Класс DriverManager
Класс DriverManager является уровнем управления JDBC, отслеживает все доступные драйверы и управляет установлением соединений между БД и соответствующим драйвером.
Прежде чем подключаться к серверу БД необходимо определиться с соответствующим драйвером JDBC, который представляет собой *.jar файл. В следующей таблице представлен список jdbc.drivers для нескольких СУБД.
| СУБД | Драйвер JDBC | Сайт производителя |
|---|---|---|
| Oracle | oracle.jdbc.OracleDriver | http://www.oracle.com/technetwork/database/jdbc-112010-090769.html |
| MSSQL | com.microsoft.jdbc.sqlserver.SQLServerDriver | http://www.microsoft.com/en-us/download |
| PostgreSQL | org.postgresql.Driver | https://jdbc.postgresql.org/download.html |
| MySQL | com.mysql.jdbc.Driver | http://dev.mysql.com/downloads/connector/j/ |
| Derby | org.apache.derby.jdbc.ClientDriver | http://db.apache.org/derby/derby_downloads.html |
Примечание :
1. Драйверы лучше всего скачивать с сайта производителей СУБД.
2. Необходимо учитывать особенности использования подключения к серверу СУБД. Например, если использовать БД Derby в монопольном режиме, т.е. как хранилище, то лучше подключать драйвер org.apache.derby.jdbc.EmbeddedDriver.
Для подключения драйвера лучше всего разместить его в одной из поддиректорией приложения и прописать в classpath. При использовании IDE для разработки приложения подключение драйвера JDBC можно выполнить через интерфейс среды разработки.
Загрузка драйвера JDBC
DriverManager.registerDriver
Чтобы сказать диспетчеру драйверов JDBC, какой именно драйвер следует загрузить, необходимо выполнить одну из команд :
- Class.forName(“полное имя класса”)
- Class.forName(“полное имя класса”).newInstance()
- DriverManager.registerDriver(new “полное имя класса”)
Команды все равнозначны. Задача заключается в том, чтобы classloader загрузил нужный драйвер. Например :
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
Загрузка драйвера JDBC может производиться и другим способом. При вызове Java машины (JVM) можно указать в значении специального системного свойства jdbc.drivers название класса JDBC драйвера:
java -Djdbc.drivers=sun.jdbc.odbc.JdbcOdbcDriver myClass
В этом случае при первой попытке установления соединения с базой данных менеджер драйверов автоматически сам загрузит класс указанный в системном свойстве jdbc.drivers.
Выбирайте любой способ, ориентируясь на то, нужно ли вам будет в дальнейшем переходить на другую СУБД. Если да, то, второй способ будет предпочтительнее. Особенно для тех, кто пишет программы для широкой публики. А ей свойственно желать самолй выбирать, чем пользоваться.
Примечание : если при выполнении программы вы получаете ошибку No driver available — это, скорее всего, означает, что вы просто неправильно указалт путь к драйверу в переменной CLASSPATH.
Классы драйверов JDBC разрабатываются со статической секцией инициализации, в которой экземпляр определенного класса создается и регистрируется в классе DriverManager при загрузке. Таким образом, приложение может не вызывать DriverManager.registerDriver непосредственно. Этот вызов автоматически делается самим драйвером при загрузке класса драйвера.
Для обеспечения безопасности управления драйвером JDBC DriverManager отслеживает, каким загрузчиком классов ClassLoader загружен драйвер. При открытии соединения с сервером БД используется только драйвер, поступивший либо из локальной файловой системы, либо загруженные тем же ClassLoader’ом, которым загружено приложение, запросившее соединение с БД.
Соединение с сервером БД
DriverManager.getConnection
Устанавливать соединения с БД можно сразу после регистрации драйвера JDBC. Для этого следует вызвать метод DriverManager.getConnection, которому передаются параметры соединения с БД. DriverManager опрашивает каждый зарегистрированный драйвер с целью определения, какой из них может установить данное соединение. Может оказаться, что установить соединение согласно параметрам URL могут более одного драйвера JDBC. В этом случае важен порядок, в котором происходит этот опрос, так как DriverManager будет использовать первый драйвер, откликнувшийся на URL.
Мост JDBC-ODBC-Bridge
Получить доступ к серверу базы данных можно с использованием моста JDBC — ODBC. Программа взаимодействия между драйвером JDBC и ODBC была разработана фирмой JavaSoft в сотрудничестве с InterSolv. Данная «связка» реализована в виде класса JdbcOdbc.class (для платформы Windows JdbcOdbc.dll).
При использовании JDBC — ODBC необходимо принимать во внимание, что помимо JdbcOdbc-библиотек должны существовать специальные драйвера (библиотеки), которые реализуют непосредственный доступ к базам данных через стандартный интерфейс ODBC. Как правило эти библиотеки описываются в файле ODBC.INI.
На внутреннем уровне JDBC-ODBC-Bridge преобразует методы Java в вызовы ODBC и тем самым позволяет использовать любые существующие драйверы ODBC, которых к настоящему времени накоплено в изобилии. Однако, чаще всего, все-таки используется механизм ODBC благодаря его универсальности и доступности.
Особенности использования JDBC-ODBC
JDBC DriverManager является «хребтом» JDBC-архитектуры, и его основная функция очень проста — соединить Java-программу и соответствующий JDBC драйвер и затем «выйти из игры». Структура драйвера ODBC была взята в качестве основы JDBC из-за его популярности среди независимых поставщиков программного обеспечения и пользователей. Но может возникнуть законный вопрос — а зачем вообще нужен JDBC? не легче ли было организовать интерфейсный доступ к ODBC-драйверам непосредственно из Java? Путь через JDBC-ODBC-Bridge, как ни странно, может оказаться гораздо короче. С чем это связано:
- ODBC основан на C-интерфейсе и его нельзя использовать непосредственно из Java. Вызов из Java C-кода нарушает целостную концепцию Java и пробивает брешь в защите.
- Так как Java не имеет указателей, а ODBC их использует, то перенос ODBC C-API в Java-API нежелателен.
- Java-API необходим, чтобы добиться абсолютно чистых Java решений. Когда ODBC используется, то ODBC-драйвер и ODBC менеджер должны быть инсталлированы на каждой клиентской машине. В то же время, JDBC драйвер написан полностью на Java и может быть легко переносим на любые платформы.
Следующий код демонстрирует соединение с сервером БД с использованием моста jdbc-odbc-bridge :
import java.net.URL; import java.sql.*; import java.io.*; class SimpleSelect < public static void main (String args[]) < String url = "jdbc:odbc:dBase"; String query = "SELECT * FROM users"; try < // Загрузка jdbc-odbc-bridge драйвера Class.forName ("sun.jdbc.odbc.JdbcOdbcDriver"); DriverManager.setLogStream(System.out); // Попытка соединения с драйвером. Каждый из // зарегистрированных драйверов будет загружаться, пока // не будет найден тот, который сможет обработать этот URL Connection con = DriverManager.getConnection (url, "username", "password"); // Если соединиться не удалось, то произойдет exception (исключительная ситуация). // Получить DatabaseMetaData объект и показать информацию о соединении DatabaseMetaData dma = con.getMetaData (); // Печать сообщения об успешном соединении System.out.println("\nConnected to " + dma.getURL()); System.out.println("Driver " + dma.getDriverName()); System.out.println("Version " + dma.getDriverVersion()); // Закрыть соединение con.close(); >catch (SQLException e) < System.out.println ("\n*** SQLException caught ***\n"); while (e != null) < System.out.println ("SQLState: " + e.getSQLState ()); System.out.println ("Message: " + e.getMessage ()); System.out.println ("Vendor: " + e.getErrorCode ()); e = e.getNextException (); >> catch (java.lang.Exception ex) < e.printStackTrace (); >>
В случае применения моста jdbc-odbc-bridge в URL-строку подставляется DSN (Data Source Name), т.е. имя ODBC-источника из ODBC.INI файла.
Пример динамической загрузки JDBC-драйвера рассмотрен здесь.
JDBC
JDBC — это платформенно независимый промышленный стандарт взаимодействия Java-приложений с реляционными базами данных. Впервые был включен в состав JDK 1.1 в 1997 году. JDBC управляет:

Освойте профессию «Java-разработчик»
- подключением к базе данных;
- выдачей запросов и команд;
- обработкой данных, полученных из базы.
Как работает JDBC
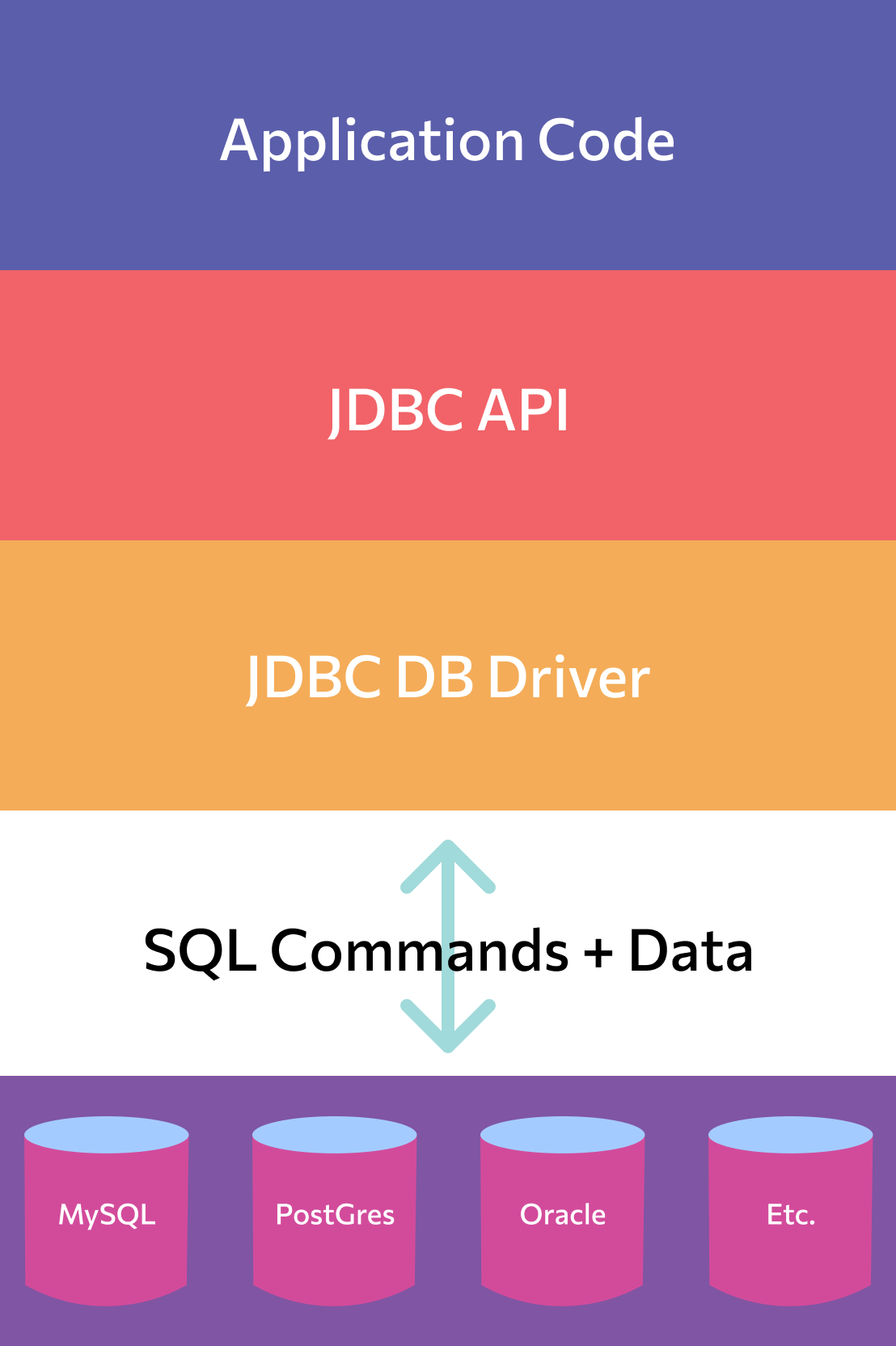
Пакет JDBC состоит из двух главных компонентов:
- API (программного интерфейса), который поддерживает связь между Java-приложением и менеджером JDBC;
- Драйвера JDBC, который поддерживает связь между менеджером JDBC и драйвером базы данных.
Профессия / 14 месяцев
Java-разработчик
Освойте востребованный язык

Соединение с базой устанавливается по особому URL. При этом разработчику не нужно знать специфику конкретной базы — API выступает в качестве посредника между базой и приложением. Это упрощает как процесс создания приложения, так и переход на базу данных другого типа.
Этапы подключения к базе данных
- Установка базы данных на сервер или выбор облачного сервиса, к которому нужно получить доступ.
- Подключение библиотеки JDBC.
- Проверка факта нахождения необходимого драйвера JDBC в classpath.
- Установление соединения с базой данных с помощью библиотеки JDBC.
- Использование установленного соединения для выполнения команд SQL.
- Закрытие соединения после окончания сеанса.
Рассмотрим каждый из этих шагов подробнее.
Установка SQLite
СУБД (система управления базами данных) SQLite отличается компактными размерами и простотой установки — для ее использования не нужна инсталляция дополнительных сервисов. Вся информация хранится в одном файле формата .db, который нужно поместить в папку с программой. Учебную базу можно скачать здесь.

Станьте Java-разработчиком
и создавайте сложные сервисы
на востребованном языке
Импорт JDBC в Java-приложение
Для использования JDBC, как и в случае со всеми остальными приложениями на платформе Java, в системе должен быть установлен JDK. Код для работы с JDBC можно писать как в среде разработки (IDE), так и в обычном текстовом редакторе. Простейшая программа может выглядеть так:
class WhatIsJdbcpublic static void main(String args[])System.out.println(«Hello World»);
>
>
Скомпилируйте этот код с помощью команды:
javac WhatIsJdbc.java
Теперь, когда программа готова, можно импортировать библиотеки JDBC. Для этого вставьте данный ниже код перед строками программы «Hello, World»:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.ResultSet;
import java.sql.Statement;
Каждый из импортированных модулей предоставляет доступ к классам, которые необходимы для взаимодействия Java-приложения с базой данных:
- Connection подготавливает подключение к базе.
- DriverManager обеспечивает подключение. Другая опция — модуль DataSource.
- SQLException обрабатывает SQL-ошибки, возникающие при взаимодействии приложении и базы данных.
- ResultSet и Statement моделируют наборы результатов данных и операторы SQL.
Добавление JDBC-драйвера в classpath
JDBC-драйвер — это класс, обеспечивающий взаимодействие интерфейса JDBC API с базой данных определенного типа. Драйвер для SQLite представляет собой .jar-файл — его нужно добавить в classpath, как показано ниже:
java.exe -classpath /path-to-driver/sqlite-jdbc-3.23.1.jar:. WhatIsJdbc
Установление соединения с базой данных
Теперь в classpath есть доступ к драйверу. Вставьте приведенный ниже код в файл с вашей первой программой:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.ResultSet;
import java.sql.Statement;
class WhatIsJdbcpublic static void main(String[] args) Connection conn = null;
try String url = «jdbc:sqlite:path-to-db/chinook/chinook.db»;
conn = DriverManager.getConnection(url);
System.out.println(«Соединение установлено»);
> catch (SQLException e) throw new Error(«Ошибка при подключении к базе данных», e);
> finally try if (conn != null) conn.close();
>
> catch (SQLException ex) System.out.println(ex.getMessage());
>
>
>
Теперь можно компилировать и запускать код. В случае успешного подключения появится сообщение «Соединение установлено».
Создание запроса к базе данных
В приведенном ниже примере показано, как создать запрос к базе SQLite, используя Connection и Statement:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.ResultSet;
import java.sql.Statement;
class WhatIsJdbcpublic static void main(String[] args) Connection conn = null;
try String url = «jdbc:sqlite:path-to-db-file/chinook/chinook.db»;
conn = DriverManager.getConnection(url);
Statement stmt = null;
String query = «select * from albums»;
try stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(query);
while (rs.next()) String name = rs.getString(«title»);
System.out.println(name);
>
> catch (SQLException e ) throw new Error(«Problem», e);
> finally if (stmt != null) < stmt.close(); >
>
> catch (SQLException e) throw new Error(«Problem», e);
> finally try if (conn != null) conn.close();
>
> catch (SQLException ex) System.out.println(ex.getMessage());
>
>
>
Результатом выполнения этого кода будет вывод списка музыкальных альбомов из учебной базы в консоль.
Возможностей JDBC API достаточно для реализации простых приложений. Для более масштабных решений чаще используют JPA API, который позволяет сохранять Java-объекты в базе данных.
Java-разработчик
Java уже 20 лет в мировом топе языков программирования. На нем создают сложные финансовые сервисы, стриминги и маркетплейсы. Освойте технологии, которые нужны для backend-разработки, за 14 месяцев.

Статьи по теме:
JDBC или с чего всё начинается

В современном мире без хранения данных никак. И история работы с базами данных началась уже очень давно, с появления JDBC. Предлагаю вспомнить то, без чего не обходися ни один современный фрэймворк, построенный поверх JDBC. Кроме того, даже работая с ними временами может понадобится возможность «вернуться к корням». Надеюсь, обзор поможет как вступительное слово или поможет что-то освежить в памяти.

Вступление
Одна из основных целей языка программирования — хранение и обработка информации. Чтобы лучше понять работу хранения данных стоит немного времени выделить на теорию и архитектуру приложений. Например, можно ознакомиться с литературой, а именно с книгой «Software Architect’s Handbook: Become a successful software architect by implementing effective arch. » авторства Joseph Ingeno. Как сказано, есть некий Data Tier или «Слой данных». Он включает в себя место хранения данных (например, SQL базу данных) и средства для работы с хранилищем данных (например, JDBC, о котором и пойдёт речь). Так же на сайте Microsoft есть статья: «Проектирование уровня сохраняемости инфраструктуры» в которой описывается архитектурное решение выделения из Data Tier дополнительного слоя — Persistence Layer. В таком случае Data Tier — это уровень хранения самих данных, в то время как Persistence Layer — это некоторый уровень абстракции для работы с данными из хранилища с уровня Data Tier. К уровню Persistence Layer можно отнести шаблон «DAO» или различные ORM. Но ORM — это тема отдельного разговора. Как Вы могли уже понять, вначале появился Data Tier. Ещё с времён JDK 1.1 в Java мире появился JDBC (Java DataBase Connectivity — соединение с базами данных на Java). Это стандарт взаимодействия Java-приложений с различными СУБД, реализованный в виде пакетов java.sql и javax.sql, входящих в состав Java SE:

Данный стандарт описан специфкицией «JSR 221 JDBC 4.1 API». Данная спецификация рассказывает нам о том, что JDBC API предоставляет программный доступ к реляционным базам данных из программ, написанных на Java. Так же рассказывает о том, что JDBC API является частью платформы Java и входит поэтому в Java SE и Java EE. JDBC API представлен двумя пакетами: java.sql and javax.sql. Давайте тогда с ними и познакомимся.

Начало работы
Чтобы понять что такое вообще JDBC API нам понадобится Java приложение. Удобнее всего воспользоваться одной из систем сборки проектов. Например, воспользуемся Gradle. Более подробно про Gradle можно прочитать в небольшом обзоре: «Краткое знакомство с Gradle». Для начала инициализируем новый Gradle проект. Так как функциональность Gradle реализуется через плагины, то для инициализации нам нужно воспользоваться «Gradle Build Init Plugin»:
gradle init --type java-application
Откроем после этого билд скрипт — файл build.gradle, где описывается наш проект и то, как с ним нужно работать. Нас интересует блок «dependencies«, где описываются зависимости — то есть те библиотеки/фрэймворки/api, без которых мы не можем работать и от которых мы зависим. По умолчанию мы увидим что-то вроде:
dependencies < // This dependency is found on compile classpath of this component and consumers. implementation 'com.google.guava:guava:26.0-jre' // Use JUnit test framework testImplementation 'junit:junit:4.12' >
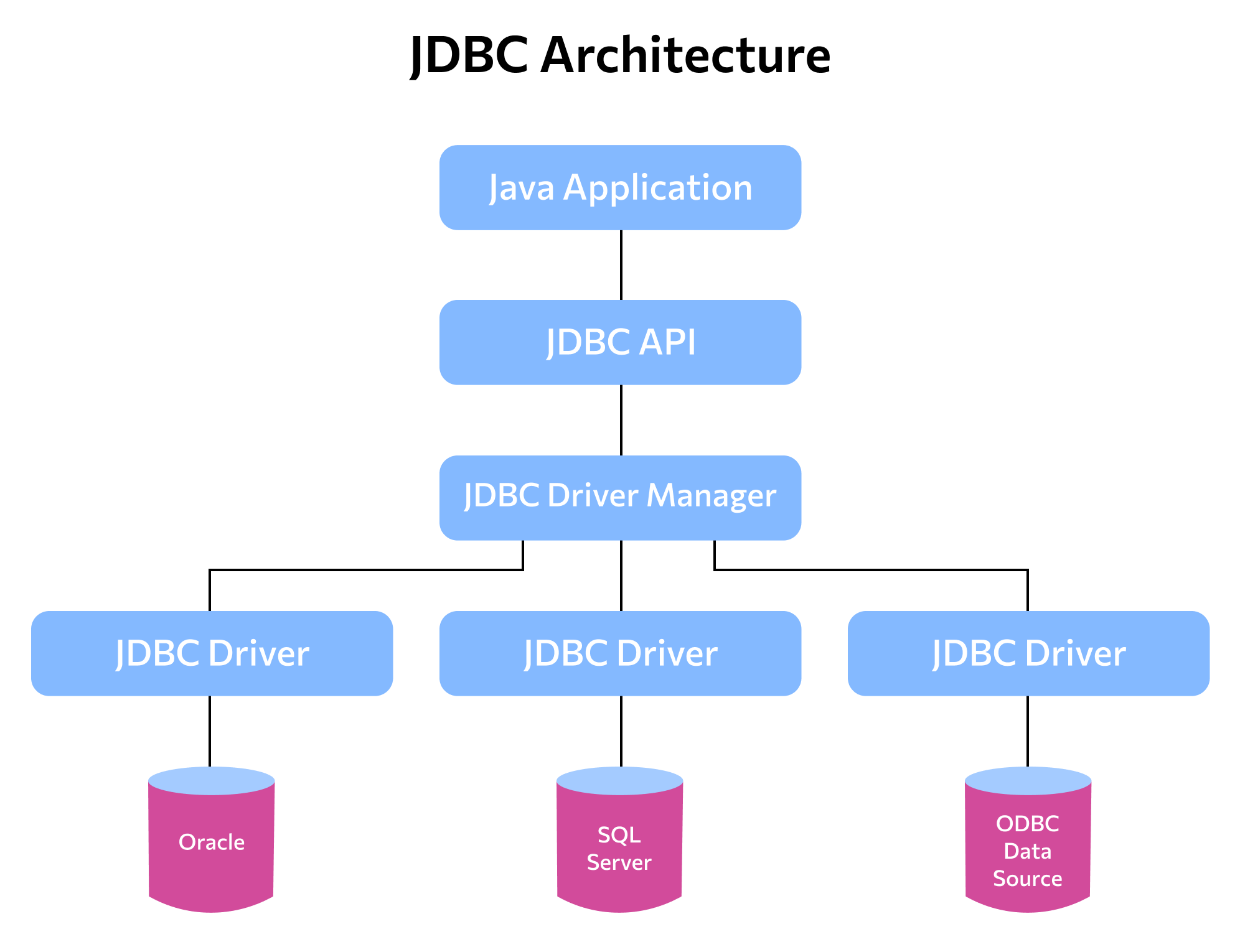
Почему мы тут это видим? Это зависимости нашего проекта, которые нам сгенерировал автоматически Gradle при создании проекта. А так же потому что guava — это отдельная библиотека, не входящая в комплект с Java SE. JUnit так же не входит в комплект с Java SE. Но JDBC у нас есть «из коробки», то есть входит в состав Java SE. Получается JDBC у нас есть. Отлично. Что же нам ещё надо? Есть такая замечательная схема:

Как мы видим, и это логично, база данных является внешним компонентом, которого нет изначально в Java SE. Это объясняется просто — существует огромное количество баз данных и работать вы можете захотеть с любой. Например, есть PostgreSQL, Oracle, MySQL, H2. Каждая из этих баз данных поставляется отдельной компанией, которые называются поставщиками баз данных или database vendors. Каждая база данных написана на каком-то своём языке программирования (не обязательно Java). Чтобы с базой данных можно было работать из Java приложения поставщик базы данных пишет особый драйвер, который является своего образа адаптером. Такие JDBC совместимые (то есть у которых есть JDBC драйвер) ещё называют «JDBC-Compliant Database». Тут можно провести аналогию с компьютерными устройствами. Например, в блокноте есть кнопка «Печать». Каждый раз когда вы её нажимаете программа сообщает операционной системе, что приложение блокнот хочет напечатать. И у Вас есть принтер. Чтобы научить разговаривать единообразно вашу операционную систему с принтером Canon или HP понадобятся разные драйверы. Но для Вас, как пользователя, ничего не изменится. Вы по прежнему будете нажимать одну и ту же кнопку. Так и с JDBC. Вы выполняете один и тот же код, просто «под капотом» могут работать разные базы данных. Думаю, тут очень понятный подход. Каждый такой JDBC драйвер — это некоторый артефакт, библиотека, jar файл. Он то и является зависимостью для нашего проекта. Например, мы можем выбрать базу данных «H2 Database» и тогда нам надо добавить зависимость следующим образом:
dependencies < implementation 'com.h2database:h2:1.4.197'
То, как найти зависимость и как её описать указано на официальных сайтах поставщика БД или на "Maven Central". JDBC драйвер не является базой данных, как Вы поняли. А лишь является проводником к ней. Но есть такое понятие, как "In memory databases". Это такие базы данных, которые существуют в памяти на время жизни вашего приложения. Обычно, это часто используют для тестирования или для учебных целей. Это позволяет не ставить отдельный сервер баз данных на машине. Что нам очень даже подойдёт для знакомств с JDBC. Вот и готова наша песочница и мы приступаем.

Connection
- Через DriverManager
- Через DataSource
Connection con = DriverManager.getConnection(url, user, passwd);
Параметры можно взять с сайта выбранной нами базы данных. В нашем случае это H2 — "H2 Cheat Sheet". Перейдём в подготовленный Gradle'ом класс AppTest. Он содержит JUnit тесты. JUnit тест — это метод, который помечен аннотацией @Test . Юнит тесты не являются темой данного обзора, поэтому просто ограничимся пониманием того, что это описанные определённым образом методы, цель которых что-то протестировать. Согласно специфкиации JDBC и сайту H2 проверим, что мы получили подключение к БД. Напишем метод получения подключения:
private Connection getNewConnection() throws SQLException
Теперь напишем тест для этого метода, который проверит, что подключение действительно устанавливается:
@Test public void shouldGetJdbcConnection() throws SQLException < try(Connection connection = getNewConnection()) < assertTrue(connection.isValid(1)); assertFalse(connection.isClosed()); >>
Данный тест при выполнении проверит, что полученное подключение валидное (корректно созданное) и что оно не закрыто. Благодаря использованию конструкции try-with-resources мы освободим ресурсы после того, как они нам больше не нужны. Это убережёт нас от "провисших" соединений и утечек памяти. Так как любые действия с БД требуют подключения, то давайте для остальных тестовых методов, помеченных @Test, обеспечим в начале теста Connection, который мы освободим после теста. Для этого нам понадобится две аннотации: @Before и @After Добавим в класс AppTest новое поле, которое будет хранить JDBC подключение для тестов:
private static Connection connection;
И добавим новые методы:
@Before public void init() throws SQLException < connection = getNewConnection(); >@After public void close() throws SQLException
Теперь, любому тестовому методу гарантируется наличие JDBC connection и он не должен каждый раз сам его создавать.

Statements
- Statement: SQL выражение, которое не содержит параметров
- PreparedStatement : Подготовленное SQL выражение, содержащее входные параметры
- CallableStatement : SQL выражение с возможностью получить возвращаемое значение из хранимых процедур (SQL Stored Procedures).
private int executeUpdate(String query) throws SQLException < Statement statement = connection.createStatement(); // Для Insert, Update, Delete int result = statement.executeUpdate(query); return result; >
Добавим метод создания тестовой таблицы с использованием прошлого метода:
private void createCustomerTable() throws SQLException
Теперь протестируем это:
@Test public void shouldCreateCustomerTable() throws SQLException
Теперь давайте выполним запрос, да ещё и с параметром:
@Test public void shouldSelectData() throws SQLException
JDBC не поддерживает именованные параметры для PreparedStatement, поэтому сами параметры указываются вопросами, а указывая значение мы указываем индекс вопроса (начиная с 1, а не с нуля). В последнем тесте мы получили true как признак того, есть ли результат. Но как представлен результат запроса в JDBC API? А представлен он как ResultSet.

ResultSet
Понятие ResultSet описано в спецификации JDBC API в главе "CHAPTER 15 Result Sets". Прежде всего, там сказано, что ResultSet предоставляет методы для получения и манипуляции результатами выполненных запросов. То есть если метод execute вернул нам true, значит мы можем получить и ResultSet. Давайте вынесем вызов метода createCustomerTable() в метод init, который отмечен как @Before. Теперь доработаем наш тест shouldSelectData:
@Test public void shouldSelectData() throws SQLException < String query = "SELECT * FROM customers WHERE name = ?"; PreparedStatement statement = connection.prepareStatement(query); statement.setString(1, "Brian"); boolean hasResult = statement.execute(); assertTrue(hasResult); // Обработаем результат ResultSet resultSet = statement.getResultSet(); resultSet.next(); int age = resultSet.getInt("age"); assertEquals(33, age); >
Тут стоит отметить, что next — это метод, который двигает так называемый "курсор". Курсор в ResultSet указывает на некоторую строку. Таким образом, чтобы считать строку, на неё нужно этот самый курсор установить. Когда курсор перемещается, то метод перемещения курсора возвращает true, если курсор валидный (правильный, корректный), то есть указывает на данные. Если возвращает false, значит данных нет, то есть курсор не указывает на данные. Если попытаться получить данные с невалидным курсором, то мы получим ошибку: No data is available Ещё интересно, что через ResultSet можно обновлять или даже вставлять строки:
@Test public void shouldInsertInResultSet() throws SQLException
RowSet
JDBC помимо ResultSet вводит такое понятие, как RowSet. Подробнее можно прочитать здесь: "JDBC Basics: Using RowSet Objects". Существуют различные вариации использования. Например, самый простой случай может выглядеть так:
@Test public void shouldUseRowSet() throws SQLException
Как видно, RowSet похож на симбиоз statement (мы указали через него command) и выполнили command. Через него же мы управляем курсором (вызывая метод next) и из него же получаем данные. Интересен не только такой подход, но и возможные реализации. Например, CachedRowSet. Он является "отключённым" (то есть не использует постоянное подключение к БД) и требует явного выполнения синхронизации с БД:
CachedRowSet jdbcRsCached = new CachedRowSetImpl(); jdbcRsCached.acceptChanges(connection);
Подробнее можно прочитать в tutorial на сайте Oracle: "Using CachedRowSetObjects".

Metadata
Кроме запросов, подключение к БД (т.е. экземпляр класса Connection) предоставляет доступ к метаданным - данным о том, как настроена и как устроена наша база данных. Но для начала озвучим несколько ключевых моментов: URL подключения к нашей БД: "jdbc:h2:mem:test". test - это название нашей базы данных. Для JDBC API это каталог. И название будет в верхнем регистре, то есть TEST. Схема по умолчанию (Default schema) для H2 - PUBLIC. Теперь, напишем тест, который показывает все пользовательские таблицы. Почему пользовательские? Потому что в базах данных есть не только пользовательские (те, которые мы сами создали при помощи create table выражений), но и системные таблицы. Они необходимы, чтобы хранить системную информацию о структуре БД. У каждой БД такие системные таблицы могут храниться по-разному. Например, в H2 они хранятся в схеме "INFORMATION_SCHEMA". Интересно, что INFORMATION SCHEMA является общим подходом, но Oracle пошли иным путём. Подробнее можно прочитать здесь: "INFORMATION_SCHEMA и Oracle". Напишем тест, получающий метаданные по пользовательским таблицам:
@Test public void shoudGetMetadata() throws SQLException < // У нас URL = "jdbc:h2:mem:test", где test - название БД // Название БД = catalog DatabaseMetaData metaData = connection.getMetaData(); ResultSet result = metaData.getTables("TEST", "PUBLIC", "%", null); Listtables = new ArrayList<>(); while(result.next()) < tables.add(result.getString(2) + "." + result.getString(3)); >assertTrue(tables.contains("PUBLIC.CUSTOMERS")); >

Пул подключений
Пулу подключений в спецификации JDBC отведен раздел "Chapter 11 Connection Pooling". В нём же и даётся главное обоснование необходимости пула подключений. Каждый Coonection - это физическое подключение к БД. Его создание и закрытие - довольно "дорогая" работа. JDBC предоставляет лишь API для пула соединений. Поэтому, выбор реализации остаётся за нами. Например, к таким реализациям относится HikariCP. Соответственно, нам понадобится добавить пул к нам в зависимости проекта:
dependencies
Теперь надо как-то пул этот задействовать. Для этого нужно выполнить инициализацию источника данных, он же Datasource:
private DataSource getDatasource()
И напишем тест на получение подключения из пула:
@Test public void shouldGetConnectionFromDataSource() throws SQLException < DataSource datasource = getDatasource(); try (Connection con = datasource.getConnection()) < assertTrue(con.isValid(1)); >>

Транзакции
- Data Manipulation Language, он же DML (Insert, Update, Delete)
Транзакция завершается как только завершилось выполнение действия Select Statements
Транзакция завершается тогда, когда ResultSet будет закрыт (ResultSet#close) - CallableStatement и выражения, возвращающие несколько результатов
Когда все ассоциированные ResultSets будут закрыты и все выходные данные получены (включая кол-во апдейтов)
@Test public void shouldCommitTransaction() throws SQLException < connection.setAutoCommit(false); String query = "INSERT INTO customers VALUES (1, 'Max', 20)"; connection.createStatement().executeUpdate(query); connection.commit(); Statement statement = connection.createStatement(); statement.execute("SELECT * FROM customers"); ResultSet resultSet = statement.getResultSet(); int count = 0; while(resultSet.next()) < count++; >assertEquals(2, count); >
Всё просто. Но это так, пока у нас всего одна транзакция. А что делать, когда их несколько? Нужно их изолировать друг от друга. Поэтому, поговорим об уровнях изоляции транзакции и как с ними справляется JDBC.

Уровни изоляции
- Atomicity(Атомарность):
Никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной. - Consistency(Согласованность):
Каждая успешная транзакция по определению фиксирует только допустимые результаты. - Isolation(Изолированность):
Во время выполнения транзакции параллельные транзакции не должны оказывать влияния на её результат. - Durability(Долговечность):
Если транзакция успешно завершенеа, сделанные в ней изменения не будут отменены из-за какого-либо сбоя.
Далее, используем это в версиях:
dependencies < implementation "com.h2database:h2:$" implementation "com.zaxxer:HikariCP:$" testImplementation "junit:junit:$" >
Вы могли заметить, что версия h2 стала ниже. Позже мы увидим, зачем. Итак, как же применять уровни изолированности? Давайте посмотрим сразу небольшой практический пример:
@Test public void shouldGetReadUncommited() throws SQLException < Connection first = getNewConnection(); assertTrue(first.getMetaData().supportsTransactionIsolationLevel(Connection.TRANSACTION_READ_UNCOMMITTED)); first.setTransactionIsolation(Connection.TRANSACTION_READ_UNCOMMITTED); first.setAutoCommit(false); // Транзакиця на подключение. Поэтому первая транзакция с ReadUncommited вносит изменения String insertQuery = "INSERT INTO customers VALUES (5, 'Max', 15)"; first.createStatement().executeUpdate(insertQuery); // Вторая транзакция пытается их увидеть int rowCount = 0; JdbcRowSet jdbcRs = new JdbcRowSetImpl(getNewConnection()); jdbcRs.setCommand("SELECT * FROM customers"); jdbcRs.execute(); while (jdbcRs.next()) < rowCount++; >assertEquals(2, rowCount); >
Интересно, что данный тест может упасть на вендоре, который не поддерживает TRANSACTION_READ_UNCOMMITTED (например, sqlite или HSQL). А ещё уровень транзакции может просто не сработать. Помните мы указывали версию драйвера H2 Database? Если мы поднимем её до h2Version = '1.4.177' и выше, то READ UNCOMMITTED перестанет работать, хотя код мы не меняли. Это ещё раз доказывает, что выбор вендора и версии драйвера - это не просто буквы, от этого будет в реальности зависеть то, как будут выполняться ваши запросы. Про то, как исправить это поведение в версии 1.4.177 и как это не работает в версиях выше можно прочитать здесь: "Support READ UNCOMMITTED isolation level in MVStore mode".
Итог
- Огненный доклад: "Transactions: myths, surprises and opportunities" от Martin Kleppmann
- Юрий Ткач: "JPA. Транзакции"
- Юрик Ткач: "JDBC - Java для тестировщиков"
- Бесплатный курс на Udemy: "JDBC and MySQL"
- "Обработка объектов CallableStatement"
- IBM Developer: "Java Database Connectivity"
- IBM Knowledge Center: "Getting started with JDBC"
Обзор спецификации JDBC
Я думаю, что читатель со мной согласится, - нельзя говорить о промышленном использовании инструментального средства общего назначения (каковым является Java в сетецентрической модели вычислений), если это средство не поддерживает работу с базами данных. Практически одновременно с выпуском первой реализации JDK (Java Development Kit) была опубликована и спецификация JDBC (часто расшифровывается как Java DataBase Connectivity, однако это не акроним, а зарегистрированная торговая марка). Если мы попытаемся дать наиболее краткую аннотацию JDBC, то скорее всего получим следующее: JDBC - это Java API для выполнения SQL-запросов к базам данных. Так как Java является объектно-ориентированным языком, то под API (Application Programming Interface) подразумевается набор классов и интерфейсов (в понимании языка Java). Эти классы и интерфейсы описываются в специальном пакете (package) java.sql .
Мы попытаемся разобраться с основными понятиями JDBC, последовательно разбирая содержание спецификации. Надеюсь, что этот материал окажется не просто введением или обзором JDBC, но и чем-то вроде навигатора по спецификации. Для этого в качестве разделов основной части статьи использовались названия глав спецификации с приведением их оригинальных названий.
Спецификация
1. Введение (Introduction)
JDBC, также как и Microsoft ODBC и Borland DataBase Engine (BDE), базируется на X/Open SQL CLI (Call Level Interface). Авторы спецификации обращают особое внимание на то, что их основная задача состоит в описании основных абстракций и концепций, определенных в X/Open CLI, в виде натуральных ("родных") интерфейсов Java.
Для того чтобы лучше понять суть подхода, используемого в JDBC, напомню, что представляют из себя интерфейсы Java. В отличие от классов, заключающих в себе как объявление, так и реализацию методов, интерфейсы обеспечивают более высокий уровень абстракции, описывая только объявления методов. Учитывая возможность наследования, причем наследования множественного (в отличие от классов), такой подход позволяет создавать программы, предназначенные для работы с базами данных, не зависящие от конкретной реализации как самой СУБД, так и методов доступа к ней. Для того чтобы обратиться к конкретной СУБД (подразумеваются серверы баз данных), будь это Oracle, Informix, InterBase или что-то другое, разработчику необходим JDBC-драйвер. В концепции универсиализации доступа к данным через стандартные интерфейсы (мы их рассмотрим ниже в этой статье) JDBC-драйвер есть совокупность классов, реализующих JDBC-интерфейсы. Под реализацией интерфейса в Java понимается создание класса, ссылающегося в своем объявлении на интерфейс и предлагающего конкретную реализацию методов интерфейса уже в виде методов данного класса.
2. Цели и философия (Goals and phylosophy)
Этот раздел спецификации определяет приоритеты, заложенные в основу взаимодействия Java-программ и баз данных.
- JDBC предполагает передачу запроса к базе данных в виде строки. Таким образом, могут использоваться конструкции SQL, специфичные для данной базы данных и/или ее JDBC-драйвера.
- Определяя некий универсальный метод работы с базами данных, JDBC предполагает и конкретные требования к базовому SQL. Базовым требованием JDBC (то, что называется JDBC compliantTM ), является удовлетворение входного уровня (Entry Level) ANSI-стандарта SQL-92 (SQL-2). Такие требования обусловлены наличием определенного понятийного поля, то есть минимального (аксиоматического) набора предопределенных сущностей, характерных для РСУБД. Например, по свойствам и поведению транзакций, базовым типам данных и т. п.
- Сохранение по возможности строгой статической типизации, что должно обеспечить большую степень защиты от ошибок на уровне компиляции в байт-код. Однако это требование не является абсолютным, так как SQL DML (Data Manipulation Language) является по своей природе динамическим. Например, такие сущности, как наборы строк результирующих множеств, содержат динамически определяемое число и типы столбцов. Несколько утрируя данную позицию создателей спецификации, можно сказать, что "динамичности" предостаточно у самого SQL.
- Увеличение числа методов интерфейсов, с одновременной "атомизацией" (упрощением, даже минимизацией) функциональности этих методов. Определяя работу по принципу "одно действие - один метод", этот подход должен обеспечить лучшую читаемость и прозрачность логики кода. Другими словами, лучше использовать набор простых методов, чем многоцелевые (в оригинале multi-purpose) методы с большими наборами параметров-флагов.
3. Обзор основных интерфейсов (Overview of the major interfaces)
Данный раздел дает краткое описание базовых интерфейсов (3.1 The JDBC API) и интерфейса драйвера (3.2 The JDBC Driver Interface).
Первая часть этого раздела выделяет как наиболее важные следующие интерфейсы (общая схема их взаимодействия представлена на рис. 1):
- java.sql.DriverManager обеспечивает загрузку драйверов и создание новых соединений (connection) с базой данных; это стержневой интерфейс JDBC, определяющий корректный выбор и инициализацию драйвера для данной СУБД в данных условиях;
- java.sql.Connection определяет характеристики и состояние соединения с БД; кроме того, он предоставляет средства для контроля транзакций и уровня их изолированности;
- java.sql.Statement выполняет функции контейнера по отношению к SQL-выражению; при этом под выражением понимается не только сам текст запроса, но и такие характеристики, как параметры и состояние выражения;
- java.sql.ResultSet предоставляет доступ к набору строк, полученному в результате выполнения данного SQL-выражения.
Рисунок 1.
Основные интерфейсы JDBC.
Интерфейс выражения java.sql.Statement выступает в качестве предка для других двух важных интерфейсов: java.sql.PreparedStatement и java.sql.CallableStatement, первый из которых предназначен для выполнения прекомпилированных SQL-выражений, второй - для выполнения вызовов хранимых процедур. Соответственно Statement выполняет обычные (статические) SQL-запросы, а указанные два наследника работают с параметризированными SQL-выражениями.
Вторая часть рассматриваемого раздела (3.2) акцентирует внимание разработчиков на разделении JDBC API на несколько уровней - прикладного API (верхний уровень), драйверного API (средний уровень) - функций драйвера для получения базовых интерфейсов - соединения, выражений и результирующих данных, а также описательного (нижний уровень), отвечающего за конкретную реализацию JDBC-драйвера, как системно/СУБД-зависимой части (например, как платформно-зависимый мост JDBC-ODBC или, полностью написанные на Java так называемые драйверы JDBC-Net).
Кроме перечисленных базовых интерфейсов JDBC описывает и другой, не менее важный специфический набор интерфейсов - для работы с метаданными, то есть со структурой БД (мы рассмотрим их несколько позже). Эти две группы интерфейсов являются краеугольными камнями JDBC.
Наконец, приведем простейший пример установки соединения и получения данных из БД:
Connection con = DriverManager.getConnection ( "jdbc:wombat", "myloginname", "mypassword"); // то же самое с использованием моста // JDBC-ODBC // Connection con = // DriverManager.getConnection ( // "jdbc:odbc:wombat", "myloginname", // "mypassword"); Statement stmt = con.createStatement(); ResultSet res = stmt.executeQuery("SELECT StringColumn,IntColumn FROM MyTable"); while (res.next()) < String sCol = res.getString("StringColumn"); int iCol = res.getInt("IntColumn"); . // обработка данных >
Рисунок 2.
Уровни реализации JDBC API.
Конечно, в реальной системе нам необходимо обработать возможные исключительные ситуации, которые могут возникнуть при неправильном вводе пароля, указании несуществующей таблицы в SQL-запросе и т.п. Однако, построение полнофункционального приложения не есть цель данной статьи, оставим ее авторам книг по Java и JDBC.
4. Сценарии использования (Scenarios of using)
Раздел описывает основные два сценария доступа к БД - из апплетов (4.1), загружаемых по сети, и самостоятельных приложений (4.2), выполняемых на клиенте.
Наиболее часто встречающаяся область применения Java - это создание апплетов, загружаемых по сети на клиентскую машину как часть web-документа (в большинстве случаев html). Как и в любой другой области применения программ, большая доля этих апплетов должна уметь взаимодействовать с базой данных, причем, с базой данных находящейся на сервере (не на клиентской машине, так как апплет обладает более существенными ограничениями по доступу к ресурсам машины по сравнению с приложением).
В этом случае сценарий взаимодействия такого апплета с БД будет напоминать следующий (см. рис. 3).
- Апплет загружается (в виде байт-кода) на клиентскую машину в составе web-документа;
- Виртуальная машина на клиенте стартует апплет.
- Апплет запрашивает менеджер драйверов JDBC (при этом необходимый JDBC-драйвер физически находится на клиенте);
- Апплет получает доступ к серверу баз данных по протоколу Internet (TCP).
В зависимости от конкретной архитектуры реализации драйвера клиентская часть сервера баз данных может присутствовать на клиенте или только на web-сервере (или другом сервере, доступном в сети). В первом случае JDBC-драйвер обычно реализуется как набор Java-классов, описывающих интерфейсы java.sql.* через native-вызовы (платформно-зависимый код). Во втором случае JDBC-драйвер обычно называют JDBC-Net. Он написан целиком на Java и обращается к серверу баз данных по TCP/IP, формируя дейтаграммы в формате, понятном серверу.
Понятно, что типичные апплеты отличаются от традиционных приложений баз данных целым рядом особенностей:
- апплеты небезопасны (untrusted relations - недоверительные отношения) по своей природе, загружаясь на клиентскую машину извне; они не имеют права обращаться к локальным ресурсам (конкретные ограничения связаны в большинстве случаев с реализацией виртуальной машины);
- апплеты добавляют новые проблемы, связанные с идентификацией и аутентификацией пользователей, а также с проверкой доступа к базе данных;
- соображения производительности имеют большее число "переменных", по сравнению с традиционными схемами клиент-сервер;
Архитектура Java позволяет также создавать и самостоятельные приложения (4.2). Конечно, они, как и апплеты, выполняются виртуальной машиной, но в отличие от последних существуют вне контекста web-документов. В этом случае сценарий отличает от описанного выше отсутствие пункта 1, а ограничения на доступ к локальным ресурсам снимается до уровня обращения к ним через виртуальную машину (см. рис. 3).
Рисунок 3.
Взаимодействие приложения с БД.
Кроме двух основных сценариев, описанных выше, этот раздел содержит и упоминание "безопасных" (trusted) апплетов и трехзвенной модели (4.3 Other scenarios). Безопасные апплеты включают криптографический ключ и могут, как и приложения, обращаться к локальным ресурсам через виртуальную машину. Случай трех-уровневой архитектуры подразумевает вызов из апплетов или приложений не сервера баз данных напрямую, а сервера приложений/бизнес-логики, который уже, в свою очередь, осуществляет взаимодействие с сервером БД.
На рис. 4 представлена диаграмма взаимодействия Java-кода и баз данных в трехуровневой (точнее, многоуровневой N-tier) модели. Как вы видите, в качестве основных способов взаимодействия между Java-приложениями (апплетами) и серверами среднего звена используются RPC (вызовы удаленных процедур) и CORBA. В случае CORBA, вообще говоря, кроме звена бизнес-логики присутствует и ORB (брокер объектных запросов или, как стало принято называть у нас в литературе, брокер объектных заявок). Что касается самих серверов приложений, то Java (в частности, JDBC) никаких специальных требований к ним не предъявляет, как и в случае с серверами баз данных.
Рисунок 4.
Трехуровневая модель.
5. Соображения безопасности (Security considerations)
Название раздела говорит само за себя. Основной упор в защите доступа к базам данных делается на использование менеджера безопасности Java, реализуемого исполняющей системой (виртуальной Java-машиной).
В отношении апплетов спецификация JDBC (5.1 JDBC and untrusted applets) формулирует следующие основные положения.
- JDBC предполагает, что неавторизованные (unsigned - буквально "неподписанные") апплеты являются небезопасными;
- JDBC не позволяет небезопасным апплетам обращаться к локальным базам данных;
- Если загружаемый JDBC-драйвер регистрирует себя у JDBC DriverManager, он должен быть загружен из того же источника (web-сервера), что и вызывающий его Java-код;
- Небезопасные апплеты могут открывать соединение с базой данных только через web-сервер, с которого они были загружены;
- JDBC игнорирует автоматическое или неявное использование локальных имен и кодов авторизации (например, имен и паролей, используемых клиентской операционной системой) для доступа к удаленным серверам баз даных.
В отношении Java-приложений (5.2 JDBC and Java applications) JDBC не накладывает никаких специальных ограничений, загружая драйверы из локального пути имен. Однако, если класс sql.Driver загружается из удаленного источника, этот драйвер может быть использован только тем загружаемым кодом, который имеет один и тот же источник с этим классом.
В качестве шаблона прикладного кода проверки доступ на уровне сетевого взаимодействия (5.3 network security), еще до открытия сессии взаимодействия с базой данных, предлагается следующее:
SecurityManager security = System.getSecurityManager(); if (security != null)
Далее начинают работать механизмы аутентификации, поддерживаемые той или иной сетевой операционной системой, сервером приложений и сервером баз данных.
Часть рассматриваемого раздела "Ответственность драйверов за безопасность" (5.4 Security Responsibilities of Drivers) описывает основные моменты, связанные с разделением (совместным использованием) TCP-соединений (5.4.1 . sharing TCP connections), необходимых проверок для доступа к локальным файлам (5.4.2) и вызовов native-методов для осуществления взаимодействия с низкоуровневыми библиотеками доступа к базам данных (на примере моста JDBC-ODBC).
Во всех этих случаях базовой конструкцией проверки безопасности является уже знакомый код, выглядящий, в общем случае, следующим образом:
SecurityManager security = System.getSecurityManager(); if (security != null)
6. Организация соединения с базой данных (Database connections)
Этот раздел освещает основные вопросы, связанные с подсоединением к базе данных.
Для доступа к базе данных необходимо получить объект java.sql.Connection. Сделать это можно, обратившись к уровню управления JDBC посредством вызова java.sql.DriverManager.getConnection. Основным параметром этого вызова является строка URL (Uniform Resource Locator), описывающая такие характеристики соединения, как субпротокол (например, ODBC) и имя базы данных (может быть комплексным, описывая сервер, путь и файл БД). После получения объекта соединения можно начать работу непосредственно с базой данных, обращаясь к методам java.sql.Connection для создания объектов java.sql.Statement, java.sql.PreparedStatement и java.sql.CallableStatement.
Механизм именования баз данных в JDBC, базируясь на URL, решает такие вопросы, как автоматический выбор драйвера, способного осуществить доступ к данной БД, определение характеристик соединения и т.п.
В общем случае спецификация рекомендует следующую конструкцию URL:
Используя субпротокол, вы можете обращаться к специфическим сетевым службам именования, например DCE. Простейшим примером может служить следующая строка: jdbc:odbc:mysrc , где в качестве субпротокола выступает ODBC, определяя использование моста JDBC-ODBC, а mysrc является источником данных (data source), определенным уже в рамках ODBC. Мост JDBC-ODBC предусматривает следующий синтаксис:
В качестве атрибутов могут выступать такие характеристики, как размер кэша (CacheSize), имя пользователя (UID), пароль (PWD) и т.п.
JDBC предусматривает и возможность динамического подсоединения к базе данных. В этом случае вы можете произвести такие операции, как явная загрузка драйвера
Class.forName("acme.db.Driver");, его регистрация через вызов DriverManager.registerDriver и т. п.
В случае с ODBC можно привести следующий пример динамического соединения:
Class.forName("sun.jdbc.odbc. JdbcOdbcDriver"); String url = "jdbc:odbc:mysrc"; DriverManager.getConnection(url, "myuserID", "mypassword");
7. Передача параметров и получение результатов (Passing parameters and receiving results)
Еще раз приведем пример получения данных из БД:
Statement stmt = con.createStatement(); ResultSet res = stmt.executeQuery("SELECT StringColumn,IntColumn FROM MyTable"); while (res.next()) < String sCol = res.getString("StringColumn"); int iCol = res.getInt("IntColumn"); . // обработка данных >
В данном случае использовалось обращение к столбцам таблицы по их именам. Причем регистр имени столбца не играет роли (case insensitive).
JDBC предусматривает и доступ по номеру столбца:
Statement stmt = con.createStatement(); ResultSet res = stmt.executeQuery("SELECT StringColumn,IntColumn FROM MyTable"); while (res.next())
При этом столбцы нумеруются начиная с 1, а не с нуля.
Очевидно, что при описанных подходах в работе с результирующим множеством строк особое значение приобретает исчерпывающее описание методов ResultSet.getXxxx. Действительно, информация в базе данных часто хранится не только в виде столбцов простейших типов (целое, длинное целое и т. п.), но и в специфических двоичных форматах. Таблица 1 описывает возможность получения данных того или иного типа с помощью соответствующих методов getXxxx (особо выделены те ячейки отображения "метод-тип", использование которых рекомендовано стандартом).
| T | S | I | B | R | F | D | D | N | B | C | V | L | B | V | L | D | T | T | |
| Y | M | N | I | E | L | O | E | U | I | H | A | O | I | A | O | A | I | I | |
| I | A | T | G | A | O | U | C | M | T | A | R | N | N | R | N | T | M | M | |
| N | L | E | I | L | A | B | I | E | R | C | G | A | B | G | E | E | E | ||
| Y | L | G | N | T | L | M | R | H | V | R | I | V | S | ||||||
| I | I | E | T | E | A | I | A | A | Y | N | A | T | |||||||
| N | N | R | L | C | R | R | A | R | A | ||||||||||
| T | T | C | R | B | M | ||||||||||||||
| H | Y | I | P | ||||||||||||||||
| A | N | ||||||||||||||||||
| Y | |||||||||||||||||||
| getByte | X | x | x | x | x | x | x | x | x | x | x | x | x | ||||||
| getShort | x | X | x | x | x | x | x | x | x | x | x | x | x | ||||||
| getInt | x | x | X | x | x | x | x | x | x | x | x | x | x | ||||||
| getLong | x | x | x | X | x | x | x | x | x | x | x | x | x | ||||||
| getFloat | x | x | x | x | X | x | x | x | x | x | x | x | x | ||||||
| getDouble | x | x | x | x | x | X | X | x | x | x | x | x | |||||||
| getNumcric | x | x | x | x | x | x | x | X | X | x | x | x | x | ||||||
| getBoolean | x | x | x | x | x | x | x | x | x | X | x | x | x | ||||||
| getString | x | x | x | x | x | x | x | x | x | x | X | X | x | x | x | x | x | x | x |
| getBytes | X | X | x | ||||||||||||||||
| getDate | x | x | x | X | x | ||||||||||||||
| getTime | x | x | x | X | x | ||||||||||||||
| getTimestamp | x | x | x | x | X | ||||||||||||||
| getAsciiSteam | x | x | X | x | x | x | |||||||||||||
| getUnicodeStream | x | x | X | x | x | x | |||||||||||||
| getBinaryStream | x | x | X | x | x | x | |||||||||||||
| getObject | x | x | x | x | x | x | x | x | x | x | x | x | x | x | x | x | x | x | x |
Таблица 1.
Использование методов ResultSet.getXxxx для основных типов SQL.
В рассматриваемом разделе спецификации JDBC определяется и обработка значения SQL "NULL". Для его идентификации можно использовать метод ResultSet.wasNull. В случае чтения "пустых" данных с использованием методов ResultSet.getXxxx вы получите:
- величину "null" в понимании Java, если вызываете методы, возвращающие объекты Java (например, строку или дату);
- 0 для getByte, getShort, getInt, getLong, getFloat и getDouble;
- false для getBoolean.
Как вы обратили внимание (см. табл.1), JDBC предусматривает работу с "большими" величинами - LONGVARBINARY и LONGVARCHAR. Для их обработки используются методы getBytes и getString соответственно. Однако существует величина Statement.getMaxFieldSize, ограничивающая объем данных, прочитываемых за одну операцию getXxxx. В случае данных, размеры которых больше описанной величины, предлагается использовать потоки Java, например:
java.sql.Statement stmt = con.createStatement(); ResultSet r = stmt.executeQuery("SELECT FirstCol FROM MyTable"); byte buff = new byte[4096]; while (r.next()) < Java.io.InputStream fin = r.getAsciiStream(1); for (;;) < int size = fin.read(buff); if (size == -1) < // конец потока break; >. . .
Говоря о передаче параметров, мы подразумеваем параметры IN (передаваемые) и OUT (возвращаемые).
В обоих случаях требуется установить взаимное соответствие типов Java и SQL. Отображению типов посвящен раздел 8 спецификации. В данном же контексте для нас важнее методы работы с параметрами объектов, описывающих интерфейсы PreparedStatement и CallableStatement.
В случае с параметрами IN, необходимо использовать методы PreparedStatement.setXxxx, принимающие в качестве первого значения номер параметра. Сам же параметр должен описываться в SQL-выражении символом ? , как показано в следующем примере:
PreparedStatement pstmt = con.prepareStatement( "UPDATE MyTable SET IntCol1 = ? WHERE IntCol2 = ?"); pstmt.setLong(1, 12345); pstmt.setLong(2, 67890); pstmt.executeUpdate();
Параметры OUT несут смысловую нагрузку в случае работы с хранимыми процедурами. Для этого используются методы CallableStatement. Как и в случае с параметрами IN, в SQL-выражении они представлены символами ?. Вызов Connection.prepareCall принимает такое SQL-выражение. Далее, по порядковому номеру параметров, регистрируются их типы посредством вызовов CallableStatement.registerOutParameter. Теперь запрос может быть выполнен с помощью CallableStatement.executeUpadate(). В остальном работа с набором строк не отличается от описанной выше. Следующий пример демонстрирует работу с параметрами OUT:
CallableStatement cstmt = con.prepareCall( ""); cstmt.registerOutParameter(1, java.sql.Types.DECIMAL, 2); cstmt.registerOutParameter(2, java.sql.Types.TYNYINT); cstmt.executeQuery();
При работе с параметрами, также как и при чтении, возможна работа с "большими" данными. Для этого используются такие методы, как setBinaryStream и т. п.
Конечно, мы смогли остановиться лишь на основных моментах, связанных с получением результатов и передачей параметров. Более полную информацию вы сможете найти в самой спецификации.
8. Отображение типов данных SQL в Java (Mapping SQL data types into Java)
По сути, этот раздел содержит две таблицы отображения типов SQL в Java и Java в SQL. Соответствующие комментарии спецификации обосновывают выбранные варианты отображения. Мы же приведем, так сказать, только факты - сами таблицы.
| SQL type | Java Type |
| CHAR | String |
| VARCHAR | String |
| LONGVARCHAR | String |
| NUMERIC | java.sql.Numeric |
| DECIMAL | java.sql.Numeric |
| BIT | boolean |
| TINYNT | byte |
| SMALLINT | short |
| INTEGER | int |
| BIGINT | long |
| REAL | float |
| FLOAT | double |
| DOUBLE | double |
| BINARY | byte[ ] |
| VARBINARY | byte[ ] |
| LONGVARBINARY | byte[ ] |
| DATE | java.sql.Date |
| TIME | java.sql.Time |
| TIMESTAMP | java.sql.Timestamp |
Таблица 2.
Отображение типов SQL в Java.
9. Асинхронные запросы, потоки и транзакции (Asynchrony, Threading, and Transactions)
Некоторые API, ориентированные на работу с базами данных, предлагают специальные методы для поддержки асинхронных обращений к БД (например, фонового резервного копирования). JDBC не предлагает никаких специальных методов такого рода. Так как Java изначально разрабатывалась как многопоточный инструмент. вы, можете создавать новые потоки Java и выполнять в них операции, требующие асинхронной обработки информации. Соответственно выдвигаются и необходимые требования по поддержке многопоточности (multi-thread safe) к объектам, описывающим интерфейсы пакета java.sql.* .
Новое подключение к базе данных изначально стартует в режиме auto-commit. Это значит, что каждое выражение выполняется в отдельной транзакции. При необходимости можно отменить этот режим, вызвав метод Connection.setAutoCommit с параметром false. После этого необходимо в явном виде указывать операции завершения/отката транзакции посредством вызовов Connection.commit / Connection.rollback. Для определения и контроля уровней изолированности транзакций (набор которых может отличаться для разных серверов баз данных) предлагается использовать методы java.sql.DatabaseMetaData и java.sql.Connection.
10. Курсоры (Cursors)
JDBC предоставляет простейшую поддержку курсоров. Приложения могут использовать ResultSet.getCursorName() для получения курсора, ассоциированного с данным набором строк. После этого с помощью курсора можно выполнять выборочные (с позиционированием) обновления и удаления строк. Однако не все серверы БД поддерживают эти механизмы, поэтому перед их вызовом необходимо удостовериться в такой поддержке с помощью методов DatabaseMetaData.supportPositionedUpdate и DatabaseMetaData.supportPositionedDelete.
11, 12. Расширения SQL (11 SQL Extensions, 12 Variants and Extensions)
Ряд серверов баз данных поддерживают расширения SQL, выходящие за рамки входного уровня стандарта SQL-2. Данный раздел спецификации описывает следующие положения, необходимые для получения драйвером логотипа JDBC-CompliantTM:
- должны поддерживаться синтаксис и семантика Selective Transaction Level (например, должна поддерживаться конструкция DROP TABLE);
- необходимая семантика "транзакционного уровня" должна поддерживаться на уровне escape-синтаксиса так, чтобы драйвер мог анализировать специфический синтаксис того или иного сервера БД.
Расширения также включают поддержку литералов, специфицирующих величины даты и времени, скалярные функции (в соответствии с семантикой, определенной X/Open CLI и ODBC), escape-последовательности для оператора LIKE и синтаксис outer join.
Раздел 12 включает дополнительные соображения, касающиеся специфики конкретных сервров, по сути, разъясняя достаточно "нейтральную" позицию спецификации, в отношении дополнительной поддержки драйверами особенностей серверов по определению и работе с метаданными. Основным моментом здесь является предоставление всей необходимой информации о расширениях через реализацию интерфейса java.sql.DatabaseMetaData (информация о метаданных).
13. Определение интерфейсов JDBC (JDBC Interface Definitions)
Спецификация не включает полного описания JDBC API, адресуя разработчиков к документации по пакету java.sql. Однако в данном разделе дается диаграмма связей между ними (рис. 6) перечисляются все базовые интерфейсы JDBC:
Интерфейсы ядра JDBC:
java.sql.CallableStatement java.sql.Connection java.sql.DataTruncation java.sql.Date java.sql.Driver java.sql.DriverManager java.sql.DriverPropertyInfo java.sql.Numeric java.sql.PreparedStatement java.sql.ResultSet java.sql.SQLException java.sql.SQLWarning java.sql.Statement java.sql.Time java.sql.Timestamp java.sql.Types
java.sql.DatabaseMetaData java.sql.ResultSetMetaData
14. Динамический доступ к базам данных (Dynamic Database Access)
Авторами спецификации отмечается, что, хотя в большинстве случаев разработчики заранее знают схему базы данных (метаданные), существует ряд задач, когда анализ БД происходит "на лету". Именно для такого анализа и предназначены указанные в предыдущем разделе интерфейсы метаданных. Эти интерфейсы могут использоваться в сочетании с интерфейсами ядра JDBC без каких либо конфликтов со стороны менеджера драйверов или самих драйверов. В продолжение раздела 8 определяется соответствие SQL-типов объектам Java для использования методов getObject и setObject для ввода/вывода данных. В качестве примера использования этих методов можно привести следующий вариант уже знакомой последовательности вызовов на чтение данных:
Statement stmt = con.createStatement(); ResultSet res = stmt.executeQuery("SELECT StringColumn,IntColumn FROM MyTable"); while (res.next()) < Object sCol = res.getObject("StringColumn"); Object iCol = res.getObject("IntColumn"); . // анализ реального типа объектов, // их преобразование и использование >
Рисунок 6.
Важнейшие связи между интерфейсами JDBC.
Приложения
Спецификация JDBC включает четыре приложения.
Приложение A освещает некоторые приемы и методы, используемые при разработке JDBC-приложений .
Приложение B представляет собой набор примеров использования JDBC (использование SELECT и UPDATE).
В Приложении C даются краткие замечания по реализации JDBC на примере работы с результирующим набором строк через интерфейс ResultSetMetaData.
Приложение D содержит список последних изменений и дополнений стандарта JDBC.
В заключение, я еще раз попросил бы читателей обратить внимание непосредственно на саму спецификацию JDBC, так как ни одна статья, популяризирующая тот или иной подход (или архитектуру), не заменит документ, подготовленный авторами этого подхода.
Наиболее полную информацию (спецификации, слайд-шоу, примеры, статьи и т.п.) по JDBC и другим технологиям Java читатель может получить на Web-сервере.
Сергей Орлик, Московский офис Borland, тел. 238 - 36 - 11