Я не совсем понимаю как работает Intellij Idea и как она собирает мою программу. Можно краткий инструктаж в системы сборки и для чего они нужны? Ещё бы хорошо, если была бы инфа неустаревшая.
Отслеживать
задан 23 фев 2016 в 22:31
Dark Casual Dark Casual
136 1 1 серебряный знак 8 8 бронзовых знаков
А вы для начала попробуйте разработать небольшую программу (типа «Hello world») и собрать проект вручную без IDE. Крайне рекомендую так сделать. Вам это поможет разобраться.
24 фев 2016 в 6:04
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
TL;DR, к сожалению, не получилось.
Система сборки – это программное обеспечение, обеспечивающее автоматизацию сборки проекта. Основное отличие от IDE в том, что конфигурационный файл для системы сборки вы описываете в текстовом виде. Как следствие, быстрее можете начать проект, за счет того, что что все типовые задачи заключаются в копировании уже готовых сниппетов. Это гораздо быстрее, более гибко, мобильно, и, главное, читаемо, чем вводить то же самое через UI диалоги IDE.
Как в общих чертах работает ваша IDE:
Когда вы создаете проект, то IDE определяет некоторые source каталоги, в которых находятся исходные файлы вашего проекта. При запуске проекта эти файлы будут скомпилированы и переместятся в целевую директорию. Все это, как правило, легко меняется. Можно назначить дополнительные source каталоги, в которых IDE будет осуществлять поиск исходных файлов или поменять целевую директорию;
Если ваш проект использует библиотеки, то вы скачиваете их, складываете в определенную директорию, и подключаете их как зависимости вашего проекта. Таким образом IDE оповещается о том, что при запуске проекта, эти JAR-файлы будут находиться в classpath , она сама подставит их в ключ java –cp и начнет предоставлять типы и методы этих библиотек в автодополнении, и делать другие удобные вещи, для которых и предназначены IDE;
Проекту назначается соответствующая JDK, компилятор которой и будет компилировать классы;
Могут назначаться некоторые дополнительные опции, такие как переменные окружения, аргументы JVM и прочее;
IDE также может выполнять определенные задачи. Например, не только положить собранный проект в каталог сборки, или запустить его, но задеплоить его на удаленный сервер;
Настройки проекта IDE сохраняет в своем внутреннем формате, и складывает в виде файлов, иногда и дополнительных каталогов в директории проекта. Вся эта логика работает через UI диалоги, которые зачастую не очевидны и плохо описаны.
Очевидные недостатки, которые из этого следуют:
если в проекте несколько участников, они все должны использовать одну и ту же IDE и синхронизировать настройки при каждом изменении;
тыкать мышкой в кучу разных диалогов долго и неудобно;
Кроме того, если проект большой, его нужно каким-то образом поделить на модули, а также объявить какой модуль от какого зависит. Машина разработчика — не единственное место где нужно запускать проект — нужны конфигурации проекта для запуска в разных средах: разработка и продакшн, как минимум. Перед сборкой проекта также необходимо запустить интеграционные и юнит- тесты (иногда очень много), чтобы убедиться в отсутствии багов.
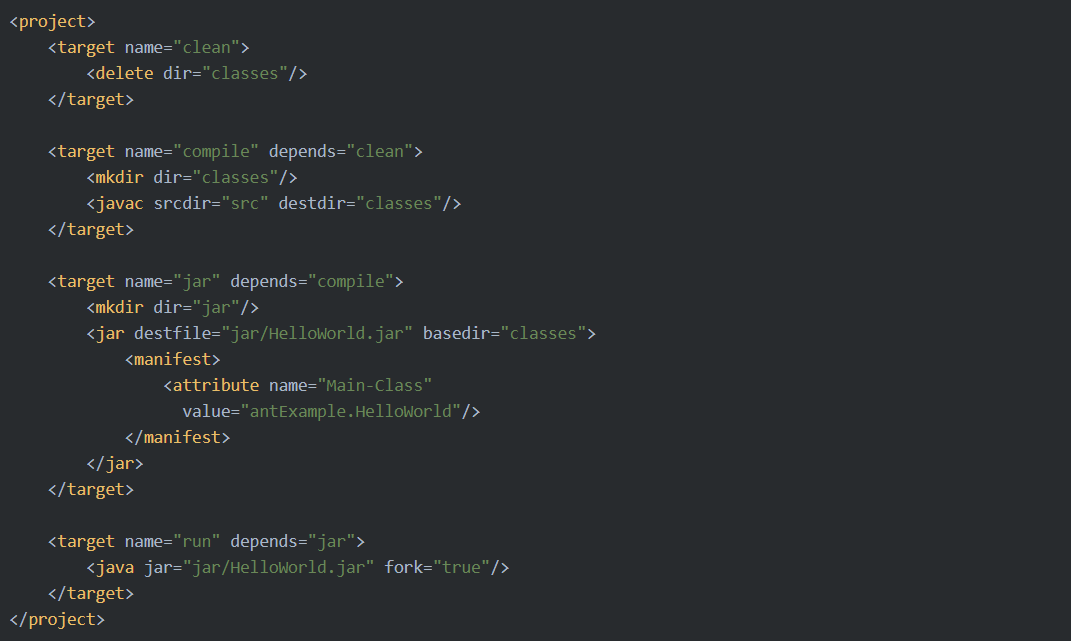
Первым для автоматизации этих задач появился Ant. Это аналог make-файла, а по сути набор скриптов (которые называются tasks). Ant – это пример императивного стиля описания сборки проекта. Вы описываете некое действие, например, скомпилировать файлы в директории проекта:
.. потом , скопировать их рабочую директорию
" includes="**/*.*" excludes="**/*.java"/>
И вот из таких маленьких кирпичиков, поэтапно собираете весь сценарий сборки проекта. А точнее, несколько сценариев для разных целей. Написав единожды хороший универсальный сценарий, можно копировать его в последующие проекты.
Удобно в Ant то, что вы имеете полный и наглядный контроль над сборкой проекта, а неудобно что вы описываете огромное количество очевидных задач, и по прежнему управляете зависимостями проекта вручную (существует возможность подключить Ivy для управления зависимостями).
Если вы хотите именно пошагового понимания, что делает IDE за ширмой — соберите проект с помощью Ant.
Правда жизни состоит в том, что большие проекты используют большое число библиотек, причем библиотека A, от которой зависит ваш проект, может в свою очередь зависеть еще от десяти других, и из этих десяти, половина будет пересекаться с другими зависимостями, от которых зависят ваши библиотеки, включенные в ваш проект 🙂
На смену Ant пришел Maven, который не такой гибкий, но значительно сокращает объем рутинной работы. Основные особенности:
Конфигурация Maven — это один файл pom.xml ;
Из коробки поддерживаются различные типы сборки: JAR, WAR, EAR;
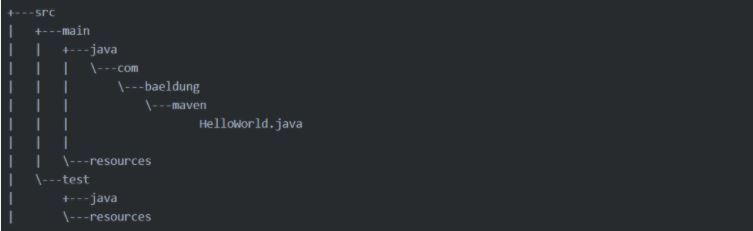
Введена стандартная структура каталогов для проекта. Это сделано для того, чтобы по умолчанию вам не нужно было объяснять системе сборки, где лежат исходные файлы, ресурсы и куда их нужно переместить после компиляции;
Цикл сборки разбит на phases (фазы). Каждая фаза включает в себя определенный стандартный сценарий, который называется goal (цель) . Упрощенно, вы указываете до какой фазы нужно выполнить проект (например, только скомпилировать), и выполняется набор сценариев связанных указанной и предыдущими фазами build lifecycle. Дополнительные сценарии реализуются через плагины к Maven;
Поддерживается модульная архитектура проекта. Можно объявлять зависимости между модулями;
Поддерживаются профили. Это возможность, которая позволяется выполнять сборку проекта для различных окружений (машин) по-разному. Например, в профиле для разработки приложения определяются настройки и плагины, которых нет в профиле для продакшена, и наоборот. Т.е. можно, например, иметь разные настройки для подключения к базе данных для рабочей машины и сервера, где будет разворачиваться приложения. Или добавить профиль для развертывания среды окружения, который содержит только плагины и скрипты, которые подготовят ваше рабочее место при переезде с места на место. Название профиля передается как опция (ключ -P ) к сборке проекта;
Для централизованного хранения библиотек введен центральный репозиторий. Все популярные библиотеки публикуются и периодически обновляются в центральном репозитории. Каждая библиотека уникально идентифицируется по параметрам: groupId, artifactId, version. Вам не нужно скачивать зависимости и хранить их где-то вместе с проектом, они объявляются декларативно в теге dependency и скачиваются автоматически при сборке проекта.
Maven выполняет автоматическое разрешение зависимостей (так называются библиотеки, от которых зависит ваше приложение). Таким образом, например, если библиотека A зависит от библиотеки C, и библиотека B зависит от библиотеки C, но эти C – разных версий, Maven автоматически включит в проект только последнюю версию C (иногда это минус, но все настаивается). Также просто, например, проверить не появились ли новые версии для библиотек, входящих в состав проекта:
Поскольку зависимости выкачиваются автоматически, очень удобно делить проект между участниками команды. Предположите, как-бы вы управляли большим числом зависимостей вручную;
Maven поддерживает архетипы. Это предопределенная структура проекта (шаблон) для быстрого начала разработки приложения. При создании проекта вы можете указать архетип, и вот уже есть некая начальная заготовка. Естественно, можно создавать собственные.
Для Maven есть огромное число полезных плагинов. Основной недостаток, которым ему обычно пеняют, вытекает из его преимуществ. Декларативный стиль описания задач не позволяет так же просто “подшаманить” в определенных случаях, как это делает Ant. Но и это обычно решается через через различные плагины. Например, задачм Ant можно запускать из Maven через antrun-plugin.
Нужно отметить, что когда вы работаете с Maven проектом в IDE, настройки извлекаются именно из Maven. Например, через compiler-plugin проекту указывается версия JDK:
Все IDE на сегодняшний момент хорошо хорошо работают с Maven — можно использовать любую. UI диалог IDE для запуска Maven проекта — это обертка, при желании вы можете работать в ним из командной строки.
За Gradle не скажу, потому что игрался, но вплотную не использовал.
Резюме: если вы учитесь или делаете тестовый проект без зависимостей на час — IDE нормальный вариант — хотя сейчас все туториалы тоже пишутся под Maven или Gradle. Для остального — система сборки.
Обновление:
Как вам правильно указал @Arsenicum, проект можно собрать и без участия IDE и систем сборки. JDK (Java Development Kit), которое необходимо для разработки, как раз и состоит из виртуальной Java машины (JRE) — это среда исполнения или рантайм, и Development Tools — это инструменты среды разработки.
Development Tools — это набор, в основном, консольных утилит. Они находятся в директории $JAVA_HOME/bin . Полный список тут. Умение напрямую работать с утилитами из набора Basic Tools (особенно jar, java, javac, javadoc), несомненно поможет лучше ориентироваться в вопросах запуска и сборки Java приложений.
Системы сборки на Java
При изучении любого языка программирования и написании учебных программ достаточно только среды разработки, где код можно скомпилировать и запустить, но для промышленных проектов нужно обязательное знание систем сборщиков. В этой статье разберемся, зачем они вообще нужны и какие существуют для Java.
Зачем нужна система сборки
Когда компьютеры только начинали свое существование, системы сборки не были нужны, программы писались под определенные ЭВМ. С развитием индустрии серверы для разработки отделились от промышленных(“продакшен”) серверов, на которых разработанные приложения должны были использоваться.
Вы можете запускать приложения в среде разработки, но тогда вам понадобится установить ее на все компьютеры заказчика, разложить исходные коды по нужным папкам, установить все требуемые библиотеки и так далее. Очевидно, что это неудобно.
Поэтому и появились системы сборки: они не зависят от IDE и автоматически выполняют действия, перечисленные выше.
Какие бывают системы сборки
Система сборки — это скриптовый код, написанный обычно на определенном языке программирования. Следовательно, для каждого языка они разные. Большинство основаны на самом первом сборщике — Linux-утилите make. Она использует специальные make-файлы, в которых подробно расписаны зависимости файлов друг от друга и порядок их сборки. Этот подход появился еще в 1976 и использовался всеми языками программирования, в том числе Java до разработки собственного средства.
Давайте узнаем подробнее о сборщиках Java.
Первым из них был Apache Ant (Another neat tool). По схеме работы очень похож на утилиту make, но вместо make-файла, состоящего из команд Bash, использует файл формата XML. Вот пример build.xml файла для простого проекта “Hello World”.
Фазы сборки называются целями (). В этом файле их 4: clean, compile, jar и run. Например, при вызове
Сначала отработает clean, который удалит каталог «classes». После этого compile заново создаст каталог, который скомпилируется в папку src, все как определил разработчик. И вообще, поскольку Ant не навязывает никаких соглашений о структуре проекта, программисты сами пишут все команды и определяют порядок сборки.
Что не так?
Ant-файлы могут разрастаться до нескольких десятков мегабайт по мере увеличения проекта. Здесь все выглядит неплохо, но на промышленный проектах они длинные и неструктурированные, а потому сложны для понимания.
Что привело к появлению новой системы
Apache Maven
Хоть он также использует XML для построения конфигурации (файл называется POM.xml), но имеет серьезные отличия:
1. Здесь есть четкая структура каталогов, и вы обязательно должны ей следовать. (При использовании плагинов IDE, она создается автоматически).Она выглядит вот так:
И если вы, к примеру, поместите файл с тестами в папку с ресурсами, то ваше приложение просто не скомпилируется.
Также у каждого проекта может быть только один файл JAR файл, тогда как при сборке Ant модификации были безграничны: вы вообще можете добавить файл в какую угодно папку, собрать 5 классов в 3 JAR-а и так далее. Все это, безусловно, ухудшало поддерживаемость кода.
2. Автоматическое управление зависимостями
В промышленных проектах зависимостей очень много. В Ant вы должны все скачать вручную, распаковать, подключить и обязательно помнить, какую вы используете версию. А вот Maven все делает сам, только напишите, что вам нужно.
3. Стандартизированные названия билдов
Каждый билд имеет атрибуты groupId, artifactId и version. Первые два уникальны и используются для определения в репозитории. Обычно groupId — доменное имя организации, а artifactId — название текущего проекта. Поэтому эта пара и является определяющей: нет двух компаний с одинаковым доменом, как и не существует двух одинаковых проектах в одной компании.
4. Жизненный цикл и плагины
Жизненный цикл maven-проекта — это список фаз, определяющий порядок действий при его построении. Он содержит три независимых порядка выполнения: clean, default и site.
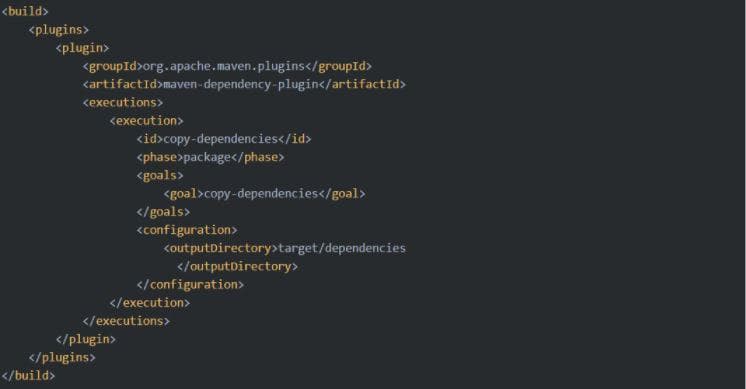
Для расширения и модификации стандартных ЖЦ используются плагины. Ниже представлен пример плагина, который копирует зависимости в ваше директорию.
Плагины, хоть и предоставляют программистам дополнительные возможности, но Maven не дает большой свободы модификаций. Программисты решили взять лучшее из двух миров и разработали Gradle.
Gradle
Оба, и Ant, и Maven используют XML для конфигурирования сборки. Gradle — предметно-ориентированный язык на основе Groovy. И это его основное отличие от Maven. В остальном Gradle руководствуется теми же принципами. Здесь за выполнение всей работы также ответственны плагины и нет широкой свободы действий.
Приведем пример файла build.gradle для того же проекта с HelloWorld
Gradle распространен в мобильной Android- разработке, а Maven используется в системах управления предприятиями. Почему так? Вопрос остается открытым. Возможно, так просто сложилось. Но Maven все-таки гораздо популярнее на рынке и будет полезен Java-разработчикам в любом случае.
Интегрированная система автоматизации сборки микрообъективов Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Падун Борис Степанович, Латыев Святослав Михайлович
Рассматривается процесс автоматизированной сборки микрообъективов, который основан на предварительном моделировании процесса этой сборки. Представлена концепция построения системы автоматизированной сборки. Описаны состав и структура интегрированной системы сборки, технологическая система и программные средства управления сборкой, а также проектирования виртуальной сборки.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Падун Борис Степанович, Латыев Святослав Михайлович
Оптимизация процессов сборки микрообъективов
Особенности проектирования захватных устройств для повышения гибкости автоматизированных и роботизированных технологических линий приборостроительных производств
Проект линии автоматизированной сборки микрообъективов
Создание имитационной модели сборочной линии с использованием системы delmia
Организация управления технологической системой автоматизированной линии сборки микрообъектива i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы. i Надоели баннеры? Вы всегда можете отключить рекламу.
INTEGRATED SYSTEM OF AUTOMATED ASSEMBLY OF MICROLENSES
The process of automated assembly of microlenses based on preliminary modeling of the process is considered. Design concept is presented of automated assembly system, the assembly technology and the system composition and structure are described. Program means to be used in assembly control and virtual assembly design are outlined.
Текст научной работы на тему «Интегрированная система автоматизации сборки микрообъективов»
Б. С. Падун, С. М. Латыев
ИНТЕГРИРОВАННАЯ СИСТЕМА АВТОМАТИЗАЦИИ СБОРКИ
Рассматривается процесс автоматизированной сборки микрообъективов, который основан на предварительном моделировании процесса этой сборки. Представлена концепция построения системы автоматизированной сборки. Описаны состав и структура интегрированной системы сборки, технологическая система и программные средства управления сборкой, а также проектирования виртуальной сборки.
Ключевые слова: технологическая система сборки, микрообъектив, автоматизация сборки, виртуальная сборка.
Введение. Требования к точности функционирования приборов, в частности микрообъективов (МО), постоянно возрастают, достичь ее за счет уменьшения погрешности изготовления деталей и узлов в некоторых случаях невозможно, поэтому необходимо искать новые пути обеспечения точности приборов. Один из путей — обеспечение функциональной точности при сборке прибора путем использования таких методов, как, например, селективная сборка, применение компенсаторов, коррекция элементов изделия. Характерное организационное отличие этих методов — зависимость операций сборки от операций формообразования.
Второй путь — обеспечение функциональной точности приборов за счет коррекции формообразующих операций. В этом случае организуется обратная связь между сборочной и формообразующими операциями, здесь можно выделить два метода: организация обратной связи во время изготовления конкретного изделия и организация обратной связи на основе предварительного прогноза изменения параметров оснащения. Первый метод получил название „адаптивно-селективная сборка» (АСС) [1], второй назовем методом перспективного прогноза [2].
Следует отметить, что и первый, и второй путь предполагают использование дополнительных измерительных операций, которые могут выполняться до, во время и после сборки. В настоящей работе для достижения заданной точности при сборке МО выбран второй путь.
Концепция построения системы сборки микрообъективов. Основная идея концепции — это сборка МО по результатам виртуальной сборки, которая проводится с использованием математических моделей, описывающих функциональную точность МО [3]. Позволяет реализовать виртуальную сборку специальная программная система, задача которой определить из заданных множеств деталей и узлов МО те, которые могут обеспечить при совместной сборке требования по точности конкретного объектива. Следовательно, интегрируются технологическая система сборки (ТСС) и система автоматизированного проектирования виртуальной сборки (САПР ВС).
Нетрудно заметить, что ТСС должна содержать средства измерения деталей и узлов, от которых зависит функциональная точность МО, а для реализации и качественного обеспечения спроектированной виртуальной сборки целесообразно автоматизировать процесс сборки. Следует назвать еще несколько принципов проектирования ТСС:
1) линии сборки и склады рассматриваются как единая система. Сборочные действия на линии в общем случае не согласуются по времени их выполнения, поэтому для их синхронизации предусмотрена организация „разделяющих» складов, в которых хранятся детали, узлы и собранные изделия;
2) прямоточность движения собираемого изделия на линиях;
3) замыкание линии и оперативная программная переадресация транспортных тележек (шаттлов). Это обеспечит выполнение операций на ТСС в любой последовательности;
4) возможность перехода без существенных потерь времени от сборки МО одного наименования к сборке МО другого наименования, основанная на унификации конструкций МО [4] и технологий их изготовления [5], что позволит обеспечить рабочие места типовой и групповой технологической оснасткой.
Состав и структура интегрированной системы. В соответствии с концепцией построения системы сборки в ней предусмотрено пять компонентов (рис. 1):
1) автоматизированная складская система, предназначенная для накопления, хранения и учета деталей, сборочных единиц и МО, а также синхронизации операций сборки и контроля. В состав складской системы входят мобильные склады (М1 и М2), подключенные к стационарному через порты приема (Р — подвижный робот, обслуживающий стационарный склад);
2) линия „измерений изделий и сборки узлов МО». По результатам работы этой линии формируются базы данных об изделиях, в которых каждой измеряемой детали и узлу присвоено оригинальное имя, выполняется виртуальная сборка узлов и МО в целом, проектируются технологические процессы сборки и алгоритм управления линией сборки;
3) линия сборки МО (работает на основе результатов виртуальной сборки);
4) автоматизированная система управления (АСУ) ТСС;
5) САПР ВС, которая проектирует технологические процессы сборки и схемы эксплуатации оборудования.
Стационарный склад деталей и сборочных единиц
Линия измерений и
сборки узлов (сборка партиями)
Линия сборки микрообъективов (поточная параллельная сборка)
Автоматизированная система управления ТСС
Система автоматизированного проектирования ВС
На линии измерений деталей и сборки узлов МО параллельно выполняются сборочные операции. Предусмотрены три станции (рис. 2, а): комплектации и сборки (1), бесконтактного (2) и контактного измерения изделий (3). На линии сборки МО осуществляется поточная параллельная сборка, на ней предусмотрены пять станций (рис. 2, б): сборки стакана (4), контроля изображения (5), сборки корпуса (6), контроля высоты МО (7) и окончательной сборки
МО (5). Транспортная связь между зонами обеспечивается через стационарный склад. Мобильные склады позволяют обеспечить транспортную связь между цехами формообразования и сборочными линиями. Нетрудно заметить, что АСУ объединяет в единое целое все компоненты ТСС. Автоматизированная система управления информационно связывает ТСС с САПР ВС.
Алгоритм работы ТСС. В системе можно выделить четыре основных типа транспортных потоков, если рассматривать склад (см. рис. 1) как начальную и конечную точки потоков:
1) измерительный — поток деталей или узлов, проходящий только через одну операцию измерения;
2) комплектации и измерений узла — поток сборки, проходящий через операции сборки и измерения. Данный поток определяет размещение станций на первой линии (рис. 2, а);
3) подготовительный — поток для заполнения буферных накопителей (лифтовых складов) на станциях тарами с деталями и узлами. Буферные накопители предназначены для того, чтобы создать страховочные (например, линзы, оправы, прокладные кольца) и технологические (например, сборочные единицы „линза в оправе») запасы и обеспечить эффективную организацию контрольных операций;
4) потоки, проходящие через операции сборки МО. Эти потоки могут быть разветвляющимися вследствие неудовлетворительного результата контрольных операций (см. рис. 2, б).
Такое разделение транспортных потоков закладывается в базовый алгоритм работы ТСС: измерение линз и оправ ^ комплектация, сборка и измерение узлов „линза в оправе » ^ измерение механических деталей ^ комплектация деталей в буферных накопителях ^ сборка МО.
Измеренные детали и узлы накапливаются в стационарном складе до момента использования при сборке линзы. Данные об измерении деталей и узлов автоматически накапливаются в базе данных.
В реальной ситуации алгоритм сборки МО может иметь другой порядок действий либо может усложниться за счет организации параллельного измерения партий разных объектов или за счет совмещения во времени второго и первого потоков, либо упроститься за счет разделения во времени процессов комплектации и измерения узлов и т. п.
Автоматизированная система управления ТСС строится как четырехуровневая. Средствами управления первого уровня решаются задачи управления отдельными элемента-
ми ТСС, например, приводом робота, перекладчиком, шаттлом и т.д. В средства управления отдельного элемента первого уровня включаются один или несколько контроллеров и одна или несколько типовых программных функций управления конкретным элементом ТСС. На данном уровне средства управления объединяют отдельные элементы.
На втором уровне средства управления координируют работу оборудования, выполняющего конкретную сборочную операцию, например, измерительную, складскую, сборки узла „линза в оправе» и т.д. Каждая единица оборудования, функционирующая независимо и параллельно, рассматривается как единое целое. Средства управления второго уровня в общем случае включают компьютер (контроллер или вычислительный комплекс) и программы, которые передают данные, обрабатывают прерывания, передают управление программам первого уровня и т.д. Одной из основных функций средств управления второго уровня является синхронизация темпа работы компонентов исполнительной системы с темпом работы оборудования в соответствии с заданной технологией изготовления изделий. Синхронизация выполняется путем инициирования работы соответствующих компонентов в заданные моменты времени, согласно циклограмме (временной диаграмме) функционирования элементов ТСС и программ средств управления, а также текущему состоянию каждого элемента ТСС. Средства управления второго уровня объединяют оборудование станций в единое целое, а оборудование склада — в единый стационарный склад.
На третьем уровне координируется работа станций конкретной линии и стационарного склада. Станции рассматриваются на данном уровне как неделимые единицы. Средства управления третьего уровня включают компьютер и программы, которые передают данные (технологические процессы), обрабатывают прерывания, передают управление программам второго уровня, выполняют программу (технологический процесс) работы линии, обеспечивают необходимые условия эксплуатации линии или склада. На этом уровне также выполняется синхронизация функционирования станций путем инициирования их работы в заданные моменты времени согласно текущему состоянию станций и по определенной временной диаграмме. Средства управления третьего уровня объединяют станции в неделимую линию, стационарный и мобильные склады — в единую складскую систему.
На четвертом уровне осуществляется координация работы складской системы с работой линии сборки. Средства управления четвертого уровня включают компьютер и программы, которые выполняют спроектированную дисциплину работы всей ТСС. Особенно важно согласовать работу робота-штабелера с состоянием позиций приема и съема тары на линиях. Программное обеспечение (ПО) четвертого уровня включает программную систему контроля ТСС и контроля технологии сборки, оно функционирует в диалоговом режиме с пользователем.
Следовательно, АСУ ТСС работает:
— в режиме реального времени, когда она управляет аппаратной частью технологической системы или принимает данные от измерительных станций;
— в диалоговом режиме, когда выполняется настройка системы или анализируются работа и состояние компонентов ТСС, или формируются отчеты по выполнению производственных функций.
Управление и контроль процесса сборки ведется с учетом результатов виртуальной сборки.
Система автоматизированного проектирования ВС. Программное обеспечение САПР ВС состоит из четырех компонентов (рис. 3): управляющей программы „монитор», системы моделирования сборки изделия, системы визуализации процесса сборки изделия, банка данных. Компоненты „монитора» работают в диалоговом режиме. Системы моделирования (иначе — виртуальной сборки и визуализации) функционируют в автоматическом режиме. Банк данных работает в автоматическом и диалоговом режимах.
Для повышения гибкости линии сборки предусмотрена программная система проектирования технологии сборки изделий, которая способна при выполнении некоторых требований обеспечить такой вариант технологического процесса сборки нового изделия, который может быть реализован на ТСС. Данная система может быть информационно связана с АСУ ТСС и САПР ВС.
Монитор автоматизированной системы
Система моделирования сборки изделия с подбором деталей для сборки
Компонент выбора команд
Система визуализации процесса сборки изделия
Комплекс моделирования сборки „линза в оправе»
Комплекс моделирования сборки микрообъектива
Комплекс моделирования высоты микрообъектива
Комплекс визуализации процессов на линии 1
Комплекс визуализации процессов на линии 2
Комплекс визуализации процессов в складской зоне
Комплекс визуализации процессов всей ТСС
Рассмотренный подход позволяет обеспечить системе сборки ряд полезных свойств, а именно:
— параллельность выполнения сборочных операций при выходе на устойчивый режим работы ТСС, что является следствием независимой работы линий и станций;
— адаптивность, которая обеспечивается моделированием технологических процессов (и выбором оптимального варианта) при изменении запросов деталей и узлов на стационарном складе;
— оперативность корректировки технологических процессов сборки, которая достигается благодаря возможностям САПР ВС;
— возможность эволюции системы за счет применения методов адаптивно-селективной сборки и перспективного прогноза (применение этих методов не только уменьшает ограничения по объему партии, но и позволяет изменить базовый технологический процесс сборки);
— возможность использования станций комплектации и сборки для оптимизации размещения деталей в таре;
— система сборки строится как прототип будущих производственных систем сборки.
Заключение. Предложенный подход уже сегодня является „полигоном» для проведения
научных и практических работ по исследованию и изучению методов обеспечения функциональной точности оптических приборов на этапе их сборки, исследованию методов измерений и созданию стендов для контроля качества прибора, исследованию способов автоматизации сборочных операций и созданию линий сборки, разработке автоматизированных систем управления ТСС и проектирования технологических операций сборки.
В проекте участвуют творческие коллективы специалистов России и Германии, организованы группы преподавателей, аспирантов и студентов разных кафедр, работающих над комплексными проблемами.
1. Zocher K.-P. Adaptive und Selektive Montage in der flexiblen Fertigung // Informationsmaterial TU Ilmenau. 2002.
Februar. S. 423—424.
Оптимизация процессов сборки микрообъективов
2. Падун Б. С., Свердлина И. И. Новый подход к организации технологической подготовки производства с элементами управления точностью // Инструмент и технологии. 2004. № 21—22. С. 99—104.
3. Латыев С. М., Смирнов А. П., Воронин А. А., Падун Б. С., Яблочников Е. И., Фролов Д. Н., Табачков А. Г., Тезка Р., Цохер П. Концепция линии автоматизированной сборки микрообъектива на основе адаптивной селекции их компонентов // Оптич. журн. 2009. Т. 76, № 7. С. 79—83.
4. Tabachkov А. G., Frolov D. N., Latyev S. M., Zocher K.-P. Die Haupttendenzen der Projektierung der Microobjektive // 50th Intern. Wissencschaftliches Kolloquium. TU Ilmenau. 2005. S. 535—536.
5. Митрофанов С. П. Групповая технология машиностроительного производства. Л.: Машиностроение, 1983.
Борис Степанович Падун
Святослав Михайлович Латыев
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Рекомендована кафедрой технологии приборостроения
Сведения об авторах
канд. техн. наук, доцент; Санкт-Петербургский государственный университет информационных технологий, механики и оптики, кафедра технологии приборостроения; E-mail: bsp.tps.ifmo@mail.ru д-р техн. наук, профессор; Санкт-Петербургский государственный университет информационных технологий, механики и оптики, кафедра компьютеризации и проектирования оптических приборов; E-mail: latyev@qrv.ifmo.ru
Поступила в редакцию 14.12.09 г.
Т. И. Алиев, Б. С. Падун ОПТИМИЗАЦИЯ ПРОЦЕССОВ СБОРКИ МИКРООБЪЕКТИВОВ
Рассматриваются концептуальная и стохастические модели, а также подходы к оптимизации технологического процесса функционирования линии сборки.
Введение. Высокая стоимость создания и обслуживания современного интеллектуального оборудования, к которому относится автоматизированная технологическая линия сборки (ТЛС) микрообъективов (МО), выдвигает на первый план задачу его эффективного использования. На данном этапе для современной экономики подобные задачи являются первоочередными. Поэтому необходима оптимизация процессов, выполняемых ТЛС, состав и концепция построения которой подробно описаны в работе [1].
— Технологический процесс функционирования (ТПФ) ТЛС представляет собой совокупность действий, выполняемых на линии во время изготовления МО (сборка узлов и МО, перемещение объектов — деталей, узлов и МО, измерение деталей и узлов, контроль качества собранных узлов, складирование объектов, комплектация деталей и узлов, передача данных, ожидание). ТПФ имеет несколько уровней декомпозиции: уровень ТЛС, уровень зон и стационарного склада, уровень станций и транспортных линий, уровень отдельных устройств.
— Материальные потоки — это движение тары, деталей и узлов в ТЛС МО. Потоки вне станций — это потоки тары, на станциях — это потоки деталей и узлов.
— Виртуальная сборка — это процесс проектирования ТПФ, на котором по результатам измерений деталей и узлов определяются элементы, входящие в конкретный МО.
Постановка задачи. Следует определить загрузку ТЛС в целом и ее отдельных компонентов, оценить время сборки МО и возможность выполнения заказа в заданные сроки,
Делаем свою простейшую систему сборки для Java
Довелось мне обучать одного знакомого, желающего войти в ИТ (привет, Саша!). Человек он упорный, прошел разные курсы, стажировки, упорно продолжает идти вперед и уже вполне тянет на уровень джуна. Но иногда внезапно задает такие вопросы, из которых я понимаю, что у него огромные дыры в базовых знаниях и представлениях. На курсах этому, видимо, не учат.
Один из последних вопросов был про устройство сборки. И он показал явное непонимание того, как исходный код собирается в исполняемый файл и запускается. Начинающим обычно говорят в духе «вот создаешь Gradle-проект, в IDE жмешь кнопочку запуска и все работает». Gradle/Maven при этом представляются таким черным ящиком, в котором есть кнопка сборки и запуска, а внутри — черная магия. И как только возникает необходимость что-то в этом простом процессе изменить или понять — начинаются проблемы.
В этой статье я пробегусь по основам того, как в Java работает компиляция, а также покажу, как по шагам прийти к идее необходимости системы сборки и как написать свою простенькую систему. Ведь лучший способ понять, как что-то устроено внутри — сделать это самому.
.java и .class
Сперва небольшой ликбез.
Итак, наша Java (и прочие JVM языки такие как Kotlin) является языком с промежуточным байт-кодом.
Мы пишем исходный код на Java, сохраняем его в текстовом .java файле. Затем с помощью компилятора javac , идущего в комплекте поставки JDK, мы компилируем наш текст в байт-код в виде .class файла. Это уже бинарный файл, содержащий инструкции для виртуальной машины. Инструкции там примерно такие же, как и в любом другом машинном коде — сложить пару чисел, переместить содержимое из одной ячейки памяти в другую, вызвать указанный метод и т.п.
Полученный .class можно уже запустить с помощью специального приложения — виртуальной машины Java, JVM.
Зачем вся эта бодяга и почему бы сразу не исполнять наш код напрямую? Изначально идея была в том, чтобы единожды скомпилировав наше приложение в .class, мы потом могли запустить его на любой платформе, где есть JVM, хоть Windows, хоть Linux, хоть Java ME (помнит еще кто эту технологию?). В отличие от программ на других языках, которые сразу компилируются в нативный код, но он — разный для разных платформ, и чтобы запустить приложение на новой платформе его потребуется скомпилировать специально под нее.
То есть «другие» языки:
Нужно иметь компилятор под каждую целевую платформу.
Разработчик должен собрать и выложить отдельно версии для каждой целевой платформы.
Если разработчик недоступен или ваша платформа ему не интересна, а исходного кода нет — запустить программу вы не сможете.
А для JVM-языков:
Нужно иметь разные JVM, а компилятор один (в те времена JVM была простой, а компиляторы — сложными, и это было преимуществом).
Имея скомпилированное приложение, вы можете запустить его на любой платформе, где есть JVM, от разработчика приложения вам ничего не нужно.
Вот и родился этот подход с промежуточным форматом. Но для сборки и запуска он да, представляет некоторые неудобства, ведь нужно научиться работать с двумя разными инструментами командных строки — компилятором javac и виртуальной машиной java .
Компилируем один файл
Итак, напишем простой HelloWorld:
public class HelloWorld < public static void main(String[] args) < System.out.println("Hello World"); >>
И теперь скомпилируем его вручную:
javac HelloWorld.java
Ура, мы получили .class файл. Можно заглянуть внутрь — увидим кучу разных байт. Это и есть инструкции JVM, плюс всякая служебная информация.
Дальше этот .class файл мы можем запустить в JVM. Для этого нам надо вызвать JVM ( java.exe ), сказать ей где искать наши классы ( -cp . говорит искать классы в этой же папке) и какой класс надо запустить (наш HelloWorld )
java -cp . HelloWorld
Все работает. javac скомпилировал из нашего исходного кода .class, а виртуальная машина Java запустила его и вывела результат.
Компилируем несколько файлов
Окей, один файл — это недостаточно по-джавовски. Маловато энтерпрайза и абстрактных фабрик. Давайте добавим еще два класса, делающих некую работу, и положим их в пакет print:
import print.*; public class HelloWorld < public static void main(String[] args) < IHelloWorldPrinter printer = new ConsoleHelloWorldPrinter(); printer.print("Hello World"); >> // print/IHelloWorldPrinter.java public interface IHelloWorldPrinter < public void print(String str); >// print/ConsoleHelloWorldPrinter.java public class ConsoleHelloWorldPrinter implements IHelloWorldPrinter < @Override public void print(String str) < System.out.println(str); >>
Теперь чтобы скомпилировать наше приложение надо передать javac уже три файла:
И JVM должна знать, где они все лежат, и ей тоже нужны все три чтобы запустить наше приложение. javac по умолчанию кладет скомпилированные .class файлы рядом с исходными .java файлами, так что нам надо указать java.exe что классы надо искать в том числе в папке ./print:
java -cp .;print HelloWorld
Добавим зависимость
Все еще недостаточно энтерпрайзнутости. Например, мы хотим выводить в консоль разными цветами. Для этого мы возьмем библиотеку JColor и добавим к проекту.
Возьмем где-то .jar файл (не важно где, на сайте автора, например). .jar по сути это просто .zip архив с теми же самыми .class файлами. Можно его открыть любым архиватором и убедиться:
Иногда, кстати, приходится внутри что-то смотреть или даже подменять, так что имейте в виду — всегда можно его распаковать и запаковать обратно.
Jar удобен чтобы не копировать кучу скомпилированных файлов по одному, можно засунуть в архив и распространять и использовать единым файлом.
Итак, слегка модернизируем наш CosoleHelloWorldPrinter, чтобы он печатал текст каким-нибудь другим цветом:
import com.diogonunes.jcolor.*; public class ConsoleHelloWorldPrinter implements IHelloWorldPrinter < @Override public void print(String str) < System.out.println(Ansi.colorize(str, Attribute.YELLOW_TEXT(), Attribute.MAGENTA_BACK())); >>
Если мы сейчас попробуем запустить javac , то он ругнется и скажет что не знает, где ему брать классы из пакета com.diogonunes.jcolor . Чтобы он их нашел — надо ему в явном виде указать путь к .jar файлу:
и на этапе запуска тоже, ведь java тоже ничего не знает про то, где искать нужные библиотечные классы во время выполнения программы:
Если вместо цвета в консоли у вас выводятся спецсимволы, значит в вашей Windows по умолчанию поддержка цветной печати отключена, как ее включить описано тут
Подведем итог:
Сперва нам необходимо превратить все .java классы нашего проекта в скомпилированные .class файлы. Для этого мы должны вызвать компилятор javac , передав ему все .java файлы и все дополнительные библиотечные классы и архивы.
Затем мы должны запустить полученные .class файлы в JVM. Для этого надо вызвать java , передав ей пути ко всем местам где лежат наши .class, а так же имя главного класса, с которого надо начинать выполнение программы.
Наведем порядок
Хм, что-то в нашей директории стало слишком много всякого хлама. Вперемешку лежат исходные коды .java, скомпилированные файлы .class, зависимости .jar.
Давайте наведем немного порядок и разложим все по папочкам:
В src положим исходный код
В lib положим зависимости
В out будем собирать наши class файлы
Дополнительно давайте положим весь исходный код в пакет helloworld . Использование классов без пакетов в Java приносит некоторые трудности. Так что переложим код в src/helloworld, и соответствующим образом изменим package и import директивы.
Нам потребуется немного модифицировать наши командные строки для сборки и запуска приложения:
Что-то мне надоело каждый раз прописывать вручную все имена файлов. А если мы добавим еще несколько .java с исходным кодом? Нам придется опять дописывать их к командным строкам запуска javaс и java . Очень легко что-то пропустить, забыть или перепутать.
Не, мыжпрограммисты. Давайте напишем скриптик, который компилирует все классы, лежащие в src. К сожалению, javac такого из коробки не умеет и может только обрабатывать список файлов, переданный в командной строке. Ничего, сгенерируем временный список со всеми исходными файлами с помощью команды dir, положим его во временный файл build/sources.txt, а затем прочитаем его через javac . Дополнительно еще переделаем вывод, сложим классы в out/classes:
А ведь .jar это удобно. Давайте сделаем сборку в него. Добавим еще строчку, собирающую содержимое нашей папки out
cd out/classes jar cf ../HelloWorld.jar .
Теперь вместо мешанины отдельных классов у нас есть один готовый файл нашего приложения, лежащий в out/HelloWorld.jar.
Автоматизируем
Заранее прошу прощения у всех линуксоидов, но напишу я скрипты свои на Windows Shell. Поскольку сейчас в моде Gradle, назовем наш скрипт microgradle.
Итак, на этапе сборки нам понадобятся все файлы лежащие в src и все .jar файлы лежащие в lib. Как было показано выше, сперва соберем исходные файлы из src в промежуточный файл, скормим его компилятору javac, получим собранные файлы в /out/classes, затем с помощью утилиты jar соберем это в архив.
На этапе запуска — возьмем все .jar файлы из out и lib и передадим их приложению java .
Добавим две команды для нашего скрипта, build для сборки и run для запуска:
@echo off if "%1"=="build" ( echo Building. mkdir build dir /s /B *.java > build/sources.txt javac -d out/classes -cp lib/*;src @build/sources.txt cd out/classes jar cf ../HelloWorld.jar . echo Build complete ) else if "%1"=="run" ( echo Running. call java -cp ./out/*;lib/* %2 ) else ( echo Unknown command: %1 )
Теперь можно выполнить microgradle build в папке с правильной структурой файлов, и наша микросборочная система все скомпилирует. А затем сделать microgradle run — и вуаля, мы получаем запущенное приложение
Ура, поздравляю, мы сделали простенькую систему сборки. Теперь можно создать нужную структуру папок, положить в них исходный код на Java и собирать или запускать его одной строчкой. Все как у больших Gradle/Maven.
Управление зависимостями
Конечно, про «все как у больших» я пошутил. Нашей системе не хватает еще как минимум одной очень важной вещи — управления зависимостями.
В примере выше мы просто откуда-то скачивали jar файл с библиотекой. Окей если такой файл один, вручную это сделать просто, но что если их много? Откуда их качать, где хранить?
Для решения этих вопросов в современные системы сборки встроены системы управления зависимостями. Вы в описании проекта лишь указываете, что вам нужна библиотека такой-то версии, а они дальше сами сходят в интернет в один из репозиториев, найдут там эту библиотеку, скачают jar файл и добавят его куда надо.
Репозитории поддерживаются различными организациями, как коммерческими так и нет. В Java-мире крупнейший такой репозиторий — Maven Central. Изначально, как понятно из названия, созданный для нужд системы сборки Maven, но через стандартный интерфейс им могут пользоваться и другие системы сборки и их встроенные системы управления зависимостями.
С репозиториями, кстати, иногда бывают проблемы. Недавно компания JFrog решила прибить свой репозиторий JCenter, который был вторым по популярности. Это сломало очень много билдов различных проектов, так как многие библиотеки, особенно для Android, выкладывались только туда (процесс публикации там был проще, чем в Maven Central).
Так что никакой магии тут нет. Есть онлайн-хранилища библиотек, которые кто-то поддерживает, крупные и малые (используя различное ПО вы можете создать и свое собственное приватное хранилище для своей организации). Авторы библиотек выкладывают свои .jar файлы туда, а затем различные системы сборки ищут и скачивают эти файлы оттуда.
Реализовывать свою собственную систему управления зависимости слишком сложно, и тут мы этого делать уже не будем. Но мы можем использовать готовую, например, Apache Ivy. Эта система встроена в систему сборки Apache Ant, но может использоваться и независимо, в виде отдельного консольного приложения.
Напишем файл ivy.xml с конфигурацией и положим в корень нашего проекта. Опишем тут, что для работы нашего проекта нам нужна библиотека JColor версии 5.5.1:
Положим в корень нашего проекта исполняемый архив Ivy (взять его можно с официального сайта) и допишем таск dependencies в наш скрипт microgradle
@echo off if "%1"=="build" ( echo Building. mkdir build dir /s /B *.java > build/sources.txt javac -d out/classes -cp lib/*;src @build/sources.txt cd out/classes jar cf ../HelloWorld.jar . echo Build complete ) else if "%1"=="run" ( echo Running. call java -cp ./out/*;lib/* %2 ) else if "%1"=="dependencies" ( echo Resolving dependencies. mkdir lib java -jar ./ivy-2.5.2.jar -retrieve "lib/[artifact]-[type]-[revision].[ext] ) else ( echo Unknown command: %1 )
Вуаля, теперь нам не нужно хранить нашу зависимость вручную в папке lib. Все что надо — прописать в нашем файлике, затем сделать шаг microgradle dependencies . Он запустит под капотом Ivy, который прочитает наш ivy.xml и скачает с репозитория Maven Central все что там написано в папку lib.
После этого шаг build уже подхватит эти скачанные .jar файлы и все соберет как надо.
Что дальше
Дальше можно придумывать много чего. Например, полноценные системы сборки не перекомпилируют файлы, если в них нет изменений, в отличие от нашей. А на проектах с сотнями файлов это важно. Полноценные системы имеют локальный кеш зависимостей, имеют конфигурируемые настройки, плагины, возможность создавать собственные шаги сборки и много-много чего еще.
Но наша микросистема уже имеет все основные черты настоящей системы сборки:
Имеет структуру папок и файлов с описанием проекта
Умеет скачивать зависимости
Умеет компилировать проект
Умеет запускать
Вполне достаточно для сборки маленького проекта.
Заключение
Этим туториалом я попытался показать, как вообще эти системы работают, а главное — зачем они нужны. Мы по шагам прошли от ручной компиляции отдельных файлов, которая с каждым шагом становилась все более сложной и громоздкой, к автоматической системе. Умеющей управлять зависимостями, автоматически подхватывать новые файлы, собирать и запускать наше приложение. Повторив тем самым в миниатюре эволюцию реальных систем.
Надеюсь, теперь Gradle или Maven не будут казаться вам черной магией, и станет немного понятнее, что там происходит под капотом.