ORM — Ключевые аспекты веб-разработки на Python
Любое программное обеспечение разрабатывается под конкретную предметную область, например:
- Система аналитики оперирует понятиями «просмотр», «сессия», «воронка» и «когорта»
- Для интернет-магазина понятия будут другими — «товар», «категория», «платежный шлюз».
Все вместе они составляют онтологию предметной области . В некоторых источниках встречается термин модель предметной области — это то же самое, что и онтология.
Кроме самих понятий онтология содержит и описание их связей. Например, сущность «Пользователь» связана с сущностью «Покупка» как «один ко многим». То есть один пользователь может выполнить сколько угодно покупок, но каждая покупка принадлежит только одному пользователю.
Модель предметной области — основа коммуникации и взаимопонимания между членами команды. Она не зависит ни от языка программирования, ни от программирования вообще.
Не важно, кто общается: программисты между собой или программисты с заказчиками, менеджерами или дизайнерами. Все вместе они оперируют сущностями и связями предметной области и бизнес-правилами, используемыми в данной программе. К таким правилам может относиться автоматическое включение скидки при заказе от определенного объема товаров:
Важно понимать, что модель отражает лишь часть предметной области с некоторой детализацией. Причем в программах от разных производителей модель может быть разной, даже если они из одной области. Конечно же, в некоторых областях есть некоторый набор фиксированных сущностей, их связей и правил работы — например, в бухгалтерии. Но есть и менее формальные области, в которых таких возможностей еще больше.
Приведем несколько примеров из Хекслета. Количество сущностей — больше сотни, количество связей — много сотен, количество правил посчитать сложно — их тоже много.
На основе модели предметной области формируется модель данных в коде. Создаем сущности, определяем их связи. Затем мы строим рабочий код, который оперирует сущностями, исходя из требований и бизнес-правил.
На этом этапе возникает вопрос: а как эти сущности будут отображаться на базу данных, в которой они хранятся?
Самый простой вариант — создавать по таблице на каждую сущность и связывать их через внешние ключи. В большинстве проектов именно так и делают. Для этого используют Object-relational mapper (ORM) — фреймворк для данных.
С помощью ORM описываются сущности и их связи, а также определяется то, как сущность отображается на базу данных (как правило, в полуавтоматическом режиме). ORM берет на себя серьезную часть работы по:
- Генерации SQL-запросов
- Извлечению данных
- Кастингу — преобразованию типов базы данных в типы целевого языка и обратно
- Автоматическому извлечению связей
В итоге получается, что ORM прячет всю работу с базой данных. От программиста нужна только правильная конфигурация, а ORM сам выполняет все необходимые запросы. В сложных случаях их все равно приходится писать самостоятельно, но это не так сложно — ORM содержат в себе query builder, который упрощает генерацию SQL.
В экосистеме Python есть несколько ORM. Некоторые из них разрабатывались под конкретные фреймворки и поставляются с ними, другие вполне самостоятельны. Рассмотрим пример, реализованный с использованием Django ORM.
Определение сущности Photo:
from django.db import models class Photo(models.Model): title = models.CharField(max_length=200) image = models.ImageField() slug = models.SlugField() # получаем объекты из базы photos = Photo.objects.all() # передаем их в шаблон render(request, 'polls/detail.html', 'photos': photos>) Код, описывающий сущность, может показаться простым, однако степень автоматизации в Django ORM очень велика. Под капотом у такого простого кода скрыты создание сущности в БД и набор проверок значений, которые вы помещаете в модель.
Перед тем, как начинать работать с ORM, нужно сначала научиться основам баз данных. Причем не через программирование, а через прямую работу с базой. Также важно познакомиться с:
- Нормализацией
- Внешними и первичными ключами
- Индексами
- Планом запроса
- Языком SQL, чтобы менять структуры базы данных и манипулировать данными внутри базы
Затем можно перейти на уровень выполнения запросов из языка программирования. В Python для этого используются различные библиотеки вроде postgres . И только после всего этого стоит переходить к ORM. Все это будет далее в курсах.
Вот лишь некоторые темы, вовлеченные в код выше:
- Entity-relation model
- Domain-driven design
- ActiveRecord / DataMapper
- Identity map
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Что такое орм в программировании
Object-Relational Mapping — объектно-реляционное отображение — технология связывания таблиц реляционной базы данных с объектами языка программирования. В платформе CUBA используется реализация ORM на основе фреймворка EclipseLink.
Использование ORM дает ряд очевидных преимуществ:
- Позволяет работать с данными реляционной СУБД, манипулируя объектами Java.
- Упрощает программирование, избавляя от рутины написания тривиальных SQL-запросов.
- Упрощает программирование, позволяя извлекать и сохранять целые графы объектов одной командой.
- Обеспечивает легкое портирование приложения на различные СУБД.
- Позволяет использовать лаконичный язык запросов JPQL.
В то же время, имеются и некоторые недостатки. Во-первых, разработчик, использующий ORM непосредственно, должен хорошо понимать особенности работы этой технологии. Во-вторых, усложняется оптимизация SQL и использование особенности применяемой СУБД.
Если вы столкнулись с проблемами производительности при доступе к БД, начните с того, что проверьте, какие конкретно SQL-операторы выполняются в вашем приложении. Вы можете использовать логгер eclipselink.sql для вывода всех SQL-операторов, генерируемых ORM, в файл лога.
ORM или как забыть о проектировании БД
Прежде чем учить кого-то уму-разуму стоит понять что представляет из себя термин ORM. Согласно аналогу БСЭ, аббревиатура ORM скрывает буржуйское «Object-relational mapping», что в переводе на язык Пушкина означает «Объектно-реляционное отображение» и означает «технология программирования, которая связывает базы данных с концепциями объектно-ориентированных языков программирования»… т.е. ORM — прослойка между базой данных и кодом который пишет программист, которая позволяет созданые в программе объекты складывать/получать в/из бд.
Все просто! Создаем объект и кладем в бд. Нужен этот же объект? Возьми из бд! Гениально! НО! Программисты забывают о первой буковке абравиатуры и пхнут в одну и ту же табличку все! Начиная от свойств объектов, что логично, и, заканчивая foreign key, что никакого отношения к объекту не имеет! И, что самое страшное, многие тонны howto и example пропагандируют такой подход… мне кажется что первопричина кроется в постоянной балансировке между «я программист» и «я архитектор бд», а т.к. ORM плодятся и множатся — голос программиста давлеет над архитекторским. Все, дальше боли нет, только imho.
«Кто Вы, Мистер Брукс?» или «Что такое объект?»
- Для каждого пола желательно (но не принципиально) иметь свою табличку
- Где-то надо хранить информацию о принадлежности мужа жене и обратно
Тяжкое наследие ООП
- Одна женщина не может иметь более одного мужа мужского пола
- Один мужчина не может иметь более одной жены женского пола
- значение man_id впределах таблицы woman_and_man должно уникально и не null
- значение woman_id впределах таблицы woman_and_man должно уникально и не null
Критикам посвящается
После высказывания своих мыслей руководителю я получил вполне ожидаемую реакцию: «Зачем так усложнять? KISS!»
Пришлось «набраться опыта»:
Были случаи с циклическими связями между объектами содержащими среди свойств fkey и задачей «бекапа/сериализации» этого безобразия в xml/json. Нет, бекапы то делаются, вот восстанавливать потом это безобразие чертовски сложно… необходимо жестко отслеживать какие свойства создаются при восстановлении/десериализации, а потом повторно проходить по объектам и восстанавливать связи между ними. Придерживаясь правила выше — надо сначала восстановить объекты, а уж потом связи между ними. Т.к. хранится эта информация в разных таблицах/сущностях — логика была линейной и простой.
На каждый выпад «возьми монгу и не парься» или «документо-ориентированые бд рулят» я всегда приходил к одному и тому же результату который еще никто покрыть не смог:
Я смогу создать схему в реляционной бд которая будет сохранять произвольную структуру данных (произвольные документы), а вот сможете ли вы в документо-ориентированой бд гарантирвать целостность данных на уровне реляционых бд? Я не смог достич такого уровня.
Никого не смущает множественные куски повторяющихся документов с произвольным уровнем вложенности? Не, я знаю что их хранение оптимизировано и вобще, тебе какая разница? Но все же.
P.S. Это далеко не весь «поток сознания» связаный с ORM. Есть еще пара абзацев по null, пара по потимизации запросов и отложеной загрузке объектов, абзац по свойствам отношений (ага, и такое бывает), но актуально ли это? Прошу критиков высказываться в коментариях. Особо острые и интересные вопросы включу в продолжение.
ORM — отвратительный анти-паттерн
От автора перевода: Написанный далее текст может не совпадать с мнением автора перевода. Все высказывания идут от лица оригинального автора, просьба воздержаться от неоправданных минусов. Оригинальная статья выпущена в 2014 году, поэтому некоторые фрагменты кода могут быть устаревшими или «нежелаемыми».
Вступление
ORM — это ужасный анти-паттерн, который нарушает все принципы объектно-ориентированного программирования, разбирая объекты на части и превращая их в тупые и пассивные пакеты данных. Нет никаких оправданий существованию ORM в любом приложении, будь то небольшое веб-приложение или система корпоративного размера с тысячами таблиц и манипуляциями CRUD с ними. Какова альтернатива? Объекты, говорящие на языке SQL (SQL-speaking objects).
Как работают ORM
Object-relational mapping (ORM) — это способ (он же шаблон проектирования) доступа к реляционной базе данных с помощью объектно-ориентированного языка (например, Java). Существует несколько реализаций ORM почти на каждом языке, например: Hibernate для Java, ActiveRecord для Ruby on Rails, Doctrine для PHP и SQLAlchemy для Python. В Java ORM даже стандартизирован как JPA.
Во-первых, рассмотрим на примере как работает ORM. Давайте использовать Java, PostgreSQL и Hibernate. Допустим, у нас есть единственная таблица в базе данных, называемая post:
+-----+------------+--------------------------+ | id | date | title | +-----+------------+--------------------------+ | 9 | 10/24/2014 | How to cook a sandwich | | 13 | 11/03/2014 | My favorite movies | | 27 | 11/17/2014 | How much I love my job | +-----+------------+--------------------------+Теперь мы хотим манипулировать этой таблицей CRUD-методами из нашего Java-приложения (CRUD расшифровывается как create, read, update и delete). Для начала мы должны создать класс Post (извините, что он такой длинный, но это лучшее, что я могу сделать):
@Entity @Table(name = "post") public class Post < private int id; private Date date; private String title; @Id @GeneratedValue public int getId() < return this.id; >@Temporal(TemporalType.TIMESTAMP) public Date getDate() < return this.date; >public String getTitle() < return this.title; >public void setDate(Date when) < this.date = when; >public void setTitle(String txt) < this.title = txt; >>Перед любой операцией с Hibernate мы должны создать SessionFactory:
SessionFactory factory = new AnnotationConfiguration() .configure() .addAnnotatedClass(Post.class) .buildSessionFactory();Эта фабрика будет выдавать нам “сеансы” каждый раз, когда мы захотим работать с объектами Post. Каждая манипуляция с сеансом должна быть заключена в этот блок кода:
Session session = factory.openSession(); try < Transaction txn = session.beginTransaction(); // your manipulations with the ORM, see below txn.commit(); >catch (HibernateException ex) < txn.rollback(); >finally
Когда сеанс будет готов, вот так мы получаем список всех записей из этой таблицы:
List posts = session.createQuery("FROM Post").list(); for (Post post : (List) posts)
Я думаю, вам ясно, что здесь происходит. Hibernate — это большой, мощный движок, который устанавливает соединение с базой данных, выполняет необходимые SELECT запросы и извлекает данные. Затем он создает экземпляры класса Post и заполняет их данными. Когда объект приходит к нам, он заполняется данными, и чтобы получить доступ к ним, необходимо использовать геттеры, как пример getTitle() выше.
Когда мы хотим выполнить обратную операцию и отправить объект в базу данных, мы делаем все то же самое, но в обратном порядке. Мы создаем экземпляр класса Post, заполняем его данными и просим Hibernate сохранить его:
Post post = new Post(); post.setDate(new Date()); post.setTitle("How to cook an omelette"); session.save(post);Так работает почти каждая ORM. Основной принцип всегда один и тот же — объекты ORM представляют собой немощные/анемичные (прямой перевод слова anemic) оболочки с данными. Мы разговариваем с ORM фреймворком, а фреймворк разговаривает с базой данных. Объекты только помогают нам отправлять запросы в ORM framework и понимать его ответ. Кроме геттеров и сеттеров, у объектов нет других методов. Они даже не знают, из какой базы данных они пришли.
Вот как работает object-relational mapping.
Что в этом плохого, спросите вы? Все!
Что не так с ORM?
Серьезно, что не так? Hibernate уже более 10 лет является одной из самых популярных библиотек Java. Почти каждое приложение в мире с интенсивным использованием SQL использует его. В каждом руководстве по Java будет упоминаться Hibernate (или, возможно, какой-либо другой ORM, такой как TopLink или OpenJPA) для приложения, подключенного к базе данных. Это стандарт де-факто, и все же я говорю, что это неправильно? Да.
Я утверждаю, что вся идея, лежащая в основе ORM, неверна. Его изобретение было, возможно, второй большой ошибкой в ООП после NULL reference.
ORM, вместо того чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм.
На самом деле, я не единственный, кто говорит что-то подобное, и определенно не первый. Многое на эту тему уже опубликовано очень уважаемыми авторами, в том числе OrmHate автора Martin Fowler (не против ORM, но в любом случае стоит упомянуть), Object-Relational Mapping is the Vietnam of Computer Science от Jeff Atwood, The Vietnam of Computer Science автора Ted Neward, ORM Is an Anti-Pattern от Laurie Voss и многие другие.
Однако мои аргументы отличаются от того, что они говорят. Несмотря на то, что их доводы практичны и обоснованны, например, “ORM работает медленно” или “обновление базы данных затруднено”, они упускают главное. Вы можете увидеть очень хороший, практический ответ на эти практические аргументы, от Bozhidar Bozhanov в его блоге ORM Haters Don’t Get It.
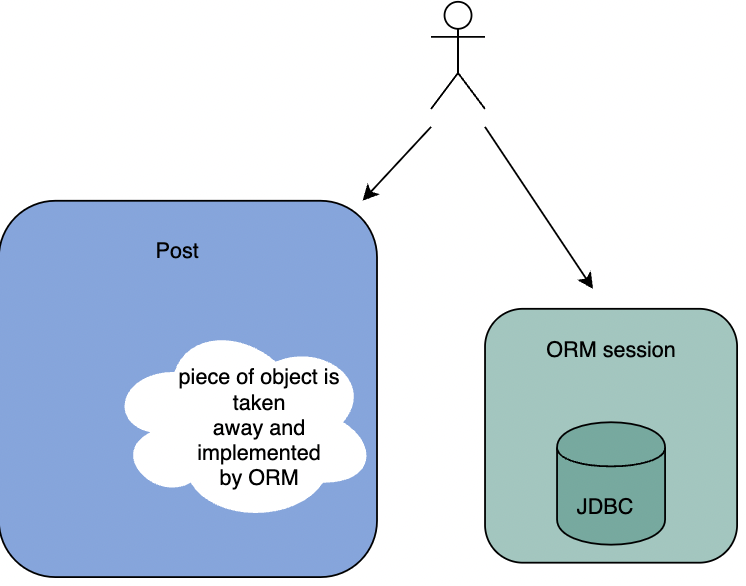
Суть в том, что ORM вместо того, чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм. Одна часть объекта хранит данные, в то время как другая, реализованная внутри механизма ORM ( sessionFactory ), знает, как обращаться с этими данными, и передает их в реляционную базу данных. Посмотрите на эту картинку; она иллюстрирует, что делает ORM.
Я, будучи читателем сообщений, должен иметь дело с двумя компонентами: 1) ORM и 2) возвращенный мне объект “ob-truncated”. Предполагается, что поведение, с которым я взаимодействую, должно предоставляться через единую точку входа, которая является объектом в ООП. В случае ORM я получаю такое поведение через две точки входа — механизм ORM и “предмет”, который мы даже не можем назвать объектом.
Из-за этого ужасного и оскорбительного нарушения объектно-ориентированной парадигмы у нас есть много практических проблем, уже упомянутых в уважаемых публикациях. Я могу добавить еще только несколько.
SQL Не Скрыт. Пользователи ORM должны говорить на SQL (или его диалекте, например, HQL). Смотрите пример выше; мы вызываем session.CreateQuery(«FROM Post») , чтобы получить все сообщения. Несмотря на то, что это не SQL, он очень похож на него. Таким образом, реляционная модель не инкапсулируется внутри объектов. Вместо этого он доступен для всего приложения. Каждому, с каждым объектом, неизбежно приходится иметь дело с реляционной моделью, чтобы что-то получить или сохранить. Таким образом, ORM не скрывает и не переносит SQL, а загрязняет им все приложение.
Трудно протестировать. Когда какой-либо объект работает со списком записей, ему необходимо иметь дело с экземпляром SessionFactory . Как мы можем замокать эту зависимость? Мы должны создать имитацию этого? Насколько сложна эта задача? Посмотрите на приведенный выше код, и вы поймете, насколько подробным и громоздким будет этот модульный тест. Вместо этого мы можем написать интеграционные тесты и подключить все приложение к тестовой версии PostgreSQL. В этом случае нет необходимости имитировать SessionFactory , но такие тесты будут довольно медленными, и, что еще более важно, наши объекты, не имеющие ничего общего с базой данных, будут протестированы на экземпляре базы данных. Ужасный замысел.
Позвольте мне еще раз повторить. Практические проблемы ORM — это всего лишь последствия. Фундаментальный недостаток заключается в том, что ORM разрывает объекты на части, ужасно и оскорбительно нарушая саму идею того, что такое объект.
SQL-speaking объекты

Какова альтернатива? Позвольте мне показать вам это на примере. Давайте попробуем спроектировать класс Post. Нам придется разбить его на два класса: Post и Posts , единственное и множественное число. Я уже упоминал в одной из своих предыдущих статей, что хороший объект — это всегда абстракция реальной сущности. Вот как этот принцип работает на практике. У нас есть две сущности: таблица базы данных и строка таблицы. Вот почему мы создадим два класса. Posts будет представлять таблицу, а Post будет представлять строку.
Как я также упоминал в этой статье, каждый объект должен работать по контракту и реализовывать интерфейс. Давайте начнем наш дизайн с двух интерфейсов. Конечно, наши объекты будут неизменяемыми. Вот как будут выглядеть Posts :
interface Posts < Iterableiterate(); Post add(Date date, String title); >Вот как будет выглядеть один Post :
interface Post
Вот так мы будем перечислять все записи в таблице базы данных:
Posts posts = // we'll discuss this right now for (Post post : posts.iterate())
Вот так создаётся новый Post :
Posts posts = // we'll discuss this right now posts.add(new Date(), "How to cook an omelette");Как вы видите, теперь у нас есть настоящие объекты. Они отвечают за все операции, и они прекрасно скрывают детали их реализации. Нет никаких транзакций, сеансов или фабрик. Мы даже не знаем, действительно ли эти объекты взаимодействуют с PostgreSQL или они хранят все данные в текстовых файлах. Все, что нам нужно от Posts — это возможность перечислить все записи для нас и создать новую. Детали реализации идеально скрыты внутри. Теперь давайте посмотрим, как мы можем реализовать эти два класса.
Я собираюсь использовать jcabi-jdbc в качестве оболочки JDBC, но вы можете использовать что-то другое, например jOOQ, или просто JDBC, если хотите. На самом деле это не имеет значения. Важно то, что ваши взаимодействия с базой данных скрыты внутри объектов. Давайте начнем с Posts и реализуем его в классе PgPosts (“pg” означает PostgreSQL):
final class PgPosts implements Posts < private final Source dbase; public PgPosts(DataSource data) < this.dbase = data; >public Iterable iterate() < return new JdbcSession(this.dbase) .sql("SELECT id FROM post") .select( new ListOutcome( new ListOutcome.Mapping() < @Override public Post map(final ResultSet rset) < return new PgPost( this.dbase, rset.getInt(1) ); >> ) ); > public Post add(Date date, String title) < return new PgPost( this.dbase, new JdbcSession(this.dbase) .sql("INSERT INTO post (date, title) VALUES (?, ?)") .set(new Utc(date)) .set(title) .insert(new SingleOutcome(Integer.class)) ); > >Далее давайте реализуем интерфейс Post в классе PgPost :
final class PgPost implements Post < private final Source dbase; private final int number; public PgPost(DataSource data, int id) < this.dbase = data; this.number = id; >public int id() < return this.number; >public Date date() < return new JdbcSession(this.dbase) .sql("SELECT date FROM post WHERE .set(this.number) .select(new SingleOutcome(Utc.class)); > public String title() < return new JdbcSession(this.dbase) .sql("SELECT title FROM post WHERE .set(this.number) .select(new SingleOutcome(String.class)); > >Вот как будет выглядеть сценарий полного взаимодействия с базой данных с использованием только что созданных нами классов:
Posts posts = new PgPosts(dbase); for (Post post : posts.iterate()) < System.out.println("Title: " + post.title()); >Post post = posts.add( new Date(), "How to cook an omelette" ); System.out.println("Just added post #" + post.id());Вы можете увидеть полный практический пример здесь. Это веб—приложение с открытым исходным кодом, которое работает с PostgreSQL, используя точный подход, описанный выше, — объекты, говорящие на SQL.
Как насчет производительности?
Я слышу, как вы спрашиваете: “А как же производительность?” В этом сценарии, приведенном несколькими строками выше, мы совершаем множество избыточных обходов базы данных. Сначала мы извлекаем идентификаторы записей с помощью SELECT id , а затем, чтобы получить их заголовки, мы выполняем дополнительный вызов SELECT title для каждой записи. Это неэффективно или, проще говоря, слишком медленно.
Не беспокойтесь, это объектно-ориентированное программирование, а это значит, что оно гибкое! Давайте создадим декоратор PgPost , который будет принимать все данные в своем конструкторе и кэшировать их внутри навсегда:
final class ConstPost implements Post < private final Post origin; private final Date dte; private final String ttl; public ConstPost(Post post, Date date, String title) < this.origin = post; this.dte = date; this.ttl = title; >public int id() < return this.origin.id(); >public Date date() < return this.dte; >public String title() < return this.ttl; >>Обратите внимание: этот декоратор ничего не знает о PostgreSQL или JDBC. Он просто декорирует объект типа Post и предварительно кэширует дату и заголовок. Как обычно, этот декоратор также неизменяем.
Теперь давайте создадим другую реализацию Posts , которая будет возвращать “постоянные” объекты:
final class ConstPgPosts implements Posts < // . public Iterableiterate() < return new JdbcSession(this.dbase) .sql("SELECT * FROM post") .select( new ListOutcome( new ListOutcome.Mapping() < @Override public Post map(final ResultSet rset) < return new ConstPost( new PgPost( ConstPgPosts.this.dbase, rset.getInt(1) ), Utc.getTimestamp(rset, 2), rset.getString(3) ); >> ) ); > >Теперь все записи, возвращаемые iterate() этого нового класса, предварительно снабжены датами и заголовками, полученными за одно обращение к базе данных.
Используя декораторы и несколько реализаций одного и того же интерфейса, вы можете создать любую функциональность, которую пожелаете. Что наиболее важно, так это то, что, хотя функциональность расширяется, сложность дизайна не возрастает, потому что классы не увеличиваются в размерах. Вместо этого мы вводим новые классы, которые остаются сплоченными и прочными, потому что они маленькие.
Что касается транзакций
Каждый объект должен иметь дело со своими собственными транзакциями и инкапсулировать их так же, как запросы SELECT или INSERT . Это приведет к вложенным транзакциям, что вполне нормально при условии, что сервер базы данных их поддерживает. Если такой поддержки нет, создайте объект транзакции для всего сеанса, который будет принимать “вызываемый” класс. Например:
final class Txn < private final DataSource dbase; public T call(Callable callable) < JdbcSession session = new JdbcSession(this.dbase); try < session.sql("START TRANSACTION").exec(); T result = callable.call(); session.sql("COMMIT").exec(); return result; >catch (Exception ex) < session.sql("ROLLBACK").exec(); throw ex; >> >Затем, когда вы хотите обернуть несколько манипуляций с объектами в одну транзакцию, сделайте это следующим образом:
new Txn(dbase).call( new Callable() < @Override public Integer call() < Posts posts = new PgPosts(dbase); Post post = posts.add( new Date(), "How to cook an omelette" ); post.comments().post("This is my first comment!"); return post.id(); >> );Этот код создаст новую запись и опубликует комментарий к ней. Если один из вызовов завершится неудачей, вся транзакция будет откачена.
Мне этот подход кажется объектно-ориентированным. Я называю это “объектами, говорящими на SQL”, потому что они знают, как разговаривать на SQL с сервером базы данных. Это их мастерство, идеально заключенное в их границах.