Для чего нужен train_test_split в sklearn?
Сейчас занимаюсь машинным обучением, может кто подробно рассказать, для чего в МО нужны X_train,X_test,y_train,y_test, аргументы, которые мы получаем в результате функции train_test_split() ?
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42) И каким образом задается параметр test_size?
Отслеживать
задан 12 дек 2019 в 15:59
389 1 1 золотой знак 5 5 серебряных знаков 16 16 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Таким образом вы делите свою выборку на тренировочную и тестовую часть. Обучение будет происходит на тренировочной выборке, а на тестовой — проверка полученных «знаний». test_size используется для разбиения выборки(в вашем случае будет 20% использовано на тесты).
Отслеживать
ответ дан 12 дек 2019 в 18:05
386 1 1 серебряный знак 13 13 бронзовых знаков
А как формируется тренировочная и тестовая часть?
12 дек 2019 в 19:38
Вы сами их формируете, разбивая выборку.
12 дек 2019 в 19:55
- python
- машинное-обучение
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Как создать обучающий и тестовый набор из фрейма данных Pandas
При подгонке моделей машинного обучения к наборам данных мы часто разбиваем набор данных на два набора:
1. Набор для обучения: используется для обучения модели (70-80% исходного набора данных).
2. Тестовый набор: используется для получения объективной оценки производительности модели (20-30% исходного набора данных).
В Python существует два распространенных способа разделить DataFrame pandas на обучающий и тестовый наборы:
Способ 1: используйте train_test_split() из sklearn
from sklearn. model_selection import train_test_split train, test = train_test_split(df, test_size= 0.2 , random_state= 0 ) Способ 2: использовать sample() из панд
train = df.sample (frac= 0.8 ,random_state= 0 ) test = df.drop (train. index ) В следующих примерах показано, как использовать каждый метод со следующими пандами DataFrame:
import pandas as pd import numpy as np #make this example reproducible np.random.seed (1) #create DataFrame with 1,000 rows and 3 columns df = pd.DataFrame() #view first few rows of DataFrame df.head () x1 x2 y 0 5 1 1 1 11 8 0 2 12 4 1 3 8 7 0 4 9 0 0 Пример 1: Используйте train_test_split() из sklearn
В следующем коде показано, как использовать функцию train_test_split() из sklearn для разделения DataFrame pandas на обучающие и тестовые наборы:
from sklearn. model_selection import train_test_split #split original DataFrame into training and testing sets train, test = train_test_split(df, test_size= 0.2 , random_state= 0 ) #view first few rows of each set print(train.head()) x1 x2 y 687 16 2 0 500 18 2 1 332 4 10 1 979 2 8 1 817 11 1 0 print(test.head()) x1 x2 y 993 22 1 1 859 27 6 0 298 27 8 1 553 20 6 0 672 9 2 1 #print size of each set print(train. shape , test. shape ) (800, 3) (200, 3) Из вывода мы видим, что было создано два набора:
- Учебный набор: 800 строк и 3 столбца.
- Набор для тестирования: 200 строк и 3 столбца.
Обратите внимание, что test_size управляет процентом наблюдений из исходного DataFrame, которые будут принадлежать тестовому набору, а значение random_state делает разделение воспроизводимым.
Пример 2: Используйте sample() из панд
В следующем коде показано, как использовать функцию sample() из pandas для разделения кадра данных pandas на обучающие и тестовые наборы:
#split original DataFrame into training and testing sets train = df.sample (frac= 0.8 ,random_state= 0 ) test = df.drop (train. index ) #view first few rows of each set print(train.head()) x1 x2 y 993 22 1 1 859 27 6 0 298 27 8 1 553 20 6 0 672 9 2 1 print(test.head()) x1 x2 y 9 16 5 0 11 12 10 0 19 5 9 0 23 28 1 1 28 18 0 1 #print size of each set print(train. shape , test. shape ) (800, 3) (200, 3) Из вывода мы видим, что было создано два набора:
- Учебный набор: 800 строк и 3 столбца.
- Набор для тестирования: 200 строк и 3 столбца.
Обратите внимание, что frac управляет процентом наблюдений из исходного DataFrame, которые будут принадлежать обучающему набору, а значение random_state делает разделение воспроизводимым.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Python:
Примеры разделения датасета на train и test c Scikit-learn
Если вы разбиваете датасет на данные для обучения и тестирования, нужно помнить о некоторых моментах. Далее следует обсуждение трех передовых практик, которые стоит учитывать при подобном разделении. А также демонстрация того, как реализовать эти соображения в Python.
В данной статье обсуждаются три конкретных особенности, которые следует учитывать при разделении набора данных, подходы к решению связанных проблем и практическая реализация на Python.
Для наших примеров мы будем использовать модуль train_test_split библиотеки Scikit-learn, который очень полезен для разделения датасетов, независимо от того, будете ли вы применять Scikit-learn для выполнения других задач машинного обучения. Конечно, можно выполнить такие разбиения каким-либо другим способом (возможно, используя только Numpy). Библиотека Scikit-learn включает полезные функции, позволяющее сделать это немного проще.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67, random_state=42)Возможно, вы использовали этот модуль для разделения данных в прошлом, но при этом не приняли во внимание некоторые детали.
Случайное перемешивание строк
Первое, на что следует обратить внимание: перемешаны ли ваши экземпляры? Это следует делать пока нет причин не перетасовывать данные (например, они представляют собой временные интервалы). Мы должны убедиться в том, что наши экземпляры не разбиты на выборки по классам. Это потенциально вносит в нашу модель некоторую нежелательную предвзятость.
Например, посмотрите, как одна из версий набора данных iris, упорядочивает свои экземпляры при загрузке:
from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target print(f"Классы датасета: ")Классы датасета: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]Если такой набор данных с тремя классами при равном числе экземпляров в каждом разделить на две выборки: 2/3 для обучения и 1/3 для тестирования, то полученные поднаборы будут иметь нулевое пересечение классовых меток. Это, очевидно, недопустимо при изучении признаков для предсказания классов. К счастью, функция train_test_split по умолчанию автоматически перемешивает данные (вы можете переопределить это, установив для параметра shuffle значение False ).
- В функцию должны быть переданы как вектор признаков, так и целевой вектор (X и y).
- Для воспроизводимости вы должны установить аргумент random_state .
- Также необходимо определить либо train_size , либо test_size , но оба они не нужны. Если вы явно устанавливаете оба параметра, они должны составлять в сумме 1.
Вы можете убедится, что теперь наши классы перемешаны.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67, random_state=42) print(f"Классы в y_train:\n") print(f"Классы в y_test:\n")Классы в y_train: [1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 1 2 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2 0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 1 2 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1 0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 1 1 2 2 0 1 2 0 1 2] Классы в y_test: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1 0 0 0 2 1 1 0 0 1 2 2 1 2]Стратификация (равномерное распределение) классов
Данное размышление заключается в следующем. Равномерно ли распределено количество классов в наборах данных, разделенных для обучения и тестирования?
import numpy as np print(f"Количество строк в y_train по классам: ") print(f"Количество строк в y_test по классам: ")Количество строк в y_train по классам: [31 35 34] Количество строк в y_test по классам: [19 15 16]Это не равная разбивка. Главная идея заключается в том, получает ли наш алгоритм равные возможности для изучения признаков каждого из представленных классов и последующего тестирования результатов обучения, на равном числе экземпляров каждого класса. Хотя это особенно важно для небольших наборов данных, желательно постоянно уделять внимание данному вопросу.
Мы можем задать пропорцию классов при разделении на обучающий и проверяющий датасеты с помощью параметра stratify функции train_test_split . Стоит отметить, что мы будем стратифицировать в соответствии распределению по классам в y .
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67, random_state=42, stratify=y) print(f"Количество строк в y_train по классам: ") print(f"Количество строк в y_test по классам: ")Количество строк в y_train по классам: [34 33 33] Количество строк в y_test по классам: [16 17 17]Сейчас это выглядит лучше, и представленные числа говорят нам, что это наиболее оптимально возможное разделение.
Дополнительное разделение
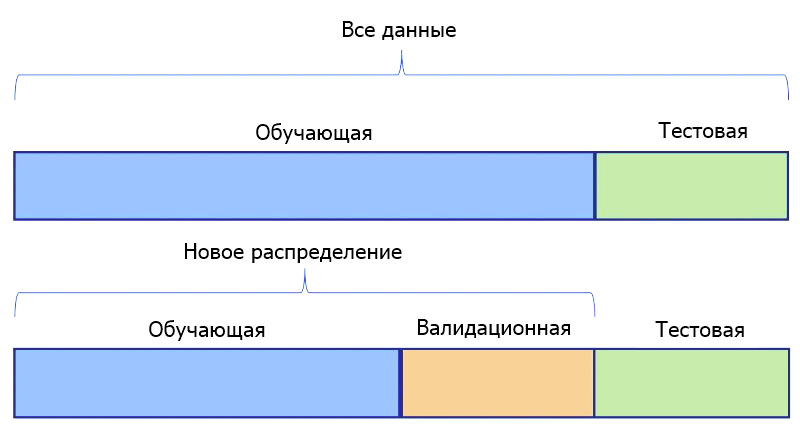
Третье соображение относится к проверочным данным (выборке валидации). Есть ли смысл для нашей задачи иметь только один тестовый датасет. Или мы должны подготовить два таких набора — один для проверки наших моделей во время их точной настройки, а еще один — в качестве окончательного датасета для сравнения моделей и выбора лучшей.
Если мы определим 2 таких набора, это будет означать, что одна выборка, будет храниться до тех пор, пока все предположения не будут проверены, все гиперпараметры не настроены, а все модели обучены для достижения максимальной производительности. Затем она будет показана моделям только один раз в качестве последнего шага в наших экспериментах.
Если вы хотите использовать датасеты для тестирования и валидации, создать их с помощью train_test_split легко. Для этого мы разделяем весь набор данных один раз для выделения обучающей выборки. Затем еще раз, чтобы разбить оставшиеся данные на датасеты для тестирования и валидации.
Ниже, используя набор данных digits, мы разделяем 70% для обучения и временно назначаем остаток для тестирования. Не забывайте применять методы, описанные выше.
from sklearn.datasets import load_digits digits = load_digits() X, y = digits.data, digits.target X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42, stratify=y) print(f"Количество строк в y_train по классам: ") print(f"Количество строк в y_test по классам: ")Количество строк в y_train по классам: [124 127 124 128 127 127 127 125 122 126] Количество строк в y_test по классам: [54 55 53 55 54 55 54 54 52 54]Обратите внимание на стратифицированные классы в полученных наборах. Затем мы повторно делим тестовый датасет.
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test, train_size=0.5, random_state=42, stratify=y_test) print(f"Количество строк в y_test по классам: ") print(f"Количество строк в y_val по классам: ")Количество строк в y_test по классам: [27 27 27 27 27 28 27 27 26 27] Количество строк в y_val по классам: [27 28 26 28 27 27 27 27 26 27]Обратите внимание на стратификацию классов по всем наборам данных, которая является оптимальной.
Теперь вы готовы обучать, проверять и тестировать столько моделей машинного обучения, сколько вы сочтете нужным для ваших данных.Еще один совет: вы можете подумать об использовании перекрестной валидации вместо простой стратегии обучение/тестирование или обучение/валидация/тестирование. Мы рассмотрим вопросы кросс-валидации в следующий раз.
10.3. Контроль случайности ¶
Некоторые объекты scikit-learn по своей природе случайны. Обычно это оценщики (например RandomForestClassifier ) и разделители перекрестной проверки (например KFold ). Случайность этих объектов контролируется с помощью их random_state параметра, как описано в Глоссарии . В этом разделе подробно рассматривается запись в глоссарии, и описываются передовые методы и распространенные ошибки, связанные с этим тонким параметром.
Для оптимальной надежности кросс-валидации (CV) результатов, проходят RandomState экземпляры при создании оценок, либо оставить random_state в None . Передача целых чисел в разделители CV обычно является самым безопасным и предпочтительным вариантом; передача RandomState экземпляров разделителям иногда может быть полезна для достижения очень конкретных вариантов использования. И для оценщиков, и для разделителей передача целого числа по сравнению с передачей экземпляра (или None ) приводит к тонким, но значительным различиям, особенно для процедур CV. Эти различия важно понимать при сообщении результатов.
Чтобы получить воспроизводимые результаты при выполнении, удалите любое использование random_state=None .10.3.1. Использование None или RandomState экземпляры, а также повторные вызовы fit и split
Параметр random_state определяет , будет ли несколько вызовов fit (для оценок) или split (для CV разветвителей) будет производить те же результаты, в соответствии с этими правилами:
- Если передано целое число, вызов fit или split несколько раз всегда дает одни и те же результаты.
- Если None или RandomState экземпляр передается: fit и split будет давать разные результаты каждый раз, когда они вызываются, а последовательность вызовов исследует все источники энтропии. None — значение по умолчанию для всех random_state параметров.
Здесь мы проиллюстрируем эти правила как для оценщиков, так и для CV-сплиттеров.
Поскольку передача random_state=None эквивалентна передаче глобального RandomState экземпляра из numpy ( random_state=np.random.mtrand._rand ), мы не будем None здесь явно упоминать . Все, что относится к экземплярам, также применимо к использованию None .
10.3.1.1. Оценщики
Передача экземпляров означает, что fit многократный вызов не даст одинаковых результатов, даже если оценщик приспособлен к одним и тем же данным и с одними и теми же гиперпараметрами:
>>> from sklearn.linear_model import SGDClassifier >>> from sklearn.datasets import make_classification >>> import numpy as np >>> rng = np.random.RandomState(0) >>> X, y = make_classification(n_features=5, random_state=rng) >>> sgd = SGDClassifier(random_state=rng) >>> sgd.fit(X, y).coef_ array([[ 8.85418642, 4.79084103, -3.13077794, 8.11915045, -0.56479934]]) >>> sgd.fit(X, y).coef_ array([[ 6.70814003, 5.25291366, -7.55212743, 5.18197458, 1.37845099]])
Из приведенного выше фрагмента видно, что многократные вызовы sgd.fit привели к созданию разных моделей, даже если данные были одинаковыми. Это связано с тем, что генератор случайных чисел (RNG) оценщика потребляется (т. Е. Изменяется) при fit вызове, и этот измененный RNG будет использоваться в последующих вызовах fit . Кроме того, rng объект является общим для всех объектов, которые его используют, и, как следствие, эти объекты становятся в некоторой степени взаимозависимыми. Например, два оценщика, которые используют один и тот же RandomState экземпляр, будут влиять друг на друга, как мы увидим позже, когда будем обсуждать клонирование. Об этом важно помнить при отладке.
Если бы мы передали целое число в random_state параметр объекта RandomForestClassifier , мы бы получили одни и те же модели и, следовательно, каждый раз одни и те же оценки. Когда мы передаем целое число, во всех вызовах используется один и тот же RNG fit . Что внутри происходит, так это то, что даже если RNG потребляется при fit вызове, он всегда сбрасывается в исходное состояние в начале fit .
10.3.1.2. CV разветвители
Рандомизированные разделители CV имеют аналогичное поведение при RandomState передаче экземпляра; вызов split несколько раз дает разные разбиения данных:
>>> from sklearn.model_selection import KFold >>> import numpy as np >>> X = y = np.arange(10) >>> rng = np.random.RandomState(0) >>> cv = KFold(n_splits=2, shuffle=True, random_state=rng) >>> for train, test in cv.split(X, y): . print(train, test) [0 3 5 6 7] [1 2 4 8 9] [1 2 4 8 9] [0 3 5 6 7] >>> for train, test in cv.split(X, y): . print(train, test) [0 4 6 7 8] [1 2 3 5 9] [1 2 3 5 9] [0 4 6 7 8]
Мы видим, что расколы отличаются от второго раза split . Это может привести к неожиданным результатам, если вы сравните производительность нескольких оценщиков путем многократного вызова split , как мы увидим в следующем разделе.
10.3.2. Распространенные подводные камни и тонкости
Хотя правила, управляющие random_state параметром, кажутся простыми, они, тем не менее, имеют некоторые тонкие последствия. В некоторых случаях это может даже привести к неверным выводам.
10.3.2.1. Оценщики
Различные типы random_state приводят к разным процедурам перекрестной проверки
В зависимости от типа random_state параметра оценщики будут вести себя по-разному, особенно в процедурах перекрестной проверки. Рассмотрим следующий фрагмент:
>>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import cross_val_score >>> import numpy as np >>> X, y = make_classification(random_state=0) >>> rf_123 = RandomForestClassifier(random_state=123) >>> cross_val_score(rf_123, X, y) array([0.85, 0.95, 0.95, 0.9 , 0.9 ]) >>> rf_inst = RandomForestClassifier(random_state=np.random.RandomState(0)) >>> cross_val_score(rf_inst, X, y) array([0.9 , 0.95, 0.95, 0.9 , 0.9 ])
Мы видим, что результаты перекрестной проверки rf_123 и rf_inst отличаются, как и следовало ожидать, поскольку мы не передали один и тот же random_state параметр. Однако разница между этими оценками более тонкая, чем кажется, и процедуры перекрестной проверки, которые выполняли cross_val_score , значительно различаются в каждом случае :
- Поскольку rf_123 было передано целое число, каждый вызов fit использует один и тот же RNG: это означает, что все случайные характеристики случайного оценщика леса будут одинаковыми для каждого из 5 кратностей процедуры CV. В частности, (случайно выбранное) подмножество функций оценщика будет одинаковым для всех складок.
- Поскольку rf_inst был передан RandomState экземпляр, каждый вызов fit начинается с другого RNG. В результате случайный набор функций будет отличаться для каждой складки.
Хотя наличие постоянного оценщика RNG по сгибам не является неправильным по своей сути, мы обычно хотим, чтобы результаты CV были устойчивыми по отношению к случайности оценщика. В результате передача экземпляра вместо целого числа может быть предпочтительнее, поскольку это позволит оценивающему RNG изменяться для каждой кратности.
Здесь cross_val_score будет использоваться нерандомизированный разделитель CV (по умолчанию), поэтому обе оценки будут оцениваться на одних и тех же разделениях. Этот раздел не о вариативности шпагатов. Кроме того, make_classification для нашей цели иллюстрации не имеет значения , передаем ли мы целое число или экземпляр : важно то, что мы передаем RandomForestClassifier оценщику.
Клонирование
Еще один тонкий побочный эффект передачи RandomState экземпляров — это то, как clone будет работать:
>>> from sklearn import clone >>> from sklearn.ensemble import RandomForestClassifier >>> import numpy as np >>> rng = np.random.RandomState(0) >>> a = RandomForestClassifier(random_state=rng) >>> b = clone(a)
Поскольку RandomState экземпляр был передан a , a и b они не являются клонами в строгом смысле, а скорее клонами в статистическом смысле: a и b все равно будут разными моделями, даже при обращении к fit(X, y) одним и тем же данным. Кроме того, a и b будут влиять друг на друга, так как они одни и те же внутренние RNG: вызов будет потреблять b RNG, и вызов b.fit будет потреблять a RNG, так как они одинаковы. Этот бит истинен для любых оценщиков, которые совместно используют параметр random_state; это не относится к клонам.
Если бы было передано целое число, a и b были бы точными клонами, и они не влияли бы друг на друга.
10.3.2.2. CV разветвители
При передаче RandomState экземпляра разделители CV дают разные разделения каждый раз при split вызове. При сравнении различных оценщиков это может привести к переоценке дисперсии разницы в производительности между оценщиками:
>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import KFold >>> from sklearn.model_selection import cross_val_score >>> import numpy as np >>> rng = np.random.RandomState(0) >>> X, y = make_classification(random_state=rng) >>> cv = KFold(shuffle=True, random_state=rng) >>> lda = LinearDiscriminantAnalysis() >>> nb = GaussianNB() >>> for est in (lda, nb): . print(cross_val_score(est, X, y, cv=cv)) [0.8 0.75 0.75 0.7 0.85] [0.85 0.95 0.95 0.85 0.95]
Непосредственное сравнение производительности LinearDiscriminantAnalysis оценщика и GaussianNB оценщика в каждом сгибе было бы ошибкой: разбиения, на которых оцениваются оценщики, разные . Действительно, cross_val_score будет внутренне вызывать один и cv.split тот же KFold экземпляр, но разбиение будет каждый раз другим. Это также верно для любого инструмента, который выполняет выбор модели с помощью перекрестной проверки, например, GridSearchCV and RandomizedSearchCV : scores не сопоставимы по размеру при разных вызовах search.fit , поскольку cv.split они вызывались бы несколько раз. Однако в рамках одного вызова search.fit сравнение сгиба-к-сгибу возможно, так как средство оценки поиска вызывает только cv.split один раз.
Для получения сравнимых сгиба до раза результатов во всех сценариях, следует передать целое число в CV разветвителя: cv = KFold(shuffle=True, random_state=0)
Несмотря на то, что сравнение кратных значений с RandomState экземплярами не рекомендуется , однако можно ожидать, что средние баллы позволят сделать вывод о том, лучше ли один оценщик, чем другой, при условии, что используется достаточное количество складок и данных.
В этом примере важно то, что было передано KFold . Передаем ли мы RandomState экземпляр или целое число, make_classification не имеет отношения к нашей цели иллюстрации. Кроме того, нет LinearDiscriminantAnalysis и GaussianNB рандомизированных оценок.
10.3.3. Общие рекомендации
10.3.3.1. Получение воспроизводимых результатов при многократном выполнении
Чтобы получить воспроизводимые (т. Е. Постоянные) результаты при выполнении нескольких программ , нам нужно удалить все варианты использования random_state=None , что является значением по умолчанию. Рекомендуемый способ — объявить rng переменную в верхней части программы и передать ее любому объекту, принимающему random_state параметр:
>>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> import numpy as np >>> rng = np.random.RandomState(0) >>> X, y = make_classification(random_state=rng) >>> rf = RandomForestClassifier(random_state=rng) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, . random_state=rng) >>> rf.fit(X_train, y_train).score(X_test, y_test) 0.84
Теперь нам гарантируется, что результат этого скрипта всегда будет 0,84, независимо от того, сколько раз мы его запускали. Изменение глобальной rng переменной на другое значение должно повлиять на результаты, как и ожидалось.
Также можно объявить rng переменную как целое число. Однако это может привести к менее надежным результатам перекрестной проверки, как мы увидим в следующем разделе.
Мы не рекомендуем устанавливать глобальное numpy начальное число путем вызова np.random.seed(0) . Смотрите здесь для обсуждения.
10.3.3.2. Надежность результатов перекрестной проверки
Когда мы оцениваем производительность рандомизированного оценщика с помощью перекрестной проверки, мы хотим убедиться, что оценщик может давать точные прогнозы для новых данных, но мы также хотим убедиться, что оценщик устойчив по отношению к своей случайной инициализации. Например, мы хотели бы, чтобы инициализация случайных весов SGDCLassifier была стабильно хорошей для всех сверток: в противном случае, когда мы обучаем эту оценку новым данным, нам может не повезти, и случайная инициализация может привести к плохой производительности. Точно так же мы хотим, чтобы случайный лес был устойчивым по отношению к набору случайно выбранных функций, которые будет использовать каждое дерево.
По этим причинам предпочтительно оценивать преформность перекрестной проверки, позволяя оценщику использовать различный RNG в каждом сгибе. Это делается путем передачи RandomState экземпляра (или None ) в инициализацию оценщика.
Когда мы передаем целое число, оценщик будет использовать один и тот же RNG для каждого сгиба: если оценщик работает хорошо (или плохо), по оценке CV, это может быть просто потому, что нам повезло (или не повезло) с этим конкретным начальным числом. Передача экземпляров приводит к более надежным результатам CV и делает более справедливым сравнение между различными алгоритмами. Это также помогает ограничить соблазн рассматривать RNG оценщика как гиперпараметр, который можно настраивать.
Независимо от того, передаем ли мы RandomState экземпляры или целые числа в разделители CV, это не влияет на надежность, если split вызывается только один раз. Когда split вызывается несколько раз, сравнение сгиба-к-сгибу больше невозможно. В результате передача целого числа в разделители CV обычно более безопасна и охватывает большинство случаев использования.
Если вы хотите помочь проекту с переводом, то можно обращаться по следующему адресу support@scikit-learn.ru
© 2007 - 2020, scikit-learn developers (BSD License).