Архитектура и особенности процессора Эльбрус 2000
В чем принципиальные особенности процессора российской разработки Эльбрус? О ней в последнее время много говорят: как хвалят, так и ругают. Но давайте углубимся в архитектуру процессора, чтобы все-таки понять в чем его плюсы и минусы.
Расскажу, что такое скрытый и явный параллелизм, как используются предикаты и осуществляется подготовка переходов. Почему Эльбрусу не нужны push и pop команды и в чем особенности его регистрового окна. Какая защита от атак есть у российского процессора и какие возможности дает защищенный режим.
Данная статья — транскрипт моего выступления на конференции HighLoad++.

Что такое Эльбрус
Эльбрус не является клоном какого-либо процессора. Это абсолютно российская, даже еще советская разработка. Эльбрус умеет исполнять код x86, но делает это не аппаратно, а путем бинарной трансляции. Современные версии довольно производительны. Например, Эльбрус-16С — это 16 ядер, 2 ГГц, 750 Гфлоп/с, 16 нм. И 2 ГГц Эльбруса — это не 2 ГГц того же самого Интела, потому что Эльбрус умеет запускать на один такт до 50 инструкций. Конечно, компилятор должен суметь сгенерировать такой код, но технически это возможно.
Эльбрус серийно производится с 2014 года. Имеет поддержку МСВС, ALT Linux, Astra Linux. Есть версия QNX, российские ОСРВ и Postgres. На него вообще перенесено довольно много кода.
Эльбрус — довольно специфичный вид процессоров. Он непохож на то, к чему все привыкли. В нем есть все те же базовые инструкции: сложение, вычитание, умножение, условные и безусловные переходы, но у него теговая архитектура. Процессор тегирует данные в памяти таким образом, что знает тип объектов. Когда обычный процессор обращается в памяти к какому-то значению, он просто считывает битовую строку и трактует ее как float, или int, или pointer. Эльбрус же точно знает, что лежит в данной ячейке памяти.
Закон Мура
Есть закон Мура: каждые два года количество транзисторов на одном кристалле в среднем удваивается. Появился он давно, но работает до сих пор.
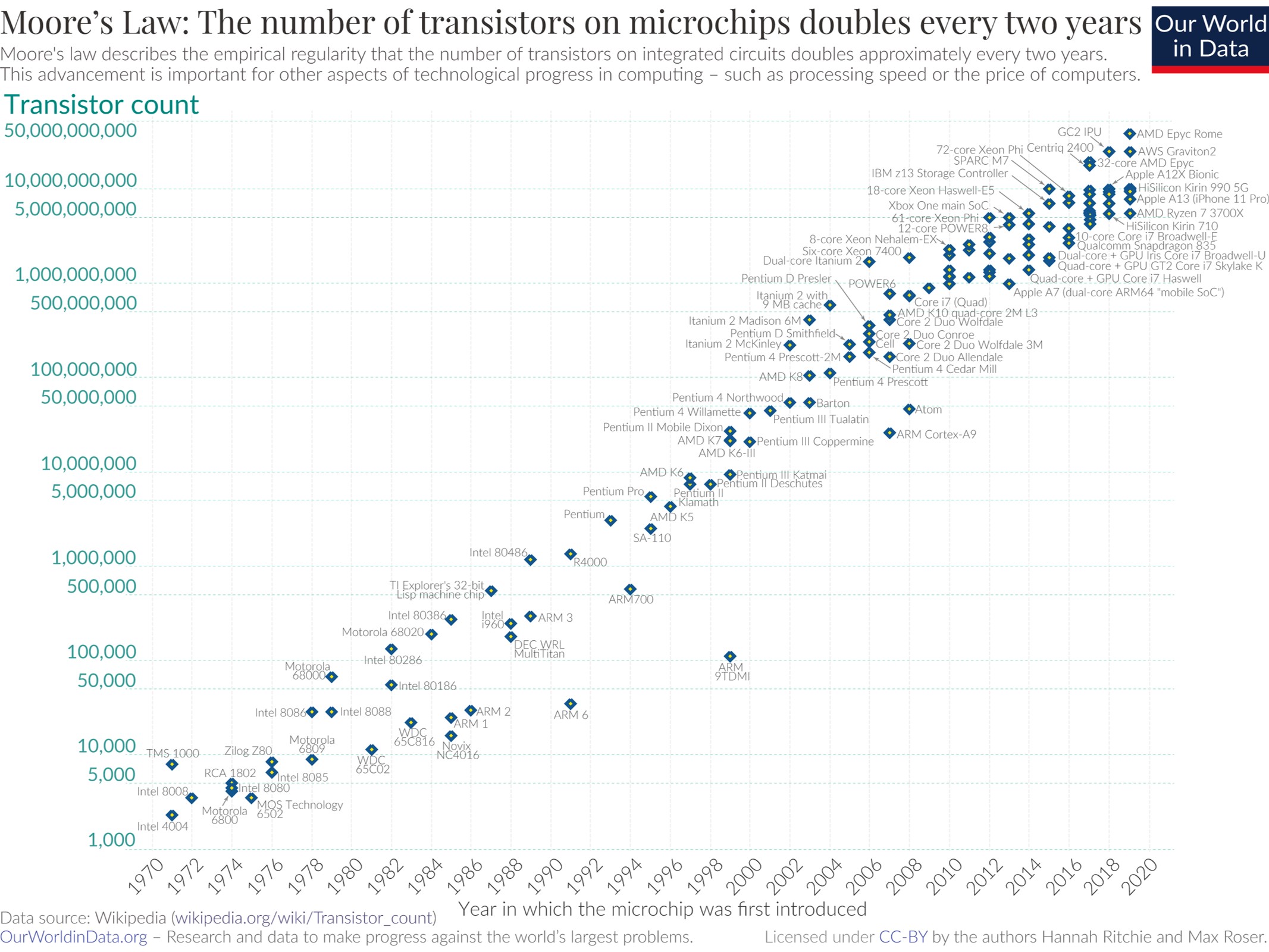
До 1995 года это было абсолютной синекурой для программистов: удвоение давало прямой прирост производительности единственного ядра процессора, и программы без приложения усилий со стороны программиста работали быстрее. Заменили 8086 на 286 — все ускорилось, 386 — еще быстрее, 486 — еще быстрее, Пентиум — программы просто летали. Но дальше начались проблемы. Прирост производительности отдельного ядра замедлился, и развитие процессоров пошло в сторону параллелизма. Ускорение начали делать за счет увеличения числа ядер, и программисты больше не могли просто запускать программы на более быстром процессоре, их пришлось распараллеливать. Тогда и появились процессоры со встроенным распараллеливанием исполнения кода.
Скрытый параллелизм
В 1995 году у Интел возникла проблема с тем, что программы завязаны на набор команд, но в архитектуре x86 мало регистров. Например, мы написали часть кода, который использует все 8 регистров, но следующая часть кода тоже их использует. Если за счет мощности процессора попытаться исполнить две части кода параллельно, они все равно упрутся в одни и те же регистры.
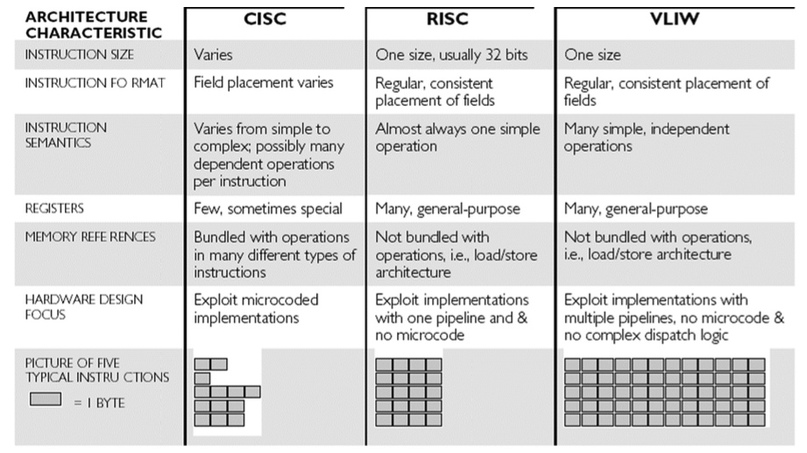
Чтобы решить проблему Интел начал разбивать сложные инструкции на простые, которым назначалось больше регистров, чем видно с точки зрения программиста. Когда два таких набора инструкций обращались к одному и тому же регистру, использовали его — загружали, считали и записали в память — они распараллеливались. Им выдавались две отдельные копии виртуального регистра AX.

На схеме слева показано, как устроена инструкция Интел, справа — как это сделано в RISC процессоре, который такую инструкцию исполняет. В Интел инструкция сама может сходить в память, считать значения, сделать вычисления и сохранить данные в память. В процессорах RISC инструкции фиксированного размера: либо инструкция читает из памяти, либо она выполняет регистровую операцию. Поэтому одна инструкция Интел на RISC-машинах разбивалась на серию простых инструкций.
Это до сих пор позволяет ускорять программы не сильно нагружая программистов, за счет выявления процессором в коде скрытого параллелизма и реализации его в виде реального параллельного запуска участков кода. Но такой подход сильно усложняет процессор. Ему приходится много анализировать и внутри него возникает много дополнительных действий, связанных с разбором инструкций, исполнением микроинструкций и выяснением где они заканчиваются.
Явный параллелизм
Конечно, полностью снять с программиста задачу распараллеливания, не получилось. Под многоядерные процессоры все равно нужно писать мультритредные программы и искать способы прогрузки всех аппаратных средств. Поэтому компиляторы внутри процессора и код прикладной программы сложны и требуют от программиста ручного распараллеливания алгоритмов. Хотя в пределах ядра модель CISC/RISC преобразования на x86/x64 процессорах до сих пор работает.
VLIW: ручной параллелизм
При разработке Э2К был принят кардинально другой подход. Чтобы процессор не распараллеливал изначально линейный код, эту работу полностью перенесли на компилятор. Он и так знает о программе больше, чем процессор. Может анализировать крупные участки кода, вплоть до всей программы, и принимать решения об оптимизации на более высоком уровне. Поэтому Эльбрус не пытается разбираться, где и что можно параллельно исполнять в коде, а оставляет это компилятору. Компилятор генерирует большую сложную инструкцию и подробно объясняет процессору, какие именно исполняющие устройства в данной инструкции должны делать.
Обычному интеловскому компилятору надо знать, что происходит в процессоре и подавать код так, чтобы процессору было легче его распараллеливать. А в процессорах с длинным командным словом (таких как Эльбрус и, кстати, Интел Itanium) — это полностью происходит на стороне компилятора. Процессор упрощается и существенное количество его аппаратуры можно потратить на исполнение, исполняющие устройства и кэш.
На борту Эльбруса
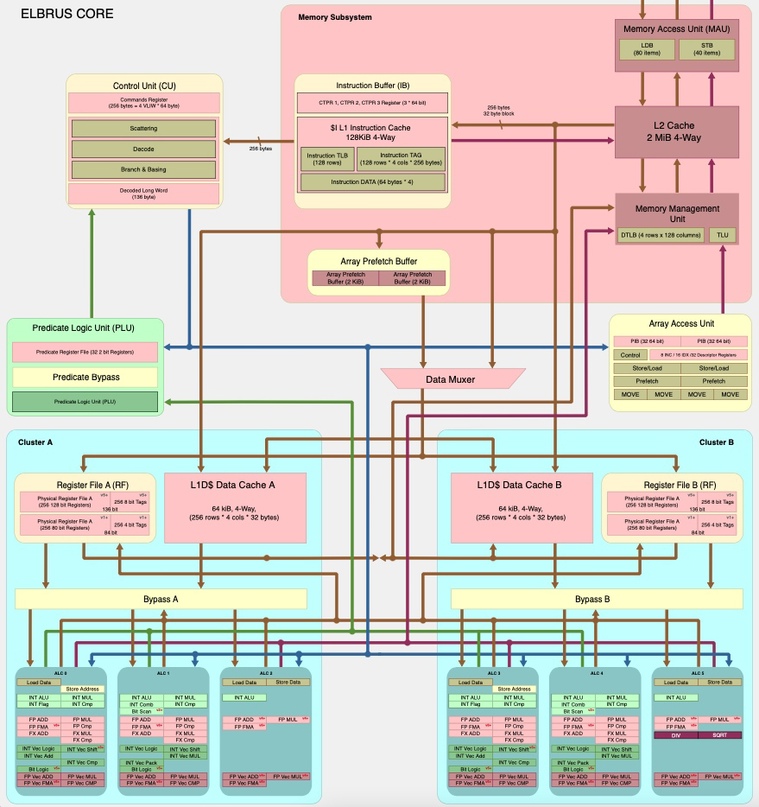
У каждого ядра процессора Эльбрус шесть АЛУ (арифметико-логических устройств), которые работают параллельно и могут исполнять шесть полноценных параллельных инструкций: вычисления, доступ к памяти, и все, что считается инструкцией. В очень широкой команде Эльбруса у каждого АЛУ свой фрагмент — слог, где точно определено, что надо делать. Например: складывать, вычитать, делить, записывать в память.
Кроме слогов для шести АЛУ широкая команда может содержать:
- одну субинструкцию для юнита, которая управляет переходами
- 3 вычисления на предикатах и 6 квалифицирующих предикатов
- 4 инструкции для асинхронного чтения данных в цикле
- 4 литерала в 32 бита, которые идут в исполнение как константы
Интересное решение заложено в предикатах.
Предикаты
У процессора Эльбрус есть отдельный регистр, который называется регистром предикатов. Один бит в этом регистре (на самом деле там два бита) — это булево значение, которое можно использовать для условного исполнения инструкций. Когда вы запускаете на исполнение огромную инструкцию, то 6 субинструкций для каждого АЛУ можно завязать на предикаты. Это позволяет экономить на jmp потому, что некоторые простые условные операции можно закодировать в одной инструкции таким образом, что первая половина IF выполняется, если предикат 1, а вторая, если он 0. Мы сразу кладем в команду оба варианта кода для IF и для ELSE, и проверяем по определенному биту, какую из них исполнять.
Еще есть субинструкции для самих предикатов, которые позволяют посчитать их перед исполнением команды. В регистре предикатов можно связать биты по И, ИЛИ, получить ответ, и по этому ответу условно использовать команду или оставить ответ в регистре предикатов. Это как бы большой флаговый регистр, в котором можно сохранять большое количество булевых значений.
Еще большое количество булевых вычислений, которые относятся, как правило, к control-flow, можно исполнять параллельно с основным кодом программы.
Все современные процессоры это пайплайновые устройства. Каждая команда исполняется в процессоре много тактов — 5, 7 до 19. Из-за того, что в каждом такте команды исполняются по очереди: от первой инструкции первый шаг, от второй второй, от третьей третий и т.д., они расположены ступенью.

В первой инструкции мы только считываем инструкцию из памяти, на втором такте для следующей инструкции считываем ее из памяти, а для предыдущей декодируем ее, и т.д. Так мы движемся по цепочке и процессор каждую инструкцию исполняет, скажем, 10 тактов. Но за счет того, что в каждом такте исполняется очередной этап десяти инструкций, в сумме процессор выполняет одну инструкцию за такт.
Так устроены все современные процессоры. Команда перехода (jmp) сбивает работу конвейера и обходятся процессору как десяток других команд. Она вынуждает процессор доработать все висящие в пайплайне инструкции: полностью закончить исполнение, сделать переход и потом снова начать наполнять пайплайн с нуля в новом месте. Из-за этого теряется огромное количество процессорного времени. Один jmp по стоимости может достигать 10-20 инструкций. Это огромная проблема для компиляторов, поэтому и компиляторы, и процессоры максимально оптимизируют код, избегая команд перехода.
Эльбрус может избежать этой проблемы не только с помощью предикатов, но и за счёт по другому устроенной команды переходов.
Подготовка переходов
В обычном процессоре есть две традиционные команды. Jmp, по которой процессор переходит на новый адрес инструкции и исполняет код с нового места. И условный jmp, который проверяет условие (в Эльбрусе это, как правило, предикат) и делает переход, если условие исполнилось.
В Эльбрусе условный и безусловный переход, вызов подпрограммы и возврат из подпрограммы можно разделить на две части. Сначала мы готовим переход и специальной инструкцией сообщаем процессору, что планируем перейти по такому-то адресу и сообщаем, как вычислить адрес перехода. Аппаратура Эльбруса параллельно с исполнением других конструкций выполняет это вычисление. Она может сходить в память, прочитать этот адрес и подготовиться к исполнению перехода.
Затем исполняется инструкция собственно перехода.
Если между подготовкой и исполнением перехода процессор успел выполнить другие задачи, переход оказывается «бесплатным». Потому что процессор параллельно подготовился, выяснил адрес перехода и подготовил к этому свою аппаратуру, и никакого сбоя пайплайна не происходит.
Процессор позволяет подготовить до 3 переходов одновременно. У него есть три специальных регистра, которые используются для подготовки jmp. Например, мы не знаем по какому адресу будем переходить, у нас типичный код IF (может быть, перейдем по нему, может, нет), но заранее знаем куда будем переходить потому, что адрес константный. Два из трех регистров обычно используется для подготовки переходов внутри кода функции, а третий умеет вызывать функции и возвращаться из них.
Еще в Эльбрусе необычно сделано регистровое окно.
Регистровое окно
В обычном процессоре есть 10-20-40 регистров. Он пишет в регистры промежуточные значения и читает из них. Обычно при вызове функций в регистрах сохраняются аргументы и возвратные значения. На Интеле и АРМе обычная функция устроена так. Перед ее вызовом команда push сохраняет в память регистров значения, которые понадобятся после возврата. Вызывается функция, что-то делает с этими регистрами, возможно затирает. Потом важные регистры поднимаются командой pop из стека и работа продолжается.
В Эльбрусе команды push и pop не используются. Процессор содержит пул из 256 84-разрядных регистров. Не все они видны программе: каждая функция «заказывает» у процессора нужное количество и процессор выделяет ей часть пула, в которой она будет жить.
Видимая подпрограмме группа регистров (окно в регистровый файл) делится на три последовательные части:
- Общие регистры для нас и для вызвавшей нас функции, в которых находятся переданные нам параметры.
- Регистры, в которых мы просто работаем, они видны только нашей функции.
- Регистры, в которых мы будем передавать параметры вызываемой функции. Они готовятся перед вызовом.
Когда мы вызываем функцию, окно сдвигается вверх так, что параметры для следующей функции становятся нижней частью окна регистров. Дальше образуется следующая ее личная часть и те регистры, которые функция будет использовать для вызова уже своих функций:
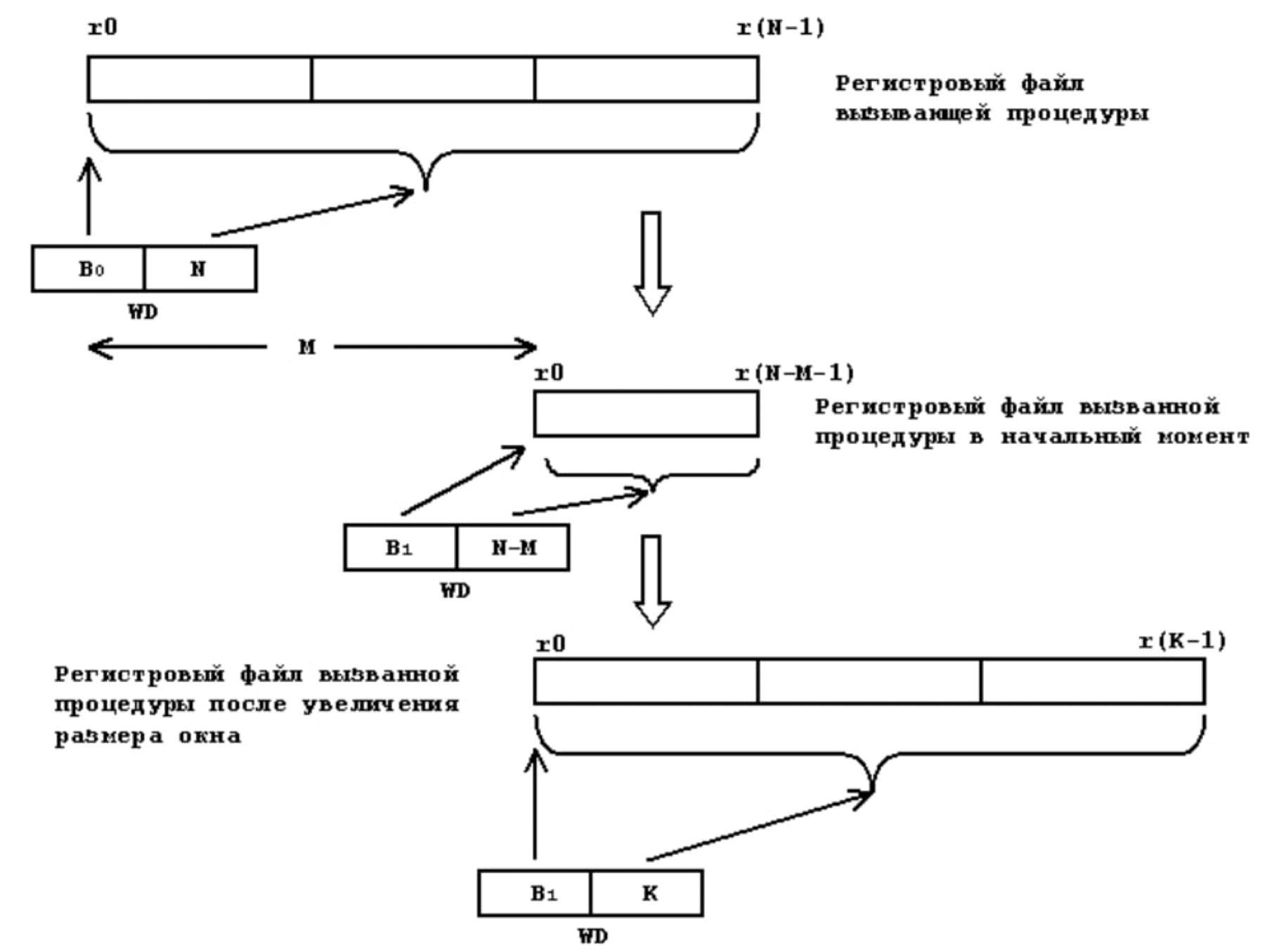
В момент вызова функции регистровый файл виртуально сдвигается вниз — первая и вторая группы уходят ниже и не видны вызванной функции. Третья группа становится первой, а новые вторую и третью группы вызванная функция заказывает себе у процессора специальной командой.
Стек регистров
Для большей части кода все происходит без обращений к памяти. На глубину 10-20 вызовов хватает пула из 256 регистров. Если процессору хватило физических регистров для обеспечения вызывающей и вызываемой функции, то обращений к памяти не происходит. Если регистровый файл кончается, процессор прозрачно для прикладного и системного кода сохраняет в стек части регистрового файла. Если функция запрашивает регистры, а свободных в файле нет, то процессор прозрачно для программы сохраняет «нижнюю» часть регистрового файла в стеке одной крупной операции записи. Что куда более эффективно, чем обслуживание мелких push/pop инструкций в традиционных архитектурах. Естественно, что по мере возвратов из функций процессор так же прозрачно для кода возвращает регистры из стека.
Регистровое окно содержит отдельную часть, которая не передвигается, а является глобальной. Она видна всем функциям и может использоваться как обычные регистры в обычном процессоре. Либо как временный регистр, и мы понимаем, что в момент вызова функции он будет затираться вызванной функцией, поэтому длительно ничего в нем не храним. Либо, наоборот, как глобальный регистр, например, регистр для хранения ссылок на глобальные данные или position-independent code регистр, который используется компиляторами для глобальных таблиц с нужными данными.
Подкачка данных для цикла
Быстродействие современных процессоров в огромной мере упирается в обмен с памятью. Доступ в ОЗУ в сотни раз медленнее, чем операции внутри самого процессора, особенно с ожиданием результатов. Запись выполняется отдельными записывающими юнитами. Неважно когда они произведут запись, работу это не останавливает. А вот считывание останавливает. Например, вы обсчитываете видео или звук: считываете значения из буфера, посэмплово их обрабатываете и записываете. Если вы закодируете эту операцию обычным циклом (часть кода, jmp на начало, снова та же часть кода, который исполняется в цикле), то на каждой итерации будет обращение к памяти, на котором процессор зависнет, пока не получит данные из памяти. Поэтому разработчики архитектуры стараются сделать так, чтобы мы узнали о потребности считывания из памяти как можно раньше, желательно до того, как оно стало критичным. Практически во всех современных процессорах есть инструкция, которая готовит данные для использования, и старается заранее сохранить их в кэш, чтобы мгновенно получить при считывании.
У Эльбруса есть отдельно параллельно работающий юнит аппаратной подкачки данных. Внутри цикла вы пишете не инструкцию считывания из памяти, а инструкцию выборки данных из FIFO. До начала цикла запускаете аппаратную подкачку, которой сообщаете, из какого места в памяти идти и как считывать значения. Она опережает цикл, выдергивает из памяти значения, которые нужны циклу и кладет в FIFO, а цикл параллельно забирает считанные значения оттуда. Если все сделано правильно, то считывание из памяти идет параллельно с работой процессора со скоростью, которая практически не задерживает исполнение цикла.
Эльбрус поддерживает схему исполнения циклов, которая запускает следующие итерации цикла на исполнение в процессоре до того, как закончились предыдущие. В традиционном процессоре, jmp не позволит исполнять следующую итерацию до окончания предыдущей, поэтому код будет исполняться строго до последней инструкции. В Эльбрусе внутри регистрового окна может быть выделено подокно, и коду цикла указывается не конкретный регистр, а подокно. Процессор аппаратно для каждой следующей итерации цикла выдает следующий регистр из этого подокна. Это позволяет логически написать обращение к одному и тому же регистру для 10 идущих подряд итераций цикла в коде, а физически каждая следующая итерация получает следующий отдельный регистр. Таким образом итерации работают с той степенью параллельности, которую допускает аппаратура процессора.
Эти подходы позволяют ускорить выполнение циклов и снизить зависимость от обращений к оперативной памяти.
Несколько стеков
Эльбрус поддерживает несколько параллельных стеков. В частности, есть стек вызовов, который полностью поддерживается аппаратно. Из-за того, что на него не сохраняются данные из регистрового файла и пользовательские данные, он может быть организован в отдельной части памяти. Инструкция вызова функции сохраняет на этом стеке информацию о текущем состоянии и все, что нужно для возврата в предыдущую функцию. Поэтому пересечение в стеке между адресами возврата и данными пользователя невозможно. Они находятся в двух разных стеках. Это защищает от типичного для Интела метода атаки на код на C, когда в переменную (обычно строковую, которая лежит на стеке) записывается больше, чем размер этой переменной. Старые функции типа strcpy такое позволяли. Если строка длиннее, чем буфер, в который ее копируют и буфер находится на стеке, то буфер перезаписывается. Данные в нем затираются, а вместо адресов возврата вписывается специальный адрес, и при выполнении возврата из функции, функция возвращается не туда, куда должна, а к вирусному коду. Перехват управления через переполнение буфера — типовая проблема, которая встречается до сих пор.
В Эльбрус это невозможно из-за того, что стеки находятся в разных местах. Но помимо этой особенности, у российской разработки есть и другие способы защиты кода.
Защищенный режим
Эльбрус устроен сложнее традиционных процессоров, поэтому большинство вирусов в нем не работают. Сохранение регистра происходит аппаратно и не доступно для прикладного кода, но для максимальной защиты, можно использовать защищенный режим, который заключается в тегировании данных в памяти процессора. С каждым значением в памяти лежат биты тегов, которые говорят — это число, а это указатель. Процессор знает, что именно он считывает из памяти. В защищенном режиме запрещено преобразование целых чисел и вообще чего бы то ни было в указатели. Поэтому получить указатель можно только из другого указателя. При этом первый указатель порождается в специальном режиме. Мало того, в защищённом режиме указатель не просто адрес в памяти, а 128 битная структура с тремя полями: базовый адрес (64 бита), размер окна и текущее положение в этом окне.
Чтобы получить обычный указатель, который смотрит на одно число в памяти, окно уменьшается до 4-8 байт. Раздвинутый указатель может смотреть уже на массив или структуру. Когда у указателя размер больше 8 байт, к нему можно применять адресную арифметику внутри поля. Если нам передали пойнтер на массив, то он указывает на начало массива, в размере указан размер массива, и он смотрит в опорную точку массива. От нее можно двигаться адресной арифметикой вверх и вниз, делать внутри этого массива все, что угодно, но выйти за его пределы нельзя. Адресная арифметика допустима в пределах [база, база+размер]. Этим же диапазоном ограничены указатели, которые можно породить из данного указателя.
Эффект от такого ограничения проще всего описать, как защищенность уровня Java или C#, то есть среды с managed указателями. Нельзя просканировать память! Можно обратиться только в ту часть памяти, к которой выдан указатель.
К сожалению, этим свойством Эльбруса мало пользуются из-за низкой совместимости существующего кода на Си с механизмами защиты. К примеру, недопустимо использование одного и того же поля структуры для хранения целого числа и указателя попеременно.. На сегодня сделать ядро Linux для защищенного режима пока не удалось.
На данный момент, защищенный режим можно использовать, например, как инструмент тестирования кода. Защищенный режим — это такой аппаратный valgrind с абсолютной скоростью исполнения на уровне скорости процессора, который всегда проверяет все ваши указатели. Можно не использовать его в продакшен-коде, но во время тестирования это помогает.
Но давайте вернемся к вопросу об исполнении кода x86.
Исполнение кода x86
Процессор Эльбрус не умеет исполнять Интеловский код аппаратно, но для него реализована программная бинарная трансляция кода x86 в код Э2К. Трансляция выполняется прозрачно для исполняемого кода и позволяет запускать на Э2К операционные системы для Интеловских процессоров.
Бинарная трансляция частично поддержана аппаратно — процессор содержит элементы аппаратуры архитектуры x86, которые слишком дорого эмулировать программно: например, сегментная адресация и набор сегментных регистров. Адресные вычисления при работе с сегментными регистрами процессор делает аппаратно, а все остальное программно.
Бинарный транслятор
Бинарный транслятор сделан в виде набора из трёх трансляторов и состоит из трех уровней кодогенерации:
- Шаблонный, который реализует пошаговую трансляцию: берет одну инструкцию Интела, синтезирует для нее соответствующий набор инструкций Эльбруса и исполняет. Это эффективно только для кода, который исполняется один раз.
- Быстрый регионный, который берет уже не одну инструкцию, а линейный фрагмент и компилирует его, учитывая взаимосвязи между инструкциями. В скомпилированный код вставляются точки замера, которые показывают часто или редко исполняется код. Для часто исполняемого кода запускается третий уровень кодогенерации.
- Оптимизирующий уровень работает медленно и применяется для перекомпиляции горячих участков кода. Это тяжелый оптимизирующий компилятор, который выжимает из бинарной трансляции все, что возможно, и синтезирует эффективный код. По быстродействию он мало уступает прямому исполнению на родном Интеле.
Исполнение кода x86 было необходимо 10 лет назад, когда Эльбрус только появился и для него не было родных операционных систем. Сейчас запуск на Э2К операционных систем, скомпилированных под x86 не такактуален, в отличие от режима, который запускает скомпилированные под x86 Linux приложения на ядре Linux под Эльбрус.

В штатной скомпилированной под Эл/ьбрус ОС Linux возможен запуск бинарной трансляции для прикладного кода. Это позволяет запускать под Эльбрусом приложения или библиотеки, скомпилированные под x86.
Итоги
Я описал только верхний уровень. У Эльбруса ещё три этажа тонкостей и деталей, не все из которых надо знать прикладному программисту. С моей точки зрения, а я знаю довольно много процессоров и то как они устроены, Эльбрус — это инженерное чудо. Он в некотором смысле проще, чем Интеловские процессоры, но он не простой. С ним надо уметь жить. Практика показывает, что для оптимизации вычислительного кода надо приложить усилия, чтобы выкачать из Эльбруса всю его производительность. Но по этому поводу есть много статей и руководство от разработчиков для программиста на С, есть готовые библиотеки, которые уже оптимизированы под Эльбрус и большой опыт перенесения кода.
HighLoad++ 2021 пройдет 17 и 18 марта 2022 года в Крокус-Экспо. Доклады уже сформированы, но из-за короновируса придется немного подождать. Билеты купить можно здесь.
- e2k
- highload++
- высокая производительность
- высокая нагрузка
- процессоры
- железо
- hardware
- эльбрус
- отечественный производитель
- отечественная электроника
- Блог компании Конференции Олега Бунина (Онтико)
- Высокая производительность
- IT-стандарты
- Компьютерное железо
- Процессоры
E2K: от истоков до нюансов Российской архитектуры [ч. 1]

Эльбрус 2000 — это микропроцессорная архитектура, разработка которой началась в России в 1998 году. Процессоры на основе архитектуры Эльбрус 2000 сейчас используются в высокопроизводительных безотказных серверах и компьютерах, например, в решениях для банков, государственных учреждений и научных центров.
Предисловие
В этой статье (или заметке?) я попробую обьяснить простым и понятным языком в чем «соль» этой архитектуры. Сразу оговорюсь, базовое понимание математики, информатики и принципов работы компьютера или телефона с которого читается статья — обязательна.
Статья разбита на части, пишу в свободное от работы и личных забот время. Эта творчество, скажем, пробник в первую очередь — себя. Если будет положительный фидбэк — то проба пера успешная:3

Историческая справка
Московский центральный научно‑исследовательский институт информатики и автоматизации (МЦСТ, первоначально Московский центр SPARC-технологий) был создан в 1992 году в результате реорганизации Московского научно‑производственного объединения «Электроника». Основной целью создания института было развитие отечественной вычислительной техники и программного обеспечения.

В свое время СССР добился достаточно серьезных достижений в создании компьютерной техники. Примером этому может служить серия советских суперкомпьютеров «Эльбрус», которые были созданы в Институте точной механики и вычислительной техники (ИТМиВТ) в 1970-1990-х годах прошлого века, это же название носит серия микропроцессоров и систем, созданных на их основе и выпускаемых сегодня ЗАО МЦСТ (Московский центр SPARC-технологий).
При этом история «Эльбруса» достаточно обширна. Работы над первым компьютером с таким названием велись с 1973 по 1978 год в ИТМиВТ им. Лебедева, руководил этими работами Б. С. Бурцев, разработка велась при участии Бориса Бабаяна, который являлся одним из замов главного конструктора. В то время основным заказчиком данной продукции, конечно же, выступали военные.
Первый компьютер «Эльбрус» обладал модульной архитектурой и мог включать в себя от 1 до 10 процессоров на базе схем средней интеграции. Быстродействие данной машины достигало 15 миллионов операций в секунду. Объем оперативной памяти, которая была общей для всех 10 процессоров, составлял до 2 в 20 степени машинных слов или, если применять принятые сейчас обозначения, 64 Мб. Однако самым интересным в «Эльбрусе-1» была именно его архитектура. Созданный в СССР суперкомпьютер стал первой в мире коммерческой ЭВМ, которая применяла суперскалярную архитектуру. Ее массовое применение за рубежом началось только в 90-х годах прошлого века с появлением на рынке доступных процессоров Intel Pentium.
Позднее выяснилось, что подобные разработки существовали еще до «Эльбруса», ими занималась компания IBM, но работы по данным проектам не были завершены и так и не привели к созданию конечного коммерческого продукта. По словам В.С. Бурцева, являвшегося главным конструктором «Эльбруса», советские инженеры старались применять самый передовой опыт как отечественных, так и зарубежных разработчиков. На архитектуру компьютеров «Эльбрус» повлияли не только компьютеры компании Burroughs, но и разработки такой известной фирмы, как Hewlett—Packard, а также опыт разработчиков БЭСМ-6.

После завершения работ над ЭВМ «Эльбрус-2» в ИТМиВТ взялись за разработку ЭВМ на базе принципиально новой процессорной архитектуры. Проект, который был назван достаточно просто – «Эльбрус-3», также значительно опередил аналогичные разработки на Западе. В «Эльбрусе-3» впервые был реализован подход, который Борис Бабаян называет «постсуперскалярным». Именно такой архитектурой в будущем обладали процессоры Intel Itanium, а также чипы компании Transmeta. Стоит отметить, что в СССР работы над данной технологией были начаты в 1986 году, а Intel, Transmeta и НР присупили к реализации работ в этом направлении лишь в середине 1990-х годов.
К сожалению, «Эльбрус-3» так никогда и не был запущен в серийное производство. Его единственный работающий экземпляр был построен в 1994 году, но в это время он был никому не нужен. Логическим продолжением работ над данным компьютером стало появление процессора «Эльбрус-2000», известного также как Е2К. У российской компании имелись большие планы по серийному производству данного процессора, который должен был пойти в серию одновременно или даже еще раньше, чем Itanium. Но из-за отсутствия необходимого объема инвестиций, все данные планы не были реализованы и так и остались на бумаге.
Архитектура Эльбрус 2000 была создана в России в начале 2000-х годов. Проект разработки новой архитектуры был запущен в 1999 году в рамках программы «Эльбрус» Министерства промышленности, науки и технологий Российской Федерации.
Основной целью программы было создание отечественного высокопроизводительного процессора, который мог бы конкурировать с зарубежными аналогами. В рамках программы были разработаны несколько поколений процессоров, начиная с Эльбрус-1 и заканчивая Эльбрус-4.
Однако основным достижением программы стала архитектура Эльбрус 2000, которая была представлена в 2002 году, в основе которой лежит подход VLIW. Эта архитектура была разработана с учетом современных требований к производительности и энергопотреблению, а также с учетом возможности выполнения параллельных вычислений.
Архитектура Эльбрус 2000 была успешно протестирована на различных задачах, включая математические расчеты, обработку изображений и видео, а также на задачах, связанных с обработкой больших объемов данных.
Сегодня архитектура Эльбрус 2000 продолжает развиваться и улучшаться. На ее основе создаются новые процессоры, которые успешно используются в различных областях, включая научные и промышленные вычисления, обработку данных и телекоммуникации. А МЦСТ является одним из ведущих отечественных разработчиков компьютеров и программного обеспечения. Институт занимается разработкой вычислительных систем для различных областей применения, включая научные исследования, проектирование, финансы, государственное управление и т. д. Компьютеры МЦСТ используются во многих отечественных организациях и предприятиях, а также экспортируются за рубеж.
Основные особенности
Начнем с основных особенностей архитектуры Эльбрус 2000:
- Многопоточность — каждое ядро процессора может обрабатывать несколько потоков одновременно, что позволяет значительно увеличить производительность системы.
- Симметричная мультипроцессорность — архитектура поддерживает одновременную работу нескольких процессоров, что также способствует арифметическому увеличению производительности.
- Использование эффективных алгоритмов обработки данных, таких как алгоритмы сжатия данных и алгоритмы сортировки, параллельных вычислений, что позволяет ускорить выполнение задач. Например, определение ацикличных участков с дальнейшим разделением на суб‑процессинг, или же использование эффективных алгоритмов предварительного чтения данных из памяти, что снижает задержку при исполнии кода.
- Наличие защиты от ошибок и сбоев, что обеспечивает высокую надежность работы системы. А так же особый режим выполнения и матрицы доступа к памяти, который аппаратно исключает вмешательство в соседние страницы памяти ПО. (Вспомним со слезами о Meltdown и Spectra на x86-архитектуре и потере в среднем 15% производительности)
- Архитектура Эльбрус 2000 поддерживает ВСЕ операционные системы Linux и Windows, так как спокойно кушает 64-битные инструкции, а так же спокойно может переваривать ассемблер (двоичные инструкции процессора) Intel или AMD64 платформ. Lintel — более производительное решение, даже чем от Купертиновских конкурентов (Apple со своей Rosetta любого поколения.)
Архитектура Эльбрус 2000 имеет ряд преимуществ перед другими архитектурами, такими как высокая производительность и надежность, но также имеет и недостатки, такие как ограниченная поддержка со стороны производителей программного обеспечения и высокая стоимость производства, а также (на момент написания) отсутствие локализации производства на территории РФ.
Давайте начнем разбираться с описанными преимуществами и почему они таковыми являются.
Мультипоточность
Мультипоточность в процессорах Эльбрус — это возможность одновременного выполнения нескольких потоков инструкций на одном процессоре. Каждый поток может выполняться независимо от других потоков, что позволяет увеличить производительность и эффективность работы процессора.
Процессоры Эльбрус поддерживают два типа мультипоточности: аппаратную и программную.
Аппаратная мультипоточность
Аппаратная мультипоточность в процессорах Эльбрус реализуется с помощью технологии Hyper‑Threading. Она позволяет процессору выполнять два потока инструкций на каждом ядре, используя различные ресурсы процессора, такие как регистры и функциональные блоки.
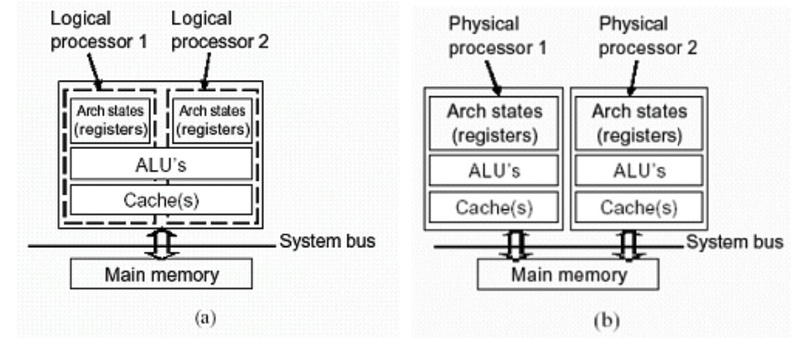
Но тут я остановлюсь подробнее, так как с каждым годом всё больше и больше транзисторов задействуется в процессорах, но производителям постоянно приходится идти на ухищрения для роста производительности, т.к. больше параллелизма им со старым подходом не выжать. Поэтому в 2002-м году свет увидели процессоры Intel Pentium 4, которые первыми на потребительском рынке получили поддержку виртуальной многоядерности или многопоточности, которую назвали Intel Hyper‑Threading. Суть этой технологии в том, что ядро физически у вас одно, но система его видит как 2 разных ядра, и ваши программы работают с одним ядром так, словно их 2.
И, если ранее программы не могли задействовать все вычислительные возможности каждого из ядер процессора, то теперь они на каждом ядре старались задействовать больше ALU (до 2 раз больше).
2 виртуальных ядра делят между собой один и тот же набор арифметико‑логических устройств (АЛУ), один и тот же кэш, но разные регистры, тогда как в случае с двумя обычными ядрами у вас разделены для каждого из ядер и АЛУ, и кэш, и все регистры. За счёт того, что на АЛУ приходится больше параллельных команд (8 вместо 4 в случае с современным суперскалярным подходом CISC процессоров), у вас удаётся загрузить одно ядро процессора в большей мере, и таким образом вы добиваетесь роста производительности в расчёте на каждое из ядер. Но по итогу, да, логические ядро, как правило, медленнее, чем физическое.
Программная мультипоточность
Программная мультипоточность в процессорах Эльбрус реализуется с помощью технологии OpenMP. Она позволяет разделять задачи на несколько потоков, которые выполняются параллельно на разных ядрах процессора. Это позволяет ускорить выполнение задач, которые могут быть разделены на независимые подзадачи.
Мультипоточность в процессорах Эльбрус позволяет увеличить производительность и эффективность работы процессора. Она позволяет выполнять несколько задач одновременно, что уменьшает время выполнения задач и увеличивает общую производительность системы.
Кроме того, мультипоточность позволяет использовать ресурсы процессора более эффективно, что уменьшает нагрузку на систему и повышает ее стабильность и надежность.
В целом, мультипоточность является важной технологией для повышения производительности и эффективности работы процессоров Эльбрус. Она позволяет использовать ресурсы процессора более эффективно и выполнять несколько задач одновременно, что делает систему более быстрой и стабильной.
Симметричная мультипроцессорность
Симметричная мультипроцессорность (SMP) — это архитектура компьютерной системы, в которой два или более процессоров работают параллельно и независимо друг от друга, обмениваясь данными через общую память. В этой архитектуре каждый процессор имеет доступ к общей памяти и периферийным устройствам, что позволяет им выполнять задачи более эффективно, чем в случае использования одного процессора.
Симметричная мультипроцессорность позволяет распределять задачи между процессорами таким образом, чтобы каждый из них мог выполнять свою работу независимо друг от друга. Это позволяет увеличить производительность системы и сократить время выполнения задач, а также обеспечивает масштабируемость.
Архитектура Эльбрус 2000 представляет собой симметричную мультипроцессорную систему, которая имеет ряд преимуществ перед другими архитектурами.
- Высокая производительность. Симметричная мультипроцессорность Эльбрус 2000 позволяет использовать несколько процессоров одновременно, что повышает производительность системы. Каждый процессор может выполнять свои задачи независимо друг от друга, что увеличивает скорость обработки данных и снижает время ожидания.
- Гибкость системы Архитектура Эльбрус 2000 позволяет легко добавлять или удалять процессоры в системе в зависимости от потребностей пользователя. Это позволяет гибко настраивать систему под конкретные задачи и обеспечивает масштабируемость.
- Надежность. Симметричная мультипроцессорность Эльбрус 2000 обеспечивает высокую надежность системы. Если один из процессоров выходит из строя, остальные процессоры могут продолжать работу без проблем. Это позволяет избежать сбоев в работе системы и обеспечивает бесперебойную работу.
- Энергоэффективность. Архитектура Эльбрус 2000 потребляет меньше энергии, чем другие архитектуры. Это достигается за счет использования более эффективных алгоритмов обработки данных и оптимизации работы процессоров.
- Высокая безопасность. Симметричная мультипроцессорность Эльбрус 2000 обеспечивает высокую безопасность системы. Каждый процессор имеет свой собственный набор инструкций и операционную систему, что делает невозможным взлом системы через один процессор.
Таким образом, симметричная мультипроцессорность архитектуры Эльбрус 2000 обеспечивает высокую производительность, гибкость, надежность, энергоэффективность и безопасность системы.
Алгоритмы обработки данных
Prefetching и аппаратная асинхронная подгрузка данных (APB)
Архитектура Эльбрус 2000 имеет ряд особенностей, которые позволяют эффективно обрабатывать данные. Одной из главных особенностей является наличие нескольких ядер процессора, которые могут работать параллельно. Это позволяет распараллеливать задачи и ускорять обработку данных, но что бы убрать ожидание данных для дальнейшей обработки — реализовано использование эффективных алгоритмов предварительного чтения данных из памяти, что в свою очередь снижает задержку при исполнии кода.
Предварительное чтение данных из памяти (Prefetching) является одним из методов оптимизации производительности в архитектуре Эльбрус 2000. Он позволяет загрузить данные из памяти в кэш процессора заранее, до того, как они будут фактически использоваться в вычислениях. Это может существенно ускорить выполнение программы, так как время доступа к кэшу намного меньше, чем к памяти.
В Эльбрус 2000 предусмотрено несколько способов предварительного чтения данных.
Один из них — это использование инструкций PREFETCH. Эти инструкции позволяют загрузить данные из памяти в кэш процессора заранее, до того, как они будут фактически использоваться. Инструкции PREFETCH могут быть использованы как для чтения, так и для записи данных.
Еще один способ предварительного чтения данных — это использование аппаратной поддержки предварительного чтения в кэше процессора, отдельный параллельно работающий модуль для подкачки данных, APB (Asynchronous Prefetch Buffer). В Эльбрус 2000 кэш оборудован специальным механизмом, который автоматически загружает данные из памяти в кэш заранее, если он обнаруживает, что эти данные скоро будут использоваться. Это происходит благодаря анализу обращений к данным и прогнозированию будущих обращений.
Предварительное чтение данных из памяти особенно полезно в случае работы с большими объемами данных или при обработке данных в циклах. Оно позволяет уменьшить время доступа к памяти и ускорить выполнение программы. Однако, необходимо учитывать, что неправильное использование предварительного чтения может привести к ухудшению производительности, так как может привести к загрузке ненужных данных в кэш. Поэтому, необходимо выбирать правильные параметры для инструкций PREFETCH и настраивать аппаратную поддержку предварительного чтения в соответствии с характеристиками программы и алгоритма.
То есть Эльбрус чётко знает, с какими данными ему предстоит работать. Это ещё до того, как он с этими данными начал работу. Работает ли он с данными или же с указателем на данные, заранее известно из тэга, которым помечаются данные в регистрах. И эта информация также позволяет добиться более высокой защищённости. Есть ещё интересный момент с работой памяти. При работе с любым процессором у вас при выполнении цикла может процессор стопориться на большое количество тактов из‑за ожидания подгрузки данных для обработки.
Single Instruction Multiple Data
Архитектура Эльбрус 2000 использует специальные инструкции SIMD (Single Instruction Multiple Data), которые позволяют выполнять одну операцию над несколькими данными одновременно. Это особенно полезно в задачах, связанных с обработкой графики, звука и видео.SIMD‑инструкции в Эльбрус 2000 реализуются через специальные регистры, называемые векторными регистрами. Каждый векторный регистр может содержать несколько элементов данных одного типа, например, 16 целых чисел или 8 чисел с плавающей точкой.Для выполнения операций над векторными регистрами в Эльбрус 2000 используются специальные команды, которые могут выполнять операции над всеми элементами векторного регистра одновременно. Например, команда ассемблера «ADDV» складывает все элементы двух векторных регистров и сохраняет результат в третий векторный регистр. (Я прям чувствую как начали закипать мозги:D)
SIMD‑инструкции в Эльбрус 2000 могут быть использованы в различных областях, например:
- Обработка графики и видео: SIMD‑инструкции позволяют быстро применять эффекты к видео и изображениям, например, изменять яркость и контрастность, применять фильтры и т. д.
- Обработка звука: SIMD‑инструкции могут быть использованы для обработки аудиосигналов, например, для уменьшения шума или изменения тональности.
- Математические вычисления: SIMD‑инструкции позволяют быстро выполнять математические операции над большим количеством данных, например, для расчета физических моделей или статистических анализов.
Использование SIMD‑инструкций позволяет значительно ускорить выполнение задач, связанных с обработкой больших объемов данных. В Эльбрус 2000 SIMD‑инструкции реализованы эффективно и позволяют достичь высокой производительности при работе с векторными данными.
Также в архитектуре Эльбрус 2000 используется кэш‑память, которая позволяет ускорить доступ к данным. Кэш‑память хранит наиболее часто используемые данные, что позволяет уменьшить время доступа к ним. Смешно? Тогда вспомните, что огромное число процессоров до сих пор не умеют в L3-cache.
В целом, архитектура Эльбрус 2000 имеет ряд особенностей, которые позволяют эффективно обрабатывать данные. Применение различных алгоритмов и использование SIMD инструкций и кэш‑памяти позволяет ускорить обработку данных и повысить производительность системы.
Текстовый процессинг
Архитектура Эльбрус 2000 предоставляет несколько алгоритмов для обработки текстовых данных, которые могут быть использованы в различных приложениях.
Один из таких алгоритмов — это алгоритм сжатия данных LZO (Lempel‑Ziv‑Oberhumer). Он используется для сжатия текстовых данных и может быть применен для уменьшения размера файлов или передачи данных по сети. Алгоритм LZO работает на основе словарного кодирования, когда повторяющиеся последовательности символов заменяются одним кодом. В Эльбрус 2000 реализована оптимизированная версия алгоритма LZO, которая позволяет достигать высокой скорости сжатия и декомпрессии.
Еще один алгоритм для обработки текстовых данных — это алгоритм поиска подстроки в строке. Он может использоваться для поиска слов или фраз в тексте, а также для обработки запросов в поисковых системах. В Эльбрус 2000 реализована оптимизированная версия алгоритма Бойера‑Мура, который работает на основе сравнения символов справа налево.
Также в Эльбрус 2000 реализованы алгоритмы сортировки данных, которые могут быть использованы для обработки текстовых данных. Например, алгоритм быстрой сортировки (QuickSort) может быть использован для сортировки больших массивов строк. В Эльбрус 2000 реализована оптимизированная версия алгоритма QuickSort, которая работает на основе разделения массива на подмассивы и их параллельной сортировки.
В целом, архитектура Эльбрус 2000 предоставляет широкий набор алгоритмов для обработки текстовых данных, которые могут быть использованы в различных приложениях. Они отличаются высокой производительностью и оптимизацией под архитектуру процессора Эльбрус 2000.
Источники
- PDF: Руководство по эффективному программированию на платформе «Эльбрус»
- PDF: Кремнивые секреты
- Полезное: Шпаргалка по Assembler x86
- Видео: Архитектура процессора Эльбрус 2000 / Дмитрий Завалишин (Digital Zone)
- История: История компьютеров Эльбрус
Архитектура «Эльбрус»

Оригинальная 64-битная Little Endian VLIW; также известна как «Эльбрус-2000» (сокращённо e2k).
Не путать со SPARC и иными RISC, а также x86 (CISC).

Архитектура ядра Эльбрус
Версии
Микропроцессоры «Эльбрус» различаются версиями микроархитектуры и системы команд; на март 2022 года известны следующие:
- v2: «Эльбрус-2С+», «Эльбрус-2СМ» (устарела с лета 2018 [1] )
- v3: «Эльбрус-4С» (уходящая) e4c, он же e2s
- v4: «Эльбрус-8С», «Эльбрус-1С+» (предыдущая серийная) e8c, он же p1; и e1cp, он же e1c+ или p2
- v5: «Эльбрус-8СВ» (серийная, расширенные векторные вычисления) e8c2, он же p9
- v6: «Эльбрус-16С», «Эльбрус-12С», «Эльбрус-2С3» (инженерные образцы, аппаратнаявиртуализация) e16c, e12c, e2c3
- v7: «Эльбрус-32C», «Эльбрус-4C3» (перспективная) e32c, e4c3
Безопасность
Одной из ключевых особенностей e2k в любом режиме является наличие трёх аппаратных стеков — с одной стороны это исключает срыв стека, с другой — добавляет проблем при переносе ПО, которое пытается с предположительно единственным стеком крутить свои «штучки» (начиная с JIT).
В защищённом режиме добавляется тегирование памяти, исключая ещё и переполнение массива.
Совместимость
В процессе портирования Альта была отмечена отличная практическая совместимость процессоров четвёртого поколения с бинарным кодом e2kv3, включая ядро, видеоподсистему и даже бинарный транслятор; официально она не гарантируется, хотя неофициально и подтверждается.
Также наблюдается хорошая совместимость v5-машин с кодом v4+ и достаточная как минимум для rescue-образа работоспособность кода v3+ на v6.
Производительность
При сборке под e2k для производительности и совместимости следует применять компилятор, настроенный под конкретную версию архитектуры (начиная с lcc 1.23 — возможна настройка и под конкретный процессор).
При этом разница по 7za b , собранным под v3 и v4, на v4 составила у нас порядка процента.
Известно, что при переходе на e2kv6 «штраф» бинарникам, оптимизированным под предыдущие версии архитектуры, в ряде случаев вырастет, т.к. вследствие значительного роста тактовой частоты сильно изменятся планируемые задержки при работе с памятью и не ожидающий этого код будет чаще попадать на останов конвейера.
В то время как компилируемый код благодаря большим возможностям оптимизации (в т.ч. выявления и задействования скрытого параллелизма) во время компиляции находится в потенциально выигрышном положении по сравнению с суперскалярными архитектурами, виртуальные машины для байткода и интерпретаторы симметрично находятся в положении проигрышном (для их работы характерна высокая степень зависимости по данным в циклах). Это стоит учитывать при планировании разработки.
Ссылки
- Руководство по эффективному программированию на платформе «Эльбрус»
- Система команд микропроцессора «Эльбрус»
- Основные принципы архитектуры Е2К (2001)
Отечественные микропроцессоры: Elbrus E2K
Хотя потенциальные заказчики, вероятно, уже устали от долгого ожидания создаваемого HP и Intel микропроцессора Merced, к нему сохраняется высокий интерес. Причины этого вызваны в первую очередь революционными изменениями в архитектуре
данного процессора, которую разработчики охарактеризовали как «пост-RISC». Появившиеся весной данные о разработке группой российских компаний «Эльбрус» МП E2K [1,2] представляют большой интерес, поскольку в них реализованы все основные особенности, позволившие Intel и HP заявлять о наступлении эры новых микропроцессорных архитектур. Анализу характеристик E2K и посвящена настоящая публикация.
К моменту объявления о разработке Мerced в развитии линии RISC-процессоров, по мнению части специалистов, стали проявляться некоторые «предкризисные явления». Среди все усложняющихся проблем можно отметить сложность логики, обеспечивающей загрузку функциональных исполнительных устройств (ФУ); проблемы пропускной способности и задержек при обращении к разным уровням иерархии памяти — от кэша до оперативной памяти (ОП); проблемы предсказания переходов и др. Нерешенность этих проблем грозит простоями ФУ современных суперскалярных микропроцессоров, т.е. понижением КПД их работы.
Предложенные в IA-64 архитектурные идеи близки к известной концепции VLIW (Very Large Instruction World — сверхбольшое командное слово). С точки зрения автора, из данных, представленных разработчиками IA-64, можно выделить два наиболее принципиальных нововведения по сравнению с процессорами RISC-архитектуры: применение технологии явного параллелизма на уровне команд (EPIC — Explicitly Parallel Instruction Computing) и применение предикатных вычислений [3]. В сочетании с новым уровнем спекулятивных вычислений это значительно уменьшает количество условных переходов и, соответственно, ошибочных предсказаний направления переходов. В свою очередь, применение EPIC как некоего, грубо говоря, модернизированного варианта VLIW, однозначно диктует появление в архитектуре большого числа ФУ и сверхбольших файлов регистров.
Между тем близкий к этому подход уже был реализован в России — в произведенном в единственном экземпляре суперкомпьютере Эльбрус-3 [1, 4], выпущенном в 1991 году. В целом, по мнению автора [1], архитектуры IA-64 и E2K весьма сходны. Это позволяет думать об определенном российском приоритете в этой области.
Прежде чем перейти собственно к обсуждению процессора E2K, следует сказать несколько слов по поводу VLIW. Хотя идеи VLIW сформулированы уже давно, до настоящего времени они были известны в основном специалистам в области компьютерных архитектур. Имеющиеся реализации, например, VLIW Multiflow, не получили широкого распространения. Пожалуй, единственными популярными процессорами, архитектура которых близка к VLIW, была линия AP-120B/FPS-164/FPS-264 компании Floating Point Systems, которые в 80-е годы активно применялись при проведении научно-технических расчетов.
Команда в этих системах содержала ряд полей, каждое из которых управляло работой отдельного блока процессора, так что все командное слово определяло поведение всех блоков процессора [5]. Однако длина команды в FPS-х64 была равна всего 64 разрядам, что по современным меркам никак нельзя отнести к сверхбольшим.
Выделение в архитектуре VLIW компонентов командного слова, управляющих отдельными блоками МП, вводит явный параллелизм на уровень команд. Задача обеспечения эффективного распараллеливания работы отдельных блоков возлагается при этом на компилятор, который должен сгенерировать машинные команды, содержащие явные указания на одновременное исполнение операций в разных блоках. Таким образом, достижение параллелизма, обеспечиваемое в современных суперскалярных RISC-процессоров их аппаратурой, в VLIW возлагается на компилятор. Очевидно, что это вызывает сложные проблемы разработки соответствующих компиляторов. При этом распараллеливание работы между ФУ в EPIC происходит статически при компиляции, в то время как современные суперскалярные RISC-процессоры осуществляют это динамически.
Архитектура E2K
Структура команд и регистры E2K
Обсуждение архитектуры E2K естественно начать с формата команды. В классическом варианте VLIW длина команды фиксирована. Это приводит к значительному дополнительному расходу памяти под коды программы и, как следствие, к неэффективному использованию программного кэша. Кроме того, это является ограничением на «масштабируемость» микропроцессора. Здесь под масштабируемостью мы имеем в виду возможность наращивать число ФУ (в новых поколениях микропроцессоров), не требующую изменения программных кодов.
В IA-64 по 3 команды объединяются в так называемые связки (bundle) длиной 128 разрядов. В формат команд вводятся специальные разряды маски (template bits), которые указывают на зависимости между командами [6]. Разряды маски указывают как на зависимости внутри одной связки, так и на зависимости между связками команд. Наличие такой зависимости подавляет возможность параллельного выполнения соответствующих операций. Как известно, в RISC-процессоре подобные взаимозависимости определяются аппаратно.

Рис.1. Структура команды E2k В E2K используется иной подход, базирующийся на применении команд переменной длины. Общий формат команд E2K представлен на рис. 1. Команда E2K состоит из слогов длиной 32 разряда каждый. Число этих слогов может меняться от 2 до 16, причем данную архитектуру можно еще расширить — до 32 слогов.
Любая команда всегда включает 1 слог заголовка и еще от 1 до 15 слогов, указывающих на операции, которые могут выполняться параллельно. Слог заголовка содержит информацию о структуре команды и ее длине, что облегчает дешифрацию команды переменной длины.
Таблица 1. Типы команды слогов E2K
Содержание слога Число слогов Заголовок 1 Операции АЛУ 6 Управление подготовкой перехода 3 Дополнительные операции АЛУ при зацеплении 2 Загрузка из буфера предварительной выборки массивов в регистр 4 Литеральные константы для ФУ 4 Логические операции с предикатами 3 Предикаты и Маски для управления ФУ 3 Если не считать заголовок, в архитектуре E2K имеется 7 типов слогов (табл. 1). В команде может быть представлено сразу несколько слогов одного типа, максимальное число которых указано в последнем столбце данной таблицы. Количество и типы слогов в команде E2K задаются в ее заголовке.
Применение заголовка позволяет не проводить предварительного декодирования команд перед их помещением в кэш команд. Отрицательной стороной введения поля заголовка является некоторое увеличение длины команды.
Слоги должны располагаться слева направо в определенном порядке, — в том, в котором они указаны в табл. 1 сверху вниз. Если какой-то тип слогов в команде отсутствует, последующие слоги в команде как бы занимают их место.
Естественно, в архитектуре E2K представлен сверхбольшой файл регистров. Все регистры E2K являются универсальными и могут содержать как целочисленные данные, так и числа с плавающей запятой. Всего имеется 256 регистров длиной по 64 разряда каждый. Это резко выделяет E2K среди практически всех современных микропроцессоров, в которых регистры общего назначения отделены от регистров с плавающей запятой. Для сравнения, в IA-64 имеется 128 целочисленных регистров и 128 регистров с плавающей запятой [6]. Динамическое выделение из общего пула регистров в соответствии с тем, какого типа данные требуются, позволяет более оптимально использовать емкость файла регистров.
Интересно сравнить характеристики E2K не только с Merced, подробные данные по которому отсутствуют, но и с ведущими по производительности RISC-процессорами Alpha 21264 [7]. Так, число целочисленных регистров в этом процессоре равно 80 (этот файл регистров продублирован, см. ниже), а число регистров с плавающей запятой — 72.
Здесь необходимо обратиться к одной общей особенности Alpha 21264 и E2K — наличию в их микроархитектуре понятия кластера. Оба процессора содержат по 2 кластера. Причиной введения кластеров является ориентация на высокие тактовые частоты —
1 ГГц и выше. В этом случае время распространения сигнала становится определяющей величиной, и возникает потребность размещать часто обменивающиеся информацией блоки процессора рядом друг с другом. Реализовать это на достижимом уровне плотности упаковки не удается, поэтому разработчики обоих процессоров выделили по две области (кластера), внутри которых логические блоки процессоров расположены достаточно близко друг к другу.
Кластеры обоих микропроцессоров содержат, в частности, по 1 копии файла регистров (в Alpha 21264 — только целочисленных) и ФУ, причем в отношении последних кластеры в Alpha 21264 не являются симметричными, а в E2K — почти симметричны. В E2K каждый кластер содержит по 256 регистров (рис. 2). Всего в этом процессоре имеется 30 регистровых портов: 20 портов чтения (по 10 портов на кластер) и 10 портов записи. Для сравнения, в Alpha 21264 у целочисленных регистров имеется 8 портов чтения (по 4 на кластер) и 6 портов записи.
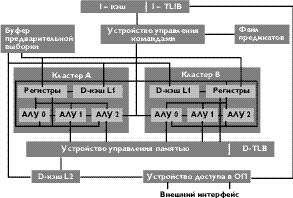
Рис.2. Упрощенная схема E2K В Alpha 21264 применяется реализованное во многих суперскалярных процессорах динамическое переименование регистров. Этого механизма в E2K нет, так как в нем подобные задачи возлагаются на компилятор, однако в циклах с постоянным шагом применяется аналогичная схема циклической замены используемых регистров. А именно, набор используемых в цикле регистров можно представить в виде некоторого окна, накладываемого на регистровый файл. На начало этого окна указывает специальный регистр базы.
Когда происходит переход на следующую итерацию цикла, регистр базы увеличивается на размер окна, что эквивалентно продвижению окна вперед по файлу регистров на столько регистров, сколько их имеется в окне. Такой механизм позволяет, очевидно, производить одновременное выполнение команд из разных итераций цикла.
Любопытно, что Дифендорфф, автор первой подробной статьи об E2K, опубликованной в бюллетене Microprocessor Report [1], предположил, что в Merced будет использоваться раскрутка (unrolling) циклов с программным переименованием регистров, что должно увеличивать размер кодов программы. Однако в феврале 1999 года разработчики из Intel и HP сообщили, что в Merced будет применяться механизм, аналогичный описанному выше, который был ими назван «вращением регистров» [6].
С целью сохранения когерентности запись производится, естественно, в регистры обоих кластеров. В обоих микропроцессорах за введение кластеров приходится расплачиваться одним дополнительным тактом на передачу данных между кластерами. К рассмотрению кластеров мы еще вернемся ниже, а сейчас упомянем об еще одной интересной особенности E2K — регистровом окне для процедуры. Это решение является традиционным для машин серии «Эльбрус», однако особенно важным оно является для E2K, поскольку он содержит сверхбольшое количество регистров — 256.
Затраты на сохранение/восстановление регистров в данной ситуации становятся весьма значительными. Поэтому реализация в E2K аппаратного механизма переключения окон представляется актуальной. В отличие от архитектуры SPARC [8], в которой также используется этот подход, окно регистров в E2K имеет переменную длину (до 192 регистров). Адресация регистров внутри контекста происходит относительно текущей базы, и при вызове другой процедуры достаточно сменить значение базы.
Этот механизм — фактически такой же, как и рассмотренный выше механизм работы с итерациями цикла. Файл регистров рассматривается при этом как циклический буфер с окном переменного размера. При исчерпании файла регистров аппаратура E2K помещает часть регистров в стек оперативной памяти, освобождая место для нового окна. При возврате из процедуры в этом случае будет аппаратно проделана обратная операция. Минусом такого подхода являются накладные расходы — необходимость суммирования относительного регистрового адреса с базой, что потребовало в E2K введения дополнительной стадии в конвейер [1].
Разработчики E2K приняли в недавние времена довольно малораспространенную схему с размещением на основной микросхеме двух уровней кэш-памяти. Сегодня такая схема уже не редкость: можно упомянуть Intel Сeleron, AMD K6-3 и DEC Alpha 21164. Лишь последний является высокопроизводительным 64-разрядным процессором. Поэтому двухуровневое строение кэша микропроцессора E2K, предполагающее применение еще и внешней кэш-памяти третьего уровня, естественно сопоставлять лишь с
Alpha 21164 [9]. C другой стороны, ввиду отсутствия достаточных данных о Merced полезно сопоставить E2K c Alpha 21264 (табл. 2).
Таблица 2. Сравнительные характеристики E2K и Alpha 21264
E2K Alpha 21264 I-кэш L1 Емкость, Кбайт 64 64К Тип 4-канальный частично ассоц. 2-канальный частично ассоц. Время доступа 2 такта 3 такта D-кэш L1 Емкость, Кбайт 8 + 8 64 Тип прямоадресуемый 2-канальный частично ассоц. Время доступа 2 такта 3 такта D-кэш L2 Емкость 256 Кбайт Кэш второго уровня является внешним Тип 2-канальный частично ассоц. Время доступа 8 тактов I-TLB Емкость 64 строки 128 строк D-TLB Емкость 16 строк (ассоц.)+256 строк 4-канальн. частично ассоц. 128 строк (ассоц.) Регистры Число по 256 на кластер 80×2 целоч., 72 веществ. Число портов 20 чтения, 10 записи 8 чтения, 6 записи (целоч.) Тактовая частота, МГц 1200 500-667 (*) Число транзисторов 28 млн. 15,2 млн. Площадь, кв. мм 126 302 Рассеяние тепла, Вт 35 60 Технология, мкм 0,18 0,35(*) SPECint95 135 30 SPECfp95 350 60 (*) При 0,18 мкм -технологии (EV68) частота — до 1 ГГц.
Кэш данных первого уровня в E2K имеет емкость всего 8 Кбайт (как у Alpha 21164) и продублирован в каждом из кластеров (рис. 2). Этот кэш, как и в Alpha 21164, является прямоадресуемым. Обе «половинки» кэша данных первого уровня в обоих кластерах содержат одинаковые данные и имеют по 2 порта. Данный кэш использует алгоритм сквозной записи данных, что, вероятно, вызвано наличием внутри кристалла кэша второго уровня, и является не блокирующим. Время доступа в кэш первого уровня равно «стандартным» для большинства процессоров
2 тактам, в отличие от Alpha 21264, где оно равно 3 тактам для загрузки целочисленного регистра и 4 тактам — для загрузки числа с плавающей запятой. Пропускная способность кэша первого уровня (при попадании) превышает 38 Гбайт/с, что можно сопоставить с пропускной способностью файла регистров — 288 Гбайт/с (данные для частоты 1,2 ГГц).
Интересно, что, как утверждают разработчики, непопадание в кэш данных первого уровня в E2K никогда не останавливает работу микропроцессора. Этот кэш имеет буфер адресов отсутствующих строк кэша. Обычно кэш данных второго уровня успевает заполнить кэш первого уровня до того, как этот буфер переполнится. Если же это все-таки произойдет, новые запросы к памяти будут направлены прямо в кэш второго уровня.
Кэш данных второго уровня в E2K имеет емкость 256 Кбайт при времени доступа в 8 тактов. Он является двухканальным частично-ассоциативным и имеет 4 банка, то есть обеспечивает
4-кратное расслоение кэш-памяти. В отличие от кэша первого уровня, в кэше данных второго уровня применяется алгоритм обратной записи. Кэш второго уровня также является неблокирующим.
Если входные буферы кэша второго уровня будут переполнены, то E2K остановится. При непопадании в кэш второго уровня будет происходить обращение к внешнему интерфейсу оперативной памяти, причем «системная шина» может управлять до 64 запросами для различных строк кэша второго уровня, что является очень высоким показателем.
По сравнению с Alpha 21164, при близких характеристиках кэша данных первого уровня, кэш данных второго уровня в E2K имеет гораздо большую емкость (в Alpha 21164 она равна
96 Кбайт, и этот кэш содержит команды и данные), а время доступа во вторичный кэш E2K (в тактах) меньше. Тем не менее автору остается неясным, почему разработчики E2K выбрали подобную «опасную» схему построения кэша данных. Известно, что Alpha 21164 из-за большого числа непопаданий в кэш данных первого уровня на широком классе приложений весьма часто «простаивает». Возможным ответом здесь является архитектурная поддержка в E2K команд спекулятивной загрузки, допускающая вынос вперед таких операций через границу базовых блоков с целью их предварительного выполнения. Спекулятивная загрузка представлена и в архитектуре IA-64 [6].
Разработчики Alpha 21264 отказались от двухуровневой схемы кэша в процессоре в пользу традиционной одноуровневой схемы. Емкость кэша первого уровня в этом процессоре меньше, чем кэша данных второго уровня в E2K. Хотя в Alpha 21264 кэш данных имеет трехтактный доступ, он может выдавать 2 результата за такт.
Разработчики E2K утверждают, что выбранная схема построения кэша не создает узких мест. Очевидно, что «полная» неблокируемость кэша данных первого уровня говорит в пользу выбранной схемы. Критерий истины, как известно, практика. Высокие оценочные характеристики, полученные разработками для тестов SPECint95/fp95 (табл. 2), являются определенным свидетельством эффективности принятого решения по строению кэша E2K.
Как и сама кэш-память, буфер быстрой переадресации (TLB) в E2K имеет двухуровневую иерархию: 16 строк полностью ассоциативной памяти плюс 512 строк TLB второго уровня (последний является 4-канальным частично-ассоциативным со временем доступа 2 такта). При этом поддерживается до 4 одновременных преобразований адресов при обращении в кэш второго уровня или к оперативной памяти.
При непопадании в TLB первого уровня процессор останавливается на 4 такта. В случае непопадания в TLB второго уровня время ожидания процессора составит от 10 до примерно 200 тактов в зависимости от числа требуемых просмотров в таблице страниц и ситуации с попаданием/непопаданием в кэши второго и третьего уровня. Емкость TLB второго уровня выглядит достаточно большой (так, в Alpha 21264 TLB имеет лишь 128 строк), поэтому более реальная опасность — непопадание в TLB первого уровня. Отметим, что при работе с кэшем первого уровня TLB вообще не нужен, так как этот кэш индексируется и тегируется виртуально (в отличие от кэша второго уровня).
Учитывая большую ширину команды, не удивительно, что разработчики E2K особо позаботились о пропускной способности кэша команд первого уровня, имеющего емкость 64 Кбайт при длине строки 256 байт. Этот кэш является 4-канальным частично ассоциативным. Ширина тракта, по которому команды из кэша команд поступают в устройство управления командами, составляет аж
256 байт. Однако максимальная скорость заполнения кэша команд cоставляет 32 байта за такт, что может создать узкое место в микроархитектуре E2K, если коды не будут почти линейными [1]. Буфер TLB для команд имеет емкость 64 строки и является полностью ассоциативным.
Кроме рассмотренных типов кэш-памяти в E2K представлен специализированный кэш предварительной выборки, который разработчики назвали буфером предварительной подкачки. Он является частью устройства доступа к массивам (этот блок на рис.2 не представлен) и задействуется только при работе с массивами в циклах. Его емкость составляет всего 4 Кбайт, и он состоит из 2 банков с 2 портами в каждом из них. За один такт в буфер можно считать, следовательно, до 4 слов длиной 8 байт. Буфер организован как очередь FIFO и имеет до 64 зон предварительной выборки.
Задача этого буфера — та же, что и у работающих с ним команд типа «prefetch», имеющихся у многих современных процессоров (SGI R10000, Intel Pentium III, AMD K6-3 и т.д.): обеспечить возможность предварительной выборки данных заранее, до того, как они реально понадобятся, а в данном случае — опережающей выборки в цикле. Такая выборка, происходящая одновременно с выполнением тела цикла, позволяет скрыть задержки при обращении к оперативной памяти. Важно, что эта особенность E2K позволяет ускорить работу с операциями типа «сборки» (gather), когда выбираются несмежные элементы массива.
Ясно, что для микропроцессора высшего уровня производительности кэша второго уровня емкостью
256 Кбайт мало, и необходимо комплектовать процессор еще и внешним кэшем третьего уровня. В Е2К предусматриваются два варианта подключения третьего уровня — кэш: непосредственно к процессору Е2К, что позволяет разгрузить «системную шину» — коммутатор, или через набор коммутаторных микросхем.
Как и у многих современных RISC-процессоров, в частности, Sun UltraSPARC и Alpha 21264, вместо системной шины в E2K будет применяться коммутатор. В наборе микросхем планируется обеспечить поддержку
600-мегагерцевой памяти, построенной по технологии RAMBUS. В Е2К предусмотрено два независимых порта по 32 байта каждый, работающие на частоте 400-600 МГц.
Функциональные устройства
ФУ E2K, как это уже было указано выше, разнесены по двум кластерам (рис. 2). В отличие от Alpha 21264, эти кластеры содержат по 3 одинаковых целочисленных конвейера — АЛУ (правда, один из кластеров имеет также ФУ деления — целочисленного и с плавающей запятой). Такая симметрия кластеров по АЛУ дает преимущество по сравнению с Alpha 21264, поскольку практически любая команда может быть направлена в любой кластер.
В каждом кластере представлены также адресные сумматоры (на рис. 2 не указаны), которые имеются для 2 из 3 путей («каналов») данных. В результате каждый кластер может одновременно выполнять до 2 операций загрузки регистров или 1 операцию записи в оперативную память; cоответственно 2 кластера — до 4 операций загрузки регистров или до 2 записей в оперативную память. Возможен и смешанный случай: 2 загрузки плюс одна запись.
Кроме того, имеется 4 канала для данных с плавающей запятой, по 2 на кластер. В каждом канале может выполняться команда типа MADD — «умножить-и-сложить», что дает темп 8 результатов с плавающей запятой за такт. Это вдвое больше, чем у наиболее «продвинутых» в этом смысле RISC-процессоров HP PA-8500 [10], и при тактовой частоте 1,2 ГГц дает пиковую производительность 9,6 GFLOPS. Эта величина уступает лишь векторным процессорам Hitachi S3800. Темп в 8 результатов за такт связан с особенностями реализации команды MADD: она осуществляется в форме последовательного выполнения умножения и сложения, причем результат первой части команды не помещается в регистр, а подается на вход второй части команды. Такое зацепление напоминает известную схему, реализованную еще в Cray-1. Аналогичная схема применяется также в SGI R10000, однако в нем в команде MADD задействуется сразу 2 ФУ, так что темп выдачи результатов равен числу ФУ.
Следует также отметить, что и сам набор команд E2K «богаче», чем у традиционных RISC-процессоров: в нем представлены четырехадресные команды, например, типа d=a+b+c. Такого нет и в IA-64 [6]. Что касается команд с плавающей запятой, то кроме полной поддержки IEEE754 в E2K реализована работа с 80-разрядным представлением Intel x86. При этом операнды хранятся в парах 64-разрядных регистров E2K. Правда, сложение/умножение таких чисел не полностью конвейеризовано. Кроме того, для приближения системы команд E2K к x86 в E2K реализованы также команды расширения ММХ.
Интересно сопоставить длины конвейеров E2K и Alpha 21264. В E2K целочисленный конвейер имеет длину
8 тактов (собственно выполнение идет на седьмом такте, а обратная запись — на восьмом) против 7 тактов в Alpha 21264. Длина «вещественных» конвейеров на этапе выполнения составляет
4 такта, как и в Alpha 21264. Конвейер загрузки регистров/записи в оперативную память в обоих процессорах имеет длину 9 тактов.
Таблица 3. Времена выполнения основных операций E2K (в тактах)
Операции Задержка Темп Целочисленное АЛУ 1 1 Загрузка/запись из/в кэш первого уровня 2 1 Загрузка/запись из/в кэш второго уровня 8 1 Вещественное сложение 4 1 Умножение 4-5 1 Веществ. умножение-и-сложение 8-9 1 Деление 32 разряда 10-13 2 Деление 64 разряда 10-17 2 Вещественное деление (32/64) 11/14 2 ММХ, сложение/вычитание 1 1 ММХ, умножение/деление 2 1 Однако следует отметить два важных обстоятельства: 1) в 21264 команда в среднем находится 4-5 тактов в очереди команд перед тем, как она выдается в ФУ, что увеличивает фактическую длины конвейера; 2) благодаря наличию в Е2К команды подготовки перехода, «зазор» между командой, формирующей условие перехода и самим переходом составляет всего 3 такта, что в 2 раза меньше, чем в 21264. Поэтому разработчики имеют основания утверждать, что конвейер Е2К фактически гораздо более короткий, чем в 21264. Данные о временах выполнения команд приведены в табл. 3.
Что касается количества одновременно выполняемых операций, то Е2К обеспечивает очень высокий уровень: в команде их кодируется до 23 (сюда кроме арифметико-логических операций входят также доступ в оперативную память, приращение индекса массива и т.п.). Ясно, что эффективные показатели параллельной работы ФУ у E2K выше, чем у всех суперскалярных процессоров.
Переходы и предикаты
В архитектуре E2K, как и в IA-64, делается все, чтобы по возможности исключить обычные операции перехода. Для этого в E2K имеется 32 одноразрядных регистра-предиката, причем команда способна сформировать до 7 предикатов: 4 в операциях сравнения в АЛУ и еще 3 — в операциях логики с предикатами (в 3 предикатных слогах, табл. 1).
Хотя в IA-64 предикатных регистров формально в 2 раза больше, чем в E2K, реально их практически столько же, так как в IA-64 хранятся пары — предикат и его отрицание. В IA-64 поля предикатов всегда представлены в команде, а в E2K — могут отсутствовать. Предикаты могут использоваться в канале АЛУ или в канале доступа к массивам; для указания на это используются условные слоги, содержащие маски предикатов и ФУ. Всего в этих слогах может кодироваться до 6 предикатов, указывающих на то, нужно ли выполнять соответствующие операции из «широкой» команды.
Если условие перехода удается вычислить до выполнения этого перехода, компилятор стремится применять предикатные вычисления, чтобы обойтись без перехода вообще. Если же это не удается, компилятор порождает явные спекулятивные коды. Спекулятивные вычисления в более ограниченном масштабе применяются в суперскалярных микропроцессорах (Alpha 21264, R10000 и др.), но в них этим занимается исключительно аппаратура.
Компилятор E2K порождает коды для обоих ветвей программы, возникающих при условном переходе, и, пользуясь большим числом ФУ и регистров, заставляет процессоры выполнять обе ветви программы. Та же процедура применяется и в IA-64. До тех пор, пока условие перехода остается неизвестным, обе ветви выполняются спекулятивно. Когда, наконец, условие найдено, выбираются нужные результаты. Признак спекулятивного выполнения взводится при этом в специальном бите в коде операции в соответствующем слоге. При возникновении ситуации исключения (exception) результат снабжается тегом недействительного значения. По мнению [1], это обеспечивает такие же возможности, как команды спекулятивной загрузки регистров IA-64, но реализованные в более общем виде.
Если в процессе спекулятивного выполнения условие стало известным, ненужная ветвь программы должна быть «сброшена» подобно тому, как это делается в конвейерах современных процессорах при неудачных предсказаниях переходов. Накладные расходы в подобных случаях весьма высоки (11 тактов в Alpha 21264), и разработчики процессоров стремятся к их уменьшению и увеличению точности предсказания перехода. Последнего в E2K делать нет необходимости, а для сокращения накладных расходов в E2K применяется так называемая операция подготовки перехода.
Она считывает команды из кэша по адресу перехода (или помещает их в кэш, если их там еще нет), и выполняет первые 4 стадии общего конвейера. Такая подготовка не зависит от условия перехода и может быть выполнена заранее. Когда переход происходит, команды по новому адресу частично уже будут выполнены. E2K может выполнять одновременно до трех операций подготовки перехода.
В файле предикатов E2K, как и в регистровом файле, используются окна. Этот оконный механизм предикатов E2K, как и аналогичное вращение предикатных регистров в Merced, позволяет эффективным образом организовать прологи и эпилоги циклов.
К заоблачным высотам
Мы не остановились еще на целом ряде интересных особенностей архитектуры E2K, в первую очередь на тегировании данных, поддерживаемом во всей линейке процессоров ЭВМ «Эльбрус». Среди других особенностей E2K можно отметить сегментно-страничную организацию и поддержку мультипрограммирования в стиле x86. В сочетании с разработанными средствами двоичной компиляции и специальными аппаратными средствами ее поддержки [1] это позволяет выполнять x86-коды на E2K. Поддерживается также двоичная компиляция для SPARC-архитектуры. Очевидная близость IA-64 к E2K позволяет рассчитывать и на эффективную компиляцию кодов IA-64 в будущем. По сравнению с DEC FX!32 двоичная компиляция в E2K более эффективна и допускает статическое компилирование [1].
В настоящий момент разработка E2K еще не завершена. Имеется только исполняемое описание Verilog, а детализация до уровня транзисторов еще предстоит. Для достижения планируемых показателей необходима 0,18-микронная технология изготовления. Однако E2K может достигнуть более высокой производительности (SPECint95/fp95 = 135/350), чем Merced (SPECint95/fp95=45/70 при 800 МГц [1]), при меньшей площади кристалла и меньшем энергопотреблении (табл. 2).
Мы не пытаемся здесь оценить вероятность успешного завершения проекта разработки E2K (см. [1,2]). В любом случае она представляет огромный интерес и, помимо прочего, дает нам возможность предположить, какими свойствами сможет обладать Merced.
Михаил Кузьминский (kus@free.net)— старший научный сотрудник Центра компьютерного обеспечения химических исследований РАН (Москва).
Литература
1. К. Dieffendorf, Microprocessor Report, 1999, v.13, №. 2, p. 1.
2. М. Кузьминский, «Сomputerworld Россия», 1999, № 8.
3. М. Кузьминский, «Сomputerworld Росия», 1997, № 47.
4. B.A. Babajan e.a., Elbrus Software Methodology: Instrumentation-Experience, IFIP Conference, 1989.
5. Р. Хокни, К. Джессхоуп, Параллельные ЭВМ, М., Радио и связь, 1986.
6. IA-64 Application Instruction Set Architecture Guide, Rev. 1.0, Intel, Hewlett-Packard, 1999.
7. М. Кузьминский, «Открытые системы», 1998, № 1, cтр. 7.
8. В. Шнитман, «Открытые системы», 1996, № 2, cтр. 5.
9. М. Кузьминский, «Computerworld Россия», 1995, № 2.
10. М. Кузьминский, «Открытые системы», 1997, № 3, cтр. 6.