Создание файла с кодировкой UTF-8 C++
Хочу записать переменную типа char в файл с кодировкой UTF-8, в переменной хранятся символы кириллицы, в этом и есть вся проблема. Если я правильно понимаю, то эта переменная в кодировке ANSI, может как-то можно перевести саму переменную в UTF-8? Это бы тоже решило проблему. У меня получилось создать «UTF-8 со спецификацией», но это не подходит. Работаю в Qt.
Отслеживать
166 6 6 бронзовых знаков
задан 15 июл 2021 в 9:18
1 1 1 бронзовый знак
кириллица в uft-8 занимает 2 байта, то есть, нужно два char. В один не влезет никак.
15 июл 2021 в 9:31
но если у Вас Qt — там относительно легко преобразовать с cp1251 в utf-8
15 июл 2021 в 9:46
Пишите и читайте бинарные файлы, там кодирока будет as is (как есть). Байты кирилицы прийдётся преобразовать в utf-8
16 июл 2021 в 11:19
Скорее всего вы работаете в винде?
16 июл 2021 в 11:27
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
С кодировками желательно хорошенько разобраться. Есть нюансы, так, по умолчанию:
- Qt 5 сохраняет текстовые файлы в локальной кодировке. И, соответственно, при считывании считается, что используется локальная кодировка.
- Qt 6 сохраняет текстовые файлы в кодировке utf-8. И, соответственно, при считывании текстовые файлы должны быть в кодировке utf-8.
Раньше в книжках советовали сохранять исходные файлы в кодировке utf-8, а в коде использовать функцию QObject::trUtf8() . В Qt 6 больше этой функции нету, а исходные файлы обязаны быть сохранеными в кодировке utf-8. Также есть функция QString::fromUtf8() .
Также важно понимать, что в классах QChar И QString используется кодировка utf-16. Qt сам, под капотом, преобразовывает тексты в данную кодировку и обратно.
Если же нужно получить набор байтов в кодировке utf-8, есть функция QString::toUtf8() :
QString myString("foo/bar"); QByteArray inUtf8 = myString.toUtf8(); const char *data = inUtf8.constData(); И как создавать сам текстовый файл: unicode — Create UTF-8 file in Qt — Stack Overflow. Актуально для Qt 5, в Qt 6 нет необходимости дополнительно устанавливать кодировку.
Учебники. Программирование для начинающих.
Programm.ws — это сайт, на котором вы можете почитать литературу по языкам программирования , а так-же посмотреть примеры работающих программ на С++, ассемблере, паскале и много другого..
Программирование — в обычном понимании, это процесс создания компьютерных программ.
В узком смысле (так называемое кодирование) под программированием понимается написание инструкций — программ — на конкретном языке программирования (часто по уже имеющемуся алгоритму — плану, методу решения поставленной задачи). Соответственно, люди, которые этим занимаются, называются программистами (на профессиональном жаргоне — кодерами), а те, кто разрабатывает алгоритмы — алгоритмистами, специалистами предметной области, математиками.
В более широком смысле под программированием понимают весь спектр деятельности, связанный с созданием и поддержанием в рабочем состоянии программ — программного обеспечения ЭВМ. Более точен современный термин — «программная инженерия» (также иначе «инженерия ПО»). Сюда входят анализ и постановка задачи, проектирование программы, построение алгоритмов, разработка структур данных, написание текстов программ, отладка и тестирование программы (испытания программы), документирование, настройка (конфигурирование), доработка и сопровождение.
Cамоучитель по Java
Глава 18. Потоки ввода/вывода
Кодировка UTF-8
Запись потока в байтовой кодировке вызывает трудности с использованием национальных символов, запись потока в Unicode увеличивает длину потока в два раза. Кодировка UTF-8 (Universal Transfer Format) является компромиссом. Символ в этой кодировке записывается одним, двумя или тремя байтами.
Символы Unicode из диапазона ‘\u0000′ —’\u007F’, в котором лежит английский алфавит, записываются одним байтом, старший байт просто отбрасывается.
Символы Unicode из диапазона ‘\u0080′ —’\u07FF’, в котором лежат наиболее распространенные символы национальных алфавитов, записываются двумя байтами следующим образом: символ Unicode с кодировкой 00000хххххуууууу записывается как 110ххххх10уууууу.
Остальные символы Unicode из диапазона ‘\u0800′ —’\UFFFF’ записываются тремя байтами по следующему правилу: символ Unicode с кодировкой xxxxyyyyyyzzzzzz записывается как 1110xxxx10yyyyyy10zzzzzz.
Такой странный способ распределения битов позволяет по первым битам кода узнать, сколько байтов составляет код символа, и правильно отсчитывать символы в потоке.
Так вот, метод writeUTF( string s) сначала записывает в поток в первые два байта потока длину строки s в кодировке UTF-8, а затем символы строки в этой кодировке. Читать эту запись потом следует парным методом readUTF() класса DatalnputStream.
Класс DatalnputStream преобразует входной поток байтов типа InputStream, составляющих данные простых типов Java, в данные этого типа. Такой поток, как правило, создается методами класса DataOutputstream. Данные из этого потока можно прочитать методами readBoolean(), readByte(), readShort(), readChar(), readlnt(), readLong(), readFloat(), readDouble(), возвращающими данные соответствующего типа.
Кроме того, методы readUnsignedByteO H readUnsignedShort () возвращают целое типа int, в котором старшие три или два байта нулевые, а младшие один или два байта заполнены байтами из входного потока.
Метод readUTF(), двойственный методу writeUTF(), возвращает строку типа string, полученную из потока, записанного методом writeUTF ().
Еще один, статический, метод readUTF(Datainput in) делает то же самое со входным потоком in, записанным в кодировке UTF-8. Этот метод можно применять, не создавая объект класса DatalnputStream.
Программа в листинге 18.4 записывает в файл fib.txt числа Фибоначчи, а затем читает этот файл и выводит его содержимое на консоль. Для контроля записываемые в файл числа тоже выводятся на консоль. На рис. 1S.5 рока-зан вывод этой программы.
Листинг 18.4. Ввод/вывод данных
public static void main(String[] args) throws IOException
DataOutputstream dos = new DataOutputstream (
int a = 1, b = 1, с = 1;
System.out.println(«End of file»);
Обратите внимание на то, что попытка чтения за концом файла выбрасывает исключение класса IOException, его обработка заключается в закрытии файла и окончании программы.
Рис. 18.5. Ввод и вывод данных
Использование UTF-8 в HTTP заголовках

Как известно, HTTP 1.1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266, для «Content-Disposition» и преобразуйте текст в латиницу (транслит) в остальных случаях.
Небольшая вводная в кодировки
В статье упоминаются и используются кодировки US-ASCII (часто именуемую просто ASCII), ISO-8859-1 и UTF-8. Это небольшая вводная в эти кодировки. Раздел предназначен для разработчиков, которые редко или совсем не работают с кодировками и успели подзабыть их. Если вы к ним не относитесь, то смело пропускайте раздел.
ASCII — это простая кодировка, содержащая 128 символов и включающая весь английский алфавит, цифры, знаки препинания и служебные символы.

7 бит достаточно, чтобы представить любой ASCII символ. Слово «test» будет представлено в HEX представлении, как 0x74 0x65 0x73 0x74. Первый бит у всех символов всегда 0, поскольку символов в кодировке 128, а байт предоставляет 2^8 = 256 вариантов.
ISO-8859-1 — кодировка, предназначенная для западноевропейских языков. Содержит французскую диакритику, немецкие умляуты и т.д.

Кодировка содержит 256 символов и, таким образом, может быть представлена одним байтом. Первая половина (128 символов) полностью совпадает с ASCII. Таким образом, если первый бит = 0, то это обычный ASCII символ. Если 1, то это символ, специфичный для ISO-8859-1.
UTF-8 — одна из самых известных кодировок наравне с ASCII. Способна кодировать 1.112.064 символов. Размер каждого символа варьируется от 1-го до 4-х байт (раньше допускались значения до 6 байт).


Программа, работающая с этой кодировкой, определяет по первым битам, как много байтов входит в символ. Если октет начинается с 0, то символ представлен одним байтом. 110 — два байта, 1110 — три байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 символов полностью соответствуют ASCII. Поэтому тексты, использующие только ASCII символы, будут абсолютно идентичны в бинарном представлении, вне зависимости от того, использовалась ли для кодирования US-ASCII, ISO-8859-1 или UTF-8.
Использование UTF-8 в теле сообщения
Прежде чем перейти к заголовкам, давайте быстро взглянем, как использовать UTF-8 в теле сообщений. Для этого используется заголовок «Content-Type».

Если «Content-Type» не задан, то браузер должен обрабатывать сообщения, как будто они написаны в ISO-8859-1. Браузер не должен пытаться отгадать кодировку и, тем более, игнорировать «Content-Type». Но, что реально отобразится в ситуации, когда «Content-Type» не передан, зависит от реализации браузера. Например, Firefox сделает согласно спецификации и прочитает сообщение, будто оно было закодировано в ISO-8859-1. Google Chrome, напротив, будет использовать кодировку операционной системы, которая для многих российских пользователей равна Windows-1251. В любом случае, если сообщение было в UTF-8, то оно будет отображено некорректно.

Проставляем UTF-8 сообщение в значение заголовка
С телом сообщения все достаточно просто. Тело сообщения всегда следует после заголовков, поэтому здесь не возникает технических проблем. Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Что будет, если просто взять и записать UTF-8 значение в значение заголовка? Мы видели, что такой трюк с телом сообщения приведет к тому, что значение будет просто прочитано в ISO-8859-1. Логично было бы предположить, что то же самое произойдет с заголовком. Но это не так. Фактически, во многих, если не в большинстве, случаях такое решение будет работать. Сюда включаются старые айфончики, IE11, Firefox, Google Chrome. Единственным из находящихся у меня под рукой браузеров, когда я писал эту статью, который не захотел работать с таким заголовком, является Edge.

Такое поведение не зафиксировано в спецификациях. Возможно, разработчики браузеров решили облегчить жизнь разработчиков и автоматически определять, что в заголовках сообщение закодировано в UTF-8. В общем-то, это не является такой сложной задачей. Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Нет ли в этом случае пересечения с ISO-8859-1? На самом деле, практически нет. Возьмем для примера UTF-8 символ из 2-х октетов (русские буквы представлены двумя октетами). Символ в бинарном представлении будет иметь вид: 110xxxxx 10xxxxxx. В HEX представлении: [0xC0-0x6F] [0x80-0xBF]. В ISO-8859-1 этими символами едва ли можно закодировать что-то, несущее смысловую нагрузку. Поэтому риск того, что браузер неправильно расшифрует сообщение, очень мал.
Однако, при попытке использовать этот способ можно столкнуться с техническими проблемами: ваш веб-сервер или фреймворк может просто не разрешить записывать UTF-8 символы в значение заголовка. Например, Apache Tomcat вместо всех UTF-8 символов проставляет 0x3F (вопросительный знак). Разумеется, это ограничение можно обойти, но, если само приложение бьет по рукам и не дает что-то сделать, то, возможно, вам и не нужно это делать.
Но, независимо от того, разрешает ли вам ваш фреймворк или сервер записать UTF-8 сообщения в заголовок или нет, я не рекомендую этого делать. Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Транслит
Я думаю, что использовать транслит — eto bolee horoshee reshenie. Многие крупные популярные русские ресурсы не брезгуют использовать транслит в названиях файлов. Это гарантированное решение, которое не сломается с выпуском новых браузеров и которое не надо тестировать отдельно на каждой платформе. Хотя, разумеется, надо подумать, как преобразовывать весь спектр возможных символов, что может быть не совсем тривиально. Например, если приложение рассчитано на российскую аудиторию, то в имя файла могут попасть татарские буквы ә и ң, которые надо как-то обработать, а не просто заменять на «?».
RFC 2047
Как я уже упомянул, томкат не позволил мне проставить UTF-8 в заголовке сообщения. Отражена ли эта особенность поведения в Java docs для сервлетов? Да, отражена:
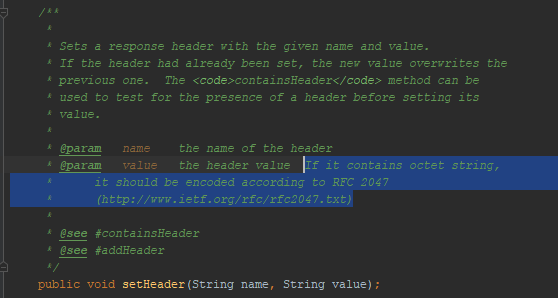
Упоминается RFC 2047. Я пробовал кодировать сообщения, используя этот формат, — браузер меня не понял. Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
RFC 6266
В тикете, ссылка на который содержится в предыдущем разделе, есть упоминания, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать UTF-8 значения в названии скачиваемых файлов: RFC 6266. На мой взгляд, это самое правильно решение на сегодняшний день. Многие популярные интернет ресурсы используют его. Мы в CUBA Platform также используем именно этот RFC для генерации «Content-Disposition».
RFC 6266 — это спецификация, описывающая использование “Content-Disposition” заголовка. Сам способ кодировки подробно описан в другой спецификации — RFC 8187.

Параметр “filename” содержит название файла в ASCII, “filename*” — в любой необходимой кодировке. При наличии обоих атрибутов “filename” игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Совсем старые браузеры, напротив, игнорируют “filename*”.
При использовании данного способа кодирования в параметре сначала указывается кодировка, после » идет закодированное значение. Видимые символы из ASCII кодирования не требуют. Остальные символы просто пишутся в hex представлении, со стоящим «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Да, можно поместить в заголовок параметр с * префиксом, и это, возможно, будет даже работать для некоторых браузеров, но спецификация предписывает не делать так.
В каждом случае, где в заголовках поддерживается UTF-8, на настоящий момент есть явное упоминание об этом в релевантном RFC. Помимо «Content-Disposition» данная кодировка используется, например, в Web Linking и Digest Access Authentication.
Следует учесть, что стандарты в этой области постоянно меняются. Использование описанной выше кодировки в HTTP было предложено лишь в 2010. Использование данной кодировки именно в «Content-Disposition» было зафиксировано в стандарте в 2011. Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
UTF-8 — что это и зачем нужна кодировка символов
Машины и люди говорят «на разных языках», однако пользователи видят на экране компьютера понятный им текст, даже если в памяти устройства он хранится в виде чисел. При создании веб-сайта разработчику необходимо помнить, что возможность его использовать должна быть не только у сервера, но и у конечного пользователя. Для преобразования числового представления информации в ее символьный вид используют кодировки. Долгое время разработчики использовали разные схемы для трансформации текста, и если на другом устройстве работала иная кодировка, часть информации не могла быть распознана и терялась. Ситуация исправилась с появлением Юникода. В нашем материале отвечаем на вопросы: UTF-8 — что это? Для чего служит? Какие преимущества и недостатки имеет стандарт?
Что такое UTF-8
UTF-8 (Unicode Transformation Format, 8-bit) — это система кодирования, работающая по стандарту Unicode. В библиотеке Юникода хранится более миллиона символов. Каждому из них присваивается уникальный код — кодовая точка. Например, для «!» кодовой точкой будет U+0021. UTF-8 преобразовывает символы Unicode в компьютерный текст — двоичные строки. Кроме того, кодировка работает и в обратную сторону: от двоичных строк к символам.

UTF-8 входит в семейство кодировок Unicode, каждая из которых уникальна. Особенность UTF-8 заключается в том, что она представляет символы в однобайтовых единицах. Один байт содержит в самом простом виде восемь бит информации, что нашло отражение в названии кодировки.
Для чего нужна кодировка символов
Компьютеры обрабатывают информацию в двоичной системе. Чтобы разобраться в текстовом сообщении, им необходимо обработать последовательность нулей и единиц. Например, английская литера А — это 01000001. Человеку для понимания текста этого недостаточно, он воспринимает данные, записанные с помощью букв, цифр и других символов, кроме того ему потребуется знание языка, на котором написано сообщение. Чтобы текст, передаваемый компьютером, стал доступен для пользователя, необходимо преобразовать его числовое представление в символьное. Инструментом для трансформации являются кодировки, которые содержат набор правил по преобразованию одного способа представления информации в другой.
Компьютер говорит на языке битов и байтов. Информация в двоичной системе измеряется с помощью битов. Если объем данных достигает 8 битов, то для удобства подсчетов используют большую единицу измерения — байт, далее следуют килобайты, мега- и гигабайты. Каждый символ текста записывается в компьютерной системе в виде строки битов.
Человек говорит на языке символов. Одним из первых наиболее универсальных стандартов кодирования является ASCII. Он имеет библиотеки, в которых систематизированы элементы двух языков — байтового и символьного. Буквам, знакам пунктуации, цифрам присваиваются индивидуальные числовые коды. Например, литере «B» в верхнем регистре по стандарту кодирования ASCII присваивается код «066». Затем данное обозначение соотносится с двоичной системой: «066» — это 01000010 при записи в нулях и единицах. В результате каждому идентификатору принадлежит свой символ и его байтовый аналог.
Стандарт ASCII содержит данные о самых востребованных символах и работает для передачи текста, написанного латинскими буквами. Однако пользователи веб-ресурсов, приложений, программного обеспечения и других ИТ-продуктов рассредоточены по всему миру. Поэтому для кодирования всех языков человечества и вообще любого символа, который когда-либо использовался, включая эмотиконы, появился стандарт с более широкими возможностями по хранению символов и соответствующих им кодов — Unicode. Его понимают большинство компьютеров на планете и носители основных мировых языков. Юникод хранит результаты преобразования информации, выполненного через систему кодирования UTF-8, UTF-16 или UTF-32.
Преимущества и недостатки
Юникод — это набор символов, взятых из всех языков мира, глифов и эмодзи. Семейство кодировок UTF определяет, как символ будет представлен в двоичной системе. UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде.
Языки программирования (ЯП) по-разному поддерживают и используют кодировки. Иногда они могут искажать Unicode. Недостатки Юникода для разных ЯП и программ:
- PHP. Данный язык программирования поддерживает 256 символов, то есть воспринимает 1 символ в строке за 1 байт информации. Так происходит, даже если символ в строке весит больше одного байта. Например, смайл может весить четыре байта, а для PHP все равно один. Однако это можно исправить, настроив многобайтовые функции. Тогда при подсчете длины строки PHP будет обращаться к памяти, а не считать символ за байт.
- JavaScript. Работает с кодировкой UTF-16. Сложные символы требуют две кодовых точки для ссылки.
- MySQL. Система управления базами данных не поддерживает UTF-8 в его стандартном виде. MySQL недостаточно 24 битов, чтобы представить один символ. СУБД поддерживает расширенную версию кодировки — UTF-8mb4.
Максимальный потенциал
С помощью UTF-8 можно записать код любой длины. Однако, для того чтобы работа алгоритма была эффективной и надежной, лучше ограничить размер кода. Unicode 6.х является действующим стандартом и предполагает использование кода до четырех байт в UTF-8.
Сравнение UTF-8 и UTF-16
UTF-8 и UTF-16 — две самые широко используемые кодировки в стандарте Unicode. Они обе обладают переменной длинной кодирования. Один символ в них может быть представлен разным количеством байт. В Юникоде все данные хранятся в таблице и отсортированы по количеству байт, которое они имеют в двоичной системе. В начале стандарта символы могут занимать всего 1 байт, поэтому и UTF-8 зашифрует их с помощью 1 байта. Если данные требуют двух байтов, то и в UTF-8 они будут весить два байта. UTF-8 кодирует символ в двоичную строку от одного до четырех байтов. Так, для шифрования латинских символов достаточно одного байта, а для кириллических — двух. Для данных языков максимального потенциала UTF-8 достаточно.
UTF-16 оперирует данными из двух и четырех байт. Кодировка подходит для восточных языков.
Заключение
UTF-8 является самым распространенным методом кодирования в Сети, поскольку позволяет хранить текст, содержащий любой символ. Он способен перевести символы, содержащиеся в библиотеке Юникода, в байты, а затем выполнить обратный процесс.