Чем отличается структура от массива
(9)
И Андрей закричал: Я покину причал,
если ты мне откроешь секрет.
И Сиддхартха ответил: Спокойно, Андрей,
никакого причала здесь нет!
я исхожу из правила какой вопрос такой ответ))
даа очень прикольно. есть начинающие и есть профессионалы опытные, Но веь они тоже когда-то были начинающими.
(13) Даже начинающие должны правильно формулировать вопросы.
ага. у меня ребёнка тоже только начинает учиться выражать свои мысли словами
(13) не жалей клавиатуру чем лучше (полнее) опишеш вопрос тем
1) будет меньше стеба
2) Быстрее получиш ответ
ок спасибо большое!
я хотел получить краткое точное описание о различии Структуру, Массив, Таблицу значений, Соответствие()
в каких случаях надо создать Структуру и как и в каких на пример Массив и т.д.
(16) Бери ььььь, мне не жалко, пользуйся.
(17) Массив — это коллекция, элементы которой индексируются по номеру — числовому значению.
Структура — это коллекция, элементы которой индексируются по строковому значению, причем строка должна соответствовать правилам создания идентификаторов.
Соответствие — это коллекция, элементы которой индексируются значением произвольного типа.
Таблица значений — это коллекция, состоящая из строк-кортежей с одинаковой структурой (колонок).
(17)
Надо Структуру — создаешь структуру, надо массив — массив и т.д. И странно что ты не включил сюда СписокЗначений. А что надо — никто кроме тебя не знает. Очень странный вопрос. Нет каких то универсальных кратких ответов. Могу конечно написать что Структура используется для задания отборов. Массив используется, например, для задания типов. Но это лишь верхушка айсберга.
9 структур данных, которые вам понадобятся

Еще в девяностые профессор Корейского университета передовых технологий Сонгчун Мун предложил Биллу Гейтсу назвать свой стартап Microdata, а не Microsoft. Мун указал на то, что данные и их структура — будущее программирования.
Структуры данных — способы хранения и извлечения информации. Правильный выбор структуры поможет эффективнее выполнить задачу. СД важны в разработке ПО, от них зависит, как будут работать алгоритмы.
Рассказываем о структурах данных, которые используются чаще всего.
#1. Массив (Array)
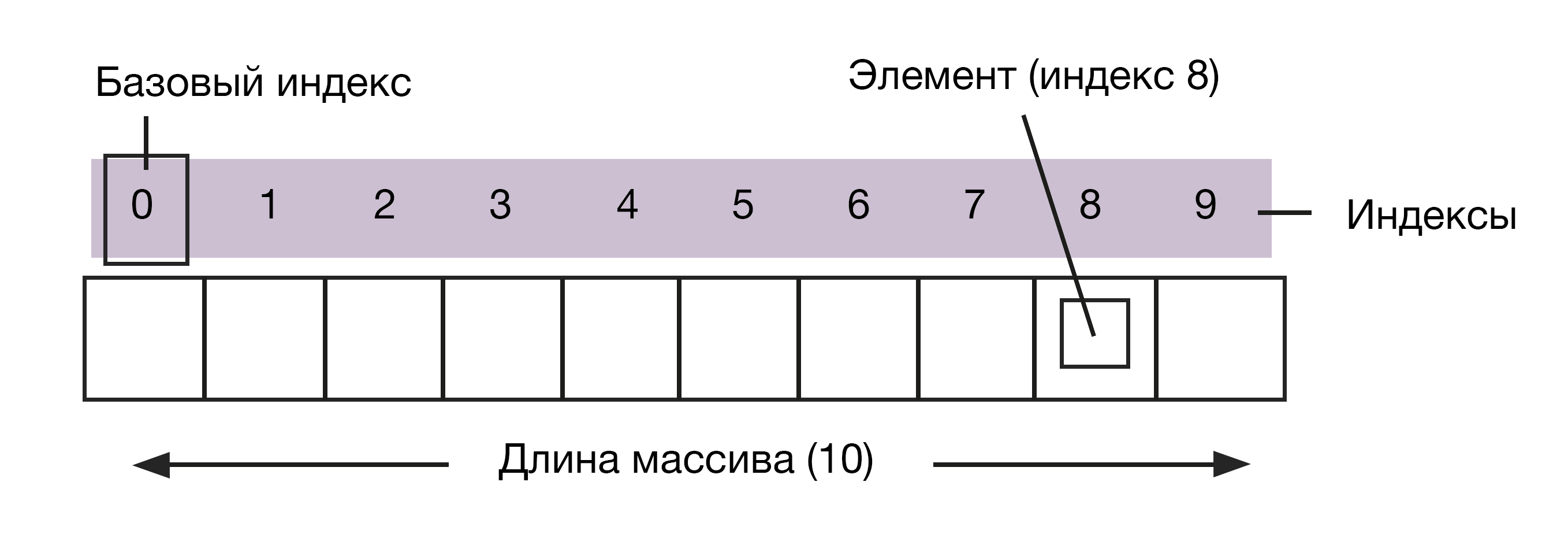
Массив — простая базовая структура. Стеки, очереди и списки — производные от массивов. Единице данных в массиве присваивается число или индекс, который указывает на ее расположение. Чтобы найти ячейку с информацией в массиве, нужно добавить к базовому элементу ее индекс. Базовый элемент, как правило, обозначается именем самого массива.
Представьте себе записную книжку со страницами, пронумерованными от 1 до 10. Каждая из них может содержать информацию или быть пустой. Блокнот — массив страниц, страницы — элементы массива «блокнот». Программно вы извлекаете информацию со страницы, обращаясь к ее индексу, то есть «блокнот+4» будет ссылаться на содержимое четвертой страницы.
Массив — это фиксированная структура, хранящая элементы одного типа в непрерывных ячейках памяти. Есть исключение — гетерогенные массивы, которые могут хранить данные разных типов. Массивы бывают одномерными и многомерными (массивы в массивах). Их размеры фиксированы, поэтому в уже созданный массив нельзя просто вставить новый элемент. Нужно скопировать старый массив и создать новый, увеличив размер.
#2. Матрица (Matrix)
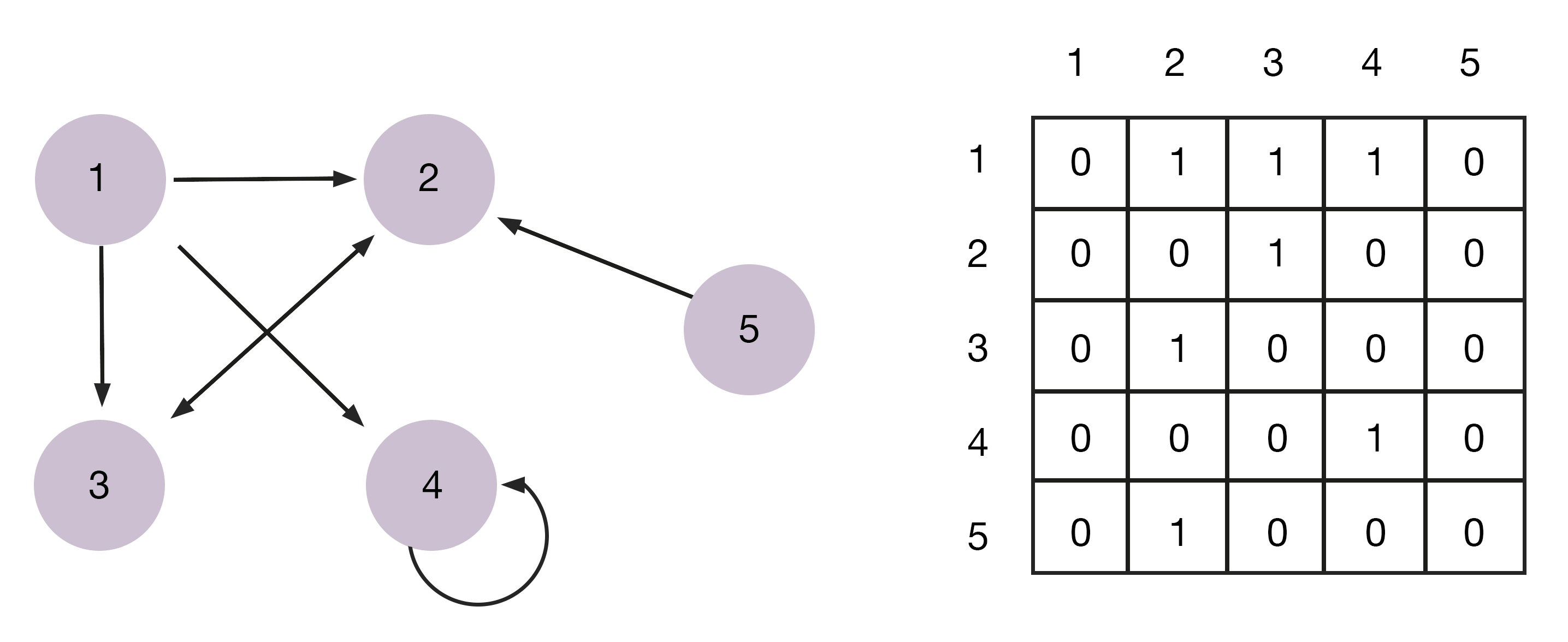
Матрица — двумерный массив, выглядящий как список столбцов и строк, на пересечении которых находятся элементы данных. Это прямоугольный массив, в котором количество строк и столбцов задает его размер. В математике их используют для компактной записи линейных алгебраических или дифференциальных уравнений.
Матрицы используют для описания вероятностей. Например, для ранжирования страниц в поиске Google при помощи алгоритма PageRank. В компьютерной графике — для работы с 3D-моделями и проецирования их на двумерный экран.
#3. Связный список (Linked list)
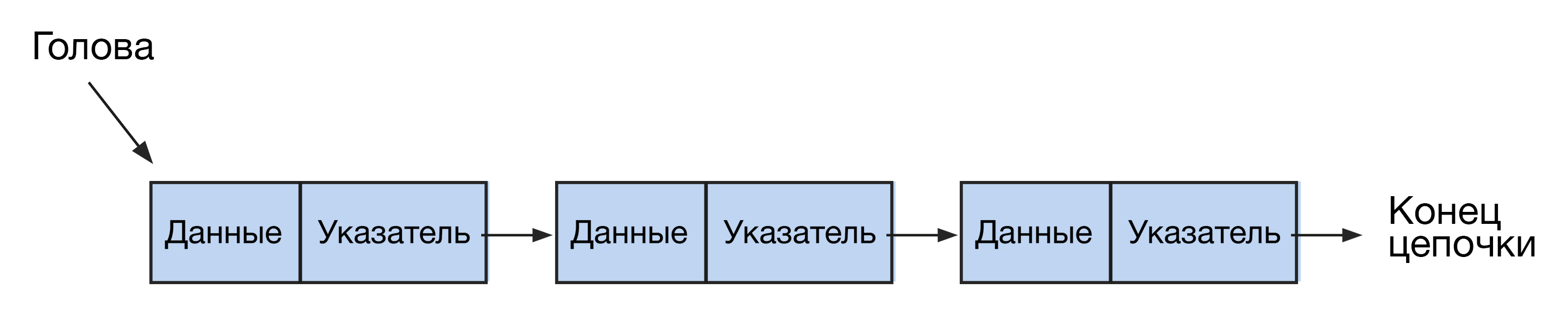
Списки схожи с массивами, но отличаются более гибкой структурой. Они выглядят как цепочки нод или узлов, где каждая нода содержит ссылку на следующую. Доступ к элементам в связном списке осуществляется последовательно, в отличие от массивов с произвольным доступом. Списки бывают односвязными и двусвязными.
Начальный элемент этой структуры называется головой, а все последующие узлы цепочки — хвостом. Хвост состоит из элементов двух типов: с информацией (info) и с указанием на следующий узел (next). Конец цепочки обозначается как null.
#4. Стек (Stack)
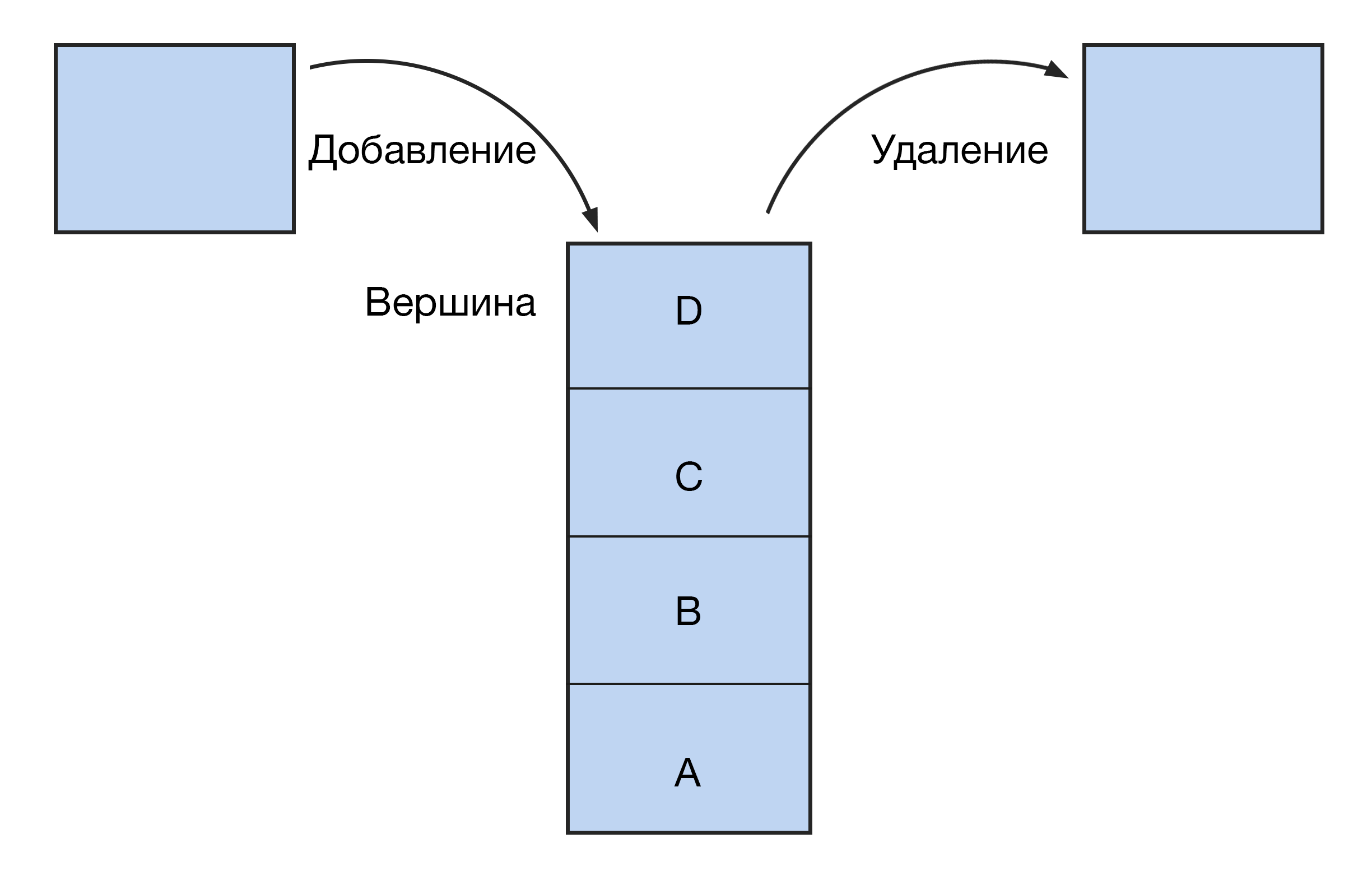
Это вертикальный столбец с блоками, доступ к которым можно получить только с одного конца: сверху или снизу. Как в стопке книг — чтобы добраться до нижней, нужно сначала убрать все книги сверху.
Новые элементы стека заменяют старые. Принцип работы такой структуры — LIFO (last in — first out, «последним пришел — первым ушел»). Поэтому стек еще называют магазином — по аналогии с огнестрельным оружием: выстрелит патрон, который был заряжен последним.
Эта структура данных реализована в функции «отменить» (undo). Программа сохраняет статус работы так, что последнее действие становится первым в очереди на отмену. В стеке возможны всего три операции: добавление элемента (push), удаление (pop), чтение (peek).
Стек может быть реализован в виде связного списка или одномерного массива. В первом случае, каждый элемент содержит ссылку на следующий, во втором — упорядочен индексом.
Существует похожая СД — дек (deque — double ended queue, «двусторонняя очередь»). Это стек с двусторонним доступом.
#5. Очередь (Queue)
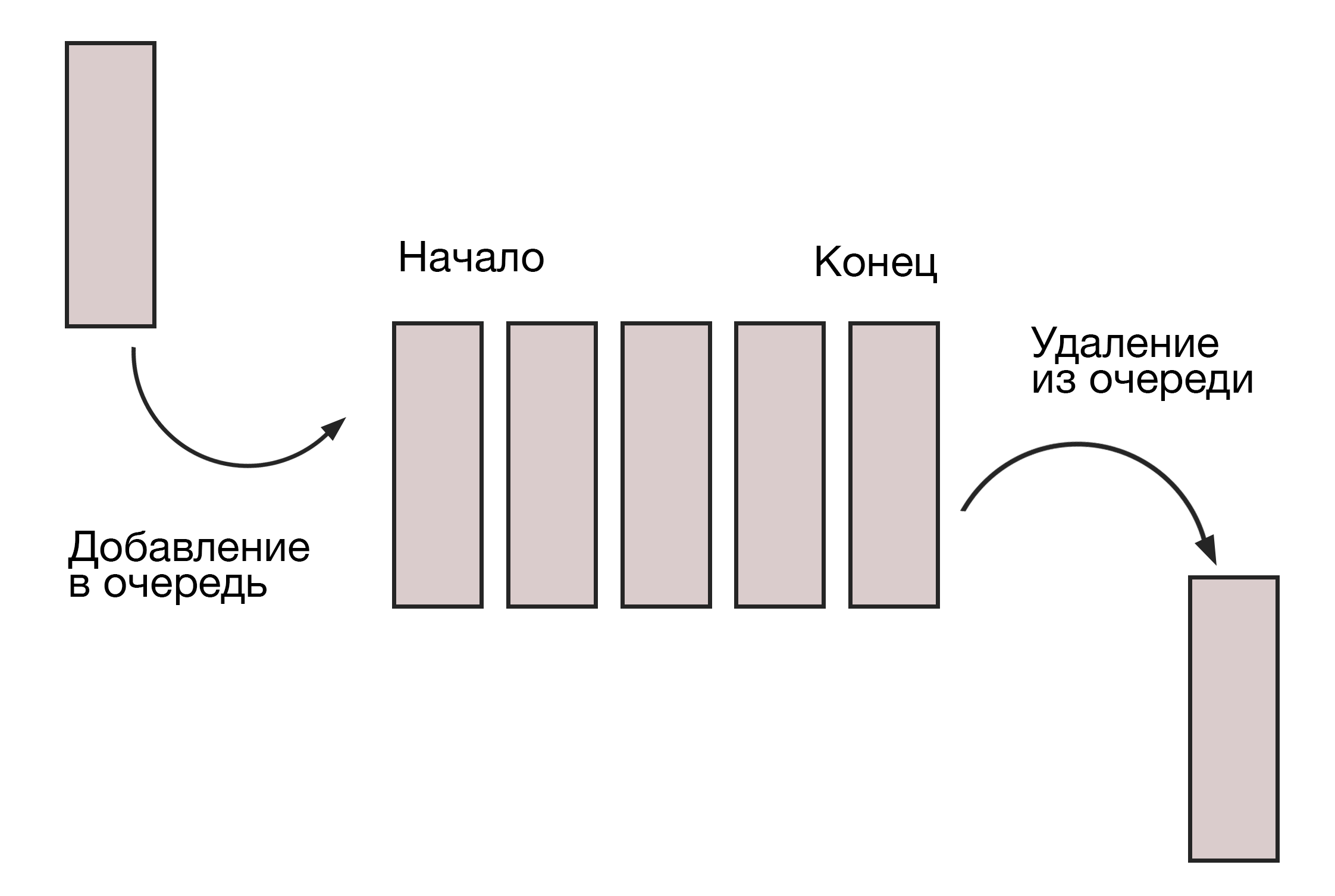
Этот тип СД напоминает стеки, но принцип работы реализован как FIFO (first in — first out, «первым пришел — первым ушел»). Как в супермаркете: первым покупки унесет домой тот, кто раньше всех займет очередь.
Очереди используются, когда ресурс нужно распределить между несколькими потребителями (работа ЦП, пропускная способность роутера). Или когда данные передаются асинхронно, то есть скорости приема и отдачи — разные.
В этой СД можно выполнить две операции: добавление элемента в конец очереди (enqueue) и удаление первого элемента (dequeue). Очереди бывают в виде связных списков или массивов, по аналогии со стеками.
#6. Дерево (Tree)
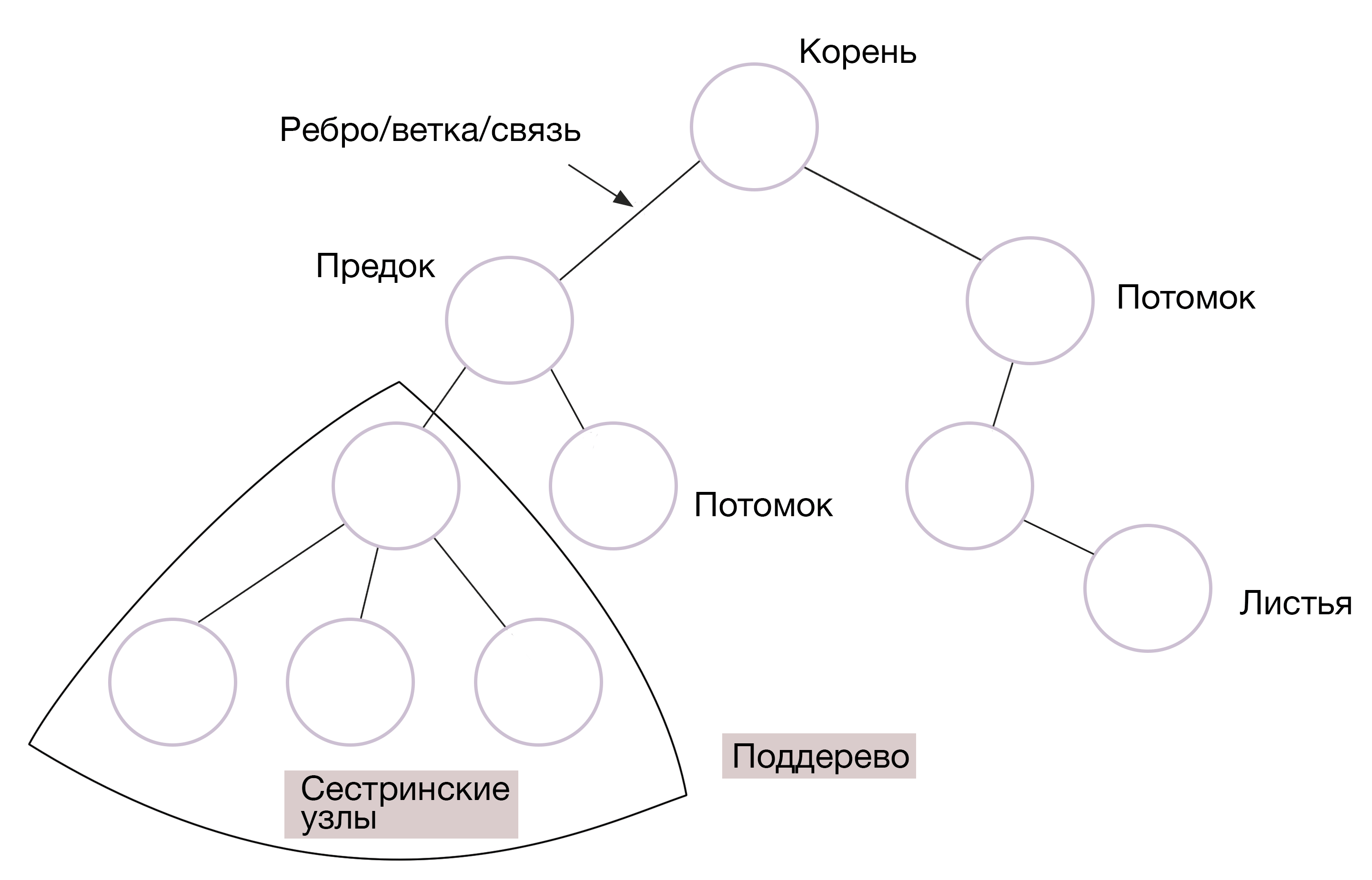
Деревья — структура, в которой данные связаны между собой узлами, и при этом расположены иерархически. Различают двоичное дерево поиска, расширенное, черно-красное и еще десяток видов.
Как и у настоящего дерева, тут есть корни, ветви и листья. Самый верхний узел в этой СД, не имеющий предков, называется корневым. Остальные узлы — потомками или дочерними элементами. Дочерние узлы с одним и тем же родителем — это узлы-братья. А листья — это узлы, не имеющие потомков.
Деревья используют, например, в разработке видеоигр. Они позволяют разделить пространство и быстро находить объекты. Так, дерево с четырьмя дочерними узлами (quadtree) — квадрант — используется для создания карты и ориентации по четырем сторонам света в игре.
Но деревья сложно хранить и у них невысокая скорость работы.
курсы по теме:
Data Science with Python
Ячейка по сравнению с массивами структур
Этот пример сравнивает ячейку и массивы структур, и показывает, как хранить данные в каждом типе массива. И ячейка и массивы структур позволяют вам хранить данные различных типов и размеров.
Массивы структур
Массивы структур содержат данные в полях, к которым вы получаете доступ по наименованию.
Например, сохраните записи о пациенте в массиве структур.
patient(1).name = 'John Doe'; patient(1).billing = 127.00; patient(1).test = [79, 75, 73; 180, 178, 177.5; 220, 210, 205]; patient(2).name = 'Ann Lane'; patient(2).billing = 28.50; patient(2).test = [68, 70, 68; 118, 118, 119; 172, 170, 169]; patient
patient=1×2 struct array with fields: name billing test
Создайте столбчатый график результатов испытаний для каждого пациента.
numPatients = numel(patient); for p = 1:numPatients figure bar(patient(p).test) title(patient(p).name) xlabel('Test') ylabel('Result') end


Массивы ячеек
Массивы ячеек содержат данные в ячейках, к которым вы получаете доступ числовой индексацией. Распространенные приложения массивов ячеек включают хранение отдельные части текста и хранить гетерогенные данные из электронных таблиц.
Например, храните температурные данные для трех городов в зависимости от времени в массиве ячеек.
temperature(1,:) = '2009-12-31', [45, 49, 0]>; temperature(2,:) = '2010-04-03', [54, 68, 21]>; temperature(3,:) = '2010-06-20', [72, 85, 53]>; temperature(4,:) = '2010-09-15', [63, 81, 56]>; temperature(5,:) = '2010-12-09', [38, 54, 18]>; temperature
temperature=5×2 cell array <[ 45 49 0]> <[54 68 21]> <[72 85 53]> <[63 81 56]>
Постройте температуры для каждого города по дате.
allTemps = cell2mat(temperature(:,2)); dates = datetime(temperature(:,1)); plot(dates,allTemps) title('Temperature Trends for Different Locations') xlabel('Date') ylabel('Degrees (Fahrenheit)')

Другие контейнерные массивы
Массивы структур и массивы ячеек являются обычно используемыми контейнерами для того, чтобы хранить гетерогенные данные. Таблицы удобны для того, чтобы хранить неоднородные ориентированные на столбец или табличные данные. В качестве альтернативы используйте контейнеры карты или создайте ваш собственный класс.
Смотрите также
Связанные примеры
- Доступ к данным в массиве ячеек
- Массивы структур
- Доступ к данным в таблицах
Больше о
Открытый пример
У вас есть модифицированная версия этого примера. Вы хотите открыть этот пример со своими редактированиями?
Документация MATLAB
Поддержка
- MATLAB Answers
- Помощь в установке
- Отчеты об ошибках
- Требования к продукту
- Загрузка программного обеспечения
© 1994-2021 The MathWorks, Inc.
- Условия использования
- Патенты
- Торговые марки
- Список благодарностей
Для просмотра документации необходимо авторизоваться на сайте
Войти
Памятка переводчика
1. Если смысл перевода понятен, то лучше оставьте как есть и не придирайтесь к словам, синонимам и тому подобному. О вкусах не спорим.
2. Не дополняйте перевод комментариями “от себя”. В исправлении не должно появляться дополнительных смыслов и комментариев, отсутствующих в оригинале. Такие правки не получится интегрировать в алгоритме автоматического перевода.
3. Сохраняйте структуру оригинального текста — например, не разбивайте одно предложение на два.
4. Не имеет смысла однотипное исправление перевода какого-то термина во всех предложениях. Исправляйте только в одном месте. Когда Вашу правку одобрят, это исправление будет алгоритмически распространено и на другие части документации.
5. По иным вопросам, например если надо исправить заблокированное для перевода слово, обратитесь к редакторам через форму технической поддержки.
Структуры и типы данных
В этой статье мы представим основные термины и классификацию простейших структур и типов данных, расскажем про их особенности и нюансы применения. Также приведем примеры статических и динамических структур.
Классификации
Вряд ли кто-нибудь решится спорить с тем, что в памяти компьютера данные (data) представлены в виде последовательности битов. Эти последовательности структурированы недостаточно, что затрудняет их применение на практике. Именно поэтому широко используются специальные структуры данных.
Структурой данных можно назвать некое количество элементов, которые имеют между собой внутренние связи. Существуют как простые, так и интегрированные структуры данных. Простые организуются из битов, вот их примеры:
Интегрированные организуются с помощью простых и других интегрированных структур. Также структуры бывают физические и логические.
Немаловажно знать и такой термин, как изменчивость структуры — речь идет об изменении количества элементов и связей между ними. Учитывая понятие изменчивости, можно разделить структуры на статические и динамические. Статические структуры данных мы все хорошо знаем — из основных можно вспомнить массив, множество, вектор, запись, таблицу. Программистам хорошо известны и динамические структуры данных (три наиболее популярные — очередь, стек, списки).
Как уже было сказано выше, структура состоит из элементов данных. Эти элементы бывают как упорядоченными, так и неупорядоченными. С учетом этого признака, структуры данных можно разделить на следующие группы:
— нелинейные (к примеру, многосвязные списки, графы, деревья с их корневыми узлами, потомками и т. д.);
— линейные с последовательным распределением (это вектор, массив, строка, очередь, стек);
— линейные, но уже с произвольным связным распределением (это односвязные и двусвязные списки).
Простейшие структуры и основные типы
Такие конструкции называют примитивами либо базовыми структурами данных. К примеру, в языках программирования они представлены простыми типами данных. В зависимости от языка набор типов может отличаться, но эти различия не очень существенны, поэтому можно говорить о наличии неких общих принципов.
Первый тип — целочисленный (целый тип), который применяется для обозначения целых чисел (int, integer). Из школьного курса математики мы знаем, что целые числа бывают отрицательными либо беззнаковыми. Во внутреннем машинном представлении целое число может занимать 1, 2 либо 4 байта.
Второй тип— вещественный. Он уже имеют вид числа с плавающей точкой. Такое число представляется посредством двух целых чисел – матиссы и порядка, плюс знака.

Третье — десятичный тип (decimal). Его поддерживает не каждый язык программирования. К примеру, такой тип есть в C# — он имеет разрядность 128 бит и может представлять числовые значения в пределах от 1Е-28 до 7,9Е+28. Применяется в финансовых расчетах.
Если предполагается работа с отдельными двоичными числовыми разрядами, существует битовый тип. Здесь данные — это набор битов, которые объединены в байты либо слова. При выполнении операций предполагается обращение к каждому биту отдельно.
Идем дальше. Переменная, имеющая логический тип, способна принимать одно из 2-х значений: либо истину, либо ложь. Для хранения такой переменной требуется 1 байт памяти. False кодируется нулевым значением байта, True — любым значением, отличным от нуля.
Символьный тип дает возможность представлять данные в виде последовательности символов какого-нибудь определенного заранее множества. Каждый символ хранится в памяти в качестве последовательности битов. Соответствие символов и последовательностей называют кодировкой. Разные кодировки представляют символы в форме битовых последовательностей разной длины.
Указатель — это переменная, ее значение — адрес ячейки памяти. В результате указатель ссылается на какой-нибудь блок данных и указывает на его первую ячейку.
Примеры статических структур данных
Вектор либо одномерный массив – структура, содержащая определенное количество элементов простого типа. У каждого элемента — свой уникальный индекс. Для обращения к элементу используют имя массива, а также индекс элемента. В памяти компьютера массивы размещаются я ячейках, причем эти ячейки располагаются одна за другой.
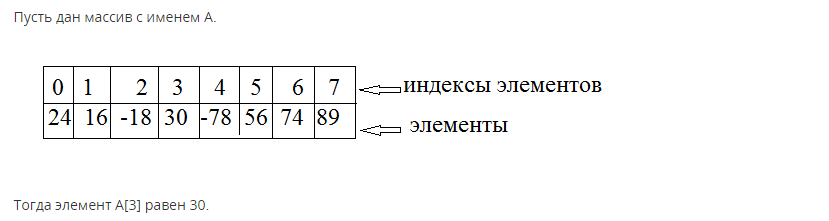
В двумерном массиве каждый элемент массива сам будет являться одномерным массивом. В результате у элемента существуют не один, а 2 индекса.
Записи (ассоциативные массивы или хэш-массивы) представляют собой массивы, индексируемые строками, а не натуральными числами. Индекс компонента здесь называют ключом.
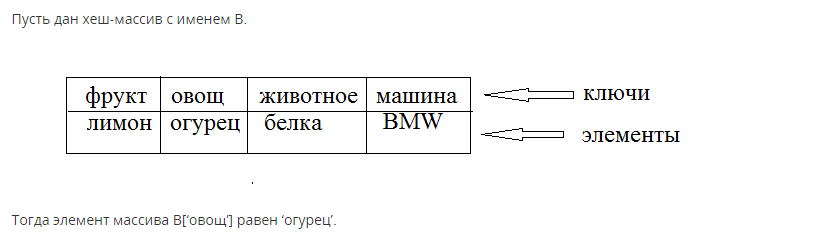
Примеры динамических структур данных
В этом случае объем памяти не фиксируется заранее, а определяется «на ходу» в процессе исполнения программы. Чтобы работать с динамическими типами, во многих языках программирования предусмотрены указатели, причем сами по себе они имеют статический тип.
Яркий пример — стек. Это, по сути, вектор, где каждый следующий компонент адресуется указателем на текущий компонент. Ниже рассмотрено последовательное добавление компонентов в стек, а также последовательное извлечение. Стек организован по принципу LIFO (last in — first out).
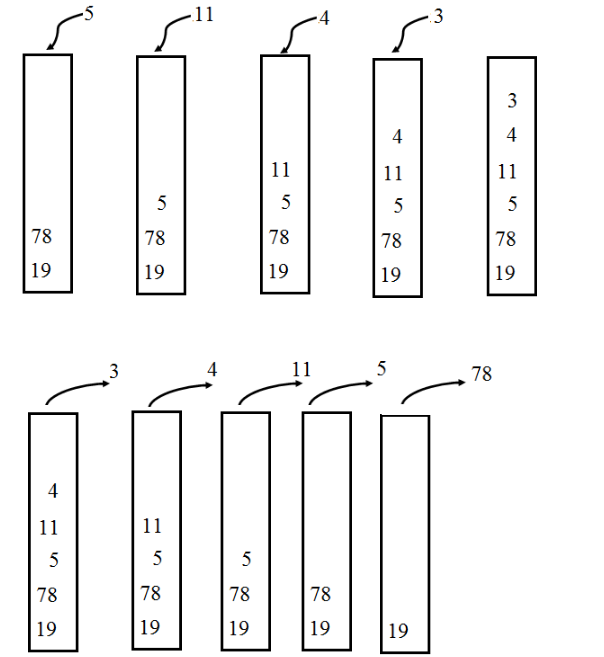
Нельзя не вспомнить и про очередь — динамическую структуру, отличающуюся от стека наличием 2-х указателей. Эти указатели показывают на 1-й и последний компоненты очереди. Очередь организована по принципу FIFO (first in, first out).
Если хотите узнать про структуры данных подробнее, обратите внимание на следующую статью.