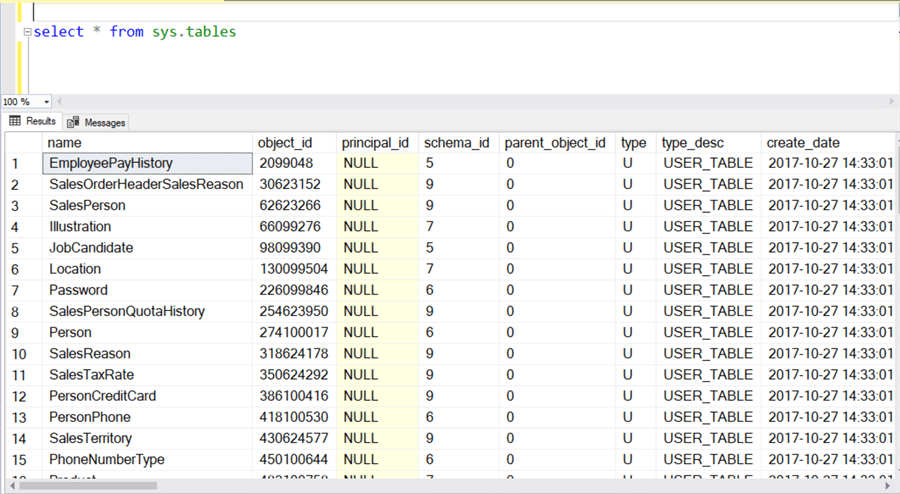
Выполним теперь несколько примеров с функцией substring в предложении WHERE запроса SELECT. Мы можем использовать вывод из sys.tables (на рисунке ниже). Пусть нам требуется выбрать все таблицы, имена которых содержат слово «Pro».
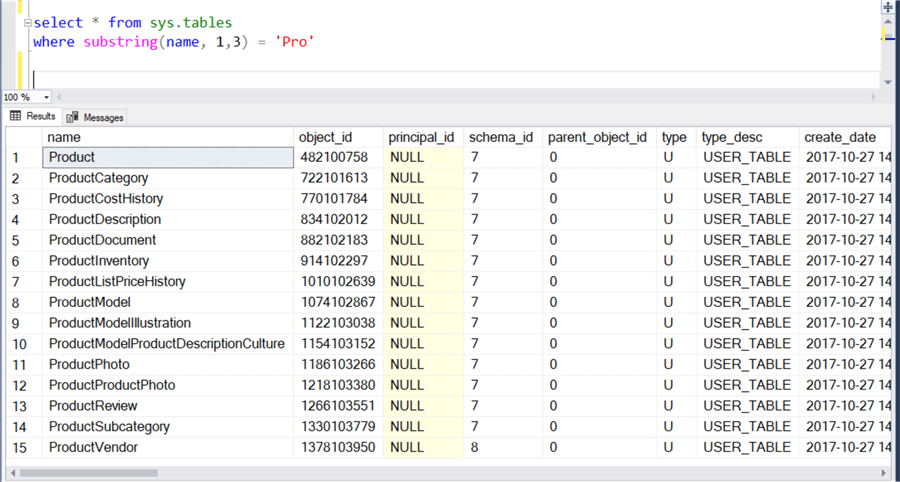
Мы можем использовать функцию substring как часть критерия для фильтрации. В этой функции роль expression играет поле «name», начальная позиция 1, а длина 3, поскольку мы знаем, что слово «Pro» имеет длину 3 символа. Критерием в предложении WHERE должно быть логическое выражение, поэтому мы будем искать соответствие значения функции substring со словом «Pro». Выполнение нижеприведенного запроса даст на выходе имена таблиц, которые начинаются со слова «Pro».
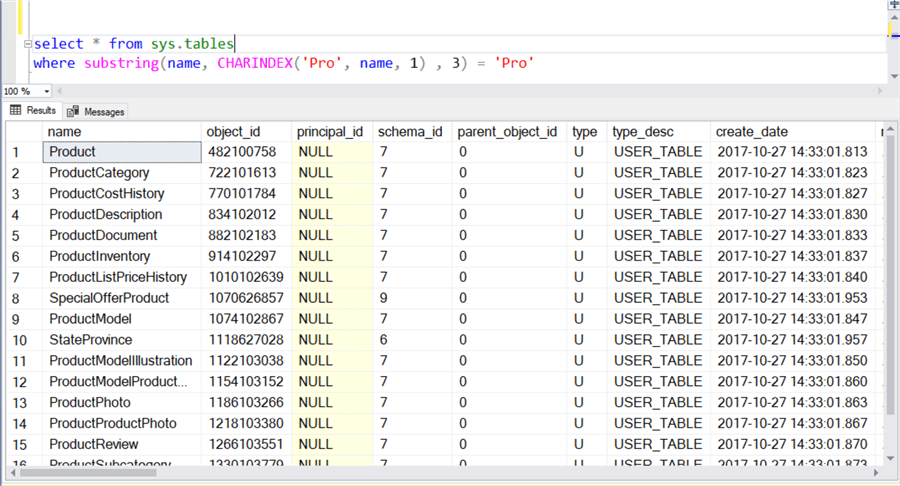
Результат выше не вполне верный, поскольку мы получили только имена таблиц, которые начинаются с «Pro», но слово «Pro» может также находиться в середине или в конце строки. Это приводит нас к ситуации, когда требуется найти начальную позицию слова «Pro» динамически. Для этого мы можем использовать функцию charindex. Эта функция первым аргументом имеет поисковую строку, вторым — поле/переменную/значение, в котором выполняется поиск строки. Третий аргумент — начальная позиция поиска — является необязательным. Модифицируем запрос SELECT, как показано ниже, и теперь мы получим все имена таблиц, содержащих слово «Pro».
Функция substring в R
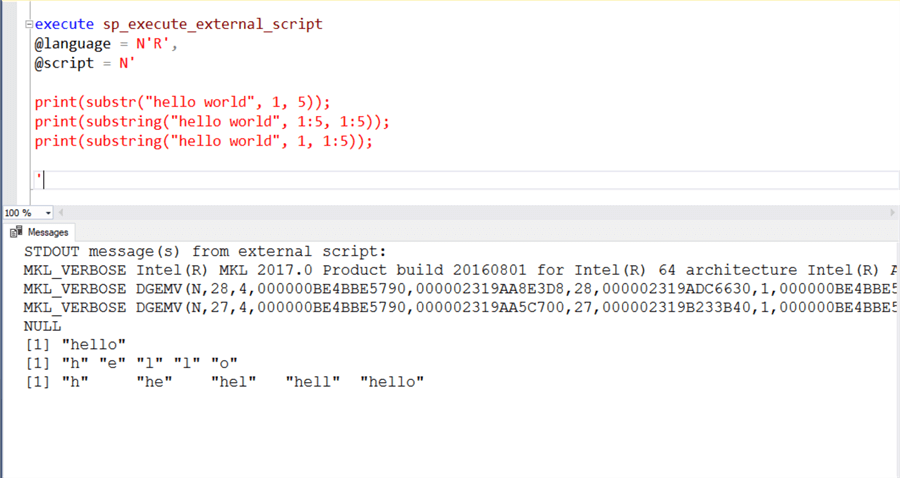
Давайте теперь разберемся с тем, как substring работает в языке программирования R. R предоставляет функции substring и substr, которые имеют эквивалентную функциональность функции substring в T-SQL. Вы можете выполнить код R в T-SQL, используя хранимую процедуру sp_execute_external_script.
Ниже первый пример демонстрирует применение функции substr, которая работает в точности как функция substring в T-SQL. Вы можете также использовать функцию substring, которая принимает строку, начальную и конечную позиции в качестве аргументов. Вы можете использовать диапазоны для параметра начальной и конечной позиций.
Во втором примере мы задаем диапазон 1 — 5 для начальной позиции, как и для конечной позиции; результат приведен ниже. Вы могли бы получить каждую букву на выходе для первых пяти символов строки, т.к. параметры трактуются так: начало 1 и конец 1, начало 2 и конец 2, и т.д. Поэтому длина на выходе всегда 1 символ.
Если мы немного изменим код, и оставим стартовую позицию константой, а конечную позицию сделаем диапазоном, выход в порядке увеличения длины будет выглядеть, как на рисунке ниже.
Функция substring в Python
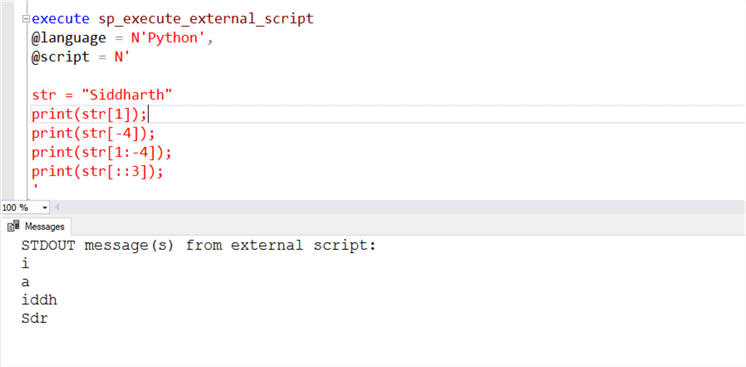
Строка в python рассматривается как массив символов Юникод. Python не имеет эквивалента для типа данных символов, т.к. строки рассматриваются просто как массивы. Доступ к массивам в Python осуществляется с помощью номера позиции в квадратных скобках. Поэтому давайте разберемся, как выполняются операции с массивами строковых литералов.
В первой строке кода мы создаем строковый литерал присвоением ему строкового значения. В следующей строке кода мы получаем второй символ строкового литерала, обращаясь к элементу массива на позиции 1 (индексация начинается с 0). Если мы используем отрицательное значение, например, -4, то это будет стартовой позицией выборки с правой стороны строки. Если вы посмотрите на результат выполнения третьей строки кода, то поймете, как работают отрицательные позиции.
Допустим мы хотим получить строку, указывая стартовую и конечную позиции. В этом случае мы можем задать диапазон в качестве элемента массива. В четвертой строке кода мы задаем диапазон от 1 до -4, что означает, что выбор начинается с первого элемента и заканчивается четвертым элементом с конца (заметим, что в Python правая граница не входит в диапазон).
Давайте рассмотрим еще один пример, когда нам требуется извлечь каждый третий символ строки. Вы можете использовать оператор двойного двоеточия в массиве и указать интервалы, как показано в последней строке кода (3 в нашем случае). На выходе будет строка, состоящая из каждого третьего символа исходной строки.
Таким образом, вы можете выполнять операции выборки подстроки на разных языках с помощью функции substring или ее эквивалента. Сравнивая производительность функциональности substring в разных языках, вы можете выбрать тот язык, который даст наилучшую производительность на больших объемах данных.
Функция substring
Возвращает подстроку, входящую в expr , которая начинается с pos и имеет длину len . Эта функция является синонимом функции substr.
Синтаксис
substring(expr, pos [, len]) substring(expr FROM pos [FOR len] ] ) Аргументы
- expr : выражение или STRING выражение BINARY .
- pos : целочисленное числовое выражение, которое определяет начальную позицию.
- len : необязательное целочисленное числовое выражение.
Возвраты
Для pos нумерация начинается с 1. Если pos отрицательное начало определяется подсчетом символов (или байтов для BINARY ) с конца.
Если len меньше 1, возвращается пустая строка.
Если len отсутствует, функция возвращает символы или байты начиная с позиции pos .
Примеры
> SELECT substring('Spark SQL', 5); k SQL > SELECT substring('Spark SQL', -3); SQL > SELECT substring('Spark SQL', 5, 1); k > SELECT substring('Spark SQL' FROM 5); k SQL > SELECT substring('Spark SQL' FROM -3); SQL > SELECT substring('Spark SQL' FROM 5 FOR 1); k > SELECT substring('Spark SQL' FROM -10 FOR 5); Spar Связанные функции
Python. Функции, основанные на поиске и замене подстроки в строке
Функции, основанные на поиске и замене подстроки в строке
Поиск на других ресурсах:
1. Функция str.count() . Количество вхождений подстроки в заданном диапазоне
Функция str.count() возвращает количество вхождений подстроки в заданном диапазоне. Согласно документации Python общая форма использования функции следующая
n = str.count(substring[, start[, end]])
- n – результат, количество вхождений подстроки substring в строке str , которые не перекрываются;
- str – исходная строка;
- substring – подстрока, которая может входить в строку str ;
- start , end – соответственно начальная и конечная позиции (индексы) в строке str , определяющие диапазон который принимается ко вниманию (рассматривается). Иными словами значения start , end определяют срез.
Пример.
# Функция str.count() - количество вхождений подстроки в заданном диапазоне # 1. Вызов функции с указанием диапазона s1 = 'abcdef' # исходная строка n = s1.count('bcd', 0, len(s1)) # n = 1, диапазон 0..5 n = 'ab ab babab'.count('ab', 2, 10) # n = 2 n = 'ab ab babab'.count('ab', 0, 6) # n = 2 # 2. Вызов функции без указания диапазона s1 = 'Hello world!' n = s1.count('о') # n = 2, количество символов 'о' в строке s1 = 'abcbcd abcd' n = s1.count("bc") # n = 3 # 3. Вызов функции с указанием начального значения start s1 = 'abc abc abcd' n = s1.count('abc', 3) # n = 2
2. Функция str.find() . Поиск подстроки в строке
Функция find() предназначена для поиска подстроки в строке. В соответствии с документацией Python общая форма вызова функции следующая:
index = s.find(sub [, start[, end]])
- index – целочисленное значение, которое есть индексом первого вхождения подстроки sub в строке s. Если подстрока sub не найдена в строке s, то index =-1;
- s – строка, в которой осуществляется поиск подстроки sub ;
- start , end – позиции в строке s . Эти позиции определяют границы среза s [ start : end ], определяющего обрабатываемый диапазон. Если не задавать параметры start , end , то поиск осуществляется во всей строке.
Пример.
# Функция str.find() - поиск подстроки в строке # Исходная строка, в которой осуществляется поиск s = 'abcde fg hijkl mnop' # 1. Обработка целой строки index = s.find('hij') # index = 9 index = s.find('+-=') # index = -1 # 2. Обработка среза s[start:end] # берется ко вниманию часть 'abcde' строки s index = s.find('hij', 0, 5) # index = -1 index = s.find('cde', 0, 5) # index = 2 index = 'hello world!'.find('wor', 2, len(s)) # index = 6
3. Функция str.index() . Поиск подстроки в строке с генерированием исключения
Функция str.index() осуществляет поиск подстроки в строке. Данная функция работает так же как и функция str.find() , однако, если подстрока не найдена, то вызывается исключение ValueError .
Согласно документации Python общая форма вызова функции следующая:
pos = str.index(substring [, start [, end]])
- pos – позиция подстроки substring в строке str в случае, если строка найдена. Если подстрока не найдена, то вызывается исключение ValueError ;
- str – строка, в которой осуществляется поиск;
- start , end – соответственно начальная и конечная позиции в строке str , определяющие диапазон поиска.
Пример.
# Функция str.index() - поиск подстроки в строке # Случай 1. Генерируется исключение ValueError: substring not found #t = str.index('sdf', 'abcdef def hj') - исключительная ситуация # Случай 2. Подстрока существует в строке s = 'abcdef' t = s.index('bc') # t = 1 - позиция найденной подстроки # Поиск в заданном диапазоне s = 'abc def ghi def' t = s.index('def', 0, len(s)) # t = 4 # Поиск в диапазоне '012' s = '0123456789' t = s.index('012', 0, 3) # t = 0
4. Функция str.rfind() . Найти наибольший индекс вхождения подстроки в строку
Функция str.rfind() возвращает наибольшую позицию (индекс) в строке заданной подстроки, если таковая найдена. Общая форма использования функции следующая:
position = str.rfind(subs[, start[, end]])
- position – искомая позиция (индекс) вхождения подстроки subs в строке str . Если подстрока subs в строке str не найдена, то position =-1;
- str – строка, в которой осуществляется поиск подстроки subs ;
- subs – заданная подстрока;
- start , end – соответственно начальный и конечный индексы, определяющие срез в строке str .
Пример.
# Функция str.rfind() # 1. Использование без указания диапазона s1 = 'abc def ab abc' index = s1.rfind('ab') # index = 11 index = s1.rfind('jkl') # index = -1 # 2. Использование с указанием начала start s1 = '012 345 012' index = s1.rfind('01', 3) # index = 8 # 3. Использование с указанием начала start и конца end s1 = 'abc def abc def gh' s2 = 'bc' # подстрока index = s1.rfind(s2, 0, len(s1)) # index = 9 index = s1.rfind(s2, 0, 1) # index = -1, подстрока не найдена
5. Функция str.rindex() . Найти наибольший индекс вхождения подстроки в строку с генерированием исключения ValueError
Функция str.rindex() работает также как и функция rfind() , то есть возвращает наибольшую позицию подстроки в строке. Разница между rindex() и rfind() состоит в следующем: если подстрока не найдена в строке, то генерируется исключение ValueError .
Общая форма использования функции следующая:
position = str.rindex(subs[, start[, end]])
- position – искомая позиция (индекс) вхождения подстроки subs в строке str . Если подстрока subs в строке str не найдена, генерируется исключение ValueError ;
- str – строка, в которой осуществляется поиск подстроки subs ;
- subs – заданная подстрока;
- start , end – соответственно начальный и конечный индексы, определяющие срез в строке str .
Пример.
# Функция str.index() # 1. Использование без указания диапазона s1 = 'abc def ab abc' index = s1.rindex('ab') # index = 11 index = str.rindex(s1, ' ') # index = 10, символ пробел на 10-й позиции # 2. Использование с указанием начала start s1 = '012 345 012' index = s1.rindex('01', 3) # index = 8 # 3. Использование с указанием начала start и конца end s1 = 'abc def abc def gh' s2 = 'bc' # подстрока index = s1.rindex(s2, 0, len(s1)) # index = 9 # Следующий код сгенерирует исключение # ValueError: substring not found index = s1.rindex(s2, 0, 1)
6. Функция str.replace() . Замена подстроки в строке
Функция str.replace() возвращает копию строки, в который все вхождения подстроки old заменены на new .
Общая форма использования функции
s1 = s2.replace(old, new[, count])
- s1 – результирующая строка-копия;
- s2 – строка-оригинал, в которой делаются замены подстроки old на подстроку new ;
- old – подстрока, которая может быть заменена другой подстрокой new . Количество символов в подстроке произвольно. Если подстрока old не найдена в строке s2 , тогда функция возвращает строку s2 без изменений;
- new – подстрока, заменяющая подстроку old в строке s2 ;
- count – количество замен которые могут быть осуществлены. Если count не задано, то замены осуществляются во всех возможных вхождениях подстроки old в строке s2 .
Пример.
# Функция str.replace() - замена подстроки в строке # 1. Вызов без использования параметра count s1 = 'abcdef' s2 = s1.replace('bc', '111') # s2 = 'a111def' s1 = 'abc abc abc' s2 = s1.replace('bc', '0000') # s2 = 'a0000 a0000 a0000' # Случай, если подстрока в строке не найдена s2 = str.replace(s1, 'jkl', '111') # s2 = 'abcdef' # 2. Вызов с использованием параметра count s1 = 'abcd abcd abcd' s2 = s1.replace('bcd', '+++', 3) # s2 = 'a+++ a+++ a+++' s2 = s1.replace('bcd', '++++', 2) # s2 = 'a++++ a++++ abcd' s2 = s1.replace('ab', '---', 1) # s2 = '---cd abcd abcd' s2 = s1.replace('abcd', '==', 6) # s2 = '== == =='
Связанные темы
- Функции для работы со строками, определяющие особенности строки
- Функции обрабатывающие и определяющие начало и конец строки
- Функции обработки строки в соответствии с форматом или правилом кодирования. Стили форматирования