Способы сжатия и архивации информации
При архивировании и передаче по каналам связи объем информации является основным параметром. Поэтому модели представления дополняются процедурами сжатия, т. е. плотной упаковкой информации.
Разработаны и применяются два типа алгоритмов сжатия:
- • сжатие с изменением структуры данных (оно происходит без потери данных);
- • сжатие с частичной потерей данных.
Алгоритмы первого типа предусматривают две операции: сжатие информации для хранения, передачи и восстановление данных точно в исходном виде, когда их требуется использовать. Такой тип сжатия применяется, например, для хранения текстов (наиболее известны алгоритмы Хаффмана и Лемпела—Зива). Алгоритмы второго типа не позволяют полностью восстановить оригинал и применяются для хранения графики или звука; для текстов, чисел или программ они неприменимы.
Алгоритмы сжатия
Сжатие — это кодирование с уменьшением объема данных и возможностью однозначного декодирования. Обратный процесс — декодирование — называется разжатие. Другие названия: компрессия/декомпрессия, упаковка/распаковка. Эффективность алгоритма сжатия зависит не только от степени сжатия (отношение длины несжатых данных к длине соответствующих им сжатых данных), но и скорости сжатия и разжатия, объема памяти, необходимого для работы алгоритмов и т. д. На практике выделяют следующие два вида компрессии данных:
- 1. Сжатие без потерь (lossless compression) — собственно сжатие в смысле приведенного выше определения.
- 2. Сжатие с потерями (lossy compression) — процесс, состоящий из двух этапов:
- • выделение сохраняемой части информации в зависимости от цели сжатия и особенностей приемника и источника;
- • собственно сжатие без потерь.
Методы сжатия без потерь
В основе всех методов сжатия лежит простая идея: если представлять часто используемые элементы короткими кодами, а редко используемые — длинными кодами, то для хранения блока данных требуется меньший объем памяти, чем если бы все элементы представлялись кодами одинаковой длины. Точная связь между вероятностями и кодами установлена в теореме Шеннона о кодировании источника: элемент а., вероятность появления которого равняется р., выгоднее всего представлять —log 1pj бит. Если при кодировании размер элементарных кодов в точности получается равным —log^., то длина кода будет минимальной из всех возможных способов алфавитного кодирования и равна энтропии tf = -2>, log2jP|. Сжатие всегда осуществляется за счет устранения статистической избыточности в представлении информации. Компрессор не может сжать любой файл. Размер некоторых файлов уменьшается, а остальных остается неизменным или увеличивается.
Коды Хаффмана (Huffman Coding), или коды с минимальной избыточностью
Характеристики: степени сжатия — от 1 до 8, средняя — 1,5; не увеличивает размер файла (не считая таблицы перекодировки).
Кодирование длин повторов, Run Length Encoding (RLE)
Один из наиболее старых методов сжатия. Идея метода состоит в замене идущих подряд одинаковых символов (бит или байт) парой (количество, символ). В основном используется для кодирования растровых изображений. Характеристика: степень сжатия от 0,5 до 32.
Алгоритмы Зива-Лемпеля (LZ-методы)
Реализации LZ77, LZ78, LZW и LZH. Относятся к словарным методам сжатия, т. е. сообщение кодируется не побуквенно (алфавитное кодирование), а по словам. Характеристики LZ78: степень сжатия в зависимости отданных, обычно 2—3, алгоритмы универсальны, но лучше всего подходят для сжатия текстов, рисованных картинок или других однородных данных.
Идея словарного метода состоит в обнаружении во входном тексте повторяющихся цепочек байтов (слов), составлении таблицы таких слов (словаря). Все слова в исходном сообщении заменяются на код — номер слова в словаре. Алгоритм устроен так, что распаковщик, анализируя сжатые данные, может построить копию исходной таблицы, и следовательно, ее не надо хранить вместе с сжатыми данными.
Рассмотрим подробнее алгоритм LZ78. Кодируемый текст разбивается на слова, каждое из которых кодируется парой (номер, символ). За один проход по тексту динамически строится словарь и сжатый текст. Изначально словарь содержит одно слово с номером 0 — пустое Л. На каждом шаге алгоритма считываются символы, начиная с текущего, и формируется слово наибольшей длины, совпадающее с каким-нибудь из уже имеющихся в словаре, плюс еще один символ.
Рассмотрим, например, входную последовательность 010 001 011 001 010 001 101 011 00.
На первом шаге рассматривается слово из одного символа 0, оно добавляется в словарь под номером 1 и кодируется в выходной последовательности (0,0), что означает слово из словаря под номером 0 (пустое слово) + символ 0. На втором шаге в словарь добавляется слово 1 под номером 2, имеющее код (1,0). На третьем шаге имеем совпадение с непустым словом в словаре 0, в словарь добавляется слово 00, имеющее код (1,0), и т. д. На шестом шаге мы уже закодировали последовательность 010001011, словарь имеет вид , остался текст 0010100011. Максимальное совпадение с третьим словом словаря «00». Данная последовательность вместе со следующим символом (здесь 1) кодируется парой чисел (номер совпадающего слова в словаре, следующий символ) (здесь (3,1)) и добавляется в словарь (теперь словарь имеет вид (Л, 0, 1, 00, 01, 011, 001>. На следующем шаге считывается следующий за уже закодированными символ и т. д. до конца входного текста.
В результате последовательности 010 001 011 001 010 001 101 011 00 соответствует словарь , разбиение последовательности на слова и код (см. табл. 7):
Алгоритмы сжатия данных без потерь
Существующие алгоритмы сжатия данных можно разделить на два больших класса – с потерями, и без. Алгоритмы с потерями обычно применяются для сжатия изображений и аудио. Эти алгоритмы позволяют достичь больших степеней сжатия благодаря избирательной потере качества. Однако, по определению, восстановить первоначальные данные из сжатого результата невозможно.
Алгоритмы сжатия без потерь применяются для уменьшения размера данных, и работают таким образом, что возможно восстановить данные в точности такими, какие они были до сжатия. Они применяются в коммуникациях, архиваторах и некоторых алгоритмах сжатии аудио и графической информации. Далее мы рассмотрим только алгоритмы сжатия без потерь.
Основной принцип алгоритмов сжатия базируется на том, что в любом файле, содержащем неслучайные данные, информация частично повторяется. Используя статистические математические модели можно определить вероятность повторения определённой комбинации символов. После этого можно создать коды, обозначающие выбранные фразы, и назначить самым часто повторяющимся фразам самые короткие коды. Для этого используются разные техники, например: энтропийное кодирование, кодирование повторов, и сжатие при помощи словаря. С их помощью 8-битный символ, или целая строка, могут быть заменены всего лишь несколькими битами, устраняя таким образом излишнюю информацию.История
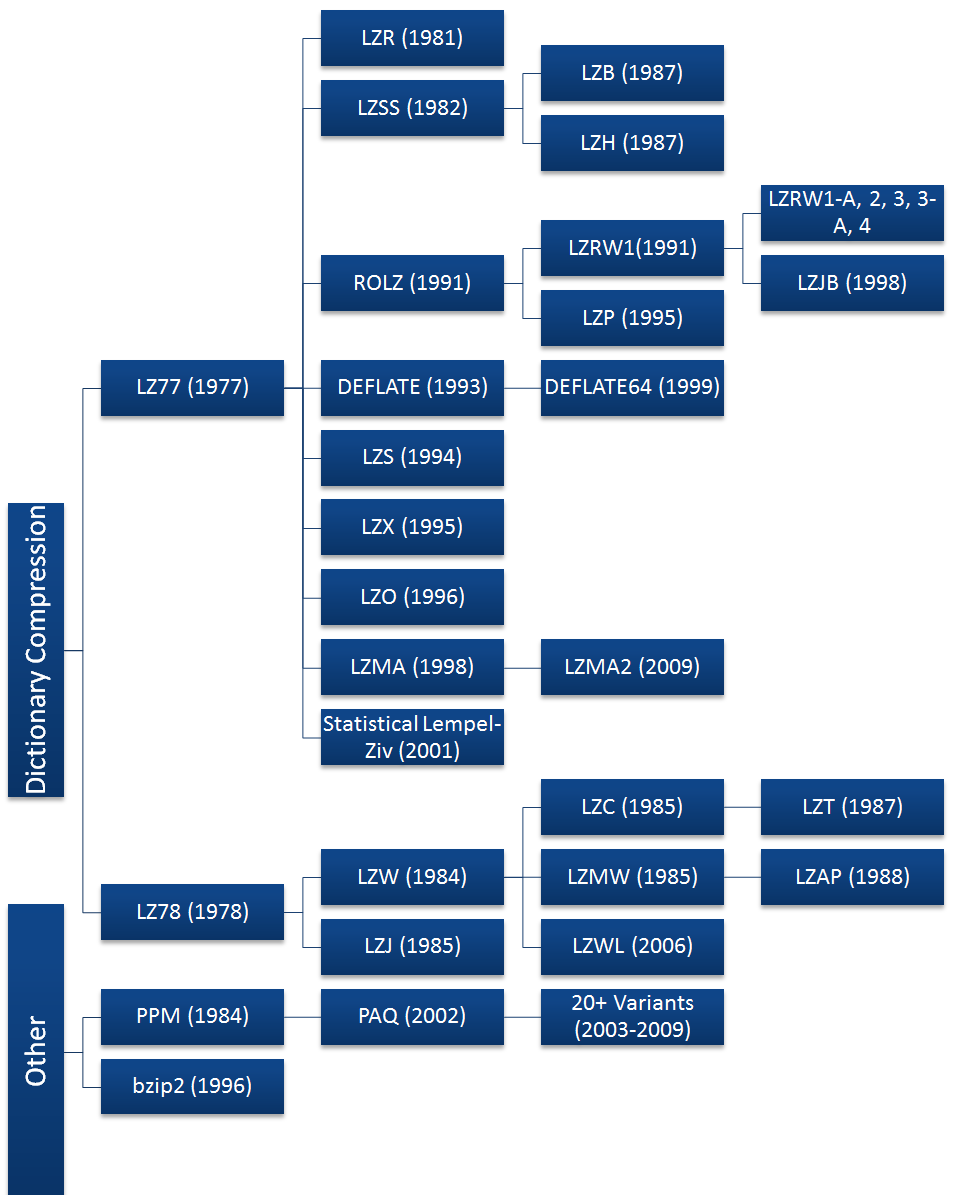
Иерархия алгоритмов:
Хотя сжатие данных получило широкое распространение вместе с интернетом и после изобретения алгоритмов Лемпелем и Зивом (алгоритмы LZ), можно привести несколько более ранних примеров сжатия. Морзе, изобретая свой код в 1838 году, разумно назначил самым часто используемым буквам в английском языке, “e” и “t”, самые короткие последовательности (точка и тире соотв.). Вскоре после появления мейнфреймов в 1949 году был придуман алгоритм Шеннона — Фано, который назначал символам в блоке данных коды, основываясь на вероятности их появления в блоке. Вероятность появления символа в блоке была обратно пропорциональна длине кода, что позволяло сжать представление данных.
Дэвид Хаффман был студентом в классе у Роберта Фано и в качестве учебной работы выбрал поиск улучшенного метода бинарного кодирования данных. В результате ему удалось улучшить алгоритм Шеннона-Фано.
Ранние версии алгоритмов Шеннона-Фано и Хаффмана использовали заранее определённые коды. Позже для этого стали использовать коды, созданные динамически на основе данных, предназначаемых для сжатия. В 1977 году Лемпель и Зив опубликовали свой алгоритм LZ77, основанный на использования динамически создаваемого словаря (его ещё называют «скользящим окном»). В 78 году они опубликовали алгоритм LZ78, который сначала парсит данные и создаёт словарь, вместо того, чтобы создавать его динамически.Проблемы с правами
Алгоритмы LZ77 и LZ78 получили большую популярность и вызвали волну улучшателей, из которых до наших дней дожили DEFLATE, LZMA и LZX. Большинство популярных алгоритмов основаны на LZ77, потому что производный от LZ78 алгоритм LZW был запатентован компанией Unisys в 1984 году, после чего они начали троллить всех и каждого, включая даже случаи использования изображений в формате GIF. В это время на UNIX использовали вариацию алгоритма LZW под названием LZC, и из-за проблем с правами их использование пришлось сворачивать. Предпочтение отдали алгоритму DEFLATE (gzip) и преобразованию Барроуза — Уилера, BWT (bzip2). Что было и к лучшему, так как эти алгоритмы почти всегда превосходят по сжатию LZW.
К 2003 году срок патента истёк, но поезд уже ушёл и алгоритм LZW сохранился, пожалуй, только в файлах GIF. Доминирующими являются алгоритмы на основе LZ77.
В 1993 году была ещё одна битва патентов – когда компания Stac Electronics обнаружила, что разработанный ею алгоритм LZS используется компанией Microsoft в программе для сжатия дисков, поставлявшейся с MS-DOS 6.0. Stac Electronics подала в суд и им удалось выиграть дело, в результате чего они получили более $100 миллионов.Рост популярности Deflate
Большие корпорации использовали алгоритмы сжатия для хранения всё увеличивавшихся массивов данных, но истинное распространение алгоритмов произошло с рождением интернета в конце 80-х. Пропускная способность каналов была чрезвычайно узкой. Для сжатия данных, передаваемых по сети, были придуманы форматы ZIP, GIF и PNG.
Том Хендерсон придумал и выпустил первый коммерчески успешный архиватор ARC в 1985 году (компания System Enhancement Associates). ARC была популярной среди пользователей BBS, т.к. она одна из первых могла сжимать несколько файлов в архив, к тому же исходники её были открыты. ARC использовала модифицированный алгоритм LZW.
Фил Катц, вдохновлённый популярностью ARC, выпустил программу PKARC в формате shareware, в которой улучшил алгоритмы сжатия, переписав их на Ассемблере. Однако, был засужен Хендерсоном и был признан виновным. PKARC настолько открыто копировала ARC, что иногда даже повторялись опечатки в комментариях к исходному коду.
Но Фил Катц не растерялся, и в 1989 году сильно изменил архиватор и выпустил PKZIP. После того, как его атаковали уже в связи с патентом на алгоритм LZW, он изменил и базовый алгоритм на новый, под названием IMPLODE. Вновь формат был заменён в 1993 году с выходом PKZIP 2.0, и заменой стал DEFLATE. Среди новых возможностей была функция разбиения архива на тома. Эта версия до сих пор повсеместно используется, несмотря на почтенный возраст.
Формат изображений GIF (Graphics Interchange Format) был создан компанией CompuServe в 1987. Как известно, формат поддерживает сжатие изображения без потерь, и ограничен палитрой в 256 цветов. Несмотря на все потуги Unisys, ей не удалось остановить распространение этого формата. Он до сих пор популярен, особенно в связи с поддержкой анимации.
Слегка взволнованная патентными проблемами, компания CompuServe в 1994 году выпустила формат Portable Network Graphics (PNG). Как и ZIP, она использовала новый модный алгоритм DEFLATE. Хотя DEFLATE был запатентован Катцем, он не стал предъявлять никаких претензий.
Сейчас это самый популярный алгоритм сжатия. Кроме PNG и ZIP он используется в gzip, HTTP, SSL и других технологиях передачи данных.К сожалению Фил Катц не дожил до триумфа DEFLATE, он умер от алкоголизма в 2000 году в возрасте 37 лет. Граждане – чрезмерное употребление алкоголя опасно для вашего здоровья! Вы можете не дожить до своего триумфа!
Современные архиваторы
ZIP царствовал безраздельно до середины 90-х, однако в 1993 году простой русский гений Евгений Рошал придумал свой формат и алгоритм RAR. Последние его версии основаны на алгоритмах PPM и LZSS. Сейчас ZIP, пожалуй, самый распространённый из форматов, RAR – до недавнего времени был стандартом для распространения различного малолегального контента через интернет (благодаря увеличению пропускной способности всё чаще файлы распространяются без архивации), а 7zip используется как формат с наилучшим сжатием при приемлемом времени работы. В мире UNIX используется связка tar + gzip (gzip — архиватор, а tar объединяет несколько файлов в один, т.к. gzip этого не умеет).
Прим. перев. Лично я, кроме перечисленных, сталкивался ещё с архиватором ARJ (Archived by Robert Jung), который был популярен в 90-х в эру BBS. Он поддерживал многотомные архивы, и так же, как после него RAR, использовался для распространения игр и прочего вареза. Ещё был архиватор HA от Harri Hirvola, который использовал сжатие HSC (не нашёл внятных объяснений — только «модель ограниченного контекста и арифметическое кодирование»), который хорошо справлялся со сжатием длинных текстовых файлов.
В 1996 году появился вариант алгоритма BWT с открытыми исходниками bzip2, и быстро приобрёл популярность. В 1999 году появилась программа 7-zip с форматом 7z. По сжатию она соперничает с RAR, её преимуществом является открытость, а также возможность выбора между алгоритмами bzip2, LZMA, LZMA2 и PPMd.
В 2002 году появился ещё один архиватор, PAQ. Автор Мэтт Махоуни использовал улучшенную версию алгоритма PPM с использованием техники под названием «контекстное смешивание». Она позволяет использовать больше одной статистической модели, чтобы улучшить предсказание по частоте появления символов.Будущее алгоритмов сжатия
Конечно, бог его знает, но судя по всему, алгоритм PAQ набирает популярность благодаря очень хорошей степени сжатия (хотя и работает он очень медленно). Но благодаря увеличению быстродействия компьютеров скорость работы становится менее критичной.
С другой стороны, алгоритм Лемпеля-Зива –Маркова LZMA представляет собой компромисс между скоростью и степенью сжатия и может породить много интересных ответвлений.
Ещё одна интересная технология «substring enumeration» или CSE, которая пока мало используется в программах.В следующей части мы рассмотрим техническую сторону упомянутых алгоритмов и принципы их работы.
6.4. Типы сжатия информации
Сжатие без потерь (англ. Lossless data compression) — метод сжатия информации, при использовании которого закодированная информация может быть восстановлена с точностью до бита. При этом оригинальные данные полностью восстанавливаются из сжатого состояния
Этот тип сжатия принципиально отличается от сжатия данных с потерями. Для каждого из типов цифровой информации, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
Сжатие данных без потерь используется во многих приложениях. Например, оно используется в популярном файловом формате ZIP и Unix-утилите Gzip. Оно также используется как компонент в сжатии с потерями.
Сжатие без потерь используется, когда важна идентичность сжатых данных оригиналу. Обычный пример — исполняемые файлы и исходный код. Некоторые графические файловые форматы, такие как PNG или GIF, используют только сжатие без потерь; тогда как другие (TIFF, MNG) могут использовать сжатие как с потерями, так и без.
Техника сжатия без потерь
Из комбинаторики следует, что нет алгоритма сжатия без потерь, способного уменьшить хотя бы на байт любой файл. Впрочем, признак качества алгоритма сжатия не в этом — алгоритм должен эффективно работать на тех данных, на которые он рассчитан.
Многоцелевые алгоритмы сжатия отличаются тем, что способны уменьшать широкий диапазон данных — исполняемые файлы, файлы данных, тексты, графику и т. д., и применяются в архиваторах. Специализированные же алгоритмы рассчитаны на некоторый тип файлов (текст, графику, звук и т. д.), зато сжимают такие файлы намного сильнее. Например: архиваторы сжимают звук примерно на треть (в 1,5 раза), в то время как FLAC — в 2,5 раза. Большинство специализированных алгоритмов малопригодны для файлов «чужих» типов: так, звуковые данные плохо сжимаются алгоритмом, рассчитанным на тексты.
Большинство алгоритмов сжатия без потерь работают в две стадии:
- на первой генерируется статистическая модель для входящих данных,
- вторая отображает входящие данные в битовом представлении, используя модель для получения «вероятностных» (то есть часто встречаемых) данных, которые используются чаще, чем «невероятностные».
- Преобразование Барроуза — Уилера (блочно-сортирующая преобработка, которая делает сжатие более эффективным)
- LZ77 и LZ78 (используется DEFLATE)
- LZW
- Алгоритмы кодирования через генерирование битовых последовательностей:
- Алгоритм Хаффмана (также используется DEFLATE)
- Арифметическое кодирование
- Преимущество методов сжатия с потерями над методами сжатия без потерь состоит в том, что первые существенно превосходят по степени сжатия, продолжая удовлетворять поставленным требованиям.
- Методы сжатия с потерями часто используются для сжатия звука или изображений.
- В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений.
Сжатие информации с потерями и без потерь
Еще вчера казалось, что диск размером в один гигабайт — это так много, что даже неясно, чем его заполнить, и уж конечно, каждый про себя думал: был бы у меня гигабайт памяти, я бы перестал «жадничать» и сжимать свою информацию какими-то архиваторами. Но, видимо, мир так устроен, что «свято место пусто не бывает», и как только у нас появляется лишний гигабайт — тут же находится чем его заполнить. Да и сами программы, как известно, становятся все более объемными. Так что, видимо, с терабайтами и экзабайтами будет то же самое.
Поэтому, как бы ни росли объемы памяти диска, упаковывать информацию, похоже, не перестанут. Наоборот, по мере того как «места в компьютере» становится все больше, число новых архиваторов увеличивается, при этом их разработчики не просто соревнуются в удобстве интерфейсов, а в первую очередь стремятся упаковать информацию все плотнее и плотнее.
Однако очевидно, что процесс этот не бесконечен. Где лежит этот предел, какие архиваторы доступны сегодня, по каким параметрам они конкурируют между собой, где найти свежий архиватор — вот далеко не полный перечень вопросов, которые освещаются в данной статье. Помимо рассмотрения теоретических вопросов мы сделали подборку архиваторов, которые можно загрузить с нашего диска, чтобы самим убедиться в эффективности той или иной программы и выбрать из них оптимальную — в зависимости от специфики решаемых вами задач.
Совсем немного теории для непрофессионалов
Позволю себе начать эту весьма серьезную тему со старой шутки. Беседуют два пенсионера:
— Вы не могли бы сказать мне номер вашего телефона? — говорит один.
— Вы знаете, — признается второй, — я, к сожалению, точно его не помню.
— Какая жалость, — сокрушается первый, — ну скажите хотя бы приблизительно…
Действительно, ответ поражает своей нелепостью. Совершенно очевидно, что в семизначном наборе цифр достаточно ошибиться в одном символе, чтобы остальная информация стала абсолютно бесполезной. Однако представим себе, что тот же самый телефон написан словами русского языка и, скажем, при передаче этого текста часть букв потеряна — что произойдет в подобном случае? Для наглядности рассмотрим себе конкретный пример: телефонный номер 233 34 44.
Соответственно запись «Двсти трцать три трицть четре сорк чтре», в которой имеется не один, а несколько пропущенных символов, по-прежнему легко читается. Это связано с тем, что наш язык имеет определенную избыточность, которая, с одной стороны, увеличивает длину записи, а с другой — повышает надежность ее передачи. Объясняется это тем, что вероятность появления каждого последующего символа в цифровой записи телефона одинакова, в то время как в тексте, записанном словами русского языка, это не так. Очевидно, например, что твердый знак в русском языке появляется значительно реже, чем, например, буква «а». Более того, некоторые сочетания букв более вероятны, чем другие, а такие, как два твердых знака подряд, невозможны в принципе, и так далее. Зная, какова вероятность появления какой-либо буквы в тексте, и сравнив ее с максимальной, можно установить, насколько экономичен данный способ кодирования (в нашем случае — русский язык).
Еще одно очевидное замечание можно сделать, вернувшись к примеру с телефоном. Для того чтобы запомнить номер, мы часто ищем закономерности в наборе цифр, что, в принципе, также является попыткой сжатия данных. Вполне логично запомнить вышеупомянутый телефон как «два, три тройки, три четверки».
Избыточность естественных языков
Теория информации гласит, что информации в сообщении тем больше, чем больше его энтропия. Для любой системы кодирования можно оценить ее максимальную информационную емкость (Hmax) и действительную энтропию (Н). Тогда случай Н
R = (Hmax — H)/ Hmax
Измерение избыточности естественных языков (тех, на которых мы говорим) дает потрясающие результаты: оказывается, избыточность этих языков составляет около 80%, а это свидетельствует о том, что практически 80% передаваемой с помощью языка информации является избыточной, то есть лишней. Любопытен и тот факт, что показатели избыточности разных языков очень близки. Данная цифра примерно определяет теоретические пределы сжатия текстовых файлов.
Кодирование информации
Факт избыточности свидетельствует о возможностях перехода на иную систему кодирования, которая уменьшила бы избыточность передаваемого сообщения. Говоря о переходе на коды, которые позволяют уменьшить размер сообщения, вводят понятие «коды сжатия». В принципе, кодирование информации может преследовать различные цели:
- кодирование в целях сжатия сообщения (коды сжатия);
- кодирование с целью увеличения помехоустойчивости (помехоустойчивые коды);
- криптографическое кодирование (криптографические коды).
Сжатие с потерями
Говоря о кодах сжатия, различают понятия «сжатие без потерь» и «сжатие с потерями». Очевидно, что когда мы имеем дело с информацией типа «номер телефона», то сжатие такой записи за счет потери части символов не ведет ни к чему хорошему. Тем не менее можно представить целый ряд ситуаций, когда потеря части информации не приводит к потери полезности оставшейся. Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где в силу огромных размеров файлов степень сжатия очень важна, и можно пожертвовать деталями, не существенными для восприятия этой информации человеком. Особые возможности для сжатия информации имеются при компрессии видео. В ряде случаев большая часть изображения передается из кадра в кадр без изменений, что позволяет строить алгоритмы сжатия на основе выборочного отслеживания только части «картинки». В частном случае изображение говорящего человека, не меняющего своего положения, может обновляться только в области лица или даже только рта — то есть в той части, где происходят наиболее быстрые изменения от кадра к кадру.
В целом ряде случаев сжатие графики с потерями, обеспечивая очень высокие степени компрессии, практически незаметно для человека. Так, из трех фотографий, показанных ниже, первая представлена в TIFF-формате (формат без потерь), вторая сохранена в формате JPEG c минимальным параметром сжатия, а третья с максимальным. При этом можно видеть, что последнее изображение занимает почти на два порядка меньший объем, чем первая.Однако методы сжатия с потерями обладают и рядом недостатков.
Первый заключается в том, что компрессия с потерями применима не для всех случаев анализа графической информации. Например, если в результате сжатия изображения на лице изменится форма родинки (но лицо при этом останется полностью узнаваемо), то эта фотография окажется вполне приемлемой, чтобы послать ее по почте знакомым, однако если пересылается фотоснимок легких на медэкспертизу для анализа формы затемнения — это уже совсем другое дело. Кроме того, в случае машинных методов анализа графической информации результаты кодирования с потерей (незаметные для глаз) могут быть «заметны» для машинного анализатора.
Вторая причина заключается в том, что повторная компрессия и декомпрессия с потерями приводят к эффекту накопления погрешностей. Если говорить о степени применимости формата JPEG, то, очевидно, он полезен там, где важен большой коэффициент сжатия при сохранении исходной цветовой глубины. Именно это свойство обусловило широкое применение данного формата в представлении графической информации в Интернете, где скорость отображения файла (его размер) имеет первостепенное значение. Отрицательное свойство формата JPEG — ухудшение качества изображения, что делает практически невозможным его применение в полиграфии, где этот параметр является определяющим.
Теперь перейдем к разговору о сжатии информации без потерь и рассмотрим, какие алгоритмы и программы позволяют осуществлять эту операцию.
Сжатие без потерь
Сжатие, или кодирование, без потерь может применяться для сжатия любой информации, поскольку обеспечивает абсолютно точное восстановление данных после кодирования и декодирования. Сжатие без потерь основано на простом принципе преобразования данных из одной группы символов в другую, более компактную.
Наиболее известны два алгоритма сжатия без потерь: это кодирование Хаффмена (Huffman) и LZW-кодирование (по начальным буквам имен создателей Lempel, Ziv, Welch), которые представляют основные подходы при сжатии информации. Кодирование Хаффмена появилось в начале 50-х; принцип его заключается в уменьшении количества битов, используемых для представления часто встречающихся символов и соответственно в увеличении количества битов, используемых для редко встречающихся символов. Метод LZW кодирует строки символов, анализируя входной поток для построения расширенного алфавита, основанного на строках, которые он обрабатывает. Оба подхода обеспечивают уменьшение избыточной информации во входных данных.
Кодирование Хаффмена
Кодирование Хаффмена [1] — один из наиболее известных методов сжатия данных, который основан на предпосылке, что в избыточной информации некоторые символы используются чаще, чем другие. Как уже упоминалось выше, в русском языке некоторые буквы встречаются с большей вероятностью, чем другие, однако в ASCII-кодах мы используем для представления символов одинаковое количество битов. Логично предположить, что если мы будем использовать меньшее количество битов для часто встречающихся символов и большее для редко встречающихся, то мы сможем сократить избыточность сообщения. Кодирование Хаффмена как раз и основано на связи длины кода символа с вероятностью его появления в тексте.
Статическое кодирование
Статическое кодирование предполагает априорное знание таблицы вероятностей символов. К примеру, если вы сжимаете файл, состоящий из текста, написанного на русском языке, то такая информация может быть получена из предварительного статистического анализа русского языка.
Динамическое кодирование
В том случае, когда вероятности символов входных данных неизвестны, используется динамическое кодирование, при котором данные о вероятности появления тех или иных символов уточняются «на лету» во время чтения входных данных.
LZW-сжатие
Алгоритм LZW [2], предложенный сравнительно недавно (в 1984 году), запатентован и принадлежит фирме Sperry.
LZW-алгоритм основан на идее расширения алфавита, что позволяет использовать дополнительные символы для представления строк обычных символов. Используя, например, вместо 8-битовых ASCII-кодов 9-битовые, вы получаете дополнительные 256 символов. Работа компрессора сводится к построению таблицы, состоящей из строк и соответствующих им кодов. Алгоритм сжатия сводится к следующему: программа прочитывает очередной символ и добавляет его к строке. Если строка уже находится в таблице, чтение продолжается, если нет, данная строка добавляется к таблице строк. Чем больше будет повторяющихся строк, тем сильнее будут сжаты данные. Возвращаясь к примеру с телефоном, можно, проведя весьма упрощенную аналогию, сказать, что, сжимая запись 233 34 44 по LZW-методу, мы придем к введению новых строк — 333 и 444 и, выражая их дополнительными символами, сможем уменьшить длину записи.
Какой же выбрать архиватор?
Наверное, читателю будет интересно узнать, какой же архиватор лучше. Ответ на этот вопрос далеко не однозначен.
Если посмотреть на таблицу, в которой «соревнуются» архиваторы (а сделать это можно как на соответствующем сайте в Интернете [3], так и на нашем CD-ROM), то можно увидеть, что количество программ, принимающих участие в «соревнованиях», превышает сотню. Как же выбрать из этого многообразия необходимый архиватор?
Вполне возможно, что для многих пользователей не последним является вопрос способа распространения программы. Большинство архиваторов распространяются как ShareWare, и некоторые программы ограничивают количество функций для незарегистрированных версий. Есть программы, которые распространяются как FreeWare.
Если вас не волнуют меркантильные соображения, то прежде всего необходимо уяснить, что имеется целый ряд архиваторов, которые оптимизированы на решение конкретных задач. В связи с этим существуют различные виды специализированных тестов, например на сжатие только текстовых файлов или только графических. Так, в частности, Wave Zip в первую очередь умеет сжимать WAV-файлы, а мультимедийный архиватор ERI лучше всех упаковывает TIFF-файлы. Поэтому если вас интересует сжатие какого-то определенного типа файлов, то можно подыскать программу, которая изначально предназначена специально для этого.
Существует тип архиваторов (так называемые Exepackers), которые служат для сжатия исполняемых модулей COM, EXE или DLL. Файл упаковывается таким образом, что при запуске он сам себя распаковывает в памяти «на лету» и далее работает в обычном режиме.
Одними из лучших в данной категории можно назвать программы ASPACK и Petite. Более подробную информацию о программах данного класса, а также соответствующие рейтинги можно найти по адресу [4].
Если же вам нужен архиватор, так сказать, «на все случаи жизни», то оценить, насколько хороша конкретная программа, можно обратившись к тесту, в котором «соревнуются» программы, обрабатывающие различные типы файлов. Просмотреть список архиваторов, участвующих в данном тесте, можно на нашем CD-ROM.
При этом необходимо отметить, что в тестах анализируются лишь количественные параметры, такие как скорость сжатия, коэффициент сжатия и некоторые другие, однако существует еще целый ряд параметров, которые определяют удобство пользования архиваторами. Перечислим некоторые из них.
Поддержка различных форматов
Большинство программ поддерживают один или два формата. Однако некоторые, такие, например, как программа WinAce, поддерживают множество форматов, осуществляя компрессию в форматах ACE, ZIP, LHA, MS-CAB, JAVA JAR и декомпрессию в форматах ACE, ZIP, LHA, MS-CAB, RAR, ARC, ARJ, GZip, TAR, ZOO, JAR.
Умение создавать solid-архивы
Создание solid-архивов — это архивирование, при котором увеличение сжатия возрастает при наличии большого числа одновременно обрабатываемых коротких файлов. Часть архиваторов, например ACB, всегда создают solid-архивы, другие, такие как RAR или 777, предоставляют возможность их создания, а некоторые, например ARJ, этого делать вообще не умеют.
Возможность создавать многотомные архивы
Многотомные архивы необходимы, когда файлы переносятся с компьютера на компьютер с помощью дискет и архив не помещается на одной дискете.
Возможность работы в качестве менеджера архивов
Различные программы в большей или меньшей степени способны вести учет архивам на вашем диске. Некоторые архиваторы, например WinZip, позволяют быстро добраться до любого архивного файла (и до его содержимого), в каком бы месте диска он ни находился.
Возможность парольной защиты
В принципе, архивирование есть разновидность кодирования, и если раскодирование доступно по паролю, то это, естественно, может использоваться как средство ограничения доступа к конфиденциальной информации.
Удобство в работе
Не последним фактором является удобство в работе — наличие продуманного меню, поддержка мыши, оптимальный набор опций, наличие командной строки и т.д. При этом необходимо отметить, что для многих (особенно непрофессионалов) важен фактор привычки. Если вы привыкли работать с определенной программой и вам сообщают, что есть альтернативная программа, которая на каком-либо тесте выигрывает у вашей десять пунктов, — это вполне может означать, что программа-победитель сжимает файлы лишь на 2% лучше, а для вас это не принципиально. При этом вероятно, что эта программа менее удобна в работе и т.д. Однако если вам не хватает именно 2%, чтобы сжать распространяемую вами программу до размера дискеты, то подобный архиватор для вас — находка.
Я отнюдь не сторонник консервативной позиции «раз все работает, то главное — ничего не менять», я лишь подчеркиваю, что переход на новую программу должен быть обоснованным.
- ПК и комплектующие
- Настольные ПК и моноблоки
- Портативные ПК
- Серверы
- Материнские платы
- Корпуса
- Блоки питания
- Оперативная память
- Процессоры
- Графические адаптеры
- Жесткие диски и SSD
- Оптические приводы и носители
- Звуковые карты
- ТВ-тюнеры
- Контроллеры
- Системы охлаждения ПК
- Моддинг
- Аксессуары для ноутбуков
- Принтеры, сканеры, МФУ
- Мониторы и проекторы
- Устройства ввода
- Внешние накопители
- Акустические системы, гарнитуры, наушники
- ИБП
- Веб-камеры
- KVM-оборудование
- Сетевые медиаплееры
- HTPC и мини-компьютеры
- ТВ и системы домашнего кинотеатра
- Технология DLNA
- Средства управления домашней техникой
- Планшеты
- Смартфоны
- Портативные накопители
- Электронные ридеры
- Портативные медиаплееры
- GPS-навигаторы и трекеры
- Носимые гаджеты
- Автомобильные информационно-развлекательные системы
- Зарядные устройства
- Аксессуары для мобильных устройств
- Цифровые фотоаппараты и оптика
- Видеокамеры
- Фотоаксессуары
- Обработка фотографий
- Монтаж видео
- Операционные системы
- Средства разработки
- Офисные программы
- Средства тестирования, мониторинга и диагностики
- Полезные утилиты
- Графические редакторы
- Средства 3D-моделирования
- Веб-браузеры
- Поисковые системы
- Социальные сети
- «Облачные» сервисы
- Сервисы для обмена сообщениями и конференц-связи
- Разработка веб-сайтов
- Мобильный интернет
- Полезные инструменты
- Средства защиты от вредоносного ПО
- Средства управления доступом
- Защита данных
- Проводные сети
- Беспроводные сети
- Сетевая инфраструктура
- Сотовая связь
- IP-телефония
- NAS-накопители
- Средства управления сетями
- Средства удаленного доступа
- Системная интеграция
- Проекты в области образования
- Электронный документооборот
- «Облачные» сервисы для бизнеса
- Технологии виртуализации
1999 1 2 3 4 5 6 7 8 9 10 11 12 2000 1 2 3 4 5 6 7 8 9 10 11 12 2001 1 2 3 4 5 6 7 8 9 10 11 12 2002 1 2 3 4 5 6 7 8 9 10 11 12 2003 1 2 3 4 5 6 7 8 9 10 11 12 2004 1 2 3 4 5 6 7 8 9 10 11 12 2005 1 2 3 4 5 6 7 8 9 10 11 12 2006 1 2 3 4 5 6 7 8 9 10 11 12 2007 1 2 3 4 5 6 7 8 9 10 11 12 2008 1 2 3 4 5 6 7 8 9 10 11 12 2009 1 2 3 4 5 6 7 8 9 10 11 12 2010 1 2 3 4 5 6 7 8 9 10 11 12 2011 1 2 3 4 5 6 7 8 9 10 11 12 2012 1 2 3 4 5 6 7 8 9 10 11 12 2013 1 2 3 4 5 6 7 8 9 10 11 12