Что такое Data Science? Объясняем простыми словами

Наука о данных (Data Science) включает в себя все инструменты, методы и технологии, помогающие нам обрабатывать данные и использовать их для нашего блага. Это междисциплинарная смесь статистических выводов, анализа данных, разработки алгоритмов и технологий для решения аналитически сложных задач.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

- Организация данных — хранение и форматирование. Также сюда входят практики управления данными (Data Management).
- Агрегация данных — объединение исходных данных в новое представление и/или пакет.
- Доставка данных — обеспечение доступа к массивам агрегированных данных.
Наука о данных — обширная и субъективная тема для обсуждения, которую практически невозможно уместить в одну статью. Сама по себе Data Science не самостоятельная наука, а скорее сочетание нескольких смежных дисциплин: математики и статистики, программирования, бизнес-аналитики и стратегического планирования.
На диаграмме Венна, показано, как все дисциплины сочетаются и работают вместе.

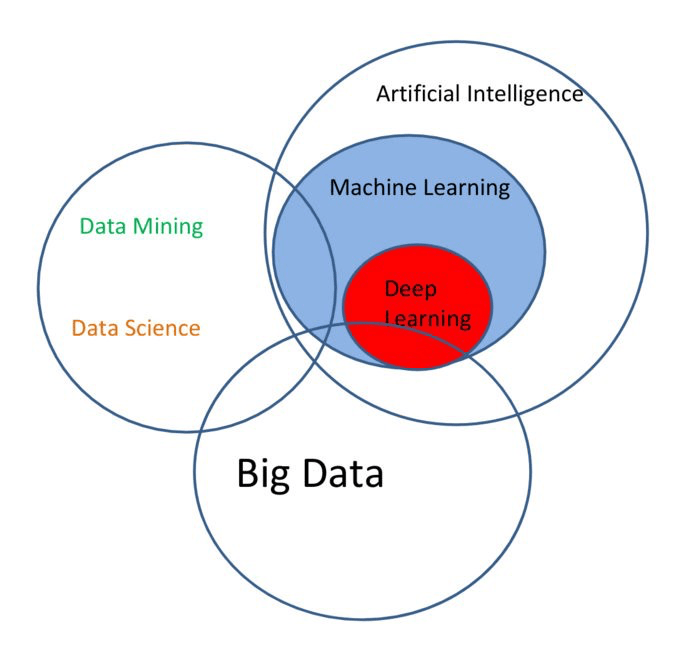
Big Data
Big Data — это различные инструменты, подходы и методы обработки как структурированных, так и неструктурированных данных, которые позволяют использовать эти данные для решения конкретных задач и достижения целей.
Используя анализ Big Data, розничные продавцы смогут заранее узнать, какие продукты будут хорошо продаваться, телекоммуникационные компании смогут предсказать, захочет ли клиент сменить оператора и когда это произойдёт, а страховые компании смогут оценить, насколько безопасно их клиенты управляют автомобилем. Среди прочего, анализ Big Data позволяет нам лучше понимать и прогнозировать эпидемии болезней и находить самые эффективные способы лечения.
Машинное Обучение
Цитируя Тома Митчела: Машинное обучения изучает вопрос создания программ, способных улучшаться в процессе обучения.
Машинное Обучение носит междисциплинарный характер и использует, среди прочего, методы из области информатики, статистики и искусственного интеллекта.
Основной областью исследований в Машинном Обучении являются алгоритмы, которые способны обучаться и запоминать и могут применяться в различных областях науки и бизнеса.
Data Mining (Сбор и интеллектуальный анализ данных)
Файяд, Пятецкий-Шапиро и Смайт дают следующее определение Data Mining:
«Применение специальных алгоритмов для извлечения шаблонов из данных. В интеллектуальном анализе данных акцент делается на применение алгоритмов, а не на сами алгоритмы.»
Мы можем определить взаимосвязь машинного обучения и Data Mining следующим образом: интеллектуальный анализ данных — это процесс, в ходе которого алгоритмы МО используются в качестве инструментов для извлечения потенциально ценных шаблонов, содержащихся в наборах данных.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
Deep Learning
Deep Learning — относительно новый термин, однако существовавший ещё до резкого роста повышения внимания к науке о данных.
Deep Learning — это процесс применения технологий глубоких нейронных сетей — архитектур нейронных сетей с несколькими скрытыми уровнями — для решения поставленных задач.
По сути это Data Mining, в котором используются архитектуры глубоких нейронных сетей — особого типа алгоритмов машинного обучения.
Читайте также 8 причин стать дата-сайентистом в 2023 году
Искусственный интеллект
Искусственный интеллект — научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются интеллектуальными.
Исследования, связанные с ИИ, высокотехнологичны и узкоспециализированны. Одной из ключевых задач искусственного интеллекта является программирование компьютеров, которые демонстрируют такие способности, как понимание, рассуждение, решение проблем, восприятие, обучение, планирование и т. д. Основные составляющие ИИ — машинное обучение, инженерия знаний (knowledge engineering) и робототехника.
Принимая во внимание перечисленные научные области, концепции, и инструменты, мы можем без труда заключить: Data Science — это наше будущее, причем ближайшее.
Что такое Data Science и кто такой Data Scientist
Что делает Data Scientist, сколько получает и как им стать, даже если вы не программист. Объясняем и делимся полезными ссылками.

Даниил Гапешин
Пишу научпоп, люблю делать сложное понятным. Рисую фантастику. Увлекаюсь спелеологией. Люблю StarCraft, шахматы, «Монополию».
Что такое Data Science?
Data Science — это работа с большими данными (англ. Big Data). Большие данные — это огромные объёмы неструктурированной информации: например, метеоданные за какой-то период, статистика запросов в поисковых системах, результаты спортивных состязаний, базы данных геномов микроорганизмов и многое другое. Ключевые слова здесь — «огромный объём» и «неструктурированность». Чтобы работать с такими данными, используют математическую статистику и методы машинного обучения.
Специалист, который делает такую работу, называется дата-сайентист (или Data Scientist). Он анализирует большие данные (Big Data), чтобы делать прогнозы. Какие именно прогнозы — зависит от того, какую задачу нужно решить. Итог работы дата-сайентиста — прогнозная модель. Если упростить, то это программный алгоритм, который находит оптимальное решение поставленной задачи.
Эти прогнозы и правда полезны?
Да. Очень многие сервисы, к которым мы уже привыкли, создали дата-сайентисты. И вы сталкиваетесь с результатами их работы каждый день. Например, это прогнозы погоды, чат-боты, голосовые помощники… А ещё — алгоритмы, рекомендующие музыку и видео под вкус конкретного пользователя. Список возможных друзей в социальных сетях — тоже результат Data Science. В основе поисковых систем и программ для распознавания лиц тоже лежат алгоритмы, написанные дата-сайентистами.
То есть Data Science — то же самое, что и обычная бизнес-аналитика?
Нет, это не одно и то же. Основная разница заключается в результате. Data Scientist ищет в массивах данных связи и закономерности, которые позволят ему создать модель, предсказывающую результат, — то есть можно сказать, что Data Scientist работает на будущее. Он использует программные алгоритмы и математическую статистику и решает поставленную задачу в первую очередь как техническую.
Бизнес-аналитик сосредоточен не столько на технической, программной стороне задачи, сколько на коммерческих показателях компании. Он работает со статистикой и может оценить, например, насколько эффективна была рекламная кампания, сколько было продаж в предыдущем месяце и так далее. Вся эта информация может использоваться для улучшения бизнес-показателей компании. Если данных много и нужен какой-то прогноз или оценка, то для решения технической стороны этой задачи бизнес-аналитик может привлечь дата-сайентистов.
Поясним на примере. Допустим, программа анализирует финансовые операции клиента и рекомендует выдать ему кредит или отказать. То есть задача программы — оценить платёжеспособность клиента. Создание такого програмного алгоритма — работа дата-сайентиста.
А бизнес-аналитик не занимается такими техническими задачами. Его не интересует работа с конкретным клиентом, но он может проанализировать всю статистику банка по кредитам, например, за последние три месяца — и рекомендовать банку сократить или увеличить объёмы кредитования. Это бизнес-задача: предлагаются действия, которые увеличат доходность банка либо снизят финансовые риски.
Работа бизнес-аналитика и дата-сайентиста нередко пересекается, просто каждый занимается своей частью задачи.
А где обычно работает Data Scientist?
Вот несколько вариантов:
- В бизнесе — в любом его направлении. Например, дата-сайентист создаёт алгоритмы, прогнозирующие спрос на услуги компании. Другие алгоритмы помогут решить, нужно ли компании открывать новое направление бизнеса. Вариантов много.
- В банках. Один из примеров мы разобрали в предыдущей карточке.
- В транспортных компаниях. Например, программы помогают выстроить оптимальный маршрут.
- В IT-сфере. Дата-сайентист разрабатывает ботов, поисковые алгоритмы, системы искусственного интеллекта.
- На производстве. Например, программы прогнозируют сбои оборудования и дефекты продукции.
- В страховых компаниях. Машинные алгоритмы оценивают вероятность страхового случая.
- Медицина. Появляется всё больше приборов, автоматически ставящих диагноз на основании данных. Например, программа может указать повреждённые органы на рентгеновских снимках.
- В сельском хозяйстве. Алгоритмы дают прогноз по урожаю, подбирают оптимальные системы землепользования.
- Биоинформатика и современные генетические исследования немыслимы без Data Science. Программы строят генетические карты, определяют вид организма.
- Физические исследования. Например, алгоритмы выявляют элементарные частицы и их следы.
- Метеослужбы. Да, современные прогнозы погоды тоже готовятся с помощью Data Science.
И это далеко не полный список. Везде, где нужны прогнозы, совершаются сделки или оцениваются риски, пригодится Data Scientist. Вот несколько примеров рабочих моделей. Некоторые неожиданные: например, Corrupt Social Interactions — модель, выявляющая коррупцию в Департаменте строительства (Department of Building) США. Или сервис А Roommate Recommendation — он помогает подобрать соседа по комнате в кампусе или хостеле.
Понятно. А работу найти легко? Это точно востребовано?
Легко ли найти работу — зависит и от кандидата тоже. Но сама профессия весьма востребована. В 2016 году американская компания Glassdoor опубликовала рейтинг 25 лучших вакансий в США и профессия Data Scientist возглавила этот список. С тех пор востребованность стала даже выше.
Алгоритмы машинного обучения сейчас стремительно развиваются, прогнозы на их основе становятся точнее, а сфер их применения всё больше. Это значит, что у профессии Data Scientist большое будущее.
Но это за рубежом. А что в России?
У нас спрос на этих специалистов тоже постоянно растёт. Например, в 2018 году вакансий с названием Data Scientist было в 7 раз больше по сравнению с 2015 годом, а в 2019 году рост продолжился.
На середину апреля 2020 года на hh.ru — 323 вакансии с заголовком Data Scientist, из них 204 вакансии — в Москве, 39 — в Санкт-Петербурге и остальные — в других городах.
А сколько они зарабатывают?
Как и везде, это зависит от опыта работы и навыков дата-сайентиста, особенностей компании и сложности конкретного проекта. Но общий расклад примерно такой (данные приведены по состоянию на февраль 2020 года):
- Зарплаты по вакансии Data Scientist на HH.ru начинаются от 70 тысяч рублей по России и от 100 тысяч рублей в Москве. Это деньги, на которые могут претендовать новички в отрасли. Чтобы было проще сориентироваться, средняя зарплата в Москве в начале 2020 года составляет около 86 тысяч рублей.
- Основной диапазон зарплат по вакансиям дата-сайентиста — примерно от 100 до 160 тысяч рублей по России и от 150 до 200 тысяч рублей в Москве. На такие зарплаты могут претендовать специалисты с опытом.
Высококвалифицированные специалисты по Data Science могут получать в месяц 250 тысяч рублей и более.
Вы сказали, что Data Scientist создаёт программный алгоритм. А что конкретно он делает?
В разных компаниях деятельность дата-сайентиста будет различаться. Однако основные этапы похожи:
- сначала он выясняет, что нужно заказчику (внутреннему или внешнему);
- теперь надо оценить, можно ли решить эту задачу методами машинного обучения;
- если да, то дата-сайентист готовит данные для анализа и ищет критерии оценки — чтобы понять, насколько эффективна модель, которую он создаёт;
- затем программирует и тренирует модель машинного обучения;
- после ему нужно оценить, насколько применение этой модели целесообразно экономически. Здесь ему могут помочь другие специалисты;
- теперь полученная модель внедряется в производственный цикл или продукт;
- когда модель уже введена в эксплуатацию, обязанность дата-сайентиста — вести её, то есть дорабатывать и изменять под текущие нужды.
Что нужно знать и уметь, чтобы работать в Data Science?
Если в общих чертах, то нужно знать математику, математическую статистику, программирование, принципы машинного обучения и ту отрасль, где всё это будет использоваться.
И умение работать в команде тоже никто не отменял: дата-сайентисту приходится общаться с разными специалистами.
Если у меня нет технического образования, то о работе в Data Science лучше не мечтать?
Будем откровенны — гуманитариям осваивать эту профессию может быть непросто: для работы в Data Science нужно хорошее знание математики и программирования. А у гуманитария этих знаний чаще всего нет. И наоборот: чем увереннее вы чувствуете себя в этом уже на старте, тем проще будет учиться.
Однако не стоит опускать руки: очень многое зависит от мотивации, от того, насколько вы готовы восполнять пробелы в своем образовании. Сейчас люди приходят в Data Science с разным бэкграундом и в разном возрасте. Вот пример одной такой истории — возможно, она вас поддержит.
А с чего лучше начать?
Начать лучше с математики. Очень сложная математика не понадобится, но вы должны свободно ориентироваться в таких понятиях, как производная, дифференциал, определитель матрицы, и в том, что с ними связано. Освоить это вам помогут книги и лекционные курсы. Например, книга «Математический анализ» Липмана Берса, написанная довольно простым языком.
А что дальше? Там было что-то о статистике?
Да, потому что математическая статистика используется в любой аналитике. И Data Science не исключение. Вот несколько бесплатных курсов, которые помогут вам изучить статистику.
- Курс «Основы статистики» подойдёт тем, кто знакомится с ней с нуля.
- «Математическая статистика» — курс для более продвинутых, там много практических заданий.
- «Статистические методы в гуманитарных исследованиях» — здесь, помимо самой статистики, вы научитесь работать с программами и пакетами, нужными для анализа данных.
Кажется, с математической частью закончили. Что по программированию?
Следующим шагом будет изучение Python. Сейчас этот язык программирования, пожалуй, основной инструмент в Data Science. Среди его достоинств — относительная простота и гибкость. Освоить Python вполне по силам новичку, который до того не программировал. Неслучайно этот язык нередко рекомендуют для начинающих.
По Python есть много курсов, как платных, так и бесплатных. Вот один из бесплатных курсов. И ещё один: «Питонтьютор».
У Skillbox тоже есть курс, он называется «Профессия Python-разработчик». Курс платный, длится год, и за это время студенты фактически осваивают с нуля новую профессию (как теорию, так и практику) и собирают личное портфолио — с помощью наставника. Поэтому по окончании курса им уже есть что показать потенциальному работодателю.
Что учить после Python?
Теперь можно изучать алгоритмы машинного обучения. Когда освоитесь с ними, уже сможете работать в Data Science.
Вот несколько бесплатных онлайн курсов по машинному обучению (много курсов на английском, но кое-что есть и на русском).
- Курс МФТИ «Машинное обучение и анализ данных». Там можно освоить современные инструменты для анализа больших данных и научиться проводить сам анализ — от сбора данных до представления результатов. Курс на русском языке.
- Курс машинного обучения от Google помимо объяснений содержит около 40 практических упражнений. Также на английском языке.
- Запись цикла лекций профессора факультета машинного обучения из университета Карнеги — Меллона. Бесплатный курс, рассчитан на людей с хорошей базой в программировании и математике. На английском языке, но можно поставить русские субтитры.
- Продвинутый курс об использовании алгоритмов машинного обучения в творчестве. Создан при поддержке проекта Google Magenta. На курсе изучаются основные компоненты глубокого обучения: свёрточные сети, генеративные состязательные сети, вариационные автокодеры и рекурсивные нейросети. Если эти слова вас пока пугают — начните с курсов выше, рассчитанных на новичков.
Мало знать методы машинного обучения, нужно уметь применять их для решения практических задач. Научиться этому можно на платформе Kaggle, где собрано огромное количество реальных задач.
Если вы хорошо знаете английский, он поможет вам быстрее развиваться в Data Science. Если нет — самое время его выучить.
Наука о данных
Data Science

Наука о данных (Data Science) — профессиональная деятельность, связанная с эффективным и максимально достоверным поиском закономерностей в данных, извлечение знаний из данных в обобщённой форме, а также их оформление в виде, пригодном для обработки заинтересованными сторонами (людьми, программными системами, управляющими устройствами) в целях принятия обоснованных решений.
Что такое Data Science?
Математические и алгоритмические методы, оптимизированные для эффективного выявления сложных закономерностей. Наука о методах анализа данных, сформировавшаяся на стыке математики, компьютерных наук и бизнеса, включающая в себя построение сложных аналитических моделей на основе данных для извлечения новых знаний.
Data Science — это набор конкретных дисциплин из разных направлений, отвечающих за анализ данных и поиск оптимальных решений на их основе. Раньше этим занималась только математическая статистика, затем начали использовать машинное обучение и искусственный интеллект, которые в качестве методов анализа данных к матстатистике добавили оптимизацию и computer science (то есть информатику, но в более широком смысле, чем это принято понимать в России) [1] .


Структура Data Science Проекта
Data Science — как это работает?

Традиционные риски Data Science проектов
- Высокая стоимость реализации проекта приведет к финансовым потерям (не окупится)
- Отсутствие подробной отчетности по проекту не позволит отчитаться о потраченных средствах или принять правильное решение о продолжении проекта
- Внедрение закрытого алгоритма или программы («Черный ящик») сделает невозможным дальнейшее изменение или модернизацию проекта внешними или внутренними ресурсами
Big Data≠Data Science

- ETL\ELT
- Технологии хранения больших объемов структурированных и не структурированных данных
- Технологии обработки таких данных
- Управление качеством данных
- Технологии предоставления данных потребителю
- Распознавание видео
- Распознавание текстов
- Распознавание речи
- Построение рекомендательных моделей
- Сегментация
- Кластеризация и т.д.
Data Science в реалиях производства
- Сложный и длительный во времени процесс
- Требуется глубокое понимание предметной области
- Разная частота съема данных и не все оцифровано
- Нет сквозного контроля и фиксации событий тех.процесса
- Доверие к модели со стороны технологов и операторов
- Для проверок модели требуются эксперименты с данными реального времени на производстве
Новости и основные тенденции в области данных
2023
«Искусственный интеллект от боли до эффектов» — взгляд Data-экспертов
«Рексофт Консалтинг», подразделение трансформационного и стратегического консалтинга группы «Рексофт», выпустил исследование по проблематике, с которой сталкиваются Data-специалисты российских компаний в ходе разработки и внедрения цифровых решений на базе технологий искусственного интеллекта (ИИ). Материал также содержит обзор возможных путей преодоления возникающих трудностей. Об этом «Рексофт» сообщил 28 ноября 2023 года.
Компания «Рексофт Консалтинг» провела глубинные интервью с экспертами, а именно с техническими директорами, CDO, руководителями направлений и команд Data Science, Data Science специалистами, разрабатывающими и внедряющими цифровые решения на базе ИИ в различных отраслях экономики, чтобы понять с какими проблемами они сталкиваются сегодня. В опросе приняли участие представители промышленности, медицины, финансового сектора, ритейла и ИТ-компаний.

По результатам интервью были выделены 5 ключевых областей, в которых сосредоточены основные трудности, не позволяющие эффективно внедрять ИИ-решения в российских компаниях:
- Взаимодействие Data-специалистов с бизнес-заказчиком
- Данные
- Управление разработкой и технологии
- Передача в эксплуатацию и поддержка ИИ-решений
- Поиск, удержание и развитие Data Science специалистов

Среди наиболее частых причин возникновения трудностей при взаимодействии Data-специалистов с бизнес-заказчиком называются такие как: завышенные ожидания бизнеса, нежелание бизнеса трансформироваться, неадаптированная корпоративная культура. Наиболее остро они проявляются в случае, если бизнес инвестирует в ИИ, но не достигает эффекта и испытывает затруднения с приживаемостью решений. Для их успешного внедрения бизнес-заказчикам необходимо быть готовыми трансформировать свою операционную модель.
В блоке данные фигурируют такие корневые причины как недостаточный уровень автоматизации бизнес-процессов, низкий уровень зрелости инфраструктуры данных, низкое качество исходных данных и длительный процесс их получения, неадаптированные для цифровых решений на базе ИИ процессы сбора и управления данными. Трудности, связанные с данными, всегда охватывают не только ИИ-разработку, но и всю компанию из-за отсутствия единых требований и настроенных процессов. Проблематика в части данных характеризуется тезисом «новые проблемы, старые решения» – прежде чем приступать к Data Science, необходимо отладить и адаптировать процессы, связанные с управлением данными.
Технологический стек для разработки решений на базе ИИ постоянно меняется и развивается. Здесь Data-специалисты выделяют отсутствие стандартов ИИ-разработки и гибкого подхода при прототипировании ИИ-решений, а также отсутствие сформированного подхода к работе с внешними разработчиками ИИ-решений.
В сегменте передачи в эксплуатацию и поддержки ИИ-решений специалисты отмечают отсутствие выстроенного процесса передачи в эксплуатацию и четких критериев приемки решений, а также то, что подходы ИБ не адаптированы к внедрению решений ИИ и оценке его рисков. Для минимизации барьеров, с которыми сталкиваются компании при масштабировании пилотных ИИ-решений, необходимо заранее договариваться о критериях успеха и продумывать модель поддержки. Критически важно до старта проекта определить и согласовать подход к оценке экономического эффекта со всеми заинтересованными сторонами, а также выстроить долгосрочную систему мотивации вовлеченных сотрудников, чтобы избежать трудностей с приживаемостью решений.
Особенную озабоченность у опрошенных экспертов вызывает задача поиска, удержания и развития Data Science специалистов. Существующие во многих российских компаниях HR-процессы поиска, найма, адаптации и удержания персонала не адаптированы для Data-специалистов. Недостаток Т-shape специалистов обостряет разрыв между бизнесом и Data Science. HR в сложившейся ситуации не понимает, как развивать последних и адаптировать первых. Организационные структуры и функционально-ролевые модели ИТ во многих российских компаниях не успели адаптироваться к системному внедрению решений на базе ИИ, что размывает распределение ответственности и роль Data-специалистов.
сказал Алексей Богомолов, директор практики «Стратегия трансформации» «Рексофт Консалтинг».

Названы 5 трендов на рынке Data Science
Значительное влияние на мировую отрасль наук о данных и машинного обучения (Data Science and Machine Learning, DSML) окажут системы генеративного искусственного интеллекта. Об этом говорится в отчете Gartner, опубликованном 1 августа 2023 года.

Значительное влияние на мировую отрасль DSML окажут системы генеративного ИИ
Опрос Gartner, в котором приняли участие более 2500 руководителей различных организаций, показал, что 45% компаний увеличили инвестиции в ИИ после появления чат-бота ChatGPT. При этом 70% респондентов сообщили, что изучают возможность использования средств генеративного ИИ, тогда как 19% уже экспериментируют с такими системами. Gartner выделяет пять ключевых тенденций, которые определят дальнейшее развитие отрасли DSML.
Тренд 1. Экосистемы облачных данных
Решения по обработке данных преобразуются из автономного программного обеспечения или смешанных развертываний в полноценные облачные платформы. К 2024 году, полагает Gartner, 50% новых приложений в облаке будут основаны на целостной экосистеме данных, а не на точечных массивах, интегрированных вручную.
Растет потребность в ИИ-средствах на периферии (Edge AI). Такие инструменты позволяют обрабатывать данные в момент их создания, что помогает организациям получать ценную информацию в режиме реального времени и соблюдать строгие требования к конфиденциальности. Gartner прогнозирует, что к 2025 году более 55% всего анализа данных с помощью глубоких нейронных сетей будет происходить на периферии. Для сравнения: в 2021 году этот показатель составлял менее 10%.
Тренд 3. Ответственный ИИ
Подход, основанный на ответственном использовании, позволяет извлечь максимальную выгоду от внедрения технологий ИИ и обойти возможные проблемы, связанные с доверием и общественными рисками. Концепция ответственного ИИ охватывает многие деловые и этические аспекты. Gartner рекомендует организациям соблюдать осторожность при внедрении нейросетевых моделей и применять бизнес-стратегию на основе оценки рисков для обеспечения ценности ИИ. Это поможет защититься от финансовых потерь, судебных исков и репутационного ущерба.

45% компаний увеличили инвестиции в ИИ после появления ChatGPT
Тренд 4. Искусственный интеллект, ориентированный на данные
Применение подхода, ориентированного на данные, обеспечит возможность создания более совершенных ИИ-приложений и сервисов. Использование генеративного ИИ для формирования синтетических данных — это одна из быстрорастущих областей, способствующих эффективной тренировке моделей машинного обучения. Gartner прогнозирует, что к 2024 году 60% данных для моделирования реальности, новых сценариев применения ИИ и снижения рисков будут синтетическими. В 2021 году этот показатель равнялся только 1%.
Тренд 5. Ускорение инвестиций в ИИ
Финансовые вливания в технологии ИИ продолжат увеличиваться, чему будет способствовать расширение использования соответствующих инструментов. К 2026-му, полагают эксперты Gartner, более $10 млрд будет инвестировано в стартапы, которые применяют масштабные модели ИИ, обученные на огромных объемах данных. [3]
2020: Наука о данных: пять ключевых тенденций
1. Ускорение внедрения ИИ в бизнесе
В течение последних нескольких лет ИИ постепенно становится одной из основных технологий как для малых, так и для крупных предприятий, и есть все основания полагать, что это будет продолжаться в течение следующих нескольких лет. Сегодня мы находимся на начальных этапах применения ИИ, но вполне вероятно, что уже к концу 2020 г. мы увидим новые и более прогрессивные методы его задействования в научных областях и бизнесе. Движущей силой такого быстрого роста является тот факт, что ИИ позволяет компаниям любых размеров значительно повысить эффективность и результативность своих бизнес-процессов и операций. С его помощью можно также достичь огромных успехов в управлении клиентскими и пользовательскими данными [4] .
Многие предприятия столкнутся со сложностями при внедрении ИИ, что связано с ограниченными финансовыми ресурсами или недостатком квалифицированного персонала, но те, кто инвестирует в него средства, получат ощутимую отдачу в виде продвинутых приложений, разработанных с использованием ИИ, МО и других технологий, которые значительным образом изменят те методы работы, которые приняты сегодня.
Еще одна тенденция, которая в ближайшие месяцы примет видимые очертания — автоматизированное МО, которое помогает трансформировать науку о данных при помощи улучшенного управления данными. Это приведет к тому, что начинающим специалистам по данным потребуется пройти специализированные курсы, чтобы изучить методы глубокого обучения.
2. Быстрый рост IoT
Согласно IDC, к концу 2020 года инвестиции в технологии Интернета вещей достигнут 1 трлн. долл., что является очевидным свидетельством ожидаемого роста числа «умных» и подключенных устройств. Многие люди уже применяют приложения и устройства, чтобы с их помощью управлять своими бытовыми приборами — электропечами, холодильниками, кондиционерами и телевизорами. Все это примеры базовой технологии IoT, и пользователи часто могут не знать, что за ней скрывается. Смарт-устройства типа Google Assistant, Amazon Alexa и Microsoft Cortana позволяют людям легко автоматизировать повседневные задачи в домашних условиях. Это только вопрос времени, когда компании задействуют их в комбинации с бизнес-приложениями и начнут активнее инвестировать в эту технологию. Наиболее заметный прогресс от применения IoT ожидается на производстве — там она поможет оптимизировать работу заводских цехов.
3. Эволюция аналитики больших данных
Эффективный анализ больших данных, несомненно, помогает предприятиям получить значительное конкурентное преимущество и достичь основных целей. Сегодня они применяют для анализа своих скоплений данных различные инструменты и технологии, такие как Python. Все больше компаний сосредоточились на выявлении причин, стоящих за определенными событиями, которые происходят в настоящее время, и в этом случае на помощь приходит прогнозная аналитика — она позволяет выявлять тенденции и прогнозировать, что может произойти в будущем. К примеру, она пригодится для того, чтобы определить пользовательские привычки отталкиваясь от истории просмотров или покупок. Специалисты по продажам и маркетингу могут проанализировать эти модели, чтобы создать более целенаправленные стратегии для привлечения новых клиентов и удержания уже имеющихся. Amazon применяет прогностические модели для наполнения складских запасов исходя из спроса в том или ином регионе продаж.
4. Edge Computing на подъеме
Периферийные вычисления набирают популярность, и ответственность за это несут датчики. Наступление этой технологии продолжится в значительной степени благодаря популяризации IoT, которая захватывает основные вычислительные системы. Edge Computing предоставляет компаниям возможность хранить потоковые данные рядом с источниками и анализировать их в режиме реального времени. Периферийные вычисления также являются альтернативой аналитике больших данных, которая требует высокопроизводительных устройств хранения данных и гораздо большей пропускной способности сети. Число устройств и датчиков, собирающих данные, растет экспоненциально, поэтому все больше компаний внедряют Edge Computing благодаря его возможностям в плане решения проблем, связанных с пропускной способностью, задержкой и связью. Кроме того, сочетание периферийных и облачных технологий формирует синхронизированную инфраструктуру, которая может минимизировать риски, связанные с анализом и управлением данными.
5. Растущий спрос на специалистов по безопасности данных
Без сомнений, внедрение ИИ и МО приведет к появлению многих новых специальностей в ИТ- и высокотехнологичных отраслях. Одной из самых востребованных станет специалист в области безопасности данных. На рынке труда уже в достаточном количестве имеются эксперты в области ИИ, МО и специалисты по данным, но помимо них существует потребность в специалистах по безопасности данных, которые умеют так анализировать и обрабатывать данные, чтобы передавать их клиентам в безопасном виде. Для выполнения этих функций они должны хорошо разбираться в новейших технологиях, таких как Python и другие популярные языки, которые применяются в науке о данных и аналитике. Четкое понимание концепций Python поможет решить проблемы, связанные с безопасностью данных.
Обучение Data Science
2020: НИТУ «МИСиС», SkillFactory и Mail.ru Group запускают русскоязычную онлайн-магистратуру по Data Science
28 мая 2020 года компания VK (ранее Mail.ru Group) сообщила, что НИТУ «МИСиС» и образовательная платформа в области Data Science – SkillFactory – заключили соглашение о создании совместной онлайн-магистратуры «Наука о данных» и сотрудничестве в области развития образовательных технологий в высшем образовании. Это партнерство частной образовательной компании с государственным вузом по модели OPM (Online Program Management). Индустриальным партнером программы выступает Mail.ru Group. Программу также поддерживают Nvidia, Ростелеком и Университет НТИ «20.35».
Выпускники программы смогут работать в областях Big Data Engineering, Machine Learning Development и Artificial Intelligence Development. Цель программы – вовлечь в сферу науки о данных более 1 000 молодых специалистов к 2025 году в рамках федерального проекта «Кадры для цифровой экономики», задача которого подготовить не менее 120 000 выпускников вузов по ИТ-направлениям.
Занятия будут вести профессора НИТУ «МИСиС» и практикующие специалисты из Mail.ru Group, Яндекса, банков Тинькофф и ВТБ, компаний Lamoda, BIOCAD, АльфаСтрахование и др. Интенсивная программа онлайн-магистратуры позволит студентам овладеть знаниями и навыками, востребованными работодателями, получить фундамент для дальнейшего развития и построения карьеры, пройти стажировку в компаниях-партнерах программы.
отметила Алевтина Черникова, ректор НИТУ «МИСиС»
Ещё одна особенность программы – работа с менторами. Кроме преподавателей со студентами будет работать команда менторов – специалистов в области Data Science. Они будут помогать студентам с возникающими во время обучения сложностями, давать содержательную обратную связь по выполненным работам, делиться опытом и знаниями по профессии. Поддержка менторов будет доступна студентам в чате в режиме реального времени.
Технологическим партнером программы стала компания SkillFactory, обеспечивающая сопровождение образовательного процесса. Для каждого студента будет сформирован индивидуальный план обучения, что позволит управлять его образовательным опытом и мотивацией, что, в свою очередь, повышает результативность обучения. Студенты будут учиться на интерактивных тренажерах и решать практические задачи на реальных данных. Среди дисциплин в рамках программы: язык программирования Python, Machine Learning, Deep Learning, Big Data, Computer Vision.
Data Science — что из себя представляет, зачем нужна бизнесу и какие открывает перспективы профессии

Мария Иванина, ex-Senior Data Scientist в EPAM (в настоящее время — Software инженер в Google) детально отвечает на вопрос, что такое Data Science и правда ли, что за профессией Data Scientist, — будущее. Спойлер: правда!
Что такое Data Science?
— Data Science — это наука о данных, с помощью которой специалисты изучают данные в разных их проявлениях, находят инсайты и закономерности, моделируют процессы. При этом используют алгоритмы машинного обучения для создания предсказательных моделей. Они в свою очередь применяются уже на новых данных, — поясняет Мария. — Сегодня каждое наше действие в сети (написание сообщения в мессенджере, просмотр видео, заказ в интернете и т. п.) — это данные, которые могут использоваться специалистами для понимания пользовательского поведения и улучшения рекомендательных систем. Цель сбора таких данных — помогать юзерам найти то, что им нужно, намного быстрее. Когда вы говорите «Hey, Google» своему голосовому помощнику на телефоне и просите уточнить прогноз погоды на сегодня, запускается множество моделей: распознавание речи, алгоритмы понимания текстовой информации, собственно поиск ответа на вопрос, генерация этого ответа и ряд других подзадач. И да, даже прогноз погоды моделируется с помощью машинного обучения.
Почему Data Science важен для бизнеса?
— При помощи Data Science можно лучше понимать своих клиентов, выстраивать стратегию развития и быстрее улучшать свой продукт. Раньше бизнесу было сложно собирать обратную связь от своих клиентов. Нужно было экспериментировать почти вслепую, опираясь на опросы клиентов и их комментарии. Сейчас за счет мониторинга взаимодействия пользователей многие бизнесы могут быстрее понять, какие функции чаще используются, какие реже, нравится им взаимодействовать с интерфейсом или нет, когда стоит вводить промо акции, подсчитывать свои показатели и прогнозировать рост на будущее и т.п.
В каких отраслях используется Data Science сегодня?
IT-сферы
Поисковые системы, организация рабочих процессов на основе чат-ботов и голосовых помощников.
Страхование
Расчет вероятности несчастного случая и оценка потенциального риска для каждого клиента.
E-commerce
Рекомендательные системы для поиска нужной продукции, расчеты закупок продуктов, проведение маркетинговых кампаний, предсказание оттока покупателей.
Медицина
Прогнозирование заболеваний и рекомендации по сохранению здоровья.
Транспорт и логистика
Оптимизация маршрутов доставки, расчет времени ожидания привоза продуктов и даже внедрение беспилотных автомобилей.
Реклама
Автоматизированное размещение контента и таргетирование.
Финансы
Скоринг клиента для принятия решения о выдаче кредита, обнаружение и предотвращение мошенничества, микротрейдинг.
Недвижимость
Поиск и предложение наиболее подходящих покупателю объектов.
Спорт
Отслеживание показателей здоровья для персонализированных тренировок, отбор перспективных игроков, разработка стратегий игры.
Как крупные компании сегодня используют Data Science
Data Science внедряют в компаниях, чтобы использовать возможности аналитики для оптимизаций процессов в бизнесе. Подключать Data Science специалистов стараются как можно раньше, чтобы продумать стратегию: какие данные собирать, как организовать получение фидбэка от пользователя через действия. Однако порой и просто данные о продукте и продажах могут стать отправной точкой для анализа — в этом случае можно накопить побольше данных, чтобы специалисту было с чем работать. Чем больше собранных данных, которые релевантны задаче, тем лучше: анализ будет лучше описывать реальную картину мира, к тому же можно будет использовать более мощные модели алгоритмов для их обработки. Многие крупные IT-компании, такие как Google, Amazon, Meta, Microsoft, собирают терабайты-петабайты данных: это позволяет тренировать и использовать модели, которые можно назвать state of the art в области машинного обучения. Но благодаря тому, что некоторые модели они выпускают в open source, менее крупные компании могут их использовать для своих нужд за счет transfer learning и тренировать модели, для которых уже можно иметь меньше данных на старте.
Кто такие специалисты по Data Science?
Data Scientist – это разработчик-аналитик с хорошим математическим и алгоритмическим бэкграундом, который сначала разбирается с тем, какая проблема у бизнеса и как ее можно формализовать, анализирует данные. Отличие от аналитика данных в том, что специалист производит не только анализ, подготавливает отчеты и описывает то, о чем уже говорят данные, но использует их для моделирования, чтобы в будущем можно было на основе модели делать предсказания. Разработчику программного обеспечения нужно реализовать какой-то функционал на основе требований заказчика: это могут быть определенные функции на веб-сайте, в мобильном приложении. Главное отличие Data Science от разработки – это степень неопределенности в результатах работы. Например, если есть задача – написать веб-сайт, то понятно, что это возможно сделать. Есть, конечно, много вопросов по назначению сайта, технологиям, фичам и т.п., но факт остается фактом, сделать это — вполне реально. А в Data Science, пока ты не исследовал данные, не понял до конца цели и задачи проекта, ты вообще не можешь сказать, возможно решить задачу заказчика или нет. Или может быть так, что заказчику необходима заданная точность модели, а с теми данными и алгоритмами, которые существуют, просто нереально добиться такого качества. И поэтому зачастую проект начинается с PoC (proof of concept) стадии, чтобы примерно понять, с какой задачей мы имеем дело и в каком направлении можно идти к ее решению. Но тем не менее много и моментов, пересекающихся со стандартным IT, когда уже нужно доставлять результаты моделей: продукционализировать модель путем создания веб-сервиса, например.
Быть или не быть: перспективы профессии Data Scientist

Data Science – это слияние нескольких компонентов знаний и умений: хорошие математические знания, навыки разработки программного обеспечения и экспертиза в бизнес-процессах или какой-то доменной области.
Хорошая математика
Необходима хорошая математическая база: это и теория вероятности, и статистика, и знания математического анализа и дифференцирования, методы оптимизации и еще много предметов, которые изучаются в высших учебных заведениях по математическому профилю. Многие студенты думают, зачем же они это изучают, ведь в разработке софта это практически не используется, но в Data Science эти знания как раз будут полезными и очень важными. Они помогут понимать, как правильно решать задачу, знать, почему в алгоритмах что-то не работает, проверять гипотезы и делать правильные выводы. К счастью, сейчас эти знания можно получить не только в университете: есть онлайн курсы, посвященные этим темам, на Coursera, Stepik, лекции школы анализа данных от Яндекс и другие.
Python
Основным языком программирования для Data Science является Python, поэтому нужны хорошие знания в основах языка. Огромным плюсом будет углубленные знания, так как если ты будешь разбираться в некоторых фишках языка, сможешь более эффективно и оптимизировано писать решения задач. Не только Pythonединым: есть место и для R, и Julia, да и в принципе на других языках программирования тоже существуют библиотеки машинного обучения, которыми можно пользоваться. Отличным плюсом будут знания в паттернах программирования, понимание, как писать чистый и оптимизированный код, владение CI/CD. Сейчас еще популярно использование облачных технологий, так что умение работать с каким-то из облачным сервисом (Microsoft Azure, AWS, GCP) будет тоже очень здорово.
Бизнес-процессы
И наконец, последняя составляющая, но не менее важная. Понимание бизнес-процессов и бизнес-задачпоможет общаться с заказчиком на его языке и быстрее разбираться с тем, какую проблему он хочет решить, для чего ему это нужно, как измерить успех для бизнеса и донести идею своего решения. Такому уже, к сожалению, не учат в университете для программиста и математика, и скорее всего нужно читать дополнительную литературу. Одна из лучших книг для тех, кто хочет начать изучение дата сайнс с нуля и даже продолжающих — “Data Science for Business” Tom Fawcett, там разбираются некоторые примеры задач и как к ним подступиться, какие вопросы можно задать заказчику и какие могут быть идеи решения. Это хорошая отправная точка, но понятно, что лучше всего этот компонент Data Science работы приходит с опытом и разнообразием проектов, в которых удастся поучаствовать.
Английский язык
А чтобы понимать, какую проблему хочет решить заказчик, нужно общаться с ним, и в большинстве случаев клиент будет иностранцем. Поэтому просто необходимо хорошее владение английским языком, ведь чем лучше вы будете общаться и понимать друг друга, тем выше будет доверие клиента к вам и тем быстрее вы определите фронт работ.
Софт-скиллы
Еще один навык из софт-скиллов, который пригодится Data Science специалисту— основы презентационных скиллов. Data Scientist часто нужно выступать с презентациями: показывать предполагаемые решения заказчику, убедить в каких-то изменениях, поделиться с коллегами наработками на конференции или митапе. Да и вообще развитие любых софт-скиллов будет очень большим преимуществом.
Основные инструменты по работе с данными
Big Data
- HDFS — распределенная файловая система;
- MapReduce — модель распределенных вычислений, которая используется для параллельных вычислений — когда нужно преобразовать задачи в задания. Одна из задач — представить данные в виде ключа – значение (операция Map, другая — сделать какие-то агрегационные действия, такие как суммирование, взятие максимума, расчет каких-то показателей или другие более сложные операции (операция Reduce);
- YARN — технология для управления кластерами;
- Различные библиотеки для работы остальных модулей с HDFS;
- Apache Spark основан на Hadoop, но представляет собой улучшение над концепцией MapReduce. В этой технологии распределенные вычисления происходят в оперативной памяти, что увеличивает скорость обработки.
Machine Learning (Машинное обучение)
Для работы с данными Data Scientist чаще всего использует Python, поэтому можно рассмотреть несколько библиотек, которые чаще всего используются в каждодневных задачах:
- Numpy применяется для манипуляций с массивами данных, на его базе был построен Pandas — библиотека, которая помогает работать с данными в табличном виде.
- Scipy – библиотека для математических, научных, инженерных вычислений, есть алгоритмы интегрирования, дифференцирования и методов оптимизации.
- Matplotlib — самая популярная библиотека для визуализирования. На его основе была создана библиотека seaborn — она предоставляет более красивые графики и с упрощенным синтаксисом.
- Plot.ly – библиотека для создания интерактивных и готовых к публикации графиков.
- Scikit-learn собрал в себе все методы классического машинного обучения, а также удобные утилиты для предобработки данных.
Deep Learning (Обучение на основе нейронных сетей)
Обучение нейронных сетей чаще всего происходит с помощью Tensorflow или Pytorch. Tensorflow, возможно, более сложный фреймворк для старта, есть много понятий, с которыми нужно разобраться, но есть и плюсы: большое сообщество разработчиков, удобный инструмент для визуализации тренировки данных, много примеров для того, чтобы решать задачи.
Pytorch еще достаточно молодой, но развивающийся. Еще уступает в популярности Tensorflow, но быстро нагоняет его за счет академической среды, так как на Pytorch можно быстрее начать эксперименты. Зато Tensorflow более оптимизирован для удобного вывода в продакшн, мониторинга обучения, что, несомненно, влияет на выбор технологий для крупных проектов.
Artificial Intelligence (Искусственный интеллект)
Artificial intelligence — это широкое понятие, которое описывает систему, которая способна имитировать человеческое поведение для выполнения определенных задач и может постепенно обучаться, используя полученную информацию. Это же понятие в себя включает machine learning и deep learning.
Data Mining (Сбор и интеллектуальный анализ данных)
Интеллектуальный анализ данных можно производить и с помощью Python библиотек, описанных выше, однако существуют целые продукты, которые позволяют загрузить данные, анализировать и исследовать их из удобного графического юзер интерфейса, создавать графики и дашборды для интерактивного использования, например, такие системы, как SAS Data Mining, RapidMiner, Knime, Qlik и т.п.
Выводы
Data Science простыми словами — это работа с данными и моделирование решений задач с помощью их. С ростом количества данных специалисты Data Science становятся все более востребованными, поэтому открывается множество вакансий, связанных с такими задачами. Некоторые специалисты из разработки, аналитики и даже не из IT сферы переходят в данную область. Порог входа в нее может быть, конечно, более высоким из-за перечисленных выше особенностей и необходимых знаний, но тем не менее научиться этому можно, особенно сейчас, в век развития онлайн обучения.
Подробнее о Data Science можно узнать в выпуске АйТиБорода Shorts на YouTube-канале Anywhere Club