Proxmox: Openvswitch и сущность VLAN для него
Если мы работаем с Proxmox и нам нужно иметь дело с тегированным трафиком, рекомендуется использовать OVS.
Т.к. в случае с классическим Linux Bridge (не рассматриваем VLAN Aware Bridge) мы имеем расклад Bridge per VLAN — сколько VLAN’ов, столько и бриджей.
Громоздко, неудобно и легко запутаться, когда много VLAN’ов.
OVS же реализует подход Port per VLAN один свитч, куча портов и каждого порта свой VLAN (упрощенно).
Дальше OVS занимается маршрутизацией кадров на основе тегов.
Теперь мой вопрос: зачем VLAN’у может потребоваться назначать IP?
Я представлял VLAN просто как порт на свитче.
Но зачем нам доступ к самому VLAN’у (по ссылке на официальную доку)?
Какова его роль, сущность в данном случае?
Или VLAN в данном случае это аналог бриджа-шлюза, чтобы получить доступ к VM в подсети?
Жду примеров из практики.
Twissel ★★★★★
04.05.20 11:42:46 MSK

Или VLAN в данном случае это аналог бриджа-шлюза, чтобы получить доступ к VM в подсети?
Сразу скажу — я с Proxmox не работал, сужу только по работе с openvswitch в контексте libvirt/opennebula.
Ну в общем-то да, если трафик из vlan планируется выпускать наружу, то логично, что кто-то должен всё это хозяйство маршрутизировать(и возможно nat-ить). Это может быть как что-то внешнее, либо один из гипервайзоров(хотя я считаю это не очень хорошей практикой, особенно если гипервайзоров несколько — чем меньше на них будет постороннего говна, тем лучше) или одна из виртуальных машин на этих гипервайзорах.
И вот в случае когда это один из гипервайзоров тебе и потребуется как-то вытащить из openvswitch интерфейс(в терминологии openvswitch он называется ЕНМИП internal interface) внутрь гипервайзора.
Плюс если у тебя в сервер идет несколько интерфейсов, объединенных в bonding(через тот же openvswitch) и ты не хочешь делать классическое разделение отдельными сетевухами на «управляющий интерфейс/служебная сеть кластера/трафик виртуальных машин», то как минимум управляющий интерфейс тебе придется в качестве internal делать(по умолчанию в openvswitch такой интерфейс есть и назван он аналогично имени свича) — иначе ты до сервера тупо не достучишься.
Pinkbyte ★★★★★
( 04.05.20 12:20:14 MSK )
Последнее исправление: Pinkbyte 04.05.20 12:25:23 MSK (всего исправлений: 4)
Разбираюсь с сабжем чисто для самообразования. с сабжем чисто для самообразования. Теперь мой вопрос: зачем VLAN’у может потребоваться назначать IP?
там же в доке написано.
VLANs Host Interfaces
In order for the host (e.g. proxmox host, not VMs themselves!) to utilize a vlan within the bridge, you must create OVSIntPorts. These split out a virtual interface in the specified vlan that you can assign an ip address to (or use DHCP). You need to set ovs_options tag=$VLAN to let OVS know what vlan the interface should be a part of. In the switch world, this is commonly referred to as an RVI (Routed Virtual Interface), or IRB (Integrated Routing and Bridging) interface.
ukr_unix_user ★★★★
( 04.05.20 12:43:31 MSK )
Ответ на: комментарий от ukr_unix_user 04.05.20 12:43:31 MSK
Ну так у меня и вопрос, зачем может на практике потребоваться гипервизору Vlan по ip. Там есть реализация, но нет примеров использования.
Twissel ★★★★★
( 04.05.20 12:48:50 MSK ) автор топика
Последнее исправление: Twissel 04.05.20 12:49:09 MSK (всего исправлений: 1)
Ответ на: комментарий от Pinkbyte 04.05.20 12:20:14 MSK
Спасибо, теперь ситуация прояснилась.
Twissel ★★★★★
( 04.05.20 12:55:49 MSK ) автор топика
Последнее исправление: Twissel 04.05.20 12:56:30 MSK (всего исправлений: 1)
Ответ на: комментарий от Twissel 04.05.20 12:48:50 MSK
Это нужно чтоб на хост попасть,как минимум. Без ip по L2 это будет проблематично…
ukr_unix_user ★★★★
( 04.05.20 12:56:17 MSK )
Последнее исправление: ukr_unix_user 04.05.20 12:59:33 MSK (всего исправлений: 1)
Ответ на: комментарий от ukr_unix_user 04.05.20 12:56:17 MSK
Это и называется когнитивный диссонанс:
я привык, что классический VLAN это L2 без свойств L3 🙂
Twissel ★★★★★
( 04.05.20 13:05:58 MSK ) автор топика
Ответ на: комментарий от Twissel 04.05.20 13:05:58 MSK
vlan это просто широковещательный домен (L2), если не нужен ip на vSwitch то можно и без ip. но если вирт машины не живут изолировано от мира, то ip дефолт гетвея где-то нужно же прописать? так вот этот ip всё равно будет прописан где-то. и да, это будет интерфейс именно в этом влане, разве что не на виртуальном коммутаторе а на физическом.
ukr_unix_user ★★★★
( 04.05.20 13:18:04 MSK )
Ответ на: комментарий от ukr_unix_user 04.05.20 13:18:04 MSK
vlan это просто широковещательный домен (L2)
Я уже даже прочитал в Википедии, что могут быть ip-based VLAN’ы 😉
Вот только толку от них мало.
В остальном понятно.
Twissel ★★★★★
( 04.05.20 13:26:37 MSK ) автор топика
Ответ на: комментарий от ukr_unix_user 04.05.20 13:18:04 MSK
Это можно сформулировать короче: когда мы завернём сетевой интерфейс на котором висит гипервизор в OVS, нам нужно как-то на него попасть.
Отсюда все вытекающее.
Первый случай (два гипервизора) описал Pinkbyte .
Всем спасибо, вопрос решён.
Twissel ★★★★★
( 04.05.20 13:34:25 MSK ) автор топика
Последнее исправление: Twissel 04.05.20 13:34:46 MSK (всего исправлений: 1)
Ответ на: комментарий от Pinkbyte 04.05.20 12:20:14 MSK
Кстати, не подскажешь по OpenNebula каких-нибудь туториалов (можно текстом)?
А то, насколько я понял, Proxmox выезжает в основном за счет своей популярности у «домохозяек» 🙂
Twissel ★★★★★
( 04.05.20 13:39:22 MSK ) автор топика
Ответ на: комментарий от Twissel 04.05.20 13:39:22 MSK
Я настраивал по официальному howto — мне хватило. Перед этим почитал пару статей на хабре, типа этой. Заморачиваться отказоустойчивостью самой машины, где стоит сама рулилка opennebula я правда так и не стал — машина лежит на отдельном пуле в ceph, куда у самой opennebula нет доступа на запись, бэкапится отдельно + снапшоты rbd никто не отменял.
Вообще OpenNebula всё же немного не о том, пусть я и использую её как пускалку отдельных виртуальных машин, но сама идеология того что нельзя создать виртуальную машину без создания шаблона этой самой машины, намекает. А у меня такие машины — основные.
Сравнивать Proxmox и Opennebula, это как сравнивать LXC и Docker, к примеру. В докере тоже можно рожать отдельные контейнеры, не разделять stateful и stateless части, храня всё в одной ФС. Но забиванием гвоздей микроскопом это быть не перестанет.
Жалею ли я что выбрал Opennebula? Наверное всё же нет. Плацдарм для экспериментов на ней делать(когда надо родить пару десятков типовых виртуалок из шаблона) — одно удовольствие.
После опробованного мной oVirt-а так вообще — небо и земля(отдебажить проблемы работы oVirt я так и не осилил). А Proxmox 5 лет назад(когда я приценивался куда свалить с ручного руления тремя libvirt-нодами) в тандеме работы с ceph показался мне сыроватым по обзорам.
Pinkbyte ★★★★★
( 04.05.20 13:51:21 MSK )
Последнее исправление: Pinkbyte 04.05.20 13:52:13 MSK (всего исправлений: 1)

Т.к. в случае с классическим Linux Bridge (не рассматриваем VLAN Aware Bridge) мы имеем расклад Bridge per VLAN — сколько VLAN’ов, столько и бриджей.
Настройка EVPN на Juniper

В прошлой статье про EVPN было рассказано о возможностях и преимуществах использования данной технологии для DCI. В этой статье будет рассказано о том, как легко настраивается, включается и масштабируется EVPN. Основное внимание уделено конфигурации EVPN на платформе Juniper MX, но т.к. Junos это единая операционная система для большинства устройств компании Juniper, настройка на других платформах (например EX9200) будет идентичной.
Дизайн сети
Топология сети для примера будет очень простой. Используется 2 маршрутизатора, так что multi-homing не рассматривается. Каждый роутер имеет подключенный к нему Ethernet сегмент, который состоит из нескольких VLAN с каждой стороны, причем один из VLAN ID не совпадает с обеих сторон (101 и 211).
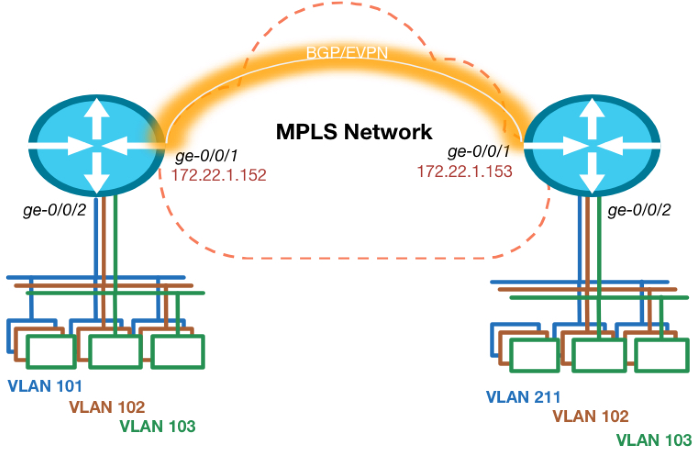
Подготовка к запуску EVPN
Перед тем как начать настраивать наш VPN, мы должны произвести предварительную подготовку. Это подразумевает под собой то, что мы должны обеспечить IP связанность между loopback адресами роутеров в наших дата-центрах и настроить BGP с EVPN address family. Версия Junos на которой проводилась настройка, требует явного включения функционала composite-chained next hops для EVPN. В Junos до версии 14.1 этого не требовалось.
routing-options <
autonomous-system 64999;
forwarding-table <
chained-composite-next-hop <
ingress <
evpn;
>
>
>
>
protocols <
mpls <
interface ge-0/0/1.0;
>
bgp <
group INTERNAL <
type internal;
local-address 172.22.250.152;
family inet-vpn <
unicast;
>
family evpn <
signaling;
>
neighbor 172.22.250.153;
>
>
ospf <
area 0.0.0.0 <
interface lo0.0 <
passive;
>
interface ge-0/0/1.0;
>
>
ldp <
interface ge-0/0/1.0;
>
>
Интерфейс ge-0/0/1 это тот, который смотрит в MPLS сеть и на котором мы настроили соседа по iBGP с обеими Layer 3 VPN и EVPN address family для обмена между собой layer 2 и layer 3 маршрутами. Мы использовали OSPF в качестве протокола внутренней маршрутизации, но на такой простой топологии мы могли бы обойтись и статическими маршрутами.
VLAN Based Service
Существует два способа настройки EVPN. Первый, это настройка отдельных EVPN инстансов или EVI для каждого VLAN/Bridge-домена. Это наилучший вариант для разделение трафика, обмена MAC адресами между ДЦ и полного контроля над flooding или broadcast трафиком в каждом VLAN/Bridge-домене. VLAN ID для трафика между PE маршрутизаторами дата-центров в таком случае будет изменен на 0.

Значения Route-Target и Route-Distinguisher задаются для каждого EVI и поэтому каждый VLAN будет иметь свою MPLS метку.
Это может потенциально привести к проблемам масштабирования, т.к. PE маршрутизаторы имеют ограничение на количество VPN которые могут быть настроены.
Ниже представлена конфигурация для данного способа и нашей топологии.
interfaces <
ge-0/0/2 <
flexible-vlan-tagging;
encapsulation flexible-ethernet-services;
unit 101 <
encapsulation vlan-bridge;
vlan-id 101;
>
unit 102 <
encapsulation vlan-bridge;
vlan-id 102;
>
unit 103 <
encapsulation vlan-bridge;
vlan-id 103;
>
>
>
routing-instances <
BD1 <
instance-type evpn;
interface ge-0/0/2.101;
route-distinguisher 1001:1001;
vrf-target target:1001:1001;
>
BD2 <
instance-type evpn;
interface ge-0/0/2.102;
route-distinguisher 1002:1002;
vrf-target target:1002:1002;
>
BD3 <
instance-type evpn;
interface ge-0/0/2.103;
route-distinguisher 1003:1003;
vrf-target target:1003:1003;
>
>
Команды “flexible-ethernet-services” и “flexible-vlan-tagging” в настройках интерфейса позволяют использовать его для различных сервисов. Это значит, что мы можем настроить интерфейс одновременно как для тегированного, нетегированного и трафика с двумя тегами, а так же с layer 2 bridging и layer 3 сабинтерфейсами на одном физическом интерфейсе. Одна из сильнейших возможностей платформы MX!
Как вы можете увидеть, настройка VPN очень простая! Мы всего-лишь убедились, что нужные интерфейсы находятся в VPN и присвоили значения RD и RT.
Т.к. в нашем случае используется сценарий с single-homed, то никакой другой конфигурации не требуется. Для ESI (Ethernet Segment Identifier) по умолчанию выставлено значение 0 на single-homed маршрутизаторах и оно не должно различаться на разных сайтах.
VLAN Aware Service
Второй способ более гибкий при использовании. Это так называемый VLAN Aware service. Этот способ позволяет помещать множество VLAN и Bridge-доменов в один EVPN инстанс (EVI). Это улучшает масштабируемость и до сих пор позволяет должным образом разделять трафик. VLAN ID теперь содержится в каждом пакете. Для обеспечения надлежащей работы ECMP (equal-cost multipath) форвардинга в MPLS сети, MPLS метка назначается на каждый VLAN ID, это значит, что трафик теперь сможет балансироваться на VLAN, а не на EVI.

Настройка для такого способа немного сложнее, но всё еще очень простая и еще позволяет делать VLAN translation! Так же, в такой конфигурации допускается пересечение MAC-адресов между VLAN или Bridge-доменами.
interfaces <
ge-0/0/2 <
flexible-vlan-tagging;
encapsulation flexible-ethernet-services;
unit 0 <
family bridge <
interface-mode trunk;
vlan-id-list [ 101 102 103 ];
vlan-rewrite <
translate 211 101;
>
>
>
>
>
routing-instances <
EVPN <
instance-type virtual-switch;
interface ge-0/0/2.0;
route-distinguisher 1000:1000;
vrf-target target:1000:1000;
protocols <
evpn <
extended-vlan-list [ 101 102 103 ];
>
>
bridge-domains <
NETWORK1 <
domain-type bridge;
vlan-id 101;
>
NETWORK2 <
domain-type bridge;
vlan-id 102;
>
NETWORK3 <
domain-type bridge;
vlan-id 103;
>
>
>
>
Как вы можете видеть, мы позаботились и о VLAN translation. Это позволяет использовать различные VLAN в разных ДЦ, но работать они будут как один L2 домен.
Заключение
Данная статья показывает, как вы легко и гибко можете настроить EVPN в Junos и как быстро организовать оптимальный Layer 2 Data Center Interconnect. В следующих статьях будет рассмотрен multi-homing и интеграция с Layer 3 для использования всех активных линков дата-центра.
RAD IPmux-24
Многофункциональный шлюз RAD IPmux-24 принадлежит к новому поколению решений для псевдопроводного доступа и предназначен для псевдопроводной передачи трафика Gigabit Ethernet. Его основные особенности — возможность объединённой коммутации трафика Fast Ethernet и Gigabit Ethernet и поддержка нескольких отраслевых стандартов псевдопроводного доступа. Шлюз поддерживает всех режимы эмуляции TDM, включая TDMoIP, CESoPSN и SAToP-RFC 4553.
Благодаря новой прикладной специализированной интегральной схеме, шлюз IPmux-24 передает трафик в сетях IP, Ethernet и MPLS, используя любую стандартную технологию эмуляции TDM. При передаче обеспечиваются минимальные задержки и высокоточная синхронизация.
Усовершенствованный механизм адаптивного восстановления синхронизации
Предоставление услуг TDM операторского класса требует использования сложных методов восстановления тактовой синхронизации. Расширенный механизм адаптивного восстановления синхронизации, примененный в шлюзе IPmux-24, соответствует стандарту G.823, использует сценарии стандарта G.8261 и обеспечивает точность 16•частей на миллиард. Для тактовой частоты предусмотрены возможности резервирования (при условии использования резервного генератора) и вывода на внешние периферийные устройства через дополнительный порт синхронизации.
Шлюз IPmux-24 обеспечивает высокоточное восстановление тактовой частоты отдельно для каждого порта (эта функция необходима для синхронизации нескольких клиентов), поддерживает внутриполосные шлейфы для проверки клиентских каналов независимо от провайдера и обеспечивает режим моста в режимах «VLAN-aware» и «VLAN-unaware» с ограничением скорости на входах/выходах для регулирования полосы пропускания.
Для реализации технологии адаптивного восстановления тактовой синхронизации не требуется расширение полосы пропускания и поддержка дополнительных протоколов, поскольку синхросигналы восстанавливаются из исходных сигналов, переданных от исходного псевдопроводного устройства. Эта особенность обеспечивает взаимозаменяемость шлюза IPmux-24 с другими решениями для псевдопроводной передачи данных, осуществляющими восстановление тактовой синхронизации. Кроме того, шлюз полностью управляем и поддерживает все функции служб ОАМ.
Способы применения
Шлюз IPmux-24 подходит для использования в качестве устройства разграничения трафика Ethernet при работе с такими сервисами передачи данных, как 4G WiMAX, поскольку он может выполнять функции гибкого Ethernet-моста с поддержкой сетей 802.1D и 802.1Q, Q-in-Q и ограничения скорости с одновременным обеспечением приоритезации и качества услуг TDM.
Использование шлюзов IPmux-24 сможет помочь поставщикам услуг передачи сотового трафика соответствовать особым требованиям, которые предъявляются операторами сотовой связи. Поскольку такие поставщики услуг работают сразу с несколькими операторами, они обязаны обеспечить поддержку всех задействованных технологий передачи данных: от CDMA и EVDO, для которых критична задержка в линии, до GSM и UMTS, для которых особенно важна синхронизация. IPmux-24 — это одноблочное решение, оптимальное для поставщиков, обслуживающих сразу несколько операторов.
Шлюз IPmux-24 также может использоваться для замены дорогостоящих выделенных линий путем передачи трафика TDM через более дешевые в обслуживании сети Fast Ethernet и Gigabit Ethernet.
| № | Наименование | Цена с НДС | Кол-во | Наличие | |
|---|---|---|---|---|---|
| Шлюзы IP-Mux для формирования потоков TDM over IP | |||||
| 1 | IPMUX-24/1E1/UTP/UTP/UTP | ||||
IPMUX-24/1E1/UTP/UTP/UTP — Шлюз TDM PSEUDOWIRE ACCESS GATEWAY,Single E1 port,SFP,S
Узнать срок поставки
IPMUX-24/2E1/UTP/UTP/UTP — Шлюз TDM PSEUDOWIRE ACCESS GATEWAY,2 E1,SFP,SFP,8 100Ba
Overlay Networks
Underlay — физическая IP сеть. Это база (транспорт) поверх которого уже строится overlay netw.
Примеры underlay: MPLS, IP-сеть построенная на IGP/EGP.
Также в underlay входят bare metal servers (или могу ошибаться и это не так). Подразумевается, что underlay — это прям железо-железо в голом виде.
Overlay — это наложенная сеть на underlay. Виртуальные свитчи, серверы и другие VM соединены virt logical links (VTEPs — virtual tunnel endpoints).
- host machine — сервер, на котором запущен hypervisor.
- guest machine — каждая VM.
Hypervisor предоставляет OS с virt платформой для guest и далее управляет работой guest OS. Несколько разных guest OS будут делать hardware ресурсы сервера.
VXLAN — overlay technology, которая строит virt туннели на основе IP/MPLS netw (VTEPs)
VM на одном хосте будут коммуницировать между собой через virt switch — L2. VM на разных хостах будут коммуницировать между собой через VTEP — L3. То есть прибегать к инкапсуляции L2 в L3 и передаче трафика через underlay сеть.
VTEP — располагаются на hypervisor или есть брать сервера, включенные с обычные access switches, то на свитчах тоже можно создавать VTEP. VTEP — туннель между хостами VTEP имеет 2 iface:
- switching interface — в сторону VM
- IP interface — в сторону IP сети (L3 netw)
Для инкапсуляции используется обычно VXLAN. О нем ниже.
Положительные особенности overlay network (наложенных сетей):
- Отделение сети от физического оборудования позволяет сетям дата-центров быть развернутыми за считанные секунды.
- Поддержка L2 и L3 между VM и серверами.
- В отличие от стандартной сети поддерживает до 16,4 млн «заказчиков» (вланов).
Чем приходится платить за использование overlay network:
— virtual tunnel endpoints (VTEPs) ипользует MAC и route. В отличие от традиционной модели, где каждая VM и каждый сервер использует MAC и route. В overlay трафик от VM и сервером инкапсулируется между VTEP. mac и route каждого сервера теперь не виден для оборудования overlay сети. mac и route теперь перенесены с физического уровня на уровень hypervisor.
Bare metal server
Редко в каких сетях получится найти полностью виртуализированую сеть. Какая-то часть серверов все-равно останется железной (в основном из-за производительности).
Как не бросить те самые железные сервачки и сохранить с ними сетевую связность?
Один из методов: соединить VTEP с физическим access switch.
Каждый гипервизор имеет VTEP. VTEP передает инкапсулированный трафик data plane между VM. Также VTEP делает mac-learning, предоставляет новые virt netw и другие изменения конфигурации.
На железных серверах нет VTEP. Чтобы железный сервер включить в overlay netw архитектуру, нужно чтобы кто-то инкапсулировал трафик от сервера и делал mac-learning. Пусть это делает обычный access-switch от имени сервера. Сервер при этом просто думает, что посылает от себя трафик дальше в сеть.
Fabric Design
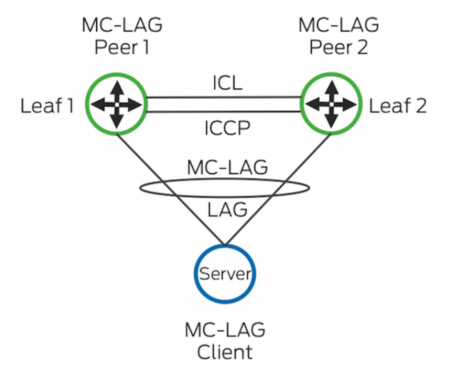
- Traditional – MC-LAG (multichassis link aggregation group)
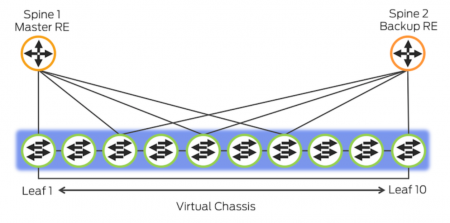
- Virtual Chassis
top-of-rack topology
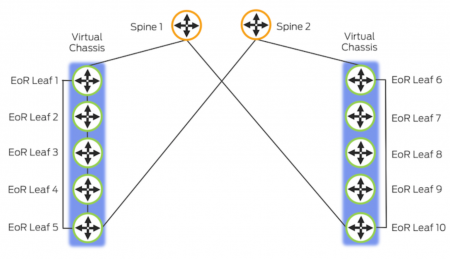
end-of-row topology
- Virtual Chassis Fabric
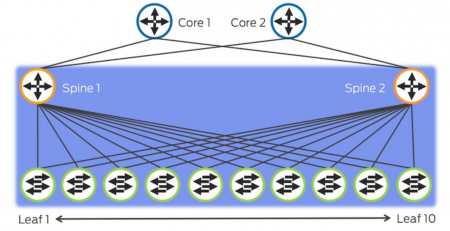
top-of-rack topology
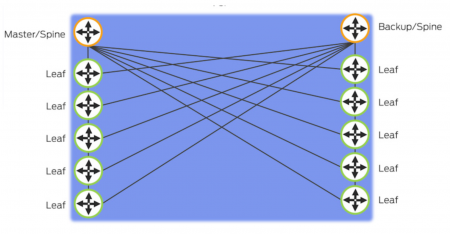
end-of-row topology
Большое приемущество в том, что между каждыми двумя host в фабрике есть только 2 hops. В отличие от VC, где число hops может достигать до 9.
-Virtual Chassis = 10 members -Virtual Chassis Fabric = 20 members [2-4 spine + 16-18 leaf]
Master + backup используют один и тот же MAC + IP для GW.
Можно легко вставлять/вытаскивать членов VC. На них автоматически будет сделан upgrade софта если нужно, подъедет конфиг, новый член будет назначен linecard.
В VC для вычисления кратчайшего пути используется Dejkstra и путь выбирается один.
В VC fabric VCCP отвчечает за эту процедуру и при возникновении нескольких равнозначных путей трафик балансируется.
Virtual Chassis Fabric works really well for a top-of-rack based solution, but for end-of-row it becomes a little more problematic.
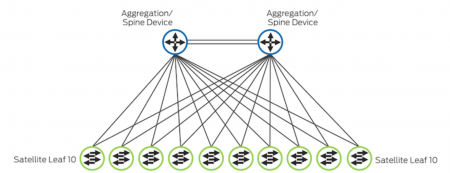
top-of-row topology
- IP CLOS Fabrics
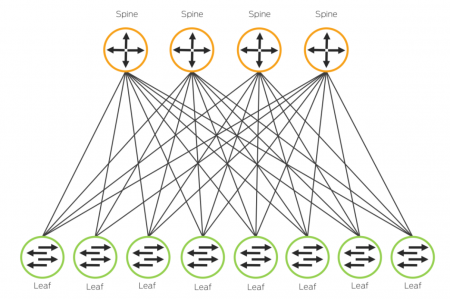
finely grained failure domains
IP Fabrics
Самое важное условие для IP Fabric: VTEP должны соединяться по L3.
Clos придумал распределенную топологию для L3, при которой возможно достаточно хорошее масштабирование сети. В такой сети есть разделение на уровни: ingress, middle, egress.
На основе CLOS произошла топология spine anf leaf, которую иногда называют сложенной CLOS сетью. То ест тут ingress и egress уровни сложены друг на друга (если можно так выразиться).
Spine — это L3 свитчи.
Leaf — это top-of-the-rack свитчи, который связывают сервер и VTEP.
Масштабируемость определяется двумя параметрами: «толщиной» spine, коэффициентов переподключенийleaf светчей.
Spine L3 свитчи можно собирать в кластер, а можно и нет. Причем говорится про кластре, в котором будут и SPINE и LEAF, все вместе.
Если я правильно поняла, то обычно, когда требуется особо большая масштабируемость сети, то VChassis не собирают.
При фабрике без VChassis емкость рассчитывается как умножение кол-во портов под серверы на кол-во LEAF, используемых на SPINE.
При использовании такого оборудования: SPINE = QFX5100-24Q [32 x 40GbE] LEAF = QFX5100-96S [96 x 10G + 8 x 40GbE] получаем фабрику размерностью = (32*96) x 10GbE = 3072 x 10GbE и oversubscription ratio 3:1
Control Plane
Для фабрик с VChassis беспокоиться о Control Plane не приходится. Она прост работает. Но если требуется более масштабируемся сеть, то придется отойти от VChassis и подумать о ControlPlane.
В фабрике каждому LEAF потребуется отправлять и получать маршрутную инфу вместе с остальными LEAF.
В той или иной степени для ControlPlane фабрики могут подойти следующие протоколы: BGP, OSPF, ISIS. Сравним их по разным параметрам:
Scale + Advertise Prefixes: Adveritse prefixes — у всех протоколов — норм, но OSFP и ISIS флудят префиксами. Чем больше префиксов в сети, тем больше флуда. Для уменьшения флуда можно и нужно в данном случае разбивать сегменты на area. Но при этом утратятся возможности CSPF. При этом BGP специально был придуман для работы с большим кол-вом префиксов. В плане масштабируемости он значительно выигрывает!
Traffic engineering + traffic tagging: иногда нужно управлять трафиком в фабриках, например, чтобы пустить его в обход какого-то SPINE. Тут понятно, что OSPF и ISIS сильно проигрывают. В отличие от них у BGP есть дофига атрибутов, которыми можно управлять трафиком.
Multivendor stability: Вроде и OSPF и ISIS неплохо себя должны вести, но кто знает, кто проверял. Гораздо чаще разные компании, использующие разное оборудование настраивают взаимодействие между собой именно посредством BGP. Так что именно BGP можно считать самым неприхотливым в работе в разными вендорами.
Ну в итоге для IP Fabric самый адекватный протокол — BGP.
BGP Design
- Using EBGP in an IP fabric: каждому свитчу свою AS. Каждый LEAF пирится с каждым SPINE. Тут все просто и понятно и красиво. И также с помощью LPF и AS-PATH можем спокойно рулить трафиком. Защита от петель, напомню в том, что при отправке префикса проверяется AS-path. Префикс не отправляется пиру, если в AS-path есть AS пира.