Big Data: что такое большие данные и где они применяются
В статье расскажем о характеристиках и классификации больших данных, методах обработки и хранения, областях применения и возможностях работы с Big Data, которые дает Selectel.

Big Data простыми словами — структурированные, частично структурированные или неструктурированные большие массивы данных. В статье мы расскажем о характеристиках и классификации больших данных, методах обработки и хранения, областях применения и возможностях работы с Big Data, которые дает Selectel.
Характеристики больших данных
Несмотря на актуальность для многих сфер, границы термина размыты и могут отличаться в зависимости от конкретной задачи. Тем не менее существуют три основных признака, определенные еще в 2001 году Meta Group. Они получили аббревиатуру VVV:
Volume. Объем данных чаще всего измеряется терабайтами, петабайтами и даже эксабайтами. Нет точного понимания, с какого объема данные становятся «большими». Существуют задачи, когда информация занимает меньше терабайта, но из-за неоднородной структуры их обработка требует мощности кластера из пяти серверов.
Velocity. Скорость прироста и обработки данных. Яркий пример — новые данные для анализа появляются с каждым сеансом пользователя «ВКонтакте». Подобные потоки информации требуют высокоскоростной обработки. Если для обработки данных достаточно одной машины, это не Big Data. Число серверов в кластере всегда превышает единицу.
Variety. Разнообразие данных. Даже если информации очень много, но она имеет четкую и ясную структуру — это не Big Data. Возвращаясь к примеру с «ВКонтакте», биографии пользователей соцсети структурированные и легко поддаются анализу. А вот данные о реакциях на посты или времени, проведенном в приложении, не имеют точной структуры.
И еще два V
В дальнейшем появилась интерпретация c «пятью V»:
Viability. Жизнеспособность данных. При большом разнообразии данных и переменных, необходимо проверять их значимость при построении модели прогнозирования. Например, факторы предсказывающие склонность потребителя к покупке: упоминания товара в соцсетях, геолокация, доступность товара, время суток, портрет покупателя.
Value. Ценность данных. После подтверждения жизнеспособности специалисты Big Data изучают взаимосвязи данных. Например, поставщик услуг может попытаться сократить отток клиентов, анализируя продолжительность звонков в колл-центр. После оценки дополнительных переменных прогнозная модель становится сложнее и эффективнее. Пример итогового вывода — повышенную склонность к оттоку в течение 45 дней после своего дня рождения демонстрируют клиенты попадающие в категории:
- геопозиция — юго-запад России с теплой погодой,
- образование — степень бакалавра,
- имущество — владельцы автомобилей 2012 года выпуска или более ранних моделей,
- кредитная история без просрочек.
Классификация данных
Структурированные данные. Как правило, хранятся в реляционных базах данных. Упорядочивают данные на уровне таблиц — например, Excel. От информации, которую можно анализировать в самом Excel, Big Data отличается большим объемом.
Частично структурированные. Данные не подходят для таблиц, но могут быть иерархически систематизированы. Под такую характеристику подходят текстовые документы или файлы с записями о событиях.
Неструктурированные. Не обладают организованной структурой: аудио- и видеоматериалы, фото и другие изображения.
Источники данных
- Генерируемые людьми социальные данные, главные источники которых — соцсети, веб, GPS-данные о перемещениях. Также специалисты Big Data используют статистические показатели городов и стран: рождаемость, смертность, уровень жизни и любую другую информацию, отражающую показатели жизни людей.
- Транзакционная информация появляется при любых денежных операциях и взаимодействии с банкоматами: переводы, покупки, поставки.
- Источником машинных данных служат смартфоны, IoT-гаджеты, автомобили и другая техника, датчики, системы слежения и спутники.
Как данные забирают из источника
Начальная стадия — Data Cleaning — выявление, очистка и исправление ошибок, нерелевантной информации и несоответствий данных. Процесс позволяет оценить косвенные показатели, погрешности, пропущенные значения и отклонения. Как правило, во время извлечения данные преобразуются. Специалисты Big Data добавляют дополнительные метаданные, временные метки или геолокационные данные.
Существует два подхода к извлечению структурированных данных:
- Полное извлечение, при котором нет потребности отслеживать изменения. Процесс проще, но нагрузка на систему выше.
- Инкрементное извлечение. Изменения в исходных данных отслеживают с момента последнего успешного извлечения. Для этого создают таблицы изменений или проверяют временные метки. Многие хранилища имеют встроенную функцию захвата данных об изменениях (CDC), которая позволяет сохранить состояния данных. Логика для инкрементального извлечения более сложная, но нагрузка на систему снижается.
При работе с неструктурированными данными большая часть времени уйдет на подготовку к извлечению. Данные очищают от лишних пробелов и символов, удаляют дубликаты результатов и определяют способ обработки недостающих значений.
Подходы к хранению Big Data
Для хранения обычно организуют хранилища данных (Data Warehouse) или озера (Data Lake). Data Warehouse использует принцип ETL (Extract, Transform, Load) — сначала идет извлечение, далее преобразование, потом загрузка. Data Lake отличается методом ELT (Extract, Load, Transform) — сначала загрузка, следом преобразование данных.
Существуют три главных принципа хранения Big Data:
Горизонтальное масштабирование. Система должна иметь возможность расширяться. Если объем данных вырос — необходимо увеличить мощность кластера путем добавления серверов.
Отказоустойчивость. Для обработки требуются большие вычислительные мощности, что повышает вероятность сбоев. Большие данные должны обрабатываться непрерывно в режиме реального времени.
Локальность. В кластерах применяется принцип локальности данных — обработка и хранение происходит на одной машине. Такой подход минимизирует расходы мощностей на передачу информации между серверами.
Анализ больших данных: от web mining до визуализации аналитики
Интеллектуальный анализ данных представляет из себя совокупность подходов к классификации, моделированию и прогнозированию.
Анализ может включать в себя добычу различных видов информации, будь то текст, изображения, аудио- и видеоданные. Отдельно выделяют web mining и social media mining, работающие с интернетом и соцсетями. Для работы с реляционными базами данных используется язык программирования SQL, подходящий для создания, изменения и извлечения хранимых данных.
Нейронные сети. Обученная нейросеть может обрабатывать огромные объемы данных с большой скоростью и точностью. Чтобы использовать нейросеть в анализе, ее необходимо обучить.
Машинное обучение — наука о том, как обучить ИИ самостоятельной работе и расширению своих знаний и возможностей. Сфера ML изучает, как создавать системы, которые автономно улучшаются с приобретением опыта. Алгоритмы машинного обучения обобщают уже имеющиеся примеры для выполнения более сложных задач. С помощью этой технологии искусственный интеллект проводит анализ, строит прогнозы, воспроизводит и улучшает модели.
После анализа данные представляют в виде аналитического отчета с предложениями о возможных решениях. Методы перевода больших данных в читаемую форму называются Business intelligence. Главный инструмент BI — дашборды, интерпретация и визуализация аналитики в виде изображений и диаграмм. Дашборды помогают фокусировать внимание на KPI, создавать бизнес-модели и отслеживать результаты принятых решений.
Эта обратная связь и дает возможности для роста бизнеса, которые можно получить с помощью Big Data. Неочевидные раньше закономерности способствуют улучшению бизнес-процессов и росту прибыли.
Работайте с Big Data на инфраструктуре Selectel
От серверов с мощными GPU до полноценной платформы обработки данных.
Инструменты для обработки больших данных
Один из способов распределенных вычислений — разработанный Google метод параллельной обработки MapReduce. Фреймворк организовывает данные в виде записей. Функции работают независимо и параллельно, что обеспечивает соблюдение принципа горизонтальной масштабируемости. Обработка происходит в три стадии:
- Map. Функцию определяет пользователь, map служит начальной обработке и фильтрации. Функция применима к одной входной записи, она выдает множество пар ключ-значение. Применяется на том же сервере, на котором хранятся данные, что соответствует принципу локальности.
- Shuffle. Вывод map разбирается по «корзинам». Каждая соответствует одному ключу вывода первой стадии, происходит параллельная сортировка. «Корзины» служат входом для третьей стадии.
- Reduce. Каждая «корзина» со значениями попадает на вход функции reduce. Ее задает пользователь и вычисляет финальный результат для каждой «корзины». Множество всех значений функции reduce становится финальным результатом.
Для разработки и выполнения программ, работающих на кластерах любых размеров, используется набор утилит, библиотек и фреймворк Hadoop. ПО Apache Software Foundation работает с открытым исходным кодом и служит для хранения, планирования и совместной работы с данными. Об истории и структуре проекта Hadoop можно почитать в отдельном материале.
Apache Spark — open-source фреймворк, входящий в экосистему Hadoop, используется для кластерных вычислений. Набор библиотек Apache Spark выполняет вычисления в оперативной памяти, что заметно ускоряет решение многих задач и подходит для машинного обучения.
NoSQL — тип нереляционных СУБД. Хранение и поиск данных моделируется отличными от табличных отношений средствами. Для хранения информации не требуется заранее заданная схема данных. Главное преимущество подобного подхода — любые данные можно быстро помещать и извлекать из хранилища. Термин расшифровывается как «Not Only SQL».
Примеры подобных СУБД
Все базы данных относятся к «семейству» Amazon:
- DynamoDB — управляемая бессерверная БД на основе пар «ключ-значение», созданная для запуска высокопроизводительных приложений в любом масштабе, подходит для IoT, игровых и рекламных приложений.
- DocumentDB — документная БД, создана для работы в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем.
- Neptune — управляемый сервис графовых баз данных. Упрощает разработку приложений, работающих с наборами сложносвязанных данных. Подходит для работы с рекомендательными сервисами, соцсетями, системами выявления мошенничества.
Самые популярные языки программирования для работы с Big Data
- R. Язык используется для обработки данных, сбора статистики и работы с графикой. Загружаемые модули связывают R с GUI-фреймворками и позволяют разрабатывать утилиты анализа с графическим интерфейсом. Графика может быть экспортирована в популярные форматы и использована для презентаций. Статистика отображается в виде графиков и диаграмм.
- Scala. Нативный язык для Apache Spark, используется для анализа данных. Проекты Apache Software Foundation, Spark и Kafka, написаны в основном на Scala.
- Python. Обладает готовыми библиотеками для работы с AI, ML и другими методами статистических вычислений: TensorFlow, PyTorch, SKlearn, Matplotlib, Scipy, Pandas. Для обработки и хранения данных существуют API в большинстве фреймворков: Apache Kafka, Spark, Hadoop.
Про то, как устроен и работает брокер сообщений Apache Kafka мы писали в отдельной статье.
Примеры использования аналитики на основе Big Data: бизнес, IT, медиа
Большие данные используют для разработки IT-продуктов. Например, в Netflix прогнозируют потребительский спрос с помощью предиктивных моделей для новых функций онлайн-кинотеатра. Специалисты стриминговой платформы классифицируют ключевые атрибуты популярности фильмов и сериалов, анализируют коммерческий успех продуктов и фич. На этом построена ключевая особенность подобных сервисов — рекомендательные системы, предсказывающие интересы пользователей.
В геймдеве используют большие данные для вычисления предпочтений игроков и анализа поведения в видеоиграх. Подобные исследования помогают совершенствовать игровой опыт и схемы монетизации.
Для любого крупного производства Big Data позволяет анализировать доходы и обратную связь от заказчиков, детализировать сведения о цепочках производства и логистике. Подобные факторы улучшают прогноз спроса, сокращают расходы и простои.
Big Data помогает со слабоструктурированными данными о запчастях и оборудовании. Записи в журналах и сведения с датчиков могут быть индикаторами скорой поломки. Если ее вовремя предсказать, это повысит функциональность, срок работы и эффективность обслуживания техники.
В сфере торговли анализ больших данных дает глубокие знания о моделях поведения клиентов. Аналитика информации из соцсетей и веб-сайтов улучшает качество сервиса, повышает лояльность и решает проблему оттока покупателей.
В медицине Big Data поможет с анализом статистики использования лекарств, эффективности предоставляемых услуг, с организацией работы с пациентами.
В банках используют распределенные вычисления для работы с транзакционной информацией, что полезно для выявления мошенничества и улучшения работы сервисов.
Госструктуры анализируют большие данные для повышения безопасности граждан и совершенствования городской инфраструктуры, улучшения работы сфер ЖКХ и общественного транспорта.
Это лишь часть сфер, где растет востребованность аналитики больших данных. В интересантах не только технические направления, но и медиа, маркетинг, социология, сфера найма, недвижимость.
Управление большими данными — кто занимается
Люди, работающие с большими данными, разделяются по многим специальностям:
- аналитик Big Data,
- дата-инженер,
- Data Scientist,
- ML-специалист и др.
Учитывая высокий спрос, для работы в сфере требуются специалисты разных компетенций. Например, существует направление data storytelling — умение эффективно донести до аудитории информацию из набора данных с помощью повествования и визуализации. Для понимания контекста используются сюжетные линии и персонажи, графики и диаграммы, изображения и видео.
Рассказы о данных используют внутри компании, чтобы на основе представленной информации донести до сотрудников необходимость улучшения продукта. Другое применение — презентация потенциальным клиентам аргументов в пользу покупки продукта.
Что такое Big Data и почему их называют «новой нефтью»

Смартфоны предлагают нам загрузить все данные в облако, а большие компании вроде Google и «Яндекса» — воспользоваться своими экосистемами. Проще говоря, мы живем в эпоху Big Data. Но что это значит на самом деле?
Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений. Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
«Лиза Алерт» использует Big Data, чтобы находить пропавших людей
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
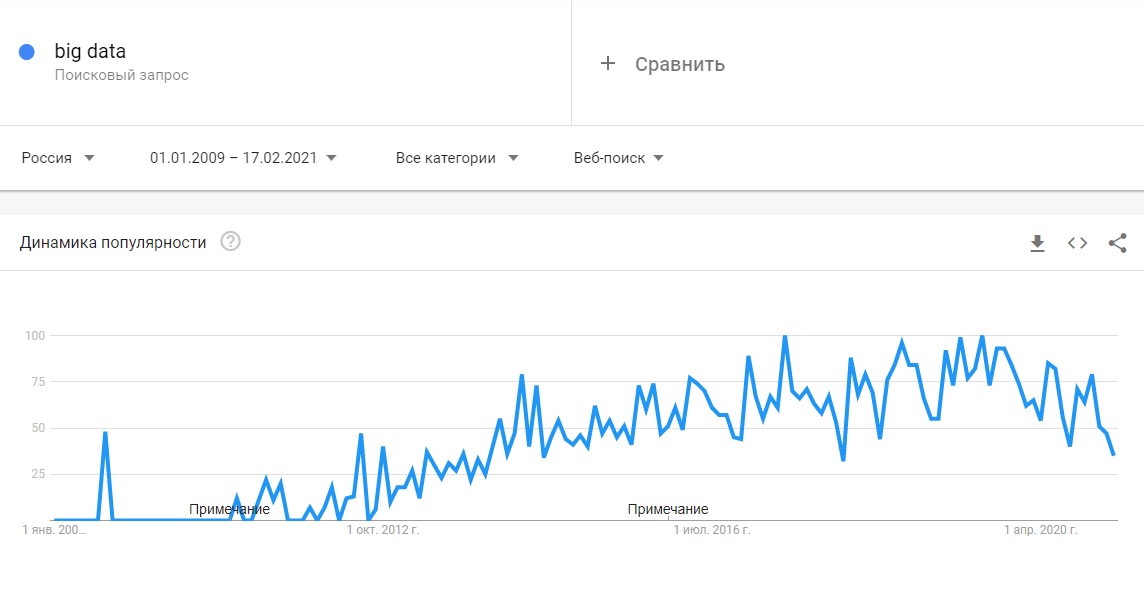
Всплеск интереса к большим данным в Google Trends
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и IT-специальностям. Затем к сбору и анализу подключились IT-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook (с 21 марта 2022 года соцсеть запрещена в России решением суда) и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
Какие есть характеристики Big Data?
- Volume — объем данных: от 150 Гб в сутки;
- Velocity — скорость накопления и обработки массивов данных. Большие данные обновляются регулярно, поэтому необходимы интеллектуальные технологии для их обработки в режиме онлайн;
- Variety — разнообразие типов данных. Данные могут быть структурированными, неструктурированными или структурированными частично. Например, в соцсетях поток данных не структурирован: это могут быть текстовые посты, фото или видео.
Сегодня к этим трем добавляют еще три признака [3]:
- Veracity — достоверность как самого набора данных, так и результатов его анализа;
- Variability — изменчивость. У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать;
- Value — ценность или значимость. Как и любая информация, большие данные могут быть простыми или сложными для восприятия и анализа. Пример простых данных — это посты в соцсетях, сложных — банковские транзакции.
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
- интернет вещей (IoT) и подключенные к нему устройства;
- соцсети, блоги и СМИ;
- данные компаний: транзакции, заказы товаров и услуг, поездки на такси и каршеринге, профили клиентов;
- показания приборов: метеорологические станции, измерители состава воздуха и водоемов, данные со спутников;
- статистика городов и государств: данные о перемещениях, рождаемости и смертности;
- медицинские данные: анализы, заболевания, диагностические снимки.
С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Как выглядит современный дата-центр
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
Сеть медицинских центров Aurora Health Care ежегодно экономит $6 млн за счет предписывающей аналитики: ей удалось снизить число повторных госпитализаций на 10% [5].
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
- Cпециальное ПО: NoSQL, MapReduce, Hadoop, R;
- Data mining — извлечение из массивов ранее неизвестных данных с помощью большого набора техник;
- ИИ и нейросети — для построения моделей на основе Big Data, включая распознавание текста и изображений. Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
- Визуализация аналитических данных — анимированные модели или графики, созданные на основе больших данных.
Примеры визуализации данных (data-driven animation)
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
- Обезличивание данных делает персональную информацию пользователей в какой-то степени недоступной;
- Агрегированность данных позволяет оперировать лишь со средними показателями.
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
В каких отраслях уже используют Big Data?
- Государственное управление. Изучение и анализ больших данных помогает правительствам принимать решения в таких областях, как здравоохранение, занятость населения, экономическое регулирование, борьба с преступностью и обеспечение безопасности, реагирование на чрезвычайные ситуации;
- Промышленность. Внедрение инструментов Big Data помогает повысить прозрачность промышленных процессов и внедрять «предиктивное производство», позволяющее более точно прогнозировать спрос на продукцию и, соответственно, планировать расходование ресурсов;
- Медицина. Огромное количество данных, собираемых медицинскими учреждениями и различными электронными приспособлениями (фитнес-браслетами и т.п.) открывает принципиально новые возможности перед индустрией здравоохранения. Большие данные помогают находить новые лекарства, точнее ставить диагнозы, подбирать эффективное лечение, бороться с пандемий;
- Ретейл. Развитие сетевой и электронной торговли невозможно представить без основанных на Big Data решениях — так магазины персонализируют ассортимент и доставку;
- Интернет вещей. Big Data и интернет вещей неразрывно связаны между собой. Промышленные и бытовые приборы, подключенные к интернету вещей, собирают огромное количество данных, на основе анализа которых впоследствии регулируется работа этих приборов;
- Рынок недвижимости. Девелоперы используют технологии Big Data, чтобы собрать и проанализировать весь массив информации, а затем выдать пользователю наиболее интересные для него варианты. Уже сейчас будущий покупатель может посмотреть понравившийся дом без продавца;
- Спорт. С помощью больших данных футбольные клубы отбирают самых перспективных игроков и разрабатывают эффективную стратегию для каждого противника.
Выпуск «Индустрии 4.0» о том, как используют Big Data в футболе
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды. Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения», — прокомментировали в «МегаФоне».
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Первыми Big Data еще пять лет назад начали использовать в ИТ, телекоме и банках. Именно в этих сферах скапливается большой объем данных о транзакциях, геолокации, поисковых запросах и профилях в Сети. В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
Как большие данные помогают онлайн-кинотеатрам подбирать персональные рекомендации
Мировыми лидерами по сбору и анализу больших данных являются США и Китай. Так, в США еще при Бараке Обаме правительство запустило шесть федеральных программ по развитию больших данных на общую сумму $200 млн. Главными потребителями Big Data считаются крупные корпорации, однако их деятельность по сбору данных ограничена в некоторых штатах — например, в Калифорнии.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
- Запуск продуктов и сервисов, которые точнее всего «выстрелят» по потребностям целевой аудитории;
- Анализ клиентского опыта в отношении продукта или услуги, чтобы улучшить их;
- Привлечение и удержание клиентов с помощью аналитики.
Большие данные помогают MasterCard предотвращать мошеннические операции со счетами клиентов на сумму более $3 млрд в год [13]. Они позволяют рекламодателям эффективнее распределять бюджеты и размещать рекламу, которая нацелена на самых разных потребителей.
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
Каковы проблемы и перспективы Big Data?
Главные проблемы:
- Большие данные неоднородны, поэтому их сложно обрабатывать для статистических выводов. Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;
- Для работы с большими массивами данных онлайн нужны огромные вычислительные мощности. Такие ресурсы обходятся очень дорого, и пока что доступны только большим корпорациям;
- Хранение и обработка Big Data связаны с повышенной уязвимостью для кибератак и всевозможных утечек. Яркий пример — скандалы с профилями Facebook;
- Сбор больших данных часто связан с проблемой приватности: не все хотят, чтобы каждое их действие отслеживали и передавали третьим лицам. Герои подкаста «Что изменилось» объясняют, почему конфиденциальности в Сети больше нет, и технологическим гигантам известно о нас все;
- Большие данные используют в своих целях не только корпорации, но и политики: например, чтобы повлиять на выборы.
Плюсы и перспективы:
- Большие данные помогают решать глобальные проблемы — например, бороться с пандемией, находить лекарства от рака и предотвращать экологический кризис;
- Big Data — хороший инструмент для создания умных городов и решения проблемы транспорта;
- Большие данные помогают экономить средства даже на государственном уровне: например, в Германии вернули в бюджет около €15 млрд [14], обнаружив, что часть граждан получают пособие по безработице без всяких оснований. Их вычислили с помощью транзакций.
Как Big Data и ИИ меняют наше представление о справедливости
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
Как в современном мире используют Big Data?

Информация хранится в системах, работающих на кластерах из сотен узлов, или в распределённых системах управления базами данных. Её обрабатывают, переводя из «сырого» формата в удобный для работы. Массивы информации структурируют, устраняют избыточность и неконсистентность. После этого данные анализируют. Процесс перевода Big Data в полезную информацию обозначают термином «Data Mining». Это интеллектуальный и глубинный анализ данных для выявления ключевых закономерностей. Полученная информация удобна для создания различных визуализаций, построения наглядных дашбордов, также она используется для машинного обучения.
Какие вопросы помогают решать большие данные?
- Анализировать текущее положение дел и оптимизировать бизнес-процессы. С помощью больших данных компания Intel обнаружила, что делает много лишних тестов при производстве процессоров. В результате анализа полученной информации и отказа от дополнительной проверки продукции удалось сэкономить большие суммы денег.
- Автоматизировать рутину. На больших данных обучаются автоматические программы, которые умеют выполнять определённые задачи, например, сортировать документы или общаться в чат-ботах. Это могут быть как примитивные алгоритмы, так и искусственный интеллект (голосовые помощники или нейросети).
- Строить модели. На основе больших данных можно собрать компьютерную модель магазина или оборудования, что позволяет проводить различные эксперименты, задав нужные параметры. Например, компании могут смоделировать проблемные ситуации и таким образом избежать их возникновения.
- Делать прогнозы. Данные о прошлом помогают сделать выводы о будущем, при этом чем больше информации, тем точнее прогнозы. Логистическая компания ПЭК запустила Центр управления перевозками с использованием Big Data. Это позволило предсказывать загрузку складов и планировать маршруты транспорта во избежание простоев.
В каких отраслях используют Big Data?
Первыми Big Data начали использовать специалисты в ИТ, телекоммуникациях и банковском секторе. Именно в этих сферах скапливается большой объём данных о транзакциях, геолокации, поисковых запросах и профилях в Сети.
Большие данные незаменимы в обеспечении безопасности. Их используют в борьбе с преступностью, для обеспечения правопорядка и предотвращения незаконной деятельности. Кроме того, Big Data позволяют отслеживать негативный контент в цифровом пространстве. Например, можно исследовать социальную активность пользователей Интернета и на основе открытых данных (лайки, посты, фотографии) предлагать вероятностные прогнозы о возможности риска развития деструктивного поведения человека.
В медицине на основе больших данных специалисты могут прогнозировать заболевания, точнее ставить диагнозы.
В образовании Big Data позволяют анализировать способности студентов, чтобы впоследствии предложить им подходящие направления трудовой деятельности.
На рынке финансов большие данные используют для оценки платёжеспособности клиента и рисков для компаний, повышения качества различных сервисов, создания персонализированных предложений.
В промышленности Big Data применяют для анализа производства и его оптимизации. Например, большие данные позволяют оценить, оптимально ли работают станки, выявить проблемы с поставкой товаров.
Трудности в применении Big Data
Из-за неоднородности структуры, типа и объёма больших данных их зачастую сложно собирать и анализировать. Прежде чем пользоваться полученной информацией, Big Data необходимо подготовить. Собранные из различных источников данные могут быть некачественными (содержать дубликаты, иметь неконсистентный формат, отсутствующие значения), поэтому их необходимо консолидировать и структурировать. Для работы с Big Data требуются большие человеческие и технические ресурсы. Рост данных может быть экспоненциальным, а сама информация становится всё более разнообразной.
Переосмысление информации и перспективы Big Data
После первого появления больших данных в мире произошла цифровая революция. Каждый день количество информации стремительно увеличивается, Big Data расширяются во всех направлениях. Совсем недавно базы данных воспринимались как объект для научных исследований и побочный продукт различных производственных процессов. Компании попросту удаляли накопившуюся информацию, теперь же они тщательно её собирают, накапливают и анализируют для получения прибыли. Таким образом Big Data обрели ценность: чем больше данных, тем больше открытий можно сделать.
Более того, огромные базы данных становятся объектом целенаправленного инвестирования средств для получения прибыли. В современном мире с каждым годом будет расти значимость данных. Big Data станут основным инструментом для решения проблем общества и бизнеса.
Как крупные компании используют big data: 5 направлений и 12 кейсов
Большие данные уже перестали быть просто трендом. Сейчас для крупных компаний это незаменимый драйвер бизнеса, который позволяет прокачать все его составляющие: от пользовательского пути до поиска перспективных отраслей масштабирования дела.
Big data плотно исследуют уже больше десяти лет, но и сейчас многие эксперты утверждают, что компании даже близко не подобрались к раскрытию реальных возможностей технологии. И мы в Platforma с этим согласны, поэтому сегодня делимся с вами большим материалом, который подготовила команда ProjectPro. Они собрали более 20 кейсов, как бизнес использует большие данные, и выделили 5 основных направлений. Специально для вас мы адаптировали перевод на русский и выделили 12 самых интересных проектов с big data, а также рассказали об одном бонусном кейсе в сфере MedTech. Поехали!
- Как Amazon отслеживает цены на товары
- ФК Atlanta Falcons следит за передвижением игроков
- Как авиакомпания Delta отслеживает негатив в медиа
- Универмаг Macy’s предугадывает спрос на куртки с помощью Twitter
- Bank of America рассчитывает персонифицированный кэшбек
- Как компания Target узнает о беременности клиенток
- McDonald’s уменьшает издержки
- WarnerMedia узнает о политических взглядах зрителей
- Как Amazon формирует персонифицированную ленту предложений
- Университет Пёрдью следит за успеваемостью студентов
- Прогнозирование заболеваний в Ayasdi
- Как K Health определяет болезни клиентов
- Страховое бюро Канады (IBC) вычисляет мошенников
Начнем с кейсов, которые эксперты ProjectPro решили не классифицировать, но хотели о них рассказать.
Как компания Amazon использует большие данные
У компании Amazon около 1 млн кластеров Hadoop, которые обеспечивают управление рисками, работу партнерских сетей, обновление веб-сайтов, работу систем машинного обучения и многое другое. И в 2011 году концерн запустил рекламную акцию со словами: «Amazon платит покупателю пять долларов, если он уходит из магазина без покупки». Необычно, правда?
Amazon и сейчас дает скидку в пять долларов всем, кто пользуется мобильным приложением Amazon Price Check. Оно служит для сканирования и фотографирования товаров в магазинах, а также поиска самых выгодных предложений. Но еще покупатель может отмечать цены на товары, которые продают в других магазинах.
Так в Amazon следят за тем, чтобы цены были выгодными для покупателей, а сама компания получала конкурентное преимущество. Amazon собирает информацию о ценообразовании своих конкурентов. И эти данные используются для эффективной работы в быстро меняющейся и высококонкурентной среде онлайн-торговли, где главные факторы успеха – это цена и реклама.
Как лидеры среди спортивных компаний используют большие данные
Футбольный клуб Atlanta Falcons, входящий в NFL (Национальную лигу американского футбола), использует технологию GPS для сбора и анализа данных о передвижении игроков по полю во время тренировок. Используя аналитику на основе этих данных, тренер может выстроить оптимальную тактику игры.
Интересная ситуация также и в мире виртуального спорта. Количество геймеров в мире выросло с 200 млн до 1,5 млрд. Компании Electronic Arts и Riot Games используют большие данные, чтобы следить за ходом реальных спортивных состязаний и предсказывать характеристики и развитие игроков. Чтобы сделать один успешный анализ, нужно обработать около 4 терабайт операционных журналов и 500 гигабайт структурированных данных.
1. Анализ публикаций и комментариев в соцсетях
Мир больших данных среди прочего включает в себя общение людей в сети, различные обзоры, отзывы и комментарии. Количество каналов коммуникации постоянно растет, а компании все чаще общаются со своими потребителями с помощью социальных сетей.
Чтобы удовлетворять потребности клиентов, крайне важно грамотно анализировать их мнение о товарах и услугах. Big data социальных сетей дают достаточно информации для анализа настроений пользователей. В свою очередь, это обеспечивает четкое понимание — что нужно делать, чтобы победить в конкурентной борьбе.
Компании часто задействуют большие данные, полученные при помощи различных коммерческих решений, например, данные о просмотренных страницах, посещаемых сайтах и другие. Они также анализируют комментарии в социальных сетях, обзоры и отзывы на разных форумах. С помощью собранных данных специалисты могут быстро и адекватно реагировать на позитивные или негативные комментарии, оперативно решать возникающие проблемы. Таким образом, анализ онлайн-публикаций потребителей получается более объективным и его результаты можно использовать при разработке продуктов и планировании рекламных кампаний.
Работа с негативом от авиакомпании Delta
Авиакомпании достаточно часто используют анализ отзывов для повышения качества своих услуг. К примеру, компания Delta следит за сообщениями в Twitter, чтобы узнать, как их клиенты реагируют на задержки рейсов, изменения в графиках, процесс перелета и многое другое. И если клиент публикует негативный твит — например, о потере багажа при пересадке на другой рейс — авиакомпания мгновенно отслеживает его и отправляет запрос в службу поддержки.
В свою очередь, служба поддержки отправляет своего представителя в пункт пересадки пассажира и предлагает решение проблемы. К примеру, клиент продолжит полет в первом классе и получит обещание, что ему доставят багаж к моменту, когда путешествие будет закончено. После этого всю оставшуюся часть полета пассажир пишет уже положительные твиты, укрепляя репутацию и узнаваемость компании.
Анализ трендов и тенденций от бренда Macy’s
Американская сеть универмагов Macy’s собирает большие данные об интересах клиентов на основе покупок сезонных товаров, динамики цен, демографических показателей, цветовых предпочтений, места проживания и еще целого ряда характеристик. Далее специалисты отслеживают положительные и отрицательные отзывы о товарах в социальных сетях. И как результат, с помощью систем прогностического анализа они могут предугадывать тенденции, которые способны повлиять на доход компании.
К примеру, с помощью анализа публикаций в соцсетях компания Macy’s узнала, что люди, которые пишут в Twitter о куртках, часто используют названия Michael Kors и Louis Vuitton. Подобная информация помогает определить, какие бренды курток стоит предлагать со скидкой, чтобы привлечь больше клиентов.
Аналитические системы Macy’s даже могут предугадывать желания клиентов, благодаря грамотной сегментации. Более точные предложения лучше привлекают внимание и вовлекают потенциальных потребителей, что в конечном итоге приводит к покупке товара.
2. Анализ поведения клиентов
48% организаций используют big data, чтобы получить максимально полное представление о клиентском опыте.
Главная прелесть больших данных — с их помощью можно с высокой точностью понять поведение клиента. Причем не только понять, но и предугадать в будущем. Этот механизм уже помог некоторым компаниям в десятки раз повысить свои доходы.
Компания Amazon одной из первых внедрила рекомендации товаров на основе интересов посетителей. А сейчас то же самое делают и десятки других компаний: Spotify, Pinterest, Netflix и многих других.
Кэшбэк от Bank of America
Bank of America анализирует истории покупок по кредитным и дебетовым картам своих клиентов. А затем формирует персонифицированные cashback-предложения с помощью собственной системы бонусов BankAmeriDeals.
Прогноз жизненных событий клиентов от Target
Компания Target анализирует поведение клиентов, чтобы предугадывать разные события в их жизни.
К примеру, с помощью big data специалисты компании Target выявили 25 товаров, заказ которых с высокой долей вероятности позволяет определить, что покупательница беременна. Среди них витаминные добавки, лосьоны без запаха и другие неочевидные товары.
На основе сделанных выводов компания Target формирует специальную рассылку для женщин. Так компания смогла значительно увеличить продажи товаров для новорожденных, особенно после запуска рекламной кампании, созданной на основе результатов анализа покупательского поведения клиентов.
Оптимизация работы ресторанов McDonald’s
Рестораны быстрого питания McDonald’s ежедневно посещают 62 млн людей. Только вдумайтесь, каждую секунду компания продает 75 бургеров. А ежегодная выручка компании составляет 27 млрд долларов.
McDonald’s активно использует анализ big data, чтобы оптимизировать работу ресторанов и улучшить качество обслуживания клиентов. Аналитики собирают и учитывают десятки факторов, среди которых время ожидания и размер заказа клиентов, предпочитаемые блюда и разнообразные привычки покупателей. Всё это позволяет улучшить работу ресторанов в каждой конкретной локации. Например, компания может повысить число продавцов на точке, в которой наблюдались очереди покупателей, поставить больше продуктов туда, где они пользуются большим спросом.
3. Сегментация клиентов
Расходы на привлечение клиентов постоянно растут, поэтому для компаний важно правильно сегментировать аудитории и проводить более результативные рекламные кампании.
Бренды получают информацию о клиентах из самых разных источников: от социальных сетей до биллинга банковских операций. Также специалисты анализируют данные учетных записей клиентов, отслеживают историю покупок. Все это помогает компаниям с высокой точностью определять интересы клиентов и формировать для них персонализированные рекламные предложения. А это, в свою очередь, значительно снижает расходы на привлечение новых покупателей.
Благодаря анализу big data, расходы на привлечение клиентов можно уменьшить на 30%. Эксперты издания Harvard Business Review отмечают, что с помощью персонифицированной рекламы некоторые компании смогли на 70% повысить показатели конверсии. И это круто.
Детальная работа с аудиторией в WarnerMedia
WarnerMedia – это огромная медийная компания, которая работает в более чем 150 странах. У нее почти 14 млн клиентов, из которых 7,9 млн — ее постоянные подписчики.
Каждый день компания собирает около 0,6 терабайт данных. И они в полной мере используются для создания персонализированных рекламных кампаний. Системы анализа WarnerMedia учитывают данные о просмотрах программ на локальном уровне, демографические показатели, регистрационную информацию пользователей и даже данные из реестра владельцев недвижимости. Обработка этой информации позволяет понять индивидуальные предпочтения клиентов, их политические взгляды, информацию о доходах. Так WarnerMedia может оперативно корректировать рекламу в зависимости от того, как люди реагируют на нее на разных платформах.
Персонифицированная лента рекомендованных товаров в Amazon
Зайдите на сайт Amazon и посмотрите, какие товары вам порекомендуют купить. Гарантируем, что они точно будут отличаться от тех, которые Amazon предложит вашему другу. Как они это делают? Очень просто.
Каждый раз, когда пользователь заходит в свою учетную запись на сайте Amazon, совершает покупку или просто смотрит товары на сайте, система собирает всю эту информацию. Когда клиент приходит еще раз, то сайт предлагает ему товары, учитывая его предыдущие покупки и историю поиска.
Такой подход позволяет компании Amazon находить тенденции среди клиентов, совершающих похожие покупки. К примеру, если 75% покупателей iPhone заказывают портативный внешний аккумулятор, то Amazon начинает предлагать этот аккумулятор всем, кто выбирает iPhone. Сегментируя клиентов по интересам и покупательским привычкам, Amazon предлагает им больший выбор товаров и подталкивает сделать дополнительную покупку.
4. Использование прогностического анализа
Сегодня компании хотят знать будущее, чтобы увеличить свои продажи. В разных отраслях экономики разработка моделей прогнозирования на основе больших данных становится одним из главных приоритетов.
Повышение успеваемости студентов в университете Пёрдью, штат Индиана
Американский университет Пёрдью использует анализ big data, чтобы повышать уровень успеваемости собственных студентов.
Специальная система Signals отслеживает и анализирует уровень успеваемости студентов по разным предметам. Она позволяет находить отстающих студентов и на основе полученных данных формирует и отправляет студентам сообщения. Также Signals предупреждает учащихся о пробелах в знаниях и рассказывает о негативных последствиях, которые могут у них возникнуть на дальнейших этапах обучения.
Прогнозирование заболеваний в Ayasdi
В своей работе компания Ayasdi использует анонимизированные данные пациентов, которые болели раком груди в последние 20 лет. Массивы информации обрабатываются с помощью специальной технологии на основе машинного обучения IRIS.
Ayasdi разработала специальные структуры данных, полученных от пациентов с раком груди или лейкемией. И благодаря их анализу были обнаружены общие черты, которые могут помочь в прогнозировании и поиске новых способов лечения раковых заболеваний.
К слову, MedTech — это молодая и быстроразвивающаяся отрасль. Ежегодно на рынке появляются новые сервисы и продукты, способные по-настоящему улучшить жизнь людей. Мы хотим поделиться с вами отдельным кейсом, не вошедшим в подборку издания, но заслужившим наше восхищение.
Анализ заболеваний от K Health
Мобильное приложение K Health помогает определить заболевание по его симптомам. Оно подключено к нейронной сети, обученной на сотнях тысячах историй болезней. Принадлежит разработка второй второй по величине больничной кассой Израиля Maccabi Health Care Services.
Механизм его работы простой: пользователи должны ответить на несколько вопросов о своем самочувствии и об имеющихся симптомах, после чего они получают выгрузку по схожим случаям заболеваний и оценку вероятности их совпадения со своей ситуацией. Сервис помогает пользователям быстро определить возможные заболевания и методы их лечения, а также при необходимости получить назначение лекарств или встречи с врачом.
5. Выявление мошенничества
Финансовые преступления, мошеннические иски и несанкционированный доступ к данным – это наиболее распространенные проблемы, с которыми сталкиваются компании в самых разных отраслях.
Выявление и предотвращение мошенничества было крупной общемировой проблемой для всех отраслей экономики задолго до появления big data. Но именно анализ больших данных помогает компаниям находить, предотвращать и пресекать любые внутренние и внешние виды мошенничества.
К примеру, аналитические алгоритмы могут предупредить банк о том, что у пользователя была украдена кредитная или дебетовая карта, если обнаружат нехарактерные для этой карты операции. Таким образом, банк может временно приостановить обслуживание, чтобы связаться с держателем карты и выяснить, что происходит.
Страховое бюро Канады (IBC) борется с мошенническими исками
Страховое бюро Канады (IBC) представляет интересы владельцев автомобилей, жилой недвижимости и бизнеса. Оно пользуется решениями компании IBM для анализа больших данных, которые позволяют выявлять подозрительные страховые иски.
За последние 6 лет аналитические системы IBC обработали свыше 233 тыс. страховых исков. Так бюро смогло обнаружить попытки мошенничества на сумму около 41 млн канадских долларов. В Страховом бюро Канады считают, что программные решения для анализа big data позволяют автомобильной промышленности Онтарио экономить около 200 млн канадских долларов ежегодно, например, за счет предотвращения мошенничеств со страховкой.
Анализ big data уже давно превратился из популярного тренда в must-have инструмент для среднего и крупного бизнеса. При правильном использовании и достаточном количестве информации big data способна прокачать абсолютно любую сферу бизнеса или его отдельные составляющие: от клиентского пути и маркетинга до стратегического планирования и масштабирования.
Эти кейсы, которые собрала команда ProjectPro — лишь крайне малая часть примеров, как большие данные на самом деле используются предпринимателями. Согласно данным агентства Statista, 57% компаний крупного и среднего бизнеса во всем мире используют анализ больших данных в работе. Это тысячи компаний по всему земному шару. А 27% топ-менеджеров считают их проекты big data сверхуспешными для бизнеса.
Большие данные — это не будущее, это уже настоящее. И от того, насколько эффективно компании и бренды будут их использовать, во многом будет зависеть их место на глобальном рынке.