Разные Hints&Tips
mik17@sol1:~$ zpool status
pool: rpool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
c4t0d0s0 ONLINE 0 0 0
errors: No known data errors
pool: zfs_pool_zones
state: FAULTED
status: The pool metadata is corrupted and the pool cannot be opened.
action: Recovery is possible, but will result in some data loss.
Returning the pool to its state as of October 13, 2016 03:10:03 AM MSK
should correct the problem. Approximately 20 minutes of data
must be discarded, irreversibly. After rewind, several
persistent user-data errors will remain. Recovery can be attempted
by executing ‘zpool clear -F zfs_pool_zones’. A scrub of the pool
is strongly recommended after recovery.
see: http://illumos.org/msg/ZFS-8000-72
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zfs_pool_zones FAULTED 0 0 1 corrupted data
raidz1-0 DEGRADED 0 0 8
c4t1d0 DEGRADED 0 0 0 too many errors
spare-1 DEGRADED 0 0 0
c4t2d0 DEGRADED 0 0 0 too many errors
c4t6d0 ONLINE 0 0 0
c4t3d0 DEGRADED 0 0 0 too many errors
c4t4d0 DEGRADED 0 0 1 too many errors
c4t5d0 DEGRADED 0 0 0 too many errors
зоны не стартуют, все пропало )))
для начала попробовал «заклиарить» пулл, так как в дисках сомнений нет (это LUN с СХД)
mik17@sol1:~$ sudo zpool clear -F zfs_pool_zones
cannot clear errors for zfs_pool_zones: I/O error
теперь попробуем пулл «импортнуть»:
mik17@sol1:~$ sudo zpool import -F zfs_pool_zones
cannot import ‘zfs_pool_zones’: a pool with that name is already created/imported,
and no additional pools with that name were found
ну хоть метаданные по нему есть, так что сначала навесим на пулл флаг экспорта:
mik17@sol1:~$ sudo zpool export zfs_pool_zones
скушал
теперь опять импорт
mik17@sol1:~$ sudo zpool import -F zfs_pool_zones
mik17@sol1:~$ sudo zpool status zfs_pool_zones
pool: zfs_pool_zones
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon Oct 17 11:15:29 2016
306M scanned out of 4.94G at 43.8M/s, 0h1m to go
60.8M resilvered, 6.06% done
config:
NAME STATE READ WRITE CKSUM
zfs_pool_zones ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
c4t1d0 ONLINE 0 0 0
spare-1 ONLINE 0 0 0
c4t2d0 ONLINE 0 0 0
c4t6d0 ONLINE 0 0 0 (resilvering)
c4t3d0 ONLINE 0 0 0
c4t4d0 ONLINE 0 0 0
c4t5d0 ONLINE 0 0 0
errors: 1 data errors, use ‘-v’ for a list
восстановился с ошибками на файловой системе, нужно их scrub’нуть
mik17@sol1:~$ sudo zpool scrub zfs_pool_zones
mik17@sol1:~$ sudo zpool status -v zfs_pool_zones
pool: zfs_pool_zones
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://illumos.org/msg/ZFS-8000-8A
scan: scrub in progress since Mon Oct 17 11:38:01 2016
225M scanned out of 4.94G at 37.5M/s, 0h2m to go
0 repaired, 4.45% done
config:
NAME STATE READ WRITE CKSUM
zfs_pool_zones ONLINE 0 0 4
raidz1-0 ONLINE 0 0 8
c4t1d0 ONLINE 0 0 0
c4t2d0 ONLINE 0 0 0
c4t3d0 ONLINE 0 0 0
c4t4d0 ONLINE 0 0 0
c4t5d0 ONLINE 0 0 0
spares
c4t6d0 AVAIL
errors: Permanent errors have been detected in the following files:
/zfs_pool_zones/zoneSokolov/root/var/cron/log
/zfs_pool_zones/zonehdscci1/root/var/cron/log
/zfs_pool_zones/zonepostgres1/root/var/svc/log/application-database-postgresql_84:default_64bit.log
/zfs_pool_zones/zonepostgres1/root/var/cron/log
после окончания очистки:
mik17@sol1:~$ sudo zpool status -v zfs_pool_zones
pool: zfs_pool_zones
state: ONLINE
scan: resilvered 57.2M in 0h0m with 0 errors on Mon Oct 17 12:08:47 2016
config:
NAME STATE READ WRITE CKSUM
zfs_pool_zones ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
c4t1d0 ONLINE 0 0 0
c4t2d0 ONLINE 0 0 0
c4t3d0 ONLINE 0 0 0
c4t4d0 ONLINE 0 0 0
c4t5d0 ONLINE 0 0 0
spares
c4t6d0 AVAIL
errors: No known data errors
На другой машинке все сложнее — там и rpool тоже в DEGRADED стейте. но это уже другая история.
forum.lissyara.su
Иногда, правильный удар в бубен, приводит в чувство целое племя.
восстановление данных с развалилвшгегося ZFS pool
Простые/общие вопросы по UNIX системам. Спросите здесь, если вы новичок
Правила форума
Убедительная просьба юзать теги [cоde] при оформлении листингов.
Сообщения не оформленные должным образом имеют все шансы быть незамеченными.
Первое новое сообщение • 12 сообщений • Страница 1 из 1
Mobilesfinks мл. сержант Сообщения: 128 Зарегистрирован: 2008-04-14 14:49:48 Контактная информация:
восстановление данных с развалилвшгегося ZFS pool
На днях навернулся массив ZFS mirror
на дисках поймал бэды.
В итоге ситуация такая:
2-й диск:
— zdb -l
~ » sudo zdb -l /dev/sdd2 alexey@ayamschikov-pc -------------------------------------------- LABEL 0 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199934 pool_guid: 7755428179599985620 hostid: 2180312168 hostname: 'freenas.local' top_guid: 12958262172326587208 guid: 5059451112022724165 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/gptid/22b2b9c6-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 115 create_txg: 4 removed: 1 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 1 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199934 pool_guid: 7755428179599985620 hostid: 2180312168 hostname: 'freenas.local' top_guid: 12958262172326587208 guid: 5059451112022724165 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/gptid/22b2b9c6-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 115 create_txg: 4 removed: 1 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 2 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199934 pool_guid: 7755428179599985620 hostid: 2180312168 hostname: 'freenas.local' top_guid: 12958262172326587208 guid: 5059451112022724165 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/gptid/22b2b9c6-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 115 create_txg: 4 removed: 1 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 3 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199934 pool_guid: 7755428179599985620 hostid: 2180312168 hostname: 'freenas.local' top_guid: 12958262172326587208 guid: 5059451112022724165 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/gptid/22b2b9c6-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 115 create_txg: 4 removed: 1 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth ------------------------------------------------------------ — zpool list — no pools available
— zpool import -f
sudo zpool import -f alexey@ayamschikov-pc pool: userdata id: 7755428179599985620 state: DEGRADED status: The pool was last accessed by another system. action: The pool can be imported despite missing or damaged devices. The fault tolerance of the pool may be compromised if imported. see: http://zfsonlinux.org/msg/ZFS-8000-EY config: userdata DEGRADED mirror-0 DEGRADED 22b2b9c6-a724-11e4-8650-00e04c6b51db UNAVAIL ata-ST3500418AS_9VMTCW0E ONLINE — zpool import -f userdata
sudo zpool import -f userdata alexey@ayamschikov-pc cannot import 'userdata': I/O error Destroy and re-create the pool from a backup source. 1-й диск:
— zdb -l
sudo zdb -l /dev/sdc2 -------------------------------------------- LABEL 0 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199945 pool_guid: 7755428179599985620 errata: 0 hostid: 2831182848 hostname: 'ayamschikov-pc.vps' top_guid: 12958262172326587208 guid: 4493488366482451897 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/disk/by-id/ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473-part2' whole_disk: 1 DTL: 115 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 not_present: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 1 -------------------------------------------- failed to unpack label 1 -------------------------------------------- LABEL 2 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199945 pool_guid: 7755428179599985620 errata: 0 hostid: 2831182848 hostname: 'ayamschikov-pc.vps' top_guid: 12958262172326587208 guid: 4493488366482451897 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/disk/by-id/ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473-part2' whole_disk: 1 DTL: 115 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 not_present: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 3 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199945 pool_guid: 7755428179599985620 errata: 0 hostid: 2831182848 hostname: 'ayamschikov-pc.vps' top_guid: 12958262172326587208 guid: 4493488366482451897 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/disk/by-id/ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473-part2' whole_disk: 1 DTL: 115 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 not_present: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth ------------------------------------------------------------
— zpool import -f
sudo zdb -l /dev/sdc2 alexey@ayamschikov-pc -------------------------------------------- LABEL 0 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199945 pool_guid: 7755428179599985620 errata: 0 hostid: 2831182848 hostname: 'ayamschikov-pc.vps' top_guid: 12958262172326587208 guid: 4493488366482451897 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/disk/by-id/ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473-part2' whole_disk: 1 DTL: 115 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 not_present: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 1 -------------------------------------------- failed to unpack label 1 -------------------------------------------- LABEL 2 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199945 pool_guid: 7755428179599985620 errata: 0 hostid: 2831182848 hostname: 'ayamschikov-pc.vps' top_guid: 12958262172326587208 guid: 4493488366482451897 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/disk/by-id/ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473-part2' whole_disk: 1 DTL: 115 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 not_present: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth -------------------------------------------- LABEL 3 -------------------------------------------- version: 5000 name: 'userdata' state: 0 txg: 2199945 pool_guid: 7755428179599985620 errata: 0 hostid: 2831182848 hostname: 'ayamschikov-pc.vps' top_guid: 12958262172326587208 guid: 4493488366482451897 vdev_children: 1 vdev_tree: type: 'mirror' id: 0 guid: 12958262172326587208 metaslab_array: 35 metaslab_shift: 32 ashift: 12 asize: 497955373056 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 4493488366482451897 path: '/dev/disk/by-id/ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473-part2' whole_disk: 1 DTL: 115 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 5059451112022724165 path: '/dev/gptid/233672cb-a724-11e4-8650-00e04c6b51db' whole_disk: 1 not_present: 1 DTL: 117 create_txg: 4 features_for_read: com.delphix:hole_birth ------------------------------------------------------------
— zpool import -f
~ » sudo zpool import -f alexey@ayamschikov-pc pool: userdata id: 7755428179599985620 state: DEGRADED status: One or more devices contains corrupted data. action: The pool can be imported despite missing or damaged devices. The fault tolerance of the pool may be compromised if imported. see: http://zfsonlinux.org/msg/ZFS-8000-4J config: userdata DEGRADED mirror-0 DEGRADED ata-WDC_WD5000AARS-003BB1_WD-WCAV5K193473 ONLINE 5059451112022724165 UNAVAIL — zpool import -f userdata
после этой команды виснет. ночь так простоял, особой активности диска не наблюдаю.
Подскажите как вытащить данные с диска.
Последний раз редактировалось f_andrey 2015-07-07 15:15:40, всего редактировалось 1 раз.
Причина: Автору. пожалуйста, выбирайте соответствующий раздел форума.
Как восстановить ZFS RAIDZ1?
Воскресным вечером завис сервер.
Мягкая перезагрузка не помогла, сделал reset
Не загрузился.
Подключил монитор и увидел что загрузке не может быть прочитан сектор.
Загрузился с флешки и пробежался программой Victoria по диску с которым были проблемы .
В smart было указано что есть 1 нестабильный сектор.
Протестировал и переназначил его ( всего 1 сектор).
Не закончив полную проверку диска — снова попробовал загрузиться в Proxmox
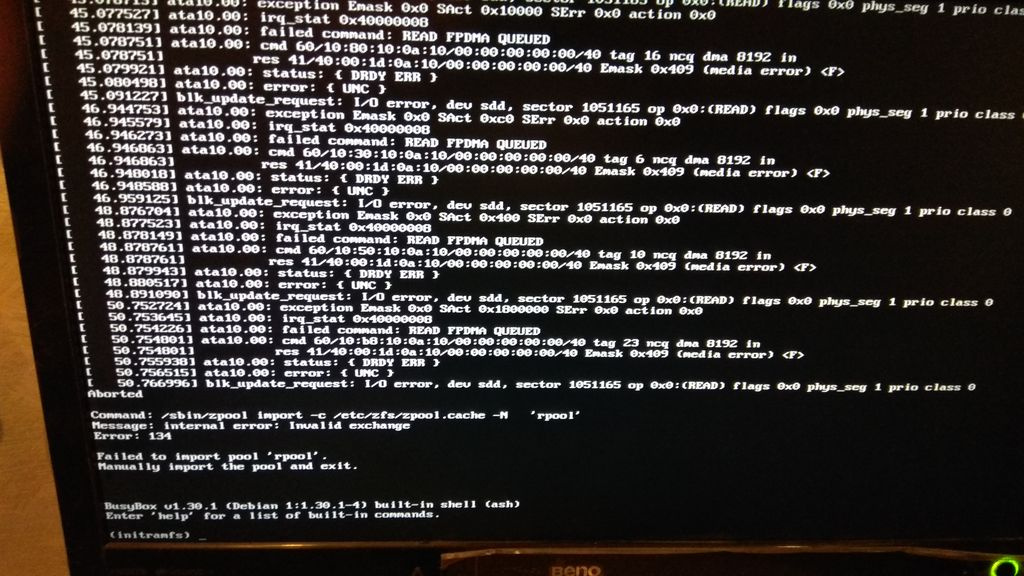
Ниже прикрепляю скрины.
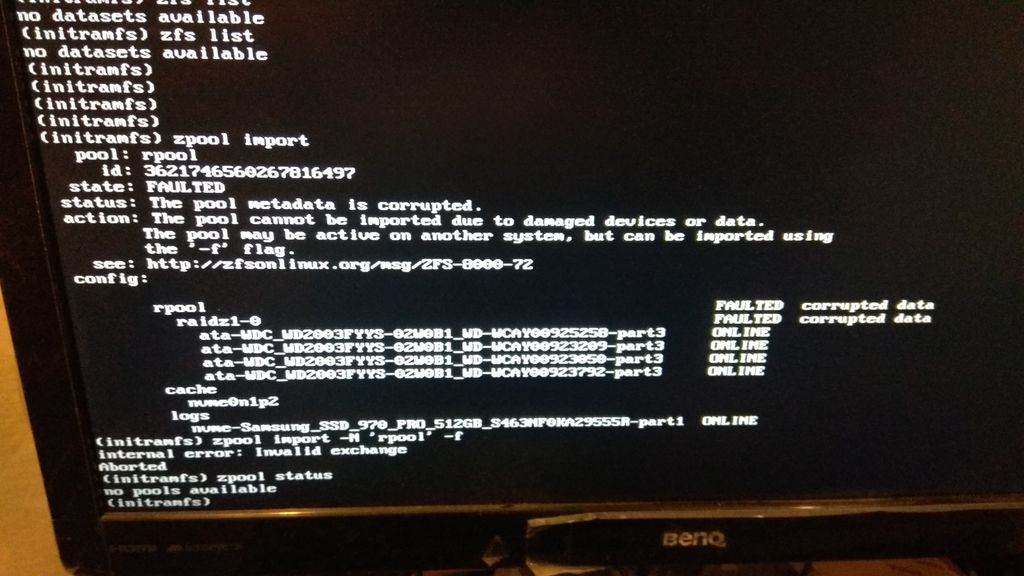
Пробовал по разному смонтировать pool — не получается.
На данный момент заканчивается создание полного бекапа образов дисков через ddrescue
Вот что выяснилось.
/dev/disk/by-id/ata-WDC_WD2003FYYS-02W0B1_WD-WCAY00923792-part3 диск смог забекапить только на 99,9 %
Сотни не читаемых секторов.
3 диска имеют одинаковые TXG ( один из них битый)
1 Диск отличается своими TXG ( сам диск читается)
Создал образы дисков.
Смонтировал эти образы
losetup /dev/loop1 /opt/ata-WDC_WD2003FYYS-02W0B1_WD-WCAY00923209-part3.bin losetup /dev/loop2 /opt/ata-WDC_WD2003FYYS-02W0B1_WD-WCAY00925258-part3.bin losetup /dev/loop5 /opt/ata-WDC_WD2003FYYS-02W0B1_WD-WCAY00923792-part3.bin losetup /dev/loop0 /opt/ata-WDC_WD2003FYYS-02W0B1_WD-WCAY00923050-part3.bin losetup /dev/loop3 /opt/nvme-Samsung_SSD_970_PRO_512GB_S463NF0KA29555R-part1.bin losetup /dev/loop4 /opt/nvme-Samsung_SSD_970_PRO_512GB_S463NF0KA29555R-part2.binПробовал пр помощи утилиты откатить к общему TXG
https://gist.github.com/jshoward/5685757
После этого пробовал смонтировать pool с указанием этого TXG
zpool import -fF -XT 922580 -o readonly=on rpool zpool import -fF -XT 962577 -o readonly=on rpoolКомп «думал» сутки, но потом все равно не смог смонтировать pool
На этом pool мне по сути нужно вытащить 2-3 образа и возможно бекапы.
Есть ли какие то утилиты для восстановления?
Вот эта прога «видит» мой pool
https://www.ufsexplorer.com/articles/how-to/recove.
Но она платная и не факт что восстановит.
Пробовал эту
https://github.com/Stefan311/ZfsSpy
Выдает много ошибок, не может считать pool
С этим скриптом так и не смог разобраться до конца. Документации минимум 🙁
https://github.com/hiliev/py-zfs-rescue
Форк предыдущего проекта.
Документации побольше, но тоже не до конца понятно как работает.
Зачем то запускается локальный сервер не понятно как запускать сам скрипт.
https://github.com/eiselekd/dumpbin-py-zfs-rescue
Может есть еще какие то способы восстановить данные с развалишегося ZFS RAIDZ1 ?
Что можете посоветовать?
- Вопрос задан более трёх лет назад
- 4404 просмотра
1 комментарий
Сложный 1 комментарий
Замена или восстановление поврежденного устройства
В этом разделе описывается определение типов сбоев устройств, сброс временных ошибок и замена устройства.
Определение типа сбоя устройства
Термин поврежденное устройство является достаточно неопределенным и может обозначать целый ряд возможных ситуаций:
- Повреждение отдельных битов. С течением времени случайные побочные факторы, например магнитное воздействие и воздействие космических лучей, могут привести к непредсказуемому изменению сохраненных на диске битов. Эти события происходят относительно редко, но достаточно вездесущи, чтобы вызвать потенциальное повреждение данных в крупных системах или системах, работающих длительное время. Обычно эти ошибки являются временными.
- Неверные адреса чтения или записи. Ошибки микропрограммного обеспечения или сбои оборудования могут привести к чтению или записи целых блоков в неправильном расположении на диске. Эти ошибки обычно являются временными, хотя большое количество таких ошибок может указывать на неисправность накопителя.
- Ошибка администратора. Администратор может непреднамеренно записать на части диска некорректные данные (например, скопировать /dev/zero на части диска), что приведет к неустранимому повреждению данных на диске. Эти ошибки всегда являются временными.
- Временный сбой. Диск может оказаться недоступным на некоторое время, что приведет к ошибкам ввода/вывода. Эта ситуация обычно связана с подключенными к сети устройствами, однако временные сбои возможны и в случае локальных дисков. Эти ошибки могут быть как временными, так и постоянными.
- Неисправное или часто отказывающее оборудование. Эта ситуация охватывает самые разные проблемы, связанные с неисправностью оборудования. Эти проблемы могут возникать в случае повторяющихся ошибок ввода/вывода, сбойных каналов передачи, приводящих к случайным повреждениям данных, или ряда других сбоев. Эти ошибки обычно являются постоянными.
- Устройство в автономном режиме. Если устройство находится в автономном режиме, предполагается, что оно было переведено в это состояние администратором по причине сбоя. Администратор, который перевел устройство в это состояние, может определить, насколько верно это предположение.
Точное определение неисправности может быть достаточно затруднительным. Первый этап этого процесса заключается в проверке счетчиков ошибок в выходных данных команды zpool status :
# zpool status -v pool
Ошибки подразделяются на ошибки ввода/вывода и ошибки контрольной суммы. Оба типа ошибок могут указывать на возможный тип сбоя. Как правило, в результате этой операции выявляется лишь незначительное количество ошибок (несколько ошибок за длительный период времени). Выявление большого количества ошибок указывает на неизбежный или уже произошедший сбой устройства. Однако ошибка администратора также может приводить к значительному возрастанию показателей счетчиков ошибок. Другим источником информации является системный журнал. Если в журнале отображается большое количество сообщений SCSI или драйвера Fibre Channel, это может указывать на серьезные сбои оборудования. Если сообщения «syslog» не генерируются, то наиболее вероятен временный характер повреждения.
Необходимо ответить на следующий вопрос:
Вероятно ли возникновение в этом устройстве другой ошибки?
Ошибки, возникающие однократно, считаются временными и не указывают на возможный сбой. Повторяющиеся ошибки или ошибки, серьезность которых указывает на возможный сбой оборудования, считаются критическими. Процедура определения типа ошибки выходит за рамки возможностей автоматизированного программного обеспечения, доступного в настоящее время в ZFS, и поэтому должна выполняться администратором вручную. После определения типа ошибки необходимо предпринять соответствующие меры по ее устранению. Устраните временные ошибки или замените устройство в случае фатальных ошибок. Эти процедуры описаны в следующих разделах.
Даже в том случае, если ошибки устройства считаются временными, они, тем не менее, могут привести к возникновению неисправимых ошибок в данных в пуле. Эти ошибки требуют специальных процедур восстановления, даже если основное устройство считается работоспособным или исправленным. Для получения дополнительной информации об устранении ошибок в данных см. Восстановление поврежденных данных.
Сброс временных ошибок
Если ошибки устройства считаются временными, т.е. могут лишь с небольшой вероятностью оказать влияние на будущую работоспособность устройства, то это позволяет безопасно выполнить их сброс. Это указывает на отсутствие фатальных ошибок. Для сброса счетчиков ошибок RAID-Z или зеркальных устройств используется команда zpool clear . Пример:
# zpool clear tank c1t1d0
Этот синтаксис позволяет сбросить любые ошибки, связанные с устройством, и любые счетчики ошибок данных устройства.
Для сброса всех ошибок, связанных с виртуальными устройствами в пуле, и любых счетчиков ошибок в данных пула используется следующий синтаксис:
# zpool clear tank
Для получения дополнительной информации о сбросе ошибок пула см. Сброс ошибок устройств в пуле устройств хранения данных.
Замена устройства в пуле устройств хранения данных ZFS
Если повреждение устройства носит постоянный характер или высока вероятность постоянного сбоя в будущем, это устройство необходимо заменить. Возможность замены устройства зависит от настройки пула.
- Определение возможности замены устройства
- Устройства, замена которых невозможна
- Замена устройства в пуле устройств хранения данных ZFS
- Просмотр статуса переноса актуальных данных
Определение возможности замены устройства
Для замены устройства пул должен находиться в состоянии ONLINE. Устройство должно входить в конфигурацию с избыточностью или быть работоспособным (находиться в состоянии ONLINE). Если диск входит в конфигурацию с избыточностью, необходимо наличие достаточного количества реплик для восстановления актуальных данных. При сбое двух дисков в четырехстороннем зеркале один диск может быть заменен, поскольку для него доступны работоспособные реплики. Однако при сбое двух дисков в четырехстороннем устройстве RAID-Z замена дисков невозможна, поскольку необходимые реплики для извлечения данных отсутствуют. Если устройство повреждено, но находится в оперативном режиме, заменить его можно только до перевода пула в состояние FAULTED. Однако любые неверные данные будут скопированы с устройства на новое устройство, если нет подходящих реплик с правильными данными.
В следующей конфигурации диск c1t1d0 может быть заменен, и любые данные в пуле могут быть скопированы из правильной реплики c1t0d0.
mirror DEGRADED c1t0d0 ONLINE c1t1d0 FAULTED
Диск c1t0d0 также может быть заменен, однако самовосстановление данных невозможно, поскольку правильные реплики недоступны.
В следующей конфигурации ни один из поврежденных дисков не может быть заменен. Диски, находящиеся в состоянии ONLINE, также не могут быть заменены вследствие неисправности пула.
raidz FAULTED c1t0d0 ONLINE c2t0d0 FAULTED c3t0d0 FAULTED c3t0d0 ONLINE
В следующей конфигурации любой диск верхнего уровня может быть заменен, несмотря на то, что все неправильные данные, присутствующие на диске, копируются на новый диск.
c1t0d0 ONLINE c1t1d0 ONLINE
При сбое диска выполнение замены невозможно, поскольку сам пул находится в состоянии сбоя.
Устройства, замена которых невозможна
Если прекращение работы устройства приводит к сбою пула или это устройство содержит слишком большое количество ошибок данных в конфигурации без избыточности, то его безопасная замена невозможна. Без необходимой избыточности наличие актуальных данных для восстановления поврежденного устройства не обеспечивается. В этом случае восстановить пул можно только путем повторного создания конфигурации и восстановления данных.
Для получения дополнительной информации о восстановлении всего пула см. Устранение повреждений в масштабе всего пула устройств хранения данных ZFS.
Замена устройства в пуле устройств хранения данных ZFS
После определения заменяемого устройства выполните команду zpool replace для замены устройства. Для замены поврежденного устройства другим устройством используется следующая команда:
# zpool replace tank c1t1d0 c2t0d0
Эта команда инициирует переход данных в новое устройство из поврежденного устройства или других устройств пула, если для него используется конфигурация с избыточностью. По завершении выполнения команды поврежденное устройство отключается от конфигурации, после чего может быть удалено из системы. Если устройство уже было удалено и заменено новым устройством в том же местоположении, используется форма команды для одного устройства. Пример:
# zpool replace tank c1t1d0
Эта команда выполняет надлежащее форматирование неформатированного диска и инициирует перенос актуальных данных из оставшейся конфигурации.
Для получения дополнительной информации о команде zpool replace см. Замена устройств в пуле устройств хранения данных.
Пример 11–1 Замена устройства в пуле устройств хранения данных ZFS
В следующем примере показано, как заменить устройство (c1t3d0) в зеркальном пуле устройств хранения данных tank в системе Sun Fire x4500. Если необходимо заменить диск c1t3d0 на новый диск в том же расположении (c1t3d0), необходимо исключить диск из конфигурации перед попыткой его замены. в.
- Сначала переведите заменяемый диск в автономный режим. Невозможно исключить диск из конфигурации, когда он используется.
- Укажите исключаемый из конфигурации диск (c1t3d0) и исключите его. Когда диск переводится в автономный режим в этой зеркальной конфигурации, уровень пула будет понижен, но пул останется доступным.
- Физически замените диск (c1t3d0). Перед физическим удалением сбойного диска убедитесь, что горит синий светодиодный индикатор «Готовность к удалению».
- Настройте диск (c1t3d0).
- Переведите диск (c1t3d0) в оперативный режим.
- Выполните команду zpool replace для замены диска (c1t3d0). Примечание – Если ранее было установлено свойство пула autoreplace=on, то любое новое устройство, обнаруженное в том же физическом расположении, что и устройство, ранее входившее в пул, автоматически форматируется и заменяется без использования команды zpool replace . Эта функциональная возможность может не поддерживаться для некоторого оборудования.
- Если отказавший диск автоматически заменяется устройством горячего резервирования, может потребоваться отключение резервного диска после замены отказавшего. Например, если резервное устройство c2t4d0 остается активным после замены отказавшего диска, его следует отключить.
# zpool detach tank c2t4d0
# zpool offline tank c1t3d0 # cfgadm | grep c1t3d0 sata1/3::dsk/c1t3d0 disk connected configured ok # cfgadm -c unconfigure sata1/3 Unconfigure the device at: /devices/pci@0,0/pci1022,7458@2/pci11ab,11ab@1:3 This operation will suspend activity on the SATA device Continue (yes/no)? yes # cfgadm | grep sata1/3 sata1/3 disk connected unconfigured ok Replace the physical disk c1t3d0> # cfgadm -c configure sata1/3 # cfgadm | grep sata3/7 sata3/7::dsk/c5t7d0 disk connected configured ok # zpool online tank c1t3d0 # zpool replace tank c1t3d0 # zpool status pool: tank state: ONLINE scrub: resilver completed after 0h0m with 0 errors on Tue Apr 22 14:44:46 2008 config: NAME STATE READ WRITE CKSUM tank ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t1d0 ONLINE 0 0 0 c1t1d0 ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t2d0 ONLINE 0 0 0 c1t2d0 ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t3d0 ONLINE 0 0 0 c1t3d0 ONLINE 0 0 0 errors: No known data errors
Следует помнить, что предыдущая команда zpool output может показывать как новые, так и старые диски под заголовком replacing. Пример:
replacing DEGRADED 0 0 0 c1t3d0s0/o FAULTED 0 0 0 c1t3d0 ONLINE 0 0 0
Этот текст означает, что выполняется процесс замены, и актуальные данные переносятся на новый диск.
Если диск c1t3d0) заменяется на другой диск (c4t3d0), то после физической замены диска необходимо только выполнить команду zpool replace . Пример:
# zpool replace tank c1t3d0 c4t3d0 # zpool status pool: tank state: DEGRADED scrub: resilver completed after 0h0m with 0 errors on Tue Apr 22 14:54:50 2008 config: NAME STATE READ WRITE CKSUM tank DEGRADED 0 0 0 mirror ONLINE 0 0 0 c0t1d0 ONLINE 0 0 0 c1t1d0 ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t2d0 ONLINE 0 0 0 c1t2d0 ONLINE 0 0 0 mirror DEGRADED 0 0 0 c0t3d0 ONLINE 0 0 0 replacing DEGRADED 0 0 0 c1t3d0 OFFLINE 0 0 0 c4t3d0 ONLINE 0 0 0 errors: No known data errors
Для завершения процесса замены диска может потребоваться выполнить команду zpool status несколько раз.
# zpool status tank pool: tank state: ONLINE scrub: resilver completed after 0h0m with 0 errors on Tue Apr 22 14:54:50 2008 config: NAME STATE READ WRITE CKSUM tank ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t1d0 ONLINE 0 0 0 c1t1d0 ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t2d0 ONLINE 0 0 0 c1t2d0 ONLINE 0 0 0 mirror ONLINE 0 0 0 c0t3d0 ONLINE 0 0 0 c4t3d0 ONLINE 0 0 0
Пример 11–2 Замена отказавшего устройства протоколирования
В примере ниже представлено восстановление устройства протоколирования c0t5d0 после сбоя в пуле устройств хранения pool. Требуются следующие основные действия.
- Ознакомьтесь с выходными данными zpool status -x и сообщением диагностики FMA, представленными ниже: http://www.sun.com/msg/ZFS-8000-K4
- Физически замените отказавшее устройство протоколирования.
- Включите устройство протоколирования.
- Удалите информацию об ошибках пула.
# zpool status -x pool: pool state: FAULTED status: One or more of the intent logs could not be read. Waiting for adminstrator intervention to fix the faulted pool. action: Either restore the affected device(s) and run 'zpool online', or ignore the intent log records by running 'zpool clear'. scrub: none requested config: NAME STATE READ WRITE CKSUM pool FAULTED 0 0 0 bad intent log mirror ONLINE 0 0 0 c0t1d0 ONLINE 0 0 0 c0t4d0 ONLINE 0 0 0 logs FAULTED 0 0 0 bad intent log c0t5d0 UNAVAIL 0 0 0 cannot open # zpool online pool c0t5d0 # zpool clear pool
Просмотр статуса переноса актуальных данных
Процесс замены диска может занять продолжительное время, в зависимости от его емкости и объема данных в пуле. Процесс переноса данных из одного устройства на другое называют переносом актуальных данных; для контроля этого процесса используется команда zpool status .
В традиционных файловых системах перенос актуальных данных выполняется на уровне блоков. Поскольку ZFS исключает искусственные слои диспетчера томов, перенос актуальных данных выполняется более универсальным и контролируемым образом. Эта функция имеет два основных преимущества:
- ZFS выполняет перенос только минимального объема необходимых данных. В случае кратковременного отключения (в противоположность полной замене устройства) возможен перенос актуальных данных диска в течение нескольких минут или секунд, вместо переноса всего диска или усложнения процедуры за счет регистрации «грязных» зон, осуществляемой некоторыми диспетчерами томов. При замене всего диска процесс переноса актуальных данных занимает время, пропорциональное объему данных на диске. Для замены диска размером 500 ГБ могут потребоваться секунды, если только малая часть используемого пространства принадлежит пулу.
- Процедура переноса актуальных данных безопасна и может быть прервана в любой момент. При отключении электропитания или перезагрузке системы процесс переноса актуальных данных запускается точно с момента прерывания без вмешательства пользователя.
Для контроля процесса переноса актуальных данных используется команда zpool status . Пример:
# zpool status tank pool: tank state: ONLINE status: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state. action: Wait for the resilver to complete. scrub: resilver in progress for 0h2m, 16.43% done, 0h13m to go config: NAME STATE READ WRITE CKSUM tank DEGRADED 0 0 0 mirror DEGRADED 0 0 0 replacing DEGRADED 0 0 0 c1t0d0 ONLINE 0 0 0 c2t0d0 ONLINE 0 0 0 c1t1d0 ONLINE 0 0 0
В приведенном примере диск c1t0d0 заменяется диском c2t0d0. Это событие отражается в выходных данных запроса состояния как replacing, что означает выполняющуюся замену виртуального устройства в настройке. Это устройство не существует в действительности, и создать пул с использованием этого типа виртуального устройства невозможно. Цель использования этого устройства состоит только в отображении процесса переноса актуальных данных и точном определении заменяемого устройства.
Следует отметить, что любой пул, для которого в настоящее время выполняется перенос актуальных данных, переводится в состояние ONLINE или DEGRADED, так как не может обеспечить необходимый уровень избыточности до завершения процесса переноса. Чтобы свести к минимуму воздействие на систему, перенос актуальных данных выполняется максимально быстро, хотя системные операции ввода-вывода всегда имеют более низкий приоритет, чем ввод-вывод по запросу пользователя. После завершения переноса актуальных данных выполняется переход к новой полной конфигурации. Пример:
# zpool status tank pool: tank state: ONLINE scrub: resilver completed after 0h0m with 0 errors on Tue Sep 1 10:55:54 2009 config: NAME STATE READ WRITE CKSUM tank ONLINE 0 0 0 mirror ONLINE 0 0 0 c2t0d0 ONLINE 0 0 0 c1t1d0 ONLINE 0 0 0 errors: No known data errors
Пул снова переводится в состояние ONLINE, и исходный неисправный диск (c1t0d0) удаляется из конфигурации.
- Previous: Восстановление отсутствующего устройства
- Next: Восстановление поврежденных данных