Метрика программного обеспечения
Ме́трика програ́ммного обеспе́чения (англ. software metric ) — мера, позволяющая получить численное значение некоторого свойства программного обеспечения или его спецификаций.
Поскольку количественные методы хорошо зарекомендовали себя в других областях, многие теоретики и практики информатики пытались перенести данный подход и в разработку программного обеспечения. Как сказал Том ДеМарко, «вы не можете контролировать то, что не можете измерить».
Метрики
Набор используемых метрик включает:
- порядок роста (имеется в виду анализ алгоритмов в терминах асимптотического анализа и O-нотации),
- количество строк кода,
- цикломатическая сложность,
- анализ функциональных точек,
- количество ошибок на 1000 строк кода,
- степень покрытия кода тестированием,
- покрытие требований,
- количество классов и интерфейсов,
- метрики программного пакета от Роберта Сесиль Мартина,
- связность.
Критика
Потенциальные недостатки подхода, на которые нацелена критика:
- Неэтичность: Утверждается, что неэтично судить о производительности программиста по метрикам, введенным для оценки эффективности программного кода. Такие известные метрики, как количество строк кода и цикломатическая сложность, часто дают поверхностное представление об «удачности» выбора того или иного подхода при решении поставленных задач, однако, нередко они рассматриваются, как инструмент оценки качества работы разработчика. Такой подход достаточно часто приводит к обратному эффекту, приводя к появлению в коде более длинных конструкций и избыточных необязательных методов.
- Замещение «управления людьми» на «управление цифрами», которое не учитывает опыт сотрудников и их другие качества
- Искажение: Процесс измерения может быть искажён за счёт того, что сотрудники знают об измеряемых показателях и стремятся оптимизировать эти показатели, а не свою работу. Например, если количество строк исходного кода является важным показателем, то программисты будут стремиться писать как можно больше строк и не будут использовать способы упрощения кода, сокращающие количество строк.
- Неточность: Нет метрик, которые были бы одновременно и значимы и достаточно точны. Количество строк кода — это просто количество строк, этот показатель не даёт представление о сложности решаемой проблемы. Анализ функциональных точек был разработан с целью лучшего измерения сложности кода и спецификации, но он использует личные оценки измеряющего, поэтому разные люди получат разные результаты.
См. также
- Качество программного обеспечения
- Основные метрики кода: LOC, SLOC, Джилб, Маккейб, Холстед, ООП и другие
- Проставить для статьи более точные категории.
- Проставив сноски, внести более точные указания на источники.
- Исследование программ
Программный код и его метрики
Одной из тем в программировании, к которым интерес периодически то появляется, то пропадает, является вопрос метрик кода программного обеспечения. В крупных программных средах время от времени появляются механизмы подсчета различных метрик. Волнообразный интерес к теме так выглядит потому, что до сих пор в метриках не придумано главного — что с ними делать. То есть даже если какой-то инструмент позволяет хорошо подсчитать некоторые метрики, то что с этим делать дальше зачастую непонятно. Конечно, метрики — это и контроль качества кода (не пишем большие и сложные функции), и «производительность» (в кавычках) программистов, и скорость развития проекта. Эта статья — обзор наиболее известных метрик кода программного обеспечения.
Введение
В статье приведен обзор 7 классов метрик и более 50 их представителей.
Будет представлен широкий спектр метрик программного обеспечения. Естественно, все существующие метрики приводить не целесообразно, большинство из них никогда не применяется на практике либо из-за невозможности дальнейшего использования результатов, либо из-за невозможности автоматизации измерений, либо из-за узкой специализации данных метрик, однако существуют метрики, которые применяются достаточно часто, и их обзор как раз будет приведен ниже.
В общем случае применение метрик позволяет руководителям проектов и предприятий изучить сложность разработанного или даже разрабатываемого проекта, оценить объем работ, стилистику разрабатываемой программы и усилия, потраченные каждым разработчиком для реализации того или иного решения. Однако метрики могут служить лишь рекомендательными характеристиками, ими нельзя полностью руководствоваться, так как при разработке ПО программисты, стремясь минимизировать или максимизировать ту или иную меру для своей программы, могут прибегать к хитростям вплоть до снижения эффективности работы программы. Кроме того, если, к примеру, программист написал малое количество строк кода или внес небольшое число структурных изменений, это вовсе не значит, что он ничего не делал, а может означать, что дефект программы было очень сложно отыскать. Последняя проблема, однако, частично может быть решена при использовании метрик сложности, т.к. в более сложной программе ошибку найти сложнее.
1. Количественные метрики
Прежде всего, следует рассмотреть количественные характеристики исходного кода программ (в виду их простоты). Самой элементарной метрикой является количество строк кода (SLOC). Данная метрика была изначально разработана для оценки трудозатрат по проекту. Однако из-за того, что одна и та же функциональность может быть разбита на несколько строк или записана в одну строку, метрика стала практически неприменимой с появлением языков, в которых в одну строку может быть записано больше одной команды. Поэтому различают логические и физические строки кода. Логические строки кода — это количество команд программы. Данный вариант описания так же имеет свои недостатки, так как сильно зависит от используемого языка программирования и стиля программирования [2].
- количество пустых строк,
- количество комментариев,
- процент комментариев (отношение числа строк, содержащих комментарии к общему количеству строк, выраженное в процентах),
- среднее число строк для функций (классов, файлов),
- среднее число строк, содержащих исходный код для функций (классов, файлов),
- среднее число строк для модулей.
Также к группе метрик, основанных на подсчете некоторых единиц в коде программы, относят метрики Холстеда [3]. Данные метрики основаны на следующих показателях:
n1 — число уникальных операторов программы, включая символы-
разделители, имена процедур и знаки операций (словарь операторов),
n2 — число уникальных операндов программы (словарь операндов),
N1 — общее число операторов в программе,
N2 — общее число операндов в программе,
n1′ — теоретическое число уникальных операторов,
n2′ — теоретическое число уникальных операндов.
Учитывая введенные обозначения, можно определить:
n=n1+n2 — словарь программы,
N=N1+N2 — длина программы,
n’=n1’+n2′ — теоретический словарь программы,
N’= n1*log2(n1) + n2*log2(n2) — теоретическая длина программы (для стилистически корректных программ отклонение N от N’ не превышает 10%)
V=N*log2n — объем программы,
V’=N’*log2n’ — теоретический объем программы, где n* — теоретический словарь программы.
L=V’/V — уровень качества программирования, для идеальной программы L=1
L’= (2 n2)/ (n1*N2) — уровень качества программирования, основанный лишь на параметрах реальной программы без учета теоретических параметров,
EC=V/(L’)2 — сложность понимания программы,
D=1/ L’ — трудоемкость кодирования программы,
y’ = V/ D2 — уровень языка выражения
I=V/D — информационное содержание программы, данная характеристика позволяет определить умственные затраты на создание программы
E=N’ * log2(n/L) — оценка необходимых интеллектуальных усилий при разработке программы, характеризующая число требуемых элементарных решений при написании программы
При применении метрик Холстеда частично компенсируются недостатки, связанные с возможностью записи одной и той же функциональности разным количеством строк и операторов.
Еще одним типом метрик ПО, относящихся к количественным, являются метрики Джилба. Они показывают сложность программного обеспечения на основе насыщенности программы условными операторами или операторами цикла. Данная метрика, не смотря на свою простоту, довольно хорошо отражает сложность написания и понимания программы, а при добавлении такого показателя, как максимальный уровень вложенности условных и циклических операторов, эффективность данной метрики значительно возрастает.
2. Метрики сложности потока управления программы
Следующий большой класс метрик, основанный уже не на количественных показателях, а на анализе управляющего графа программы, называется метрики сложности потока управления программ.
Перед тем как непосредственно описывать сами метрики, для лучшего понимания будет описан управляющий граф программы и способ его построения.
Пусть представлена некоторая программа. Для данной программы строится ориентированный граф, содержащий лишь один вход и один выход, при этом вершины графа соотносят с теми участками кода программы, в которых имеются лишь последовательные вычисления, и отсутствуют операторы ветвления и цикла, а дуги соотносят с переходами от блока к блоку и ветвями выполнения программы. Условие при построении данного графа: каждая вершина достижима из начальной, и конечная вершина достижима из любой другой вершины [4].
Самой распространенной оценкой, основанной на анализе получившегося графа, является цикломатическая сложность программы (цикломатическое число Мак-Кейба) [4]. Она определяется как V(G)=e — n + 2p, где e — количество дуг, n — количество вершин, p — число компонент связности. Число компонентов связности графа можно рассматривать как количество дуг, которые необходимо добавить для преобразования графа в сильно связный. Сильно связным называется граф, любые две вершины которого взаимно достижимы. Для графов корректных программ, т. е. графов, не имеющих недостижимых от точки входа участков и «висячих» точек входа и выхода, сильно связный граф, как правило, получается путем замыкания дугой вершины, обозначающей конец программы, на вершину, обозначающую точку входа в эту программу. По сути V(G) определяет число линейно независимых контуров в сильно связном графе. Так что в корректно написанных программах p=1, и поэтому формула для расчета цикломатической сложности приобретает вид:
К сожалению, данная оценка не способна различать циклические и условные конструкции. Еще одним существенным недостатком подобного подхода является то, что программы, представленные одними и теми же графами, могут иметь совершенно разные по сложности предикаты (предикат — логическое выражение, содержащее хотя бы одну переменную).
Для исправления данного недостатка Г. Майерсом была разработана новая методика. В качестве оценки он предложил взять интервал (эта оценка еще называется интервальной) [V(G),V(G)+h], где h для простых предикатов равно нулю, а для n-местных h=n-1. Данный метод позволяет различать разные по сложности предикаты, однако на практике он почти не применяется.
Еще одна модификация метода Мак-Кейба — метод Хансена. Мера сложности программы в данном случае представляется в виде пары (цикломатическая сложность, число операторов). Преимуществом данной меры является ее чувствительность к структурированности ПО.
Топологическая мера Чена выражает сложность программы через число пересечений границ между областями, образуемыми графом программы. Этот подход применим только к структурированным программам, допускающим лишь последовательное соединение управляющих конструкций. Для неструктурированных программ мера Чена существенно зависит от условных и безусловных переходов. В этом случае можно указать верхнюю и нижнюю границы меры. Верхняя — есть m+1, где m — число логических операторов при их взаимной вложенности. Нижняя — равна 2. Когда управляющий граф программы имеет только одну компоненту связности, мера Чена совпадает с цикломатической мерой Мак-Кейба.
Продолжая тему анализа управляющего графа программы, можно выделить еще одну подгруппу метрик — метрики Харрисона, Мейджела.
Данные меры учитывает уровень вложенности и протяженность программы.
Каждой вершине присваивается своя сложность в соответствии с оператором, который она изображает. Эта начальная сложность вершины может вычисляться любым способом, включая использование мер Холстеда. Выделим для каждой предикатной вершины подграф, порожденный вершинами, которые являются концами исходящих из нее дуг, а также вершинами, достижимыми из каждой такой вершины (нижняя граница подграфа), и вершинами, лежащими на путях из предикатной вершины в какую-нибудь нижнюю границу. Этот подграф называется сферой влияния предикатной вершины.
Приведенной сложностью предикатной вершины называется сумма начальных или приведенных сложностей вершин, входящих в ее сферу влияния, плюс первичная сложность самой предикатной вершины.
Функциональная мера (SCOPE) программы — это сумма приведенных сложностей всех вершин управляющего графа.
Функциональным отношением (SCORT) называется отношение числа вершин в управляющем графе к его функциональной сложности, причем из числа вершин исключаются терминальные.
SCORT может принимать разные значения для графов с одинаковым цикломатическим числом.
Метрика Пивоварского — очередная модификация меры цикломатической сложности. Она позволяет отслеживать различия не только между последовательными и вложенными управляющими конструкциями, но и между структурированными и неструктурированными программами. Она выражается отношением N(G) = v *(G) + СУММАPi, где v *(G) — модифицированная цикломатическая сложность, вычисленная так же, как и V(G), но с одним отличием: оператор CASE с n выходами рассматривается как один логический оператор, а не как n — 1 операторов.
Рi — глубина вложенности i-й предикатной вершины. Для подсчета глубины вложенности предикатных вершин используется число «сфер влияния». Под глубиной вложенности понимается число всех «сфер влияния» предикатов, которые либо полностью содержатся в сфере рассматриваемой вершины, либо пересекаются с ней. Глубина вложенности увеличивается за счет вложенности не самих предикатов, а «сфер влияния». Мера Пивоварского возрастает при переходе от последовательных программ к вложенным и далее к неструктурированным, что является ее огромным преимуществом перед многими другими мерами данной группы.
Мера Вудворда — количество пересечений дуг управляющего графа. Так как в хорошо структурированной программе таких ситуаций возникать не должно, то данная метрика применяется в основном в слабо структурированных языках (Ассемблер, Фортран). Точка пересечения возникает при выходе управления за пределы двух вершин, являющихся последовательными операторами.
Метод граничных значений так же основан на анализе управляющего графа программы. Для определения данного метода необходимо ввести несколько дополнительных понятий.
Пусть G — управляющий граф программы с единственной начальной и единственной конечной вершинами.
В этом графе число входящих вершин у дуг называется отрицательной степенью вершины, а число исходящих из вершины дуг — положительной степенью вершины. Тогда набор вершин графа можно разбить на две группы: вершины, у которых положительная степень =2.
Вершины первой группы назовем принимающими вершинами, а вершины второй группы — вершинами отбора.
Каждая принимающая вершина имеет приведенную сложность, равную 1, кроме конечной вершины, приведенная сложность которой равна 0. Приведенные сложности всех вершин графа G суммируются, образуя абсолютную граничную сложность программы. После этого определяется относительная граничная сложность программы:
где S0 — относительная граничная сложность программы, Sa — абсолютная граничная сложность программы, v — общее число вершин графа программы.
Существует метрика Шнейдевинда, выражающаяся через число возможных путей в управляющем графе.
3. Метрики сложности потока управления данными
Следующий класс метрик — метрики сложности потока управления данных.
Метрика Чепина: суть метода состоит в оценке информационной прочности отдельно взятого программного модуля с помощью анализа характера использования переменных из списка ввода-вывода.
Все множество переменных, составляющих список ввода-вывода, разбивается на 4 функциональные группы :
1. P — вводимые переменные для расчетов и для обеспечения вывода,
2. M — модифицируемые, или создаваемые внутри программы переменные,
3. C — переменные, участвующие в управлении работой программного модуля (управляющие переменные),
4. T — не используемые в программе («паразитные») переменные.
Поскольку каждая переменная может выполнять одновременно несколько функций, необходимо учитывать ее в каждой соответствующей функциональной группе.
Q = a1*P + a2*M + a3*C + a4*T,
где a1, a2, a3, a4 — весовые коэффициенты.
Весовые коэффициенты использованы для отражения различного влияния на сложность программы каждой функциональной группы. По мнению автора метрики, наибольший вес, равный 3, имеет функциональная группа C, так как она влияет на поток управления программы. Весовые коэффициенты остальных групп распределяются следующим образом: a1=1, a2=2, a4=0.5. Весовой коэффициент группы T не равен 0, поскольку «паразитные» переменные не увеличивают сложность потока данных программы, но иногда затрудняют ее понимание. С учетом весовых коэффициентов:
Q = P + 2M + 3C + 0.5T
Метрика спена основывается на локализации обращений к данным внутри каждой программной секции. Спен — это число утверждений, содержащих данный идентификатор, между его первым и последним появлением в тексте программы. Следовательно, идентификатор, появившийся n раз, имеет спен, равный n-1. При большом спене усложняется тестирование и отладка.
Еще одна метрика, учитывающая сложность потока данных — это метрика, связывающая сложность программ с обращениями к глобальным переменным.
Пара «модуль-глобальная переменная» обозначается как (p,r), где p — модуль, имеющий доступ к глобальной переменной r. В зависимости от наличия в программе реального обращения к переменной r формируются два типа пар «модуль — глобальная переменная»: фактические и возможные. Возможное обращение к r с помощью p показывает, что область существования r включает в себя p.
Данная характеристика обозначается Aup и говорит о том, сколько раз модули Up действительно получали доступ к глобальным переменным, а число Pup — сколько раз они могли бы получить доступ.
Отношение числа фактических обращений к возможным определяется
Эта формула показывает приближенную вероятность ссылки произвольного модуля на произвольную глобальную переменную. Очевидно, что чем выше эта вероятность, тем выше вероятность «несанкционированного» изменения какой-либо переменной, что может существенно осложнить работы, связанные с модификацией программы.
На основе концепции информационных потоков создана мера Кафура. Для использования данной меры вводятся понятия локального и глобального потока: локальный поток информации из A в B существует, если:
1. Модуль А вызывает модуль В (прямой локальный поток)
2. Модуль В вызывает модуль А и А возвращает В значение, которое используется в В (непрямой локальный поток)
3. Модуль С вызывает модули А, В и передаёт результат выполнения модуля А в В.
Далее следует дать понятие глобального потока информации: глобальный поток информации из А в В через глобальную структуру данных D существует, если модуль А помещает информацию в D, а модуль В использует информацию из D.
На основе этих понятий вводится величина I — информационная сложность процедуры:
I = length * (fan_in * fan_out)2
Здесь:
length — сложность текста процедуры (меряется через какую-нибудь из метрик объёма, типа метрик Холстеда, Маккейба, LOC и т.п.)
fan_in — число локальных потоков входящих внутрь процедуры плюс число структур данных, из которых процедура берёт информацию
fan_out — число локальных потоков исходящих из процедуры плюс число структур данных, которые обновляются процедурой
Можно определить информационную сложность модуля как сумму информационных сложностей входящих в него процедур.
Следующий шаг — рассмотреть информационную сложность модуля относительно некоторой структуры данных. Информационная мера сложности модуля относительно структуры данных:
J = W * R + W * RW + RW *R + RW * (RW — 1)
W — число процедур, которые только обновляют структуру данных;
R — только читают информацию из структуры данных;
RW — и читают, и обновляют информацию в структуре данных.
Еще одна мера данной группы — мера Овиедо. Суть ее состоит в том, что программа разбивается на линейные непересекающиеся участки — лучи операторов, которые образуют управляющий граф программы.
Автор метрики исходит из следующих предположений: программист может найти отношение между определяющими и использующими вхождениями переменной внутри луча более легко, чем между лучами; число различных определяющих вхождений в каждом луче более важно, чем общее число использующих вхождений переменных в каждом луче.
Обозначим через R(i) множество определяющих вхождений переменных, которые расположены в радиусе действия луча i (определяющее вхождение переменной находится в радиусе действия луча, если переменная либо локальна в нём и имеет определяющее вхождение, либо для неё есть определяющее вхождение в некотором предшествующем луче, и нет локального определения по пути). Обозначим через V(i) множество переменных, использующие вхождения которых уже есть в луче i. Тогда мера сложности i-го луча задаётся как:
где DEF(vj) — число определяющих вхождений переменной vj из множества R(i), а ||V(i)|| — мощность множества V(i).
4. Метрики сложности потока управления и данных программы
Четвертым классом метрик являются метрики, близкие как к классу количественных метрик, классу метрик сложности потока управления программы, так и к классу метрик сложности потока управления данными (строго говоря, данный класс метрик и класс метрик сложности потока управления программы являются одним и тем же классом — топологическими метриками, но имеет смысл разделить их в данном контексте для большей ясности). Данный класс метрик устанавливает сложность структуры программы как на основе количественных подсчетов, так и на основе анализа управляющих структур.
Первой из таких метрик является тестирующая М-Мера [5]. Тестирующей мерой М называется мера сложности, удовлетворяющая следующим условиям:
Мера возрастает с глубиной вложенности и учитывает протяженность программы. К тестирующей мере близко примыкает мера на основе регулярных вложений. Идея этой меры сложности программ состоит в подсчете суммарного числа символов (операндов, операторов, скобок) в регулярном выражении с минимально необходимым числом скобок, описывающим управляющий граф программы. Все меры этой группы чувствительны к вложенности управляющих конструкций и к протяженности программы. Однако возрастает уровень трудоемкости вычислений.
Также мерой качества программного обеспечения служит связанность модулей программы [6]. Если модули сильно связанны, то программа становится трудномодифицируемой и тяжелой в понимании. Данная мера не выражается численно. Виды связанности модулей:
Связанность по данным — если модули взаимодействуют через передачу параметров и при этом каждый параметр является элементарным информационным объектом. Это наиболее предпочтительный тип связанности (сцепления).
Связанность по структуре данных — если один модуль посылает другому составной информационный объект (структуру) для обмена данными.
Связанность по управлению — если один посылает другому информационный объект — флаг, предназначенный для управления его внутренней логикой.
Модули связаны по общей области в том случае, если они ссылаются на одну и туже область глобальных данных. Связанность (сцепление) по общей области является нежелательным, так как, во-первых, ошибка в модуле, использующем глобальную область, может неожиданно проявиться в любом другом модуле; во-вторых, такие программы трудны для понимания, так как программисту трудно определить какие именно данные используются конкретным модулем.
Связанность по содержимому — если один из модулей ссылается внутрь другого. Это недопустимый тип сцепления, так как полностью противоречит принципу модульности, т.е. представления модуля в виде черного ящика.
Внешняя связанность — два модуля используют внешние данные, например коммуникационный протокол.
Связанность при помощи сообщений — наиболее свободный вид связанности, модули напрямую не связаны друг с другом, о сообщаются через сообщения, не имеющие параметров.
Отсутствие связанности — модули не взаимодействуют между собой.
Подклассовая связанность — отношение между классом-родителем и классом-потомком, причем потомок связан с родителем, а родитель с потомком — нет.
Связанность по времени — два действия сгруппированы в одном модуле лишь потому, что ввиду обстоятельств они происходят в одно время.
Еще одна мера, касающаяся стабильности модуля — мера Колофелло [7], она может быть определена как количество изменений, которые требуется произвести в модулях, отличных от модуля, стабильность которого проверяется, при этом эти изменения должны касаться проверяемого модуля.
Следующая метрика из данного класса — Метрика Мак-Клура. Выделяются три этапа вычисления данной метрики:
1. Для каждой управляющей переменной i вычисляется значениt её сложностной функции C(i) по формуле: C(i) = (D(i) * J(i))/n.
Где D(i) — величина, измеряющая сферу действия переменной i. J(i) — мера сложности взаимодействия модулей через переменную i, n — число отдельных модулей в схеме разбиения.
2. Для всех модулей, входящих в сферу разбиения, определяется значение их сложностных функций M(P) по формуле M(P) = fp * X(P) + gp * Y(P)
где fp и gp — соответственно, число модулей, непосредственно предшествующих и непосредственно следующих за модулем P, X(P) — сложность обращения к модулю P,
Y(P) — сложность управления вызовом из модуля P других модулей.
3. Общая сложность MP иерархической схемы разбиения программы на модули задаётся формулой:
MP = СУММА(M(P)) по всем возможным значениям P — модулям программы.
Данная метрика ориентирована на программы, хорошо структурированные, составленные из иерархических модулей, задающих функциональную спецификацию и структуру управления. Также подразумевается, что в каждом модуле одна точка входа и одна точка выхода, модуль выполняет ровно одну функцию, а вызов модулей осуществляется в соответствии с иерархической системой управления, которая задаёт отношение вызова на множестве модулей программы.
Также существует метрика, основанная на информационной концепции — мера Берлингера [8]. Мера сложности вычисляется как M=СУММАfi*log2pi, где fi — частота появления i-го символа, pi — вероятность его появления.
Недостатком данной метрики является то, что программа, содержащая много уникальных символов, но в малом количестве, будет иметь такую же сложность как программа, содержащая малое количество уникальных символов, но в большом количестве.
5. Объектно-ориентированные метрики
В связи с развитием объектно-ориентированных языков программирования появился новый класс метрик, также называемый объектно-ориентированными метриками. В данной группе наиболее часто используемыми являются наборы метрик Мартина и набор метрик Чидамбера и Кемерера. Для начала рассмотрим первую подгруппу.
Прежде чем начать рассмотрение метрик Мартина необходимо ввести понятие категории классов [9]. В реальности класс может достаточно редко быть повторно использован изолированно от других классов. Практически каждый класс имеет группу классов, с которыми он работает в кооперации, и от которых он не может быть легко отделен. Для повторного использования таких классов необходимо повторно использовать всю группу классов. Такая группа классов сильно связна и называется категорией классов. Для существования категории классов существуют следующие условия:
Классы в пределах категории класса закрыты от любых попыток изменения все вместе. Это означает, что, если один класс должен измениться, все классы в этой категории с большой вероятностью изменятся. Если любой из классов открыт для некоторой разновидности изменений, они все открыты для такой разновидности изменений.
Классы в категории повторно используются только вместе. Они настолько взаимозависимы и не могут быть отделены друг от друга. Таким образом, если делается любая попытка повторного использования одного класса в категории, все другие классы должны повторно использоваться с ним.
Классы в категории разделяют некоторую общую функцию или достигают некоторой общей цели.
Ответственность, независимость и стабильность категории могут быть измерены путем подсчета зависимостей, которые взаимодействуют с этой категорией. Могут быть определены три метрики :
1. Ca: Центростремительное сцепление. Количество классов вне этой категории, которые зависят от классов внутри этой категории.
2. Ce: Центробежное сцепление. Количество классов внутри этой категории, которые зависят от классов вне этой категории.
3. I: Нестабильность: I = Ce / (Ca+Ce). Эта метрика имеет диапазон значений [0,1].
I = 0 указывает максимально стабильную категорию.
I = 1 указывает максимально не стабильную категорию.
Можно определять метрику, которая измеряет абстрактность (если категория абстрактна, то она достаточно гибкая и может быть легко расширена) категории следующим образом:
A: Абстрактность: A = nA / nAll.
Значения этой метрики меняются в диапазоне [0,1].
0 = категория полностью конкретна,
1 = категория полностью абстрактна.
Теперь на основе приведенных метрик Мартина можно построить график, на котором отражена зависимость между абстрактностью и нестабильностью. Если на нем построить прямую, задаваемую формулой I+A=1, то на этой прямой будут лежать категории, имеющие наилучшую сбалансированность между абстрактностью и нестабильностью. Эта прямая называется главной последовательностью.
Далее можно ввести еще 2 метрики:
Расстояние до главной последовательности: D=|(A+I-1)/sqrt(2)|
Нормализированной расстояние до главной последовательности: Dn=|A+I-2|
Практически для любых категорий верно то, что чем ближе они находятся к главной последовательности, тем лучше.
Следующая подгруппа метрик — метрики Чидамбера и Кемерера [10]. Эти метрики основаны на анализе методов класса, дерева наследования и т.д.
WMC (Weighted methods per class), суммарная сложность всех методов класса: WMC=СУММАci, i=1. n, где ci — сложность i-го метода, вычисленная по какой либо из метрик (Холстеда и т.д. в зависимости от интересующего критерия), если у всех методов сложность одинаковая, то WMC=n.
DIT (Depth of Inheritance tree) — глубина дерева наследования (наибольший путь по иерархии классов к данному классу от класса-предка), чем больше, тем лучше, так как при большей глубине увеличивается абстракция данных, уменьшается насыщенность класса методами, однако при достаточно большой глубине сильно возрастает сложность понимания и написания программы.
NOC (Number of children) — количество потомков (непосредственных), чем больше, тем выше абстракция данных.
CBO (Coupling between object classes) — сцепление между классами, показывает количество классов, с которыми связан исходный класс. Для данной метрики справедливы все утверждения, введенные ранее для связанности модулей, то есть при высоком CBO уменьшается абстракция данных и затрудняется повторное использование класса.
RFC (Response for a class) — RFC=|RS|, где RS — ответное множество класса, то есть множество методов, которые могут быть потенциально вызваны методом класса в ответ на данные, полученные объектом класса. То есть RS=(((i>), i=1. n, где M — все возможные методы класса, Ri — все возможные методы, которые могут быть вызваны i-м классом. Тогда RFC будет являться мощностью данного множества. Чем больше RFC, тем сложнее тестирование и отладка.
LCOM (Lack of cohesion in Methods) — недостаток сцепления методов. Для определения этого параметра рассмотрим класс C с n методами M1, M2,… ,Mn, тогда ,. — множества переменных, используемых в данных методах. Теперь определим P — множество пар методов, не имеющих общих переменных; Q — множество пар методов, имеющих общие переменные. Тогда LCOM=|P|-|Q|. Недостаток сцепления может быть сигналом того, что класс можно разбить на несколько других классов или подклассов, так что для повышения инкапсуляции данных и уменьшения сложности классов и методов лучше повышать сцепление.
6. Метрики надежности
Следующий тип метрик — метрики, близкие к количественным, но основанные на количестве ошибок и дефектов в программе. Нет смысла рассматривать особенности каждой из этих метрик, достаточно будет их просто перечислить: количество структурных изменений, произведенных с момента прошлой проверки, количество ошибок, выявленных в ходе просмотра кода, количество ошибок, выявленных при тестировании программы и количество необходимых структурных изменений, необходимых для корректной работы программы. Для больших проектов обычно рассматривают данные показатели в отношении тысячи строк кода, т.е. среднее количество дефектов на тысячу строк кода.
7. Гибридные метрики
В завершении необходимо упомянуть еще один класс метрик, называемых гибридными. Метрики данного класса основываются на более простых метриках и представляют собой их взвешенную сумму. Первым представителем данного класса является метрика Кокола. Она определяется следующим образом:
H_M = (M + R1 * M(M1) +… + Rn * M(Mn)/(1 + R1 +… + Rn)
Где M — базовая метрика, Mi — другие интересные меры, Ri — корректно подобранные коэффициенты, M(Mi) — функции.
Функции M(Mi) и коэффициенты Ri вычисляются с помощью регрессионного анализа или анализа задачи для конкретной программы.
В результате исследований, автор метрики выделил три модели для мер: Маккейба, Холстеда и SLOC, где в качестве базовой используется мера Холстеда. Эти модели получили название «наилучшая», «случайная» и «линейная».
Метрика Зольновского, Симмонса, Тейера также представляет собой взвешенную сумму различных индикаторов. Существуют два варианта данной метрики:
(структура, взаимодействие, объем, данные) СУММА(a, b, c, d).
(сложность интерфейса, вычислительная сложность, сложность ввода/вывода, читабельность) СУММА(x, y, z, p).
Используемые метрики в каждом варианте выбираются в зависимости от конкретной задачи, коэффициенты — в зависимости от значения метрики для принятия решения в данном случае.
Заключение
Подводя итог, хотелось бы отметить, что ни одной универсальной метрики не существует. Любые контролируемые метрические характеристики программы должны контролироваться либо в зависимости друг от друга, либо в зависимости от конкретной задачи, кроме того, можно применять гибридные меры, однако они так же зависят от более простых метрик и также не могут быть универсальными. Строго говоря, любая метрика — это лишь показатель, который сильно зависит от языка и стиля программирования, поэтому ни одну меру нельзя возводить в абсолют и принимать какие-либо решения, основываясь только на ней.
15 метрик разработки программного обеспечения для создания успешного продукта
Насколько продуктивно работает команда разработчиков? Когда планировать релиз? Будет ли продукт реально полезен для пользователей? Чтобы ответы на эти вопросы не переходили в разряд философских, нужно опираться на точные цифры. Для этого и существуют метрики разработки программного обеспечения.
Даже если вы выбираете аутсорсинг для разработки программного обеспечения, это не значит, что не нужно включаться в проект: на разных этапах важно контролировать метрики. В ходе разработки — менеджерские, перед релизом — технические. А после релиза — пользовательские, чтобы понять, как аудитория взаимодействует с продуктом. Однако метрик существуют сотни, и отслеживать все не имеет смысла: рассмотрим ключевые показатели для стартапов.
Время чтения: 7 минут

Менеджерские метрики
Успех всего проекта зависит от эффективности процесса разработки. Бюджет, сроки, приоритетные задачи — все это следует выбирать и корректировать на основе конкретных цифр. Менеджерские метрики помогают к омпаниям по разработке программного обеспечения оценить работу команды.
Burn Rate
Это одна из самых главных менеджерских метрик разработки программного обеспечения : диаграмма сгорания задач показывает, сколько работы уже выполнено и сколько осталось. Метрику можно посмотреть за:
- конкретный спринт — это называется sprint burndown chart или диаграмма сгорания задач за спринт;
- весь проект — это называется release burndown chart или диаграмма сгорания задач до релиза.
График представляет собой кривые, идущие вниз: они показывают динамику решения задач. По шкале X отмечают количество дней до окончания спринта или до релиза. По шкале Y — число задач. Одна из линий графика демонстрирует то, как быстро планировалось выполнить работу. Вторая линия — то, как работа идет на самом деле. Диаграмма может выглядеть, например, так:
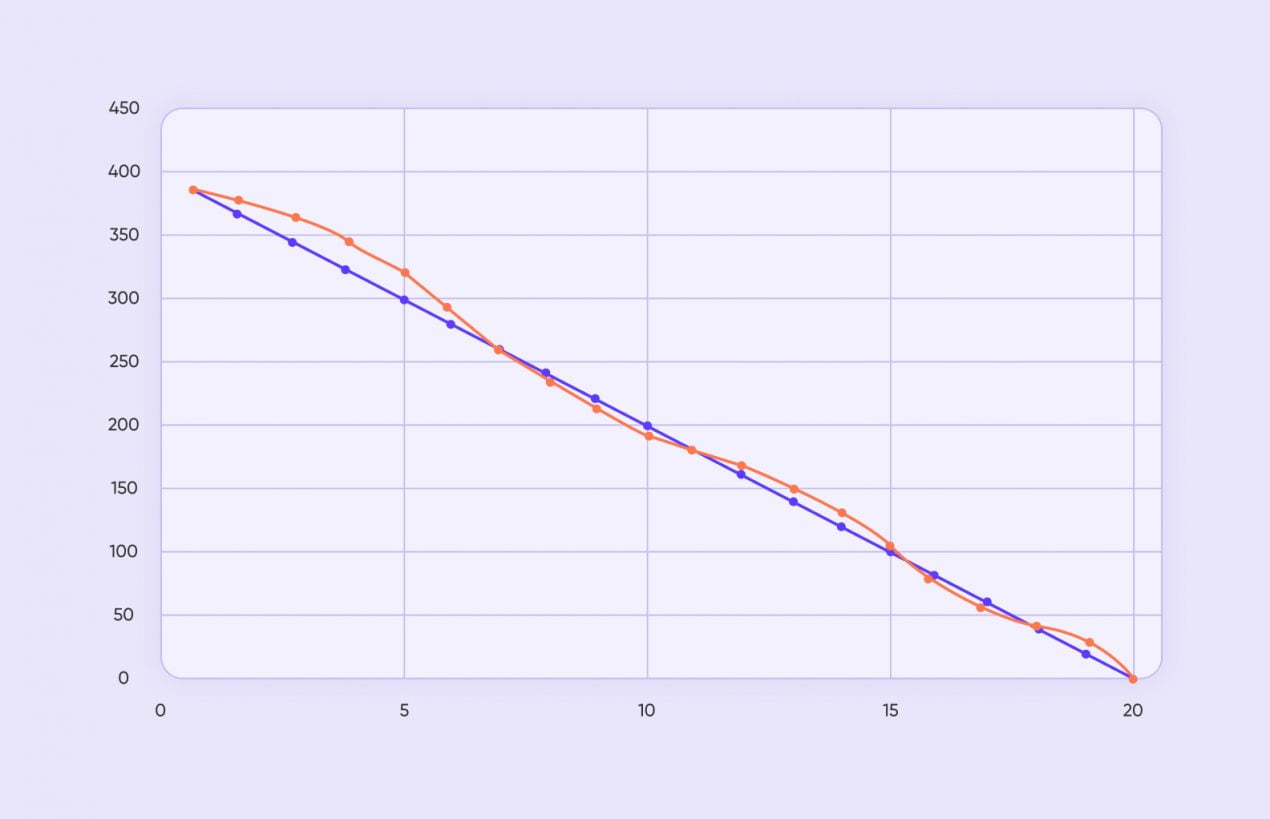
Если диагональ, отражающая реальную работу, будет иметь более крутой наклон, значит, работа выполняется быстрее, чем планировалось. Если она будет более пологой — дело идет медленнее. Также график реальной работы может быть сильно искривленным. Например, сначала идти по горизонтали (когда никакие задачи не решаются), а потом резко пойти вниз (если команда, оказывающая услуги по разработке программного обеспечения , работает в ударном темпе).
�� По диаграмме сгорания задач смотрят:
- реально ли закрыть все задачи за спринт;
- реально ли успеть сделать релиз в планируемые сроки;
- на каком этапе находится проект сейчас;
- насколько планомерно работает команда;
- насколько правильно рассчитывается время на работу.
Хотите разобраться, чем полезна диаграмма сгорания задач на примере реального проекта? Читайте наш кейс:
READ MORE Фотографы, $250 тысяч инвестиций и 300 экранов «какого-то» дизайна. Кейс Purrweb
Flow Efficiency
В разработке программного обеспечения на заказ есть стадии активной работы и время ожидания: когда для того, чтобы приступить к задаче, не хватает информации или ресурсов. Минимизировать простои — одна из задач менеджера. Соотношение времени работы ко всему времени с учетом простоя и называют эффективностью потока.

Например, если над задачей работали 3 дня, а еще 2 она «висела» в ожидании, когда разработчик для нее освободится, формула эффективности потока будет: 3/(2+3) *100%.
�� Эта метрика разработки программного обеспечения служит, чтобы:
- оценить, как долго простаивают задачи и является ли это проблемой для проекта;
- оптимизировать аутсорсинг разработки программного обеспечения и контролировать время работы.
Team Velocity
Эта метрика разработки программного обеспечения демонстрирует, какой объем работы команда способна выполнить за спринт. Для вычисления показателя производительности в продуктовых командах используют стори поинты (story points) — с их помощью каждой задаче в бэклоге назначают вес в зависимости от ее сложности. Если вы работаете со студией, вместо стори поинтов оценка идет в часах: так всем проще и понятнее.
Сумма всех стори поинтов или всех часов за спринт — это и есть производительность.
�� Метрику используют, чтобы:
- понять, справляется ли команда с темпами проекта или нужно нанимать дополнительных сотрудников;
- планировать количество задач в следующих спринтах;
- отслеживать, как те или иные изменения в рабочем процессе влияют на производительность;
- планировать время релиза продукта исходя из реальных возможностей разработки.
Среднее количество багов за спринт
Баги при разработке ПО возникают неизбежно. Чтобы их контролировать, можно подсчитывать количество в каждом спринте. На примере нескольких спринтов можно выявить нормальный показатель для конкретного проекта и в дальнейшем равняться на него. А существенные отклонения от средней цифры — повод задуматься.
�� Вот что можно увидеть по количеству багов за спринт:
- Если багов слишком много, значит, в разработке что-то пошло не так: нужно выявить причину систематических ошибок.
- Если багов слишком мало, это тоже повод насторожиться — возможно, тестирование было недостаточно тщательным.
READ MORE Проектный менеджмент и SCRUM: как, зачем и почему?
Технические метрики
Это группа метрик разработки программного обеспечения , на которые опираются программисты. Показатели, которые мы рассмотрим, важны также для контроля работы: обязательно запросите их у команды перед релизом.
Test Coverage
Плотность покрытия программного кода тестами — это процент кода, который проверили в ходе тестирования. Например, если этот показатель равен 78%, значит, 78% всего, что написали программисты, было проверено в ходе теста.
�� Специалистам компании по разработке программного обеспечения метрика помогает понять:
- достаточно ли тестов было проведено;
- насколько велик риск, что какие-то баги в программе остались незамеченными и попадут в релиз.
Скорость загрузки страниц
Это крайне важная метрика разработки программного обеспечения — ведь скорость загрузки напрямую определяет жизнеспособность программы. Если страница будет долго грузиться, пользователь просто перестанет пользоваться приложением, а бизнес потеряет деньги. Слишком сложно написанный код, большое число редиректов, «тяжелый» мультимедийный контент — все это может пагубно сказываться на времени загрузки.
Поскольку оно зависит от множества факторов, то для измерения скорости обычно используют сразу несколько узконаправленных метрик. Среди них время:
- отображения первой отрисовки — когда появляется белая страница в окне браузера;
- появления первой отрисовки контента — когда в окне возникает любая картинка или текст;
- загрузка первой значимой отрисовки — когда подгружаются элементы, определяющие ценность приложения: например, информация о товарах;
- появления интерактивности — когда появляется первая кнопка, на которую можно кликнуть;
- от первого пользовательского взаимодействия до реакции системы (через какое время страница отреагирует на клик)
- полной загрузки страницы.
�� По этим метрикам разработки программного обеспечения можно сделать следующие выводы:
- достаточно ли быстро страницы загружаются или требуется сократить скорость;
- на каких именно этапах скорость недостаточная и что с этим можно сделать — например, сократить код или сжать контент.
ER-диаграмма
ER-диаграмма — это схема базы данных. Она показывает, как различные элементы связаны между собой. Диаграмма состоит из простых геометрических фигур и линий между ними. В фигурах отражены «сущности» — объекты и понятия, а линии указывают на действия, которые выполняются между ними.

Диаграмма базы данных нужна, чтобы заказав услуги по разработке программного обеспечения, согласовать логику программы. Разработчики рисуют диаграмму на основе данных от заказчика.
�� Если с ней что-то не так, возможно:
- разработчики неверно поняли задачи и могут переделать логику программы;
- решения заказчика невозможно реализовать и нужно искать компромисс .
Использование зрелого фреймворка
Фреймворк — это платформа с базовыми программными модулями, на которые затем «наращивают» приложение. Он задает архитектуру продукта. И как любой фундамент, фреймворк имеет важное значение для всей дальнейшей работы.
Сомнительный фреймворк, не подходящий под цели приложения, может обеспечить уйму проблем. А качественная платформа с поддержкой крупных компаний (например, Google или IBM) упрощает разработку, дает возможности и инструменты для высококлассной работы.
�� Хороший фреймворк дает следующие преимущества:
- ускоряет время разработки;
- снижает издержки;
- позволяет писать более чистый код — он, в свою очередь, влияет на работу программы и скорость загрузки;
Например, мы в Purrweb для мобильной разработки используем React Native — это фреймворк JavaScript, поддерживаемый Facebook. В отличие от других технологий React Native позволяет экономить 30-35% времени и бюджета на создании приложений для iOS и Android.
Проверка дублирования кода
Этот показатель важно проконтролировать при разработке программного обеспечения на заказ . Код с большим количеством повторений отдельных кусков считается низкокачественным: он занимает больше строк, требует больше времени на обработку. Соответственно, такой софт работает медленнее. Иногда код повторяют для упрощения процесса программирования, но зачастую это случайные повторы. Есть специальные сервисы, позволяющие автоматически выявить дублирование: в них загружают код, и система выдает, какие фрагменты повторяются. Один из них — Sonarqube .
Технических метрик разработки программного обеспечения гораздо больше, но большинству владельцев стартапов их трудно оценить без экспертизы в IT. Контроль этих метрик можно делегировать собственному техническому директору или сторонним специалистам — если вы выбираете аутсорсинг разработки программного обеспечения . А если вы планируете разобраться самостоятельно, наш перечень вам поможет. Но более понятной для бизнеса будет следующая группа показателей.
Пользовательские метрики
В конечном счете любое приложение компании по разработке программного обеспечения создают для пользователей. Их удобство и удовлетворение — важнейшие показатели для бизнеса, которые будут конвертироваться в прибыль.
Customer Satisfaction Score
CSAT позволяет оценить качество конкретного взаимодействия пользователя с сервисом. В таком случае респонденту задают короткий прицельный вопрос. Например, просят оценить удобство навигации, отслеживание доставки или понятность программы лояльности — выбирая из вариантов «хорошо», «плохо» и «нейтрально».
Результат опроса может не отражать лояльность пользователя в широком смысле: возможно, конкретная услуга ему понравилась, а все остальное — нет. Но CSAT позволяет быстро оценивать отдельные составляющие сервиса, с которыми взаимодействовали пользователи.
�� Это может быть важно для:
- оценки ключевой функциональности приложения: например, если речь об интернет магазине, важно знать, удовлетворены ли пользователи форматом каталога и системой оплаты;
- оценки тех составляющих, которые вызывают опасения — если речь об инновационных решениях или просто непривычных для данного сегмента пользователей;
- проверки эффективности редизайна — чтобы понять, удалось ли улучшить конкретную функциональность сервиса.
Net Promoter Score
Метрика NPS рассчитывается по ответу на вопрос «насколько вы порекомендуете сервис друзьям и знакомым?». Обычно предлагается оценить вероятность по десятибалльной шкале.
В отличие от CSAT, по которой видна удовлетворенность конкретным взаимодействием в данный момент времени, NPS показывает общую лояльность к приложению в целом, за весь период его использование.
�� NPS дает понять, как много пользователей:
- в высшей степени лояльны и готовы рекомендовать продукт;
- не определились или нейтрально относятся к приложению;
- имеют негативные впечатления от продукта.
Retention Rate
Приложения создаются для того, чтобы ими пользовались регулярно, поэтому показатель возвращаемости важен для бизнеса. В зависимости от назначения продукта, эту метрику можно отслеживать за день, за неделю или за месяц.
�� Показатель возвращаемости нужен, чтобы:
- понять, как часто пользователям нужна функциональность приложения;
- выявить, за какими услугами люди обращаются к продукту с той или иной частотой;
- при редизайне, смене контента, проведении акций — отслеживать, как изменения влияют на возвращаемость.
Conversion Rate
Метрика разработки программного обеспечения показывает, сколько людей среди посетителей приложения совершили целевое действие. Это может быть подписка, покупка, клик по нужной кнопке — в качестве целевого действия можно выбирать то, что нужно в рамках конкретного анализа. Коэффициент конверсии рассчитывается в процентах. Скажем, всего на странице за день было 200 человек, из них 20 кликнули на нужную кнопку — выходит конверсия 10%.
У этой метрики одно назначение — понять, насколько привлекателен CTA-элемент для аудитории.
�� Если конверсия низкая, можно думать о ее причинах. Это могут быть:
- проблемы в маркетинге: цена, качество товара или отсутствие отзывов, незаинтересованность аудитории в продукте, услуге, контенте;
- проблемы в функционировании сайта: например, страница оплаты долго грузится, поэтому мало людей доходят до покупки.
- проблемы в дизайне: возможно, кнопку, по которой нужно кликать, просто плохо видно.
READ MORE Разработка дизайна приложения для стартапа: основные этапы
Adoption Rate
Эта метрика показывает, насколько полно люди пользуются продуктом: задействуют ли они все возможности приложения или выполняют в нем очень ограниченные операции. Показатель можно рассчитать, разделив число новых пользователей конкретного раздела приложения на число всех пользователей.
�� По метрике видно:
- какая функциональность пользуется спросом, а какая нет;
- где пользователю может быть необходим онбординг (подсказки);
- после внедрения новых функций — пользуются ли ими люди или игнорируют.
Что делать дальше
Метрики разработки программного обеспечения помогают управлять бизнес процессами с разных сторон: с точки зрения менеджмента, разработки и улучшения пользовательского опыта. Мы рассмотрели основные показатели, которые важно отслеживать в любом стартапе.
Однако каждый проект имеет свою специфику, и среди сотен метрик могут потребоваться более узконаправленные: для решения задач конкретного продукта. Поэтому стартапу не обойтись без специалистов по аналитике — они смогут выявить актуальные проблемы на разных этапах разработки. При разработке приложений мы тщательно отслеживаем метрики на разных этапах работы — это помогает корректировать курс и выдавать качественный результат в сжатые сроки.
Если вам нужно создать мобильное приложение, в Purrweb можно обратиться за разработкой программного обеспечения на заказ . Мы всегда готовы проконсультировать по любому вопросу — пишите!
Насколько публикация полезна?
Оцени эту статью!
86 оценок, среднее 4.4 из 5.
Оценок пока нет. Поставьте оценку первым.
Так как вы нашли эту публикацию полезной.
Подписывайтесь на нас в соцсетях!
Что такое метрика?
Метрика — эффективный инструмент web-аналитики, который используется специалистами каждый день. В этой статье мы поговорим, для чего данный инструмент нужен.
В современном мире маркетинга и продаж все подлежит измерению. Очень важно быстро и своевременно получать совокупность характеристик, позволяющих оценивать поведение пользователей, спрос на продукт, работу программного обеспечения и многое-многое другое. Все дисконтные программы, акции и скидки тоже оцениваются с помощью метрик. И так далее. Давайте же рассмотрим особенности создания и использования метрик в контексте классического интернет-магазина.
Метрики в интернет-торговле
Изо дня в день тысячи людей делают покупки онлайн. Современный интернет-магазин — это уже давным-давно не просто каталог с товарами — это искусно выстроенная маркетинговая платформа, которая способна плавно подвести вас к покупке тех вещей, которые вам даже не очень-то и нужны. А оценивается эффективность работы такой платформы, как уже было сказано выше, с помощью метрик — количественной системы показателей.
На практике они позволяют:
— оценивать, насколько эффективны источники рекламного трафика;
— понимать, какие именно категории и бренды наиболее популярны;
— видеть, что именно потенциальный клиент просматривает и кладет в корзину, но по каким-то причинам не покупает;
— создавать грамотные маркетинговые стратегии.
Качественная система метрик в интернет-магазине предполагает разделение на модули. Как это может выглядеть, мы сейчас и посмотрим.
События, фиксирующие действия посетителя
Это главное, что надо отслеживать. В рамках работы такого модуля фиксируются следующие операции:
— просмотр карточки товара;
— добавление какого-нибудь товара в корзину, а также удаление его оттуда;
— успешно совершенная транзакция.
Когда какое-нибудь из вышеописанных событий случается, активируется специальный уникальный отчет — очень полезная вещь в электронной коммерции. Что могут содержать такие отчеты:
— информацию по содержимому заказов, статистику по заказам. Подсчитываются визиты и число посетителей, которые купили товар с учетом нужного временного промежутка (в час, в день и пр.). Что покупали, на какую сумму совершали заказы и т. п. Можно узнать средний доход визита/покупки, общее число покупок в день и всех визитов за все время. Перед тем как создать такую систему показателей, определяют сегменты пользователей, в результате чего соответствующие группы указываются в настройках. Таким образом можно без проблем создать отчет в разрезе источников трафика, отслеживать эффективность каждого канала, причем как в плане привлеченного дохода за день, так и в плане числа транзакций. Также маркетологи получают данные о том, какая рекламная кампания принесла больше клиентов нужного пола/возраста, за какой отчетный период это произошло (сколько было куплено, к примеру, за выходной день, за праздничный день либо за специальный день — день «Черной пятницы»);
— популярные бренды/товары/категории. Не менее важно увидеть, что больше всего востребовано. Путем деления ассортимента на группировки можно отследить сезонность категорий и востребованность брендов, что берется в учет отделом снабжения при последующих товарных закупках;
— состояние корзины. Тут будет статистика по всему ассортименту, попавшему в корзину в отчетный период (день, неделю, месяц). Что было в итоге куплено, а что «брошено». Данные можно сегментировать, добавляя группировки и дополнительные метрики. А наличие информации об удаленных вещах позволит скорректировать как рекламную кампанию, так и ценовую политику;
— промокоды. Без них сейчас никуда и любой маломальский опытный пользователь всегда поищет промокод со скидками, прежде чем что-нибудь заказать. И мы очень радуемся, думая, что являемся самыми умными, а некоторые даже считают, что они, дескать, обхитрили систему интернет-магазина, удачно воспользовавшись сразу двумя такими кодами и суммировав скидку. Однако не стоит заблуждаться: действия промокодов всегда контролируются — это, если хотите, «управляемый хаос». Специальная ме трика позволяет отслеживать, как отработали те либо иные промокоды и связанные с ними программы/рекламные кампании, а также что приводило к покупке чаще всего. Главная цель магазина не меняется — конвертировать ваше посещение в деньги, даже если вы случайный посетитель. Меняются лишь средства достижения этой цели, сделайте вывод, друзья.
Вдобавок к вышеописанному, можно создать метрики для отслеживания и анализа:
— воронки оформления заказа;
— действий в онлайн-чате;
— отправки форм обратной связи, заказа обратного звонка и пр.
Как видите, данные, получаемые с помощью метрик, весьма информативны. Они широко используются в веб-аналитике и в конечном итоге существенно влияют на маркетинговую стратегию.