Как git хранит данные
Эта глава более подробно описывает как Git физически хранит объекты.
Все объекты хранятся в сжатом виде по имени их sha значения. Они содержат тип объекта, размер и содержимое в формате gzipped.
Существуют два формата в которых Git хранит объекты — свободные и сжатые.
Свободные Objects
Свободные объекты это простейший формат. Это просто сжатые данные сохраненные в файл на диске. Каждый объект записывается в отдельный файл.
Если sha значение вашего объекта ab04d884140f7b0cf8bbf86d6883869f16a46f65 , то файл будет храниться по след. пути:
GIT_DIR/objects/ab/04d884140f7b0cf8bbf86d6883869f16a46f65 Git отсекает два первых символа и использует их как поддиректорию, таким образом никогда не бывает очень много объектов в одной директории. Имя файла в действительности состоит из оставшихся 38 символов.
Простейший способ описать в точности как хранятся данные, это показать реализацию на Ruby хранилища объекта:
def put_raw_object(content, type) size = content.length.to_s header = "#type> #size>\0" # type(space)size(null byte) store = header + content sha1 = Digest::SHA1.hexdigest(store) path = @git_dir + '/' + sha1[0. 2] + '/' + sha1[2..40] if !File.exists?(path) content = Zlib::Deflate.deflate(store) FileUtils.mkdir_p(@directory+'/'+sha1[0. 2]) File.open(path, 'w') do |f| f.write content end end return sha1 end
Сжатые объекты
Другой формат хранения объектов это пакфайлы, Так как Git хранит каждую версию файла как отдельный объект, то это способ будет не очень эффективным. Представьте что у вас есть файл в несколько тысяч строк и изменяется всего лишь одна строка. Git сохранит второй файл не полностью, что было бы расточительством дискового пространства.
Чтобы сохранить это пространство, Git использует пакфайлы. Это формат, в котором Git сохранит только измененную часть второго файла, и указатель на первый оригинальный файл.
Когда объекты записываются на диск, чаще это свободный формат, так как этот формат менее затратный. Тем не менее, со временем вам потребуется сохранить дисковое простанство упаковывая объекты — это выполняется командой git gc. Эта команда использует специальный алгоритм чтобы определить какие файлы похожи в наибольшей степени. Могут существовать и составные пакфайлы, они могут быть перепакованы если это необходимо (git repack) или легко распакованы обратно в свободный формат (git unpack-objects).
Git также запишет индекс файл для каждого пакфайла который значительно меньше и содержит смещения в пакфайле, чтобы можно было еще быстрее найти определенные объекты по их sha значению.
Подробности реализации пакофайлов могут быть найдены в главе Пакфайлы которая будет несколько позже.
This book is maintained by Scott Chacon, and hosting is donated by GitHub.
Please email me at schacon@gmail.com with patches, suggestions and comments.
Как гит хранит историю? И как ее чистить?
Сегодня пришлось задуматься о том, как гит хранит историю? Вопрос очень простой, скажем я создал проект, сложил в него очень тяжелые файлы(2 гб) и сделал коммит. Потом я эти файлы удалил и у меня и сделал еще коммит. Но я могу вернуться на предыдущий коммит и получить эти файлы обратно, верно? Значит из этого следует, что при удалении файлов, гит все равно хранит их копии, а значит вес проекта (самой папки) и занимаемое ей место при удалении тяжелых файлов не уменьшиться? Но мне почему то не кажется, что когда я делаю клон ветки прокта, что я получаю всю историю (скажем прошлые коммиты и тяжелые файлы 2гб в нашем примере) во всяком случае локально в файлах на компе их нет. Но ведь история коммитов у меня есть, а значит и все файлы должны быть сохранены(как то, где то). Короче, что то тут не сходиться. Вопрос в том, действительно ли храняться все копии файлов? А если проекту 10 лет и за это время уже миллион файлов(и их вес) были удалены они, что до сих пор где то в гите храняться?
Отслеживать
задан 31 июл 2019 в 6:59
11k 18 18 золотых знаков 64 64 серебряных знака 128 128 бронзовых знаков
Гит хранит всё. Вся история (если специально не заморачиваться) есть в папке .git , но данные сжимаются и всячески оптимизируются, поэтому вы и не можете найти там свой файл.
31 июл 2019 в 7:10
А вообще ответ на вопрос в заголовке отлично находится гуглом
31 июл 2019 в 7:12
Есть хороший цикл статей о внутреннем устройстве git. Вот его компиляция на opennet: opennet.ru/base/dev/git_guts.txt.html
31 июл 2019 в 12:29
Вам бы понять разницу в инфинитивах возвратных глаголов в русском языке. А по теме, в индексе всё есть. Git компрессирует файлы, а также умеет работать со sparse-файлами, если я правильно помню.
6 авг 2019 в 19:39
Для удаления совсем старых и точно ненужных вещей (когда-то по ошибке впушенных бинарников, например) можно использовать BFG Repo-Cleaner: rtyley.github.io/bfg-repo-cleaner
– user177221
6 авг 2019 в 19:59
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Гит все равно хранит их копии, а значит вес проекта (самой папки) и занимаемое ей место при удалении тяжелых файлов не уменьшиться
Да, верно. Проверим:
# так смотрим размер каталога .git du -hs .git # так можно сделать файл 1Мб dd if=/dev/zero of=filename bs=1M count=1 - пустой проект 104 Кб
- после коммита файла filename в 1Мб вес .git 164 Кб (гит сжимает данные)
- после удаления файла filename и коммита — 180 Кб
Но мне почему то не кажется, что когда я делаю клон ветки прокта, что я получаю всю историю
Это вам только кажется
А если проекту 10 лет и за это время уже миллион файлов(и их вес) были удалены они, что до сих пор где то в гите храняться?
Как можно уменьшить размер .git каталога:
- запустить git gc —aggressive , но он пропылесосит только ненужные файлы, и пережмет данные, но файл filename так и останется в репо, но место освободилось: стало 152Кб
- переписать историю через git rebase : что-то удалить, что-то слить
- выкачивать репо без всей истории: git clone —depth 1 . скачает историю на глубину 1
Для хранения больших файлов (мультимедиа) лучше использовать Git Large File Storage
git gc
Это служебная команда оптимизации «базы данных гита». Какие-то объекты в этой базе становятся недостижимыми (столкнетесь при большем погружении в гит, они появляются при «переписывании истории») — они удаляются. Данные пережимаются, ведь индекс в процессе эксплуатации становится не совсем оптимальным, вот он и «перестраивается». С самим репозиторием, как это видно «внешне», при вызове git gc ничего не происходит, вся история остается на месте.
если я локально чищу .git, то синхронизируются ли эти изменения с удаленным репо?
- через git gc — нет, эта команда для локального применения, она оптимизирует локальный репо, смысла делать ее перед push совершенно нет, удаленный репо имеет «свой мусор», и чистить удаленный репо можно только путем захода на удаленный сервер и запуска git gc в bare-репо
- если вы комитили, комитили, и наконец, перед push (это крайне важно. ) решили сократить размер репо — используйте git rebase : путем объединения коммитов вы «почтистите историю» (в первом коммите огромный файл был, а во втором его удалили) — при пуше в удаленный репо этот огромный файл передаваться не будет, это главное. А в локальном репо размер .git после rebase вырастет — на «историю rebase». И тот огромный файл в каталоге .git также останется в виде сжатого объекта, хотя и недоступного (так как вы поменяли историю). А вот запуск git gc теперь удалит из .git этот файл и из вашего локального репо
правда я так понимаю, что они не идентичны так как удалено находится bare repo
Правильно понимаете. А для распределённой системы управления версиями, которой является git, «клонированный» может быть точь-в-точь как «удаленный» только в момент клонирования. Дальше, по мере появления коммитов, на уровне байтов они начинают расходиться все больше. История может и будет совпдать, но каталог .git — нет. По сути .git — это база данных, и работать с ней нужно как с базой данных, а не на уровне файлов и байтов. git gc искусственно запускать также не нужно, git сам предложит это сделать, когда начнет работать медленно, и даже будет делать это самостоятельно, если стоит опция gc.auto 1 .
Глава 9. Раскрываем тайны
Мы заглянем под капот и объясним, как Git творит свои чудеса. Я опущу излишние детали. За более детальными описаниями обратитесь к руководству пользователя.
Невидимость
Как Git может быть таким ненавязчивым? За исключением периодических коммитов и слияний, вы можете работать так, как будто и не подозреваете о каком-то управлении версиями. Так происходит до того момента, когда Git вам понадобится, и тогда вы с радостью увидите, что он наблюдал за вами все это время.
Другие системы управления версиями вынуждают вас постоянно бороться с загородками и бюрократией. Файлы могут быть доступны только для чтения, пока вы явно не укажете центральному серверу, какие файлы вы намереваетесь редактировать. С увеличением количества пользователей большинство базовых команд начинают выполняться всё медленнее. Неполадки с сетью или с центральным сервером полностью останавливают работу.
В противоположность этому, Git просто хранит историю проекта в подкаталоге .git вашего рабочего каталога. Это ваша личная копия истории, поэтому вы можете оставаться вне сети, пока не захотите взаимодействовать с остальными. У вас есть полный контроль над судьбой ваших файлов, поскольку Git в любое время может легко восстановить сохраненное состояние из .git.
Целостность
Большинство людей ассоциируют криптографию с содержанием информации в секрете, но другой столь же важной задачей является содержание ее в сохранности. Правильное использование криптографических хеш-функций может предотвратить случайное или злонамеренное повреждение данных.
SHA1 хеш можно рассматривать как уникальный 160-битный идентификатор для каждой строки байт, с которой вы сталкиваетесь в вашей жизни. Даже больше того: для каждой строки байтов, которую любой человек когда-либо будет использовать в течение многих жизней.
Так как SHA1 хеш сам является последовательностью байтов, мы можем получить хеш строки байтов, содержащей другие хеши. Это простое наблюдение на удивление полезно: ищите «hash chains» (цепочки хешей). Позднее мы увидим, как Git использует их для эффективного обеспечения целостности данных.
Говоря кратко, Git хранит ваши данные в подкаталоге «.git/objects», где вместо нормальных имен файлов вы найдете только идентификаторы. Благодаря использованию идентификаторов в качестве имен файлов, а также некоторым хитростям с файлами блокировок и временны́ми метками, Git преобразует любую скромную файловую систему в эффективную и надежную базу данных.
Интеллект
Как Git узнаёт, что вы переименовали файл, даже если вы никогда не упоминали об этом явно? Конечно, вы можете запустить git mv ; но это то же самое, что git rm , а затем git add .
Git эвристически находит файлы, которые были переименованы или скопированы между соседними версиями. На деле он может обнаружить, что участки кода были перемещены или скопированы между файлами! Хотя Git не может охватить все случаи, он всё же делает достойную работу, и эта функция постоянно улучшается. Если она не сработала, попробуйте опции, включающие более ресурсоемкое обнаружение копирования и подумайте об обновлении.
Индексация
Для каждого отслеживаемого файла, Git записывает такую информацию, как размер, время создания и время последнего изменения, в файле, известном как «индекс». Чтобы определить, был ли файл изменен, Git сравнивает его текущие характеристики с сохраненными в индексе. Если они совпадают, то Git не станет перечитывать файл заново.
Поскольку считывание этой информации значительно быстрее, чем чтение всего файла, то если вы редактировали лишь несколько файлов, Git может обновить свой индекс почти мгновенно.
Мы отмечали ранее, что индекс это буферная зона. Почему набор свойств файлов выступает таким буфером? Потому что команда add помещает файлы в базу данных Git и в соответствии с этим обновляет эти свойства; тогда как команда commit без опций создает коммит, основанный только на этих свойствах и файлах, которые уже в базе данных.
Происхождение Git
Это сообщение в почтовой рассылке ядра Linux описывает последовательность событий, которые привели к появлению Git. Весь этот тред — привлекательный археологический раскоп для историков Git.
База данных объектов
Каждая версия ваших данных хранится в «базе данных объектов», живущей в подкаталоге .git/objects. Другие «жители» .git/ содержат вторичные данные: индекс, имена веток, теги, параметры настройки, журналы, нынешнее расположение «головного» коммита и так далее. База объектов проста и элегантна, и в ней источник силы Git.
Каждый файл внутри .git/objects это «объект». Нас интересуют три типа объектов: объекты «блобов», объекты деревьев и объекты коммитов.
Блобы
Для начала один фокус. Выберите имя файла — любое имя файла. В пустом каталоге:
$ echo sweet > ВАШЕ_ИМЯ_ФАЙЛА $ git init $ git add . $ find .git/objects -type f
Вы увидите .git/objects/aa/823728ea7d592acc69b36875a482cdf3fd5c8d .
Откуда я знаю это, не зная имени файла? Это потому, что SHA1 хеш строки
«blob» SP «6» NUL «sweet» LF
равен aa823728ea7d592acc69b36875a482cdf3fd5c8d, где SP это пробел, NUL — нулевой байт и LF — перевод строки. Вы можете проверить это, набрав
$ printf "blob 6\000sweet\n" | sha1sum
Git использует «адресацию по содержимому»: файлы хранятся в соответствии не с именами, а с хешами содержимого, — в файле, который мы называем «блоб-объектом». Хеш можно понимать как уникальный идентификатор содержимого файла, что означает обращение к файлам по их содержимому. Начальный «blob 6» — лишь заголовок, состоящий из типа объекта и его длины в байтах и упрощающий внутренний учет.
Таким образом, я могу легко предсказать, что вы увидите. Имя файла не имеет значения: для создания блоб-объекта используется только его содержимое.
Вам может быть интересно, что происходит с одинаковыми файлами. Попробуйте добавить копии своего файла с какими угодно именами. Содержание .git/objects останется тем же независимо от того, сколько копий вы добавите. Git хранит данные лишь единожды.
Кстати, файлы в каталоге .git/objects сжимаются с помощью zlib поэтому вы не сможете просмотреть их напрямую. Пропустите их через фильтр zpipe -d, или введите
$ git cat-file -p aa823728ea7d592acc69b36875a482cdf3fd5c8d
что выведет указанный объект в читаемом виде.
Деревья
Но где же имена файлов? Они должны храниться на каком-то уровне. Git обращается за именами во время коммита:
$ git commit # Введите какое-нибудь описание $ find .git/objects -type f
Теперь вы должны увидеть три объекта. На этот раз я не могу сказать вам, что из себя представляют два новых файла, так как это частично зависит от выбранного вами имени файла. Далее будем предполагать, что вы назвали его «rose». Если это не так, то вы можете переписать историю, чтобы она выглядела как будто вы это сделали:
$ git filter-branch --tree-filter 'mv ВАШЕ_ИМЯ_ФАЙЛА rose' $ find .git/objects -type f
Теперь вы должны увидеть файл .git/objects/05/b217bb859794d08bb9e4f7f04cbda4b207fbe9 , так как это SHA1 хеш его содержимого:
«tree» SP «32» NUL «100644 rose» NUL 0xaa823728ea7d592acc69b36875a482cdf3fd5c8d
Проверьте, что этот файл действительно содержит указанную строку, набрав
$ echo 05b217bb859794d08bb9e4f7f04cbda4b207fbe9 | git cat-file --batch
С zpipe легко проверить хеш:
$ zpipe -d < .git/objects/05/b217bb859794d08bb9e4f7f04cbda4b207fbe9 | sha1sum
Проверка хеша с помощью cat-file сложнее, поскольку ее вывод содержит не только «сырой» распакованный файл объекта.
Этот файл — объект «дерево» (tree, прим. пер.): список цепочек, состоящих из типа, имени файла и его хеша. В нашем примере: тип файла — 100644, что означает, что «rose» это обычный файл; а хеш — блоб-объект, в котором находится содержимое «rose». Другие возможные типы файлов: исполняемые файлы, символические ссылки или каталоги. В последнем случае, хеш указывает на объект «дерево».
Если вы запускали filter-branch, у вас есть старые объекты которые вам больше не нужны. Хотя по окончании срока хранения они будут выброшены автоматически, мы удалим их сейчас, чтобы было легче следить за нашим игрушечным примером:
$ rm -r .git/refs/original $ git reflog expire --expire=now --all $ git prune
Для реальных проектов обычно лучше избегать таких команд, поскольку вы уничтожаете резервные копии. Если вы хотите иметь чистое хранилище, то обычно лучше сделать свежий клон. Кроме того, будьте осторожны при непосредственном вмешательстве в каталог .git : что если другая команда Git работает в это же время, или внезапно произойдет отключение питания? Вообще говоря, ссылки нужно удалять с помощью git update-ref -d , хотя обычно ручное удаление refs/original безопасно.
Коммиты
Мы рассмотрели два из трех объектов. Третий объект — «коммит» (commit). Его содержимое зависит от описания коммита, как и от даты и времени его создания. Для соответстия тому, что мы имеем, мы должны немного «подкрутить» Git:
$ git commit --amend -m Shakespeare # Изменим описание коммита. $ git filter-branch --env-filter 'export GIT_AUTHOR_DATE="Fri 13 Feb 2009 15:31:30 -0800" GIT_AUTHOR_NAME="Alice" GIT_AUTHOR_EMAIL="alice@example.com" GIT_COMMITTER_DATE="Fri, 13 Feb 2009 15:31:30 -0800" GIT_COMMITTER_NAME="Bob" GIT_COMMITTER_EMAIL="bob@example.com"' # Подделаем временные метки и авторов. $ find .git/objects -type f
Теперь вы должны увидеть .git/objects/49/993fe130c4b3bf24857a15d7969c396b7bc187 который является SHA1 хешем его содержимого:
«commit 158» NUL «tree 05b217bb859794d08bb9e4f7f04cbda4b207fbe9» LF «author Alice 1234567890 -0800» LF «committer Bob 1234567890 -0800» LF LF «Shakespeare» LF
Как и раньше, вы сами можете запустить zpipe или cat-file, чтобы увидить это.
Это первый коммит, поэтому здесь нет родительских коммитов, но последующие коммиты всегда будет содержать хотя бы одну строку, идентифицирующую родительский коммит.
Неотличимо от волшебства
Секреты Git выглядят слишком простыми. Похоже, что вы могли бы объединить несколько shell-скриптов и добавить немного кода на C, чтобы сделать всё это в считанные часы: смесь базовых операций с файлами и SHA1-хеширования, приправленная блокировочными файлами и fsync для надеждности. По сути, это точное описание ранних версий Git. Тем не менее, помимо гениальных трюков с упаковкой для экономии места и с индексацией для экономии времени, мы теперь знаем, как ловко Git преображает файловую систему в базу данных, идеально подходящую для управления версиями.
Например, если какой-либо файл в базе данных объектов поврежден из-за ошибки диска, то его хеш теперь не совпадет, что привлечет наше внимание к проблеме. С помощью хеширования хешей других объектов, мы поддерживаем целостность на всех уровнях. Коммиты атомарны, так что в них никогда нельзя записать лишь часть изменений: мы можем вычислить хеш коммита и сохранить его в базу данных только сохранив все соответствующие деревья, блобы и родительские коммиты. База данных объектов нечувствительна к непредвиденным прерываниям работы, таких как перебои с питанием.
Мы наносим поражение даже самым хитрым противникам. Предположим, кто-то пытается тайно изменить содержимое файла в древней версии проекта. Чтобы база объектов выглядела неповрежденной, он также должен изменить хеш соответствующего блоб-объекта, поскольку это теперь другая последовательность байтов. Это означает, что нужно поменять хеши всех объектов деревьев, ссылающихся на этот файл; что в свою очередь изменит хеши всех объектов коммитов с участием таких деревьев; а также и хеши всех потомков этих коммитов. Вследствие этого хеш официальной головной ревизии будет отличаться от аналогичного хеша в этом испорченном хранилище. По цепочке несовпадающих хешей мы можем точно вычислить искаженный файл, как и коммит, где он изначально был поврежден.
Одним словом, невозможно подделать хранилище Git, оставив невредимыми двадцать байт, отвечающие последнему коммиту.
Как насчет известных характерных особенностей Git? Ветвление? Слияние? Теги? Очевидные подробности. Текущая «голова» хранится в файле .git/HEAD , содержащем хеш объекта коммита. Хеш обновляется во время коммита, а также при выполнении многих других команд. С ветками всё аналогично: это файлы в .git/refs/heads . То же и тегами: они живут в .git/refs/tags , но их обновляет другой набор команд.
Основы Git. Как работает Git?
Git — распределённая система контроля версий, позволяющая сохранять изменения, внесённые в файлы, которые хранятся в репозитории. Сами изменения сохраняются в виде снимков, называемых коммитами. Они могут размещаться на разных серверах, поэтому вы всегда восстановите код в случае сбоя, а также без проблем откатитесь до любого предыдущего состояния. Кроме того, значительно облегчается взаимодействие с другими разработчиками: несколько человек могут работать над одним репозиторием одновременно, сохраняя свои изменения.
Git имеет множество плюсов, поэтому считается незаменимым инструментом для всех, кто работает в сфере разработки ПО. В этой статье мы рассмотрим, когда используется Git, изучим наиболее полезные Git-команды. Если Git вам уже знаком, вы сможете освежить свои знания.
Как работать с Git?
В Git имеется много команд, поэтому разобьём их по теме и причине использования. Но начнём с того, что рассмотрим работу Git на локальной машине, ведь большая часть операций происходит именно там. После этого перейдём к многопользовательскому формату.
Вообще, с Git можно работать и через графический интерфейс (например, GitHub Desktop), и через командную строку. Командную строку изучить необходимо хотя бы потому, что она предоставляет больше возможностей, чем некоторые инструменты с интерфейсом.
Обычно, команды Git имеют следующий вид:
В качестве аргумента может быть путь к файлу. Также у команд бывают опции, обозначаемые -- либо - . Они обеспечивают более детальную настройку действия команды. В нашем материале команды будут представлены в общем виде, а значит всё, что будет в <> , вы можете менять на собственные значения.
Кстати, если возникают затруднения с использованием той либо иной команды, рекомендуется открыть руководство посредством git help . Если просто нужно напоминание, применяйте git -h либо git --help (в Git -h и --help имеют одинаковое значение).
Установка Git
Если вы пользуетесь Windows, качайте Git отсюда. Что касается macOS, то здесь Git поставляется как часть инструмента командной строки XCode. Наличие Git можно проверить, открыв терминал и набрав git --version . Для Linux используйте команду sudo apt install git-all либо sudo dnf install git-all .
Настраиваем конфигурационный файл
Сразу после установки Git нужно настроить имя пользователя и email, ведь они используются для идентификации. Данные настройки будут сохранены в конфигурационном файле.
Вы можете отредактировать файл .gitconfig напрямую с помощью редактора или, используя команду git config --global --edit . Чтобы отредактировать отдельные поля, подойдёт git config --global — здесь нас интересуют поля user.email и user.name.
Кроме того, есть возможность настройки текстового редактора для написания сообщений коммитов — это поле core.editor. По умолчанию применяется системный редактор. Поле commit.template служит для указания шаблона, который будет задействоваться при каждом коммите.
Есть и много других полей, но самое полезное — alias (привязывает команду к псевдониму). К примеру, git config --global alias.st "status -s" позволит использовать git st вместо git status –s.
А git config --list выведет все поля с их значениями из конфигурационного файла.
Создание Git-репозитория
Чтобы инициализировать новый репозиторий .git используют команду git init . Если хотите скопировать уже существующий репозиторий — git clone .
История коммитов в Git
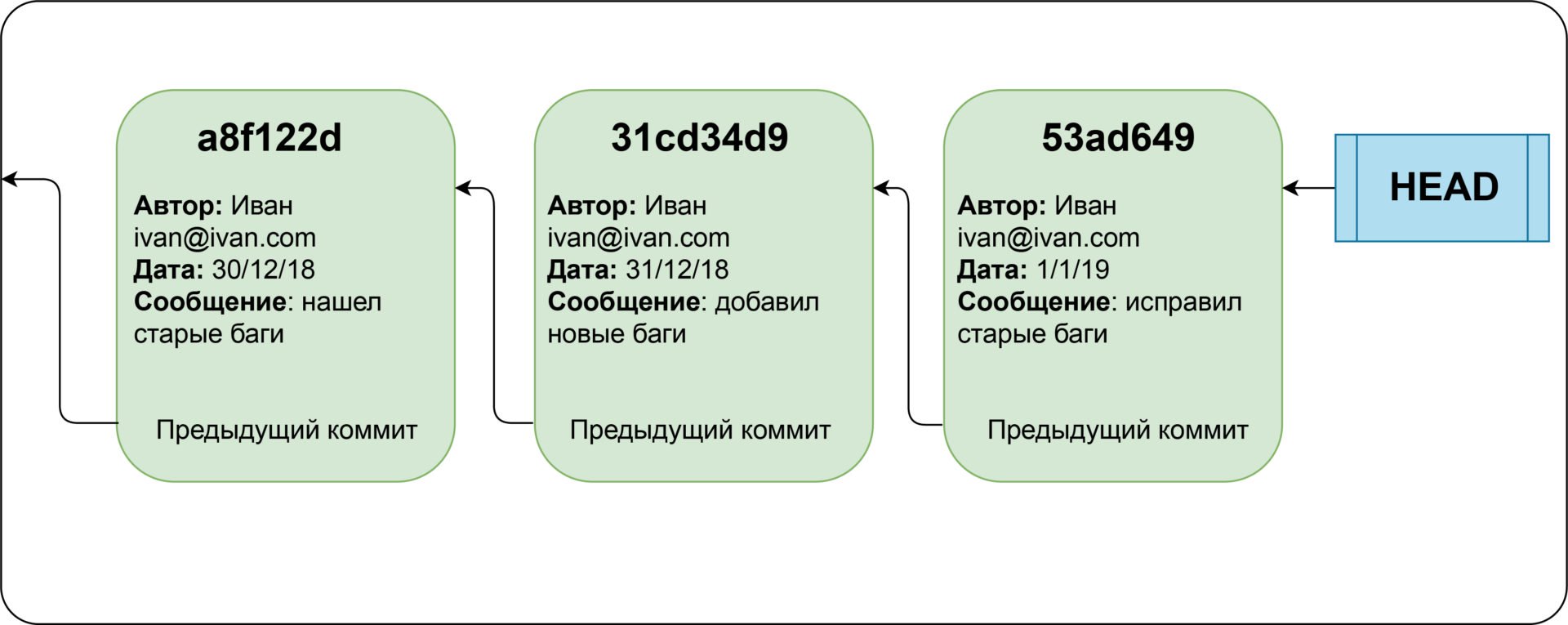
Git хранит имеющиеся данные в виде набора «снимков», называемых коммитами. Коммиты хранят состояние файловой системы в конкретный момент времени, а также имеют указатель на предыдущие коммиты. Каждый коммит содержит уникальный контрольный идентификатор, который используется Git, чтобы ссылаться на этот коммит. Для отслеживания истории Git хранит указатель HEAD, указывающий на 1-й коммит.
Ссылаться можно как через контрольную сумму коммита, так и через его позицию относительно HEAD. К примеру, HEAD~4 будет ссылаться на коммит, находящийся 4-мя коммитами ранее HEAD.
Система файлов в Git
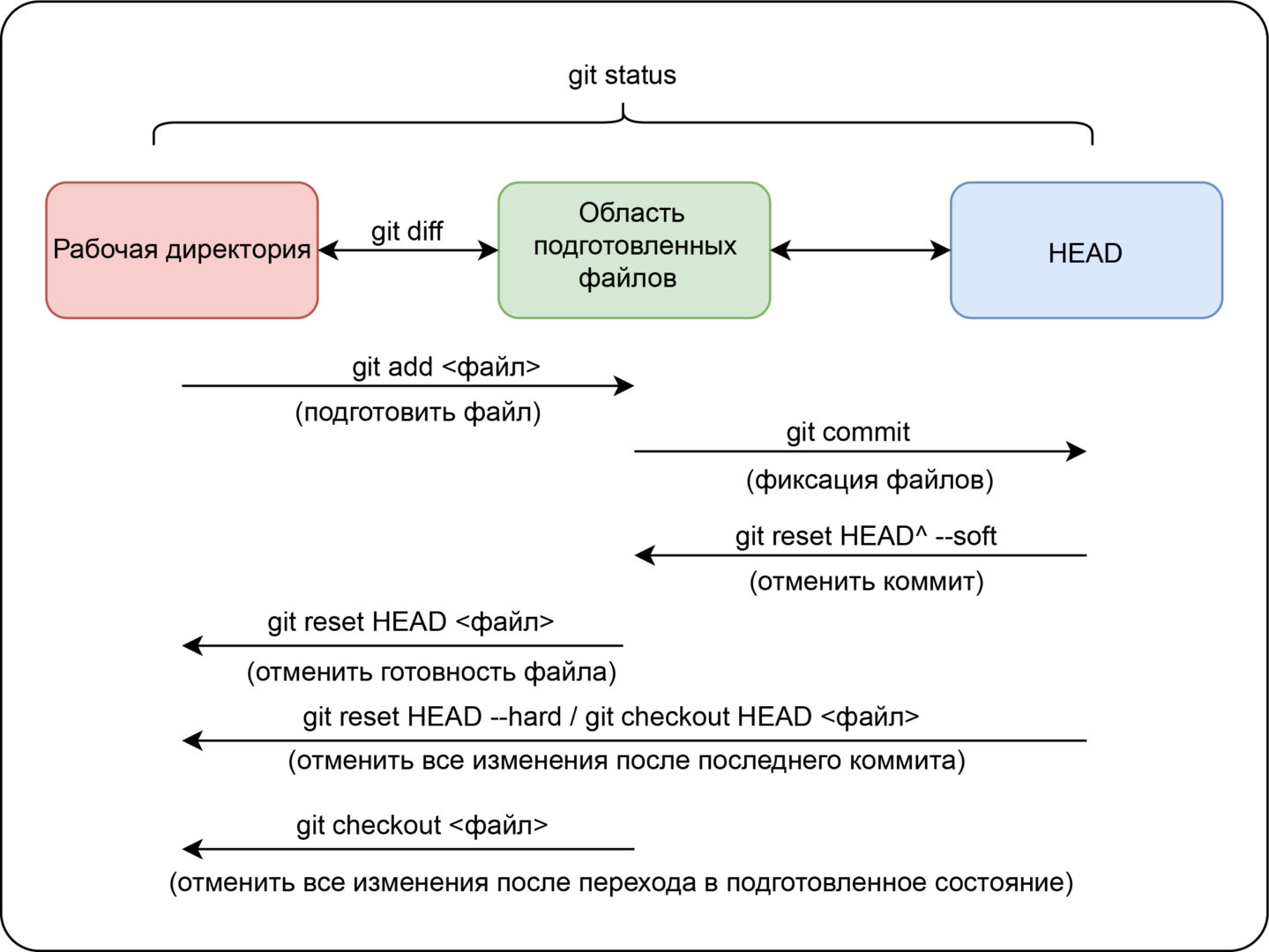
Git может отслеживать файлы в 3-х основных разделах: — рабочая директория (речь идёт о файловой системе вашего ПК); — область подготовленных файлов (это staging area, где хранится содержание следующего коммита); — HEAD (последний в репозитории коммит).
Как просматривать изменения в файловых системах?
Для этого используют команду git status . Она отображает все файлы, которые различаются между 3-мя отделами. Файлы имеют четыре состояния: 1) untracked (неотслеживаемый). Находится в рабочей директории, но его нет ни в HEAD, ни в области подготовленных файлов. Можно сказать, что Git о нём не знает; 2) modified (изменён). В рабочей директории находится его более новая версия по сравнению с той, которая хранится в HEAD либо в области подготовленных файлов (при этом изменения не находятся в следующем коммите); 3) staged (подготовлен). В области подготовленных файлов и в рабочей директории есть более новая версия, если сравнивать с хранящейся в HEAD, но файл уже готов к коммиту; 4) без изменений. Во всех разделах содержится одна версия файла, то есть в последнем коммите находится актуальная версия.
Чтобы посмотреть не изменённые файлы, а непосредственно изменения, можно использовать: — git diff — для сравнения рабочей директории с областью подготовленных файлов; — git diff --staged — для сравнения области подготовленных файлов с HEAD.
В случае применения аргумента diff покажет изменения лишь для указанных вами папок или файлов, к примеру:
git diff src/Игнорирование файлов
Иногда нам не надо, чтобы Git отслеживал все файлы в репозитории, ведь в их число могут входить: — файлы с конфиденциальной информацией; — огромные бинарные файлы; — специфичные файлы; — файлы сборок, генерируемые после каждой компиляции.
Для игнорирования предусмотрен файл .gitignore, где отмечаются файлы для игнорирования.
Коммиты
Основой истории версий являются коммиты. Для работы с ними используют git commit — эта команда откроет текстовый редактор для ввода сообщения коммита. Кроме того, она принимает следующие аргументы: • -m — позволяет написать сообщение, не открывая редактор, то есть вместе с командой; • -a — служит для переноса всех отслеживаемых файлов в область подготовленных файлов и включения их в коммит (даёт возможность перед коммитом пропустить git add); • --amend — заменяет последний коммит новым изменённым коммитом. Это бывает полезно, когда вы неправильно наберёте сообщение последнего коммита либо забудете включить в него нужные файлы.
Ряд советов по коммитам: — коммитьте часто; — одно изменение — один коммит, но не коммитьте слишком незначительные изменения (в большом репозитории они могут засорить историю); — комментируя сообщение о коммите, логически дополняйте фразу this commit will ___ и не используйте более 50 символов.
Удалённые серверы
Мы можем хранить, отслеживать и обновлять историю коммитов не только на локальной машине, но и на удалённых репозиториях. По сути, можно говорить об облачных бэкапах нашей истории коммитов.
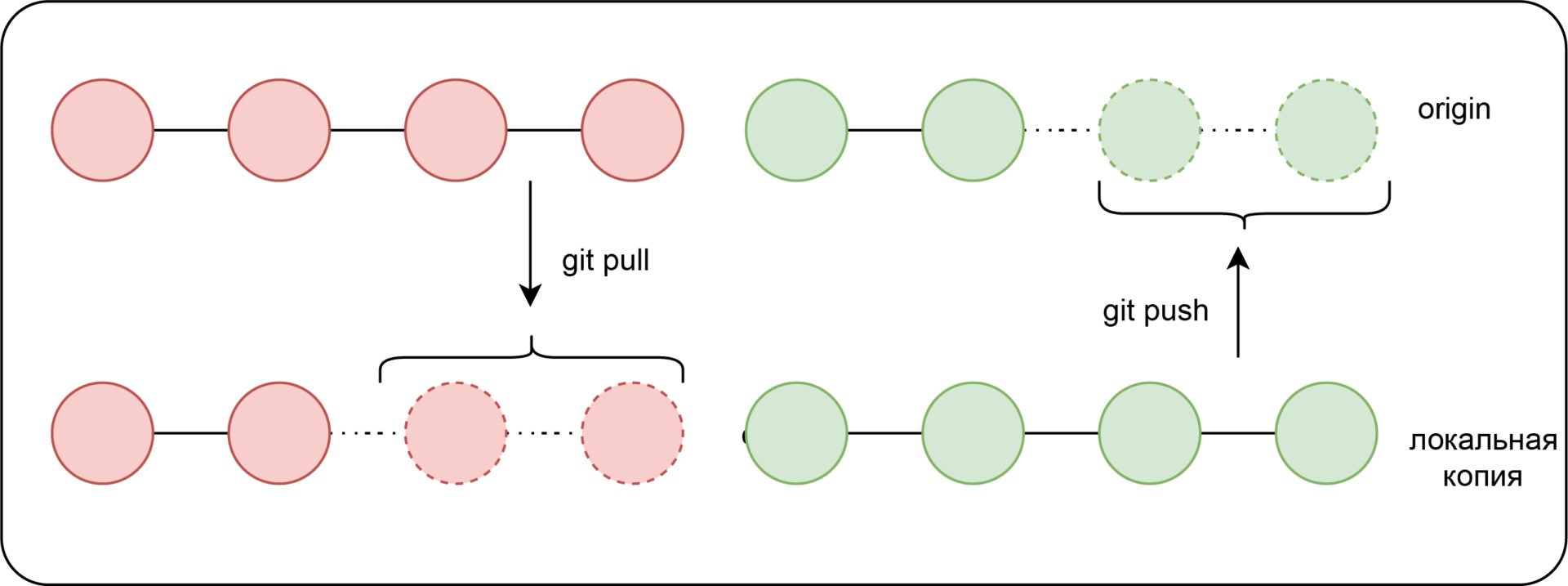
Для вывода списка удалённых репозиториев нужна команда git remote –v . С её помощью мы не только загружаем копию репозитория, но и отслеживаем удалённый сервер, находящийся по указанному адресу (ему присваивается имя origin).
Другие часто употребляемые команды: • git remote add — добавляется удалённый репозиторий с заданным именем; • git remote remove — удаляется удалённый репозиторий с заданным именем; • git remote rename — переименовывается удалённый репозиторий; • git remote set-url — репозиторию с именем присваивается новый адрес; • git remote show — показывается информация о репозитории.
Следующий список нужен для работы с удалёнными ветками: • git fetch — для получения данных из ветки заданного репозитория; • git pull — сливает данные из ветки; • git push — для отправления изменения в ветку заданного репозитория. Когда локальная ветка отслеживает удалённую, достаточно использовать git push или git pull .
В результате несколько человек могут запрашивать с сервера изменения, выполнять изменения в локальных копиях, а потом отправлять их на удалённый сервер. Всё это позволяет легко взаимодействовать между собой в пределах одного репозитория.
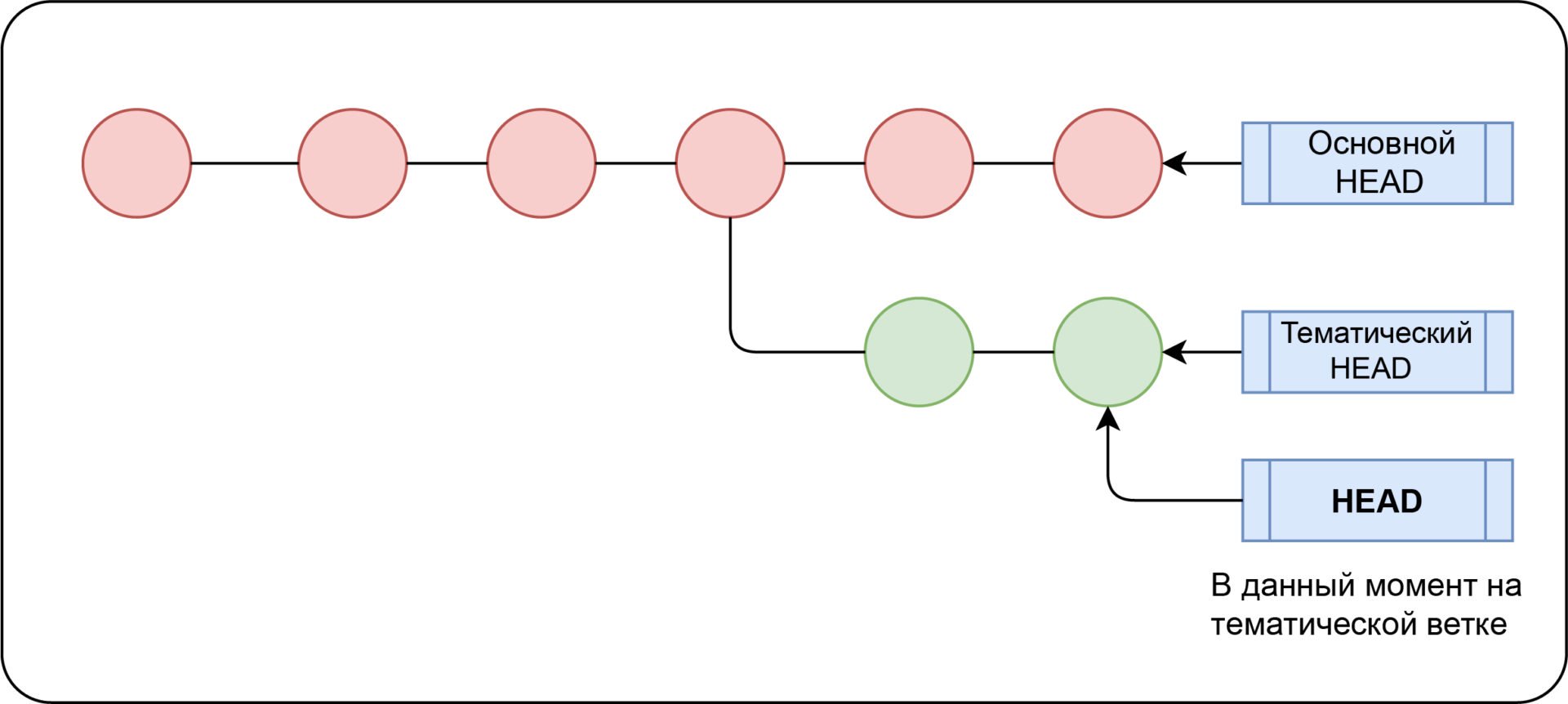
Ветвление в Git
Ключевая особенность Git — ветвление, позволяющее работать над разными версиями проекта. Таким образом, вместо одного перечня с упорядоченными коммитами история может расходиться в некоторых точках, поэтому становится похожей на дерево. И каждая ветвь содержит в Git легковесный указатель HEAD, указывающий на последний коммит в данной ветке. В результате можно легко создать много веток. Делая это, называйте ветки согласно разрабатываемой функциональности. Ветку по умолчанию называют master.
Что ж, у нас есть HEAD для каждой ветки и общий указатель HEAD. Переключение между ветками предполагает лишь перемещение HEAD в HEAD соответствующей ветки.
Стандартные команды при ветвлении в Git: • git branch — для создания новой ветки с HEAD, указывающим на HEAD. Если аргумент передан не будет, команда выведет список всех имеющихся локальных веток; • git branch -d — для удаления ветки; • git checkout — для переключения на эту ветку. Если хотим создать новую ветку перед переключением, можем передать опцию –b.
И локальный, и удалённый репозиторий могут иметь много веток, поэтому при отслеживании на деле отслеживается удалённая ветка, то есть git clone привязывает ветвь master к ветви origin/master удалённого репозитория.
Парочка команд для привязывания к удалённой ветке: • git branch -u / —текущая ветка привязывается к указанной удалённой ветке; • git checkout --track / — аналогично; • git checkout -b / — создаётся новая локальная ветвь и начинает отслеживать удалённую; • git checkout — создаётся локальная ветвь с таким же именем, как и у удалённой, плюс начинает её отслеживать; • git branch --vv — служит, чтобы показать локальные и отслеживаемые удалённые ветки.
Совмещение веток
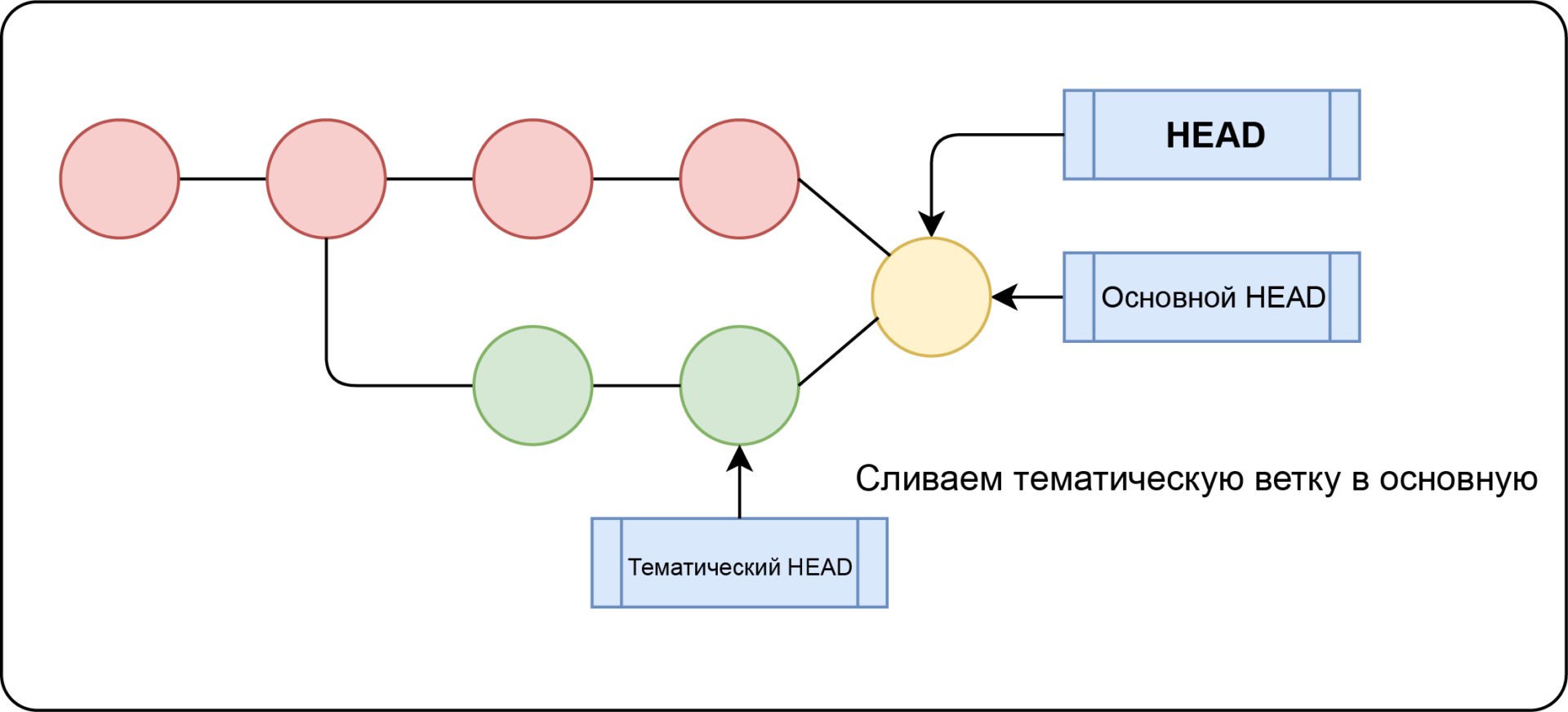
Обсудив возможности по переключению, можно поговорить, как ветки совмещать после разработки. Ветку, в которую мы желаем слить изменения, назовём основной, а ветвь, из которой будем сливать, — тематической. Существуют 2 способа внести изменения — перемещение и слияние.
Слияние
Включает в себя создание нового коммита, основанного на общем коммите-предке 2-х ветвей, указывает на оба HEAD. Для осуществления слияния нужно перейти на основную ветки и использовать команду git merge .
Когда обе ветки меняют одну и ту же часть файла, возникает конфликт слияния. В этой ситуации Git не понимает, какую версию файла нужно сохранить. Разрешать конфликт следует вручную. Для просмотра конфликтующих файлов, используйте git status .
Маркеры разрешения конфликта:
>>>>>> test:index.htmlВ этом блоке надо заменить всё на версию, которую хотите оставить, после чего подготовить файл. Разрешив все конфликты, можно завершать слияние, используя git commit .
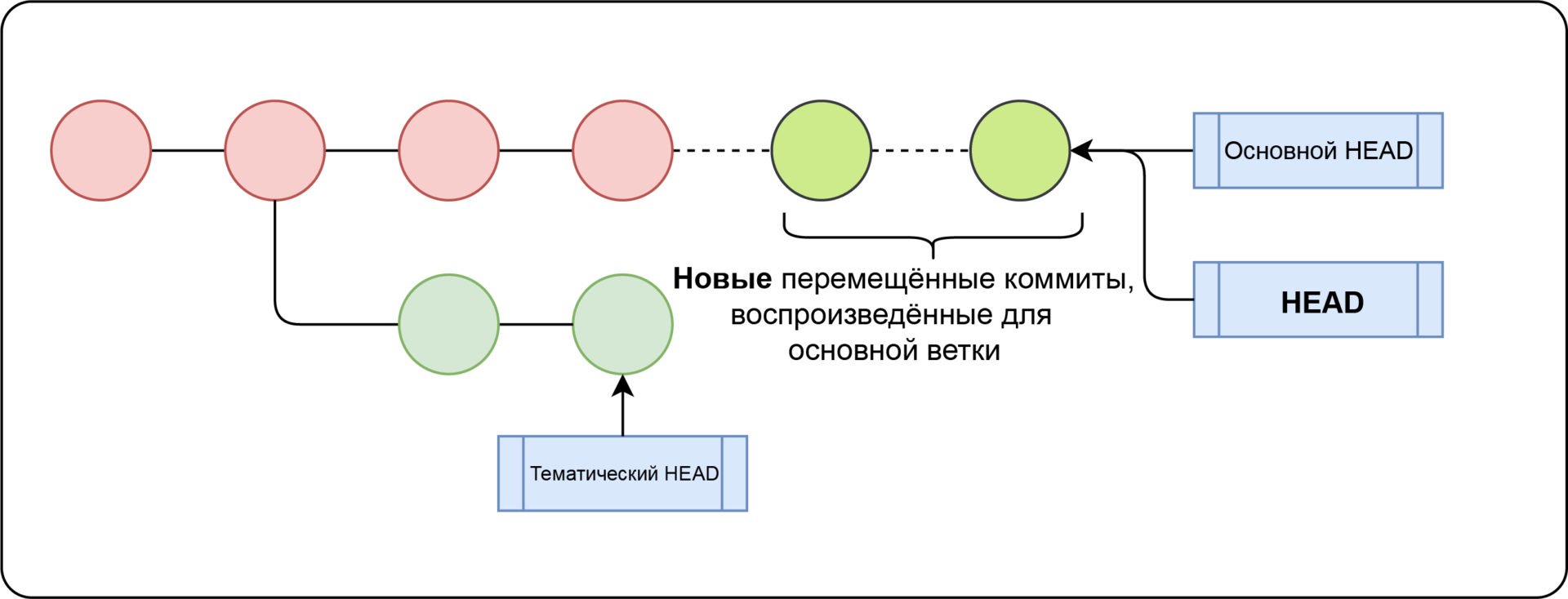
Перемещение
Осуществляется вместо совмещения 2-ух веток коммитом слияния. Перемещение заново воспроизводит коммиты тематической ветви в виде набора новых коммитов базовой ветви, что обеспечивает более чистую историю коммитов.
Чтобы выполнить перемещение, используют команду git rebase . Она воспроизводит изменения тематической ветви на основной. При этом HEAD тематической ветви указывает на последний воспроизведённый коммит.
Совет: перемещайте изменения лишь на вашей приватной локальной ветке. Не стоит перемещать коммиты, от которых ещё кто-то зависит.
Если хотите откатить коммит: — git revert — создаёт новый коммит, который отменяет изменения, но сохраняет историю; — git reset — перемещает указатель HEAD, и создаёт более чистую историю, как будто коммита никогда не было. Но это также значит, что вы не сможете вернуться обратно к изменениям, если решите, что отмена была лишней. В общем, чище — не значит лучше!