Учим_Питон_#5 — Практика: асинхронные функции

Задача: написать асинхронный код, который скачивает данные с сайта и загружает их в БД.
Создаем 5 файлов:
jsonplaceholder.py
aiohttp — это «async HTTP client/server for asyncio and Python».
asyncio — это «a library to write concurrent code using the async/await syntax».
async — создает корутину await — позволяет переключить контекст, переходя к другой ф-и, если текущая занята. async with — асинхронный менеджер контекста, который автоматически закроется после выполнения задачи (см. Менеджер контекста или with as) Корутина — cooperative routine, код, который может выполняться одновременно с другим кодом.
Что мы здесь делаем:
Импортируем библиотеки Пишем константы (по соглашению разработчиков, константы — это переменные, записанные с большой буквы, и которые НЕ следует менять!)
Создаем асинхронную ф-и(корутину) fetch_json — дословно: «получить json».
Внутри ф-и вызываем асинхронный менеджер, в нем открываем сессию через aiohttp, и следующим шагом посылаем запрос GET по урлу session.get(url). Результат кладем в переменную response и возвращаем его, преобразовав в json (return await response.json()) — код с return читается справа налево. Вначале await переменной, затем return того, что получилось)
Важно: данные, приходящие с сервера, не нужно мутировать! Почему? Потому что другие разработчики знают, как работает json() и ожидают json, а не мутанта:) Не усложняйте жизнь другим и себе, например, спустя месяц.
Итак, результат работы модуля jsonplaceholder.py — возврат данных в виде json
Результат работы модуля models.py:
- Подключаемся к БД в докере
- Дропаем и создаем заново таблицы (чтобы небыло конфликта с существующими записями)
- Сохраняем данные юзеров и постов в БД
Что здесь делаем: Создаем асинхронный main() и запускаем его в синхронном main(). Внутри async_main() последовательно запускаем асинхронные ф-и:
- Запуск БД в докере
- Дроп и создание пустых таблиц
- Получение данных юзеров и постов с сайта
- Сохранение юзеров в бд
- Сохранение постов в бд
- Закрытие подключения к бд (происходит неявно, автоматически при завершении работы менеджера контекста)
asyncio.gather — метод, который вернет то, что в него было положено, в том же порядке. (deprecated in python 3.10. ) asyncio.run - метод, создающий event loop для асинхронных ф-ий.
Результат работы main.py: В БД, в таблице User появляется 10 пользователей, в таблице Post — 100 записей, связанных отношением many to one к юзерам, написавших их.
P.S. Если будете копировать код - используйте IDE для его запуска т.к. где-то может стоять 4 пробела, а где-то табуляция. Но лучше не копировать, а руками перепечатать, так лучше запомнится и поймется.
Асинхронный Python в веб-разработке | Asyncio и Aiohttp
Асинхронное программирование хорошо подходит для задач, которые включают частое чтение и запись файлов или отправку данных с сервера туда и обратно. Асинхронные программы выполняют операции ввода-вывода неблокирующим образом, а это означает, что они могут выполнять другие задачи, ожидая возврата данных от клиента, а не просто ждать, тратя впустую ресурсы и время.
Python, как и многие другие языки, по умолчанию не является асинхронным. К счастью, быстрые изменения в мире ИТ позволяют нам писать асинхронный код даже на языках, которые изначально для этого не предназначались.
Неблокирующее поведение асинхронных программ может привести к значительному повышению производительности в контексте веб-приложения, помогая решить проблему разработки реактивных приложений.
В Python 3 встроено несколько мощных инструментов для написания асинхронных приложений. В этой статье мы рассмотрим некоторые из этих инструментов.
Введение в асинхронный Python
Для тех, кто знаком с написанием традиционного кода Python, переход к асинхронному коду может быть концептуально немного сложным. Асинхронный код в Python опирается на сопрограммы(coroutines), которые в сочетании с циклом обработки событий позволяют писать код, который может выполнять несколько действий одновременно.
Сопрограммы можно рассматривать как функции, в коде которых есть точки, в которых они возвращают управление программой вызывающему контексту. Эти точки позволяют приостанавливать и возобновлять выполнение сопрограммы в дополнение к обмену данными между контекстами.
Цикл событий решает, какой фрагмент кода выполняется в любой момент — он отвечает за приостановку, возобновление и взаимодействие между сопрограммами. Это означает, что части разных сопрограмм могут выполняться не в том порядке, в котором они были запланированы. Эта идея выполнения разных фрагментов кода не по порядку называется параллелизмом.
Размышление о параллелизме в контексте выполнения HTTP запросов может многое прояснить. Представьте, что вы хотите сделать много независимых запросов к серверу. Например, мы могли бы запросить веб-сайт, чтобы получить статистику обо всех спортивных игроках в данном сезоне.
Мы могли бы сделать каждый запрос последовательно. Однако мы можем представить, что с каждым запросом наш код может потратить некоторое время на ожидание доставки запроса на сервер и отправки ответа обратно.
Иногда эти операции могут занимать даже несколько секунд. Приложение может испытывать задержки в сети из-за большого количества пользователей или просто из-за ограничений скорости данного сервера.
Что, если бы наш код мог делать другие вещи, ожидая ответа от сервера? Более того, что, если он вернется к обработке данного запроса только после получения данных ответа? Мы могли бы сделать много запросов в быстрой последовательности, если бы нам не приходилось ждать завершения каждого отдельного запроса, прежде чем переходить к следующему в списке.
Сопрограммы с циклом событий позволяют нам писать код, который ведет себя именно таким образом.
Asyncio
asyncio , часть стандартной библиотеки Python, предоставляет цикл обработки событий и набор инструментов для управления им. С помощью asyncio мы можем планировать выполнение сопрограмм и создавать новые сопрограммы (на самом деле asyncio.Task объекты, используя терминологию asyncio ), которые завершат выполнение только после завершения выполнения составных сопрограмм.
В отличие от других языков асинхронного программирования, Python не заставляет нас использовать цикл обработки событий, который поставляется вместе с языком. Сопрограммы Python представляют собой асинхронный API, с помощью которого мы можем использовать любой цикл обработки событий.
Существуют проекты, которые реализуют совершенно другой цикл событий, например curio , или позволяют использовать другую политику цикла событий для asyncio (политика цикла событий — это то, что управляет циклом событий «за кулисами»), например uvloop .
Давайте взглянем на фрагмент кода, который одновременно запускает две сопрограммы, каждая из которых выводит сообщение через одну секунду:
# example1.py import asyncio async def wait_around(n, name): for i in range(n): print(f": iteration ") await asyncio.sleep(1.0) async def main(): await asyncio.gather(*[ wait_around(2, "coroutine 0"), wait_around(5, "coroutine 1") ]) loop = asyncio.get_event_loop() loop.run_until_complete(main())
me@local:~$ time python example1.py coroutine 1: iteration 0 coroutine 0: iteration 0 coroutine 1: iteration 1 coroutine 0: iteration 1 coroutine 1: iteration 2 coroutine 1: iteration 3 coroutine 1: iteration 4 real 0m5.138s user 0m0.111s sys 0m0.019s
Этот код выполняется примерно за 5 секунд, поскольку asyncio.sleep сопрограмма устанавливает точки, в которых цикл обработки событий может перейти к выполнению другого кода. Более того, мы указали циклу событий запланировать оба wait_around экземпляра для одновременного выполнения с asyncio.gather функцией.
Asyncio.gather берет список «ожидаемых» (т. е. сопрограмм или asyncio.Task объектов) и возвращает один asyncio.Task объект, который завершается только после завершения всех составляющих его задач/сопрограмм. Последние две строки являются asyncio шаблоном для запуска данной сопрограммы до ее завершения.
Сопрограммы, в отличие от функций, не начинают выполняться сразу после вызова. Ключевое await слово — это то, что говорит циклу обработки событий запланировать выполнение сопрограммы.
Если мы уберем await перед asyncio.sleep , программа завершится (почти) мгновенно, так как мы не сказали циклу обработки событий фактически выполнить сопрограмму, что в данном случае говорит сопрограмме приостановить работу на заданное время.
Поняв, как выглядит асинхронный код Python, давайте перейдем к асинхронной веб-разработке.
Установка aiohttp
aiohttp — это библиотека Python для выполнения асинхронных HTTP запросов. Кроме того, он предоставляет основу для сборки серверной части веб-приложения. Используя Python 3.5+ и pip, мы можем установить aiohttp :
pip install --user aiohttp
Клиентская сторона: создание запросов
В следующих примерах показано, как мы можем загрузить HTML-контент веб-сайта «example.com» с помощью aiohttp :
# example2_basic_aiohttp_request.py import asyncio import aiohttp async def make_request(): url = "https://example.com" print(f"making request to ") async with aiohttp.ClientSession() as session: async with session.get(url) as resp: if resp.status == 200: print(await resp.text()) loop = asyncio.get_event_loop() loop.run_until_complete(make_request())
Несколько вещей, которые следует подчеркнуть:
- Как и with, await asyncio.sleep мы должны использовать await with resp.text() , чтобы получить HTML-контент страницы. Если бы мы его опустили, вывод нашей программы был бы примерно таким:
me@local:~$ python example2_basic_aiohttp_request.py
- async with — менеджер контекста, который работает с сопрограммами вместо функций. В обоих случаях, когда он используется, мы можем представить себе, что внутри aiohttp закрывает соединения с серверами или иным образом освобождает ресурсы.
- aiohttp.ClientSession имеет методы, соответствующие HTTP- глаголам. Таким же
- образом, как и session.get запрос GET , session.post будет выполнен запрос POST .
Этот пример сам по себе не дает преимущества в производительности по сравнению с синхронными HTTP-запросами. Настоящая красота aiohttp на стороне клиента заключается в выполнении нескольких одновременных запросов:
# example3_multiple_aiohttp_request.py import asyncio import aiohttp async def make_request(session, req_n): url = "https://example.com" print(f"making request to ") async with session.get(url) as resp: if resp.status == 200: await resp.text() async def main(): n_requests = 100 async with aiohttp.ClientSession() as session: await asyncio.gather( *[make_request(session, i) for i in range(n_requests)] ) loop = asyncio.get_event_loop() loop.run_until_complete(main())
Вместо того, чтобы делать каждый запрос последовательно, мы просим asyncio делать их одновременно с asycio.gather .
Заключение
В этой статье мы рассмотрели, как выглядит асинхронная веб-разработка на Python, ее преимущества и способы использования.
Читайте также:

Почему изучение ООП на Python - разумный карьерный шаг?

Django vs Flask | Сравнение и выбор
HTTP-запросы с использованием Aiohttp в Python 3
Одно из критических замечаний, регулярно высказываемых в адрес Python, заключается в том, что в нем нет хорошей реализации параллелизма.
Если вы опытный программист на Python, то наверняка слышали о GIL или Global Interpreter Lock. Эта блокировка защищает доступ к объектам Python таким образом, что только один поток может одновременно выполнять байткод. Она необходима, поскольку Python (в частности, стандартная реализация CPython) не имеет потокобезопасного управления памятью.
Если позволить нескольким потокам работать с одной и той же памятью, могут произойти странные вещи. А подход Python к решению этой проблемы заключается в том, чтобы просто запретить это.
И это еще хуже: GIL приводит к накладным расходам из-за переключения контекста, так что выполнение одного и того же кода в двух разных потоках занимает больше времени, чем выполнение его дважды в одном и том же потоке.
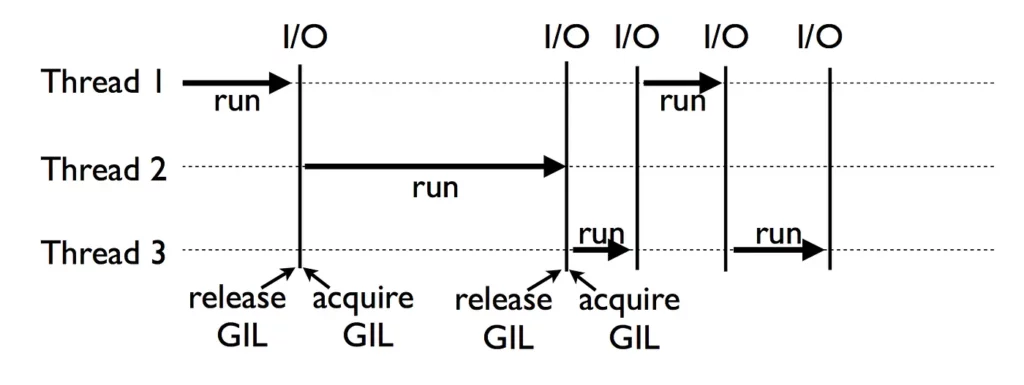
Итак, действительно ли параллелизм в Python невозможен? Вовсе нет! На самом деле, в нашем распоряжении есть несколько инструментов, каждый из которых имеет свои преимущества и недостатки.
Есть многопроцессорная обработка, которая хорошо работает во многих ситуациях, даже несмотря на большие начальные накладные расходы по сравнению с многопоточностью.
Кроме того, хотя я уже упоминал о том, что многопоточность в Python имеет некоторые недостатки по сравнению с другими языками, это не означает, что она бесполезна как способ структурировать выполнение кода. Есть и третий вариант, о котором я расскажу подробнее: асинхронное выполнение.
Пару лет назад среди языков программирования наблюдался некоторый асинхронный бум, и теперь, похоже, каждый основной язык имеет не только возможность асинхронного выполнения с помощью фьючерсов, корутин или обработчиков событий, но и синтаксис async/await. Подробнее об этом позже.
Так что же это такое? На первый взгляд, в Python async работает очень похоже на потоки, с одним существенным отличием — планированием.
Если вы используете потоки в Python, то ядро вашей операционной системы знает об этом и переключается между ними, когда считает нужным. Это называется вытесняющей многозадачностью. Код, выполняющийся в потоке, не знает, что его прерывают, и не может контролировать, когда это произойдет.
При использовании async Python сам выполняет планирование, что позволяет реализовать так называемую кооперативную многозадачность. Код, написанный с использованием этого подхода, должен каким-то образом передать управление интерпретатором, чтобы другой код мог продолжить выполнение. В JavaScript такая передача управления происходит при каждом вызове метода, а в Python вы можете контролировать, когда это происходит.
Зачем нам это нужно? Оказывается, есть класс операций, в которых имеет смысл на некоторое время передать управление: ввод/вывод!
Относительно выполнения логики программы получение чего-либо с жесткого диска занимает много времени, а получение ответа на сетевой запрос — еще больше. Если нам все равно придется ждать, почему бы не сделать за это время что-нибудь полезное?
Это также означает, что выполнение нескольких задач ввода-вывода может происходить практически одновременно. Это дает некоторые преимущества настоящего параллельного выполнения, если только время запуска новой задачи достаточно мало.
В программах, связанных со вводом-выводом, где вы читаете и записываете большое количество файлов, обмениваетесь данными с базами данных или отправляете большое количество сетевых запросов, это может значительно ускорить работу.
Немного истории
Кооперативная многозадачность в Python не является чем-то новым. Люди используют Python для реализации веб-серверов уже довольно давно, и столько же времени ищут способы увеличить количество запросов, которые они могут обрабатывать в минуту. Многие из этих решений основаны на каком-либо событийном цикле с кооперативным планированием.
Twisted, событийно-ориентированный фреймворк сетевого программирования, существует с 2002 года и используется до сих пор. На нем основаны такие проекты, как Scrapy, а Twitch использует его в своем бэкенде.
В настоящее время нет недостатка в библиотеках и фреймворках, реализующих ту или иную форму асинхронного рабочего процесса, причем многие из них специально предназначены для работы с сетями. Вот лишь некоторые из них:
- tornado, веб-сервер/фреймворк
- gevent, сетевая библиотека, основанная на Greenlet
- curio — библиотека для параллельного ввода-вывода, созданная тяжеловесом сообщества Python Dabeaz
- trio — библиотека, призванная сделать асинхронное программирование более доступным
Однако долгое время не хватало интегрированного в язык способа реализации асинхронного ввода-вывода, с функциональностью, упакованной прямо в стандартную библиотеку, и удобными ключевыми словами, позволяющими более прямолинейно и удобно программировать, избегая ада колбэков, который так хорошо знаком программистам, давно работающим на JavaScript.
Осознавая эту необходимость, в PEP 3156 было представлено видение BDFL Гвидо ван Россума по асинхронному вводу/выводу в Python, реализованное в Python 3.3 в виде модуля asyncio.
От редакции Pythonist: вас также может заинтересовать статья «asyncio — параллелизм в Python».
PEP 492, реализованный в Python 3.5, принес нам ключевые слова async/await , и с тех пор появилось множество других дополнений и улучшений, в частности, в версии 3.7.
Сразу оговорюсь, что я не пропагандирую использование asyncio вместо альтернатив, о которых я говорил ранее. У всех них есть свои достоинства и недостатки, но поскольку asyncio является частью стандартной библиотеки Python 3, с него можно начать.
Добро пожаловать в asyncio
Итак, вы убедились в том, что хотите попробовать асинхронность, и решили, что встроенный модуль asyncio — это то, что вам нужно. Какие же возможности вам доступны?
Во-первых, это сам модуль asyncio, который предоставляет несколько необходимых нам примитивов и на котором построены другие библиотеки, упомянутые в этом разделе. Примеры этих примитивов мы рассмотрим в практическом разделе ниже.
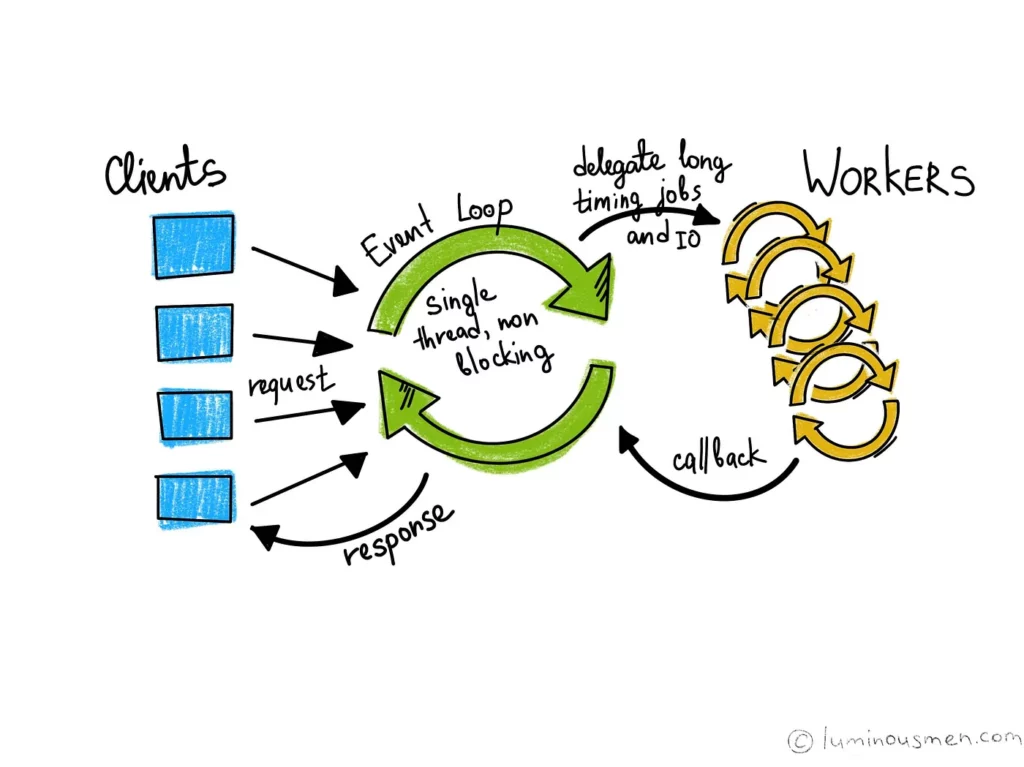
Цикл событий (event loop) — это то, что позволяет осуществлять всю кооперативную планировку. На высоком уровне это просто обычный цикл, который отслеживает все и обрабатывает события одно за другим, когда они происходят.
Цикл событий отслеживает задачи, которые помещаются в очередь, откуда их можно разбудить, когда завершится то, чего они ждут (если это вообще возможно). Задачи могут быть проверены на предмет завершения или отменены, если их результат больше не нужен или достигнут тайм-аут.
Задача (Task), в свою очередь, оборачивает корутину (Coroutine). Именно этот код выполняется, когда задача снова активируется. Далее мы на примерах рассмотрим, как это использовать. Пока просто запомните, что цикл событий фактически выполняет только одну задачу за раз и переключается только тогда, когда эта задача передает управление. Поэтому, если у вас есть одна задача, которая продолжает выполняться, то другие, которые все еще находятся в очереди, никогда не завершатся.
Многие библиотеки, которые вы наверняка будете использовать при работе с asyncio, содержатся в группе aio-libs на GitHub. Сюда входят aiohttp, о которой мы подробнее поговорим ниже, а также библиотеки для большого количества других задач, такие как aioftp, aiopg (для PostgreSQL), aioredis, aioelasticsearch, aiokafka, aiodocker, … Есть и другие библиотеки, построенные на их основе, в частности, пара веб-фреймворков, но я предоставлю вам возможность найти их самостоятельно.
Aiohttp — это, безусловно, самый активный проект aio-libs, который, возможно, является основным вариантом использования asyncio.
Aiohttp представляет собой HTTP-клиент и сервер с поддержкой Web-Sockets и таких тонкостей, как промежуточное ПО для обработки запросов и подключаемая маршрутизация.
Вики предоставляет два минимальных примера для начала работы с клиентом или сервером прямо на первой странице, что позволяет быстро опробовать их в работе.
Перейдем к коду
Начнем с самого простого примера:
import asyncio async def a_square(x): print(f'Asynchronously squaring !') return x ** 2 # This will only work in Python 3.7 and above asyncio.run(a_square(2))
Если вы не используете версию Python 3.7 или выше, то вам необходимо заменить вызов run на что-то вроде:
loop = asyncio.get_event_loop() try: loop.run_until_complete(a_square(2)) finally: loop.close()
Довольно просто, не так ли? Функция a_square является корутиной. Ключевое слово async перед определением функции означает, что если вы ее вызовете, на самом деле ничего не произойдет, а произойдет только тогда, когда вы обернете ее в задачу (Task), и цикл событий разбудит ее для выполнения вычислений.
В большинстве случаев нам не нужно делать это явно. Здесь функция run позаботилась обо всем: она запустила цикл, обернула наш корутинный объект и запланировала его как задачу, после чего он немедленно начал выполняться, так как других задач не было.
Рассмотрим кое-что посложнее. Мы можем выстраивать цепочки coroutine, заставляя их ждать друг друга. Например:
import asyncio async def sleeper(x): await asyncio.sleep(x) return x + 1 async def waiter(x): sleepy_result = (await sleepy(x)) ** 2 return sleepy_result # python >= 3.7 asyncio.run(waiter(2))
Здесь корутина waiter должна дождаться завершения работы корутины sleeper .
asyncio.sleep() — это асинхронная версия time.sleep() , поэтому она также является корутинной функцией, как и waiter и sleeper .
Ключевое слово await здесь делает несколько вещей. Во-первых, оно гарантирует, что все, что мы передаем ему, будет обернуто в задачу. Во-вторых, оно назначает эту задачу в очередь активного цикла и, когда задача будет выполнена, возвращает результат.
Это также означает, как вы уже поняли из названия, что код после этой строки начнет выполняться только тогда, когда этот результат будет доступен. Если вы хотите запланировать задачу и продолжить ее выполнение, то это тоже возможно:
import asyncio async def delayed_print(text, time=1): await asyncio.sleep(time) print(text) async def main_coro(): # python >= 3.7 task1 = asyncio.create_task(delayed_print("I'm printed second!", 2)) # python >= 3.3 task2 = asyncio.ensure_future(delayed_print("I'm printed first!")) await asyncio.gather( task1, task2, delayed_print("I'm printed last!", 3) ) # python >= 3.7 asyncio.run(main_coro())
Здесь есть несколько интересных моментов.
Во-первых, мы видим функцию create_task , которая была добавлена в Python 3.7. Она принимает корутину, который оборачивается в Task и планирует выполнение. До версии 3.7 ее эквивалентом была функция ensure_future (которая на самом деле является более низкоуровневой, но выполняет то же самое).
Затем есть функция gather , которая, как следует из названия, собирает результаты всех переданных ей задач и корутин и возвращает их в виде списка.
Теперь, когда мы разобрались с основами, давайте перейдем к тому, ради чего мы, собственно, и собрались: aiohttp! Следующий пример демонстрирует работу клиентской части:
import aiohttp import asyncio async def fetch(session, url): async with session.get(url) as response: return await response.text() async def fetch_all(urls): async with aiohttp.ClientSession() as session: texts = await asyncio.gather(*[ fetch(session, url) for url in urls ]) return texts years_to_fetch = [f'https://en.wikipedia.org/wiki/' for year in range(1990, 2020)] asyncio.run(fetch_all(years_to_fetch))
Этот код представляет собой версию примера на первой странице документации aiohttp с несколькими запросами. Он получает (HTML) текст страниц Википедии за 1990-2019 годы.
Эти GET-запросы запускаются параллельно, поэтому выполнение всех из них занимает примерно столько же времени, сколько выполнение самого длинного.
От редакции Pythonist: также предлагаем почитать «Пособие по HTTP-запросам в Python и Web API».
Конечно, есть ограничения на количество запросов, которые можно выполнить подобным образом. Если вам нужно выполнить тысячи запросов, то, вероятно, следует запускать их частями, но в большинстве случаев это будет работать, как показано на рисунке.
Как и в случае с обычной библиотекой requests, вы можете отправлять не только GET-запросы. Если вам интересны другие методы, вы всегда можете почитать об их использовании в документации.
Библиотека aiohttp также включает в себя серверный компонент, укомплектованный маршрутизатором и всем необходимым для работы с простым веб-сервером или REST API. В следующем примере показаны некоторые вещи, которые можно сделать с его помощью:
from aiohttp import web async def empty(request): return web.Response() async def get_json(request): return web.json_response(< 'path_name_variable': request.match_info.get('name'), 'query_param_a': request.rel_url.query.get('a'), 'query_param_b': request.rel_url.query.get('b'), >) async def redirected(request): location = request.app.router['default'].url_for() raise web.HTTPFound(location=location) async def index(request): return web.FileResponse('./index.html') app = web.Application() app.add_routes([ web.get('/', redirected), web.get('/empty', empty), web.get('/json/', get_json), web.static('/index', index, name='default'), ]) web.run_app(app)
Это последний пример и самый подробный. Он представляет веб-приложение с 4 маршрутами (routes): один маршрут, который перенаправляется на другой, еще один возвращает пустой ответ, третий возвращает статический HTML-файл, а четвертый имеет необязательную переменную пути (path variable) и параметры запроса (query parameters) и возвращает JSON-документ.
Очередь на сверхвысоких скоростях
Одним из интересных моментов в цикле событий asyncio является то, что он подключаемый. Это означает, что вы можете создать свою собственную реализацию. Хотя стандартная реализация, основанная на libev, уже достаточно хороша, есть и другой вариант. Более быстрый вариант!
Эта реализация называется uvloop и основана на libuv — библиотеке асинхронного ввода-вывода, изначально разработанной для node.js, а теперь используемой, в частности, в Julia.
Библиотека uvloop проста в использовании и позволяет ускорить практически все, что вы делаете с помощью asyncio, поэтому было бы стыдно не упомянуть о ней здесь.
От редакции Pythonist: также предлагаем почитать «Асинхронность в Django: бесконечная история».
Первые шаги в aiohttp

Привет, меня зовут Артём. Я работаю бэкендером в KTS и веду курсы по разработке в KTS Metaclass. Заметил, что труднее всего студентам даются темы по асинхронному программированию.
Основываясь на своём преподавательском опыте, я написал туториал, рассказывающий о создании базового aiohttp-сервиса с нуля и затрагивающий самые сложные для студентов вопросы: как сделать асинхронное python-приложение, как работать с базой данных и как разложить свой проект в интернете.
В цикле статей мы рассмотрим следующие темы:
- Архитектура веб-приложения
- Асинхронная работа с базой данных и автоматические миграции
- Работа с HTML-шаблонами с помощью Jinja2
- Размещение нашего приложения в Интернете с помощью сервиса Heroku
- А также сигналы, обработку ошибок, работу с Docker и многое другое.
Эта статья – первая из трех, и ее цель — помочь начинающим aiohttp-программистам написать первое “hello-world” приложение.
В этой статье мы напишем небольшое веб-приложение на aiohttp — стену с отзывами, где пользователь может оставить мнение о продукте.

Мы пройдем по шагам:
- Создание проекта
- Структура проекта
- Создание View
- Создание Route
- Создание шаблона
- Запуск приложения
Создание проекта
Все команды в статье были выполнены в операционной системе OSX, но также должны работать в любой *NIX системе, например в Linux Ubuntu. Во время разработки я буду использовать Python 3.7.
Давайте создадим папку aiohttp_server, которая в дальнейшем будет называться корнем проекта. В ней создадим текстовый файл requirements.txt, который будет содержать все необходимые для работы приложения зависимости и их версии. Запишем в него следующие модули:
aiohttp==3.7.3 # наш фрейворк aiohttp-jinja2==1.4.2 # модуль для работы с HTML-шаблонамиСоздадим виртуальное окружение – что-то вроде песочницы, которое содержит приложение со своими библиотеками, обновление и изменение которых не затронет другие приложение, и установим в него наши зависимости:
cd /aiohttp_server python3 -m venv venv source venv/bin/activateПосле этого в начале строки терминала должна появится надпись (venv) — это означает что виртуальное окружение успешно активировано. Установим необходимые модули:
pip install -r requirements.txtСтруктура проекта
Создадим в папке aiohttp_server следующую структуру:
├── app │ ├── __init__.py │ ├── forum │ │ ├── __init__.py │ │ ├── routes.py # тут будут пути, по которым надо отправлять запросы │ │ └── views.py # тут будут функции, обрабатывающие запросы │ ├── settings.py ├── main.py # тут будет точка входа в приложение ├── requirements.txt └── templates └── index.html # тут будет html-шаблон страницым сайтаТеперь откроем файл main.py и добавим в него следующее:
from aiohttp import web # основной модуль aiohttp import jinja2 # шаблонизатор jinja2 import aiohttp_jinja2 # адаптация jinja2 к aiohttp # в этой функции производится настройка url-путей для всего приложения def setup_routes(application): from app.forum.routes import setup_routes as setup_forum_routes setup_forum_routes(application) # настраиваем url-пути приложения forum def setup_external_libraries(application: web.Application) -> None: # указываем шаблонизатору, что html-шаблоны надо искать в папке templates aiohttp_jinja2.setup(application, loader=jinja2.FileSystemLoader("templates")) def setup_app(application): # настройка всего приложения состоит из: setup_external_libraries(application) # настройки внешних библиотек, например шаблонизатора setup_routes(application) # настройки роутера приложения app = web.Application() # создаем наш веб-сервер if __name__ == "__main__": # эта строчка указывает, что данный файл можно запустить как скрипт setup_app(app) # настраиваем приложение web.run_app(app) # запускаем приложениеПосле предварительной настройки можно создать первый View.
Первый View
View — это некий вызываемый объект, который принимает на вход HTTP-запрос — Request и возвращает на пришедший запрос HTTP-ответ — Response.
Http-запрос содержит полезную информацию, например url запроса и его контекст, переданные пользователем данные и многое другое. В контексте запроса содержатся данные, которые мы или aiohttp добавили к этому запросу. Например, мы предварительно авторизовали пользователя — чтобы повторно не проверять авторизацию пользователя из базы во всех View и не дублировать код, мы можем добавить объект пользователя в контекст запроса. Тогда мы сможем получить нашего пользователя во View, например, так: request['user'].
HTTP-ответ включает в себя полезную нагрузку, например, данные в json, заголовки и статус ответа. В простейшем View, который из примера выше, всю работу по формированию HTTP-ответа выполняет декоратор @aiohttp_jinja2.template("index.html") . Декоратор получает данные из View, которые возвращаются в виде словаря, находит шаблон index.html (о шаблонах написано ниже), подставляет туда данные из этого словаря, преобразует шаблон в html-текст и передает его в ответ на запрос. Браузер парсит html и показывает страницу с нашим контентом.
В файле views.py в папке app/forum напишем следующий код:
import aiohttp_jinja2 # создаем функцию, которая будет отдавать html-файл @aiohttp_jinja2.template("index.html") async def index(request): return
Здесь создается функциональный View (function-based View). Определение “функциональный” означает, что код оформлен в виде функции, а не классом (в следующей части мы коснемся и class-based View).
Рассмотрим написанную функцию детальнее: функция обернута в декоратор @aiohttp_jinja2.template("index.html") — этот декоратор передает возвращенное функцией значение в шаблонизатор Jinja2, а затем возвращает сгенерированную шаблонизатором html-страницу как http-ответ. В данном случае возвращенным значением будет словарь, значения которого подставляются в html-файл index.html.
Отдельно стоит заметить, что объект запроса request передается как аргумент функции index. Мы не используем request в этой функции, но будем использовать в дальнейшем.
HTTP-запрос отправляется на конкретный url-адрес. Для передачи HTTP-запроса в нужный View необходимо задать эту связь в приложении с помощью Route.
Первый Route
Route — это звено, связывающее адрес, по которому был отправлен запрос и код View, в котором этот запрос будет обработан. То есть, если пользователь перейдет в корень нашего сайта (по адресу /), то объект запроса будет передан в View index и оттуда же будет возвращен ответ. Подробней про Route можно прочитать тут.
В файл routes.py необходимо добавить следующий код:
from app.forum import views # настраиваем пути, которые будут вести к нашей странице def setup_routes(app): app.router.add_get("/", views.index)Первый Template
Теперь нам осталось только добавить в templates/index.html код верстку нашей страницы. Его можно найти по этой ссылке.
Template — это html-шаблон, в который подставляются данные, полученные в результате обработки запроса. В примере в коде View отдается словарь с ключом title, шаблонизатор Jinja2 ищет в указанном html-шаблоне строки > и заменяет их на значение из словаря по данному ключу. Это простейший пример, шаблоны позволяют делать намного больше: выполнять операции ветвления, циклы и другие операции, например, суммирование. Примеры использования можно посмотреть в документации jinja2.
Запуск приложения
Мы создали первую версию нашего приложения! Осталось запустить его следующей командой в терминале (убедитесь, что находитесь в папке aiohttp_server):
python3 main.pyВы должны увидеть следующий текст в консоли. Он означает, что сервер запущен на порту 8080.
======== Running on http://0.0.0.0:8080 ======== (Press CTRL+C to quit)Давайте теперь посмотрим результаты нашей работы! Для этого перейдите по адресу http://0.0.0.0:8080 в браузере. Вы должны увидеть первую версию нашего приложения. При клике на кнопку “Отправить” должно возникнуть сообщение о том, что отзыв отправлен.

Поздравляю! Вы успешно создали первое приложение на aiohttp!
Заключение
В статье рассмотрено создание простого приложения на aiohttp, которое принимает запрос пользователя и отдает html-страницу. Мы затронули:
- Настройку виртуального окружения
- Базовую настройку проекта на aiohttp
- Создание View
- Создание Route
- Использование html-шаблонов
Наше приложение представляет собой простой веб-сервер, отдающий html-страницу по запросу - в нем нет никакого взаимодействия с базами данных, его структура максимально проста и оно недоступно пользователям в Интернете. В следующих статьях мы разберем, как вырастить из нашей заготовки “настоящее” веб-приложение на aiohttp и опубликовать его в Интернете.
Весь код статьи можно найти на гитхабе.
Полный цикл статей «Первые шаги в aiohttp»:
- Пишем первое hello-world-приложение
- Подключаем базу данных
- Выкладываем проект в Интернет
Другие наши статьи по бэкенду и асинхронному программированию для начинающих:
- Визуализация 5 алгоритмов сортировки на Python
- Разбираемся в асинхронности: где полезно, а где — нет?
Другие наши статьи по бэкенду и асинхронному программированию для продвинутого уровня:
- Пишем свой Google, или асинхронный краулер с rate limits на Python
- Пишем асинхронного Телеграм-бота
- Пишем Websocket-сервер для геолокации на asyncio
��Асинхронное программирование на Python для джуниор-разработчиков��
Асинхронное программирование используется для высоконагруженных проектов и микросервисов. Его спрашивают на собеседованиях в технологически развитых компаниях, и оно открывает дорогу к работе в интересных проектах. Если вы уже пишете на Python, но пока не изучили модуль Asyncio, приглашаю вас на курс по асинхронному программированию на Python.
- Разберётесь, как работает асинхронное программирование и где его лучше применять.
- Получите опыт работы с микросервисами.
- Освоите стандартную python-библиотеку Asyncio, напишите чат-бота и event loop.