Слишком медленный SQL-запрос с использованием UNION
Проблема в том, что команда UNION выполняется ну очень медленно ввиду того, что записей в таблицах много. Выходит, нужно всё это заменить чем-то нормальным по скорости, но придумать ничего путного так и не смог… Прошу «помощь зала» 🙂
Отслеживать
задан 29 июл 2017 в 22:09
333 1 1 серебряный знак 10 10 бронзовых знаков
Во первых стоит делать UNION ALL , он немного быстрее. Во вторых основная проблема скорее в not exists, если записей много. сделайте dt NOT IN (select dt from tab1 union all select dt from tab2 . )
29 июл 2017 в 22:26
И в третьих, любые попытки оптимизации, так же как и вопросы об оптимизации без приведенного плана выполнения бесполезны
29 июл 2017 в 22:29
NOT IN использовать нельзя. Т.к. в этом случае СУБД создаёт временную таблицу и пытается сохранить в неё все варианты значений. А это — миллионы(!) записей. Что напрочь завесит систему. Или я не прав?
29 июл 2017 в 22:32
ну это зависит от природы данных. в вопросе об этом ни слова нет. поэтому я и сказал, что заниматься оптимизацией не видя плана выполнения невозможно. А варианты разные бывают, в одних not exists быстрее, в других not in, пробовать надо. Сильно зависит от того, сколько записей в первой таблице и сколько во внутренних. Сто тысяч раз выполнять union, ради каждой отдельной записи в первой таблице то же очень плохо. А если в тех таблицах не дай дог нет индекса по полю даты. Тем более, что union без all это так же гарантированное создание временной таблицы и группировка.
29 июл 2017 в 22:39
@Mike, Извините, я не понимаю, что такое «план выполнения». Суть: В первой таблице хранятся все записи о датах. Для начала их будет примерно 3 миллиона. Все прочие таблицы ссылаются на эти данные по id. Записей в прочих таблицах (для начала) от нескольких десятков тысяч до полутора миллионов в каждой. Указанный выше запрос очистки мусора выполняется в конце основной работы случайно с малой вероятностью (примерно 1/10000).
29 июл 2017 в 22:47
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Есть только три варианта удаления. Первый — приведен Вами. Второй:
DELETE LOW_PRIORITY dt FROM dates AS dt WHERE id NOT IN ( SELECT t1.field1 FROM table1 AS t1 UNION ALL SELECT t2.filed2 FROM table2 AS t2 ) DELETE LOW_PRIORITY dt FROM dates AS dt LEFT JOIN ( SELECT t1.field1 as id FROM table1 AS t1 UNION ALL SELECT t2.filed2 FROM table2 AS t2 ) X ON dt.id=X.id WHERE X.id IS NULL Так же возможны вариации на тему вынесения выборок из таблиц tableN из union отдельно, вроде нескольких LEFT JOIN и проверки в конце нескольких условий на NULL. Или нескольких NOT IN/NOT EXISTS.
Очень помогли бы индексы на поля fileldN, наверняка они нужны не только этому запросу. Предлагаю попробовать все эти варианты, посмотреть планы выполнения по EXLAIN и решить какой лучше будет работать на ваших данных.
Использование Union вместо OR
Иногда медленные запросы можно исправить, немного изменив запрос. Один из таких примеров может быть проиллюстрирован, когда несколько значений сравниваются в предложении WHERE с помощью оператора OR или IN. Часто OR может вызывать сканирование индекса или таблицы, которая может не быть предпочтительным планом выполнения с точки зрения потребления ввода-вывода или общей скорости запросов.
Многие переменные вступают в игру, когда оптимизатор запросов создает план выполнения. Эти переменные включают в себя множество характеристик оборудования, настроек экземпляра, настроек базы данных, статистики (таблица, индекс, auto-generated), а также способ написания запроса. Здесь мы меняем способ написания запроса. Каким бы неожиданным это ни казалось, даже если два разных запроса могут возвращать одни и те же результаты, путь, по которому они идут, может быть совершенно разным в зависимости от формата запроса.
UNION vs OR
В большей части моего опыта работы с SQL Server, OR обычно менее эффективен, чем UNION. То, что обычно происходит с OR, это то, что он чаще вызывает сканирование. Это порой может быть лучший путь для некоторых случаев, и я оставлю это отдельной статье, но в целом я обнаружил, что когда затрагивается большое количество записей — это является основной причиной медлительности. Итак, давайте начнем наше сравнение.
Вот наш оператор OR:
SELECT SalesOrderID, * FROM sales.SalesOrderDetail WHERE ProductID = 750 OR ProductID = 953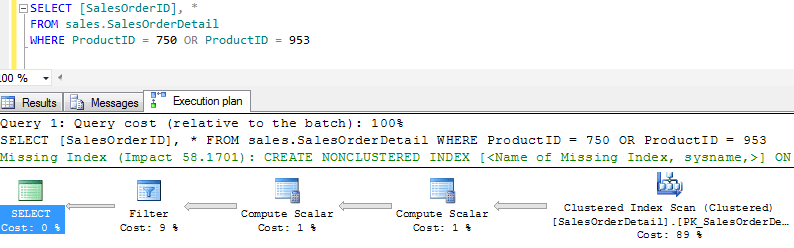
Из этого плана выполнения мы видим, что мы выполняем сканирование 121 000 строк. (Вы не можете видеть количество строк, но это так).
Теперь выполним тот же запрос, но написанный с использованием UNION вместо OR:
SELECT [SalesOrderID], * FROM sales.SalesOrderDetail WHERE ProductID = 750 UNION SELECT [SalesOrderID], * FROM sales.SalesOrderDetail WHERE ProductID = 953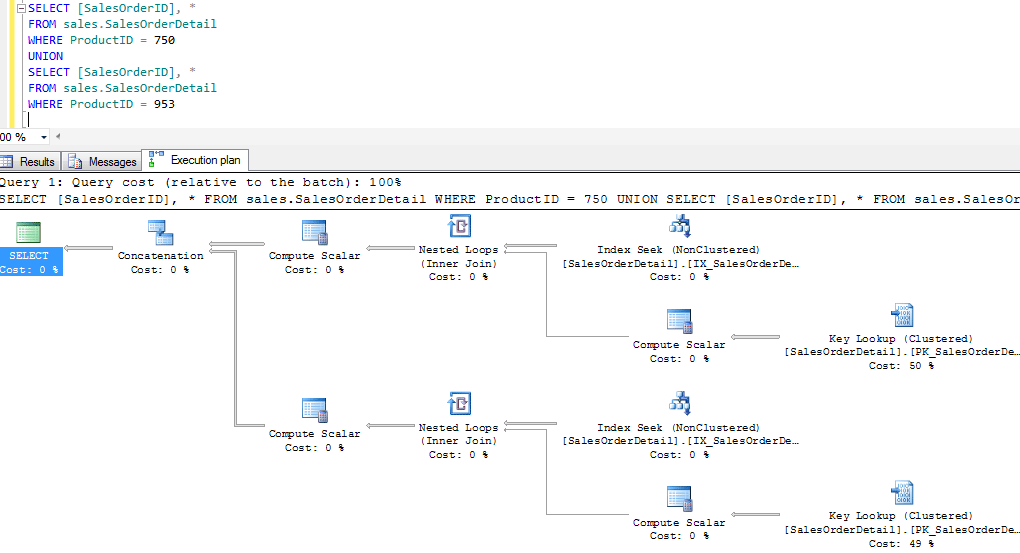
Здесь мы видим две ветви операций. Одна ветвь затрагивает 358 строк, а другая — 346 строк. Обе ветви встречаются для выполнения операции конкатенации, объединяющей оба набора результатов. У нас есть два отдельных поиска, но у нас также есть поиск ключей для получения необходимого списка SELECT. Это не было необходимо для операции сканирования, потому что мы все равно затрагивали все строки в операции сканирования, таким образом, данные были получены во время сканирования, а не после. Это связано с индексом и нужными нам строками, а не с UNION или OR. Однако я скажу, что выборка (select) также является фактором выбора поиска против сканирования (seek vs scan), но мы проигнорируем это в этой статье.
Объяснение
Почему UNION вызывает больше поисков вместо сканирований, потому что каждая операция должна удовлетворять определенному требованию селективности, чтобы претендовать на поиск. (Селективность — это уникальность конкретного фильтруемого столбца). OR происходит в одной операции, так что, когда селективность для каждого столбца объединяется и она превышает определенный процент, то сканирование считается более эффективным.
Поскольку UNION по умолчанию выполняет отдельную операцию для каждого оператора, селективность каждого столбца не объединяется, давая ему больше шансов на выполнение поиска. Теперь, поскольку UNION выполняет две операции, они должны сопоставить свои результирующие наборы, используя вышеописанную операцию конкатенации. Как правило, это не дорогостоящая операция.
Следует также отметить, что предложение OR работает так же, как оператор IN.
Надеюсь, этот совет поможет. Я считаю, что это очень ценно при работе с системами, требующими высокого параллелизма.
- SQL
- Microsoft SQL Server
Как оптимизировать MySQL UNION для высокой скорости
Есть два способа ускорить UNION в базе данных MySQL. Во-первых, используйте UNION ALL, если это вообще возможно, а во-вторых, попытайтесь снизить ваши условия.
1. UNION ALL намного быстрее, чем UNION
Как работает UNION? Представьте, что у вас есть два стола для рубашек. Таблица short_sleeve выглядит следующим образом:
blue green gray black
И long_sleeve другой, который выглядит так:
red green yellow blue
Если вы ОБЪЕДИНИТЕ эти две таблицы, сначала MySQL отсортирует объединенный набор во временную таблицу следующим образом:
black blue blue gray green green red yellow
После того, как это сделано, он может легко удалить дубликаты синего и дубликата зеленого для этого результирующего набора:
black blue gray green red yellow
Почему он это делает? UNION определяется таким образом в SQL. Дубликаты должны быть удалены, и для движка MySQL это эффективный способ их удаления. Объедините результаты, сортируйте, удаляйте дубликаты и возвращайте набор.
Запросы с помощью UNION могут быть ускорены двумя способами. Переключитесь на UNION ALL или попробуйте выдвинуть условия ORDER BY, LIMIT и WHERE внутри каждого подзапроса. Вы будете рады, что сделали!
Что если мы сделали UNION ALL? Результат будет выглядеть так:
blue green gray black red green yellow blue
Он не должен сортировать и не должен удалять дубликаты. Если вы представляете себе объединение двух 10 миллионов таблиц строк и не должны сортировать, это ускорение может быть ОГРОМНЫМ.
2. Используйте Push-down Условия для ускорения UNION в MySQL
Представьте, что в приведенном выше примере рубашки имеют дату дизайна, год выпуска. Да, мы держим этот пример очень просто, чтобы проиллюстрировать концепцию.
Вот таблица short_sleeve:
blue 2013 green 2013 green 2012 gray 2011 black 2009 black 2011
И таблица long_sleeve выглядит так:
red 2012 red 2013 green 2011 yellow 2010 blue 2011
В 2013 году дизайны могли бы объединить их так:
(SELECT type, release FROM short_sleeve) UNION (SELECT type, release FROM long_sleeve); WHERE release >=2013;
Здесь предложение WHERE работает с этой временной таблицей из 11 записей:
black 2009 black 2011 blue 2011 blue 2013 gray 2011 green 2013 green 2012 green 2011 red 2012 red 2013 yellow 2010
Но было бы намного быстрее перемещать WHERE внутри каждого подзапроса следующим образом:
(SELECT type, release FROM short_sleeve WHERE release >=2013) UNION (SELECT type, release FROM long_sleeve WHERE release >=2013);
Это будет работать на комбинированной таблице 3 записи. Быстрее сортировать и удалять дубликаты. Меньший кэш наборов результатов также лучше, обеспечивая выплату дивидендов. Вот что такое оптимизация производительности!
Помните, что многомиллионные наборы строк в каждой части этого запроса быстро проиллюстрируют оптимизацию. Мы используем очень маленькие результаты, чтобы сделать визуализацию проще.
Вы также можете использовать эту оптимизацию для ORDER BY и для условий LIMIT. Сокращая количество записей, возвращаемых КАЖДОЙ ЧАСТЬЮ СОЮЗА, вы сокращаете объем работы, которая происходит на этапе, когда они объединяются.
Если вы видите некоторые запросы UNION в своем медленном журнале запросов, я предлагаю вам попробовать эту оптимизацию и посмотреть, сможете ли вы ее настроить.
Есть два оператора объединения, union и union all. Какое\какие утверждение\утверждения ниже неверно?
Есть два оператора объединения, union и union all. Какое\какие утверждение\утверждения ниже неверно?
1)Так исторически сложилось что есть два оператора, но разницы между ними нет
2)union убирает дубли
3)union all оставляет дубли
4)union all работает быстрее при прочих равных
5)union в результате оставляет отсортированную по ключу таблицу
Лучший ответ
Утверждение 1 безусловно ошибочно.
Утверждения 2 и 3 безусловно верны.
Верность утверждений 4 и 5 зависит от особенностей конкретной СУБД: 4 скорее всего будет верно, 5 скорее всего будет ошибочно.