SQL-Ex blog

Оптимизатор запросов SQL Server опирается на статистику для построения адекватного плана запроса. Если статистика неверна, устарела или отсутствует, вы имеете весьма слабую надежду на хорошую производительность ваших запросов. Поэтому важно понимать, как SQL Server поддерживает статистику распределения.
Что такое статистика?
Оптимизатор запросов SQL Server использует статистику распределения, чтобы определиться с тем, как выполнять ваш запрос. Эта статистика представляет собой распределение данных в столбце или столбцах. Оптимизатор запросов использует его для оценки количества строк, которые будут возвращены планом запроса. При отсутствии статистики по распределению данных оптимизатор не будет иметь возможности сравнить эффективность различных планов и, следовательно, зачастую будет вынужден просто выполнять сканирование таблицы или индекса. Без статистики он не сможет узнать, содержит ли столбец искомые данные без его просмотра. При наличии статистики о содержимом столбца у оптимизатора будет значительно больше шансов сделать лучший выбор механизма доступа к данным и использования ваших индексов.
Статистика распределения создается автоматически при создании индекса. Если у вас настроено автоматическое создание статистики (установка по умолчанию параметра базы данных AUTO_CREATE_STATISTICS), вы будете получать созданную статистику при всяком обращении к столбцу в предложениях запроса, выполняющих фильтрацию или задающих критерии соединения JOIN.
Данные измеряются двумя различными способами в пределах единого набора статистики: по плотности и по распределению.
Плотность
Плотность проще понять; она представляет собой отношение, которое просто показывает, сколько уникальных значений содержится в данном столбце или наборе столбцов. Формула проще простого:
Плотность = 1/Число различных значений столбца (столбцов)
Она позволяет вам написать запрос к вашей таблице, чтобы точно увидеть, какой должна быть плотность:
SELECT 1.0 / COUNT(DISTINCT MyColumn)
FROM dbo.MyTable;
Вы также можете увидеть плотность для комбинации столбцов. Для этого в запросе достаточно сначала получить уникальную комбинацию списка столбцов:
SELECT 1.0 / COUNT(*)
FROM (SELECT DISTINCT FirstColumn,
SecondColumn
FROM dbo.MyTable) AS DistinctRows;
И, конечно, вы можете добавить столбцы, по которым построен индекс, чтобы увидеть плотность индекса.
Плотность важна, поскольку она является мерой селективности данного индекса, а также одним из лучших способов оценки эффективности его использования для выполнения запроса. Высокая плотность (низкая селективность, незначительная доля уникальных значений) делает маловероятным использование индекса оптимизатором ввиду его неэффективности для получения ваших данных. Например, если ваш столбец содержит данные типа бит, скажем, подписан клиент на почтовую рассылку или нет, то для миллиона строк вы будете видеть только одно из двух значений. Это означает, что использование индекса или статистики для получения данных из таблицы на основе двух значений сведется к сканированию, в то время как более селективные данные, например, адрес электронной почты, приводит к более эффективному доступу к данным.
Следующая мера — распределение данных — несколько сложнее.
Распределение данных
Распределение данных представляет статистический анализ вида данных, которые находятся в первом столбце, доступном для статистики. Это справедливо также и для составного индекса, т.е. вы получите только единственный столбец данных для их распределения. Это одна из причин рекомендации размещать наиболее селективный столбец первым в индексе. Однако помните, что это только предложение, и существует множество исключений, например, если первый столбец сортирует данные более эффективно при том, что он не самый селективный. Вернемся, однако, к распределению данных. Механизм хранения информации о распределении называется гистограммой. По статистическому определению гистограммой является визуальное представление распределения данных; однако статистика распределения использует более общий математический смысл этого термина.
Гистограмма — это функция, которая подсчитывает число вхождений данных в каждое множество категорий (известных как bins), и в статистике распределения эти категории выбираются так, чтобы представлять распределение данных. Именно эта информация может использоваться оптимизатором для оценки числа строк, возвращаемых заданным значением.
В SQL Server гистограмма содержит до 200 различных шагов, или bin’ов. Почему 200? 1) Это статистически существенно или, как мне говорят, 2) это мало, 3) это работает для большинства распределений данных в объеме до нескольких сотен миллионов строк. При больших объемах вам придется обратиться к материалам, относящимся к фильтрованной статистике, фрагментированным (секционированным) таблицам и другим архитектурным решениям. Эти 200 шагов представлены строками таблицы. Строки представляют способ распределения данных в столбце, показывая части данных, описывающих это распределение:
| RANGE_HI_KEY | Это верхняя граница шага, представленного данной строкой на гистограмме. |
| RANGE_ROWS | Предполагаемое количество строк, значение столбцов которых находится в пределах шага гистограммы, исключая верхнюю границу. |
| EQ_ROWS | Предполагаемое количество строк, значение столбцов которых равно верхней границе шага гистограммы. |
| DISTINCT_RANGE_ROWS | Предполагаемое количество строк с различающимся значением столбца в пределах шага гистограммы, исключая верхнюю границу. Если все строки уникальны, то RANGE_ROWS и DISTINCT_RANGE_ROWS будут равны. |
| AVG_RANGE_ROWS | Среднее количество строк с повторяющимися значениями столбцов в пределах шага гистограммы, исключая верхнюю границу (RANGE_ROWS/DISTINCT_RANGE_ROWS для DISTINCT_RANGE_ROWS > 0). |
Эти значения определяются одним из двух способов, выборкой или полным сканированием. Когда индексы создаются или перестраиваются, вы получаете статистику, созданную полным сканированием по умолчанию. Когда статистика обновляется автоматически, SQL Server использует механизм выборки для построения гистограммы. Подход на базе выборки делает генерацию и обновление статистики очень быстрой, но она может оказаться не вполне точной. Это обусловлено механизмом выборки, который случайным образом читает данные из таблицы, а затем производит вычисления для получения данных статистики. Такой алгоритм оказывается достаточно точным для большинства наборов данных, в противном случае, если вам требуется максимально точная статистика, используйте ручное обновление или создание статистики при помощи полного сканирования.
- Если в таблице нет строк, то, когда вы добавляете строку (или строки), происходит автоматическое обновление статистики.
- Если в таблице менее 500 строк, и вы добавляете более 500. Т.е. если у вас 499 строк, то вы должны добавить строки до 999, чтобы произошло автоматическое обновление.
- Когда в таблице более 500 строк, вы должны добавить дополнительно 500 строк + 20% от размера таблицы, чтобы увидеть автоматическое обновление статистики.
Вы также можете обновлять статистику вручную. Для этого SQL Server предлагает два механизма. Во-первых, sp_updatestats. Эта процедура использует курсор для прохода по всей статистике в указанной базе данных. Она учитывает число модификаций строк, и если были выполнены какие-либо изменения, rowmodctr > 0, то обновляет статистику. Вы можете также обновить отдельную статистику с помощью UPDATE STATISTICS, указав имя. При этом вы можете задать использование FULL SCAN, чтобы гарантировать актуальную статистику, однако потребуется написание кода обслуживания, чтобы сделать это изменение постоянным.
Хватит говорить о том, что такое статистика. Давайте посмотрим на её представление и разберемся с данными, которые в ней содержатся.
DBCC SHOW_STATISTICS
- Заголовок (Header): содержит метаданные о наборе статистики.
- Плотность (Density): показывает значения плотности для столбца или столбцов, которые определяют набор статистики.
- Гистограмма (Histogram): Таблица, которая определяет описанную выше гистограмму.
Информация заголовка может оказаться весьма полезной:

- Updated: когда последний раз обновлялся этот набор статистики. Отсюда вы можете узнать о возрасте набора статистики. Если вы знаете, что в один из дней в таблицу были добавлены тысячи строк, но статистика относится к прошлой неделе, вы можете вручную обновить статистику.
- Rows и Rows Sampled: Если эти значения совпадают, вы видите набор статистики, который является результатом полного сканирования. Если они различаются, то, вероятно, статистика получена на основе выборки.
Второй набор данных представляет собой меры плотности. Вот набор, который показывает плотность составного индекса:
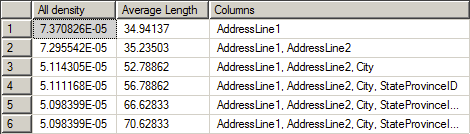
Столбец All density содержит значение плотности, полученное по упомянутой выше формуле. Видно, что это значение уменьшается с каждым следующим столбцом. Ясно, что наиболее селективным является первый столбец. Можно также увидеть среднюю длину (Average Length) значений, которые содержатся в столбце, и, наконец, список столбцов, составляющих каждый уровень плотности.
Наконец, следующий график показывает раздел гистограммы:
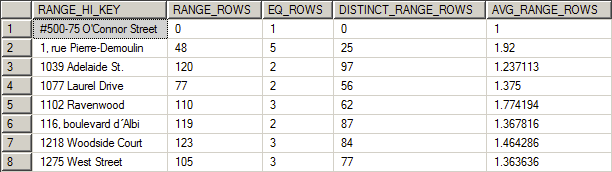
Видно как данные распределены между шагами. При этом вы можете наблюдать, насколько хорошо SQL Server распределяет вашу информацию. Поскольку все количества строк, за исключением среднего, есть целые числа, это еще один фактор, что данный набор статистики представляет собой результат полного сканирования. Если диапазоны строк представляют собой оценку, они будут представлены десятичными числами.
Вы смотрите гистограмму, когда пытаетесь понять, почему план запроса SQL Server содержит scan или seek, в то время когда вы ожидаете увидеть что-то другое. Способ, которым распределяются данные, показывает, например, среднее число строк для заданного значения в пределах некоторого диапазона, что позволяет вам понять, насколько хорошо эти данные могут использоваться оптимизатором. Если вы наблюдаете большое расхождение между строками диапазона или уникальными строками диапазона, то, вероятно, ваша статистика устарела или построена на выборке. Кроме того, если диапазон и уникальные строки сильно расходятся при том, что у вас актуальная и точная статистика, это может говорить о серьезном перекосе данных, которые требуют других подходов к индексированию и построению статистики, например, фильтрованная статистика.
Заключение
Вы можете увидеть множество статистики, поддерживаемой SQL Server. Это жизненно важная часть достижения лучшей производительности системы. Понимание того, как она работает, создается, поддерживается и как её анализировать, поможет вам в работе с собственной статистикой.
WTFM.INFO
Write The F* Manual — Заметки о сетях, администрировании и вообще
MS SQL Статистика использования индексов
Скрипт для просмотра статистики использования индексов:
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME], I.[NAME] AS [INDEX NAME], USER_SEEKS, USER_SCANS, USER_LOOKUPS, USER_UPDATES FROM SYS.DM_DB_INDEX_USAGE_STATS AS S INNER JOIN SYS.INDEXES AS I ON I.[OBJECT_ID] = S.[OBJECT_ID] AND I.INDEX_ID = S.INDEX_IDСтатистика считается с момента последнего запуска SQL-сервера.
Добавить комментарий Отменить ответ
Мета
Найти на сайте
TOP 5
- Barman сжатие WAL (108 799)
- Как получить chat id из канала telegram (19 401)
- PostgreSQL посмотреть права пользователя на таблицы (14 776)
- PostgreSQL выдача прав пользователю с учетом создаваемых в будущем объектов (11 553)
- PostgreSQL посмотреть текущие запросы к базам (10 864)
Рубрики
- DevOps (5)
- English (2)
- Python (2)
- Автоматизация (1)
- Ansible (1)
- Elasticsearch (5)
- Zabbix (4)
- Администрирование Linux (35)
- Администрирование Windows (19)
- Mikrotik (1)
Свежие записи
- Linux выполнить команду каждые 10 секунд, записать результат
- Работа с Mikrotik в Ansible
- Netbox — search for duplicate IP addresses. Python script.
- Netbox — поиск дубликатов IP адресов. Python скрипт.
- Простой мониторинг или NetWatch для FreeBSD/Linux (bash), уведомления в Telegram
Свежие комментарии
- Антон к записи Kubernetes. Taints and Tolerations. Запуск подов на мастере.
- xinferum к записи pgsentinel настройка (хранение истории активных сессий PostgreSQL)
- Sergey Shumeev к записи pgsentinel настройка (хранение истории активных сессий PostgreSQL)
- Антон к записи iSpy — уведомления в Telegram при обнаружении движения
- Аноним к записи Удаление checkpoint(snapshot) VM без опции «Удалить» через PowerShell
© WTFM.INFO (ex. shiningapples.net) 2017 — 2023
Все статьи, представленные на сайте, являются авторскими, если не указан источник. При цитировании материалов сайта, пожалуйста, указывайте ссылку на оригинальную статью. По всем вопросам обращайтесь на admin@wtfm.info
Ссылки Hostiman - наш хостинг BearScience - полезный it (и не только) блог
Обновление статистики базы данных
MS SQL Server строит план запроса на основании статистической информации о распределении значений в индексах и таблицах. Статистическая информация собирается на основании части (образца) данных и автоматически обновляется при изменении этих данных. Иногда этого оказывается недостаточно для того, что MS SQL Server стабильно строил наиболее оптимальный план выполнения всех запросов.
В этом случае возможно проявление проблем с производительностью запросов. При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальные операции).Для того, чтобы гарантировать максимально правильную работу оптимизатора MS SQL Server рекомендуется регулярно обновлять статистики базы данных MS SQL.
Для обновления статистик по всем таблицам базы данных необходимо выполнить следующий SQL запрос:
exec sp_msforeachtable N’UPDATE STATISTICS ? WITH FULLSCAN’
Обновление статистик не приводит к блокировке таблиц, и не будет мешать работе других пользователей. Статистика может обновляться настолько часто, насколько это необходимо. Следует учитывать, что нагрузка на сервер СУБД во время обновления статистик возрастет, что может негативно сказаться на общей производительности системы.Оптимальная частота обновления статистик зависит от величины и характера нагрузки на систему и определяется экспериментальным путем. Рекомендуется обновлять статистики не реже одного раза в день.
Приведенный выше запрос обновляет статистики для всех таблиц базы данных. В реально работающей системе разные таблицы требуют различной частоты обновления статистик.
Поэтому в общем случае, путем анализа планов запроса можно установить, какие таблицы больше других нуждаются в частом обновлении статистик, и настроить две (или более) различных регламентных процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит существенно снизить время обновления статистик и влияние процесса обновления статистики на работу системы в целом.
В Вашем случае, имеет смысл настроить хотя бы ежедневное обновление статистик.
Например, в период минимальной нагрузки на систему — в ночные часы.
Можно сделать, например, так: В MS SQL:
1) Создайте новый план обслуживания
2) Создайте субплан (Add Subplan) и назовите его «Обновление статистик».

3) Добавьте в него задачу Update Statistics Task из панели задач:
4) Настройте расписание обновления статистик (рекомендация не реже 1 раза в день).
5) Настройте саму задачу:
5.1) Базу данных для который выполняется обновление статистики
5.2) Список таблиц установите «All» — это означает что будет обновлена статистика по всем таблицам БД
5.3) Укажите опцию Full scan

(Примечание. Такой режим будет эквивалентен скрипту
exec sp_msforeachtable N'UPDATE STATISTICS ? WITH FULLSCAN' DBCC UPDATEUSAGE (dbname)
где dname имя вашей базы)
Также после обновлении статистики имеет смысл очистить процедурный кэш (иначе запросы будут выполнятся по планам из кэш, которые могли быть сформированы на основании устаревшей статистики.
Поэтому в субплан:
6) Добавьте задачу Execute T-SQL Statement Task.

7) Соедините задачу Update Statistics Task стрелочкой с новой задачей
8) В тексте созданной задачи Execute T-SQL Statement Task следует указать запрос «DBCC FREEPROCCACHE»
9) если у вас значительная нагрузка на базу в пиковые моменты (сотни пользователей, роботы-фоновики и т.п.) то наряду с параметром «Автоматическое создание статистики (AUTO_CREATE_STATISTICS)» будет полезно также для базы данных включить параметр «Автоматическое асинхронное обновление статистики (AUTO_UPDATE_STATISTICS_ASYNC)»
Важно знать:
Если включен параметр AUTO_UPDATE_STATISTICS (автоматическое обновление статистики), оптимизатор запросов определяет, устарела ли статистика, и при необходимости обновляет ее, если она используется в запросе. Статистика становится устаревшей, после того как операции вставки, обновления, удаления или слияния изменяют распределение данных в таблице или индексированном представлении. Оптимизатор запросов определяет, устарела ли статистика, подсчитывая операции изменения данных с момента последнего обновления статистики и сравнивая число изменений с пороговым значением. Пороговое значение основано на количестве строк в таблице или индексированном представлении.Если используется версия до SQL Server 2014 (12.x), SQL Server применяет пороговое значение в зависимости от процента измененных строк. Это значение не зависит от числа строк в таблице. Пороговое значение:
Если на момент оценки статистических данных кратность в таблице не превышала 500, обновление выполняется для каждых 500 модификаций.
Если на момент оценки статистических данных кратность в таблице превышала 500, обновление выполняется для каждых 500 + 20 % модификаций
Начиная с версии SQL Server 2016 (13.x) и при уровне совместимости базы данных 130 SQL Server используется пороговое значение для динамического обновления статистических данных по убыванию. Значение изменяется в зависимости от числа строк в таблице. Оно вычисляется как квадратный корень из произведения текущего значения кратности в таблице и 1000. Например, если таблица содержит 2 миллиона строк, значение вычисляется как квадратный корень из (1000 * 2000000) = 44721,359. Благодаря этому изменению статистика для больших таблиц будет обновляться чаще. Но если уровень совместимости для базы данных ниже 130, применяется пороговое значение SQL Server 2014 (12.x).
Оптимизатор запросов проверяет наличие устаревшей статистики перед компиляцией запроса и до выполнения кэшированного плана запроса.
Параметр AUTO_UPDATE_STATISTICS_ASYNC (асинхронное обновление статистики) определяет, какой режим обновления статистики использует оптимизатор запросов: синхронный или асинхронный. По умолчанию параметр асинхронного обновления статистики отключен, и оптимизатор запросов обновляет статистику синхронно.
При синхронном обновлении статистики запросы всегда компилируются и выполняются с актуальной статистикой. Если статистика оказывается устаревшей, оптимизатор запросов ожидает появления обновленной статистики, прежде чем начать компиляцию и выполнение запроса. При асинхронном обновлении статистики запросы компилируются с существующей статистикой, даже если она устарела. Если на момент компиляции запроса статистика оказывается устаревшей, оптимизатор запросов может выбрать неоптимальный план запроса. Запросы, которые компилируются после выполнения асинхронного обновления, будут усовершенствованы благодаря использованию обновленной статистики.Асинхронная статистика рекомендуется для достижения более прогнозируемого времени ответа на запросы в следующих сценариях.
Приложение часто выполняет один и тот же запрос, схожие запросы или схожие кэшированные планы запроса. Асинхронное обновление статистики может обеспечить более прогнозируемое время ответа на запрос по сравнению с синхронным, так как оптимизатор запросов может выполнять входящие запросы, не ожидая появления актуальной статистики. Это устраняет задержку в некоторых запросах, но не влияет на другие запросы.
Были случаи, когда в приложении истекало время ожидания клиентских запросов в результате ожидания обновленной статистики. В некоторых случаях ожидание синхронной статистики может вызвать аварийное завершение приложений, в которых задано малое время ожидания.Продажи slava@gilev.ru gilev_slava @uskorim1c Платежи, документы andrey@gilev.ru andrey.gilev @andrey_gilev Техническая поддержка support@gilev.ru nukewin Почему для SQL Server важна статистика
За годы работы с SQL Server я обнаружила, что есть несколько тем, которые часто игнорируются. Их что боятся, думают, что они сложные или что они не такие важные. Также есть мнение, что эти знания не нужны, так как SQL Server «все делает за меня». Я слышала это об индексах. Я слышала это о статистике.

Итак, давайте поговорим, почему статистика важна и почему знание о том, что она важна, поможет вам существенно повлиять на производительность ваших запросов.
Есть несколько случаев, когда статистика обрабатывается автоматически:
- SQL Server автоматически создает статистику для индексов
- SQL Server автоматически создает статистику для столбцов, когда ему требуется больше информации для оптимизации запроса
- ВАЖНО! Это происходит только тогда, когда включен параметр базы данных auto_create_statistics. Этот параметр включен по умолчанию во всех версиях и редакциях SQL Server. Однако иногда встречаются рекомендации его выключить. Я категорически против этого.
- ВАЖНО! Это происходит только тогда, когда включен параметр базы данных auto_update_statistics. Этот параметр включен по умолчанию во всех версиях и редакциях SQL Server. Иногда также встречаются рекомендации его выключить. Обычно я против этого. Узнать больше об автоматическом обновлении вы можете в статье (англ.) Updating SQL Server Statistics Part I – Automatic Updates, а про ручное обновление статистики (но с помощью более избирательного подхода) в статье Updating SQL Server Statistics Part II – Scheduled Updates.
Однако, важно знать, что, хотя статистика обрабатывается автоматически, этот процесс не всегда работает так хорошо как вы ожидаете. Для действительно эффективной оптимизации SQL Server’у нужны определенные шаблоны и наборы данных. Для понимания этого, я хочу немного поговорить о доступе к данным и о процессе оптимизации.
Доступ к данным
Обычно, когда вы отправляете запрос к SQL Server для получения данных, вы пишете код на Transact-SQL в виде простого SELECT или, возможно, в виде хранимой процедуры (да, есть и другие варианты). Однако главное в том, что вы говорите какой набор данных вы хотите получить, а не описываете то, как эти данные должны быть извлечены. Как же SQL Server “доберется“ до данных?
Обработка данных
В получении и обработке данных SQL Server’у помогает статистика. Статистика предоставляет информацию о том, какой объем данных нужно будет обработать при выполнении запроса. Если нужно будет обработать небольшой объем данных, то обработка может быть проще (возможно, другим способом), чем если бы запрос обрабатывал миллионы строк.
В частности, SQL Server использует оптимизатор запросов на основе стоимости (cost based). Существуют и другие варианты оптимизации, но сегодня, чаще всего, используются оптимизаторы, основанные на стоимости. Почему? Оптимизаторы, основанные на стоимости, используют информацию о запрашиваемых данных, чтобы сформировать более эффективные, оптимальные и целенаправленные планы, с учетом информации об этих данных. Как правило, этот процесс работает хорошо. Хотя с планами, которые сохраняются для последующих выполнений (кэшированные планы), могут быть проблемы. Тем не менее, в других способах оптимизации есть еще более серьезные недостатки.
ВАЖНО! Я здесь не говорю о кеше планов… Я говорю о начальном процессе оптимизации и о том, как SQL Server определяет, какой объем данных ему надо будет получить. Последующее выполнение кэшированного плана может привести к дополнительным проблемам с ним (известными как parameter sniffing). Об этом много написано в других статьях.
Чтобы объяснить оптимизацию на основе стоимости, позвольте мне рассказать о других видах оптимизации. Это поможет понять преимущества стоимостной оптимизации.
Оптимизация на уровне синтаксиса
SQL Server может обработать запрос, используя только его текст и не тратить время на поиск наилучшего порядка обработки таблиц. Оптимизатор может просто соединить (join) ваши таблицы в том порядке, в котором вы их указали во FROM. Хотя для того чтобы начать выполнять запрос не требуется никаких затрат, но выполнение самого запроса может быть далеко не оптимальным. В общем случае, соединение больших таблиц с маленькими менее оптимально, чем соединение маленьких таблиц с большими. Давайте посмотрим на эти два примера:
USE [WideWorldImporters]; GO SET STATISTICS IO ON; GO SELECT [so].*, [li].* FROM [sales].[Orders] AS [so] JOIN [sales].[OrderLines] AS [li] ON [so].[OrderID] = [li].[OrderID] WHERE [so].[CustomerID] = 832 AND [so].[SalespersonPersonID] = 2 OPTION (FORCE ORDER); GO SELECT [so].*, [li].* FROM [sales].[OrderLines] AS [li] JOIN [sales].[Orders] AS [so] ON [so].[OrderID] = [li].[OrderID] WHERE [so].[CustomerID] = 832 AND [so].[SalespersonPersonID] = 2 OPTION (FORCE ORDER); GO
Сравните стоимости планов. Второй запрос значительно дороже.
Стоимость одинаковых запросов с FORCE ORDER с разным порядком соединения.
Да, это чрезмерное упрощение способов оптимизации соединения, но дело в том, что вы вряд ли укажете самостоятельно оптимальный порядок таблиц во FROM. Хорошая новость в том, что если у вас есть проблемы с производительностью, то вы можете применить такие оптимизации, как соединение таблиц в указанном порядке (см. пример выше). Есть много других хинтов (hint), которые вы можете использовать:
- QUERY Hints (принудительное использование уровня параллелизма [MAXDOP], оптимизация запроса для быстрого получения первых строк, а не всего набора данных с помощью FAST n и т.д.)
- TABLE Hints (принудительное использование индекса [INDEX], поиска в индексе [FORCESEEK] и т.д.)
- JOIN Hints (принудительное использование типа соединения LOOP / MERGE / HASH)
Надо сказать, что использование хинтов всегда должно быть последним способом оптимизации. Следует попробовать другие способы оптимизации, прежде чем использовать хинты. Применяя их, вы не позволяете SQL Server оптимизировать ваши запросы при добавлении или изменении индексов, при добавлении или изменении статистики и при обновлении SQL Server. Конечно, если только вы не задокументировали используемые хинты и не протестировали их, чтобы убедиться, что они останутся полезными для вашего запроса после выполнения заданий по обслуживанию БД, модификации данных и обновлений SQL Server. Честно говоря, я не вижу, чтобы это делалось так часто, как хотелось бы. Большинство хинтов добавляются так, как будто они всегда будут работать отлично, и остаются в запросе до тех пор, пока не возникнут серьезные проблемы.
Всегда важно посмотреть, на другие способы улучшения производительности, прежде чем применять хинты. Да, легко поставить хинт сейчас, но время, которое вы потратите на поиск других решений, может окупиться сполна в долгосрочной перспективе.
Для проблем с конкретным запросом с его конкретными значениями стоит посмотреть:
- Является ли статистика точной/актуальной? Исправит ли обновление статистики проблему?
- Статистика основана на частичной выборке? Исправит ли FULLSCAN проблему?
- Можете ли вы переписать запрос и улучшить план?
- Есть ли плохие условия поиска? Столбцы всегда должны находиться с одной стороны выражения:
- Так хорошо: MonthlySalary > expression / 12
- Так плохо: MonthlySalary * 12 > expression
FROM table2 AS t1
JOIN table2 AS t2 ON t1.colX = t2.colX
WHERE t1.colX = 12 AND t2.colX = 12- Иногда простой переход от соединения к подзапросу или от подзапроса к соединению исправляет проблему (нет, одно не всегда лучше другого, но иногда переписывание может помочь оптимизатору).
- Иногда использование производных (derived) таблиц (подзапросов в FROM (. ) AS J1) может помочь оптимизатору более оптимально соединить таблицы.
- Есть ли у вас условия OR? Можете ли вы переписать их через UNION или UNION ALL для получения такого же результата (это самое главное) с лучшим планом выполнения? Будьте осторожны, семантически это разные запросы. Вам нужно хорошо понимать различие между всеми ими.
- OR удаляет дубликаты строк (на основе ID строки)
- UNION удаляет дубликаты на основе столбцов, указанных в SELECT
- UNION ALL объединяет множества (что может быть намного быстрее, чем удаление дубликатов), но это может быть (а может и не быть) проблемой:
- иногда дубликатов нет (вы должны знать свои данные)
- иногда допустимо вернуть дубликаты (вы должны знать ваших пользователей / аудиторию / приложение)
Это совсем небольшой список, но он может помочь вам повысить производительность без использования хинтов. Это значит, что при последующих изменениях в данных, индексах, статистике, в версии SQL Server, оптимизатор сможет учитывать эти изменения!
Но все-таки здорово, что хинты есть, и если мы действительно нуждаемся в них, то можем ими воспользоваться. Бывают ситуации, когда оптимизатор может не быть в состоянии придумать эффективный план. Для этих случаев можно воспользоваться хинтами. Так что да, мне нравится, что они есть. Я просто не хочу, чтобы вы использовали их, пока не определите, истинную причину проблемы.
Так что, да, вы можете добиться оптимизации на уровне синтаксиса… если вам это нужно.
Оптимизация с использованием правил (эвристика)
Я упоминала, что оптимизация на основе стоимости требует статистики. Но что, если у вас нет статистики?
На это также можно посмотреть с другой стороны — почему SQL Server не может просто использовать «набор правил» для быстрой оптимизации запросов без необходимости просматривать/анализировать информацию о ваших данных? Разве это не было бы быстрее? SQL Server может делать так, но часто это бывает не самое лучшее решение. Для демонстрации этого надо запретить SQL Server при обработке запроса использовать статистику. Я могу показать пример, когда это действительно работает хорошо, и гораздо больше примеров, когда работает плохо.
Эвристика — это правила. Простые, статичные, фиксированные правила. Тот факт, что они простые, является их преимуществом. Не нужно смотреть на данные. Делается простая и быстрая оценка запроса на основе предикатов. Например, “меньше” и “больше” имеют внутреннее правило “30%”. Проще говоря, когда вы запускаете запрос с предикатом “больше” или “меньше” и нет информации о данных (статистики), SQL Server будет использовать правило, которое говорит, что условию будут соответствовать 30% данных. Оптимизатор будет использовать это в своих оценках и придумает план, соответствующий этому правилу.
Чтобы это «заработало», нужно сначала отключить auto_create_statistics и проверить существующие индексы и статистику:USE [WideWorldImporters]; GO ALTER DATABASE [WideWorldImporters] SET AUTO_CREATE_STATISTICS OFF; GO EXEC sp_helpindex '[sales].[Customers]'; EXEC sp_helpstats '[sales].[Customers]', 'all'; GOПосмотрите sp_helpindex и sp_helpstats . В базе данных WideWorldImporters в таблице Customers на столбце DeliveryPostalCode по умолчанию нет индексов и статистики. Если вы добавили что-то самостоятельно (или SQL Server создал автоматически), то следует их удалить перед выполнением следующих примеров.
Для первого запроса мы поставим ZipCode , равный 90248 и используем предикат “меньше”. Посмотрим как SQL Server оценит количество строк без использования статистики и возможности ее автоматического создания.

SELECT [c1].[CustomerID], [c1].[CustomerName], [c1].[PostalCityID], [c1].[DeliveryPostalCode] FROM [sales].[Customers] AS [c1] WHERE [c1].[DeliveryPostalCode] < '90248';Столбцы без статистики будут использовать эвристику.
Если не найти «идеальное» значение, то большую часть времени эти правила будут неправильными!
Для первого запроса оценка работает хорошо (30% от 663 = 198,9), так как фактическое количество строк для запроса составляет 197. Один важный момент, на который стоит обратить внимание — это предупреждение рядом с таблицей Customers и около самого левого оператора SELECT. Оно говорит нам о том, что здесь что-то не так. Хотя, оценка количества строк «правильная».
Для второго запроса мы возьмем значение ZipCode равное 90003. Запрос точно такой же, за исключением значения ZipCode. Как сейчас SQL Server оценит количество строк?
SELECT [c1].[CustomerID], [c1].[CustomerName], [c1].[PostalCityID], [c1].[DeliveryPostalCode] FROM [sales].[Customers] AS [c1] WHERE [c1].[DeliveryPostalCode] < '90003';
Столбцы без статистики используют эвристику (простые правила). Часто они сильно ошибаются!
Для второго запроса оценка также равна 198,9, а фактически строк только 1. Почему? Потому что без статистики эвристика для “меньше” (и “больше”) составляет 30%. Тридцать процентов от 663 — это 198,9. Конкретное значение меняется при модификации данных, но процент остается постоянным 30%.Если этот запрос будет более сложным (с соединениями и/или дополнительными предикатами), то наличие некорректной информации — это уже проблема для последующих шагов оптимизации. Да, время от времени вам может везти с эвристиками, но это маловероятно. Более того эвристика для BETWEEN и “равно” отличается от значений для “меньше” и “больше” (равной равна 30%). На самом деле, некоторые из них даже меняются в зависимости от используемой вами модели оценки кардинальности (например, для “равно”). А меня, вообще, это должно беспокоить? На самом деле, нет! В действительности я никогда не хочу их использовать.
Итак, SQL Server может использовать оптимизацию на основе правил… но только тогда, когда у него нет лучшей информации.
Я не хочу эвристику! Я хочу статистику!
Статистика — это одно из немногих мест в SQL Server, которой не может быть мало. Нет, я не говорю о том, чтобы создавать статистику для каждого столбца таблицы, но есть некоторые случаи, когда можно предварительно создать статистику. Но это тема для отдельной статьи.
Итак, почему статистика так важна для стоимостной оптимизации?Оптимизация на основе стоимости
Что же на самом деле делает оптимизация на основе стоимости? Если кратко, то SQL Server быстро получает приблизительную оценку того, сколько данных будет обработано. Затем, используя эту информацию, он оценивает стоимость различных алгоритмов, которые могут быть использованы для доступа к данным. После этого, основываясь на “стоимости” этих алгоритмов, SQL Server выбирает тот, который, по его расчетам, является наименее дороги. Затем он его компилирует и выполняет.
Это звучит здорово, но есть много факторов, когда это может работать не так хорошо, как хотелось бы. Самое главное, что базовая информация, используемая для выполнения оценки (статистика), может быть некорректной:
- Статистика может быть устаревшей
- Статистика может быть не точной из-за ограниченной выборки
- Статистика может быть не точной из-за размера таблицы и ограничений того, что храниться в ней.
Некоторые спросят меня — может ли SQL Server иметь более подробную статистику (более подробные гистограммы и т.п.)? Да, может. Но тогда процесс чтения / доступа к этой, все большей и большей, статистике будет становиться все дороже (и занимать больше времени, больше кеша и т. д.). Что, в свою очередь, сделает процесс оптимизации более дорогим. Это сложная проблема. Везде есть плюсы и минусы, компромиссы. На самом деле, все не так просто, как “подробные гистограммы”.
Наконец, в процессе оптимизации нельзя проанализировать все возможные комбинации планов. Это сделало бы сам процесс оптимизации настолько дорогим, что это было бы непозволительно!
Итог
Лучший способ думать о процессе оптимизации — это как найти “хороший план быстро”. Иначе процесс оптимизации стал бы настолько сложным и затянулся бы настолько, что не достиг бы своей цели!
Итак, почему статистика очень важна:
- Она используется на всем протяжении процесса стоимостной оптимизации (а вы хотите оптимизацию на основе стоимости)
- Она должна присутствовать, иначе вы будете вынуждены использовать эвристику
- как правило, я настоятельно рекомендую включить параметр auto_create_statistics, если вы его выключили
СТАТИСТИКА — КЛЮЧ К ЛУЧШЕЙ ОПТИМИЗАЦИИ И, СЛЕДОВАТЕЛЬНО, ЛУЧШЕЙ ПРОИЗВОДИТЕЛЬНОСТИ (но это все еще пока далеко от идеала!)
Я надеюсь, что эта статья мотивирует вас изучить больше о статистике. Статистика в SQL Server на самом деле проще, чем вы думаете и, очевидно, она очень, очень важна!
Довольно старая, но все еще полезная статья — Statistics Used by the Query Optimizer in Microsoft SQL Server 2008
- Есть ли плохие условия поиска? Столбцы всегда должны находиться с одной стороны выражения: