Что такое база данных – особенности, принцип работы и выбора системы управления
Что такое база данных? Это инструмент, используемый для управления информацией и ее хранения. Она является основой для многих цифровых приложений, таких как онлайн-банкинг, социальные сети, поисковые системы и сайты электронной коммерции.
В чем преимущества? Прежде всего, базы данных позволяют предприятиям хранить сведения в больших объемах в упорядоченном виде. Кроме того, они безопасны и надежны, а также полезны при анализе эффективности бизнеса, что может помочь скорректировать дальнейшую работу.
В статье рассказывается:
- Преимущества работы с базами данных
- Задачи, которые ставят перед БД
- Свойства базы данных
- Система хранения информации в базах данных
- Проектирование баз данных
- Требования к проектированию БД
- Виды баз данных
- Примеры использования баз данных
- Системы управления базами данных
- Виды СУБД по способу доступа
- Популярные системы управления базами данных
- Сравнение SQL и NoSQL
- На что ориентироваться при выборе базы данных
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Преимущества работы с базами данных
Таблицы упрощают нам жизнь. В табличном виде удобно представлять меню ресторана, создавать квитанции для квартплаты и т. д. Для чтения таблиц не нужны никакие дополнительные инструменты — все данные легко и быстро читаются. Другое дело, когда число строк и столбцов начинает исчисляться сотнями тысяч. В таких случаях с обработкой табличных данных возникают сложности даже при использовании редакторов типа MS Excel.
На помощь приходят разбивка одной крупной таблицы на несколько и организация связей между значениями. Таким образом возникают базы данных. В итоге они представляют собой упорядоченную информацию, которая хранится в цифровом (электронном) виде.
Чтобы разобраться, что такое база данных, рассмотрим в качестве примера двух друзей, решивших открыть кофейню. Стоит задача определить ассортимент напитков. Прежде всего нужно проанализировать меню конкурентов. Результаты заносятся в специально созданную базу данных. Это поможет определить спрос на отдельные напитки, одни из которых обеспечат выручку кофейне, другие — привлекут посетителей уникальным составом.
Далее изучаются поставщики. Здесь также происходит деление. Кто-то поставляет свежие кофейные зерна, кто-то торгует специальным оборудованием, а у кого-то можно закупать посуду. Вся эта информация также заносится в базу. В сравнении с обычными таблицами это более удобный формат по нескольким причинам:
- Имеется возможность хранения, обработки и структурирования гораздо большего объема данных.
- Благодаря встроенному языку запросов и удаленному доступу множество людей могут одновременно выполнять операции с БД. Современные электронные таблицы также подразумевают групповую работу через интернет, но в системах управления базами данных этот процесс более организован, безопасен и оперативен.
- БД могут содержать огромные массивы данных, что никак не влияет на скорость обработки. А, к примеру, таблица Google, состоящая из нескольких сотен строк или столбцов, уже будет загружаться заметно медленнее.
Задачи, которые ставят перед БД
Крупнейшие мировые компании работают с огромными объемами информации, оперативный доступ к которой должен обеспечиваться даже в ответ на сложные запросы. Администраторам баз данных необходимо повышать производительность используемого программного обеспечения с целью:
- эффективного управления непрерывно растущими массивами информации, получаемой от различных источников;
- обеспечения безопасности данных, включая минимизацию риска утечки этой информации и защиту ее от хакерских атак;
- обеспечения быстрого доступа к информации для своевременного принятия важных решений пользователями БД;
- управления базами данных, включая регулярный мониторинг на наличие ошибок, проведение профилактики, обновление ПО и исправление возникающих проблем;
- поиска новых возможностей управления для развития бизнеса.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 25507
Современные СУБД усложняются, а объемы обрабатываемых данных возрастают. Это требует привлечения и обучения новых специалистов для решения перечисленных выше задач.
Свойства базы данных
Системы управления базами данных очень удобны в использовании. Это достигается благодаря наличию следующих свойств:
- Быстродействие системы. Система поиска позволяет легко находить нужную информацию даже в больших массивах данных. В обычных электронных таблицах это делать сложнее.
- Простота получения и изменения данных. Для добавления и обновления информации оператору требуется совершить минимальное количество действий.
- Безопасность. Большая часть баз данных настраивается под разные уровни доступа. Возможно разрешение либо запрет просмотра или редактирования записей определенным пользователям.
- Многопользовательский доступ. Современные СУБД поддерживают одновременную работу нескольких пользователей с одной базой.
- Поддержка очень больших объемов данных. В БД можно хранить действительно огромные массивы информации. Далее будет подробно разъяснено, что такое запись. База данных позволяет обрабатывать информацию, содержащуюся в миллионах таких записей.
Система хранения информации в базах данных
БД можно представить в виде трехуровневой структуры. Перечислим данные уровни по порядку от большего к меньшему.
БД
Вся база данных занимает самый верхний уровень, где объединяются абсолютно все данные, хранение которых продиктовано конкретной целью.
Каждый веб-сайт независимо от разновидности и предназначения, как правило, имеет отдельную БД, внутри которой содержится вся необходимая информация.
Таблица
База данных состоит из таблиц, коих в одной БД может насчитываться несколько тысяч.
Разберемся на простом примере, что такое таблица. База данных, допустим, представляет собой большой шкаф. Тогда все содержимое (например, коробки из-под обуви) можно сравнить с таблицами.
Иными словами, этот компонент БД служит для хранения данных какого-то одного типа. Например, создается таблица списка городов или пользователей интернет-ресурса. Фактически она может храниться в виде файла Excel или даже обычного набора строк и столбцов.
Любому пользователю компьютера такой формат знаком. Табличный файл позволяет легко подсчитать количество строк и столбцов, прочитать заголовки, внести нужные данные в таблицу.
Аналогичным образом организован процесс и в базе данных. В системе создается таблица, для которой пользователь определяет вид и структуру.
Запись
Это низший уровень иерархии БД. Запись является частью таблицы, фактически формируя ее наполнение. Данный компонент неделим. К примеру, при заполнении формы на сайте введенная информация вносится в таблицу базы как одна запись, распределяясь по столбцам и строкам этой таблицы. Объем вносимых данных должен быть заранее определен.
В качестве примера разберем процесс создания онлайн-дневника. С точки зрения системы БД выполняются следующие действия:
- Создание новой базы данных сайта с именем «private diary»
- Создание таблицы с именем «diary log»
- Задание столбца «День недели» с типом данных «текст»
- Задание столбца «День» с типом данных «дата»
- Задание столбца «Номер записи» с типом данных «число»
- Задание столбца «Настроение» с типом данных «число» и ограничением от 0 до 5 (от плохого до отличного соответственно)
- Задание столбца «Комментарий» с типом данных «текст»
- Добавление новой записи с заполнением соответствующих полей в таблице каждый раз при сохранении формы
Сформированная таким образом база данных позволит хранить всю вводимую пользователями информацию и предоставит быстрый доступ к ней.
Проектирование баз данных
Проектирование БД включает в себя не только создание таблиц, определение имен столбцов и указание типов данных. Этот процесс в целом намного сложнее. Он требует наличия специальных навыков и знаний. Под типами данных здесь понимается в числе прочего способ записи этих данных (символы, строки, числа, даты, пустые данные NULL и т. д.).
Для вас подарок! В свободном доступе до 14.01 —>
Скачайте ТОП-10
бесплатных нейросетей
для программирования
Помогут писать код быстрее на 25%
Чтобы получить подарок, заполните информацию в открывшемся окне
Основная проблема проектирования БД заключается в ограниченной вычислительной мощности оборудования. Малый объем данных обрабатывается относительно быстро. Но со временем количество информации растет, а это ведет к снижению быстродействия компьютера. Соответственно, запросы обрабатываются медленнее. Здесь стоит вкратце упомянуть, что такое реляционная база данных.
Новые записи в эти СУБД добавляются весьма быстро, а вот выборка определенной информации тратит достаточно много ресурсов. Впрочем, скорость обработки запросов зависит и от конкретных настроек системы.
Требования к проектированию БД
Ранее мы разобрались, в чем заключаются главные особенности реляционных баз данных. Теперь стоит поговорить о проблемах, возникающих при проектировании этих БД. Весь процесс начинается с постановки задач в зависимости от требований, сферы использования проектируемой базы, а также плюсов и минусов выбранной СУБД. В качестве примера рассмотрим популярную систему MySQL.
Формируем структуру базы, исходя из следующих требований:
- Необходимо обеспечить простую обработку данных.
- БД должна быть максимально компактной и лаконичной, но с сохранением всей функциональности.
Помимо этого, могут формулироваться и другие требования, иногда даже противоречащие друг другу. Основная задача проектировщика — найти оптимальный баланс в архитектуре БД с учетом изначально запланированного назначения продукта.
В роли специалиста, занимающегося проектированием, обычно выступает профессиональный серверный администратор или опытный архитектор БД. В этой работе важно понимать, какого результата необходимо достичь. Требуется также знать, что такое структура базы данных, и насколько сложной она может быть. Иные БД состоят из сотен таблиц, которые могут быть весьма замысловато связаны друг с другом. В грамотном создании структуры и состоит основная трудность проектирования.
Дарим скидку от 60%
на курсы от GeekBrains до 14 января
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
В результате должна получиться подробная диаграмма или схема, где определены все типы хранимых данных, указаны количество и типы столбцов в таблицах, показаны взаимосвязи этих таблиц и т. д. Грамотно выполненное проектирование обеспечит стабильную работу базы. В противном случае возникнут весьма серьезные проблемы. Нужно помнить, что самые грубые ошибки рождаются как раз на этапе построения архитектуры конечного продукта.
Виды баз данных
Мы разобрались, что такое база данных. Виды БД, количество которых сегодня исчисляется десятками, можно структурировать по степени популярности. Ниже перечислим наиболее популярные разновидности:
- Реляционные БД. Стали активно распространяться, начиная с 1980-х годов. Главной особенностью этого вида баз данных является организация структуры. Элементы реляционной БД представлены в виде таблиц, содержащих строки и столбцы. Благодаря этому максимально упрощается доступ к структурированным данным.
- Объектно-ориентированные БД. Здесь данные по аналогии с современными языками программирования рассматриваются как объекты.
- Хранилища данных. Служат для оперативного анализа и выполнения запросов.
- Распределенные БД. Состоят из нескольких файлов, находящихся на разных компьютерах. Одна такая база физически может как располагаться на одном узле, так и распределяться по нескольким сетям.
- Графовые БД. Данные здесь представлены как определенным образом взаимосвязанные друг с другом сущности.
- Иерархические БД. В качестве формы представления используется древовидная структура.
- Нереляционные БД. Также называются NoSQL. Предназначаются для хранения и обработки неструктурированной информации и данных со слабо выраженной структурой.
- Аналитические БД. Другое название — OLTP. Используются разными пользователями для выполнения множества операций.
Стремительное развитие сектора ИТ привело к появлению принципиально новых разновидностей баз данных:
- автономные БД;
- облачные БД;
- БД с открытым исходным кодом;
- документные БД (или JSON);
- многомодельные БД.
Примеры использования баз данных
Любая компания использует информацию, которую необходимо структурировать, где-то хранить и каким-то образом обновлять.
Показания счетчиков
Если организация располагается в отдельном помещении, она потребляет электричество и воду. Расходы этих ресурсов учитываются счетчиками. Автоматические приборы сами передают показания в управляющие компании, на основании чего потребителю выставляется счет.
Успешная оплата отображается в базе данных, где также указывается, что задолженность отсутствует. Каждая управляющая компания обслуживает огромное количество абонентов. Для хранения такого массива показаний и нужны базы данных, позволяющие сортировать счетчики по различным критериям (номера квартир, задолженности и пр.). Средствами обычных электронных таблиц эту задачу решить не получится.
Сведения о персонале
Если штат сотрудников небольшой, информацию о них можно фиксировать в обычной таблице. Но для обеспечения безопасности нужно ограничить доступ к этим данным, что легко реализуется с помощью СУБД. Персональные сведения о каждом сотруднике включают в себя конфиденциальную информацию, например, касающуюся заработной платы.
База данных в таком случае будет храниться на стороне банка. Непосредственному начальнику потребуется лишь контролировать своевременное начисление зарплаты.
База потенциальных клиентов
В различных кафе часто практикуется предложение клиентам поучаствовать в программах лояльности. Для этого собираются контактные данные покупателей. Хранение этой информации и ее обработка также невозможны без организации БД.
Налоги
Налоговые службы обрабатывают огромный массив информации о налогоплательщиках. Здесь в любом случае требуется использование СУБД. Возможностей Excel было бы недостаточно для ежемесячного оповещения всех резидентов о начисленных налогах.
Заказы в кофейне
Безусловно владельцу заведения можно лишь приблизительно оценивать посещаемость по дням недели. Однако это дает незначительный результат. Гораздо больший позитивный эффект обеспечивает работающая база данных, содержащая всю информацию о заказах и посетителях.
Только до 11.01
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:

ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы зарегистрироваться на бесплатный интенсив и получить в подарок подборку файлов от GeekBrains, заполните информацию в открывшемся окне
Сайт
Любой полноценный веб-сайт строится на основе БД. В базе хранятся абсолютно все данные, которые необходимы для нормальной работы ресурса, включая изображения, сведения о зарегистрированных пользователях, статистику посещений и т. д.
Системы управления базами данных
Физически БД являются обычными файлами на компьютере и служат местом хранения структурированной информации. Добавлять в себя данные, изменять их эти файлы сами не могут. Для этого требуется система управления (СУБД). Именно с ее помощью пользователи управляют таблицами и записями.
Итак, что такое система управления базой данных и как она организована? Фактически это набор программных средств, позволяющих добавлять, удалять, сортировать, фильтровать и искать определенные элементы БД. Также данные инструменты необходимы для изменения структуры базы и создания резервных копий.
СУБД является непосредственным исполнителем пользовательских запросов к конкретной БД.
Ядро этой системы отвечает за хранение базы, обслуживает ее и фиксирует изменения. Обработкой запросов пользователя занимается процессор или компилятор специального языка программирования . Как правило, в качестве последнего в реляционных и объектно-ориентированных БД используется SQL. В отдельных СУБД могут иметься внутренние языки запросов.
Также частью данных систем являются сервисные утилиты, поставляемые зачастую в большом количестве для выполнения конкретных задач обслуживания базы. В большинстве случаев имеется поддержка дополнительно подключаемых пользовательских модулей.
Виды СУБД по способу доступа
Для хранения БД используется сервер, который может либо располагаться на одном компьютере, либо находиться на разных устройствах, соединенных в единую сеть. В первом случае говорят о локальной СУБД, во втором — о распределенной СУБД. Базой данных, размещенной локально на компьютере, можно пользоваться лишь с этого компьютера.
Хранение информации и обеспечение к ней доступа могут организовываться тремя способами.
- Клиент-серверная архитектура подразумевает размещение базы и СУБД на одном удаленном сервере.
К этой БД могут подключаться пользователи, являющиеся в данном случае клиентами. В частности, таким образом делается запрос сведений об определенном сайте.
Обработка клиентских обращений осуществляется исключительно сервером. Клиенты же не должны напрямую взаимодействовать с базой. Иными словами, конечному пользователю не нужно устанавливаться специализированное ПО, чтобы, к примеру, получить доступ к сайту. Эта работа выполняется серверной частью, строго отделенной от клиентской.
Такая архитектура применяется наиболее часто. Она обеспечивает базам данных высокую надежность и доступность.
- Файл-серверная архитектура организует хранение базы на специальном файл-сервере, системы управления при этом располагаются на клиентских компьютерах.
Таким образом, доступ к БД имеют лишь те клиенты, на устройствах которых установлена СУБД.
В настоящее время данная архитектура используется в очень редких случаях, связанных главным образом с обеспечением работы приложений в локальных сетях. Для реализации крупных проектов файл-серверные СУБД практически не применяют.
- Встраиваемая архитектура реализуется в виде небольшой локальной системы управления, настроенной под потребности конкретного программного обеспечения.
Фактически СУБД встраивается в программу в качестве модуля. Необходимость в такой архитектуре возникает при разработке локального ПО. Система обладает малым размером и полностью устанавливается на одно устройство вместе с приложением.
Популярные системы управления базами данных
MySQL
Эта популярнейшая СУБД используется многими мировыми корпорациями (Twitter, Amazon, LinkedIn и т. д.). Она относится к реляционным системам и распространяется по принципам свободного ПО.
Перечислим характерные особенности.
- Пользователям предоставляется для работы большой выбор типов таблиц, включая такие редко используемые, как MERGE и HEAP.
- Система регулярно обновляется. Разработчики продолжают добавлять в нее поддержку новых типов таблиц.
- MySQL поддерживает многопользовательский режим, оставаясь при этом одной из самых быстрых систем. На скорость также не влияет и огромное количество строк в таблицах, достигающее 50 млн.
- Благодаря сравнительно малому количеству функций работа с данной системой не вызовет особых затруднений у новичков.
MySQL может работать как в графическом, так и в текстовом режимах. А c использованием программы phpMyAdmin администрирование БД возможно и через обычный браузер. Знать команды запросов SQL при этом необязательно.
Итак, система MySQL удобна и проста в использовании. Она обладает гибкостью и вполне пригодна в работе с крупными и средними проектами.
Oracle
Данная СУБД относится к объектно-реляционному типу. Название системе дала одноименная компания-разработчик. Взаимодействие с базой данных осуществляется посредством языка Java и расширения PL/SQL.
Приведем главные особенности системы.
- База легко восстанавливается после произошедшего сбоя. Реализована надежная система резервного копирования. Также присутствуют множество других полезных функций.
- Хранящиеся пользовательские данные надежно защищены.
- Перед использованием систему следует активировать. Это весьма дорогостоящая операция, поэтому данная СУБД может быть недоступна для начинающих администраторов и небольших компаний.
PostgreSQL
Эта СУБД также является объектно-реляционной, но в отличие от предыдущей распространяется свободно. От системы MySQL отличается более широким функционалом с внедрением инноваций. Работа с PostgreSQL осуществляется посредством языка SQL.
Какие бывают базы данных
Базы данных — это способ упорядочить информацию так, чтобы компьютер мог с ней легко работать, а человек мог пользоваться этими данными как ему удобно. Мы уже писали о базах данных в общем, теперь углубимся.
�� Это знания скорее из области информатики, чем прикладного программирования. Если вы просто делаете сайты или обслуживаете интернет-магазин, вероятнее всего, вам из этого понадобятся только реляционные базы данных. Но когда вы захотите сделать более сложные приложения — например рекомендации товаров, — вам потребуются знания о других типах баз.
Считайте, что эта статья для расширения кругозора.
Три основных типа
В зависимости от того, какие данные нужно в ней хранить и как с ними работать, базы делятся на реляционные и нереляционные:
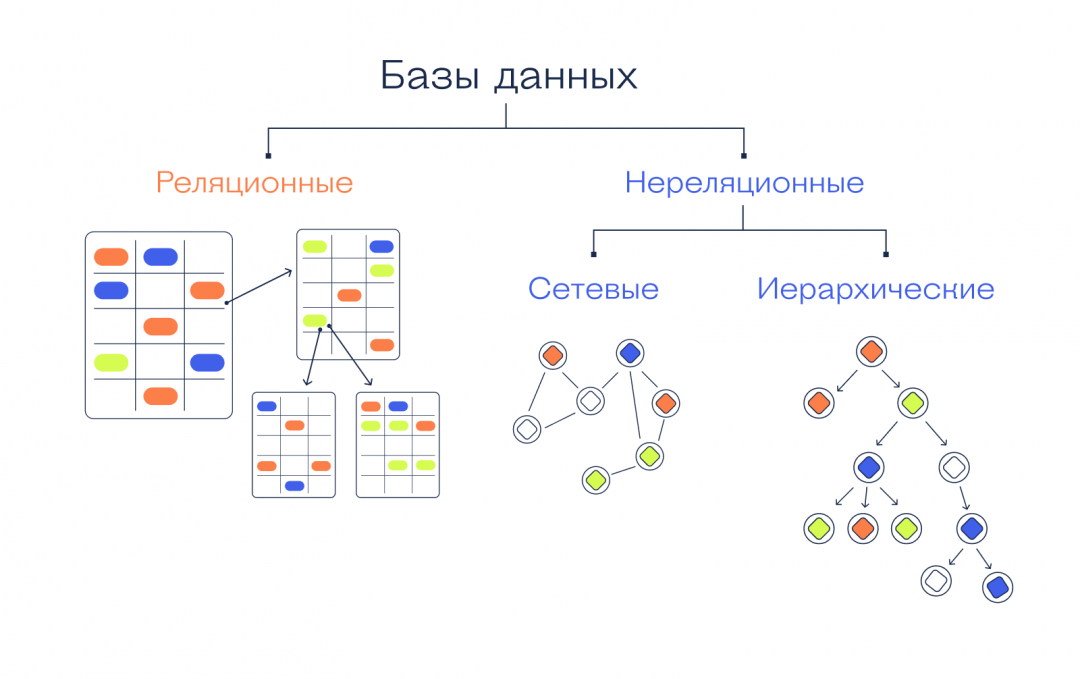
Реляционные
Реляционные базы данных ещё называют табличными, потому что все данные в них можно представить в виде разных таблиц. Одни таблицы связаны с другими, а другие — с третьими. Например, база данных покупок в магазине может выглядеть так:
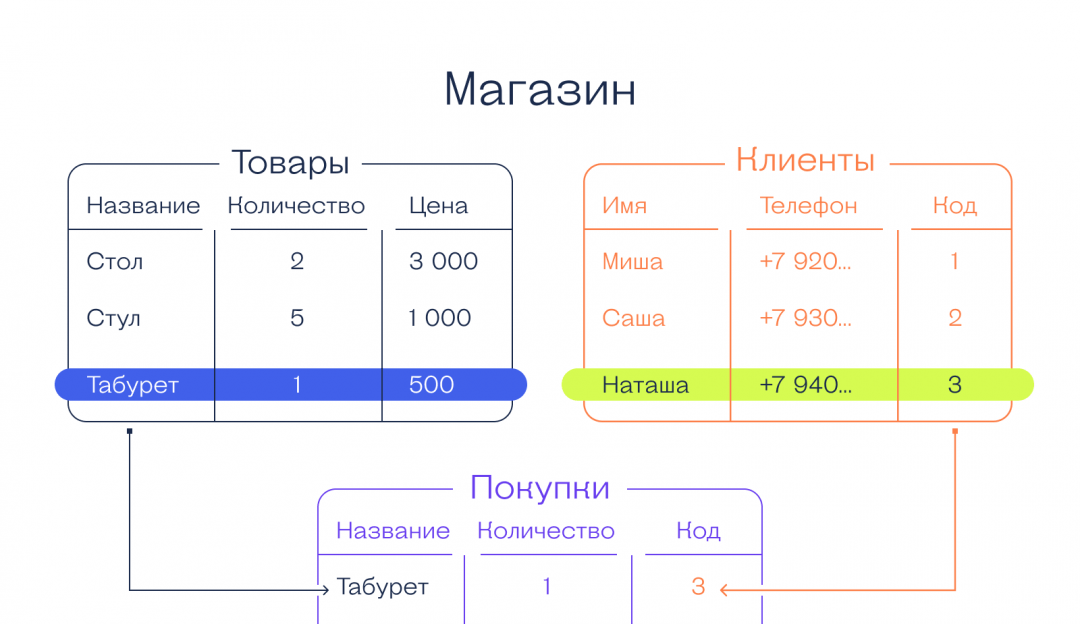
Смотрите, у магазина есть две таблицы — с товарами и покупателями. Но когда один из них что-то покупает, то данные попадают в третью таблицу. В ней есть своя информация (количество купленных товаров) и ссылки на покупателя и сам товар. Если нужно, можно по этим связям попасть в нужную таблицу и узнать подробности о той или другой записи.
Если у покупателя поменяется номер телефона, то нам достаточно будет поменять это в одной таблице «Клиенты». Благодаря тому, что в «Покупки» записывается только код покупателя, нам не нужно менять имя больше нигде — данные сами обновятся автоматически, когда мы захотим посмотреть, кто именно купил табурет.
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:
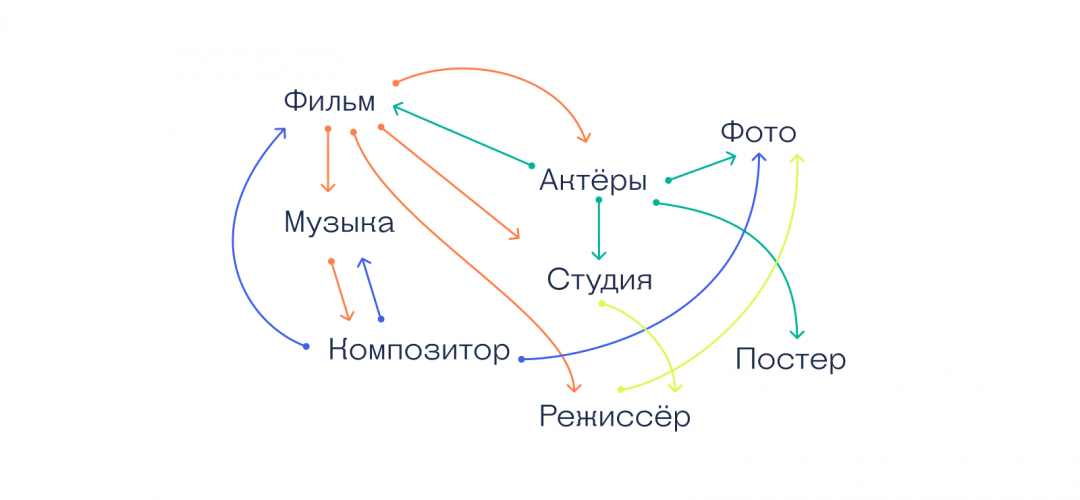
Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:
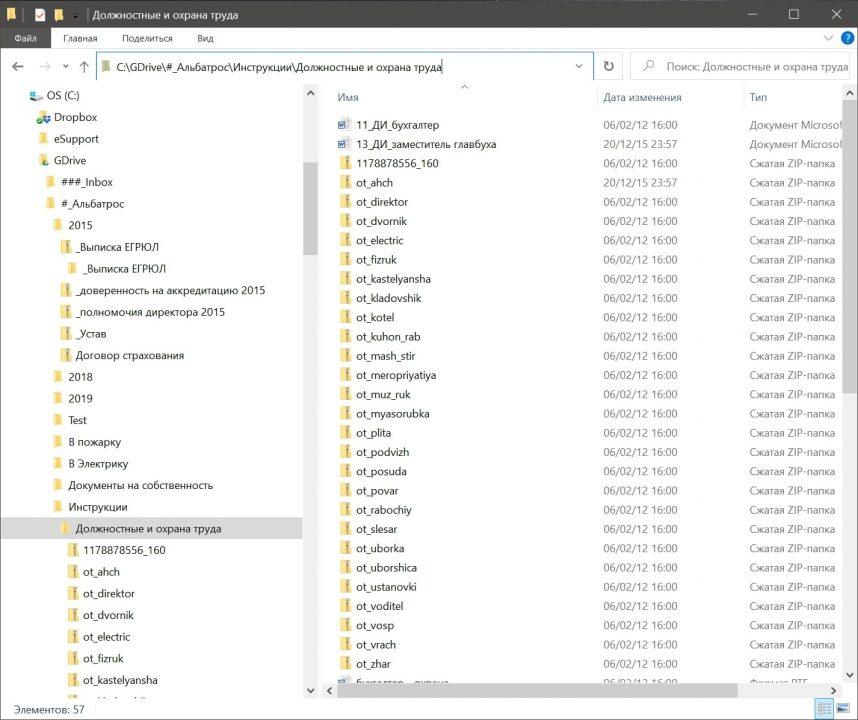
Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Главное о базах данных
- Чаще всего базы данных напоминают таблицы: в них одному параметру соответствует один набор данных. Например, один клиент — одно имя, один телефон, один адрес.
- Такие «табличные» базы данных называются реляционными.
- Чтобы строить сложные связи, разные таблицы в реляционных базах можно связывать между собой: ставить ссылки.
- Реляционная база — не единственный способ хранения данных. Есть ситуации, когда нам нужна большая гибкость в хранении.
- Бывают сетевые базы данных: когда нужно хранить много связей между множеством объектов. Например, каталог фильмов: в одном фильме может участвовать много человек, а каждый из них может участвовать во множестве фильмов.
- Бывают иерархические базы, или «деревья». Пример — наша файловая система.
- Какую выбрать базу — зависит от задачи. Одна база не лучше другой, но они могут быть более или менее подходящими для определённых задач.
Что такое база данных
База данных — это совокупность множества таблиц, которые связаны между собой.

Лолита Кочиева
Автор статьи
23 октября 2022 в 18:05
Современные компании хранят огромное количество информации: данные об операциях, контрагентах, работниках, клиентах и т. д. Сохранять информацию выгодно, потому что данные можно проанализировать и найти новые способы роста прибыли бизнеса.
Если компания небольшая, данные можно сохранить в Google Sheets, файлах Excel или даже в печатном виде в папках. Но если это крупная компания с миллионами операций в день, Excel уже не подойдет: в одном файле помещается максимум около миллиона строк.
Файлы Excel и Google Sheets при сотнях тысяч строк начинают сильно тормозить — работать с информацией в них уже неудобно. Тут на помощь приходят базы данных (БД). В статье разберем виды БД, свойства и популярные системы управления базами данных, которые помогают превратить большой объем информации в удобную систему. В статье разберем виды БД, свойства и популярные системы управления базами данных (СУБД).
База данных: что это
База данных простыми словами — это место, где хранятся данные в электронном виде.
В базе данных может храниться что угодно: фотографии на телефоне, расположение игроков на карте в компьютерной игре, номера заказов в сервисе такси или доставки продуктов. Основная работа базы данных — сохранение, изменение, быстрый поиск.
Работу с базой данных невозможно представить без СУБД (системы управления базой данных). Она позволяет изменять, добавлять или удалять данные, получить из базы нужную информацию по запросу или восстановить базу данных. Одни из самых популярных СУБД — Oracle, MySQL, Microsoft SQL Server, PostgreSQL.
На курсе «Python-разработчик» целый блок посвящен изучению баз данных. Вы узнаете, как работать с СУБД SQLite и PostgreSQL и программной библиотекой SQLAlchemy для работы с реляционными СУБД. Сделаете проект, где компания сможет выбирать поставщика товаров, исключить поставку одинаковых товаров от разных поставщиков, искать и сортировать информацию. По окончании курса с поддержкой нашего центра карьеры найдете первую работу.
Чем база данных отличается от таблиц Excel и Google Sheets
Внешне Excel, Google Sheets и базы данных похожи, но разница есть. В БД можно:
- Хранить больше записей и быстро их обрабатывать.
- Установить отношения между несколькими таблицами — связи, благодаря которым одновременно обрабатывают данные в нескольких таблицах одной БД. Еще связи нужны, чтобы обеспечить целостность данных и чтобы в базе не было потерянных записей. Если удалить из БД клиента, информация о нём удаляется во всех связанных таблицах. Если добавить — добавляется.
- Работать с расширенным набором функций: поиск, фильтрация, сортировка, агрегация и т. д.
Excel и Google Sheets ограничены размером файла. Они подойдут, если нужно работать с небольшим количеством данных и выполнять базовые операции. Для хранения и анализа больших объемов структурированных данных понадобится БД.
Свойства базы данных
Свойства баз данных:
- Быстродействие. Excel и Google Sheets тормозят, когда много данных. В них сложнее найти нужное. В БД проще и быстрее — и ничего не тормозит.
- Простота получения и обновления данных. За два клика можно обновить или добавить данные в базу.
- Безопасность. В большинстве БД можно настраивать разные уровни доступа к таблицам. Например, давать разрешение читать и редактировать не всем пользователям, а только некоторым.
- Многопользовательский доступ. С БД одновременно могут работать несколько человек.
- Объем хранимых данных. База данных дает возможность сохранять миллионы различных записей.
Как хранится информация в БД
По способу хранения данных БД делятся на:
- Централизованные — вся информация хранится на одном компьютере. Это может быть автономный ПК или сервер, к которому есть доступ у пользователей.
- Распределенные — информация распределена по разным компьютерам. Используется в локальных и глобальных компьютерных сетях.
База данных — это информационный склад. Сам по себе этот склад не может найти и обработать нужную клиенту информацию. Здесь в работу вступает СУБД. Система управления базой данных — это программное обеспечение, которое позволяет вносить изменения и отправлять запросы в базу данных, структурировать информацию и при необходимости восстановить базу с нуля.
Приходите на курс «Java-разработчик» — это не только подробные знания и практические навыки по программированию, работе с СУБД и языком запросов SQL. Еще 440 часов обучения от топовых экспертов в области, 5 проектов в портфолио, помощь в составлении резюме и диплом установленного образца. Благодаря этому вы легко найдете работу.
Типы баз данных
Существует огромное множество типов баз данных. Наиболее часто используют следующие типы:
- реляционные,
- нереляционные,
- документоориентированные,
- графовые,
- колоночные (столбцовые),
- key-value,
- сетевые,
- иерархические.
✔️ Реляционные. Состоят из множества таблиц, а между таблицами есть связи.
Две основные характеристики реляционной базы:
- Информация лежит в некотором количестве таблиц и распределена по ним по смыслу.
- Таблицы не существуют независимо друг от друга — они связаны определенными столбцами.
Чаще всего специалисты пользуются реляционными базами данных. Это базы, состоящие из множества таблиц, между которыми есть связи. Реляционные БД используют везде, где есть необходимость в сохранении огромных объемов информации: в IT-компаниях, банках, магазинах и так далее.
Обычно данные в реляционной БД хранят во вложенных таблицах. Информацию вносят с помощью записей.
Таблица — это вложенный объект по отношению к базе данных. Это значит, что база данных содержит внутри себя некоторое количество таблиц. Таблицы хранят разные группы данных. Например, одна таблица может хранить номера телефонов клиентов, а другая — список товаров на складе.
Таблица выглядит как лист в Google Sheets или Excel. Она состоит из определенного количества строк и столбцов. У каждого столбца бывает свое имя. В каждом из столбцов содержатся данные, относящиеся к заголовку столбца.
Запись — это одна строка в таблице в базе данных. Если менеджер добавляет данные нового пассажира или водителя в систему баз данных, то в таблице появляется новая запись.
К значениям столбца обычно есть некоторые требования. Часто в столбце реляционной базы данных хранятся данные одного типа: числа, тексты, файлы или другое.
Если создать реляционную базу данных, например, для такси, то она может содержать такие таблицы:
- заказы такси;
- таксисты;
- клиенты (или пассажиры);
- автомобили.
База данных такси содержит четыре таблицы, в каждой из которых — определенное количество столбцов. Например, в таблице «Клиенты» три столбца: «ID клиента», «Телефон клиента» и «Город клиента».
Можно было бы добавить всю информацию по заказам, таксистам, клиентам и автомобилям в одну таблицу, но она получилась бы слишком громоздкой. Анализировать и строить модели машинного обучения на основе такой таблицы было бы очень сложно, потому что модели машинного обучения нужны данные с определенным типом закономерностей. Удобнее, когда информация — в реляционной базе данных. То есть в разных таблицах в зависимости от смысла.
Реляционные базы данных не годятся для хаотичных неструктурированных данных, которые сложно распределить по нескольким таблицам в зависимости от смысла.
Еще бывают бизнесы и продукты, где необходим быстрый ответ на запрос, например онлайн-торги. Для них реляционные БД не подходят — лучше использовать другой тип.
✔️ Нереляционные БД. Нереляционные системы баз данных — базы данных, в которых информация содержится в виде документов JSON — стандартный текстовый формат, в котором данные структурированы на основе определенного языка программирования — джаваскрипт. Это язык программирования, который используется, например, для механизма обновления ленты новостей в соцсетях, анимации, интерактивных карт и многого другого. А в случае БД помогает структурировать данные.
✔️ Документоориентированные базы данных. По названию можно понять, что в базе данных такого типа единицей информации является документ. Обычно нет никаких ограничений по формату этого документа — он может быть в json-формате, xml, int и т. д.
В документоориентированных базах данных нет схемы данных — это значит, что можно добавлять новые данные как угодно и в каком угодно формате, не требуя, чтобы у всех остальных записей БД была одинаковая структура.
Примеры таких БД — MongoDB, Couchbase, Firebase.
✔️ Key-value базы данных. В такой базе данных удобно хранить информацию, которая легко представляется в виде пары «ключ — значение». Ключ — это специальное поле в таблице с уникальной информацией. Эти поля используют для хранения уникальных идентификаторов объектов, например ID клиента или кода товара. Значение указывает на характеристики ключа.
Самый главный плюс key-value-баз — они быстро выдают значение по ключу. Поэтому такие БД часто используют в задачах, когда ответ от базы важно получать в режиме онлайн.
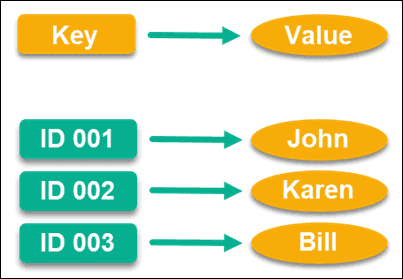
Пример БД key-value
✔️ Графовые. Этот тип баз данных хранит информацию в графах. Графы — математический термин и означает совокупность двух множеств: множества объектов — вершин и множества парных связей этих объектов — ребер. Пример графа — дерево каталогов в компьютере: диски, папки и файлы — вершины, вложенность файлов и папок в папки и диски — ребра.
Графовый тип подходит, когда нужно получить информацию об основном объекте и об объектах, которые с ним связаны.
Пример проекта, в котором идеально использовать графовые базы данных, — обычная социальная сеть вроде ВК. Графовая база данных поможет быстро найти всю необходимую информацию не только нужного нам пользователя, но и всех его друзей, групп и сообществ.
✔️ Столбцовые. В столбцовые (или колоночные) БД данные записывают в столбцы, а не в строки.
Колоночные БД удобны, когда нас интересует информация не во всех столбцах, а в каких-то конкретных. Искать по конкретным столбцам быстрее, чем по строкам.
Допустим, у нас есть таблица, где 100 миллионов записей за год. В колонке «Дата» будут храниться только 366 записей, потому что в году 366 дней — включая високосные. Можно заменить 100 миллионов отсортированных записей в этом поле на 366 пар значений вида — и в таком виде хранить их в базе. Такая запись занимает в 100 тысяч раз меньше места и ускоряет выполнение запросов.
Денис Кондратьев, программист с опытом 17 лет, разработчик компьютерных игр, рассказывает о сетевых и иерархических типах баз данных.
Сетевые и иерархические базы данных — это два примера структур данных, используемых в системах управления базами данных (СУБД). Они впервые появились в 60–70-х годах и служат основой для многих современных концепций и практик в области управления данными.
✔️ Сетевая база данных — это тип БД, в которой данные организованы по принципу сети или связанной структуры. То есть у одной записи может быть несколько родительских и дочерних записей.
Представьте сетевую базу данных для больницы. У вас есть таблицы «Пациенты», «Врачи» и «Больницы». Пациент может наблюдаться у нескольких врачей: то есть может быть несколько родительских записей. А один врач может наблюдать разных пациентов: у врача несколько дочерних записей. Так врачи и пациенты образуют связанную структуру, или сеть отношений. Еще у больницы множество врачей и пациентов, а врач может быть связан с несколькими больницами. Это создает дополнительные связи в сети.
✔️ Иерархическая база данных строится по принципу «родитель — ребенок», где каждый дочерний элемент имеет только один родительский элемент. Эта модель организует данные в древовидной структуре и идеально подходит для сценариев, где нужно хранить информацию в предопределенной и строго упорядоченной иерархии.
Рассмотрим систему управления файлами на компьютере. Местоположение каждого файла уникально в иерархической структуре каталогов или папок. Например, папка «Мои документы» может содержать подпапки «Фотографии», «Видео» и «Текстовые документы». В этих подпапках есть собственные файлы или дополнительные подпапки. В этом примере «Мои документы» — родительский элемент для «Фотографий», «Видео» и «Текстовых документов», а эти элементы, в свою очередь, могут быть родительскими элементами для своих файлов или подпапок.
Эта структура напоминает иерархическую базу данных, где у элемента есть только один «родитель», но может быть несколько «детей» или подэлементов.
Иерархические базы данных были весьма популярны в ранних СУБД, но они менее гибкие по сравнению с сетевыми или реляционными базами данных.
Как получить информацию из БД и связать данные между собой
Чтобы получать, добавлять, сохранять нужные данные в базе данных, в большинстве случаев используют язык запросов SQL. Это простой язык программирования, который помогает извлечь необходимый срез данных из базы.
Чтобы обозначить связи в БД, используют primary key и foreign key.
Primary key — это столбец (или группа столбцов) в таблице с уникальными значениями. Если брать пример с той же базой такси — primary key каждой таблицы там обозначен светло-зеленым цветом.
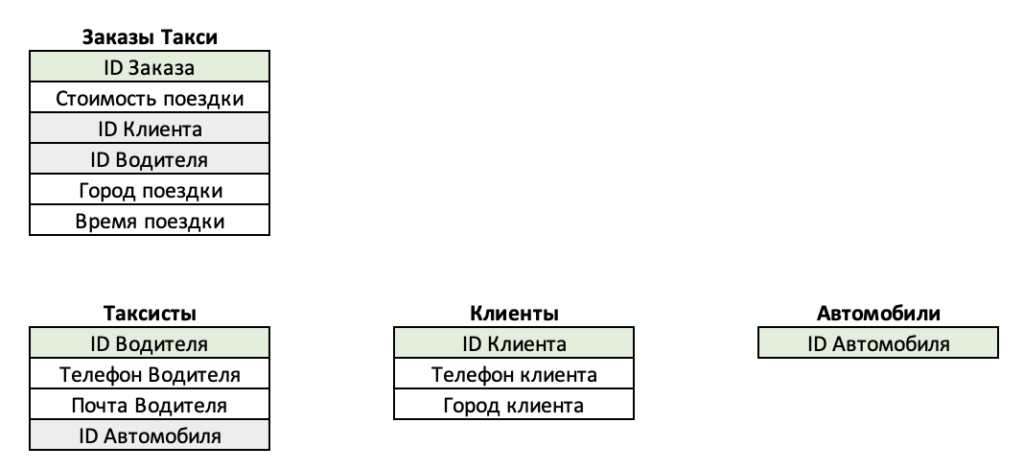
Пример реляционной БД такси
В верхней таблице, которая хранит заказы такси, каждая строка будет содержать в себе информацию об отдельном заказе со своим уникальным ID. Это значит, что в таблице не будет строк с одной и той же информацией.
Foreign key — это такой столбец в таблице, в котором содержится primary key из другой таблицы. На картинке foreign key выделены серым. ID автомобиля является primary key в таблице с автомобилями, но во всех других таблицах (например, в таблице с таксистами) ID автомобиля будет являться foreign key.
Выстраивание связей между таблицами — не единственная функция foreign и primary key. Еще они могут помочь контролировать корректность записей в таблицах. Например, если мы хотим добавить запись с новым таксистом в таблицу с таксистами и неправильно написали ID автомобиля, то база данных сообщит об этом. База не найдет соответствующий ID автомобиля в таблице с автомобилями и выдаст сообщение, что где-то произошла ошибка.
Примеры использования баз данных
Базы данных сейчас используют почти везде: это один из надежных способов ничего не потерять.
На сайтах все статьи и картинки хранятся в базах данных. Когда пользователь заходит на сайт, контент извлекается из БД. Чтобы хранить фото, контакты, музыку на смартфоне, тоже используют базы данных. Благодаря этому пользователь может получить молниеносный доступ к информации.
На любом сайте или в приложении, где есть регистрация, логины и пароли тоже хранятся в базе данных.
В большой компании данные о сотрудниках — имена, данные документов, банковские счета для зарплаты — всё хранится в базах данных. В маленькой компании информацию можно иногда хранить в обычной таблице.
Популярные СУБД
СУБД — система управления базами данных. Это инструменты, с помощью которых запрашивают данные в базе, изменяют или создают базы. В компаниях наиболее популярны такие бесплатные СУБД:
- Это реляционная СУБД. Ее используют в Google, LinkedIn, Amazon, Meta* и других крупных и средних компаниях.
- Это объектно-реляционная СУБД. Она поддерживает большое количество разных языков программирования и типов данных. Для этой СУБД можно использовать существующие расширения или писать собственные — создавать скрипты для новых объектов.
- Это нереляционная документоориентированная СУБД. Такая система может работать с огромными массивами данных весом от 1 Тб.
- Redis (Remote Dictionary Server). Это открытая NoSQL-система управления базами данных. То есть она не использует язык запросов SQL, а запрашивает данные с помощью других языков программирования и конструкций. Redis полезна, чтобы хранить игровые сессии, рейтинговые таблицы, состояние игроков, статистику игр и других временных или постоянных данных, которые нужно обрабатывать быстро.
Полезные материалы для изучения баз данных
Рассказывает Денис Кондратьев, программист с опытом 17 лет, разработчик компьютерных игр.
Новичкам полезно изучить:
�� Книги
«Базы данных: Введение в теорию и методологию» А. С. Маркова, К. Ю. Лисовского. В книге — обзор теории баз данных и как их применять на практике.
Database System Concepts А. Силбершатца, Г. Ф. Корта и С. Сударшана. Это классический учебник, который подробно рассказывает о концепциях баз данных.
�� Онлайн-курсы
Introduction to Databases на Coursera от Стэнфордского университета. Этот курс включает различные виды баз данных: реляционные, иерархические, сетевые и объектно-ориентированные.
Databases на edX от Harvard University. В курсе — про важные концепции: язык SQL, реляционные базы данных и т. д.
�� Любой курс по разработке от Skypro.
За 10–12 месяцев вы получите нужные основы, выполните практические задания и сразу сможете работать с базами данных. Готовый проект положите в портфолио — это увеличит ваш вес в глазах работодателей. С поддержкой экспертов нашего центра карьеры сможете составить сильное резюме, сопроводительное письмо и найти хорошую работу.
Курс Skypro «Аналитик данных».
За 12 месяцев научитесь работе с СУБД, освоите язык запросов SQL, Excel, основы Python, программы для визуализации данных и сможете уверенно презентовать результаты анализа заказчику. После прохождения курса гарантируем трудоустройство и выдаем диплом о профпереподготовке.
�� Веб-сайты и блоги
W3Schools — множество учебников и руководств по языку SQL и другим темам, связанным с базами данных.
Stack Overflow — ответы на вопросы о базах данных и SQL.
Database Journal — статьи, советы, учебники и новости о различных типах баз данных.
�� Интерактивные платформы для обучения
Codecademy — интерактивные курсы по SQL и работе с базами данных.
SQLZoo — интерактивные упражнения для изучения языка SQL.
«Важно помнить, что изучение баз данных — это не только о том, чтобы усвоить SQL или какой-то конкретный тип базы данных. Это про понимание основных принципов проектирования баз данных, моделирования и управления данными».
Денис Кондратьев
программист, разработчик компьютерных игр
Если хотите анализировать сложные данные, стать продвинутым пользователем Excel и научиться работать с языком запросов SQL, пройдите курс «Аналитик данных». Освоите профессию с нуля, даже если совсем нет опыта в IT. Мы не только дадим знания, но и доведем до новой работы — или вернем вам деньги за курс. Гарантию прописываем в договоре.
Что такое База Данных (БД)
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов. Вы делаете заказ, а система сохраняет ваши данные в базе.

В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работе.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.

Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!

Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.

Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги.

Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
То же самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
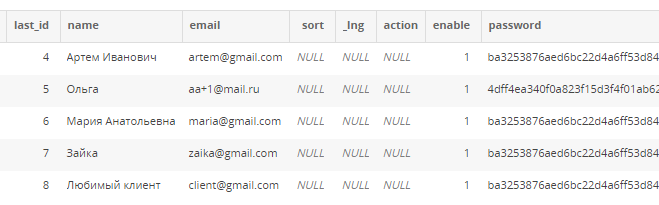
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
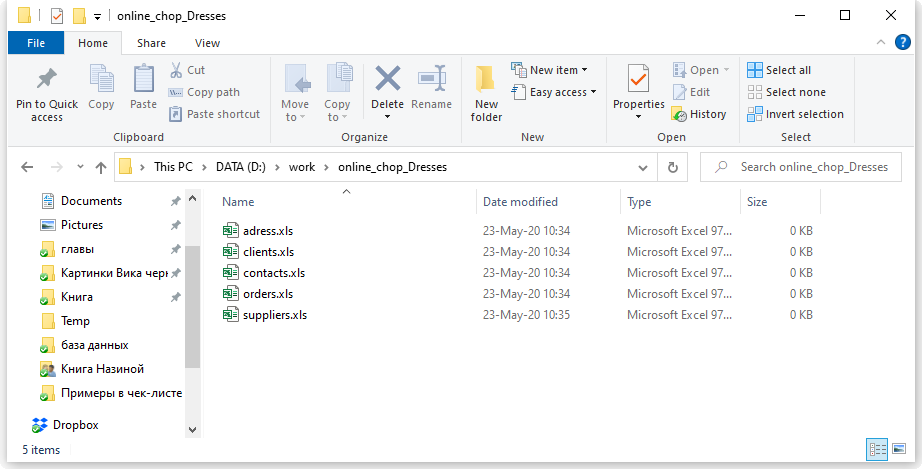
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
- заходишь в папку в винде → видишь файлики только из этой папки
- заходишь в пространство → видишь только те таблицы, которые в нем есть
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
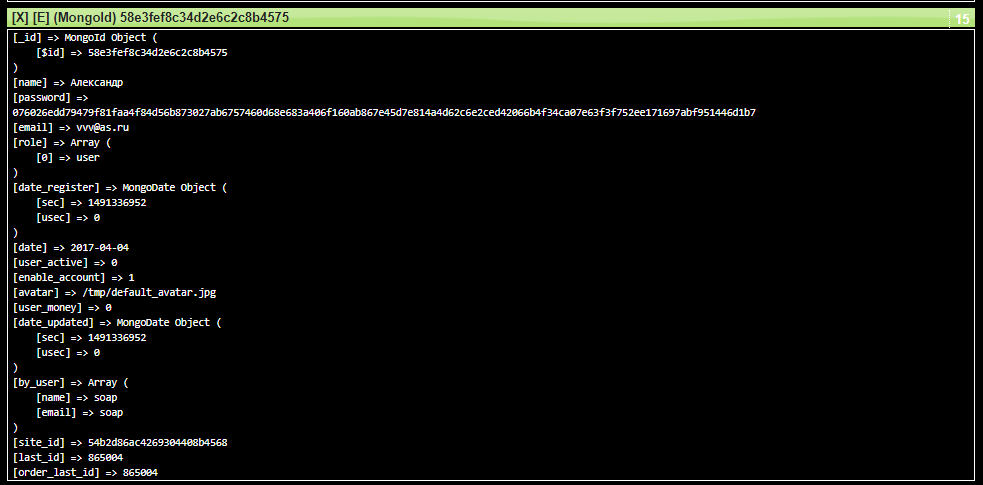
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
- select — выбери мне такие-то колонки.
- from — из такой-то таблицы базы.
- where — такую-то информацию.
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»Переделываю в SQL:
select * from clients where name = 'Назина Ольга';
В дословном переводе:
select -- выбери мне * -- все колонки (можно выбирать конкретные, а можно сразу все) from clients -- из таблицы clients where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
- Открыть файл с нужными данными (clients)
- Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. То же самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order
order (таблица order)
fio (таблица client)
phone (таблица contacts)
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
- В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name
first_name
birthdate
VIP
- В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order
addr
date
time
Роллы «Филадельфия» и «Канада»
Студеный пр-д, д 10
Пицца 35 см, роллы комбо 1
Пицца с сосиками по краям
Комбо набор 3, обед №4
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам. В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
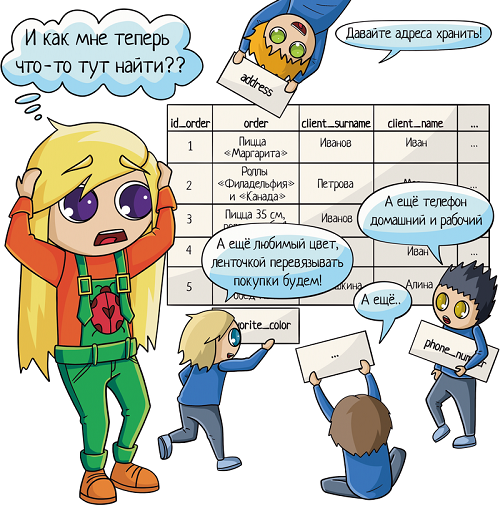
- Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
- Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
- Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
- Клиенты отдельно
- Заказы отдельно
- Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
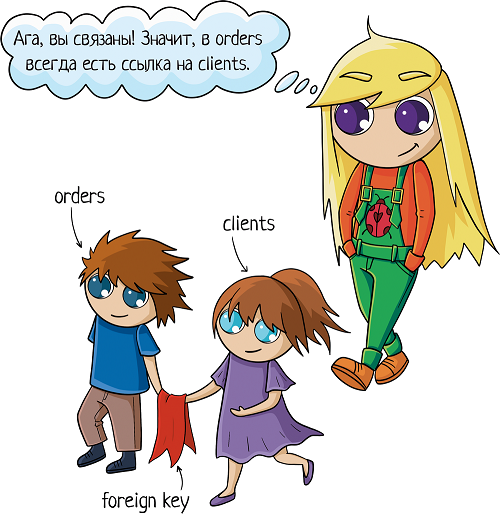
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку. А если у нас два клиента Ивана? Или три Маши? Десять Саш. Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.

А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
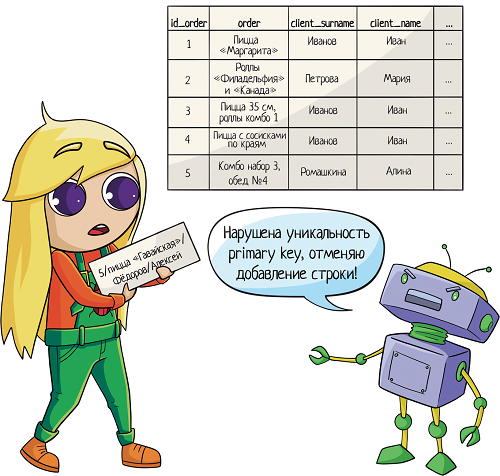
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев: