Advanced Format, 512e
Advanced Format — формат разметки области хранения данных на жестких дисках нового поколения, выполненных по технологии 4K (использование физических секторов размером 4 килобайт вместо традиционных 512 байт), разработанный IDEMA Long Data Sector Committee. Технология впервые была применена в жёстких дисках Western Digital.
В настоящее время эта технология внедрена или внедряется всеми производителями жёстких дисков.
За счёт ликвидации лишних межсекторных промежутков удается выиграть примерно 7—11% полезного дискового пространства (по данным производителя). Также улучшается сохранность данных благодаря более эффективной системе исправления ошибок.
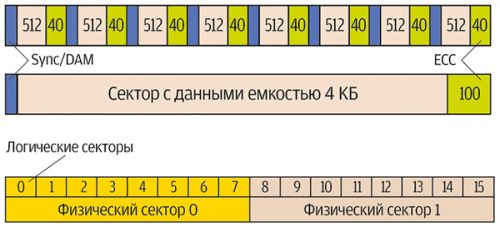
Однако длительное время размер сектора в 512 байт был стандартом де-факто, поэтому для работы с существующим программным обеспечением диски с технологией Advanced Format вынуждены эмулировать секторы такого размера, размещая в одном физическом секторе восемь логических.
Операционные системы Windows 7 и Windows Vista не требуют каких-либо мер для достижения оптимального быстродействия, уже поддерживая технологию Advanced Format, а для более старых ОС (в первую очередь — Windows XP) для выравнивания расположения логических секторов относительно физических необходимо воспользоваться программой WD Align, либо ее аналогами, для подготовки диска к работе под ОС Windows XP или перед клонированием диска, содержащего разделы с этой ОС. Также оптимизация возможна запуском этой программы уже после установки ОС.
Основным недостатком этой технологии является падение скорости работы с мелкими (менее 4096 байт) файлами по понятным причинам, однако если не произвести выравнивания разделов при установке или клонировании ОС, не имеющей встроенной поддержки 4K Cluster(другое название технологии Advaced Format), то могут наблюдаться более серьезные проблемы вплоть до трёхкратного падения скорости записи.
Получить дополнительные сведения о технологии WD Align и скачать программу WD Align можно на www.wdc.com
В настоящее время аналогичные технологии с 4Кб сектором стали применять в некоторых своих HDD фирмы Samsung и Seagate.
512e (emulation)
- Жесткие диски с поддержкой технологии Advanced Format не работают с контроллерами Adaptec Series 6 и ниже. Исключение — накопители из публикуемого Adaptec списка поддерживаемых контроллером HDD. К контроллерам Adaptec Series 6/6E относятся Adaptec ASR-6405, ASR-6805, ASR-6405E и другие.
- Для использования дисков с Advanced Format как загрузочных на контроллерах Adaptec Series 7/7E и выше активируйте UEFI Boot в настройках BIOS. Понадобятся поддерживающие загрузку UEFI современные материнская плата и операционная система. К жестким дискам с физическим сектором 4K и эмуляцией 512 байт (512e) указанное ограничение не относится. Накопители с эмуляцией 512e работают так же, как и традиционные диски с блоком в 512 байт.
- В самом неблагоприятном сценарии использования 4K-накопителей производительность падает в восемь раз. Это происходит, когда пишутся блоки объемом 512 байт или меньше, что случается редко. В компании Dell провели сравнительное тестирование дисков с блоками 4K и 512e. Графики отображают незначительное отставание накопителей с эмуляцией 512e:
Диски, контроллеры, ОС и Advanced Format

Казалось бы, что про диски Advanced Format за последние 4 года успели узнать все. Публикаций действительно много, но настало время рассмотреть все технические подробности и подводные камни в одной большой статье. Речь пойдёт об использовании AF-дисков в серверах, и я заметил, что для большинства администраторов даже в крупных компаниях знание предмета в большинстве случаев сводится к «это как-то связано с современными дисками, но у меня всё работает».
Что такое Advanced Format
Advanced Format — новый формат разметки секторов, используемый в некоторых жёстких дисках. Вместо традиционного сектора размером 512 байт используется 4096 байт. Некоторые диски SCSI/SAS/FC могут использовать 520- и 528-байтные «толстые» сектора для дополнительного контроля целостности данных, но это не относится к теме данной статьи.
Увеличение размера сектора в 8 раз связано с необходимостью повышения эффективности размещения данных на современных дисках. Накладные расходы, связанные с 512-байтной разметкой, начинают мешать дальнейшему увеличению ёмкости HDD. Помимо служебных полей в каждом 512-байтном секторе присутствует поле с кодом коррекции ошибок (ECC) длиной в 50 байт. В 4096-байтном секторе длина ECC-поля составляет 100 байт. Общее эффективность хранения данных удалось улучшить примерно на 10%.

Естественно, поддержка нестандартных секторов требуется со стороны дисковых контроллеров и операционных систем. Для решения проблем с совместимостью был ввёден дополнительный стандарт 512E, который обозначает диски с физическим размером сектора 4096 байт, но при этом эмулирующие обычный размер сектора в 512 байт. Advanced Format диски без эмуляции обозначаются 4KN. Таким образом, сейчас существует три варианта разметки:
| Формат | Логический размер сектора | Физический размер сектора |
| 512 байт | 512 байт | |
| 512 байт | 4096 байт (4КиБ) | |
| 4096 байт (4КиБ) | 4096 байт (4КиБ) |
Совместимость
Операционные системы
На первый взгляд кажется, что использование эмуляции 512-байтного сектора снимает все проблемы с совместимостью, но это не так. Во-первых, сразу же возникает проблема с производительностью. Что произойдет при записи блока размером 512 байт на диск с размером сектора 4096 байт (пусть и эмулирующий наличие секторов 512 байт)? Произойдёт классический процесс read-modify-write, вместо одной операции понадобится две: прочитать сектор 4096 байт, поменять в нём 512 байт (записываемый блок) и записать 4096 байт обратно. Аналогичная проблема проявляется и при отсутствии выравнивания, когда записываемый блок данных может быть достаточно большим и даже кратным 4096 байт, но при этом сдвинут относительно границ реальных секторов:
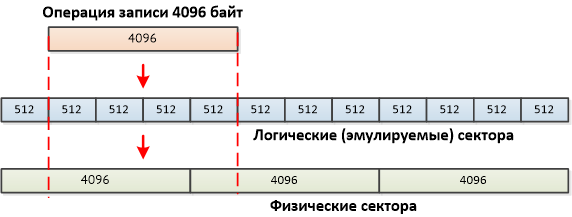
В современных условиях операции записи блоками меньше 4096 байт встречаются крайне редко, а вот проблема с выравниванием остаётся. Например, в старых Windows (до Windows Server 2008) при установке загрузочный раздел создаётся со смещением в 63 сектора. Так уж исторически сложилось с тех времён, когда BIOS использовал реальную геометрию диска вместо LBA. Разумеется, смещение в 63×512 не делится на 4096, что приводит к нарушению выравнивания для всех последующих разделов и снижению производительности. Впервые на данную проблему обратили внимание в связи с использованием RAID-контроллеров и необходимостью выравнивания разделов по границам страйпа и она была решена в Windows Vista/ Windows Server 2008 (и примерно в то же время — в других ОС) введением выравнивания по границам в 1024КиБ (1МиБ), т.е. первый раздел создается со смещением в 2048 512-байтных секторов.
Почему именно 1МиБ, если подойдёт меньшее смещение (главное — чтобы делилось на 4096 байт)? Просто потому, что нужен запас, ведь помимо физического диска в качестве блочного устройства могут выступать тома на RAID-контроллерах (с размером страйпа по умолчанию, например, у Adaptec в 256КиБ), SSD (с большим размером страниц) или образы дисков при использовании виртуализации, рекомендуемый размер NTFS-кластера для SQL или Exchange равен 64КиБ и т.д.
Проблема номер два — возможная потеря данных для сценариев с синхронной записью. Для ситуаций с записью блока меньше 4096 байт или невыравненного блока синхронной записи по факту не получится. Остаётся «научить» ОС не использовать при записи блоки меньше 4096 байт на диски 512E, но с этим есть определённые проблемы.
Microsoft
Для ОС Microsoft есть следующие официальные (первоисточник) данные:
- Windows 8, 8.1
- Windows Server 2012, 2012 R2
- Windows 7 w/ MS KB 982018
- Windows 7 SP1
- Windows Server 2008 R2 w/ MS KB 982018
- Windows Server 2008 R2 SP1
- Windows Vista w/ MS KB 2553708
- Windows Server 2008 w/ MS KB 2553708
- Windows 8, 8.1
- Windows Server 2012, 2012 R2
Обратите внимание на дополнительное напоминание о том, что Windows Server 2003 R2, Windows XP и другие ОС, основанные на кодовой базе XP (например, Windows Home Server 1.0, Windows Small Business Server 2003, 2003 R2), хоть и могут функционировать в связке с 512E дисками, но Microsoft предостерегает от использования таких дисков: если проблему с выравниванием ещё можно решить, то проблемы с производительностью или с потенциальной потерей данных при потере питания во время read-modify-write никак не обойти.
Проверить выравнивание существующих разделов и задать смещение для новых разделов в Windows можно при помощи diskpart. Пример (раздел на диске 0 со смещением в 1024КиБ или 2048 512-байтных секторов):
select disk 0 create partition primary align=1024
Проверить проще всего через WMI (пример):
wmic partition get Blocksize,StartingOffset, Name BlockSize Name StartingOffset 512 Диск #0, раздел #0 1048576 512 Диск #0, раздел #1 368050176 512 Диск #2, раздел #0 135266304 512 Диск #1, раздел #0 1048576
В колонке StartingOffset должно быть 1024КиБ для первого раздела, для остальных — должно делиться на 1024КиБ, это означает, что и на 4096 байт и все другие «хорошие числа» (размеры страйпов и NTFS-кластеров) всё будет делиться.
Напомню, что в современных Windows смещение в 1024КиБ и так используется по умолчанию, так что проверять/выставлять его вручную нужно лишь для ОС из «63-секторной» эпохи. При автоматическом создании GPT-разметки (через Disk Management) на 512N или 512E диске вы увидите смещение для первого раздела в 17КиБ. Это не повод для тревоги, так как это служебный раздел MSR. Первый стандартный раздел будет создан со смещением в 135266304 байт (129МиБ) — прекрасно делится на любое из наших «хороших чисел».
Linux
Таблица совместимости для Linux (приведены только распространённые серверные дистрибутивы):
Для других дистрибутивов можно ориентироваться на версию ядра (>2.6.31) и версии утилит для разбивки диска: GNU Fdisk >1.2.3 или GNU Parted >2.1
Посмотреть размеры физического и логического блоков можно в /sys/block/sdX/queue/physical_block_size и в /sys/block/sdX/queue/logical_block_size соответственно.
GNU Fdisk будет автоматически использовать смещение в 1МиБ при запуске с ключами -c и -u (отключить режим совместимости с DOS и использовать сектор в качестве единицы измерения). Обычный Fdisk не умеет работать с GPT, так что он бесполезен для дисков >2ТиБ, и нужно использовать Parted или GPT Fdisk. Последний по умолчанию использует для 512N/512E дисков нужное нам смещение в 2048 секторов:
Disk /dev/sde: 7814037168 sectors, 3.6 TiB Logical sector size: 512 bytes Disk identifier (GUID): BE7D7D71-F6ED-4371-ACFE-B04819A4DDC2 Partition table holds up to 128 entries First usable sector is 34, last usable sector is 7814037134 Partitions will be aligned on 2048-sector boundaries Total free space is 7814037101 sectors (3.6 TiB)
Пример для GNU Parted (для 512N/512E дисков):
# создаём новую GPT разметку mklabel gpt # создаём раздел на всё свободное пространство со смещением в 2048 секторов (parted) mkpart part1 2048s 100% (parted) print Model: ATA WDC WD40EFRX-68W (scsi) Disk /dev/sde: 7814037168s Sector size (logical/physical): 512B/4096B Partition Table: gpt Number Start End Size File system Name Flags 1 2048s 7814035455s 7814033408s part1
В LVM всё хорошо: смещение по умолчанию равно 1МиБ и размер PE (physical extent) кратен 1МиБ.
# проверяем смещение #pvs /dev/sde -o+pe_start PV VG Fmt Attr PSize PFree 1st PE /dev/sde VolRed lvm2 a-- 3.64t 3.64t 1.00m # проверяем размер PE #pvdisplay /dev/sde --- Physical volume --- PV Name /dev/sde VG Name VolRed PV Size 3.64 TiB / not usable 3.84 MiB Allocatable yes PE Size 4.00 MiB Total PE 953861 Free PE 953861 Allocated PE 0 PV UUID 9AfJr9-OOtC-PB34-dUnq-kCDK-L1fN-aTAxus
VMware
Статья в базе знаний VMware утверждает, что ни 512E, ни 4KN диски не поддерживаются. Поддержка дисков 4KN заявлена в vSphere 6.0.
С появлением VMFS-5 мы получили единый размер блока — 1МиБ и правильное 1МиБ-смещение для первого раздела. Раньше использовалось не всегда подходящее смещение в 64КиБ. Но всё это не отменяет заявления VMware о том, что 512E диски не поддерживаются. Видимо, это связано с тем, что формат VMDK хранит данные с гранулярностью 512 байт.
Прочие ОС
Mac OSX поддерживает Advanced Format начиная с Tiger. Остаются ещё FreeBSD и прочие *BSD, Oracle Solaris и множество других ОС, но детальное рассмотрение ситуации с Advanced Format дисками в них выходит за рамки данной статьи.
Сервисы Microsoft
Hyper-V
Несмотря на то, что диски 512E поддерживаются в Windows Server 2008 и 2008 R2 (см. в таблице требования по установленным KB), в Hyper-V появляется проблема: формат файлов виртуальных дисков VHD использует 512-байтные структуры для динамических («тонких») и дифференциальных VHD, что, естественно приводит к регулярным read-modify-write. Ситуация усугубляется тем, что для гостевой ОС виртуальный диск выглядит как имеющий физические сектора 512 байт. Используйте фиксированные VHD, но по-возможности не используйте диски 512E для размещения VHD-файлов.
В Windows Server 2012 появился формат VHDX, который не имеет вышеописанных проблем (его можно создать в любом виде — 512N/512E/4KN).
Exchange Server
- Все диски, используемые в группе обеспечения доступности (Database Availability Group, DAG) Exchange для хранения баз и логов, должны использовать одинаковый физический размер сектора.
- Диски 4KN не поддерживаются
- Диски 512E поддерживаются начиная с Exchange 2010 Service Pack 2
SQL Server
Ситуация та же, что и для Exchange Server — в отказоустойчивых конфигурациях для баз и логов на всех узлах должы использоваться диски с одинаковым физическим размером сектора.
При использовании Storage Spaces возникает интересная ситуация: презентуемый размер физического сектора оказывается равным 4КиБ вне зависимости от того, из каких дисков собран Storage Spaces (том Storage Spaces можно создать из разных дисков — 512N и 512E, смешивать с 4KN, естественно, нельзя, кроме случаев использования tiering’а с SSD). Формат VHDX (виртуальный диск) по умолчанию создаётся как 512E. В этом можно убедиться, запустив fsutil fsinfo ntfsinfo :
Bytes Per Sector : 512 Bytes Per Physical Sector : 4096
При использовании VHDX на томе Storage Spaces (или аппаратном RAID), состоящем из 4KN дисков, сам VHDX тоже желательно сделать 4KN:
New-VHD -Path D:\image4kn.vhdx -Fixed -SizeBytes 500GB -LogicalSectorSizeBytes 4096 -PhysicalSectorSizeBytes 4096
Безопасно ли это для SQL и других приложений, использующих синхронную запись? Ответ — да, так как большая гранулярность хранения не нарушает целостности данных, на производительность это тоже не влияет, так как 4096 делится на 512.
Сервисы, использующие ESENT
Не совсем актуальная проблема в Windows Server 2008. Сервисы, использующие в работе Extensible Storage Engine API (AD, WINS, DHCP) могут упасть при изменении размера физического сектора (например, при миграции с 512N-диска на 512E). Подробное описание и хотфикс смотрите тут.
Прочее ПО
- Продукты Acronis.
- Symantec Backup Exec поддерживает диски Advanced Format (512E и 4KN) начиная с версии 2012 revision 1798 Service Pack 2. Более ранние выпуски могут работать с дисками 512E, но Symantec утверждает, что подобное сочетание не поддерживается официально.
- Symantec Norton Ghost не поддерживает диски 4KN.
Контроллеры
- Диски 4KN и 512N/512E смешивать в одном массиве нельзя.
- У контроллеров Adaptec и LSI метаданные размещаются в конце диска, пользовательское пространство доступно с LBA0. Это означает, что проблем с выравниванием для 512E дисков не будет.
- Массив из 4KN дисков так же будет иметь физический/логический размер сектора 4КиБ, т.е. для загрузки с них нужны GPT и UEFI.
- Не забывайте вместе с прошивкой обновлять утилиты управления и драйверы.
- Как будет презентоваться LUN, созданный на 512E дисках — 512N или 512E? Из того, что удалось проверить: контроллеры LSI 9260, Adaptec 6-й серии, СХД Infortrend ESDS сообщают 512N (логический/физический блоки 512 байт), т.е. проблема с синхронной записью остаётся. Обязательно используйте write-back кэш (естественно, с защитой) и UPS. Причём не исключено, что при смене прошивки СХД и контроллер могут внезапно повести себя «правильно», и LUN’ы превратятся в 512E со всеми вытекающими последствиями для совместимости.
Adaptec by PMC
- SAS HBA серий 5 и 6: поддерживают 512E, не поддерживают 4KN
- SAS HBA серий 6H и 7H: поддерживают 512E, 4KN — начиная с прошивки 10467.
- RAID контроллеры серий 7 и 8: поддерживают 512E, 4KN — начиная с прошивки 30862.
LSI/Avago
- Старые контроллеры на базе LSI1078: не поддерживают диски Advanced Format совсем
LSI 3ware серии 9750 на базе LSI2108 и более ранние 3ware: не поддерживают диски Advanced Format совсем.- LSISAS2108 (LSI 9260/61/80): поддерживают 512E начиная с прошивки MR4.8, 4KN не поддерживают. Список совместимости (4KN диски присутствуют, но, видимо, относятся к LSI 2208, см. ниже).
- LSISAS2208 (LSI 9265/66/71/85/86): поддерживают 512E начиная с прошивки MR5.5, поддерживают 4KN начиная с прошивки MR5.8. Список совместимости.
- LSISAS3108 (LSI 9361/80): поддерживают 512E и 4KN. Список совместимости.
- SAS HBA на базе LSISAS2008 и LSISAS2308 (LSI 9211/9200/9207): поддерживают 512E и 4KN. Список совместимости.
- SAS HBA на базе LSISAS3008 (LSI 9311/9300): поддерживают 512E и 4KN. Список совместимости.
- RAID на базе LSISAS2008 (LSI 9240, прошивка iMR): поддерживают 512E, 4KN не поддерживают. Список совместимости.
- RAID на базе LSISAS3008 (LSI 9340, прошивка iMR): поддерживают 512E, 4KN не поддерживают. Список совместимости.
storcli /cx/vx set emulationType=0|1|2
Это свойство как раз и отвечает за презентуемые хосту размеры блоков:
Default (0): при наличии в томе дисков 512E он презентуется как 512E. Если все диски — 512N, тогда том презентуется как 512N
Disabled (1): Том всегда презентуется как 512N несмотря на наличие дисков 512E
Forced (2): Том всегда презентуется как 512E даже при отсутствии дисков 512E
Emulation Type был портирован и на SAS2 контроллеры (LSI 2108/2208), но без значения Forced (2).
Программный RAID в чипсетах Intel (RST/RSTe)
4KN не поддерживается совсем, Intel RST на дисках 512E требует свежих драйверов.
Advanced Format в дисках корпоративного класса. Что нас ждёт?
Речь пойдёт о дисках корпоративного класса последний серий. Десктопные HDD и позиционируемые для NAS или видеонаблюдения сюда не попали.
| Вендор | Серия | Форм-фактор | Интерфейсы | Скорость вращения шпинделя, об/мин | Дополнительно | |||
| Seagate | Enterprise Performance 10K HDD (10k.8) | 2.5″ | SAS | 10000 | Y | Y | Y | для 512N ёмкость ограничена: 600/1200ГБ |
| Seagate | Enterprise Performance 15K HDD (15k.5) | 2.5″ | SAS | 15000 | Y | Y | Y | 32ГБ встроенного SSD-кэша |
| Seagate | Enterprise Capacity 2.5 HDD (V.3) | 2.5″ | SAS, SATA | 7200 | Y | Y | ||
| Seagate | Enterprise Capacity 3.5 HDD (V.4) | 3.5″ | SAS, SATA | 7200 | Y | Y | ||
| Seagate | Archive HDD | 3.5″ | SATA | 7200 | Y | Позиционируются для архивного применения, меньше MTBF и хуже BER | ||
| Seagate | Terascale HDD | 3.5″ | SATA | 5900/7200 | Y | Позиционируются для облачного применения, меньше MTBF и хуже BER | ||
| HGST | Ultrastar C10K1800 | 2.5″ | SAS | 10000 | Y | Y | Y | для 512N ёмкость ограничена: 300/600/900/1200ГБ |
| HGST | Ultrastar C15K600 | 2.5″ | SAS | 15000 | Y | Y | Y | |
| HGST | Ultrastar C7K1000 | 2.5″ | SAS | 7200 | Y | |||
| HGST | Ultrastar He 8 | 3.5″ | SAS, SATA | 7200 | Y | Y | ||
| HGST | Ultrastar He 6 | 3.5″ | SAS, SATA | 7200 | Y | |||
| HGST | Ultrastar 7K6000 | 3.5″ | SAS, SATA | 7200 | Y | Y | ||
| HGST | MegaScale DC 4000.B | 3.5″ | SATA | 5400 | Y | Позиционируются для облачного применения, меньше MTBF и хуже BER | ||
| WD | Xe | 2.5″/3.5″ | SAS | 10000 | Y | |||
| WD | Re | 3.5″ | SATA | 7200 | Y | |||
| WD | Se | 3.5″ | SATA | 7200 | Y | Позиционируются для облачного применения, меньше MTBF и хуже BER | ||
| WD | Ae | 3.5″ | SATA | 5760 | Y | ? | Позиционируются для архивного применения, меньше MTBF и хуже BER | |
| Toshiba | AL13SE | 2.5″ | SAS | 10000 | Y | |||
| Toshiba | AL13SX | 2.5″ | SAS | 15000 | Y | |||
| Toshiba | AL13SEL | 3.5″ | SAS | 10000 | Y | |||
| Toshiba | MG03ACA/MG03SCA | 3.5″ | SAS, SATA | 7200 | Y | |||
| Toshiba | MG04ACA | 3.5″ | SATA | 7200 | Y | Y | ||
| Toshiba | MG04SCA | 3.5″ | SAS | 7200 | Y | Y | ||
| Toshiba | MC04ACA | 3.5″ | SATA | 7200 | Y | Позиционируются для облачного применения, меньше MTBF и хуже BER |
Тенденцию вы видите сами — Advanced Format окончательно проник из десктопного сегмента в корпоративный. Быстрые SAS диски 10/15 тыс. об/мин ещё выпускаются в варианте 512N, но наращивание плотности заставляет производителей использовать 4КиБ-сектора: Seagate 10k.8 и HGST Ultrastar C10K1800 ёмкостью 1800ГБ доступны только в вариантах 512E и 4KN. Все диски объёмом больше 5ТБ за исключением HGST Ultrastar He 6 — только Advanced Format.
SSD
SSD имеют свои особенности. Читать и записывать данные можно страницами, размер которых составляет 2–4–8–16КиБ в зависимости от архитектуры SSD. При этом для записи нужно обеспечить предварительное стирание ячеек, которое осуществляется не постранично, а блоками по несколько сотен страниц. Например, Samsung 840 EVO имеет блоки по 2МиБ, каждый из которых состоит из 256-ти страниц по 8КиБ. При этом, естественно, любой презентуемый хосту размер блока — 512 или 4096 байт — будет абстракцией.
Некоторые из современных SAS/SATA SSD эмулируют 512E-диск, но большая часть из соображений совместимости — 512N. Каких-либо особых мер в связи с этим предпринимать не требуется, так как в SSD корпоративного класса содержимое кэша обязательно защищается от потери питания. Достаточно обеспечить выравнивание по размеру страницы.
Некоторые PCI-E SSD, например, производства Fusion IO дают возможность при помощи фирменных утилит изменить при форматировании размер логического сектора, т.е. переключаться между 512E и 4KN режимами. Для некоторых SSD с интерфейсом SAS это тоже возможно, например, Seagate 1200 поддерживает изменение размера сектора обычным sg_format. Переход на 4КиБ сектор в некоторых сценариях может существенно поднять производительность.
Выводы
- Диски 512E не подходят для использования в серверах с устаревшими ОС, которые игнорируют размер физического сектора. В десктопных применениях это не имеет большого значения, так никто синхронную запись как правило не использует.
- Внимательно изучите свою инфраструктуру: ОС, используемые сервисы, контроллеры, СХД, режимы кэширования на контроллерах и СХД. При наличии потенциальных проблем с производительностью и/или целостностью данных примите необходимые меры.
- Проблемы с устаревшими ОС можно обойти при помощи виртуализации, но по-прежнему нужно обращать внимание на выравнивание разделов.
Ссылки
- IBM DeveloperWorks: Linux on 4 KB sector disks: Practical advice
- Документация RHEL6: IO limits и IO hints в Linux
- Выравнивание в fdisk, LVM и MD
- Поддержка дисков с большим размером сектора в Hyper-V
- Группы обеспечения доступности Exchange Server 2010 и размер сектора
- Использование Hyper-V на дисках с большим размером сектора в Windows Server 2008 и 2008 R2
- SQL Server и новые диски с размером сектора 4K
- Ошибка «Windows Setup could not configure Windows on this computer’s hardware» при установке Windows 7 или Windows Server 2008 R2
- Проблемы в приложениях, использующих Extensible Storage Engine API (ESENT), при изменении размера физического сектора
- Understanding 4KB Sector Support for Oracle Files
- Effect from innodb log block size 4096 bytes
Формат физических и логических секторов
Долго пытался найти, чем же физически отличаются эти два 4TB SATA диска Seagate Exos 7E8 (ST4000NM002A и ST4000NM000A), что продаются в DNS.
Возможно, кому-то поможет, всё необходимое есть в руководствах (Manual) для дисков этой серии: https://www.seagate.com/ru/ru/enterprise-storage/exos-drives/exos-e-drives/exos-7e8/
Итак, насколько я понял, от последних буковок зависит:
— Тип интерфейса: SATA, SAS;
— Формат: 512n, 512e, 4Kn;
— Разновидность исполнения: Standard, SED (Self-encrypting,) SED FIPS 140-2, ISE (Instant Secure Erase).
В случае же с этими двумя дисками, получается, что они:
1) одинакового исполнения: Standard,
2) с одинаковым интерфейсом: SATA,
3) но по разному отформатированы:
ST4000NM000A: 512n — физический и логический размер сектора 512 Byte
ST4000NM002A: 512e — физический размер сектора 4KB, логический размер 512 Byte (эмуляция)
В природе еще есть Exos 7E8 4TB (Standard/SATA):
ST4000NM001A: 4Kn — физический и логический размер сектора 4KB.
P.S. Но, чтобы жизнь малиной не казалось, в дисках Exos 7E8 с разным объемом 1, 2, 4, 6, 8TB, одни и те же комбинации свойств могут соответствовать, либо одинаковыми, либо разными буковками. Например, если сравнить одинаковые маркировки 2TB и 4TB Standard/SATA дисков, получится что:
1) 2TB ST2000NM000A (Standard/SATA/512n), все свойства совпадают с 4TB ST4000NM000A
2) 2TB ST2000NM001A (Standard/SATA/512e), интерфейс и исполнение совпадают, а формат отличается от 4TB ST4000NM001A (4Kn)
3) 2TB ST2000NM002A (Standard/SATA/4Kn): интерфейс и исполнение совпадают, а формат отличается от 4TB ST4000NM002A (512e)
4kn и 512e в одном рейд массиве
есть 3 винта HGST HUH728080ALN600, размер сектора 4к если добавить к ним ещё один HGST HUH728080ALE600, у которого 512e и создать raid5 из этих четырёх дисков (софтовый линуксовый рейд) — не будет ли каких проблем из за разных размеров сектора?
есть кто реально сталкивался?
ioan ★
06.08.16 22:26:53 MSK
← 1 2 →
Проблем не будет, разве что потеряешь несколько килобайтов, если размеры разделов окажутся разными.
anonymous
( 06.08.16 22:31:47 MSK )
Нельзя делать raid5 на дисках такого обьёма.
Deleted
( 07.08.16 02:59:32 MSK )
Ответ на: комментарий от Deleted 07.08.16 02:59:32 MSK
King_Carlo ★★★★★
( 07.08.16 03:05:01 MSK )

Во первых райд 5 на дисках такого объёма нельзя. Во вторых программные райд 5\6, без XOR проца и подпёртой BBU памяти — детский велосипед и тормоза при записи. В третьих, на неоптимизированном под 4к массиве с дефолтными параметрами фс пофиг, на оптимизированном похерится оптимизация.
PS. Реально сталкивался много с чем, софтварные линукс или не линукс, абсолютно не важно какие райды это 0, 1, 0+1 и т.п. максимум. 5\6 — бессмысленное баловство без реального выйгрыша. Хотите 6 — юзайте взрослое железо с правильным количеством дисков.
Jameson ★★★★★
( 07.08.16 03:15:15 MSK )
Ответ на: комментарий от Jameson 07.08.16 03:15:15 MSK
Во вторых программные райд 5\6, без XOR проца и подпёртой BBU памяти — детский велосипед и тормоза при записи
Процессор xor’ы считает быстрее, чем специализированная железка, если что.
Deleted
( 07.08.16 11:58:02 MSK )
Ответ на: комментарий от Jameson 07.08.16 03:15:15 MSK

софтварные линукс или не линукс, абсолютно не важно какие райды это 0, 1, 0+1 и т.п. максиму
Первый рейд без батарейки и кеша может рассинхронизироваться как нефиг делать. Да еще будет считать что все окей.
steemandlinux ★★★★★
( 07.08.16 13:21:16 MSK )
На таких дурах надо ZFS юзать или нормальный контроллер с raid 6 или 60.
steemandlinux ★★★★★
( 07.08.16 13:22:12 MSK )
Ответ на: комментарий от Deleted 07.08.16 02:59:32 MSK
Можно узнать почему?
Deleted
( 07.08.16 13:48:50 MSK )
Ответ на: комментарий от Deleted 07.08.16 13:48:50 MSK

Фантастическое время ребилда. Огромный шанс потерять вообще все.
Ща медвед подробнее скажет.
dk- ☆
( 07.08.16 13:51:00 MSK )
Ответ на: комментарий от Deleted 07.08.16 13:48:50 MSK

Резко взлетает шанс накрыть ещё один хард в то время, как рейд ребилдится от падения первого.
devl547 ★★★★★
( 07.08.16 13:53:15 MSK )
Ответ на: комментарий от devl547 07.08.16 13:53:15 MSK
Немного не так. Не шанс «накрыть ещё один хард», хотя он тоже приличным становится, а шанс того, что при ребилде массива проскочит ошибка (а тем более на холодных данных) после какого-то объёма составляющих дисков (сейчас точно не помню, вроде бы 4TB) 100%.
Deleted
( 07.08.16 17:15:57 MSK )
При разбиении выставлять размер блока ФС 4 килобайта, это должно нейтрализовать последствия
ism ★★★
( 07.08.16 17:53:24 MSK )
Ответ на: комментарий от Deleted 07.08.16 17:15:57 MSK

12 для десктопного шлака.
EvgGad_303 ★★★★★
( 09.08.16 14:19:34 MSK )
Ответ на: комментарий от Deleted 07.08.16 17:15:57 MSK
А если раз периодически (например раз в неделю) прогонять чтение по всем дискам, чтобы такие ошибки отлавливать заранее?
Legioner ★★★★★
( 09.08.16 14:25:30 MSK )
Последнее исправление: Legioner 09.08.16 14:25:48 MSK (всего исправлений: 1)
Ответ на: комментарий от Deleted 07.08.16 17:15:57 MSK
То есть диски 4TB без рейда использовать совсем труба, они вообще сами сразу дохнуть начинают?
slapin ★★★★★
( 09.08.16 14:27:43 MSK )
Ответ на: комментарий от EvgGad_303 09.08.16 14:19:34 MSK
Для пяти дисков вероятность получения невосстановимой ошибки чтения будет равна 1-(1-1/25)5=18.5%. 500ГБ по нынешним меркам — не очень много, в ходу диски по 1, 2, 3 и даже 4 терабайт. Для массива 8×1ГБ получаем 44.2%, а для «супер-большой-СХД-на-всю-жизнь» из 24-х десктопных дисков по 3ТБ получается шансов и вовсе не остается — 99.8%
Deleted
( 09.08.16 15:12:02 MSK )
Ответ на: комментарий от Legioner 09.08.16 14:25:30 MSK
Подпорка небольшая. AFAIK все raid’ы (кроме raidz и, может btrfs, её не щупал) при нахождении невосстановимой ошибки на одном из секторов жёсткого диска деградированного raid5 (raid5 без одного диска = raid0) разваливают массив. Сам натыкался 🙁
Deleted
( 09.08.16 15:14:18 MSK )
Ответ на: комментарий от slapin 09.08.16 14:27:43 MSK
То есть диски 4TB без рейда использовать совсем труба, они вообще сами сразу дохнуть начинают?
См выше. У десктопных дисков UER=10^14, у nearline — 10^15, у enterprise — 10^16. Если при хранении, скажем, 2TB фотографий и копировании с диска на диск тебе, грубо говоря, не важны 2-5 фотографии в 3 года, то можешь хранить их на десктопных дисках без raidz.
Deleted
( 09.08.16 15:16:25 MSK )
Ответ на: комментарий от Deleted 09.08.16 15:12:02 MSK
И зачем ты мне это написал? Я это и так знаю, тем более что речь была про TB.
EvgGad_303 ★★★★★
( 09.08.16 15:22:59 MSK )
Ответ на: комментарий от EvgGad_303 09.08.16 15:22:59 MSK
Поправить не успел.
Потому-что, для десктопных дисков не 12TB/диск, а гораздо меньше, к сожалению.
Deleted
( 09.08.16 15:31:30 MSK )
Ответ на: комментарий от Deleted 09.08.16 15:16:25 MSK
То есть на современных дисках лучше ничего не хранить, я так понимаю. Или покупать корзины и ставить диски по 500GB. Или уходить на SAS, где пока оно еще живое. Так?
slapin ★★★★★
( 09.08.16 16:16:00 MSK )
Ответ на: комментарий от Deleted 09.08.16 15:14:18 MSK
Подпорка небольшая. AFAIK все raid’ы (кроме raidz и, может btrfs, её не щупал) при нахождении невосстановимой ошибки на одном из секторов жёсткого диска деградированного raid5 (raid5 без одного диска = raid0) разваливают массив. Сам натыкался 🙁
Почему небольшая? Если на прошлой неделе все диски читались, то за 7 дней два диска вряд ли откажут одновременно. Т.е. либо при очередной проверке один диск откажет, тогда его меняем и делаем ребилд и вот тут вероятность того, что за 7 дней один из оставшихся 3 дисков откажет, уже не должна быть значима. Либо во время работы один диск откажет, опять же тогда прошло меньше 7 дней с последней проверки и вероятность того, что за эти три дня отказал ещё один диск, опять же не должна быть велика.
Legioner ★★★★★
( 09.08.16 16:20:27 MSK )
Ответ на: комментарий от Deleted 09.08.16 15:12:02 MSK
Суть расчета я понял. Но можешь чего «подробнее и с выкладками» кинуть на русском? Так, из любопытства.
Десятку на 3-4тб винтах уважаешь же?
Процессор xor’ы считает быстрее, чем специализированная железка, если что.
Но ведь не просто так же железки юзают, не? Да и условный 60+HS. Если уже ЪЪ.
dk- ☆
( 09.08.16 16:26:47 MSK )
Ответ на: комментарий от Legioner 09.08.16 16:20:27 MSK
Если на прошлой неделе все диски читались, то за 7 дней два диска вряд ли откажут одновременно.
Ещё раз напишу — не обязателен отказ сразу двух дисков. Достаточно отказа одного диска и ошибки одного блока на одном диске на оставшемся деградированном raid5 (который == raid0)
Deleted
( 09.08.16 16:27:32 MSK )
Последнее исправление: Deleted 09.08.16 16:27:58 MSK (всего исправлений: 1)
Ответ на: комментарий от slapin 09.08.16 16:16:00 MSK
Да и я так понимаю пофиг какой рейд — на 0, 1, 2 те же самые проблемы. На 5-м cool story обычно про разгильдяйство, типа у меня диск выпал из массива, сидел на двух, а тут ещё один сдох и всё накрылось. или как-то так. Понятное дело, что не надо в рейд ставить диски такие, что вероятность сбоя при ребилде будет 100%. Тут надо поприличнее что ставить. По факту у меня 3 5-х рейда используются, первый ещё на SCSI (760GB x 5), второй — на SATA 500GB x 5, и новый на SAS (1TB x 5), сбоев при ребилде не было ни разу ещё.
slapin ★★★★★
( 09.08.16 16:33:29 MSK )
Ответ на: комментарий от Deleted 09.08.16 16:27:32 MSK
Ни разу не экспулатировал RAID5 с 3 дисками, это по-моему опасно.
slapin ★★★★★
( 09.08.16 16:35:19 MSK )
Ответ на: комментарий от dk- 09.08.16 16:26:47 MSK
Суть расчета я понял. Но можешь чего «подробнее и с выкладками» кинуть на русском? Так, из любопытства.
Десятку на 3-4тб винтах уважаешь же?
Неа, уж очень много дорогого места теряется. Дома 4x3Tb raidz (и бэкап в ДЦ)
Но ведь не просто так же железки юзают, не?
Конечно. Поэтому и циски юзают, а не писюки — потому, что народ готов платить за законченное решение. В случае аппаратного контроллера:
1) Автоматически по расписанию делается проверка холодных данных (обычно по выходным), по-умолчанию включена.
2) При сбое диска контроллер выдаёт по SES команду бэкплейну зажечь красный светодиод над сбойным диском и ПИЩАТЬ!
3) При замене сбойного диска надо просто вынуть сбойный и вставить новый, ребилд запустится самостоятельно.
В случае софтрайда:
1) Проверку холодных данных (SCRUB) надо самому рисовать на bash/python/etc и засовывать в cron
2) При сбое диска ничего не происходит, если настроен мониторинг, уходит письмо одмину (я так в 2005м году чуть не просрал данные, SCSI-диск в зеркале помер и сервер на одном крыле почти полгода жил)
3) При замене сбойного диска надо самостоятельно добавить новый диск в существующий массив.
Deleted
( 09.08.16 16:35:19 MSK )
Последнее исправление: Deleted 09.08.16 16:36:47 MSK (всего исправлений: 1)
Ответ на: комментарий от Deleted 09.08.16 16:35:19 MSK
Напомни в чем там суть от десятки? Место да. Но я дешевые десктопные беру. Имею реально в запасе на замену. И репетировал отказ. В микросервере.
А бэкап терабайтов из ДЦ это муторно дорого и долго 🙂
dk- ☆
( 09.08.16 16:41:22 MSK )
Ответ на: комментарий от dk- 09.08.16 16:41:22 MSK
Напомни в чем там суть от десятки?
raidz == raid5, но без детских проблем. Вот на русском: https://www.stableit.ru/2010/08/raid-z.html
А бэкап терабайтов из ДЦ это муторно дорого и долго 🙂
Когда в ДЦ честный гигабит и дома честные 200 мегабит — не так муторно, дорого и долго 🙂
Deleted
( 09.08.16 16:42:54 MSK )
Последнее исправление: Deleted 09.08.16 16:46:33 MSK (всего исправлений: 1)
Ответ на: комментарий от Deleted 09.08.16 16:42:54 MSK
У меня коллега в Сибири с обработкой помогает. Иногда 1тб в неделю через 60мбит гоняем (сырья, ей; назад я только файлы настроек получаю). Работает, прикольно. Несколько лет назад и не мечтал бы. Но один хрен.
dk- ☆
( 09.08.16 16:47:54 MSK )
Ответ на: комментарий от Deleted 09.08.16 16:27:32 MSK
Похоже я путаю отказ диска с отказом одного блока, почему-то думал, что если хоть один блок отказал — диск идёт на гарантийный обмен. Похоже это не так.
Legioner ★★★★★
( 09.08.16 17:07:20 MSK )
Ответ на: комментарий от Legioner 09.08.16 17:07:20 MSK
А каким боком гарантийный обмен к сохранности данных на raid5?
Deleted
( 09.08.16 17:21:00 MSK )
Ответ на: комментарий от slapin 09.08.16 16:35:19 MSK
Ни разу не экспулатировал RAID5 с 3 дисками, это по-моему опасно.
raid5 из трёх дисков наиболее безопасный raid5, при прочих равных условиях.
King_Carlo ★★★★★
( 09.08.16 17:31:19 MSK )
Ответ на: комментарий от Deleted 09.08.16 16:35:19 MSK
1) Автоматически по расписанию делается проверка холодных данных (обычно по выходным), по-умолчанию включена.
Не везде и не всегда.
2) При сбое диска контроллер выдаёт по SES команду бэкплейну зажечь красный светодиод над сбойным диском и ПИЩАТЬ!
Если он есть — этот бэкплан. Пищать — да, функция нужная, но в удаленной серверной за парой дверей с уплотнением — бесполезна почти полностью. Разве что кондиционеры оценят.
3) При замене сбойного диска надо просто вынуть сбойный и вставить новый, ребилд запустится самостоятельно.
Сказки. Ребилд запуститься автоматически, если у тебя был hotspare к массиву (или вобще на весь рейд). Во всех остальных случаях — ходим руциями в управлялку и тыкаем рейд носом.
1) Проверку холодных данных (SCRUB) надо самому рисовать на bash/python/etc и засовывать в cron
Она уже давно нарисована и лежит в дистрибутиве mdadm.
2) При сбое диска ничего не происходит, если настроен мониторинг, уходит письмо одмину (я так в 2005м году чуть не просрал данные, SCSI-диск в зеркале помер и сервер на одном крыле почти полгода жил)
Оно точно так-же подключает hotspare если он есть.
3) При замене сбойного диска надо самостоятельно добавить новый диск в существующий массив.
А в железном рэйде не надо?
Заодно — плюсы mdadm над железным райдом:
1 — можно всегда диски перенести на другую аппаратную платформу. Хоть на mips с штеуда. В случае железяки — куда прикажете втыкать плату PCI-X из внезапно сдохшего сервера?
2 — Управление всё на поверхности, без всяких там интерфейсов графических. Управлялки всеми железными рейдами — трэш и ургар. Почти все в бинарном виде, хотят то железную консоль то старые плюсовые библиотеки. Хорошо, что еще перезагружаться не надо, чтоб попасть в консольку.
3 — S.M.A.R.T. В случае с железякой варьируется — от тупого SMART Ok на каждый диск, с промежуточным — вот все 10 параметров стандартных (и да, мы можем их только в XML) до полноценного проброса команды. Для mdadm — никаких проблем.
4 — Управление TLER/ERC.
5 — Возможность форсированно завести битый рейд.
6 — Для использования 4k дисков — не надо покупать новый рейд.
7 — Возможность заскриптовать любое телодвижение по любому эвенту от массива. Хочешь — повесил себе snmpd и выдавай состояние, хочешь — почту пиши, хочешь — трапы/SMS шли.
LynxChaus ★
( 09.08.16 18:07:08 MSK )
Ответ на: комментарий от LynxChaus 09.08.16 18:07:08 MSK
Сказки. Ребилд запуститься автоматически, если у тебя был hotspare к массиву (или вобще на весь рейд). Во всех остальных случаях — ходим руциями в управлялку и тыкаем рейд носом.
Чего ты мне рассказываешь, я этим летом дисков 10 уже, наверное, поменял в разных серверах на разных контроллерах. Везде из коробки стоит
/opt/MegaRAID/storcli/storcli64 /c0 show all|grep Auto\ Rebui Auto Rebuild = OnDeleted
( 09.08.16 18:26:02 MSK )
Последнее исправление: Deleted 09.08.16 18:28:58 MSK (всего исправлений: 1)
Ответ на: комментарий от Jameson 07.08.16 03:15:15 MSK
почему нельзя, где можно почитать? сейчас у меня там крутятся 4 диска по 5тб, всё отлично. софтварный raid5 даёт выигрыш при записи нормальный. что изменится, если я вставлю туда же 4 диска по 8тб?
ioan ★
( 09.08.16 18:57:49 MSK ) автор топика
Ответ на: комментарий от Deleted 09.08.16 18:26:02 MSK
Чего ты мне рассказываешь, я этим летом дисков 10 уже, наверное, поменял в разных серверах на разных контроллерах.
Не одним мегарейдом едины. В ближайших адаптеках не наблюдаю авторебилда.
По остальным пунктам претензии есть?
LynxChaus ★
( 09.08.16 20:49:00 MSK )
Ответ на: комментарий от LynxChaus 09.08.16 20:49:00 MSK
Ближайший адаптек был нещадно выкинут и заменён на lsi hba и zfs поверх него. Ты меня с кем-то путаешь, у меня вообще никаких претензий к софтрайдам, непонятно, зачем ты крестовый поход объявил в мою сторону.
Deleted
( 09.08.16 21:07:55 MSK )
Ответ на: комментарий от Deleted 09.08.16 21:07:55 MSK
Ближайший адаптек был нещадно выкинут
за что? Вполне себе нормальная железка. LSI гораздо говенней (по крайней мере старые версии). Да и за поглощение и убиение 3ware — им большой минус в карму.
Ты меня с кем-то путаешь, у меня вообще никаких претензий к софтрайдам, непонятно, зачем ты крестовый поход объявил в мою сторону.
Какой крестовый поход? Я просто обосновал свою точку зрения на софт-рейды.
И вообще — есть сторонники 2х подходов — купить за подорого на дядины деньги убер-железку которая только что кофе не варит (ну за отдельную лицензию может и сможет), натырцать чекбоксы в красивом меню и радоваться. А есть второй подход — собрать самому всё из палок и изоленты (такой-же что и в железках выше — но вам её не покажут) попутно обучившись тому, как и через что оно работает. Да, кнопок жать надо много больше — зато итоговый результат гораздо лучше.
И с моей точки зрения — даже авторебилд это сугубо контролируемый админом процесс, а не облегчение работы для инжинегра «вынь 5й диск слева (мигает красным) и воткни диск с полки».
LynxChaus ★
( 10.08.16 01:37:59 MSK )
Ответ на: комментарий от LynxChaus 10.08.16 01:37:59 MSK
за что? Вполне себе нормальная железка.
Вешал наглухо раз в 5-10 перезагрузок сервер на POST. Хотя прошивка последняя, в логах ничего. Более старые адаптеки вообще вешались в процессе работы от сбоя диска и потом писали kernel hang.
Deleted
( 10.08.16 12:17:46 MSK )
Ответ на: комментарий от Deleted 10.08.16 12:17:46 MSK
я пропользовался адаптеками последние лет 8, начиная от 2405 и заканчивая 81605. проблем никаких не возникало. брал несколько раз LSI, но он работает не на всех мамках почему-то. в брендовых серваках работает, в самосборе зачастую или вообще не детектится, или начинаются какие-то проблемы. причём адаптек на этом же самосборе пашет на ура.
ioan ★
( 10.08.16 13:54:46 MSK ) автор топика
Ответ на: комментарий от Deleted 09.08.16 15:31:30 MSK
Ну да, гораздо, на каждые 11,5TB, в приведённых тобой ссылках об этом тоже написано.
EvgGad_303 ★★★★★
( 10.08.16 17:43:58 MSK )
Ответ на: комментарий от Deleted 10.08.16 12:17:46 MSK
Вешал наглухо раз в 5-10 перезагрузок сервер на POST.
С adaptec много было приколов, с sas-seagatов из compability list контроллер странно интерпретировал smart и считал почти мёртвые диски вполне себе исправными со всеми вытекающими последствиями.
King_Carlo ★★★★★
( 10.08.16 17:58:59 MSK )
Ответ на: комментарий от King_Carlo 10.08.16 17:58:59 MSK
Увы, вполне себе отличные энтерпрайз хитачи.