Часть 4. Процесс загрузки системы
Нормальное функционирование Windows можно разделить, как минимум, на три фазы: начальную загрузку, режим работы и завершение работы (естественно, для крупных серверов идеальным считается режим, при котором компьютер загружается всего один раз, а потом работает без выключения — но такой случай, скорее, исключение, чем правило, тем более для систем на основе Windows). По большей части, авторы популярных статей и книг ограничиваются рассказом о второй стадии, в то время как первая, на наш взгляд, оказывается неоправданно забытой и обойденной вниманием. Это является неким недоразумением, ведь знание основных этапов начальной загрузки ОС может оказаться хорошим подспорьем в процессе решения проблем и устранения неполадок, не позволяющих компьютеру нормально загрузить операционку. Поэтому в этой части статьи мы подробно остановимся на том, как протекает процесс загрузки компьютера, работающего под управлением Windows 2000, и рассмотрим его детальнее, а также немного коснемся вопроса завершения работы.
Часть четвертая. Процесс загрузки системы
«Воин живет действием, а не думаньем о действии или думаньем о том, что он будет думать, когда закончит действовать.»
Карлос Кастанеда,
«Отдельная реальность»
Попытаемся пойти путем воина, и не будем лишний раз лить воду о том, как «советские космические корабли бороздят просторы Большого театра», а сразу приступим к делу. То есть, прежде всего, приведем тот минимальный набор файлов, который необходим для успешного запуска системы, вот они:
- Boot.ini
- Bootsect.dos (необходим только при использовании мультизагрузки)
- NTLDR
- Ntdetect.com
- Ntbootdd.sys (необходим только для загрузки с SCSI-винчестера)
- Ntoskrnl.exe
- Hal.dll
- Необходимые драйверы и разделы реестра.
А теперь, зная необходимые для загрузки Windows 2000 файлы, рассмотрим весь процесс загрузки компьютера, который начинается с процедуры начального тестирования оборудования (POST — Power-On Self Test). Код, выполняющий POST, зашит в БИОСе каждого компьютера, и именно ему передается управление при включении питания. Если в процессе тестирования обнаруживаются какие-либо ошибки, то БИОСом генерируются коды ошибок (POST codes), которые отличаются для БИОСа разных производителей. Наверняка сердце почти каждого сборщика компьютеров не единожды замирало от противного писка динамика, выдающего трели из комбинации длинных и коротких гудков — это и есть звуковые коды, которые выдает POST в самых запущенных случаях, когда не может вывести текст на экран монитора. Если же процедура POST завершается успешно, то БИОС передает управление главной загрузочной записи (MBR — Master Boot Record) первичного жесткого диска системы, и можно сказать, этим завершает первую «аппаратную» стадию загрузки компьютера (весь процесс зависит только от аппаратуры компьютера, но не от установленного программного обеспечения). На второй стадии загрузочная запись, оперируя данными о разбиении жесткого диска на логические тома, передает управление исполняемому коду, расположенному в загрузочном секторе. Вот тут-то и начинается самое интересное, так как в случае Windows 2000 этим кодом является NTLDR (boot loader). Из-за сложности всех предварительных операций, когда программа, почти ничего не сделав, кроме как загрузив вторую, передает управление ей, а та, в свою очередь, поступает почти так же, как и первая, программисты-системщики шутливо сравнивают всю эту процедуру с поднимающим себя за собственные шнурки человеком. Первое, что делает загрузчик, это переходит в защищенный режим и производит необходимые для успешного функционирования в этом режиме манипуляции с памятью. Кроме функций, позволяющих работать с памятью, NTLDR имеет также несколько модулей, позволяющих работать с некоторыми другими базовыми ресурсами системы, в первую очередь с файловой системой. Все другие действия выполняются с помощью вызова прерываний БИОСа. После первичной инициализации загрузчик предоставляет пользователю возможность выбрать операционную систему, которая будет загружена, из списка систем, установленных на компьютере (то есть, NTLDR выводит на экран надпись OS Loader V5.0 и приглашение выбрать операционную систему; это сообщение выводится только в том случае, если в файле boot.ini зарегистрировано более одной ОС), после чего, если выбрана Windows 2000, начинает загрузку файлов ОС.
Перечень установленных операционок находится в файле boot.ini, который располагается в корневом каталоге системного раздела. Многие думают, что единственное, чего можно достичь путем прямого редактирования boot.ini, — это создание системы с несколькими установленными версиями Windows 2000, однако это не совсем так. Во-первых, диапазон возможных ОС для альтернативной загрузки достаточно широк — это и все Win9x, MS-DOS, OS/2, и даже UNIX. Ну а во-вторых, изменение параметров загрузки самой Windows 2000 позволяет существенно влиять на ее работу и бывает очень по-лезным при отладке. Параметры, указываемые в boot.ini, носят необязательный характер, однако с их помощью можно выбирать версии ядра и HAL, изменять некоторые параметры многопроцессорных систем, режим видеоадаптера, ограничивать объем используемой системой памяти, влиять на работу мыши и многое другое. Знать принципы работы с boot.ini полезно еще и потому, что очень часто при изменении конфигурации системы (удаление или установка логических дисков или физических носителей) или при неудачном редактировании самого файла, загрузчик оказывается не в состоянии найти путь к загрузочному разделу Windows. При этом появляется сообщение типа «NTLDR is missing или Couldn’t find NTLDR», а пользователь начинает в ужасе рвать волосы на голове — не самая приятная ситуация, знаете ли. В таких случаях иногда помогает немного храбрости и возможность вручную отредактировать файл и исправить ошибку; будьте внимательны, для описания пути (в не SCSI-системах) используется следующий формат:
multi(0)disk(0)rdisk(0)partition(3)\ WINNT, где:
- multi() — номер адаптера IDE, с которого осуществляется загрузка,
- disk() — параметр, аргумент которого равен нулю,
- rdisk() — порядковый номер диска, нумерация ведется начиная с нуля,
- partition() — порядковый номер логического диска, на котором непосредственно находятся файлы операционной системы. Нумерация начинается с единицы, а не с нуля! Вообще, с этим параметром обычно возникает много проблем, и их решение похоже на ритуальные пляски шамана с бубном.
- \ path — каталог, в котором находятся файлы ОС.
К сожалению, в рамках журнальной статьи невозможно подробно описать все особенности использования boot.ini, поэтому наиболее любопытным читателям мы можем порекомендовать сайт http://support.microsoft.com/default/, где содержится огромное количество информации, так сказать, «из первых рук».
А сами тем временем «вернемся к нашим баранам», то есть, простите, к процессу загрузки. После выбора операционной системы загрузчик запускает Ntdetect.com. Этот компонент считывает из CMOS-памяти системную дату и время, после чего производит поиск и распознавание аппаратных средств, подключенных в данный момент к компьютеру. Завершив работу, Ntdetect возвращает управление и аккуратно собранную им информацию обратно в NTLDR.
Попутно заметим, что иногда бывает удобно создать несколько профилей оборудования, каждый из которых содержит отличный от других набор устройств (создание и управление профилями осуществляется при помощи диалогового окна Hardware Profiles с вкладки Hardware раздела System панели управления). Если такие профили существуют, загрузчик предложит выбрать один из них, после чего приступит к загрузке ядра Ntoskrnl.exe. Хочется подчеркнуть, что на этой стадии ядро только загружается в память, но ему не передается управление (то есть еще не инициализируется и не начинает исполняться системный код ядра).
В первую очередь в память загружается само ядро и уровень аппаратных абстракций. В этот момент на экране появляется подающая большие надежды надпись Starting Windows и индикатор завершенности процесса. Затем сканируется реестр (ищется куст, находящийся в \ Winnt \ System32 \ Config \ System) и составляется список драйверов устройств, необходимых для запуска. Из реестра извлекаются настройки, касающиеся организации памяти, которые могут задаваться как самим пользователем, так и специальными утилитами. Здесь же создается набор управляющих параметров (Control Set), который в дальнейшем играет очень важную роль в работе системы.
Управляющие параметры используются при начальной инициализации компьютера и потом на протяжении всего сеанса работы. При этом следует помнить, что всегда существует несколько наборов параметров: Default — используемый по умолчанию, LastKnownGood — набор, соответствующий последней успешной загрузке.
Определившись с используемым набором, загрузчик делает его активным, присваивая разделу HKEY_LOCAL_MACHINE \ SYSTEM \ Select значение Current, и переходит к разделу HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Services, где ищет драйверы устройств, у которых переменная Start имеет значение 0х0, что означает, что они должны загружаться без инициализации. В свою очередь, параметр Group определяет, какие устройства в каком порядке будут загружаться. Здесь стоит отметить, что наличие «лишних» устройств (дублирующих друг друга, а иногда и вообще не установленных) в системе сильно замедляет ее работу, ведь им требуются дополнительные ресурсы. Как вы уже, наверное, неоднократно замечали, загрузка ядра состоит из двух фаз: начальной, проходящей в текстовом режиме на печально черном фоне, и графической (видны радостные эмблемки «Майкрософта»), когда происходит непосредственно инициализация. В течение всего времени выполнения каждой фазы отображается текущее состояние процесса (индикаторная полоска, заполняющаяся прямоугольниками). В самом начале текстовой фазы загрузки ядра в нижней части экрана появляется надпись, в которой сообщается, что если вы успеете нажать F8, то будут доступны дополнительные варианты загрузки, используемые обычно при отладке или неполадках в работе системы. Никогда не пренебрегайте ими, ведь они могут очень здорово выручить вас в критической ситуации. После окончания загрузки ядра операционная система практически готова к работе, осталось только проинициализировать драйверы и подготовить службы — индикатор полностью заполняется, и происходит переключение из текстового режима в графический. На этом шаге управление передается ядру Ntoskrnl, которое получает ссылки на объекты, созданные при помощи NTLDR, таким образом, ядру передается вся информация, собранная другими модулями, а в конце передается и управление. При своей инициализации ядро производит ряд действий в следующей последовательности:
- окончательная подготовка к работе памяти и менеджера памяти;
- инициализация диспетчера объектов;
- установка системы безопасности;
- инициализация менеджера Plug and Play;
- установка базовых объектов и сервисов системы;
- настройка драйвера файловой системы и сохранение начальных параметров в реестре (создается копия набора управляющих параметров Clone, в которой содержатся данные, идентичные Current ControlSet, инициализируются устройства согласно порядку инициализации, затем создается ключ HKEY_LOCAL_MACHINE \ HARDWARE);
- загрузка и инициализация диспетчера ввода-вывода (обычно — самая длительная фаза);
- ядро «убирает за собой мусор», который остался после загрузки;
- последняя стадия — загрузка системных сервисов, которые, собственно, и реализуют взаимодействие с пользователем. Список основных системных сервисов приведен ниже.
- Smss.exe — диспетчер сеансов. Он управляет другими сервисами и службами Windows, в том числе запускает Win32 (Csrss) и некоторые системные утилиты, выполняемые на этапе загрузки (указываются в разделе реестра HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Control \ Session Manager\ BootExecute). Еще две важные функции — реализация графического пользовательского интерфейса и запуск процессов csrss.exe и WinLogon.exe. Этот диспетчер запускается, тем не менее, в самом конце загрузки.
- Csrss.exe — данный модуль предназначен, главным образом, для организации взаимодействия между компьютером и пользователем.
- Lsass.exe — служба, запускаемая WinLogon.exe и отвечающая за безопасность системы. Она предоставляет возможность пользователю зарегистрироваться в системе, и только после того, как в системе зарегистрировался хотя бы один пользователь, загрузка считается успешной, и текущий набор управляющих параметров Clone переименовывается в LastKnownGood.
Уже после загрузки операционной системы пользователь, чтобы доказать, что он тот, за кого себя выдает, должен пройти процедуру аутентификации, то есть ввести соб-ственное регистрационное имя (или на жаргоне — логин) и пароль. Процедура подключения к системе позволяет определить, кем является пользователь и обладает ли он правом входа и работы с системой. Эту процедуру выполняет служба WinLogon. При этом в системе происходят следующие события:
- Процесс WinLogon отображает на экране фон рабочего стола (к этому моменту объект рабочего стола уже создан, но еще не отображается), а также приглашение к вводу пользователем логина и пароля. Введенные данные передаются подсистеме безо-пасности.
- Подсистема безопасности обращается к базе данных SAM (Security Accounts Manager, подробнее про SAM смотри в части статьи, посвященной организации безопасности в Windows 2000) и проверяет, обладает ли пользователь полномочиями работы с системой.
- Если пользователь является авторизированным пользователем системы, то подсистема безопасности формирует для него токен доступа, который вместе с управлением передает обратно процессу WinLogon.
Процесс WinLogon посредством обращения к подсистеме Win32 создает новый процесс для пользователя и прикрепляет ему только что созданный токен доступа. Каждый процесс, в дальнейшем создаваемый пользователем, отмечается принадлежащим этому пользователю токеном доступа. Таким образом, любые попытки доступа пользователя к ресурсам системы контролируются и отслеживаются. Более того, с философской точки зрения можно сказать, что всегда точно известно, кто инициировал то или иное действие в системе. Благодаря обязательной процедуре подключения к системе упрощается реализация таких механизмов, как аудит системы и квоты на использование ресурсов.
- Помимо прочих данных, пользовательский токен доступа содержит идентификатор пользователя, а также идентификаторы всех групп, к которым принадлежит данный пользователь.
Итак, процесс загрузки удачно завершен — УРА! Казалось бы, это происходит так быстро, но при этом, как вы успели увидеть, система совершает ошеломительное количество операций и действий как с аппаратной платформой вашего «железного коня», так и с собственными программными модулями.
Вас, конечно же, интересует, что делать дальше, после того как компьютер загружен. Что же, придется вкратце рассказать об этом. Если вы опытный пользователь или, не дай Бог, администратор, на ваш стол наверняка уже наклеен ярлык типа Quake III или Counter Strike, так что можете смело давить на него мышью. В противном случае стоит воспользоваться рекомендацией самой «Майкрософт», вдавить кнопку «Пуск» и начинать свой трудный рабочий день. Так или иначе, мы пропускаем интимные подробности вашей работы с компьютером и, предпо-ложив, что у вас все получилось великолепно, переходим к той, немного печальной и грустной поре, когда компьютер приходится выключать. Хотя эта часть работы системы довольно неприметна, она тоже может принести пару сюрпризов.
Стадия завершения работы начинается с того, что процесс csrss получает соответствующее сообщение, передаваемое Win32 функцией ExitWindowEx, которое сигнализирует о том, что некоторая программа желает завершить работу системы. После этого csrss посылает всем оконным функциям главных окон процессов, запущенных в данный момент в системе, сообщение WM_QUERYENDSESSION, которое, по сути, оповещает программы о скором завершении работы, а затем проверяются ответы каждой программы. Программа может быть «согласна» и «не согласна» с предложением Windows. Если она не согласна, csrss пре-доставляет ей возможность завершиться в течение некоторого небольшого времени, после чего, в зависимости от настроек системы, выводит (или не выводит) окно, в котором сообщается имя мятежной программы, не желающей завершать свою работу, и предлагается ее закрыть принудительно. Так или иначе, но через некоторое время после начала стадии выключения, операционной системой прерывается работа всех пользовательских приложений, и плавно начинают завершаться системные потоки. В первую очередь, это потоки, реализующие графический режим, а затем и все остальные. В отличие от пользовательских процессов, системные не прерываются принудительно, поэтому если один из них чем-то занят, завершение работы может быть отложено на неопределенное время. В это время сохраняются настройки системы в реестре, и из системного кэша измененные данные файлов записываются на жесткий диск. Непосредственно перед выключением ряду устройств передается предупреждение об этом, после чего в свою работу включается драйвер электропитания. Проходит еще пара секунд, и ваш монитор, подмаргивая огоньком светодиода, тихо, словно выдохнув, щелкает, и экран приобретает темный цвет безжизненного полотна остывающего люминофора.
Где находится код выполняющий post
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
| ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |
Выполнение запроса в другой базе 1С без com-соединения. HTTP-сервис
Com-соединение использовать не хотелось по ряду причин. Одной из главных является зоопарк разных баз на разных платформах 1с. И поэтому написал http-сервис. 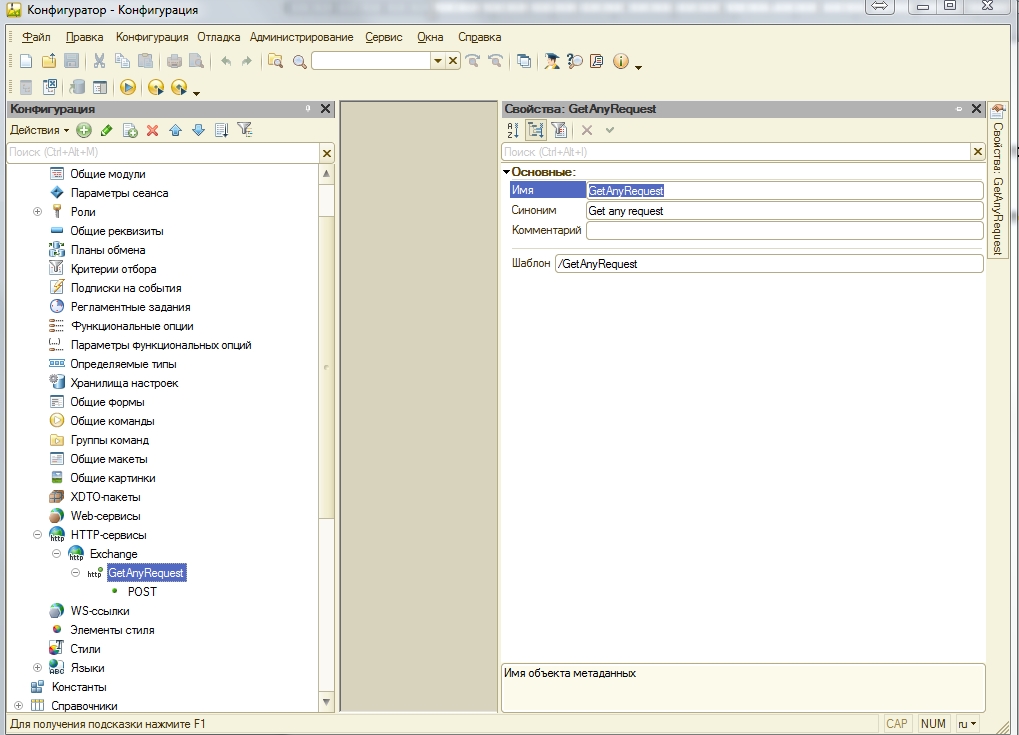
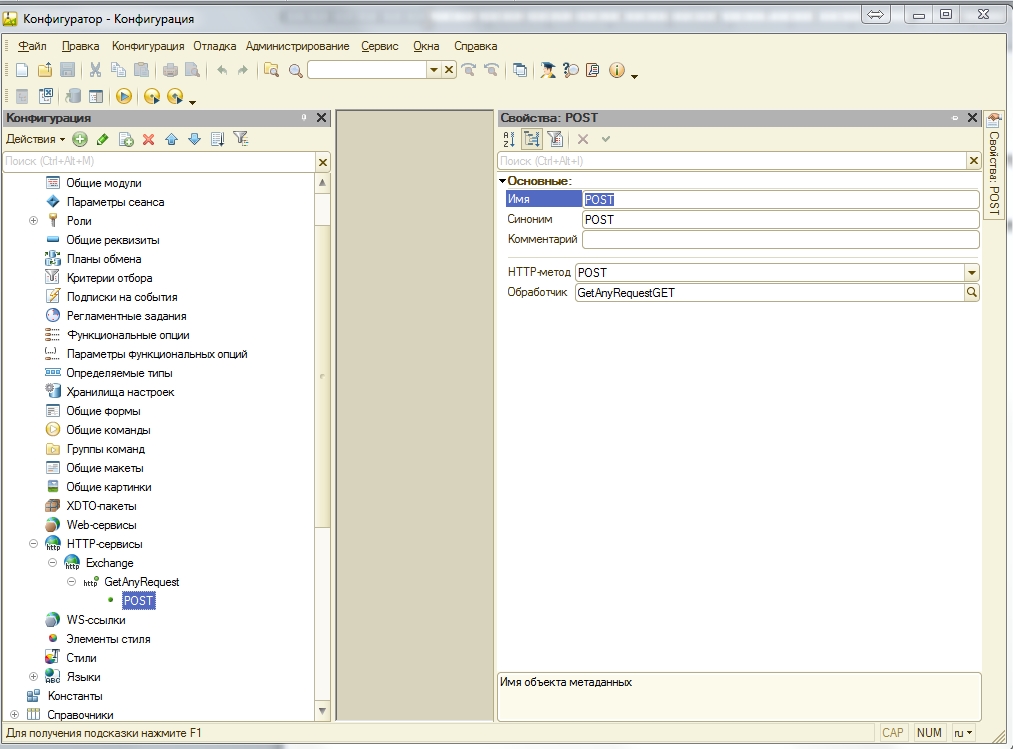 Публикуем ее на Apache или iss (об публикации 1с есть много статей в интернете) .
Публикуем ее на Apache или iss (об публикации 1с есть много статей в интернете) .  Пишем функцию, которая обрабатывает POST-запрос в теле запроса строка JSON в которой хранится Структура с запросом и его параметрами. Ниже видно как заполнить параметры с датой и элементом справочника. Функция на выходе возвращает Таблицу значений ЗначениеВСтрокуВнутр (в текстовом представлении)
Пишем функцию, которая обрабатывает POST-запрос в теле запроса строка JSON в которой хранится Структура с запросом и его параметрами. Ниже видно как заполнить параметры с датой и элементом справочника. Функция на выходе возвращает Таблицу значений ЗначениеВСтрокуВнутр (в текстовом представлении) 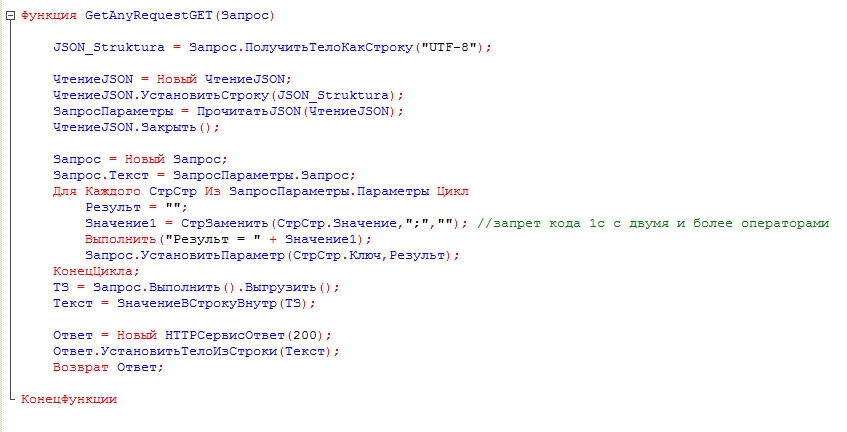 Далее Создаем обработку и пишем процедуру обращения к HTTP- сервису. Описываем запрос который будет выполнен в другой базе. Заворачиваем его в JSON. Делаем POST-запрос к адресу http-сервиса. Получаем текст из тела ответа. Преобразуем ее в Таблицу значений методом ЗначениеИзСтрокиВнутр.
Далее Создаем обработку и пишем процедуру обращения к HTTP- сервису. Описываем запрос который будет выполнен в другой базе. Заворачиваем его в JSON. Делаем POST-запрос к адресу http-сервиса. Получаем текст из тела ответа. Преобразуем ее в Таблицу значений методом ЗначениеИзСтрокиВнутр.  В демо-базе заполню данные чтобы получить результат.
В демо-базе заполню данные чтобы получить результат. 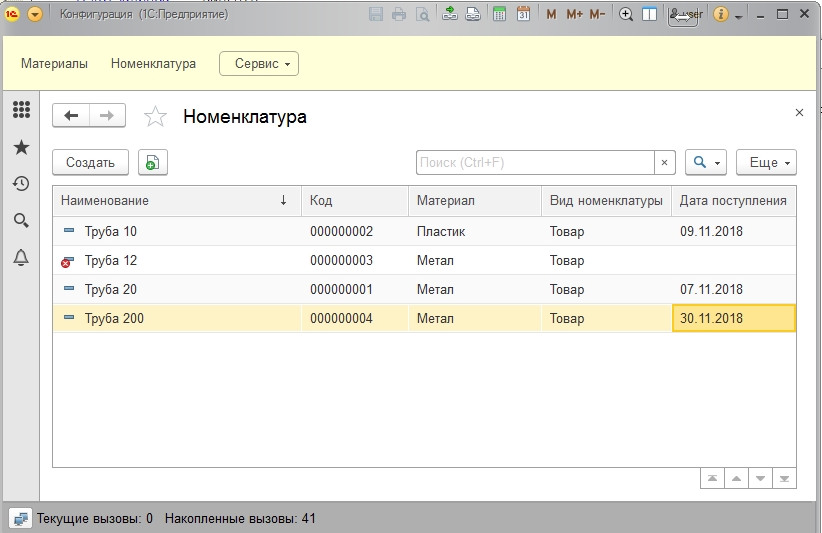
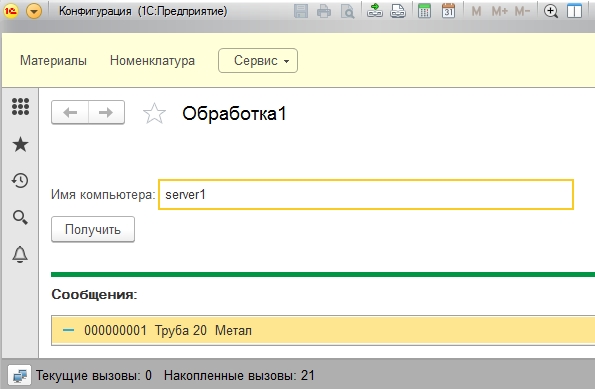 В демо-базе для скачивания требует логин и пароль Логин: user Пароль:12345 Тестировал на релизе 1С:Предприятие 8.3 (8.3.13.1513)
В демо-базе для скачивания требует логин и пароль Логин: user Пароль:12345 Тестировал на релизе 1С:Предприятие 8.3 (8.3.13.1513)
См. также
Перенос данных из УПП 1.3 в ERP 2 / УТ 11 / КА 2
Обмен между базами 1C Платформа 1С v8.3 1С:Управление производственным предприятием 1С:ERP Управление предприятием 2 1С:Управление торговлей 11 1С:Комплексная автоматизация 2.х Россия Платные (руб) Продано более 270 раз! Обработка позволяет перенести из УПП в ERP / 1С:УТ 11 / КА 2 всю возможную информацию. Переносятся документы, а также начальные остатки и справочная информация. Типовая обработка от фирмы 1С не позволяет сохранить документы за период работы. Кроме того, наши алгоритмы выгрузки начальных остатков тоже имеют больше функционала и тщательно проверялись на реальных проектах перехода с УПП на ERP. Наша разработка будет полезна как фирмам-франчайзи, которые периодически выполняют перенос данных для заказчиков, так и организациям, самостоятельно выполняющим проект по переходу. При приобретении обработки вы будете четыре месяца получать ее обновления, далее можно приобрести подписку на обновления. Конфигурации 1С постоянно меняются, выходят новые релизы. Имея подписку на обновления, вы всегда можете быть уверены, что правила конвертации данных будут работать на ваших базах 1С. 50722 руб.
04.08.2015 156603 289 264
332 289 264 156603
Перенос данных из УПП 1.3 в БП 3.0. Переносятся документы (обороты за период), справочная информация и остатки
Обмен между базами 1C Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 1С:Управление производственным предприятием 1С:Бухгалтерия 3.0 Россия Бухгалтерский учет Управленческий учет Платные (руб) Перенос данных из 1С:Управление производственным предприятием 1.3 в 1С: Бухгалтерия предприятия 3.0 с помощью правил обмена. Переносятся остатки, документы (обороты за период), справочная информация. Правила тестировались на конфигурациях УПП 1.3 (1.3.215.x) и БП 3.0 (3.0.144.x). Правила подходят для версии ПРОФ и КОРП. 28000 руб.
15.12.2021 18795 122 38
78 122 38 18795
Перенос данных из УПП 1.3 / КА 1.1 в БП 3.0 (переносятся документы, начальные остатки, справочники)
Обмен между базами 1C Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 1С:Комплексная автоматизация 1.х 1С:Управление производственным предприятием 1С:Бухгалтерия 3.0 Россия Бухгалтерский учет Платные (руб) Предлагаем перенос данных из УПП 1.3 в БП 3.0 (или из КА 1.1 в БП 3.0). Переносятся документы, начальные остатки и вся справочная информация. Есть фильтр по организации и множество других параметров выгрузки. Поддерживается несколько сценариев работы: как первичный полный перенос, так и перенос только новых документов. Перенос данных возможен в 1С: Бухгалтерию 3.0 версии ПРОФ, КОРП или базовую. Переход с «1С: Управление производственным предприятием 1.3» / «1С:Комплексная автоматизация 1.1» на «1С:Бухгалтерия предприятия 3.0» с помощью наших правил конвертации будет максимально комфортным! Обработка входит в ТОП продаж Инфостарта! 43889 руб.
25.02.2015 167411 285 237
369 285 237 167411
Перенос данных из ERP 2 / КА 2 / УТ 11 в БП 3.0
Обмен между базами 1C Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 1С:ERP Управление предприятием 2 1С:Бухгалтерия 3.0 1С:Управление торговлей 11 1С:Комплексная автоматизация 2.х Россия Платные (руб) Перенос позволяет настроить собственный обмен данными между указанными программами, альтернативный предлагаемому фирмой 1С. Перенос данных осуществляется из 1С:ERP 2 / 1С:КА 2 / 1С:УТ 11 в 1С:БП 3.0. Правила обмена оперативно обновляются при выходе новых релизов программы 1С, так что вы всегда будете иметь самую актуальную версию обработки. 38500 руб.
15.04.2019 66727 169 134
102 169 134 66727
[ED3] Обмен для ERP 2.5, КА 2.5, УТ 11.5 БП 3.0, Розница, УНФ и других с EnterpriseData (универсальный формат обмена), правила обмена
Обмен между базами 1C Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 1С:Розница 2 1С:Управление нашей фирмой 1.6 1С:Бухгалтерия 3.0 1С:Управление торговлей 11 1С:Комплексная автоматизация 2.х 1С:Управление нашей фирмой 3.0 1С:Розница 3.0 Россия Платные (руб) Правила в универсальном формате обмена для ERP 2.5, КА 2.5, УТ 11.5, БП 3.0, Розница, УНФ, для последних версий конфигураций. Ссылки на другие конфигурации в описании публикации. Правила совместимы со всеми другими версиями конфигураций новыми и старыми, поддерживающими обмен в формате EnterpriseData. Не требуется синхронного обновления правил после обновления другой конфигурации, участвующей в обмене. Типовой обмен через планы обмена кнопкой Синхронизация вручную или автоматически по расписанию, или вручную обработкой. 25080 руб.
12.06.2017 132447 692 290
380 692 290 132447
Перенос данных из ERP 2 / КА 2 в ЗУП 3
Обмен между базами 1C Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 1С:ERP Управление предприятием 2 1С:Комплексная автоматизация 2.х 1С:Зарплата и Управление Персоналом 3.x Россия Бухгалтерский учет Управленческий учет Платные (руб) Наша обработка позволяет не только перенести все документы, справочную информацию и начальные остатки из ERP 2 или КА 2 в ЗУП 3, но и организовать регулярный перенос данных между программами 1С:ERP 2 / КА 2 и 1С:ЗУП 3. Вы можете выбрать период отбора данных и установить фильтр по организациям, чтобы выгружать только необходимую информацию. Более того, перенос оперативно обновляется при выходе новых релизов программы 1С, так что вы всегда будете иметь самую актуальную версию обработки. 48278 руб.
03.12.2020 33090 73 57
72 73 57 33090
Перенос данных из УПП 1.3 в ЗУП 3.1 (или из КА 1.1 в ЗУП 3.1)
Обмен между базами 1C Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 Сложные периодические расчеты 1С:Комплексная автоматизация 1.х 1С:Управление производственным предприятием 1С:Зарплата и Управление Персоналом 3.x Россия Бухгалтерский учет Платные (руб) Перенос кадровых и расчетных данных и справочной информации из «1С:Комплексная автоматизация, ред. 1.1» или «1С:Управление производственным предприятием, ред.1.3» в «1С:Зарплата и управление персоналом», ред. 3.1. Правила позволяют перенести кадровые данные сотрудников за весь период ведения учета в КА 1.1 / УПП 1.3 и расчетные данные за выбранный период (минимально необходимый — 2 года). Позволяют осуществить переход на ведение учета зарплаты и кадров в программе 1С:Зарплата и управление персоналом, ред. 3.1. 50722 руб.
29.10.2018 53571 50 95
53 50 95 53571
Перенос данных из УТ 10.3 в УТ 11 / КА 2 / ERP 2 (ЕРП 2)
Обмен между базами 1C Взаиморасчеты Оптовая торговля Логистика, склад и ТМЦ Файловый обмен (TXT, XML, DBF), FTP Платформа 1С v8.3 1С:Управление торговлей 10 1С:ERP Управление предприятием 2 1С:Управление торговлей 11 1С:Комплексная автоматизация 2.х Россия Управленческий учет Платные (руб) Предлагаем вам качественное и проверенное временем решение для перехода с УТ 10.3 на УТ 11 / КА 2 / ERP 2. Перенос данных находится в продаже с 2015 года, постоянно развивается, им воспользовались уже более 240 компаний. Можно перенести начальные остатки, нормативно-справочную информацию и все возможные документы. При выгрузке можно установить отбор по периоду, организациям и складам. При выходе новых релизов конфигураций 1C оперативно выпускаем обновление переноса данных. 50722 руб.
24.04.2015 188863 266 237
269 266 237 188863
Посмотреть ещё
19. John_d 5044 06.12.18 17:36 Сейчас в теме
(18) красиво)
Тогда еще такую заплатку. Использовать нестандартную переменную запроса.
Запрос234а15а2 = Новый Запрос;
Aligator69; + 1 – Ответить
Остальные комментарии
- Дата
- Дата
- Рейтинг всех уровней
- Рейтинг 1-го уровня
- Древо развёрнутое
- Древо свернутое
Свернуть все
1. VmvLer 30.11.18 17:09 Сейчас в теме
Хорошая идея для небольших объемов данных: сверка, синхронизация маленьких таблиц и т.п.
Для выгрузки/загрузки полных объемов данных проще сохранить в источнике массивные данные в файл JSON и затем получить его в приемнике и обработать.
2. dsdred 2920 30.11.18 17:32 Сейчас в теме
Сразу видно не читали https://its.1c.ru/db/content/v8std/src/d810/i8100770.htm?_=1528299650
Для вашего примера достаточно OData без создания http-сервиса
А по http-сервисам вот:
П.С. Это больше на костыль похоже, причем на дыру в безопасности.
user1479482; kser87; Drivingblind; wowik; rpgshnik; papche; zarankony; frkbvfnjh; unichkin; Vladimir Litvinenko; zeegin; + 11 – Ответить
10. Aleks.spb 05.12.18 09:34 Сейчас в теме
(2) У вас отличный фундаментальный труд, на освоение которого нужно потратить от трех дней и больше, если есть возможность и время копать глубоко.
Тут конкретный узкоспециализированный пример, освоить который можно за час и оставшееся время посвятить уже решению задачи.
user1346935; gubanoff; John_d; + 3 – Ответить
13. dsdred 2920 05.12.18 15:43 Сейчас в теме
Тут конкретный узкоспециализированный пример, освоить который можно за час и оставшееся время посвятить уже решению задачи.
Есть конкретно OData, ее использование позволит сделать данную задачу еще быстрее и без создания бреши в безопасности.
П.С. Можно потратить час сейчас и X-дней потом чиня последствия. Беречь время правильно, но правильно беречь время лучше!
14. Aleks.spb 05.12.18 16:47 Сейчас в теме
(13) Вас понял, но я рассматривал это как пример организации http сервиса с post запросом/ответом в формате JSON для человека который начал с нуля.
АВЛ-деревья

Если в одном из моих прошлых постов речь шла о довольно современном подходе к построению сбалансированных деревьев поиска, то этот пост посвящен реализации АВЛ-деревьев — наверное, самого первого вида сбалансированных двоичных деревьев поиска, придуманных еще в 1962 году нашими (тогда советскими) учеными Адельсон-Вельским и Ландисом. В сети можно найти много реализаций АВЛ-деревьев (например, тут), но все, что лично я видел, не внушает особенного оптимизма, особенно, если пытаешься разобраться во всем с нуля. Везде утверждается, что АВЛ-деревья проще красно-черных деревьев, но глядя на прилагаемый к этому код, начинаешь сомневаться в данном утверждении. Собственно, желание объяснить на пальцах, как устроены АВЛ-деревья, и послужило мотивацией к написанию данного поста. Изложение иллюстрируется кодом на С++.
Понятие АВЛ-дерева
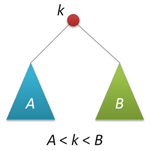
АВЛ-дерево — это прежде всего двоичное дерево поиска, ключи которого удовлетворяют стандартному свойству: ключ любого узла дерева не меньше любого ключа в левом поддереве данного узла и не больше любого ключа в правом поддереве этого узла. Это значит, что для поиска нужного ключа в АВЛ-дереве можно использовать стандартный алгоритм. Для простоты дальнейшего изложения будем считать, что все ключи в дереве целочисленны и не повторяются.
Особенностью АВЛ-дерева является то, что оно является сбалансированным в следующем смысле: для любого узла дерева высота его правого поддерева отличается от высоты левого поддерева не более чем на единицу. Доказано, что этого свойства достаточно для того, чтобы высота дерева логарифмически зависела от числа его узлов: высота h АВЛ-дерева с n ключами лежит в диапазоне от log2(n + 1) до 1.44 log2(n + 2) − 0.328. А так как основные операции над двоичными деревьями поиска (поиск, вставка и удаление узлов) линейно зависят от его высоты, то получаем гарантированную логарифмическую зависимость времени работы этих алгоритмов от числа ключей, хранимых в дереве. Напомним, что рандомизированные деревья поиска обеспечивают сбалансированность только в вероятностном смысле: вероятность получения сильно несбалансированного дерева при больших n хотя и является пренебрежимо малой, но остается не равной нулю.
Структура узлов
Будем представлять узлы АВЛ-дерева следующей структурой:
struct node // структура для представления узлов дерева < int key; unsigned char height; node* left; node* right; node(int k) < key = k; left = right = 0; height = 1; >>; Поле key хранит ключ узла, поле height — высоту поддерева с корнем в данном узле, поля left и right — указатели на левое и правое поддеревья. Простой конструктор создает новый узел (высоты 1) с заданным ключом k.
Традиционно, узлы АВЛ-дерева хранят не высоту, а разницу высот правого и левого поддеревьев (так называемый balance factor), которая может принимать только три значения -1, 0 и 1. Однако, заметим, что эта разница все равно хранится в переменной, размер которой равен минимум одному байту (если не придумывать каких-то хитрых схем «эффективной» упаковки таких величин). Вспомним, что высота h < 1.44 log2(n + 2), это значит, например, что при n=10 9 (один миллиард ключей, больше 10 гигабайт памяти под хранение узлов) высота дерева не превысит величины h=44, которая с успехом помещается в тот же один байт памяти, что и balance factor. Таким образом, хранение высот с одной стороны не увеличивает объем памяти, отводимой под узлы дерева, а с другой стороны существенно упрощает реализацию некоторых операций.
Определим три вспомогательные функции, связанные с высотой. Первая является оберткой для поля height, она может работать и с нулевыми указателями (с пустыми деревьями):
unsigned char height(node* p) < return p?p->height:0; > Вторая вычисляет balance factor заданного узла (и работает только с ненулевыми указателями):
int bfactor(node* p) < return height(p->right)-height(p->left); > Третья функция восстанавливает корректное значение поля height заданного узла (при условии, что значения этого поля в правом и левом дочерних узлах являются корректными):
void fixheight(node* p) < unsigned char hl = height(p->left); unsigned char hr = height(p->right); p->height = (hl>hr?hl:hr)+1; > Заметим, что все три функции являются нерекурсивными, т.е. время их работы есть величина О(1).
Балансировка узлов
В процессе добавления или удаления узлов в АВЛ-дереве возможно возникновение ситуации, когда balance factor некоторых узлов оказывается равными 2 или -2, т.е. возникает расбалансировка поддерева. Для выправления ситуации применяются хорошо нам известные повороты вокруг тех или иных узлов дерева. Напомню, что простой поворот вправо (влево) производит следующую трансформацию дерева:
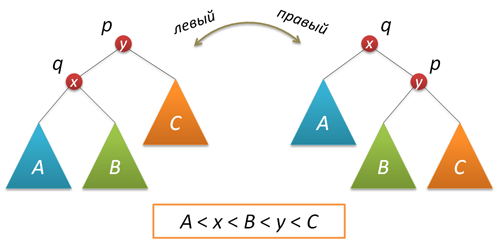
Код, реализующий правый поворот, выглядит следующим образом (как обычно, каждая функция, изменяющая дерево, возвращает новый корень полученного дерева):
node* rotateright(node* p) // правый поворот вокруг p < node* q = p->left; p->left = q->right; q->right = p; fixheight(p); fixheight(q); return q; > Левый поворот является симметричной копией правого:
node* rotateleft(node* q) // левый поворот вокруг q < node* p = q->right; q->right = p->left; p->left = q; fixheight(q); fixheight(p); return p; > Рассмотрим теперь ситуацию дисбаланса, когда высота правого поддерева узла p на 2 больше высоты левого поддерева (обратный случай является симметричным и реализуется аналогично). Пусть q — правый дочерний узел узла p, а s — левый дочерний узел узла q.
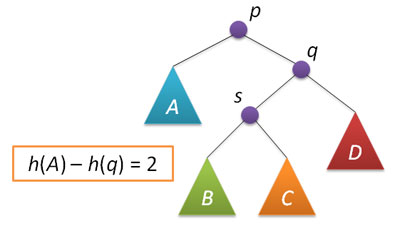
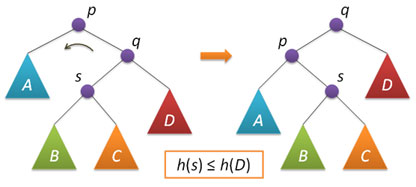
Анализ возможных случаев в рамках данной ситуации показывает, что для исправления расбалансировки в узле p достаточно выполнить либо простой поворот влево вокруг p, либо так называемый большой поворот влево вокруг того же p. Простой поворот выполняется при условии, что высота левого поддерева узла q больше высоты его правого поддерева: h(s)≤h(D).
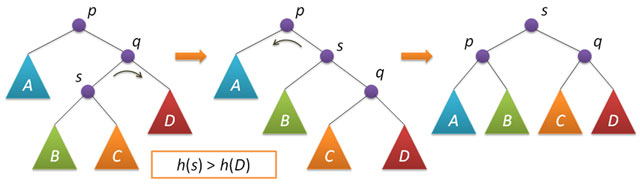
Большой поворот применяется при условии h(s)>h(D) и сводится в данном случае к двум простым — сначала правый поворот вокруг q и затем левый вокруг p.
Код, выполняющий балансировку, сводится к проверке условий и выполнению поворотов:
node* balance(node* p) // балансировка узла p < fixheight(p); if( bfactor(p)==2 ) < if( bfactor(p->right) < 0 ) p->right = rotateright(p->right); return rotateleft(p); > if( bfactor(p)==-2 ) < if( bfactor(p->left) > 0 ) p->left = rotateleft(p->left); return rotateright(p); > return p; // балансировка не нужна > Описанные функции поворотов и балансировки также не содержат ни циклов, ни рекурсии, а значит выполняются за постоянное время, не зависящее от размера АВЛ-дерева.
Вставка ключей
Вставка нового ключа в АВЛ-дерево выполняется, по большому счету, так же, как это делается в простых деревьях поиска: спускаемся вниз по дереву, выбирая правое или левое направление движения в зависимости от результата сравнения ключа в текущем узле и вставляемого ключа. Единственное отличие заключается в том, что при возвращении из рекурсии (т.е. после того, как ключ вставлен либо в правое, либо в левое поддерево, и это дерево сбалансировано) выполняется балансировка текущего узла. Строго доказывается, что возникающий при такой вставке дисбаланс в любом узле по пути движения не превышает двух, а значит применение вышеописанной функции балансировки является корректным.
node* insert(node* p, int k) // вставка ключа k в дерево с корнем p < if( !p ) return new node(k); if( kkey ) p->left = insert(p->left,k); else p->right = insert(p->right,k); return balance(p); > Чтобы проверить соответствие реализованного алгоритма вставки теоретическим оценкам для высоты АВЛ-деревьев, был проведен несложный вычислительный эксперимент. Генерировался массив из случайно расположенных чисел от 1 до 10000, далее эти числа последовательно вставлялись в изначально пустое АВЛ-дерево и измерялась высота дерева после каждой вставки. Полученные результаты были усреднены по 1000 расчетам. На следующем графике показана зависимость от n средней высоты (красная линия); минимальной высоты (зеленая линия); максимальной высоты (синяя линия). Кроме того, показаны верхняя и нижняя теоретические оценки.
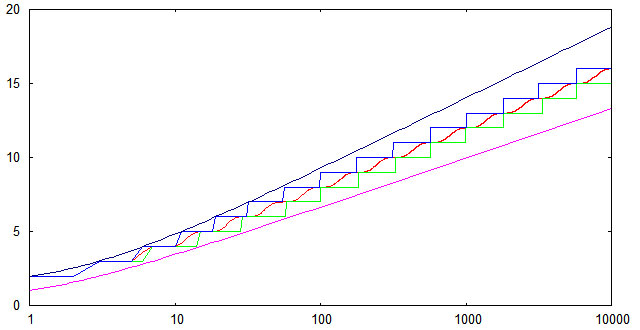
Видно, что для случайных последовательностей ключей экспериментально найденные высоты попадают в теоретические границы даже с небольшим запасом. Нижняя граница достижима (по крайней мере в некоторых точках), если исходная последовательность ключей является упорядоченной по возрастанию.
Удаление ключей
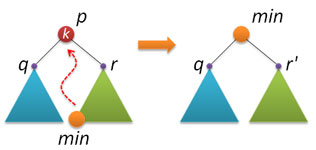
С удалением узлов из АВЛ-дерева, к сожалению, все не так шоколадно, как с рандомизированными деревьями поиска. Способа, основанного на слиянии (join) двух деревьев, ни найти, ни придумать не удалось. Поэтому за основу был взят вариант, описываемый практически везде (и который обычно применяется и при удалении узлов из стандартного двоичного дерева поиска). Идея следующая: находим узел p с заданным ключом k (если не находим, то делать ничего не надо), в правом поддереве находим узел min с наименьшим ключом и заменяем удаляемый узел p на найденный узел min.
При реализации возникает несколько нюансов. Прежде всего, если у найденный узел p не имеет правого поддерева, то по свойству АВЛ-дерева слева у этого узла может быть только один единственный дочерний узел (дерево высоты 1), либо узел p вообще лист. В обоих этих случаях надо просто удалить узел p и вернуть в качестве результата указатель на левый дочерний узел узла p.
Пусть теперь правое поддерево у p есть. Находим минимальный ключ в этом поддереве. По свойству двоичного дерева поиска этот ключ находится в конце левой ветки, начиная от корня дерева. Применяем рекурсивную функцию:
node* findmin(node* p) // поиск узла с минимальным ключом в дереве p < return p->left?findmin(p->left):p; > Еще одна служебная функция у нас будет заниматься удалением минимального элемента из заданного дерева. Опять же, по свойству АВЛ-дерева у минимального элемента справа либо подвешен единственный узел, либо там пусто. В обоих случаях надо просто вернуть указатель на правый узел и по пути назад (при возвращении из рекурсии) выполнить балансировку. Сам минимальный узел не удаляется, т.к. он нам еще пригодится.
node* removemin(node* p) // удаление узла с минимальным ключом из дерева p < if( p->left==0 ) return p->right; p->left = removemin(p->left); return balance(p); > Теперь все готово для реализации удаления ключа из АВЛ-дерева. Сначала находим нужный узел, выполняя те же действия, что и при вставке ключа:
node* remove(node* p, int k) // удаление ключа k из дерева p < if( !p ) return 0; if( k < p->key ) p->left = remove(p->left,k); else if( k > p->key ) p->right = remove(p->right,k); Как только ключ k найден, переходим к плану Б: запоминаем корни q и r левого и правого поддеревьев узла p; удаляем узел p; если правое поддерево пустое, то возвращаем указатель на левое поддерево; если правое поддерево не пустое, то находим там минимальный элемент min, потом его извлекаем оттуда, слева к min подвешиваем q, справа — то, что получилось из r, возвращаем min после его балансировки.
else // k == p->key < node* q = p->left; node* r = p->right; delete p; if( !r ) return q; node* min = findmin(r); min->right = removemin(r); min->left = q; return balance(min); >
При выходе из рекурсии не забываем выполнить балансировку:
return balance(p); >
Вот собственно и все! Поиск минимального узла и его извлечение, в принципе, можно реализовать в одной функции, при этом придется решать (не очень сложную) проблему с возвращением из функции пары указателей. Зато можно сэкономить на одном проходе по правому поддереву.
Очевидно, что операции вставки и удаления (а также более простая операция поиска) выполняются за время пропорциональное высоте дерева, т.к. в процессе выполнения этих операций производится спуск из корня к заданному узлу, и на каждом уровне выполняется некоторое фиксированное число действий. А в силу того, что АВЛ-дерево является сбалансированным, его высота зависит логарифмически от числа узлов. Таким образом, время выполнения всех трех базовых операций гарантированно логарифмически зависит от числа узлов дерева.
Всем спасибо за внимание!
Весь код
struct node // структура для представления узлов дерева < int key; unsigned char height; node* left; node* right; node(int k) < key = k; left = right = 0; height = 1; >>; unsigned char height(node* p) < return p?p->height:0; > int bfactor(node* p) < return height(p->right)-height(p->left); > void fixheight(node* p) < unsigned char hl = height(p->left); unsigned char hr = height(p->right); p->height = (hl>hr?hl:hr)+1; > node* rotateright(node* p) // правый поворот вокруг p < node* q = p->left; p->left = q->right; q->right = p; fixheight(p); fixheight(q); return q; > node* rotateleft(node* q) // левый поворот вокруг q < node* p = q->right; q->right = p->left; p->left = q; fixheight(q); fixheight(p); return p; > node* balance(node* p) // балансировка узла p < fixheight(p); if( bfactor(p)==2 ) < if( bfactor(p->right) < 0 ) p->right = rotateright(p->right); return rotateleft(p); > if( bfactor(p)==-2 ) < if( bfactor(p->left) > 0 ) p->left = rotateleft(p->left); return rotateright(p); > return p; // балансировка не нужна > node* insert(node* p, int k) // вставка ключа k в дерево с корнем p < if( !p ) return new node(k); if( kkey ) p->left = insert(p->left,k); else p->right = insert(p->right,k); return balance(p); > node* findmin(node* p) // поиск узла с минимальным ключом в дереве p < return p->left?findmin(p->left):p; > node* removemin(node* p) // удаление узла с минимальным ключом из дерева p < if( p->left==0 ) return p->right; p->left = removemin(p->left); return balance(p); > node* remove(node* p, int k) // удаление ключа k из дерева p < if( !p ) return 0; if( k < p->key ) p->left = remove(p->left,k); else if( k > p->key ) p->right = remove(p->right,k); else // k == p->key < node* q = p->left; node* r = p->right; delete p; if( !r ) return q; node* min = findmin(r); min->right = removemin(r); min->left = q; return balance(min); > return balance(p); > Источники
- B. Pfaff, An Introduction to Binary Search Trees and Balanced Trees — описание библиотеки libavl
- Н. Вирт, Алгоритмы и структуры данных — сбалансированные деревья по Вирту — это как раз АВЛ-деревья
- Т. Кормен и др., Алгоритмы: построение и анализ — про АВЛ-деревья говорится в упражнениях к главе про красно-черные деревья
- Д. Кнут, Искусство программирования — раздел 6.2.3 посвящен теоретическому анализу АВЛ-деревьев