Использование Excel со связанными серверами SQL Server и распределенными запросами
Microsoft SQL Server поддерживает подключения к другим источникам данных OLE DB (как постоянные, так и прямые). При наличии постоянного подключения сервер называется связанным. Прямое подключение устанавливается для отправки одного запроса (распределенного запроса).
Одним из типов источников данных OLE DB, которые можно запрашивать через SQL Server подобным образом, являются книги Microsoft Excel. В этой статье описан синтаксис, который необходимо использовать при настройке источника данных Excel в качестве связанного сервера, а также синтаксис распределенного запроса к источнику данных Excel.
Дополнительная информация
Запрос источника данных Excel на связанном сервере
Вы можете использовать SQL Server Management Studio или Enterprise Manager, хранимую в системе процедуру, SQL-DMO (Объекты распределенного управления) или SMO (Управляющие объекты SQL Server) для настройки источника данных Excel в качестве связанного сервера SQL Server. (Объекты SMO поддерживаются только в Microsoft SQL Server 2005.) В каждом случае необходимо задать следующие четыре свойства:
- Имя, которое необходимо использовать для связанного сервера.
- Поставщик OLE DB, который будет использоваться для подключения.
- Источник данных или полное имя пути и файла для рабочей книги Excel.
- Строка провайдера, которая идентифицирует цель как рабочую книгу Excel. По умолчанию поставщик Jet ожидает базу данных Access.
Хранимая в системе процедура sp_addlinkedserver также требует свойство @srvproduct, которое может быть любым строковым значением.
Заметка Если вы используете SQL Server 2005, то для свойства Имя продукта в SQL Server Management Studio или для свойства @srvproduct в хранимой процедуре для источника данных Excel необходимо указать значение, которое не должно быть пустым.
Использование SQL Server Management Studio или Enterprise Manager для настройки источника данных Excel в качестве связанного сервера
SQL Server Management Studio (SQL Server 2005)
- В SQL Server Management Studio разверните Серверные объекты в Обозреватель объектов.
- Щелкните правой кнопкой мыши Связанные серверы, а затем щелкните Новый связанный сервер.
- В левой панели выберите страницу Общие, а затем выполните следующие шаги:
- В первом текстовом поле введите любое имя для связанного сервера.
- Выберите опцию Другой источник данных.
- В списке Поставщик выберите Microsoft Jet 4.0 OLE DB Provider.
- В поле Имя продукта введите Excel для имени источника данных OLE DB.
- В поле Источник данных введите полный путь и имя файла Excel.
- В поле Строка поставщика введите Excel 8.0 для рабочей книги Excel 2002, Excel 2000 или Excel 97.
- Нажмите OK, чтобы создать новый связанный сервер.
Примечание В SQL Server Management Studio невозможно развернуть имя нового связанного сервера для просмотра списка объектов, содержащихся на сервере.
Enterprise Manager (SQL Server 2000)
- В менеджере Enterprise Manager щелкните, чтобы развернуть папку Безопасность.
- Щелкните правой кнопкой мыши Связанные серверы, а затем щелкните Новый связанный сервер.
- На вкладке Общие выполните следующие действия:
- В первом текстовом поле введите любое имя для связанного сервера.
- В поле Тип сервера нажмите Другой источник данных.
- В списке Имя поставщика нажмите кнопку Microsoft Jet 4.0 OLE DB Provider.
- В поле Источник данных введите полный путь и имя файла Excel.
- В поле Строка поставщика введите Excel 8.0 для рабочей книги Excel 2002, Excel 2000 или Excel 97.
- Нажмите OK, чтобы создать новый связанный сервер.
Использование хранимой процедуры для настройки источника данных Excel в качестве связанного сервера
Вы также можете использовать хранимую в системе процедуру sp_addlinkedserver для настройки источника данных Excel в качестве связанного сервера:
DECLARE @RC int
DECLARE @server nvarchar(128)
DECLARE @srvproduct nvarchar(128)
DECLARE @provider nvarchar(128)
DECLARE @datasrc nvarchar(4000)
DECLARE @location nvarchar(4000)
DECLARE @provstr nvarchar(4000)
DECLARE @catalog nvarchar(128)
— Set parameter values
SET @server = ‘XLTEST_SP’
SET @srvproduct = ‘Excel’
SET @provider = ‘Microsoft.Jet.OLEDB.4.0’
SET @datasrc = ‘c:\book1.xls’
SET @provstr = ‘Excel 8.0’
EXEC @RC = [master].[dbo].[sp_addlinkedserver] @server, @srvproduct, @provider,
@datasrc, @location, @provstr, @catalogКак уже отмечалось выше, для данной хранимой процедуры требуется дополнительное произвольное значение строки для аргумента @srvproduct, которое отображается в виде «Имени продукта» в конфигурации Enterprise Manager и SQL Server Management Studio. Аргументы @location и @catalog не используются.
Использование SQL-DMO для настройки источника данных Excel в качестве связанного сервера
Объекты распределенного управления SQL можно использовать для настройки источника данных Excel в качестве связанного сервера программно с использованием Microsoft Visual Basic или другого языка программирования. Необходимо указать те же четыре аргумента, которые требуются при настройке через Enterprise Manager и SQL Server Management Studio.
Private Sub Command1_Click()
Dim s As SQLDMO.SQLServer
Dim ls As SQLDMO.LinkedServer
Set s = New SQLDMO.SQLServer
s.Connect «(local)», «sa», «password»
Set ls = New SQLDMO.LinkedServer
With ls
.Name = «XLTEST_DMO»
.ProviderName = «Microsoft.Jet.OLEDB.4.0»
.DataSource = «c:\book1.xls»
.ProviderString = «Excel 8.0»
End With
s.LinkedServers.Add ls
s.Close
End SubИспользование SMO для настройки источника данных Excel в качестве связанного сервера
В SQL Server 2005 можно использовать управляющие объекты SQL Server (SMO) для программной настройки источника данных Excel в качестве связанного сервера. Для этого применяется Microsoft Visual Basic .NET или другой язык программирования. Необходимо указать те же аргументы, которые требуются при настройке через SQL Server Management Studio. Объектная модель SMO расширяет и заменяет объектную модель SQL-DMO. Так как модель SMO совместима с SQL Server 7.0, SQL Server 2000 и SQL Server 2005, ее также можно использовать для настройки SQL Server 2000.
Imports Microsoft.SqlServer.Management.Smo
Imports Microsoft.SqlServer.Management.Common
Public Class Form1
Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click
Dim s As Server
Dim conn As ServerConnection
Dim ls As LinkedServer
conn = New ServerConnection("ServerName\InstanceName", "YourUesrName", "YourPassword")
s = New Server(conn)
Try
ls = New LinkedServer(s, "XLTEST_DMO")
With ls
.ProviderName = "Microsoft.Jet.OLEDB.4.0"
.ProductName = "Excel"
.DataSource = "c:\book1.xls"
.ProviderString = "Excel 8.0"
End With
ls.Create()
MessageBox.Show("New linked Server has been created.")
Catch ex As SmoException
MessageBox.Show(ex.Message)
Finally
ls = Nothing
If s.ConnectionContext.IsOpen = True Then
s.ConnectionContext.Disconnect()
End If
End Try
End Sub
End ClassЗапрос источника данных Excel на связанном сервере
После настройки источника данных Excel в качестве связанного сервера, вы можете легко запросить его данные из Query Analyzer или другого клиентского приложения. Например, чтобы получить строки данных, которые хранятся на листе Sheet1 файла Excel, используйте через SQL-DMO следующий код для настроенного связанного сервера:
SELECT * FROM XLTEST_DMO. Sheet1$
Кроме того, можно использовать OPENQUERY для «транзитного» запроса связанного сервера Excel:
SELECT * FROM OPENQUERY(XLTEST_DMO, ‘SELECT * FROM [Sheet1$]’)
Первый аргумент, который требуется OPENQUERY, — это имя связанного сервера. Чтобы указать имена листов, используйте разделители, как показано выше.
Кроме того, можно получить список всех таблиц, доступных на связанном сервере Excel, с помощью следующего запроса:
EXECUTE SP_TABLES_EX ‘XLTEST_DMO’
Запрос источника данных Excel с помощью распределенных запросов
Можно использовать распределенные запросы SQL Server и функцию OPENDATASOURCE или OPENROWSET для специальных запросов к редко обращающимся источникам данных Excel.
Заметка Если вы используете SQL Server 2005, убедитесь, что вы включили опцию Ad Hoc Distributed Queries, используя Настройка контактной зоны SQL Server, как в следующем примере:
SELECT * FROM OPENDATASOURCE(‘Microsoft.Jet.OLEDB.4.0’,
‘Data Source=c:\book1.xls;Extended Properties=Excel 8.0’). Sheet1$Обратите внимание на необычный синтаксис второго аргумента OPENROWSET («Строка поставщика»):
SELECT * FROM OPENROWSET(‘Microsoft.Jet.OLEDB.4.0’,
‘Excel 8.0;Database=c:\book1.xls’, Sheet1$)Синтаксис, привычный для разработчиков ADO, выглядит следующим образом:
SELECT * FROM OPENROWSET(‘Microsoft.Jet.OLEDB.4.0’,
‘Data Source=c:\book1.xls;Extended Properties=Excel 8.0’, Sheet1$)Этот синтаксис вызывает следующую ошибку поставщика Jet:
Невозможно найти устанавливаемый ISAM.
Примечание Эта ошибка также возникает, если вместо ИсточникДанных ввести Источник данных. Например, следующий аргумент является неправильным:
SELECT * FROM OPENROWSET(‘Microsoft.Jet.OLEDB.4.0’, ‘DataSource=c:\book1.xls;Extended Properties=Excel 8.0’, Sheet1$)
Ссылки
Так как для связанных серверов SQL Server и распределенных запросов используется поставщик OLE DB, учитывайте общие рекомендации и предупреждения, которые относятся к применению ADO с Excel.
Дополнительные сведения см. в следующей статье базы знаний Майкрософт:257819 Как использовать ADO с данными из Visual Basic или VBA в Excel.
Для получения дополнительной информации об управляющих объектах SQL Server (SMO) посетите следующий веб-сайт MSDN:
Access SQL. Основные понятия, лексика и синтаксис
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
- Что такое SQL?
- Основные предложения SQL: SELECT, FROM и WHERE
- Сортировка результатов: предложение ORDER BY
- Работа со сводными данными: предложения GROUP BY и HAVING
- Объединение результатов запроса: оператор UNION
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = ‘Mary’;Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Инструкции SELECT
Чтобы описать набор данных с помощью SQL, необходимо написать инструкцию SELECT. Инструкция SELECT содержит полное описание набора данных, которые необходимо получить из базы данных. К ним относятся файлы со следующими элементами:
- таблицы, в которых содержатся данные;
- связи между данными из разных источников;
- поля или вычисления, на основе которых отбираются данные;
- условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
- необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
Предложение SQL
Обязательное
Определяет поля, которые содержат нужные данные.
Определяет таблицы, которые содержат поля, указанные в предложении SELECT.
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты.
Определяет порядок сортировки результатов.
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение.
Только при наличии таких полей
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение.
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
Сопоставимая часть речи
Определение
Имя, используемое для идентификации объекта базы данных, например имя поля.
глагол или наречие
Ключевое слово, которое представляет действие или изменяет его.
Значение, которое не изменяется, например число или NULL.
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения.
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;- Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
- Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
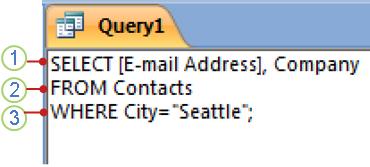
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
- Access SQL. Предложение SELECT
- Access SQL. Предложение FROM
- Access SQL. Предложение WHERE
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY.
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
SQL простыми словами: основы и применение
17 Янв 2020 10:03
 IT GIRL
IT GIRL  18
18Post Views: 4 565
SQL простыми словами: основы и применение Блог 2020-01-17 ru SQL простыми словами: основы и применение
286 104
Boodet Online +7 (499) 649 09 90 123022 , Москва , ул. Рочдельская, дом 15, строение 15
286 104
Boodet Online +7 499 649 09 90 123022 , Москва , ул. Рочдельская, дом 15, строение 15
Поделиться
ПоделитьсяSQL: простыми словами
Аббревиатура « SQL » расшифровывается как «язык структурированных запросов». Это своеобразный язык программирования, предназначенный для того, чтобы извлекать конкретную информацию из баз данных (database) было несложно. Другими словами, это язык баз данных. Зачем нужен SQL , какие там есть команды и чем этот язык лучше других — рассказывают специалисты Boodet.Online.
Зачем нужен SQL
- точность — можно не хранить избыточные данные;
- гибкость — даже самые сложные запросы легко выполнить;
- масштабируемость — с одной БД могут работать множество пользователей;
- безопасность — доступ к данным в таблицах есть только у определенных пользователей.
Из истории
История этого языка началась в конце 70 годов, когда основали компанию Relational Software, Inc. Первым ее продуктом стал Oracle, который написали на C. Чтобы продукт был гибким и простым для тех, кто не изучал программирование, создали внутренний язык — SQL . Авторство принадлежит исследователям IBM Раймонду Бойсу и Дональду Чемберлину. В 1970 SQL назывался «SEQUEL» и служил для извлечения и обработки Big Common Data (больших общих данных).
SQL — это сертифицированный ANSI-язык взаимодействия с реляционными БД. Его можно менять под свои нужды, но все распространенные продукты работают именно на той версии, которую утвердили ANSI.
Как работает SQL
Реляционная база данных — это пространство, в котором связанную информацию хранят в нескольких таблицах. При этом есть возможность запрашивать информацию в нескольких таблицах одновременно.
А теперь о том же самом, но простым языком. Допустим бизнесмен желает видеть информацию о продажах своего товара. Для этого можно настроить электронную таблицу в «Excel» со всей информацией, которую надо отслеживать, в виде отдельных столбцов:
- номер заказа;
- дата;
- сумма к оплате;
- номер накладной;
- имя клиента, адрес и телефон.
Эта сработает, когда заказ от покупателя всего один. А когда их несколько или десятки, сотни? Если продолжать вносить сведения в таблицу Excel, обнаружится, что одинаковая информация (имя, адрес и номер телефона) хранятся в нескольких строках электронной таблицы. Так появляются избыточные данные.
По мере роста бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать место, снизят эффективность этой примитивной системы отслеживания продаж. Также можно столкнуться с проблемами с целостностью данных. Например, нет гарантии, что каждое поле будут заполнять правильным типом информации или что имя и адрес будут вводить каждый раз одинаково.
С реляционной SQL таких проблем не будет. Можно настроить две таблицы: одну — для заказов, вторую — для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого, а также имя, адрес и номер телефона, которые уже отслеживают. Таблица «заказы» будет включать номер заказа, дату, сумму к оплате, номер накладной. А вместо отдельного поля для каждого элемента данных о заказчике будет столбец для «идентификатора клиента».
Это позволит получить всю информацию о клиенте для любого конкретного заказа, но благодаря SQL нужно сохранить ее только один раз, а не выводить повторно для каждого отдельного заказа.
Какие базы SQL существуют
Какими продуктами чаще всего пользуются при работе с БД:
- Oracle Database. Помимо основных функций, Oracle Database автоматизирует управление серверами и данными. Совместим с тремя основными операционными системами: MacOS, Windows и Linux.
- MySQL. Эта БД с открытым исходным кодом, разработана Oracle. Ей пользуются такие крупные бренды, как Facebook, Adobe и Google. MySQL бесплатен как для юридических, так и для частных лиц.
- Microsoft SQL. Реляционная БД, идеально совместимая с операционными системами Linux и Windows. Она идеально подходит для веб-серверов под управлением Windows, а также для потребительского софта.
- Amazon Relational Database Service (RDS). Облачная реляционная СУБД, простая в настройке и использовании. Есть инструменты бюджетирования облака, безопасности и мониторинга.
Структура SQL-запросов
Язык SQL очень простой. Он состоит из команд для выполнения различных функций. Эти функции включают в себя:
- создание объектов;
- манипулирование объектами;
- заполнение таблиц;
- обновление таблиц;
- удаление данных;
- выполнение запросов;
- управление доступом и общее администрирование.
Чтобы любому человеку было проще ориентироваться, SQL состоит из нескольких основных подгрупп.
Для определения данных (DDL)
Для манипулирования данными (DML)
Триггеры
Триггеры — это действия, которые делаются при выполнении определенных условий. Любой триггер состоит из трех частей:
- событие — изменение, которое он активирует;
- состояние — запрос или тест, который выполняется при активации;
- действие — процедура, выполняемая при срабатывании триггера и выполнении условия.
Технология клиент-сервер и удаленный доступ
Технология клиент-сервер поддерживает отношения «многие-к-одному» клиентов (многие) и сервера (один). В SQL есть команды, которые управляют тем, как клиентское приложение может получить доступ к d atabase по сети.
Безопасность и аутентификация
SQL предоставляет механизм для управления БД. То есть, он гарантирует, что пользователю будет показана только конкретная информация, а исходная версия будет защищена СУБД.
Встроенный SQL
SQL предоставляет возможность встраивания основных языков, таких как C, COBOL, Java, для запросов от них во время выполнения.
Управление транзакциями
Транзакции — это важный элементом СУБД. Для управления ими используется TCL, который имеет команды:
- Commit;
- RollBack;
- Savepoint.
Расширенный SQL
Расширенный SQL включает в себя такие запросы, как рекурсивные, поддержки принятия решений, интеллектуальный анализ данных, пространственные данные и XML (eXtensible Markup Language).
Как используется SQL
Почему многие выбирают именно SQL :
- простые запросы можно использовать для очень быстрого и эффективного извлечения большого объема данных из СУБД;
- SQL легко изучить, почти каждая СУБД поддерживает;
- управлять СУБД с помощью SQL несложно, поскольку не требуется большого количества кода.
SQL и Big Data
В настоящее время существует тенденция аккумулирования больших объемов данных. Феномен Big Data требует наличия набора навыков, чтобы обрабатывать и извлекать информацию в любой области — медицина, образование, бизнес, спорт и т.д. На основании анализа Big Data принимают стратегические и обоснованные решения, которые могут повысить прибыль компаний и решить реальные проблемы. Например, с помощью SQL разрабатывают модели, которые делают общественный транспорт простым и удобным. Это язык, которые используется практически в любой сфере жизни человека, решает реальные проблемы и помогает создавать новые технологии.
SQL позволяет изучить набор данных, визуализировать его, определить структуру и узнать, как на самом деле он выглядит. Это помогает узнать, есть ли какие-либо пропущенные значения. Благодаря нарезке, фильтрации, агрегации и сортировке SQL позволяет понять, как распределяются значения и как организован набор Data.
Подключение клиентских приложений
SQL эффективен для организации доступа к данным, при запросах и манипуляциях. Но он ограничен в визуализации. Как это решить? Он хорошо интегрируется с другими языками сценариев, например, R и Python.
Кроме того, специализированные библиотеки интеграций для SQL , такие как SQLite и MySQLdb, применяют при подключении клиентского приложения к ядру базы данных, что позволяет работать с СУБД совместно.
Чем открыть SQL-файл
Прежде чем открыть SQL -файл, спросите себя, зачем вам это. Если вы пользуетесь СУБД, все уже настроено и работает. Например, когда вы выбираете песню на айпаде, вы фактически делаете запрос на определенный набор данных из базы.
Если вы хотите просто посмотреть, что внутри SQL -файла, можно воспользоваться обычным текстовым редактором («Блокнот» для Windows или TextEdit для Mac). В этих программах можно не только посмотреть, но и вручную отредактировать сценарий. Прежде чем что-нибудь открывать и менять, рекомендуем сделать копию исходного файла. Если нужно потренироваться в работе с SQL , арендуйте безопасное облачное пространство.
Что такое SQL: как устроен, зачем нужен и как с ним работать
Рассказываем о языке, на котором «говорят» большинство баз данных.

Иллюстрация: Оля Ежак для Skillbox Media

Иван Стуков
Журналист, изучает Python. Любит разбираться в мелочах, общаться с людьми и понимать их.Вся информация, с которой вы сталкиваетесь в интернете, содержится в базах данных. В них же хранятся данные о сотрудниках и клиентах крупных компаний, научных и социологических исследованиях, расписании рейсов ближайшего к вам аэропорта и много о чём ещё.
Работать с этими циклопическими массивами информации вручную было бы долго, муторно и непродуктивно. Поэтому придумали SQL — специальный язык для общения с БД.
Что такое SQL
SQL (Structured Query Language, или язык структурированных запросов) — это декларативный язык программирования (язык запросов), который используют для создания, обработки и хранения данных в реляционных БД.
На чистом SQL нельзя написать программу — он предназначен только для взаимодействия с базами данных: получения, добавления, изменения и удаления информации в них, управления доступом и так далее.
Поэтому перед изучением SQL нужно разобраться, как устроены базы данных.
В каких базах данных используют SQL
Все БД можно поделить на два вида: реляционные и нереляционные. Язык SQL нужен для работы с первыми.
SQL настолько тесно связан с реляционными БД, что все нереляционные БД в противовес стали называть NoSQL. Вот и получилось, что SQL — это язык программирования, а NoSQL — тип баз данных.
Про реляционные БД часто говорят, что это набор двумерных таблиц. Прямо как в Excel: со столбцами, строками и ячейками. Это понятная визуализация, хотя и не совсем точная.
Представим, что мы создаём базу данных для небольшой строительной фирмы. Она проектирует загородные дома и передаёт проекты подрядчикам, которые занимаются самим строительством:

Чем же база данных отличается от таблицы? Тем, что в базе:
- У столбцов и строк нет определённого положения. Нельзя сказать, что столбец status находится до или после столбца num_floors, а имя Анастасии Романиной — до или после имени Дмитрия Пожарова.
- Каждый столбец диктует свой домен, то есть тип данных, к которому могут относиться его значения. Например, в столбцах cost и num_floors могут храниться только числа, а в столбце client — только строки.
- Каждая строка должна быть уникальной и не может повторять какую-то другую строку.
Из-за этих отличий применительно к базам данных используют другую терминологию. Столбец называется атрибутом, строка — записью или кортежем, а сама БД — их отношением друг к другу.
Нормализация в реляционных базах данных
Вернёмся к БД нашей строительной фирмы. Она может казаться удобной, но на самом деле не лишена недостатков.
Возьмём дом, который строится для Марии Медичиной. Сейчас он только проектируется, и мы ещё не выбрали для него подрядчика. Поэтому значение атрибута contractor равно NULL, то есть поле пустое. Но рано или поздно мы выберем подрядчика — например, ООО «Коттеджи». Тогда, кроме имени подрядчика, нам нужно будет заново указать его телефон. Сейчас значение этого атрибута тоже NULL. Пока что сделать это несложно.
В реальной же базе данных о подрядчике будет храниться гораздо больше информации: адрес, почта, ИНН, банковские реквизиты и так далее. Чтобы каждый раз переписывать всю эту информацию, придётся делать много лишних движений — а это не наш метод.
Если подрядчик вдруг сменит номер телефона, во всех старых записях останется устаревшая информация. А таких записей могут быть сотни и тысячи (если наша компания станет совсем успешной). Ровно та же ситуация с данными клиентов. Уследить за таким числом нюансов проблемно, и наша БД рискует превратиться в хранилище фейков.
Чтобы этого не происходило, в реляционных БД используют нормализацию. Это когда одну таблицу разбивают (декомпозируют) на несколько, а каждой записи присваивают уникальный ключ, по которому её можно идентифицировать.
Всего существует шесть нормальных форм. Чем выше номер формы, тем большему количеству правил она должна подчиняться. Приведём базу данных нашей строительной фирмы в соответствие с третьей нормальной формой.
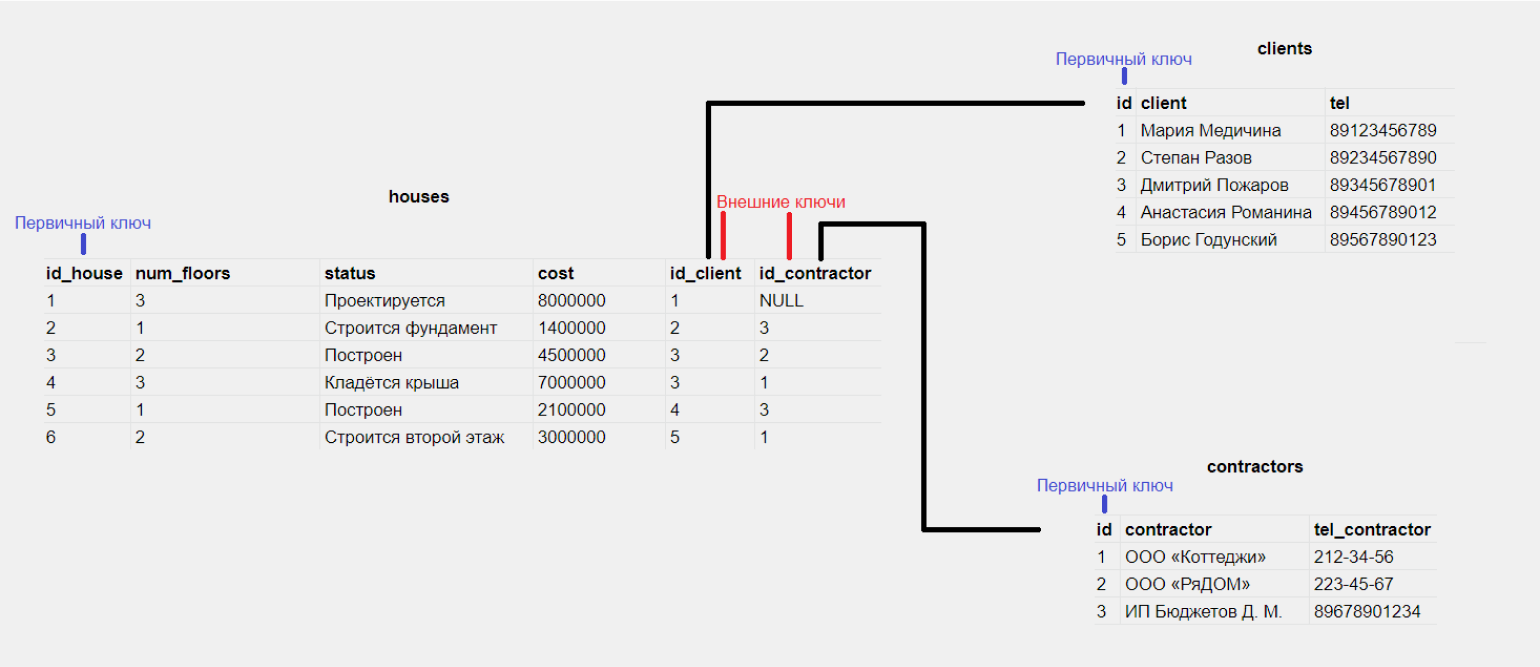
Теперь, если у любого клиента или подрядчика сменится телефон, нужно будет внести изменения всего один раз. Добавлять новые записи теперь тоже будет проще.
Таблицы связывают между собой ключами. Они бывают трёх видов.
Первичный — указывает на запись, к которой он относится. В одном отношении не может быть нескольких записей с одним и тем же первичным ключом, и значение первичного ключа не может быть NULL. Первичным ключом может быть любое уникальное значение. Например, в таблице contractors так можно было бы использовать ИНН, если б он был в нашей базе.
Внешний — содержит ссылку на первичный ключ из другой таблицы и привязывает одну таблицу к другой.
Родительский — это первичный ключ, на который ссылается внешний ключ.
Язык программирования SQL: как управлять базами данных
Ещё одно отличие реляционных БД от обычных таблиц — в них нельзя вносить изменения напрямую. Для этого нужны СУБД, или системы управления базами данных.
СУБД — это посредник, который получает от пользователя команды, что сделать с базой данных, и выполняет их. Эти-то команды и написаны на языке SQL.
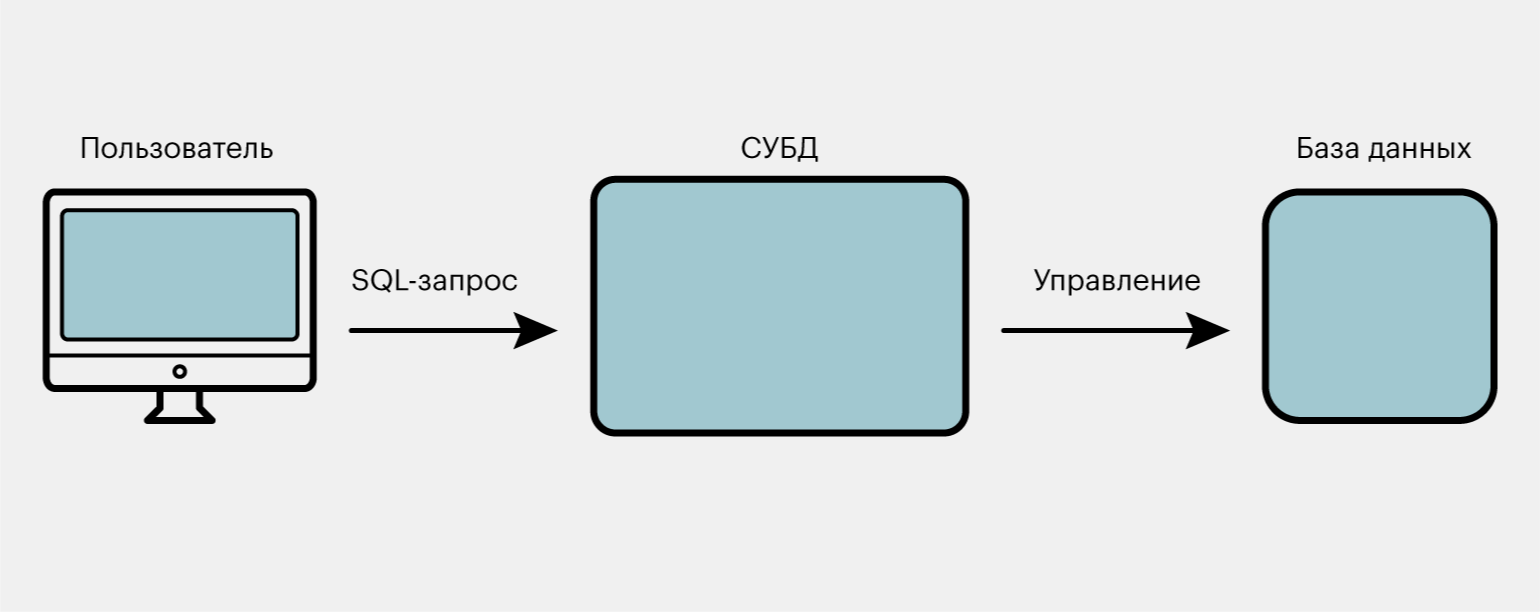
SQL — декларативный язык. Это значит, что при написании кода мы говорим, что хотим получить от программы. Логика того, как именно СУБД будет выполнять поставленную задачу, скрыта от нас.
Конечно, если вы хотите сделать свои запросы более быстрыми и эффективными или обезопасить базы данных, знать алгоритмы СУБД полезно. Но даже не разбираясь в этих тонкостях, вы сможете писать на SQL.
Все SQL-команды делятся на четыре вида:
- DDL (Data Definition Language, или язык описания данных). Их используют, чтобы создавать, изменять и удалять целые таблицы.
- DML (Data Manipulation Language, или язык управления данными). Их применяют к содержимому таблиц, чтобы создавать, изменять, удалять атрибуты и записи. Если нужно получить какую-то информацию из базы данных, то пользуются именно DML-операторами.
- DCL (Data Control Language, или язык контроля данных). Они нужны, чтобы выдавать конкретным пользователям доступ к базам данных и отзывать его.
- TCL (Transaction Control Language, или язык контроля транзакций). Позволяет управлять транзакциями. Транзакция — это набор из нескольких команд, которые выполняются поочерёдно. Если одна из команд внутри транзакции не срабатывает, то все уже совершённые действия отменяются. То есть транзакция может быть совершена либо полностью, либо никак.
Где применяют SQL
В индексе TOPDB популярность СУБД определяется по тому, как часто их гуглят. В декабре 2022 года первые пять мест в нём занимают именно реляционные СУБД — вместе они дают больше 70% поисковых запросов.
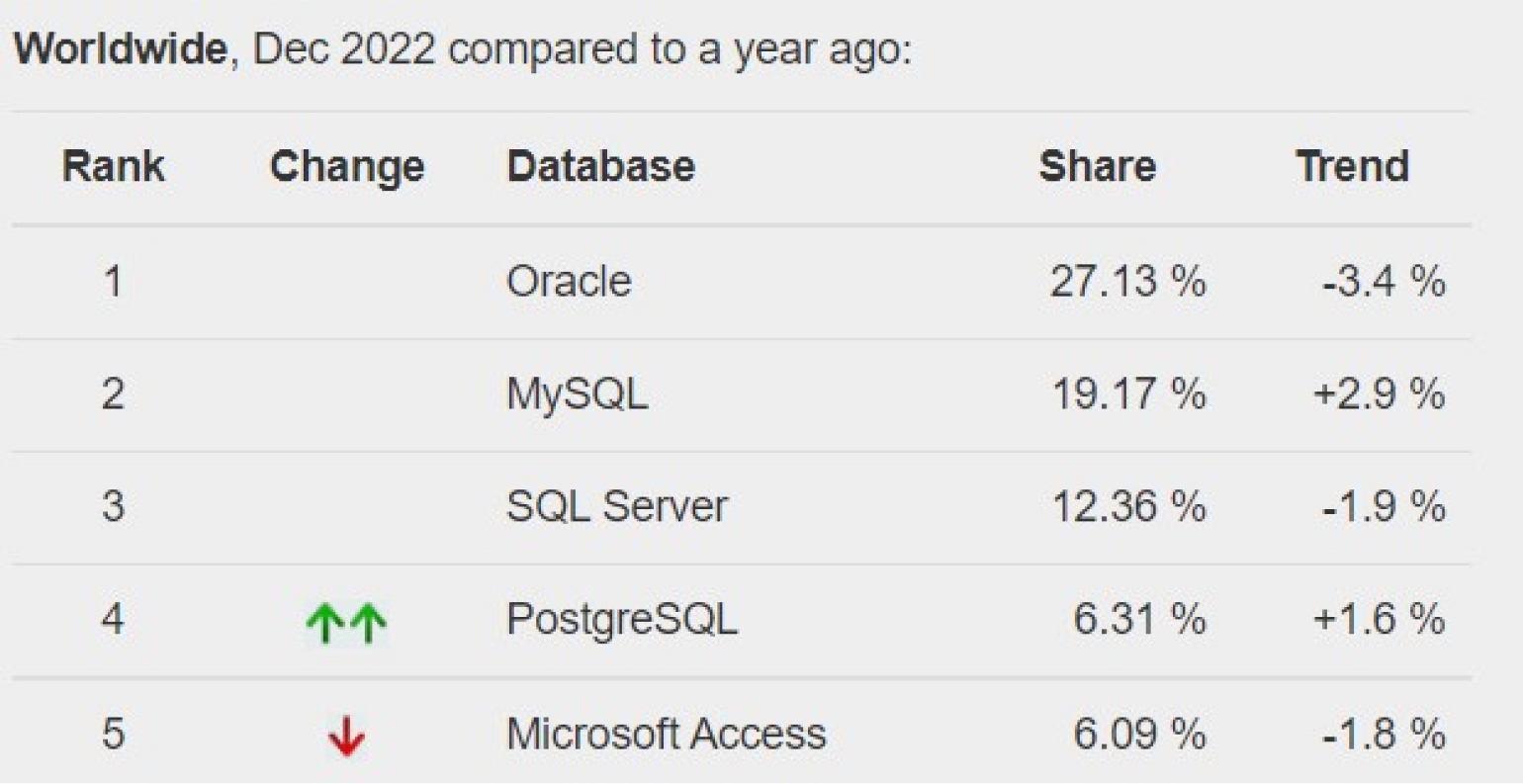
Рейтинг DB-Engines даёт похожие цифры. В декабре 2022 года доля реляционных СУБД составляет 71,7%.
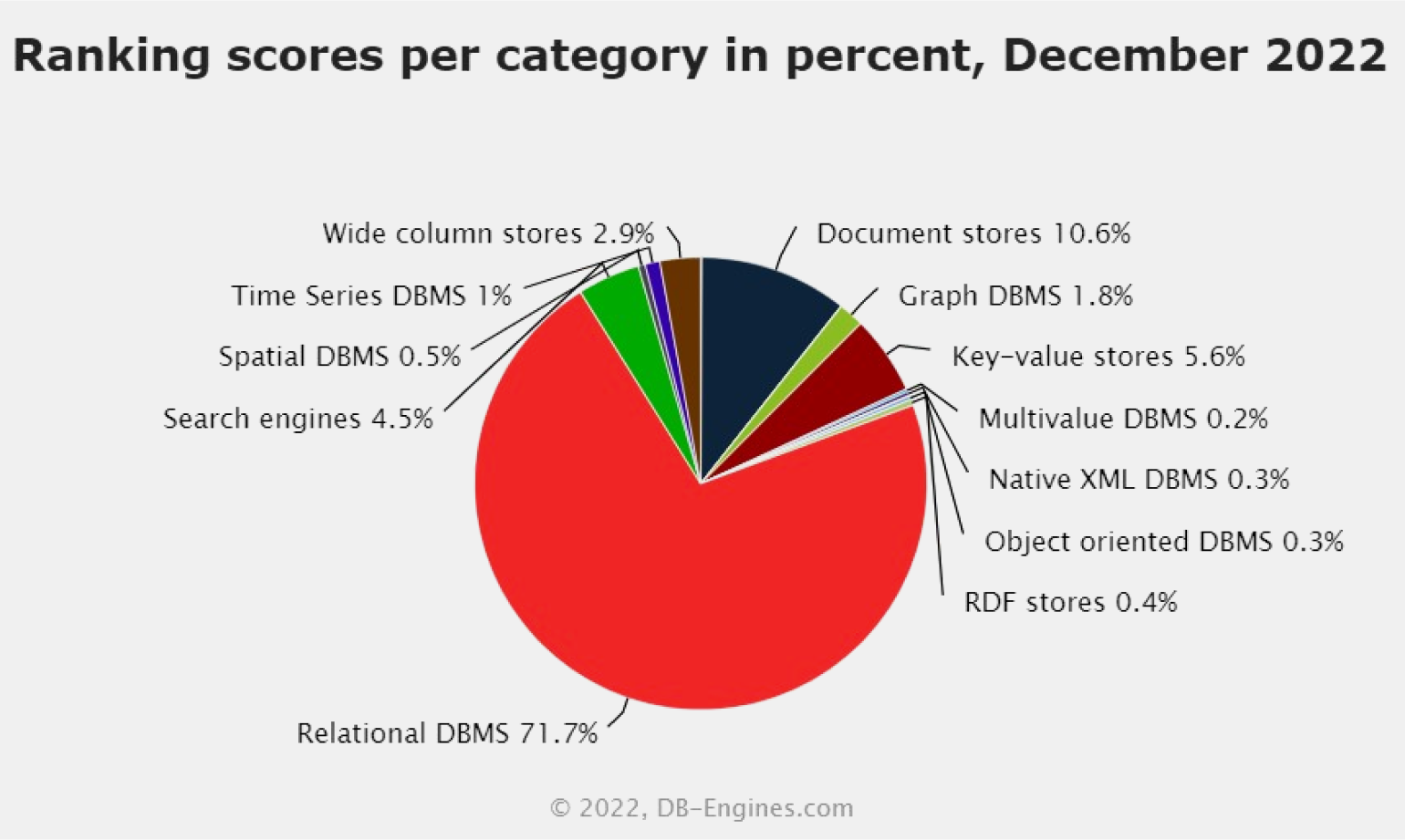
Без баз данных не будет ни сайтов, ни сетевых приложений, ни крупных информационных систем — нужно же где-то хранить всю информацию. При этом реляционных БД — большинство, а чтобы управлять ими, нужен SQL. Поэтому мало какая вакансия бэкенд-разработчика обходится без требования владеть SQL. По крайней мере, мы такой не нашли.
Но умение работать с базами данных пригодится не только программисту.
Аналитики данных напрямую работают с «сырой» информацией. Чем лучше и свободнее они общаются с БД, тем проще им добывать и обрабатывать нужные данные в нужном виде.
Маркетологам SQL тоже будет полезен для решения аналитических задач.
Тестировщикам понадобится обращаться к БД, потому что это важный компонент любого информационного продукта.
Руководители, менеджеры и бизнес-консультанты благодаря информации из БД смогут лучше понимать, как функционирует их бизнес, и принимать более взвешенные решения.
Как работать с SQL: основные операторы
Запросы в SQL похожи на естественный английский язык и выглядят как полноценные предложения.
Например, если мы захотим в базе данных нашей строительной фирмы получить номер телефона ООО «Коттеджи», нам нужно написать такую команду:

Также в SQL существуют агрегатные функции. Они позволяют производить с данными дополнительные операции и указываются вместо атрибутов. Агрегатные функции записываются в формате FUNCTION(ATTRIBUTE).
Вот некоторые из них.
COUNT — считает количество записей в колонке.
SUM — складывает содержимое значений колонки.
MIN — указывает на минимальное значение в колонке.
MAX — указывает на максимальное значение в колонке.
AVG — считает среднее значение в колонке.
ROUND — округляет значение в колонке.
Для работы с инструкциями, которые содержат агрегатные функции, есть специальные операторы.
GROUP BY — группирует выходные значения для колонок, к которым применили агрегатную функцию.
HAVING — работает как WHERE, но может применяться к агрегатным функциям.
Конечно, это далеко не все операторы, функции и ключевые слова, которые есть в SQL. Но уже этот набор даёт широкие возможности для работы с базами данных.
Что запомнить
- SQL — это язык программирования для работы с реляционными базами данных.
- Самые распространённые базы данных — реляционные. Их можно представить как набор двумерных таблиц, связанных друг с другом ключами.
- SQL обращается к базам данных не напрямую, а через системы управления базами данных, илиСУБД.
- Производители СУБД пишут для языка SQL собственные расширения — диалекты. Но базовый синтаксис у всех них одинаковый.
- SQL-запросы состоят из операторов и складываются в полноценные предложения, которые похожи на естественный английский язык.
Больше интересного про код в нашем телеграм-канале. Подписывайтесь!