Telegram Bot

Телеграм бот на Python / #1 – Разработка ботов с нуля. Как создать Telegram Bot?
Представляем курс для начинающих по разработке Telegram ботов на Python. За курс вы с нуля научитесь создавать Телеграм ботов в разных жанрах и с использованием разных библиотек.
Видеоурок
Разработка ботов
За последние несколько лет боты стали неотъемлемой частью многих интернет компаний. За счет ботов компании могут автоматизировать рутинную работу и могут позволить пользователю быстро получить необходимую информацию.
В связи с этим сфера их разработки сейчас действительно очень популярна. Многие компания хотят иметь своего телеграмм бота и поэтому ищут специализированных разработчиков. Приятно в этом то, что на изучение разработки вам придется потратить всего пару дней (за исключением изучения самого языка программирования). После пары дней тренировок вы уже сможете брать заказы на фрилансе и получать за их выполнение деньги.
Почему Telegram?
В современном мире мессенджеры стали основным способом для общения в интернете. Существует много мессенджеров, но с уверенностью можно сказать что одним из самых популярных является Телеграм.

Поэтому, если вы решили создавать ботов, то логично начать сразу с наиболее популярной платформы в этой сфере. Изучив разработку Telegram ботов вы позже сможете переключиться и на разработку ботов под другие мессенджеры или соц сети. Принцип работы всех ботов примерно одинаков. Разница заключается лишь в использовании разных библиотек и методов в них.
Инструменты разработчика
На самом деле для разработки ботов вы можете использовать любые языки программирования. Можно писать на PHP, C#, Java и даже на JavaScript.
Многие разработчики выбирают тот язык, на котором они пишут в повседневной жизни. Если же такого языка нет, то одним из наилучших в этом плане является язык Python. Он легок в использовании и позволяет быстро добавить необходимый функционал для вашего бота.

Такая легкость в частности обеспечена обилием библиотек, что были разработаны под этот язык для быстрого описания и выполнения команд.
Плюс выбор падает на Питон, так как на его основе можно создавать ботов и под другие мессенджеры, что очень удобно, ведь синтаксис будет такой же.
План курса
В ходе курса вы с нуля научитесь создавать Telegram ботов под разные сферы и цели применения. Вы научитесь работать с несколькими библиотеками для построения ботов, а также внедрите в код разные API системы для интеграции полезных функций.
К концу курса у вас будут хорошие навыки по созданию ботов. Вы сможете создавать ботов, что будут представлять из себя набор полезных действий или даже полноценный магазин с покупками.
Дополнительный курс
На нашем сайте вы также найдете курс « Профессия Python разработчик ». В ходе огромной программы вы изучите язык Python, научитесь работать с базами данных, тестированием и научитесь создавать веб сайты за счёт фреймворка Django.
За курс вы изучите массу нового и к концу программы будете уметь работать с языком Питон, создавать на нём полноценные ПК приложения на основе библиотеки Kivy и создавать веб сайты на основе библиотеки Джанго.
Задание к уроку
Создание бота
Создайте нового бота через Телеграм. Укажите что ваш бот будет иметь название: «ВашеИмяФамилия My Bot».
Посмотреть ответ
Для создания бота зайдите в Телеграм и найдите официального бота @BotFather .
Запустите его и пропишите команду «/newbot». Далее укажите название для бота и его программный адрес.
Большое задание по курсу
Вам необходимо оформить подписку на сайте, чтобы иметь доступ ко всем большим заданиям. В задание входит методика решения, а также готовый проект с ответом к заданию.
PS: подобные задания доступны при подписке от 1 месяца
Как разработать Telegram-бота на Python+C
Создаем Telegram-бот, работаем c I/O Bound нагрузкой, подключаем фичи Google Drive и пишем на C внутри Python.
Эта инструкция — часть курса «Как создавать Telegram-ботов».
Смотреть весь курс
Введение
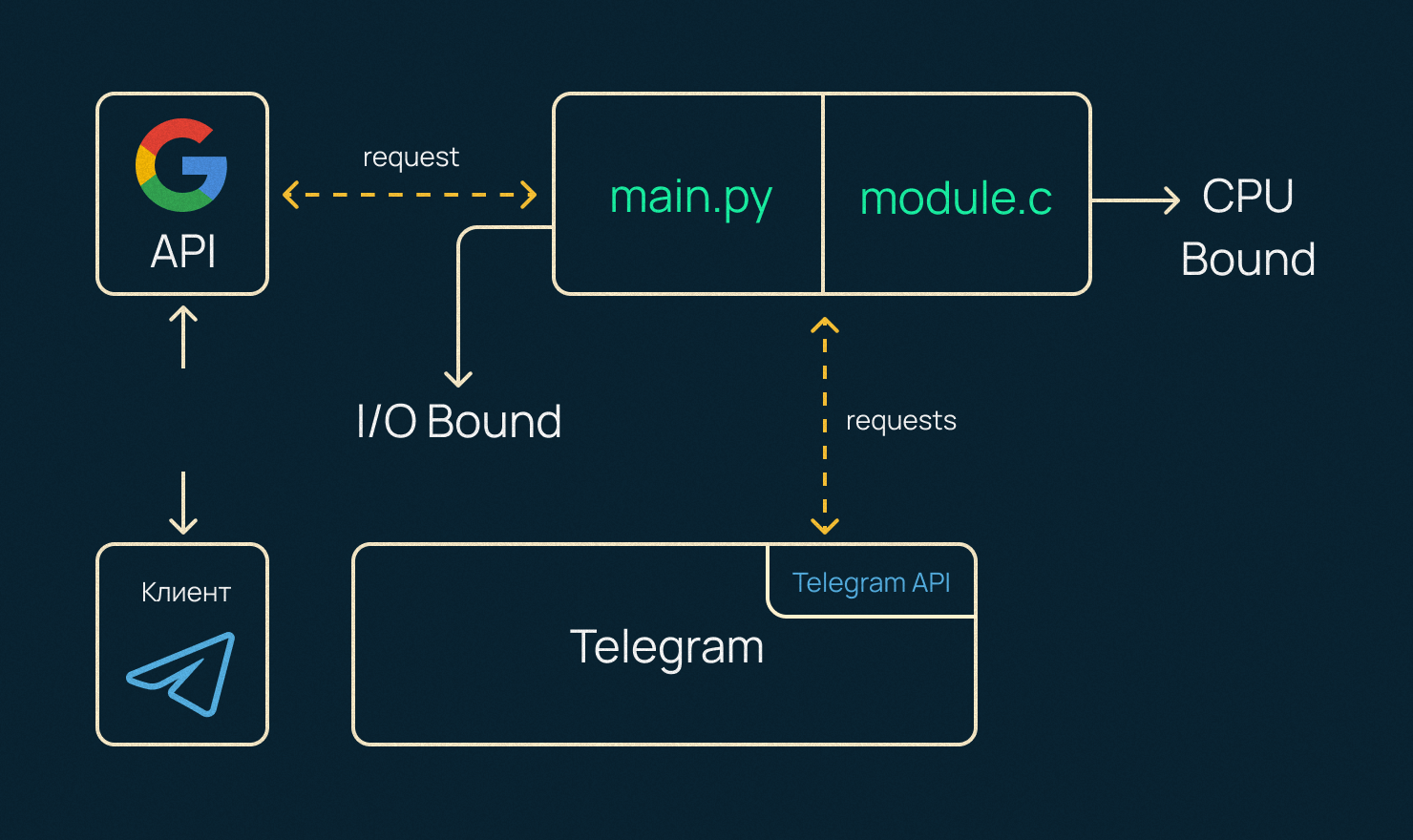
В этой инструкции мы создадим приложение, которое интегрируется со сторонними API. Разберем I/O Bound нагрузку и поработаем с асинхронностью в Python.
Часть сервера Telegram-бота мы будем писать на С, так как он считается перформанс-ориентированным языком, поэтому посмотрим также модуль обработки СPU Bound нагрузки, использующийся для сложных вычислений процессора.
Мы постараемся объяснить все: от развертывания каждого модуля до настройки проекта на удаленном сервере.
Работать все это будет в вебе, поэтому для примера клиент-серверной архитектуры используется Telegram. У нас по дефолту будет мобильный+десктопный клиент, поэтому не придется писать фронтенд самому.
Теория
У многих приложений есть открытый интерфейс (API), к которому можно подключиться из своих программ. Например, так можно подключиться к YouTube и попросить сервис прислать описания всех роликов из конкретного плейлиста.
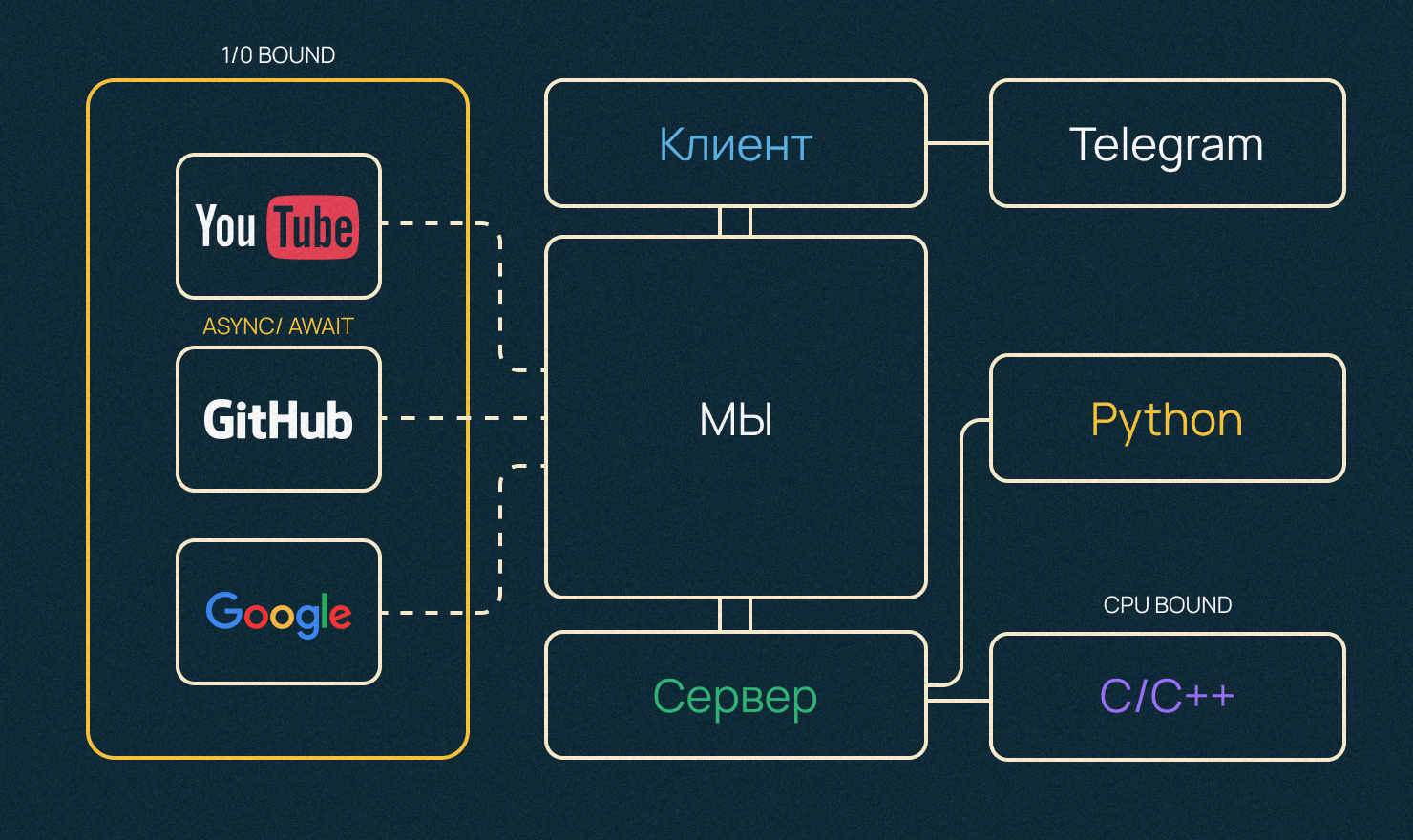
Что такое CPU Bound и I/O Bound нагрузка. Примеры
- Есть какая-то задача Х, которая сильно нагружает процессор. Например, одни из самых медленных операций, которые выполняет современный процессор — деление или тригонометрические функции типа sin или cos. Такие сложные для процессора операции называют CPU Bound нагрузкой.
- Если операции упираются в скорость сети, скорость записи или чтения какого-то файла с диска или ожидания запроса из базы данных — это I/O Bound нагрузка. Отправили запрос к серверу и ждете, пока он придет — процессор простаивает, как правило, 90% времени.
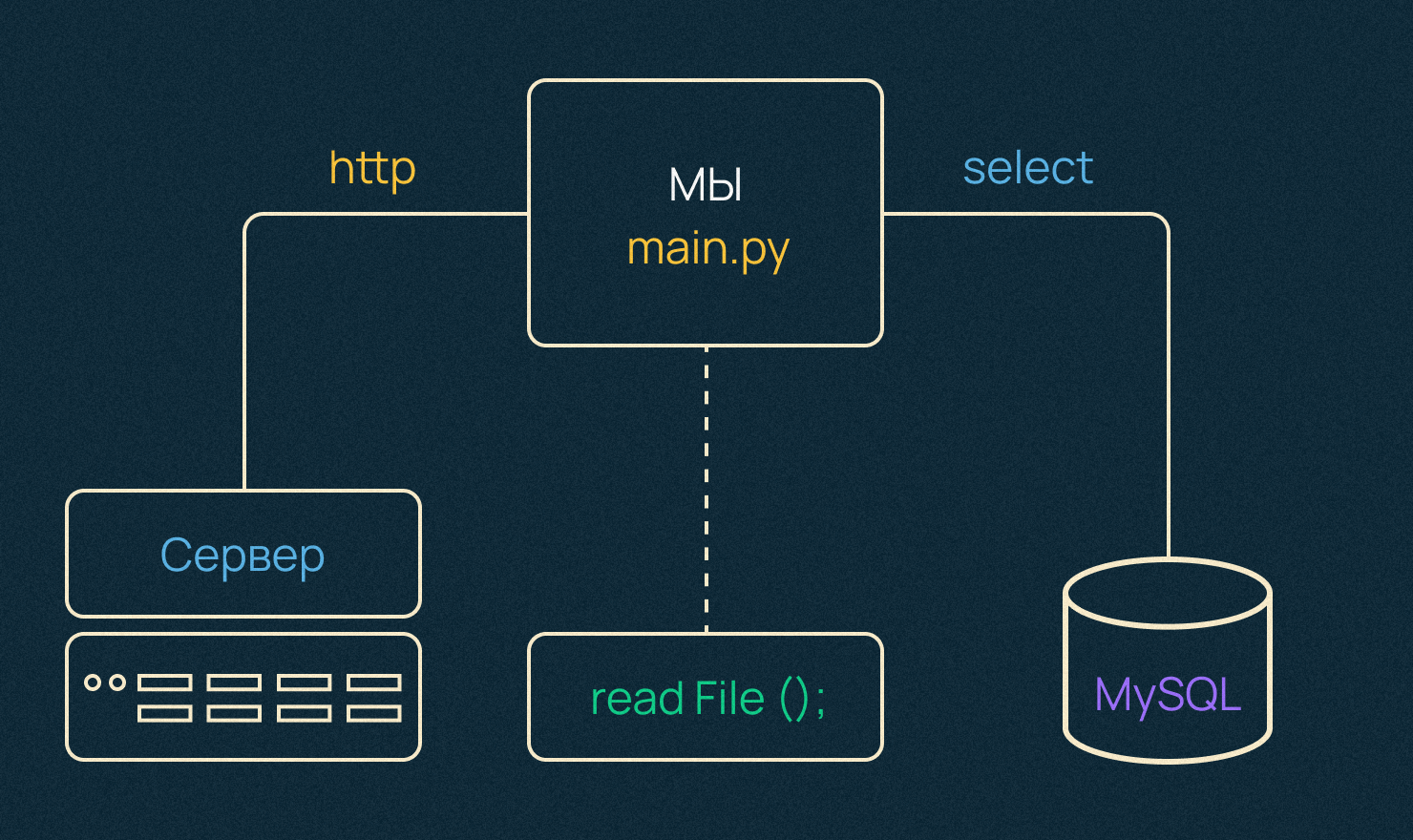
Как эти проблемы решаются в Python?
- Можно использовать модуль мультипроцессинга, который распараллелит вычисления на несколько процессов на нескольких реальных ядрах. Первый оверхед — создание новых процессов в операционной системе — достаточно дорогая операция. А их взаимодействие — второй оверхед, то есть обмен данными между ними — не самая простая вещь. Как минимум, чтобы передать объект между ними, объект должен быть сериализован и десериализован соответствующе. Если кратко: сериализация — это очень дорого.
- Мультитрединг — дешевле, особенно вскейле, то есть когда мы планируем масштабировать и создавать большие пулы потоков. Потому что поток — это более легковесная сущность с точки зрения операционной системы и в сравнении с процессом, как минимум.
Самое важное, что потоки расшаривают одну и ту же область памяти внутри одного процесса. То есть обмен данными между ними организован гораздо проще.
В Python есть GIL или блок интерпретатора, с которым могут быть проблемы. В каждый конкретный момент времени может работать только один, залоченный поток, а другим приходится ждать.
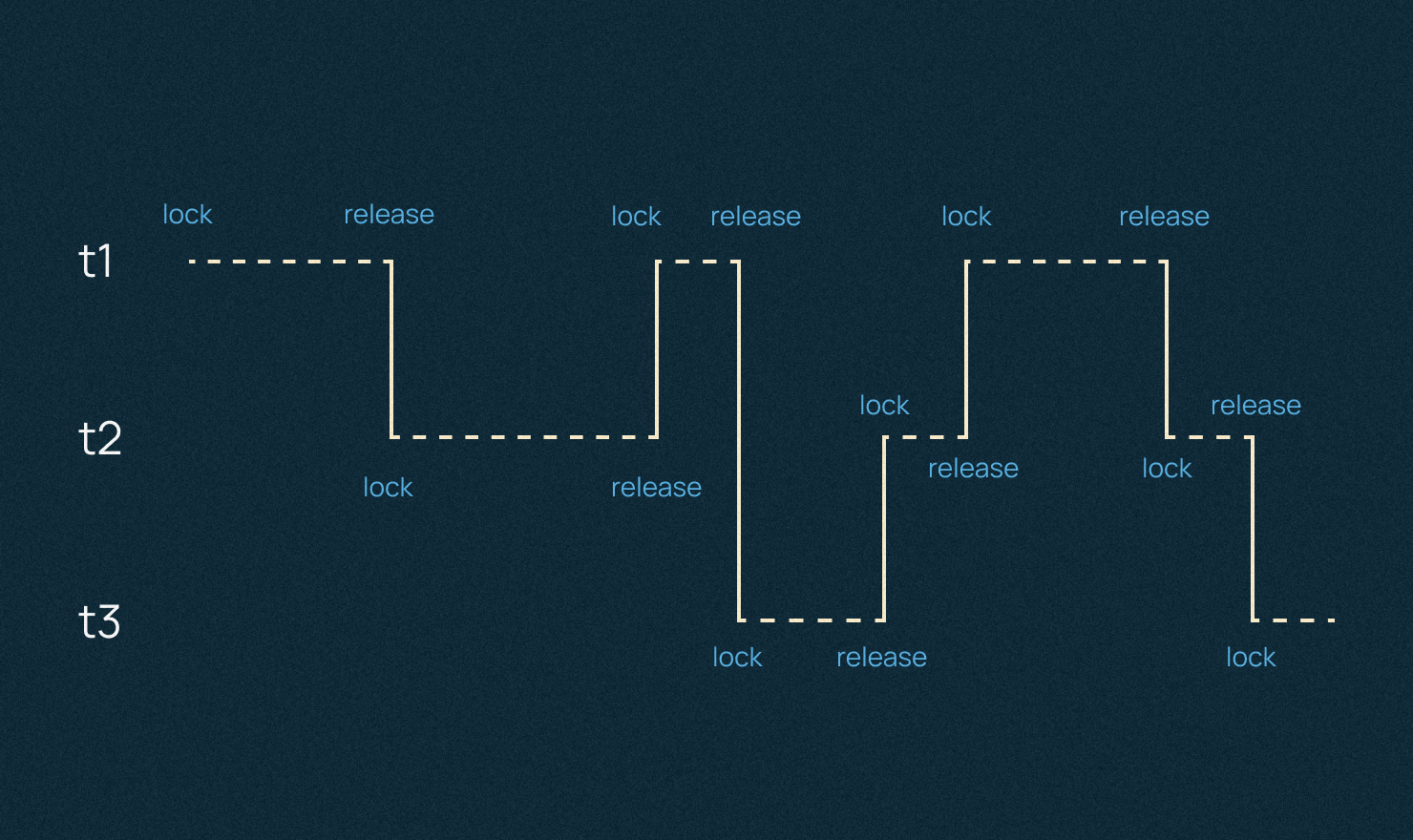
В случае решения второй проблемы и I/O Bound нагрузки, то в Python она решается асинхронным программированием.
Практика
О том, как создаются Telegram-боты, можно посмотреть здесь. Начнем с нашего интерфейса.
Возьмем первую библиотеку для Python: Python-telegram-bot.
Чтобы не захламлять компьютер чем-то лишним, будем использовать питоновскую виртуальную среду (venv). Это похоже на изолированный контейнер, в котором можно проводить любые опыты, и доступно это только внутри этой папки.
Сначала нам нужен токен от BotFather для аутентификации с API Telegram. Плюс здесь можно устанавливать ряд других настроек: изменить описание, поставить моды. BotFather по сути представляет собой админку.
Токен мы будем хранить в скрытых данных. За это в Python отвечает модуль dotenv, который также ставится внутри нашей виртуалки, и в сам файл уже переносим токен.
from bot.bot import start, list_files, upload_file, search_button, cython, pi_button, FIRST, SECOND from dotenv import load_dotenv from telegram.ext import ApplicationBuilder, CommandHandler, MessageHandler, filters, CallbackQueryHandler, ConversationHandler import os async def hello(update: Update, context: ContextTypes.DEFAULT_Type) ->Name: Name: await update.message.replay_text(f'Hello(update.effective_user.first_name)') load_dotenv() application = ApplicationBuilder().token(os.getenv('TOKEN')).build() app.add_handler(CommandHandler(“hello”, hello)) app.run.polling() Чтобы подружить Telegram с Google Drive воспользуемся API /quickstart/python. Здесь нам нужно получить что-то вроде токена, как и в случае аутентификации с API Telegram, только в Google API это называется(Credentials). В main.py мы должны добавить и токен, и обработчик функции start.
По этой логике нужно написать еще одну функцию и добавить ее в еще один handler уже для сэмпла от Google Drive.
Добавляем еще один CommandHandler (обработчик команд или все, что мы пишем через слэш).
В Telegram, проверить работу функции можно командой /files, которую мы можем легко добавить в админке BotFather
По коду Google: мы достаем секретки и вытаскиваем все файлы, дальше выводим их в консоль. Можно сделать, чтобы ответ приходил не в консоль сервера, а сразу в бот на клиент.
Загрузка файлов
Для демонстрации возможностей добавим еще и загрузку файлов. Google предлагает здесь обширный список того, что можно делать: Работа со всеми видами файлов, работа с UI Google Drive, и так далее.
Нам для интерактивности нужна динамика, поэтому мы будем грузить файл сначала на наш сервер через интерфейс Telegram, а уже оттуда его перенаправлять в Google Drive.
Чтобы загрузить файл сначала к нам на сервер, воспользуемся вот этим код-сниппетом из библиотеки telegram-bot-api а конкретно Download file.
Промежуточный итог
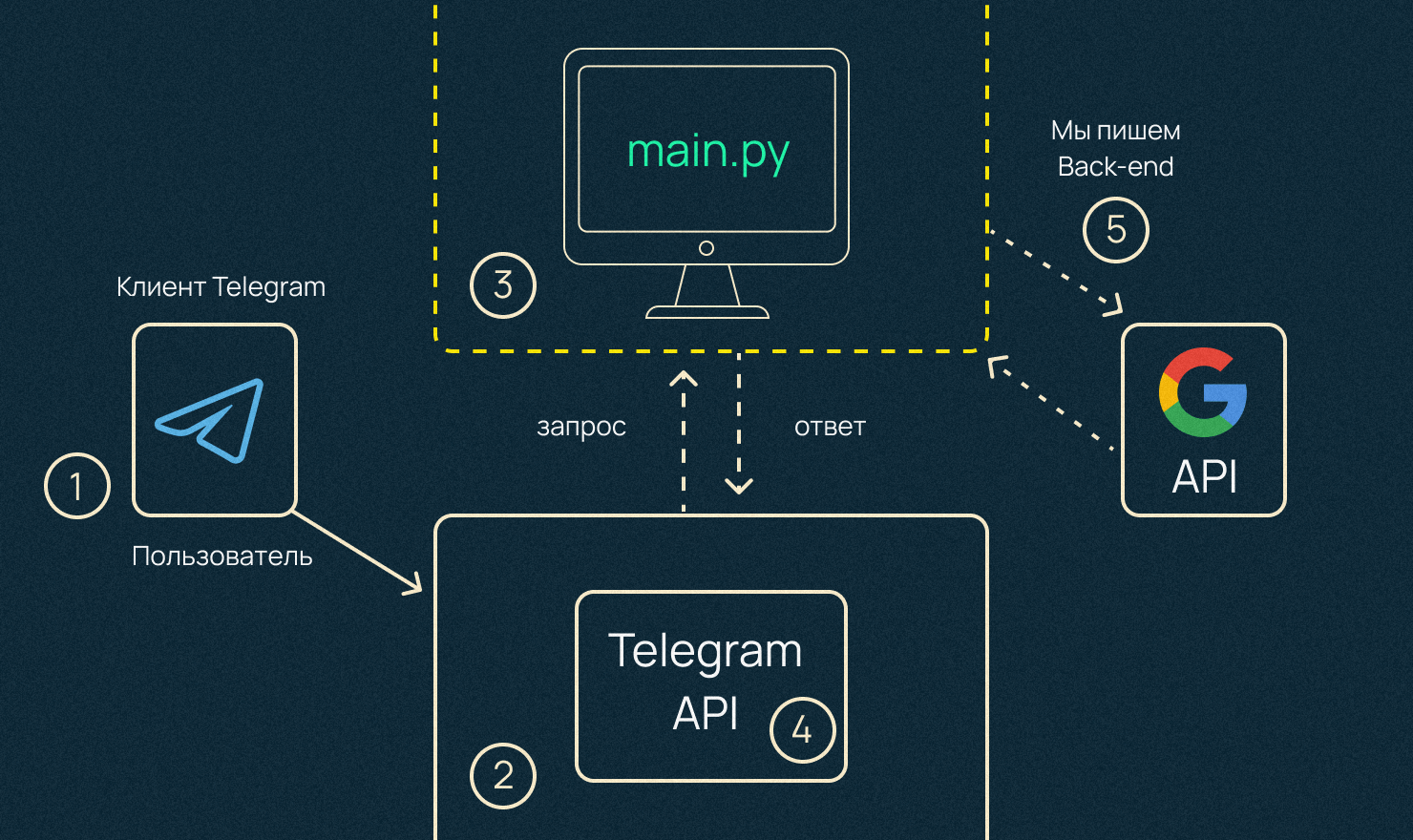
У нас есть сервер. Место, где мы разворачиваем наш код: удаленный или наш компьютер. Там мы запускаем наш Telegram-бот. Через интерфейс Telegram-бота, который нам дается по стандарту, мы можем загрузить файл, и он будет у нас лежать либо на компьютере, либо на удаленном сервере.
Этим сниппетом сначала загружаем файлы на компьютер. В отдельную функцию вынесем аутентификацию с Google Drive, чтобы было почище. Дальше во все захардкоденные сниппеты Google мы добавим наши динамические данные в виде имен файлов и путей. Все это достается из аргументов Update и Context.
Добавим также обработчик команд MessageHandler для медиасообщений.
Теперь, если вызвать эту функцию, то сначала файл появится в нашей папке Downloaded, а потом в Google Drive.
В конечном счете код в файле main.py у нас должен выглядеть так:
from bot.bot import start, list_files, upload_file, search_button, cython, pi_button, FIRST, SECOND from dotenv import load_dotenv from telegram.ext import ApplicationBuilder, CommandHandler, MessageHandler, filters, CallbackQueryHandler, ConversationHandler import os def main(): import cProfile import pstats load_dotenv() application = ApplicationBuilder().token(os.getenv('TOKEN')).build() application.add_handler(CommandHandler('start', start)) with cProfile.Profile() as pr: application.add_handler(CommandHandler('files', list_files)) stats = pstats.Stats(pr) stats.sort_stats(pstats.SortKey.TIME) stats.dump_stats(filename='profiling.prof') conv_handler = ConversationHandler( entry_points=[CommandHandler("cython", cython)], states=< FIRST: [CallbackQueryHandler(search_button)], SECOND: [CallbackQueryHandler(pi_button)], >, fallbacks=[CommandHandler("cython", cython)], ) application.add_handler(conv_handler) application.add_handler(MessageHandler(filters.Document.ALL, upload_file)) application.run_polling() if __name__ == '__main__': main() На этом мы закончили работу с I/O Bound нагрузкой и ее функциями. А что если мы хотим добавить функциональность по нагрузке процессора? Вариаций действительно много. Можно сделать промежуточный лэйер, который будет брать видео, которые мы грузим, монтажить их в клип, сжимать и выгружать на Google Drive уже готовые препродакшн видео.
Модуль для сложных вычислений на процессоре
Следующая фича на бэкенде. Мы сейчас добавим модуль для CPU Bound обработки именно на процессоре, и делать это будет Python в связке с языком С. Более того, делать мы это будем в нескольких потоках. То есть мы отключим питоновский GIL.
Потенциально это может создать много проблем с синхронизацией, но тема многопоточности — это отдельная история, которую мы в рамках инструкции вынесем за скобки.
Первый модуль будет большой аллокацией + бинарный поиск по массиву. Заодно так проверим, как это работает. Папка lowlevel для C-файлов и сразу заведем модуль с парой простых функций.
int*allocate(int N) int* ptr = malloc(sizeof(int)* N); Выделяем память для массива данных. Внутри функции поиска элементов будем вызывать наши функции для аллокации и генерации данных. Так можно увидеть наглядно, как работает процессор линейно, в нескольких потоках и в нескольких процессах. Эта практика сейчас используется для наглядности, но в боевых проектах так делать не стоит.
Чтобы вызывать код на С из-под Python нам потребуется Cython. Это суперсет Python, который позволяет писать на C прямо внутри Python. Чтобы все это работало, нужно поставить это в виртуалку и добавить файл для интерфейса Python и C.
cdef extern from "lowlevel/module.c" nogil; int binary_search_imp(int index) cdef int b_search_(int index): Затем создаем промежуточную функцию, которая будет вызывать нашу экспортированную C функцию.
cdef int b_search(int index): return binary_search_impl(index); def binary_search(int index, results = None): cdef int result; with nogil: result = b_search(index); if results is not None: results.append(result) return result Самое важное — поставить аннотацию nogil, то есть здесь мы отключаем лок интерпретатора (GIL).
Итак, у нас есть С файл с core-функциями. У нас есть файл, чтобы этими функциями пользоваться в самом Python.
Теперь в новом файле опишем все Python-функции. Чтобы не путаться, назовем его, например, performance.py. В него сразу добавим функцию по вычислению дельты времени, от начала и конца исполнения. Она позволит наглядно увидеть скорость Python в линейном режиме, многопоточном и в многопроцессном.
Функция, внутри которой есть функция-обертчик, где есть вызов функции, которую мы декорируем. Чтобы протестить все, что мы написали, нам нужны три основных функции.
Линейная. Все вычисления будут происходить по очереди в одном потоке, как обычно работает Python. Асинхронность здесь не сработает, потому что все это нагружает именно процессор, а не любого рода ввод/вывод.
def linear(N) results = [] binary_search(N, results) return results Многопоточная. Создаем пять потоков по одному вызову в каждом.
def multithreaded(N): results = [] Мультипроцессинговая. Функция с изолированным друг от друга процессами: shared.list.
shared.list. def multithreaded(N): results = mp.Managed.lists() Теперь перейдем к следующему конфигу, по настройке Cython. Назовем его setup.py. Что здесь должно быть?
- файл, который нужно скомпилировать,
- модуль, который мы создаем и будем использовать,
- функция setup, которая будет все это структурировать.
Код выглядит так:
from setuptools import setup from distutils.extension import Extension from Cython.Distutils import build_ext sourceFiles = ['bot/nogil.pyx'] ext_modules = [ Extension("nogil", sourceFiles ), ] setup( name='google drive app', cmdclass=, ext_modules=ext_modules ) Добавим простой bash-script, чтобы собирать все было удобнее.
# !/bin/bash [! -e "nogil.c" ] || rm "nogil.c" find . -name "*.so" -type f -delete python3 setup.py build_ext -b build mv bot/*.c bot/lowlevel/ Теперь все должно адекватно пересобираться и раскладываться по своим местам.
Чтобы в самом Telegram-боте это выглядело красиво, добавим пару кнопок. В Inline-боте нужны две функции: описание и кнопка + события, которые будут происходить, когда мы будем на нее нажимать.
Вызываем функцию бинарного поиска в наших 3-х тестах. Линейном, многопоточном и многопроцессном, дергаем наши три функции. Добавляем обработчики для кнопок и можно тестировать.
Почти секунда у нас уйдет, чтобы выделить необходимую память для каждого вызова функции. Многопоточность обгоняет линейную более чем на 50%. Многопроцессность также быстрее, но все же уступает многопоточности.
В конце у нас должен получиться примерно такой код в bot.py:
from __future__ import print_function import os import logging from telegram import Update from telegram.ext import ContextTypes import os.path from google.auth.transport.requests import Request from google.oauth2.credentials import Credentials from google_auth_oauthlib.flow import InstalledAppFlow from googleapiclient.discovery import build from googleapiclient.errors import HttpError from googleapiclient.http import MediaFileUpload from telegram import InlineKeyboardButton, InlineKeyboardMarkup, Update from bot.performance import linear, multithreaded, multiprocessed, linear_pi, mt_pi, mp_pi logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO ) def creds(): # If modifying these scopes, delete the file token.json. SCOPES = ['https://www.googleapis.com/auth/drive'] """Shows basic usage of the Drive v3 API. Prints the names and ids of the first 10 files the user has access to. """ creds = None # The file token.json stores the user's access and refresh tokens, and is # created automatically when the authorization flow completes for the first # time. if os.path.exists('token.json'): creds = Credentials.from_authorized_user_file('token.json', SCOPES) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'credentials.json', SCOPES) creds = flow.run_local_server(port=0) # Save the credentials for the next run with open('token.json', 'w') as token: token.write(creds.to_json()) return creds async def start(update: Update, context: ContextTypes.DEFAULT_TYPE): await context.bot.send_message(chat_id=update.effective_chat.id, text="I'm a bot, please talk to me!") async def list_files(update: Update, context: ContextTypes.DEFAULT_TYPE): try: service = build('drive', 'v3', credentials=creds()) # Call the Drive v3 API results = service.files().list( pageSize=10, fields="nextPageToken, files(id, name)").execute() items = results.get('files', []) if not items: print('No files found.') return #4.362e-06 # l = [] # for f in items: # l.append(f.get("name")) print('Files:') #4.103e-06 for item in items: await context.bot.send_message(chat_id=update.effective_chat.id, text=item.get("name")) print(u' ()'.format(item['name'], item['id'])) except HttpError as error: # TODO(developer) - Handle errors from drive API. print(f'An error occurred: ') async def upload_file(update: Update, context: ContextTypes.DEFAULT_TYPE): newFile = await update.message.effective_attachment.get_file() await newFile.download(custom_path="downloaded/" + update.message.effective_attachment.file_name) try: # create drive api client service = build('drive', 'v3', credentials=creds()) file_metadata = media = MediaFileUpload("downloaded/"+update.message.document.file_name, mimetype=update.message.document.mime_type, resumable=True) # pylint: disable=maybe-no-member file = service.files().create(body=file_metadata, media_body=media, fields='id').execute() print(F'File ID: ') except HttpError as error: await context.bot.send_message(chat_id=update.effective_chat.id, text="Failure") print(F'An error occurred: ') file = None await context.bot.send_message(chat_id=update.effective_chat.id, text="Success") return file.get('id') FIRST, SECOND = range(2) async def cython(update: Update, context: ContextTypes.DEFAULT_TYPE): keyboard = [ [InlineKeyboardButton(u"Search", callback_data=str(FIRST))] ] reply_markup = InlineKeyboardMarkup(keyboard) await update.message.reply_text(u"First module", reply_markup=reply_markup) return FIRST async def search_button(update: Update, context: ContextTypes.DEFAULT_TYPE): query = update.callback_query keyboard = [ [InlineKeyboardButton(u"Pi", callback_data=(SECOND))] ] index = ((2**31-1) // 32 - 1) await context.bot.send_message(chat_id=update.effective_chat.id, text="lin: "+linear(index)) await context.bot.send_message(chat_id=update.effective_chat.id, text="mt: "+multithreaded(index)) await context.bot.send_message(chat_id=update.effective_chat.id, text="mp: "+multiprocessed(index)) #reply_markup = InlineKeyboardMarkup(keyboard) await context.bot.edit_message_text(chat_id=query.message.chat_id, message_id=query.message.message_id, text=u"Second module") reply_markup = InlineKeyboardMarkup(keyboard) await context.bot.edit_message_reply_markup(chat_id=query.message.chat_id, message_id=query.message.message_id, reply_markup=reply_markup) return SECOND async def pi_button(update: Update, context: ContextTypes.DEFAULT_TYPE): query = update.callback_query await context.bot.send_message(chat_id=update.effective_chat.id, text="lin: "+linear_pi(100000000)) await context.bot.send_message(chat_id=update.effective_chat.id, text="mt: "+mt_pi(100000000)) await context.bot.send_message(chat_id=update.effective_chat.id, text="mp: "+mp_pi(100000000)) await context.bot.edit_message_text(chat_id=query.message.chat_id, message_id=query.message.message_id, text=u"You can add more CPU bound modules") Тестируем на Linux сервере
Мы будем использовать последнюю версию Ubuntu и выберем самое простое железо. Кроме этого, с помощью Shared Line можно использовать только 10% ресурсов, поэтому это будет еще дешевле, но под наш pet-проект хватит. В день такая конфигурация будет стоить не больше 15 рублей.
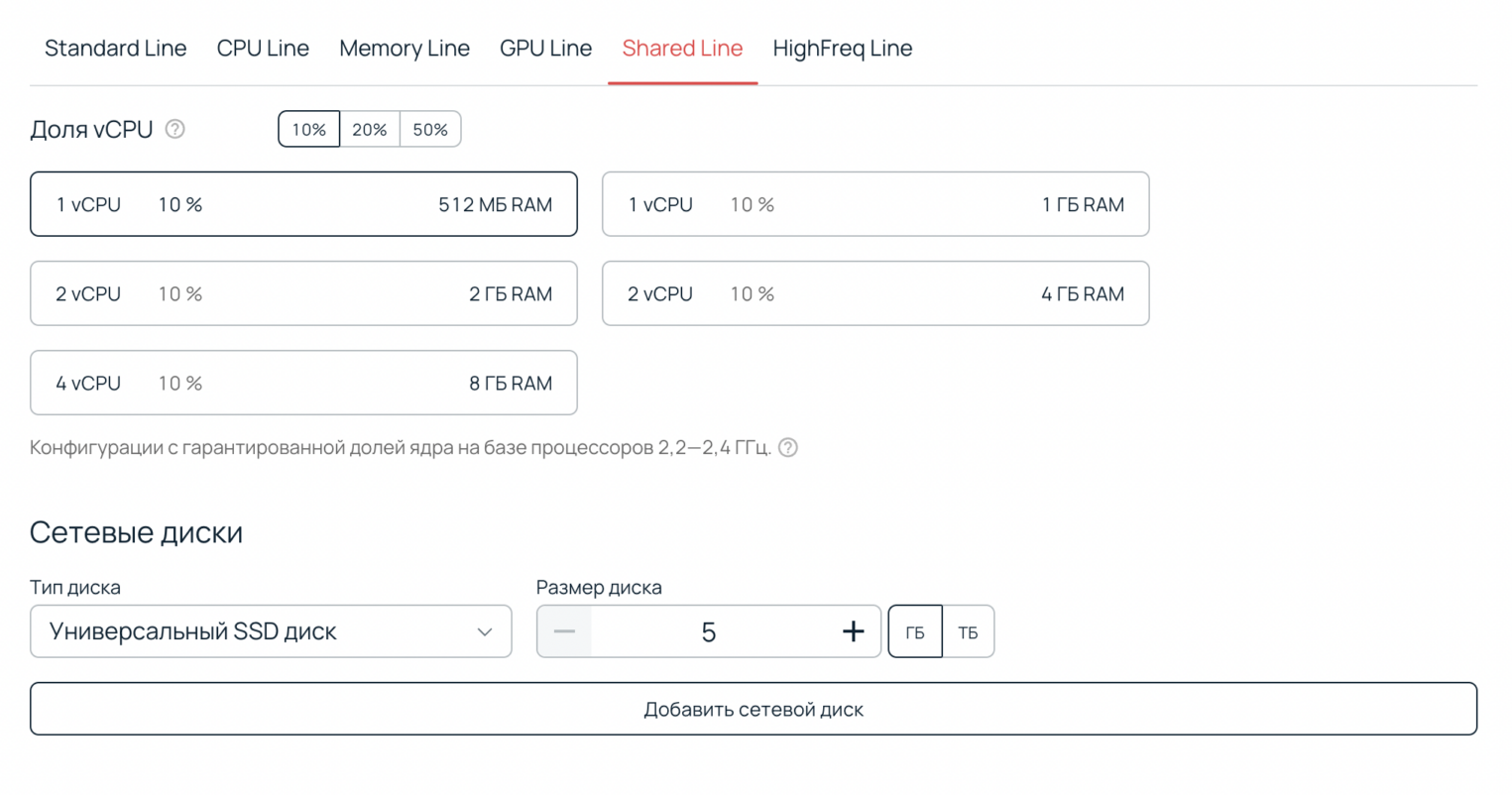
Поднимаем и обновляем там все, потому что это fresh Linux. Далее загружаем весь код бота на сервер, и можно приступать к тестированию: закинем пару файлов в наш Telegram-бот. Тестируем работу загрузки файлов. Вывода файлов, и сами функции по нагрузке CPU bound вычислений.
Заключение
Мы подключаемся к открытому API Google Drive, и вместо того, чтобы в самом диске нажимать разные кнопки, мы можем управлять им из-под Telegram-бота. Сделать это можно не только с диском, но и с любым сервисом, у которого есть открытый API.
Кроме этого, мы рассмотрели пару фич для работы с CPU Bound нагрузками, что может помочь разгрузить какие-то сложные для процессора вычисления.
Как разработать Telegram-бота на Python, который будет генерировать сложные пароли прямо в мессенджере?
Чтобы придумать надежный и запоминающийся пароль, можно объединить несколько слов в последовательность, напоминающую сюжет. А после — разбавить специальными символами. Алгоритм простой, но его можно автоматизировать — написать Telegram-бота для генерации паролей. В тексте рассказываем, как это сделать.
Используйте навигацию, если нет времени читать текст целиком:
- Требования к работе бота
- Что понадобится для разработки бота
- Как настроить бота
- Деплой бота на сервер
- Программируем кастомные пресеты
- Что можно добавить
Требования к работе бота
Прежде чем приступить к написанию кода, определим правила, по которым бот должен работать.
- Длина пароля должна быть от 2 до 8 слов. Так мы усложним задачу злоумышленнику: подобрать связку слов намного сложнее, чем одно слово.
- Между словами могут быть разделители в виде цифр и спецсимволов. Это увеличит энтропию и затруднит подбор пароля. Пароль с разделителями может выглядеть так: unmovable8ENCRUST=macho.
- Дополнительно в пароле могут использоваться спецсимволы в начале (префиксы) и в конце (суффиксы) слова, которые также помогут увеличить сложность подбора.
- Количество слов, разделителей, префиксов и суффиксов должен настраивать пользователь. Для этого ему нужен интерфейс в виде сообщения с кнопками настроек.
- Пользовательские настройки должны сохраняться даже после перезагрузки сервера с ботом. В качестве базы данных подойдет Redis.
Что понадобится для разработки бота
Перед началом нужно подготовить среду разработки, установить нужные библиотеки и программы, а именно:
- Python — от версии 3.9 и выше,
- aiogram — асинхронный фреймворк для работы с Telegram Bot API,
- Redis — быстрое key-value хранилище,
- redis-py — клиент для работы с Redis,
- XKCD-password-generator — библиотека для генерации паролей,
- pydantic — библиотека для валидации данных и формирования настроек приложения.
Самое главное — репозиторий на GitHub. Его нужно импортировать в свое рабочее окружение и настроить.
Как настроить бота
Запустим бота локально. На этом этапе можем обойтись без Redis, но важно учитывать, что пользовательские настройки не будут сохранены между перезапусками.
Если используете среду разработки PyCharm, запустить бота будет максимально просто. После клонирования репозитория переключитесь на ветку article-tweaks (git checkout article-tweaks) и создайте новую конфигурацию запуска (Run Configuration). А затем установите параметры:
- BOT_TOKEN — укажите токен бота, его можно получить у @BotFather.
- STORAGE_MODE — выберите memory.
- WORDS__WORDFILE — укажите путь к файлу с набором слов. Он входит в состав репозитория, поэтому отдельно скачивать его не нужно.
Должно получится, как на скриншоте:
После этого запустите созданную конфигурацию. Вы увидите в консоли следующий текст:
INFO:aiogram.dispatcher.dispatcher:Start polling
Если используете не PyCharm, то процесс запуска несколько отличается. Создайте виртуальное окружение bot (python3 -m venv bot) и установите зависимости (pip install -r requirements.txt), а после — запустите бота следующей командой:
BOT_TOKEN=ключ от BotFather STORAGE_MODE=memory WORDS__WORDFILE=/path/to/words.txt python -m bot
Теперь попробуйте отправить в личные сообщения с ботом команду /start. Если в ответ получили текстовое приветствие, бот работает.
При вводе символа / вы должны увидеть список команд. Попробуйте вызвать их и изучить различные конфигурации. По умолчанию поддерживаются следующие пресеты:
- /generate_weak –— два случайных слова без каких-либо дополнительных символов.
- /generate_normal — три случайных слова, каждое из которых случайным образом может состоять из всех прописных или всех строчных букв, в качестве разделителей используются числа.
- /generate_strong — то же, что и в предыдущем случае, но слов четыре, а в качестве разделителей, помимо цифр, возможны спецсимволы.
При нажатии на команду бот сразу отправляет сгенерированный пароль.
Также есть команда /settings — она выводит сообщение с настройками, и /generate — отправляет сгенерированный пароль с учетом новой конфигурации:
Деплой бота на сервер
Все готово, но есть проблема: бот запущен на компьютере. Это неудобно, если хотите обеспечить круглосуточную работу бота. Ведь тогда нужно поддерживать бесперебойную работу компьютера и постоянное соединение с интернетом.
Оптимальное решение — загрузить бота на облачный сервер с гибкой производительностью ядра. Так можно обеспечить стабильную работу и ограничить потребление ресурсов, чтобы не переплачивать.
Для начала зарегистрируемся в панели управления и создадим новый сервер в разделе Облачная платформа. Затем — настроим его.
Боту подойдет ОС Ubuntu 22.04 LTS, 2 виртуальных ядра с минимальной границей в 10% процессорного времени, 2 ГБ оперативной памяти, а также 10 ГБ на сетевом диске (базовый HDD).
С учетом выделенного IP-адреса такая конфигурация выйдет примерно в 28 ₽/день. При желании можно обойтись без маршрутизируемого IP, поскольку Telegram-бот может принимать события методом опроса (поллинга), даже находясь за NAT.
После подключения к серверу по SSH, бота необходимо перенести. Для этого выполните следующие шаги:
1. Откройте консоль сервера и обновите систему с помощью команды:
apt update && apt upgrade -y
2. Создайте отдельного пользователя для нашего бота и добавьте его в группу sudoers:
Дальнейшие действия выполняйте от лица созданного пользователя.
3. Установите Redis и присоедините его к systemd, воспользовавшись удобной инструкцией от DigitalOcean. Шаги 4 и 5 можно пропустить.
4. Клонируйте репозиторий и переключитесь на нужную ветку:
5. Настройте виртуальное окружение:
python3 -m venv venv && source /venv/bin/activate && pip install -r requirements.txt
6. Создайте файл systemd-службы по пути /etc/systemd/system/passgenbot.service со следующим содержимым:
[Unit] Description=Telegram Password Generator Bot Requires=redis.service After=network.target redis.service [Service] Type=simple WorkingDirectory=/home/bot/passgenbot ExecStart=/home/bot/passgenbot/venv/bin/python -m bot User=bot Group=bot EnvironmentFile=/home/bot/passgenbot/.env KillMode=process Restart=always RestartSec=10 [Install] WantedBy=multi-user.target
7. Обратите внимание на директиву EnvironmentFile. Создайте этот файл и поместите туда необходимые переменные окружения:
8. Убедитесь, что Redis запущен (systemctl status redis) и включите бота с добавлением в автозапуск:
sudo systemctl enable passgenbot —now
Программируем кастомные пресеты
Возможности бота можно в любой момент персонализировать под себя. Если пресетов станет недостаточно — добавить новые или изменить существующие. Это сделать достаточно просто.
За генерацию паролей по заданным пресетам отвечает класс XKCD. Под капотом наш бот выглядит так:
# bot/pwdgen.py from random import choice from xkcdpass import xkcd_password class XKCD: # Весь список разделителей, отдельно цифры, отдельно – спецсимволы delimiters_numbers = [«0», «1», «2», «3», «4», «5», «6», «7», «8», «9»] delimiters_full = [«!», «$», «%», «^», «&», «*», «-«, «_», «+», «=», «:», «|», «~», «?», «/», «.», «;»] + delimiters_numbers def __init__(self, filename: str): # Загрузка словаря в память self.wordlist = xkcd_password.generate_wordlist( wordfile=filename, valid_chars=»[a-z]», min_length=4, max_length=10, ) def weak(self): # Слабый пароль: 2 слова без раздетилей return xkcd_password.generate_xkcdpassword( self.wordlist, numwords=2, delimiter=»», ) def normal(self): # Средний пароль: 3 слова, разделитель # в виде случайной цифры return xkcd_password.generate_xkcdpassword( self.wordlist, numwords=3, case=»random», random_delimiters=True, valid_delimiters=self.delimiters_numbers ) def strong(self): # Сильный пароль: 4 слова и большой выбор разделителей return xkcd_password.generate_xkcdpassword( self.wordlist, numwords=4, case=»random», random_delimiters=True, valid_delimiters=self.delimiters_full ) def custom(self, count: int, separators: bool, prefixes: bool): # Произвольный пароль: # сложность зависит от настроек пользователя pwd = xkcd_password.generate_xkcdpassword( self.wordlist, numwords=count, case=»random», delimiter=»», random_delimiters=separators, valid_delimiters=self.delimiters_full ) if prefixes == separators: return pwd elif separators and not prefixes: return pwd[1:-1] elif prefixes and not separators: return f»»
Для добавлении нового пресета достаточно скопировать существующий, изменить его название и настроить параметры метода generate_xkcdpassword под себя.
И последним этапом — добавить в обработчик commands функцию для вызова своего пресета. Это можно сделать по аналогии с существующими пресетами.
# bot/handlers/commands.py from aiogram import types, Dispatcher from aiogram.utils.markdown import hcode from bot.pwdgen import XKCD async def cmd_generate_weak(message: types.Message): # вызов пресета weak pwd: XKCD = message.bot.get(«pwd») await message.answer(hcode(pwd.weak())) async def cmd_generate_normal(message: types.Message): # вызов пресета normal pwd: XKCD = message.bot.get(«pwd») await message.answer(hcode(pwd.normal())) async def cmd_generate_strong(message: types.Message): # вызов пресета strong pwd: XKCD = message.bot.get(«pwd») await message.answer(hcode(pwd.strong())) # вот здесь можно добавить свою функцию для вызова пресета # регистрация команд def register_commands(dp: Dispatcher): # обработчик вызывает пресет weak по команде generate_weak dp.register_message_handler(cmd_generate_weak, commands=»generate_weak») # обработчик вызывает пресет normal по команде generate_normal dp.register_message_handler(cmd_generate_normal, commands=»generate_normal») # обработчик вызывает пресет strong по команде generate_strong dp.register_message_handler(cmd_generate_strong, commands=»generate_strong») # вот здесь можно добавить свою команду
Что можно добавить
Бот работает и выполняет прямые задачи по генерации сложных паролей, но это не предел его возможностей. Программу можно улучшить: добавить, например, новые языки, автоудаление записей по таймеру, генерацию KeePass-совместимых баз данных, создание нескольких паролей одновременно и другое.
Напишите в комментариях, какого еще Telegram-бота можно разработать на Python. И подпишитесь на блог Selectel, чтобы не пропустить обзоры, новости, кейсы и полезные гайды из мира IT.
Читайте также:
- Как запустить динозаврика Google на тачбаре? Пишем игру на Python
- Создаем подругу, записывающую кружочки в Telegram, с помощью 4 нейросетей
- Telegram-бот для поиска подработки, Tinder по интересам и сегментация КТ-снимков: 10 проектов стипендиатов Selectel
Как создать телеграм-бота на Python
Узнайте, как создать своего телеграм-бота на Python с нуля, используя простые шаги в этой понятной статье для новичков.

Алексей Кодов
Автор статьи
23 июня 2023 в 18:47
Создание телеграм-бота на Python — отличный способ погрузиться в мир разработки и научиться работать с API. В этой статье мы рассмотрим, как создать простого телеграм-бота, который будет отвечать на сообщения пользователей.
Шаг 1: Зарегистрировать телеграм-бота
Для начала, вам понадобится создать телеграм-бота и получить его токен. Для этого:
- Откройте приложение Telegram и найдите бота @BotFather.
- Напишите боту /newbot и следуйте инструкциям, чтобы создать своего бота.
- Сохраните полученный токен, он потребуется для работы с API.
Шаг 2: Установить библиотеку python-telegram-bot
Для работы с API телеграма удобно использовать библиотеку python-telegram-bot . Установите ее с помощью следующей команды:
pip install python-telegram-bot
Шаг 3: Написать код для телеграм-бота
Теперь приступим к написанию кода нашего бота. Создайте файл bot.py и напишите следующий код:
import logging from telegram import Update from telegram.ext import Updater, CommandHandler, MessageHandler, Filters, CallbackContext # Введите токен своего бота TOKEN = "your_token_here" # Настройка логирования logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO ) logger = logging.getLogger(__name__) # Обработка команды /start def start(update: Update, context: CallbackContext) -> None: update.message.reply_text('Привет, я твой телеграм-бот! ��') # Обработка текстовых сообщений def echo(update: Update, context: CallbackContext) -> None: update.message.reply_text(f'Вы написали: ') # Главная функция def main() -> None: updater = Updater(TOKEN) dispatcher = updater.dispatcher # Регистрация обработчиков dispatcher.add_handler(CommandHandler("start", start)) dispatcher.add_handler(MessageHandler(Filters.text & ~Filters.command, echo)) # Запуск бота updater.start_polling() updater.idle() if __name__ == '__main__': main()
Не забудьте заменить «your_token_here» на токен вашего бота.