Определение кодировки
Поле DllImportAttribute.CharSet управляет маршалированием строк и определяет, как вызов платформы находит имена функций в библиотеке DLL. В этом разделе описываются оба механизма.
Некоторые API экспортируют две версии функций, которые принимают строковые аргументы: обычные (ANSI) и двухбайтовые (Юникод). Например, API Windows включает следующие имена точек входа для функции MessageBox:
- MessageBoxA Обеспечивает форматирование однобайтовых символов ANSI и имеет суффикс «A» в имени точки входа. При вызове MessageBoxA строки всегда маршалируются в формате ANSI.
- MessageBoxW Обеспечивает форматирование двухбайтовых символов Юникода и имеет суффикс «W» в имени точки входа. При вызове MessageBoxW строки всегда маршалируются в формате Юникод.
Маршалирование строк и сопоставление имен
Поле CharSet принимает следующие значения:
Ansi (значение по умолчанию)
- Маршалирование строк При вызове неуправляемого кода выполняется маршалинг строк из соответствующего управляемого формата (Юникод) в формат ANSI.
- Сопоставление имен Если поле DllImportAttribute.ExactSpelling имеет значение true (значение по умолчанию в Visual Basic), при вызове неуправляемого кода осуществляется поиск только указанного имени. Например, если указать MessageBox, при вызове неуправляемого кода будет выполнен поиск MessageBox, который может завершиться сбоем из-за невозможности найти точное совпадение. Если поле ExactSpelling имеет значение false (по умолчанию для C++ и C#), при вызове неуправляемого кода выполняется поиск сначала неуправляемого псевдонима (MessageBox), а затем, если неуправляемый псевдоним не найден, управляемого имени (MessageBoxA). Обратите внимание, что принципы сопоставления имен ANSI и Юникода различаются.
- Маршалирование строк При вызове неуправляемого кода строки копируются из соответствующего управляемого формата (Юникод) в формат Юникода.
- Сопоставление имен Если поле ExactSpelling имеет значение true (значение по умолчанию в Visual Basic), при вызове неуправляемого кода осуществляется поиск только указанного имени. Например, если указать MessageBox, при вызове неуправляемого кода будет выполнен поиск MessageBox, который может завершиться сбоем из-за невозможности найти точное совпадение. Если поле ExactSpelling имеет значение false (по умолчанию для C++ и C#), при вызове неуправляемого кода выполняется поиск сначала управляемого имени (MessageBoxW), а затем, если управляемое имя не найдено, неуправляемого псевдонима (MessageBox). Обратите внимание, что принципы сопоставления имен Юникода и ANSI различаются.
- При вызове неуправляемого кода во время выполнения осуществляется выбор между форматами ANSI и Юникода в соответствии с целевой платформой.
Определение кодировки в Visual Basic
В Visual Basic можно указать поведение кодировки, добавив ключевое слово Ansi , Unicode или Auto в операторе объявления. Если опустить ключевое слово кодировки, в поле DllImportAttribute.CharSet по умолчанию будет задана кодировка ANSI.
В следующем примере функция MessageBox объявляется три раза с разными кодировками. В первом операторе ключевое слово кодировки опущено, в связи с чем по умолчанию устанавливается кодировка ANSI. Во втором и третьем операторе кодировка задается явно с использованием ключевого слова.
Friend Class NativeMethods Friend Declare Function MessageBoxA Lib "user32.dll" ( ByVal hWnd As IntPtr, ByVal lpText As String, ByVal lpCaption As String, ByVal uType As UInteger) As Integer Friend Declare Unicode Function MessageBoxW Lib "user32.dll" ( ByVal hWnd As IntPtr, ByVal lpText As String, ByVal lpCaption As String, ByVal uType As UInteger) As Integer Friend Declare Auto Function MessageBox Lib "user32.dll" ( ByVal hWnd As IntPtr, ByVal lpText As String, ByVal lpCaption As String, ByVal uType As UInteger) As Integer End Class Определение кодировки в C# и C++
Поле DllImportAttribute.CharSet определяет базовую кодировку как ANSI или Юникод. Набор символов определяет способ маршалирования строковых аргументов метода. Чтобы указать кодировку, используйте одну из следующих форм:
[DllImport("DllName", CharSet = CharSet.Ansi)] [DllImport("DllName", CharSet = CharSet.Unicode)] [DllImport("DllName", CharSet = CharSet.Auto)] [DllImport("DllName", CharSet = CharSet::Ansi)] [DllImport("DllName", CharSet = CharSet::Unicode)] [DllImport("DllName", CharSet = CharSet::Auto)] В следующем примере показаны три управляемых определения функции MessageBox с атрибутами, задающими кодировку. В первом определении соответствующее ключевое слово опущено, в результате чего в поле CharSet по умолчанию устанавливается кодировка ANSI.
using System; using System.Runtime.InteropServices; internal static class NativeMethods
typedef void* HWND; // Can use MessageBox or MessageBoxA. [DllImport("user32")] extern "C" int MessageBox( HWND hWnd, String* lpText, String* lpCaption, unsigned int uType); // Can use MessageBox or MessageBoxW. [DllImport("user32", CharSet = CharSet::Unicode)] extern "C" int MessageBoxW( HWND hWnd, String* lpText, String* lpCaption, unsigned int uType); // Must use MessageBox. [DllImport("user32", CharSet = CharSet::Auto)] extern "C" int MessageBox( HWND hWnd, String* lpText, String* lpCaption, unsigned int uType); См. также
- DllImportAttribute
- Создание прототипов в управляемом коде
- Примеры вызовов неуправляемого кода
- Маршалирование данных с помощью вызова платформы
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.
Автоопределение кодировки текста

Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
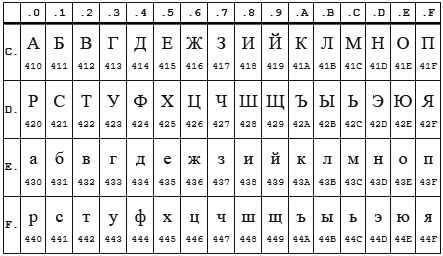
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r' func CodePageDetect(r io.Reader, stopStr . string) (IDCodePage, error) < if !reflect.ValueOf(r).IsValid() < return ASCII, fmt.Errorf("input reader is nil") >. Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr . string) (IDCodePage, error) < //test input interfase if r == nil < return ASCII, nil >//make slice of byte from input reader buf, err := bufio.NewReader(r).Peek(ReadBufSize) if (err != nil) && (err != io.EOF) < return ASCII, err >. вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File res, err := CodePageDetect(data)
В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
C как узнать кодировку строки
Для отключения данного рекламного блока вам необходимо зарегистрироваться или войти с учетной записью социальной сети.
Сообщения: 1696
Благодарности: 44
EvgeniyQQQ, Не знаю, что есть ANSI. Но в ASCII не может быть символов с кодом > 127 (это 7-итная кодировка). Если же используется «расширенный» ASCII (Latin-1 или любая другая национальная кодировка), то можно просто проверить, что исходная строка содержит символы с кодом > 127 и является корректной utf-8 строкой (т.е. удовлетворяет этим требованиям: http://tools.ietf.org/html/rfc3629#section-3). Если строка достаточно большая и не в utf-8, то где-нибудь обязательно будет неправильна закодирована, и следовательно не utf-8, иначе «произвольная однобайтовая кодировка».
Это сообщение посчитали полезным следующие участники:
Сообщения: 14
Благодарности: 4
Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байтов, в которых первый байт всегда имеет вид 11xxxxxx, а остальные — 10xxxxxx. Более подробно о UTF-8 посмотрите http://ru.wikipedia.org/wiki/UTF-8. Что же касается ANSI — то насколько я понимаю, это то же, что и кодировка Windows-1251, т.е. 8-битная и содержит русские символы.
Это сообщение посчитали полезным следующие участники:
Сообщения: 4
Благодарности: 1
| Конфигурация компьютера |  |
| Процессор: c2d E8200 | |
| Материнская плата: p5e | |
| Память: 2gb | |
| Видеокарта: gf 8800gt | |
| ОС: 2008r2 |
Потребовалось мне автоопределение кодировки в текстовом файле; нашёл (не претендуя на универсальность) такой выход (builder xe3):
String tst= al+af+am+bt+sn; // несколько тэгов, выделенных из fb2 файла
if( tst[1]>0x007F && UTF8Decode(tst)[1]!=0xfffd ) al=UTF8Decode(al);// нет, это не ansi!
суть в том, что UTF8Decode от русского ansi-текста возвращает строку, забитую 0xFFFD
а от английского ansi-текста или любого utf8-текста возвращает читабельный ansi-текст.
ps для fb2, понятно, надо каждый тег проверять (т.к. в utf файле могут быть смешаны и русские и английские тэги), но принцип проверки понятен.
C как узнать кодировку строки
Ну, почему-же. Можно. Набрать статистику распределения символов.
Для русского языка часто встречающиеся символы ОТЕНАР.
Участник клуба
Регистрация: 12.10.2007
Сообщений: 1,204
Вот схема:
объявляем два массива
WinCounts : array [char] of integer; // Количество символов в кодировке Win
DosCounts : array [char] of integer; // Количество сисволов в кодировке DOS
Очередную строку файла обработываем:
if length(S) = 0 then exit;
SetLength(S2, length(S));
OEMToChar(PChar(S), PChar(S2)); /// DOWtoWIN
S1 := Upper(S);
S2 := Upper(S2);
for i:=1 to length(S1) do begin
Inc(WinCounts[S1[i]]);
Inc(DosCounts[S2[i]]);
end;
т.е. увеличиваем количество символов в обеих кодировках.
Чем больше строк обработано, тем лучше, но достаточно даже одной строки.
После обработки части файла:
M := (WinCounts[‘О’] + WinCounts[‘Т’] + WinCounts[‘Е’] + WinCounts[‘H’] + WinCounts[‘А’]);
if (DosCounts[‘О’] + DosCounts[‘Т’] + DosCounts[‘Е’] + DosCounts[‘H’] + DosCounts[‘А’]) > M
then CodePage := cpDOS;
Форумчанин
Регистрация: 25.09.2007
Сообщений: 189
это не 100% вариант, думаю (хотя спорить не хочется)
Пользователь
Регистрация: 01.11.2007
Сообщений: 33
[b]alexBlack[b] видите ли в чем дело, мне нужно переводить из DOS кодировки в Win но я не знаю в какой кодировке пребывает файл в данный момент. Функция OEMToChar переводит (и непереводит если это не надо, хотя не уверен не тестировал ) например считав строку из файла прогоняю ее через OEMToChar и она меняется если эта строка в DOS кодировке и не меняется если в WIN кодировке! Я хочу добиться именно такого эффекта, я написал свою функцию OEMToChar, но если строка уже в Win код-ке она искажает символы входящие в диапазон от ‘р’до ‘я’
Участник клуба
Регистрация: 12.10.2007
Сообщений: 1,204
Сообщение от PuzzleC
[b]alexBlack[b] видите ли в чем дело, мне нужно переводить из DOS кодировки в Win но я не знаю в какой кодировке пребывает файл в данный момент. Функция OEMToChar переводит (и непереводит если это не надо, хотя не уверен не тестировал ) например считав строку из файла прогоняю ее через OEMToChar и она меняется если эта строка в DOS кодировке и не меняется если в WIN кодировке! Я хочу добиться именно такого эффекта, я написал свою функцию OEMToChar, но если строка уже в Win код-ке она искажает символы входящие в диапазон от ‘р’до ‘я’
То есть я не достаточно подорбно объяснил. Итак. Сначала нужно узнать в какой кодировке файл. Для этого его нужно просканировать (или хотя-бы несколько строк). Для каждой строки файла S
S1 = upper(S) — исходная строка
S2 = upper(OEMtoChar(S)) — та же строка в другой кодировке
Мы используем только верхний регистр символов, т.к. нас интересует частота встречаемости.
Увеличиваем количество символов
for i:=1 to length(S1) do begin
Inc(WinCounts[S1[i]]);
Inc(DosCounts[S2[i]]);
end;
Когда все строки проанализированы, проверяем частоты встречаемости символов ОТЕНАР в обеих кодировках
M := (WinCounts[‘О’] + WinCounts[‘Т’] + WinCounts[‘Е’] + WinCounts[‘H’] + WinCounts[‘А’]);
if (DosCounts[‘О’] + DosCounts[‘Т’] + DosCounts[‘Е’] + DosCounts[‘H’] + DosCounts[‘А’]) > M
then CodePage := cpDOS;
else CodePage := cpWIN;
И уже теперь, если cpDOS, то переводим строку в кодировку WIN.
Как уже было замечено, 100% определения не достигнуть. Но, по моим наблюдениям такой алгоритм правильно срабатывал по одной строке.
Надеюсь, я достаточно понятно объяснил.