Формула линии тренда на диаграмме неточна в Excel
Уравнение, отображаемое для линии тренда на точечной диаграмме XY в Microsoft Excel, неверно. Microsoft Excel отображает неправильную линию тренда при замене значений для переменной «x» вручную.
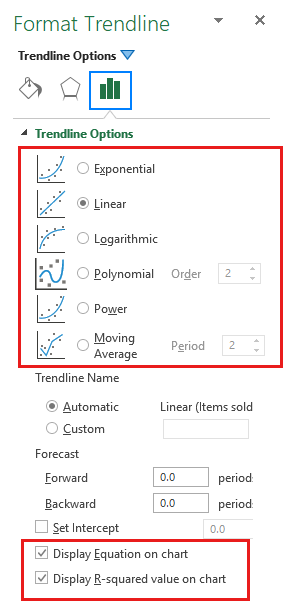
- Уравнение линии тренда — это формула, которая находит линию, которая лучше всего соответствует точкам данных.
- Величина достоверности аппроксимации (R^2) измеряет надежность линии тренда. Чем ближе R2 к 1, тем лучше линия тренда соответствует данным.
Формула линии тренда используется для точечной диаграммы XY. На этой диаграмме в качестве значений отображаются оси X и Y. Графики, гистограммы и линейчатые диаграммы отображают только ось Y в виде значений. В этих типах диаграмм ось X отображается как только линейный ряд, независимо от фактических меток. Таким образом, линия тренда будет неточной, если она отображается на диаграммах этих типов. Такое поведение является особенностью данного продукта.
Причина
Microsoft Excel неправильно отображает линии тренда, так как отображаемое уравнение может предоставлять неточные результаты при вводе значений X вручную. При отображении каждое значение X округляется до числа значащих цифр, отображаемых на диаграмме. Такое поведение позволяет уравнению занимать меньше места в области диаграммы. Однако точность диаграммы значительно снижается. Это может привести к тому, что тренд будет отображаться неправильно.
Обходной путь
Чтобы обойти это поведение, увеличьте количество цифр в уравнении линии тренда, увеличив количество отображаемых десятичных знаков. Для этого выполните следующие действия:
- На диаграмме выберите уравнение линии тренда.
- В меню Формат выберите пункт Выделенные подписи данных.
- Перейдите на вкладку Число, а затем выберите Числовой в списке Числовые форматы.
- В поле Число десятичных знаков увеличьте число десятичных знаков до 30, чтобы отобразить все десятичные знаки.
- Нажмите кнопку ОК.
Дополнительная информация
Требуется дополнительная помощь? Зайдите на сайт сообщества Майкрософт.
Величина достоверности аппроксимации r2 что показывает
1 Товарищество с ограниченной ответственность Профессиональный гуманитарно-технический колледж «Білім» Республики Казахстан
2 Республиканское государственное предприятие на праве хозяйственного ведения «Таразский государственный университет имени М.Х. Дулати» Министерства образования и науки Республики Казахстан
По результатам опытно-промышленных испытаний сушильного барабана была определена зависимость производительности барабанного агрегата от скорости теплоносителя на входе (vвх) в барабан и угла наклона барабана (a). На основе математической обработки экспериментальных данных с помощью инновационных технологий на персональном компьютере (ПК) получены уравнения регрессии линейного и полиномиального видов, и величина достоверности аппроксимации R2. Из анализа уравнений видно, что величина достоверности аппроксимации полиномиального вида R2 = 1, следовательно, уравнение регрессии адекватно эксперименту.

сушильный барабан
угол наклона
достоверность аппроксимации
1. Ахназарова С.Л., Кафаров В.В. Методы оптимизации эксперимента в химической технологии. – М.: Высшая школа, 1985. – 328 с.
2. Вадзинский Р. Статистические вычисления в среде Excel. – СПб.: Питер, 2008. – 608 с.
3. Карлберг Конрад. Бизнес-анализ с помощью Excel 2000: – Пер. с англ.: Учебное пособие. – М.: Издательский дом «Вильямс», 2000. – 480 с.
4. Корн Гранине А., Корн Тереза М. Справочник по математике для научных работников и инженеров. Определения, теоремы, формулы. – М.: Наука, 1984. – 831 с.
5. Пелих А.С. Бизнес-план или как организовать собственный бизнес: анализ, методика, практикум.
Существуют различные виды формул для расчета линий тренда (достоверности) аппроксимации.
Для аппроксимации данных по методу наименьших квадратов используются следующие виды уравнений [2], [4], [5]:
где m – угол наклона и b – координата пересечения оси абсцисс;
где b и с1 … с6 – константы;
где с и b – константы, ln – функция натурального логарифма;
где с и b – константы, е – основание натурального логарифма;
где с и b – константы.
Линии тренда обычно используются в задачах прогнозирования. Такие задачи решают с помощью методов регрессионного анализа. С помощью регрессионного анализа можно продолжить линию тренда вперед или назад, экстраполировать ее за пределы, в которых данные уже известны, и показать тенденцию их изменения. Можно также построить линию скользящего среднего, которая сглаживает случайные флуктуации, яснее демонстрирует модель и прослеживает тенденцию изменения данных.
Линиями тренда можно дополнить ряды данных, представленные на ненормированных плоских диаграммах с областями, линейчатых диаграммах, гистограммах, графиках, биржевых, точечных и пузырьковых диаграммах. Нельзя дополнить линиями тренда ряды данных на объемных диаграммах, нормированных диаграммах, лепестковых диаграммах, круговых и кольцевых диаграммах. При замене типа диаграммы на один из вышеперечисленных соответствующие данным линии тренда будут потеряны.
После того как уравнение регрессии найдено, необходимо произвести статистический анализ результатов. Этот анализ заключается в проверке значимости всех коэффициентов регрессии в сравнении с ошибкой воспроизводимости и адекватности уравнения. Такое исследование называется регрессивным анализом. Примем при проведении регрессивного анализа следующие допущения [2], [3], [5]:
1. Входной параметр х измеряется с пренебрежимо малой ошибкой по сравнению с ошибкой в определении у. Большая ошибка у объясняется наличием в каждом процессе не выявленных переменных, не вошедших в уравнение регрессии.
2. Результаты наблюдений у1, у2, …, уn, над выходной величиной у представляют собой независимые нормально распределенные случайные величины.
3. При проведении эксперимента с объемом выборки n при условии, что каждый опыт повторен m раз, i = 1, 2, …, n, выборочные дисперсии 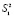 ,
, 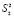 , …
, … 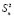 должны быть однородны.
должны быть однородны.
При одинаковом числе параллельных опытов проверка однородности дисперсии сводится к следующему [2], [3], [5]:
1. Ввод экспериментальных данных х и у в таблицу 1.
2. Используя табличные данные, строим график зависимости х и у.
3. Строим линию тренда, используя точки графика.
При построении линии тренда (аппроксимации) укажем:
– тип линии уравнения;
– степень в диапазоне от 2÷6;
– показать уравнение на диаграмме;
– поместить на диаграмму величину достоверности аппроксимации (R2)
Величина достоверности аппроксимации R2[1], [4]:
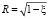
, (6)
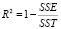
, (7)
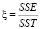
, (8)
ξ – сила связи между х и у (дисперсионное отношение по Фишеру) [2], [3]:
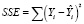
–
остаточная дисперсия; (9)
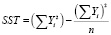
–
общая дисперсия. (10)
Связь тем сильнее, чем меньше ξ.
Чем больше R2, тем сильнее связь [2], [3], следовательно, уравнение регрессии адекватно эксперименту.
Если R = 1, то существует функциональная зависимость между, параметрами.
Однако при R = 0 величины х и у нельзя считать независимыми, так как связь между ними, не сказываясь на дисперсиях, может проявить себя в моментах более высокого порядка. И только при нормальном распределении равенство нулю корреляционного отношения однозначно свидетельствует об отсутствии связи между случайными величинами. Корреляционное отношение, как и коэффициент корреляции в линейной регрессии, характеризует тесноту связи между случайными величинами. Вообще анализ силы связи по R называют корреляционным анализом.
Зависимость производительности (G) барабанного агрегата от скорости теплоносителя (ϑвх) на входе и угла наклона барабана (α)
Число оборотов барабана
Скорость сушильного агента на входе в барабан, ϑвх, м/с
Угол наклона барабана, α о
Производительность, Gі∙10 -3 , кг/с
Величина достоверности аппроксимации r2 что показывает
Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. нет различия между фактическим и оценочным значениями y. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений y. Для получения информации о том, как вычисляется r2, см. «Заметки» в конце данного раздела.
Приведенную Вами формулу я там не нашел, поэтому предположу, что Yj — это фактические значения, yj — вычесленные по уравнению аппроксимации, n — количество значений, по которым производится вычисление.
Из справки Excel 2003
Цитата
Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. нет различия между фактическим и оценочным значениями y. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений y. Для получения информации о том, как вычисляется r2, см. «Заметки» в конце данного раздела.
Приведенную Вами формулу я там не нашел, поэтому предположу, что Yj — это фактические значения, yj — вычесленные по уравнению аппроксимации, n — количество значений, по которым производится вычисление. MCH
Сообщение отредактировал MCH — Понедельник, 28.04.2014, 15:23
Сообщение Из справки Excel 2003
Цитата
Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. нет различия между фактическим и оценочным значениями y. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений y. Для получения информации о том, как вычисляется r2, см. «Заметки» в конце данного раздела.
Приведенную Вами формулу я там не нашел, поэтому предположу, что Yj — это фактические значения, yj — вычесленные по уравнению аппроксимации, n — количество значений, по которым производится вычисление. Автор — MCH
Дата добавления — 28.04.2014 в 15:23
51. Коэффициент достоверности аппроксимации. Оценка надёжности по критерию Фишера.
Коэффициент достоверности аппроксимации это значение которое характеризует точность аппроксимации, т. е. показывает на сколько точно теоретическое распределение описывает реальное распределение.
Коэффициент достоверности аппроксимации R 2 показывает степень соответствия трендовой модели исходным данным. Его значение может лежать в диапазоне от 0 до 1. Чем ближе R 2 к 1, тем точнее модель описывает имеющиеся данные.
Критерий Фишера используется для оценки значимости модели в целом.
Для оценки используется уравнение следующего вида:
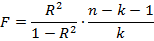
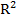
где – коэффициент детерминации, n – количество наблюдений, k – число объясняющих переменных.
Вычисленное по этой формуле значение сравнивается с критическим значением критерия Фишера из таблиц распределения Фишера:
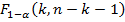
где 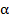 – уровень значимости,
– уровень значимости,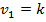 и
и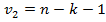 – степени свободы.
– степени свободы.
Если в результате сравнения оказывается, что 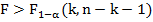 , то при заданном уровне значимости
, то при заданном уровне значимости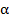 принимается гипотеза о надежности модели в целом. Если в результате сравнения оказывается, что
принимается гипотеза о надежности модели в целом. Если в результате сравнения оказывается, что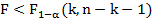 , то при заданном уровне значимости
, то при заданном уровне значимости гипотеза о надежности модели в целом отвергается.
гипотеза о надежности модели в целом отвергается.
52. Понятие экстраполяции (прогнозирование результатов измерений)
Экстраполяция— это метод прогнозирования, который предполагает, что закономерность развития, действовавшая в прошлом, сохранится и в прогнозируемом будущем.
53. Фундаментальная теорема переноса ошибок имеет вид:
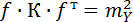 где
где 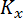 — корреляционная матрица,
— корреляционная матрица, 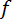 – матрица производных функций
– матрица производных функций 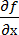 . Эта формула применяется при оценке функций.
. Эта формула применяется при оценке функций.
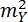
– это дисперсия DY.
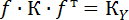
Если оценивается несколько функций, то матрица f будет являться матрицей Якоби (используем формулу ).
Получим ковариационную матрицу, диагональные элементы которой соответствуют дисперсии, корень из дисперсии будет соответствовать СКО функций.
Если мы имеем функцию суммы или разности двух независимых величин
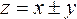
, то квадрат средней квадратической ошибки функции выразится формулой
mz 2 =mx 2 +my 2 При 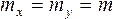
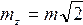
Если функция имеет вид
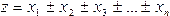
,
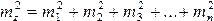
то (14)
т. е. квадрат средней квадратической ошибки алгебраической суммы аргументов равен сумме квадратов средних квадратических ошибок слагаемых.
Если m1=m2=m3=…=mn=m,то формула(14) примет вид
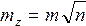 т. е. средняя квадратическая ошибка алгебраической суммы (разности) измеренных с одинаковой точностью величин в
т. е. средняя квадратическая ошибка алгебраической суммы (разности) измеренных с одинаковой точностью величин в 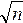 раз больше средней квадратической ошибки одного слагаемого.
раз больше средней квадратической ошибки одного слагаемого.
Если функция имеет вид
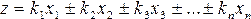
То 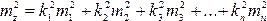 где k1, k2, kз, . kп — постоянные числа; m1,m2,m3. тп — средние квадратические ошибки соответствующих аргументов. Если имеем функцию многих независимых переменных общего вида
где k1, k2, kз, . kп — постоянные числа; m1,m2,m3. тп — средние квадратические ошибки соответствующих аргументов. Если имеем функцию многих независимых переменных общего вида
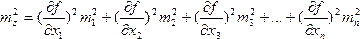
то . (15)
Из формулы (15) следует, что квадрат средней квадратической ошибки функции общего вида равен сумме квадратов произведений частных производных по каждому аргументу на среднюю квадратическую ошибку соответствующего аргумента
54. Оценка точности функций зависимых результатов измерений.
Формулы для вычислений средних квадратических ошибок функции u=f(x1,x2,….xn)
а) в случае некоррелированных аргументов :
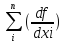
mu 2 =0 2 mxi 2
б) для коррелированных аргументов
mu 2 =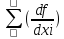 0 2 mxi 2 +2
0 2 mxi 2 +2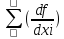 0
0 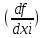 0 rxi xj mxi mxj
0 rxi xj mxi mxj
Для системы функций (вектор-функции) u = f(X)
Mu 2 = AM 2 xA T где Mu 2 и M 2 x — соответственно эмпирическне корреляционные матрицы вектор-функции и вектора измерений. А — Матрица