Список (информатика)
В информатике, спи́сок (англ. list ) — это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза. Экземпляр списка является компьютерной реализацией математического понятия конечной последовательности — кортежа. Экземпляры значений, находящихся в списке, называются элементами списка (англ. item, entry либо element ); если значение встречается несколько раз, каждое вхождение считается отдельным элементом.


Структура односвязного списка из трёх элементов
Термином список также называется несколько конкретных структур данных, применяющихся при реализации абстрактных списков, особенно связных списков.
Определение
При помощи нотации метода синтаксически-ориентированного конструирования Ч. Хоара определение списка можно записать следующим образом:





Первая строка данного определения обозначает, что список элементов типа  (говорят: «список над ») представляет собой размеченное объединение пустого списка и декартова произведения атома типа со списком над . Для создания списков используются два конструктора (вторая строка определения), первый из которых создаёт пустой список, а второй — непустой соответственно. Вполне понятно, что второй конструктор получает на вход в качестве параметров некоторый атом и список, а возвращает список, первым элементом которого является исходный атом, а остальными — элементы исходного списка. То есть получается префиксация атома к списку, с чем и связано такое наименование конструктора. Здесь необходимо отметить, что пустой список
(говорят: «список над ») представляет собой размеченное объединение пустого списка и декартова произведения атома типа со списком над . Для создания списков используются два конструктора (вторая строка определения), первый из которых создаёт пустой список, а второй — непустой соответственно. Вполне понятно, что второй конструктор получает на вход в качестве параметров некоторый атом и список, а возвращает список, первым элементом которого является исходный атом, а остальными — элементы исходного списка. То есть получается префиксация атома к списку, с чем и связано такое наименование конструктора. Здесь необходимо отметить, что пустой список ![[]](https://dic.academic.ru/dic.nsf/ruwiki/d751713988987e9331980363e24189ce.png) не является атомом, а потому не может префиксироваться. С другой стороны, пустой список является как бы нулевым элементом для конструирования списков, поэтому любой список содержит в самом своём конце именно пустой список — с него начинается конструирование.
не является атомом, а потому не может префиксироваться. С другой стороны, пустой список является как бы нулевым элементом для конструирования списков, поэтому любой список содержит в самом своём конце именно пустой список — с него начинается конструирование.
Третья строка определяет селекторы для списка, то есть операции для доступа к элементам внутри списка. Селектор  получает на вход список и возвращает первый элемент этого списка, то есть типом результата является тип . Этот селектор не может получить на вход пустой список — в этом случае результат операции неопределён. Селектор
получает на вход список и возвращает первый элемент этого списка, то есть типом результата является тип . Этот селектор не может получить на вход пустой список — в этом случае результат операции неопределён. Селектор  возвращает список, полученный из входного в результате отсечения его головы (первого элемента). Этот селектор также не может принимать на вход пустой список, так как в этом случае результат операции неопределён. При помощи этих двух операций можно достать из списка любой элемент. Например, чтобы получить третий элемент списка (если он имеется), необходимо последовательно два раза применить селектор , после чего применить селектор . Другими словами, для получения элемента списка, который находится на позиции
возвращает список, полученный из входного в результате отсечения его головы (первого элемента). Этот селектор также не может принимать на вход пустой список, так как в этом случае результат операции неопределён. При помощи этих двух операций можно достать из списка любой элемент. Например, чтобы получить третий элемент списка (если он имеется), необходимо последовательно два раза применить селектор , после чего применить селектор . Другими словами, для получения элемента списка, который находится на позиции  (начиная с
(начиная с  для первого элемента, как это принято в программировании), необходимо раз применить селектор , после чего применить селектор .
для первого элемента, как это принято в программировании), необходимо раз применить селектор , после чего применить селектор .

Четвёртая строка определения описывает предикаты для списка, то есть функции, возвращающие булевское значение в зависимости от некоторых условий. Первый предикат возвращает значение в случае, если заданный список пуст. Второй предикат действует наоборот. Наконец, пятая строка описывает части списка, которые, как уже сказано, представляют собой пустой и непустой списки.
Свойства
У определённой таким образом структуры данных имеются некоторые свойства:
- Размер списка — количество элементов в нём, исключая последний «нулевой» элемент, являющийся по определению пустым списком.
- Тип элементов — тот самый тип , над которым строится список; все элементы в списке должны быть этого типа.
- Отсортированность — список может быть отсортирован в соответствии с некоторыми критериями сортировки (например, по возрастанию целочисленных значений, если список состоит из целых чисел).
- Возможности доступа — некоторые списки в зависимости от реализации могут обеспечивать программиста селекторами для доступа непосредственно к заданному по номеру элементу.
- Сравниваемость — списки можно сравнивать друг с другом на соответствие, причём в зависимости от реализации операция сравнения списков может использовать разные технологии.
Как должно быть понятно из названия рассматриваемой структуры данных, списки используются для хранения наборов однотипных элементов. Такие элементы могут быть отсортированы для использования в функциях поиска или функциях для быстрой вставки новых элементов в список.
Списки в языках программирования
Функциональные языки
Списки в функциональных языках являются фундаментальной структурой. Большинство функциональных языков имеет встроенные средства для работы со списками вроде получения длины списка, головы (первый элемент списка), хвоста (часть списка, идущая за первым элементом), применения функции к каждому элементу списка (Map), свертки списка и пр.
Списки (list). Функции и методы списков

Сегодня я расскажу о таком типе данных, как списки, операциях над ними и методах, о генераторах списков и о применении списков.
Что такое списки?
Списки в Python — упорядоченные изменяемые коллекции объектов произвольных типов (почти как массив, но типы могут отличаться).
Чтобы использовать списки, их нужно создать. Создать список можно несколькими способами. Например, можно обработать любой итерируемый объект (например, строку) встроенной функцией list:
Список можно создать и при помощи литерала:
Как видно из примера, список может содержать любое количество любых объектов (в том числе и вложенные списки), или не содержать ничего.
И еще один способ создать список — это генераторы списков. Генератор списков — способ построить новый список, применяя выражение к каждому элементу последовательности. Генераторы списков очень похожи на цикл for.
Возможна и более сложная конструкция генератора списков:
Но в сложных случаях лучше пользоваться обычным циклом for для генерации списков.
Функции и методы списков
Создать создали, теперь нужно со списком что-то делать. Для списков доступны основные встроенные функции, а также методы списков.
Таблица «методы списков»
| Метод | Что делает |
|---|---|
| list.append(x) | Добавляет элемент в конец списка |
| list.extend(L) | Расширяет список list, добавляя в конец все элементы списка L |
| list.insert(i, x) | Вставляет на i-ый элемент значение x |
| list.remove(x) | Удаляет первый элемент в списке, имеющий значение x. ValueError, если такого элемента не существует |
| list.pop([i]) | Удаляет i-ый элемент и возвращает его. Если индекс не указан, удаляется последний элемент |
| list.index(x, [start [, end]]) | Возвращает положение первого элемента со значением x (при этом поиск ведется от start до end) |
| list.count(x) | Возвращает количество элементов со значением x |
| list.sort([key=функция]) | Сортирует список на основе функции |
| list.reverse() | Разворачивает список |
| list.copy() | Поверхностная копия списка |
| list.clear() | Очищает список |
Нужно отметить, что методы списков, в отличие от строковых методов, изменяют сам список, а потому результат выполнения не нужно записывать в эту переменную.
И, напоследок, примеры работы со списками:
Изредка, для увеличения производительности, списки заменяют гораздо менее гибкими массивами (хотя в таких случаях обычно используют сторонние библиотеки, например NumPy).
Для вставки кода на Python в комментарий заключайте его в теги
- Модуль csv - чтение и запись CSV файлов
- Создаём сайт на Django, используя хорошие практики. Часть 1: создаём проект
- Онлайн-обучение Python: сравнение популярных программ
- Книги о Python
- GUI (графический интерфейс пользователя)
- Курсы Python
- Модули
- Новости мира Python
- NumPy
- Обработка данных
- Основы программирования
- Примеры программ
- Типы данных в Python
- Видео
- Python для Web
- Работа для Python-программистов
- Сделай свой вклад в развитие сайта!
- Самоучитель Python
- Карта сайта
- Отзывы на книги по Python
- Реклама на сайте
Список
Связный список (англ. List) — структура данных, состоящая из элементов, содержащих помимо собственных данных ссылки на следующий и/или предыдущий элемент списка. С помощью списков можно реализовать такие структуры данных как стек и очередь.
Односвязный список
Простейшая реализация списка. В узлах хранятся данные и указатель на следующий элемент в списке.
![]()
Двусвязный список
Также хранится указатель на предыдущий элемент списка, благодаря чему становится проще удалять и переставлять элементы.

XOR-связный список
В некоторых случаях использование двусвязного списка в явном виде является нецелесообразным. В целях экономии памяти можно хранить только результат выполнения операции Xor над адресами предыдущего и следующего элементов списка. Таким образом, зная адрес предыдущего элемента, мы можем вычислить адрес следующего элемента.
Циклический список
Первый элемент является следующим для последнего элемента списка.

Операции на списке
Рассмотрим базовые операции на примере односвязного списка.
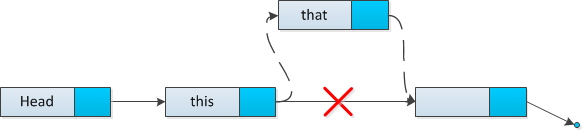
Вставка
Очевиден случай, когда необходимо добавить элемент ( [math]newHead[/math] ) в голову списка. Установим в этом элементе ссылку на старую голову, и обновим указатель на голову.
function insert(Node thatElement): thatElement.next = thisElement.next thisElement.next = thatElement
Поиск
Для того, чтобы найти элемент по значению ( [math]value[/math] ), будем двигаться по списку от головы до конца и сравнивать значение в элементах с искомым. Если элемента в списке нет, то возвращаем [math]NULL[/math] .
Node search(int value): node = head while node != NULL and value != node.value node = node.next return node
Удаление
Для того, чтобы удалить голову списка, переназначим указатель на голову на второй элемент списка, а голову удалим.
function removeHead(): if head != NULL tmp = head head = head.next delete tmp

Удаление элемента после заданного ( [math]thisElement[/math] ) происходит следующим образом: изменим ссылку на следующий элемент на следующий за удаляемым, затем удалим нужный объект.
function removeAfter(Node thisElement): if thisElement.next != NULL tmp = thisElement.next thisElement.next = thisElement.next.next delete tmp

Поиск цикла в списке
Для начала необходимо уметь определять — список циклический или нет. Воспользуемся алгоритмом Флойда "Черепаха и заяц". Пусть за одну итерацию первый указатель (черепаха) переходит к следующему элементу списка, а второй указатель (заяц) на два элемента вперед. Тогда, если эти два указателя встретятся, то цикл найден, если дошли до конца списка, то цикла нет.
boolean hasCycle(Node head): tortoise = head hare = head repeat if hare == NULL or hare.next == NULL return false tortoise = tortoise.next hare = hare.next.next until tortoise == hare return true
Если цикла не существует, то заяц первым дойдет до конца и функция возвратит [math]false[/math] . В другом случае, в тот момент, когда и черепаха и заяц находятся в цикле, расстояние между ними будет сокращаться на [math]1[/math] , что гарантирует их встречу за конечное время.
Поиск длины хвоста в списке с циклом
Так как для поиска хвоста мы должны знать, что цикл существует, воспользуемся предыдущей функцией и при выходе из неё запомним "момент встречи" зайца и черепахи. Назовем её [math]pointMeeting[/math] .
Наивные реализации
Реализация за [math]O(n^2)[/math]
Будем последовательно идти от начала цикла и проверять, лежит ли этот элемент на цикле. На каждой итерации запустим от [math]pointMeeting[/math] вперёд указатель. Если он окажется в текущем элементе, прежде чем посетит [math]pointMeeting[/math] снова, то точку окончания (начала) хвоста нашли.
Реализация за [math]O(n \log n)[/math]
Реализацию, приведенную выше можно улучшить. Для этого воспользуемся бинарным поиском. Сначала проверим голову списка, потом сделаем [math] 2 [/math] шага вперёд, потом [math] 4 [/math] , потом [math] 8 [/math] и так далее, пока не окажемся на цикле. Теперь у нас есть две позиции — на левой границе, где мы в хвосте, и на правой — в цикле. Сделаем бинарный поиск уже по этому отрезку и таким образом найдём цикл за [math]O(n \log n)[/math] .
Эффективная реализация
Возможны два варианта цикла в списке. Первый вариант — сам список циклический (указатель [math]next[/math] последнего элемента равен первому), а второй вариант — цикл внутри списка (указатель [math]next[/math] последнего элемента равен любому другому (не первому)). В первом случае найти длину цикла тривиально, во второй случай сводится к первому, если найти указатель на начало цикла. Достаточно запустить один указатель из [math]pointMeeting[/math] , а другой из головы с одной скоростью. Элемент, где оба указателя встретятся, будет началом цикла. Сложность алгоритма — [math]O(n)[/math] . Ниже приведена функция, которая находит эту точку, а возвращает длину хвоста списка.
int getTail(Node head, Node pointMeeting): firstElement = head.next secondElement = pointMeeting.next lengthTail = 1 while firstElement != secondElement firstElement = firstElement.next secondElement = secondElement.next lengthTail = lenghtTail + 1 return lengthTail
Доказательство корректности алгоритма
Рассмотрим цикл длиной [math]N[/math] с хвостом длины [math]L[/math] . Напишем функции для обоих указателей в зависимости от шага [math]n[/math] . Очевидно, что встреча не может произойти при [math]n \leqslant L[/math] , так как в этом случае [math]2n\gt n[/math] для любого [math]n\gt 0[/math] . Тогда положения указателей зададутся следующими функциями (при [math]n\gt L[/math] ):
[math]f_1(n) = L + (n-L) \bmod N[/math]
[math]f_2(n) = L + (2n-L) \bmod N[/math]
Приравнивая, получим [math]n \bmod N = 0[/math] , или [math]n = k N, n \gt L[/math] . Пусть [math]H[/math] — голова списка, [math]X[/math] — точка встречи, [math]A[/math] — первый элемент цикла, [math]Q[/math] — расстояние от [math]X[/math] до [math]A[/math] . Тогда в точку [math]A[/math] можно прийти двумя путями: из [math]H[/math] в [math]A[/math] длиной [math]L[/math] и из [math]H[/math] через [math]X[/math] в [math]A[/math] длиной [math]L + N = X + Q[/math] , то есть:
[math]Q = L + N - X[/math] , но так как [math]X = kN[/math]
[math]Q = L + (1-k) N[/math]
Пусть [math]L = p N + M, 0 \leqslant M \lt N[/math]
[math]L \lt k N \leqslant L + N[/math]
[math]pN + M \lt kN \leqslant (p+1)N + M[/math] откуда [math]k = p + 1[/math]
Подставив полученные значения, получим: [math]Q = pN + M + (1 - p - 1)N = M = L \bmod N[/math] , откуда следует, что если запустить указатели с одной скоростью из [math]H[/math] и [math]X[/math] , то они встретятся через [math]L[/math] шагов в точке [math]A[/math] . К этому времени вышедший из [math]H[/math] пройдёт ровно [math]L[/math] шагов и остановится в [math]A[/math] , вышедший из [math]X[/math] накрутит по циклу [math][L/N][/math] шагов и пройдёт ещё [math]Q = L \bmod N[/math] шагов. Поскольку [math]L = [L/N] + L \bmod N[/math] , то они встретятся как раз в точке [math]A[/math] .
Задача про обращение списка
Для того, чтобы обратить список, необходимо пройти по всем элементам этого списка, и все указатели на следующий элемент заменить на предыдущий. Эта рекурсивная функция принимает указатель на голову списка и предыдущий элемент (при запуске указывать [math]NULL[/math] ), а возвращает указатель на новую голову списка.
Node reverse(Node current, Node prev): if current == NULL return prev next = current.next current.next = prev return reverse(next, current)
Алгоритм корректен, поскольку значения элементов в списке не изменяются, а все указатели [math]next[/math] изменят свое направление, не нарушив связности самого списка.
См.также
Источники информации
- Wikipedia — Linked list
- Википедия — Список
- Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн Алгоритмы: построение и анализ — 2-е изд. — М.: «Вильямс», 2007. — Глава 11.2. — ISBN 5-8489-0857-4
- Дональд Э. Кнут Искусство программирования. Том 1. Основные алгоритмы — 2-е изд. — М.: «Вильямс», 2012. — Глава 2.2. — ISBN 0-201-89685-0
- Дискретная математика и алгоритмы
- Амортизационный анализ
- Структуры данных
Программирование в "Эврике"
— это специальный тип данных, состоящий из нескольких элементов. Элементами списка могут быть данные произвольных типов: целые и действительные числа, строки и даже другие списки. Простейший способ задать список в программе: перечислить его элементы в квадратных скобках через запятую. Например:
A=[1,2,3,4,5] B=["У лукоморья","дуб зеленый"] C=["one",1,1.0,"1"]
В этом примере переменная A — это список из 5 элементов, являющихся целыми числами, B — это список из двух элементов, являющихся строками, а C — это список из 4 элементов: строки "one" , целого числа 1 , действительного числа 1.0 и строки "1" (и все это — различные объекты).
Во многом списки похожи на множества в математике, их главное отличие в том, что списки могут содержать повторяющиеся элементы и элементы списка упорядочены. Можно задать и пустой список, не содержащий элементов: A=[] .
Пользователь может вводить список с клавиатуры, перечислив его элементы через запятую в квадратных скобках. Также списки можно выводить на экран инструкцией print .
Воспользуемся списком для решения задачи нахождения суммы большого количества чисел:
A=input("Введите список чисел: ") S=0 for f in A: S=S+f print "Сумма элементов списка", A, "равна", S
Эта программа сначала просит пользователя ввести список чисел, затем переменной S присваивается значение 0 . В эту переменную мы будем осуществлять суммирование всех элементов списка, организовав цикл по переменной f , принимающей все значение из введенного списка и увеличивая внутри списка значение переменной S на f .
Как мы видим, список, значения из которого принимает переменная, меняющаяся в цикле, можно задавать как в строке, содержащей инструкцию for , так и раньше (а в инструкции for тогда следует указать идентификатор переменной, хранящей список).
Во многих языках программирования структуры данных, наиболее близкие спискам в Питоне, называются .
Во всех реальных программах приходится иметь дело не с отдельными переменными, а с наборами данных. Например, база данных учащихся школы — это набор данных, содержащих их фамилии, имена, классы; файл, редактируемый в текстовом редакторе хранится в виде набора строк и т.д. Для хранения большого числа данных (как правило, однородных) используются структуры, которые во многих языках программирования называются массивами. Массивы в Питоне называются списками, потому что они поддерживают ряд дополнительных операций, не присущих стандартным массивам.
Выше рассказывалось, что список можно задать перечислив его элементы в квадратных скобках через запятую, либо при помощи функции input , если пользователь введет список в таком же виде, либо можно создать список при помощи функции range . Например, если необходимо, чтобы переменная A была списком из n элементов, это можно сделать при помощи присваивания A=range(n) . Распечатать элементы массива можно при помощи инструкции print .
Внимание! Если при вводе списка не заключить его в квадратные скобки, а просто перечислить его элементы через запятую, то будет создан объект, называемый кортежем. Его главное отличие от списков заключается в том, что элементы кортежа нельзя изменять. При попытке присвоить элементу кортежа новое значение будет выдана ошибка "TypeError: object doesn't support item assignment" (Ошибка типа: объект не поддерживает возможность изменения элемента). В случае возникновения таких ошибок будет говориться "смотри листочек".
Обратиться (узнать значение или изменить) элемент с номером i списка A можно используя оператор [] : A[i] . Элементы списка нумеруются, начиная с 0, то есть если в списке есть n элементов, то начальный элемент списка имеет номер 0, а конечный номер n-1. Как правило, номера элементов списка называются (произносится "элемент с индексом 0"). Узнать количество элементов в списке A можно при помощи функции len(A) . Таким образом, распечатать список поэлементно можно при помощи следующей программы:
A=input("Введите список: ") for i in range(0,len(A)): print "Элемент с номером", i, "равен", A[i]
В данном примере если список A состоит из n элементов, то переменная i принимает значения от 0 до n-1, то есть всевозможные значения индексов списка. В следующем примере используется аналогичный цикл для того, чтобы удвоить все элементы списка:
A=input("Введите список: ") for i in range(0,len(A)): A[i]=2*A[i]
Также можно использовать отрицательные значения индекса для нумерации элементов с конца списка: A[-1] обозначает последний элемент списка A , A[-2] — второй с конца и т.д. до первого элемента A[-len(A)] . При попытке обратиться к списку из n элементов по индексу, большему, чем n-1 или меньшему, чем -n, будет выдана ошибка IndexError: list index out of range (значение индекса списка выходит за допустимый диапазон). Такая ошибка является весьма типичной.