«У Вас нет адреса динамической аутентификации!» При оплате интернета. Помогите!
Юля Новик, эта штука находится вот тут 

Остальные ответы
Аутентификацию динамичную поставь
макс максЗнаток (377) 7 лет назад
А как это сделать?
dima Знаток (317) Руками
Карта какого банка у вас?
макс максЗнаток (377) 7 лет назад
Банк Санкт-Петербург
Телефон банка — на карте. Звоните и спрашивайте.
Была такая же проблема с ПриватБанком.. В ходе долгих звонков, один сотрудник посоветовал отправить скриншот ( о том, что вы ждете пароль с определенного сайта )в службу онлайн поддержки (написать СМС сотруднику банка он-лайн и отправить фото) .После, СМС с паролем пришла через 1мин ..Также проверьте лимит на покупку в интернете, подключена ли у вас услуга СМС оповещения, перезагрузите телефон, всем успехов ..
Похожие вопросы
Динамическая аутентификация пользователя в системе управления обучением
Аннотация: Объектом исследования является механизм динамической аутентификации по клавиатурному почерку. Автором подробно рассматривается усиленная аутентификации пользователей в системе управления обучением, поскольку электронное обучение постепенно занимает все большую нишу в образовательной среде. Целью работы является построение системы динамической аутентификации и ее верификация. Особое внимание уделяется анализу биометрических методов аутентификации, построению архитектуры требуемой системы, алгоритму классификации пользователей на основе параметрического обучения классификатора, а также результатам тестирования полученной системы. Автором был проведен анализ существующих методов и алгоритмов в области динамической аутентификации и предложено альтернативное решение. Основными результатами проведенного исследования являются архитектура механизма аутентификации пользователей в системе управления обучением; описание алгоритма разделения пользователей на два класса. В соответствии с полученными требованиями к системе, был реализован данный механизм на практике и проведено его тестирование, продемонстрировавшее достижение необходимого результата по ошибкам первого и второго рода. Предложенный механизм аутентификации по клавиатурному почерку может использоваться не только в системах управления обучением, но и в других системах, со схожей моделью нарушителя.
Ключевые слова:
динамическая аутентификация, безопасность, клавиатурный почерк, биометрическая аутентификация, усиленная аутентификация, система управления обучением, биометрия, параметрический классификатор, конфиденциальность, поведенческая аутентификация
Abstract: The object of the research is the mechanism of dynamic authentification via keystroke dynamics. The author examines reinforced authentification of users in Learning Management Systems whereas e-learning gradually occupying a niche in the education environment. The purpose of the present research is to develop and verify the system of dynamic authentification. Special attention is paid to analyzing biometric authentification and developing architectures of the required system and algorithm for classifying users based on the classifier’s parameter learning as well as testing results. The author of the article carried out analysis of methods and algorithms that are used in the field of dynamic authentification and offers his alternative solution of the problem. The main results of the research include: architecture of the user authentification mechanism in Learning Management Systems; and description of the algorithm for dividing users into two classes. In accordance with the obtained requirements for the system, the author implemented the aforesaid mechanism in practice and conducted testing of the mechanism. The test shows that the desired result was obtained for the first- and second-order errors. The mechanism of keystroke dynamic authentification can be used not only in Learning Management Systems but also in other systems similar to the violator’s model.
dynamic authentication, security, keystroke dynamics, biometric authentication, strong authentication, Learning Management System, biometrics, parametric classifier, confidentiality, behavioral authentication
Системы управления обучением представляют собой программное обеспечение по организации дистанционного обучения. Включают в себя такие элементы, как набор учебных материалов, организационные компоненты, позволяющие автоматизировать процесс создания курсов и проверки знаний обучающимися. Основной задачей таких систем является систематизация учебных программ и методик оценивания для повышения эффективности обучения и удобства контроля успеваемости.
Система управления обучением позволяет выполнять как индивидуальные задания, так и работать в группах, соответственно направленность получаемых компетенций не ограничивается содержательным компонентом, а может включать в себя и коммуникационный. Существует возможность обучения как в режиме реального времени, при помощи вебинаров и других инструментов, так и в собственном ритме, определяемым обучающимся самостоятельно, в зависимости от его возможности и наличия свободного времени. Обучающийся выбирает некоторый курс и, в соответствии с заданной программой направления, изучает лекционный материал, выполняет задания и проходит проверку знаний.
Одной из главных частей обучения является оценка знаний и компетенций обучающегося. Система предоставляет широкий функционал для различных методик проверки знаний.
По окончании определенного курса в данной системе может выдаваться сертификат: или о том, что обучающийся его прослушал, или он подтверждает некую компетенцию этим сертификатом. Во втором случае сертификационный центр выступает посредником между обучающимся и заказчиком соответствующих навыков и умений. Соответственно, центр несет ответственность за компетенции человека, получившего сертификат. Поэтому помимо оценки приобретенных знаний, необходимо удостовериться в личности человека, проходящего итоговую проверку знаний. Многие значимые курсы, к примеру на инженера Cisco, требуют личного присутствия при проверке компетенций для выдачи подтверждающего документа. Зачастую это не совсем удобно. Значит при прохождении итогового теста в дистанционной системе возникает необходимо, чтобы его проходил именно тот пользователь, который был зарегистрирован в системе. Отсюда возникает проблема аутентификации пользователя в системе управления обучением.
Также, одним из важных свойств системы управления обучением является масштабируемость и доступность для обучающегося. Поэтому проблему аутентификации необходимо решить, не привлекая дополнительного специфического оборудования, такого как сканер сетчатки глаза, со стороны обучающегося.
Типы аутентификации
На основе индивидуальной информации, характеризующей определенного пользователя, в системе защиты происходит аутентификация. Можно выделить несколько типов аутентификации, основывающихся на различных видах данной информации, применяющихся на сегодняшний день: парольная, имущественная и биометрическая. Наиболее распространенными являются методы, основывающиеся на предъявлении уникальной информации, заведомо известной конкретному пользователю — так называемая парольная система аутентификации.
У таких систем существует значительный недостаток. При утрате конфиденциальности пароля, нарушитель может получить доступ ко всей системе. Однако у данного метода существуют и свои преимущества, такие как простота в реализации и удобство в использовании.
Биометрические системы аутентификации можно поделить на две группы:
— анализирующие статический образ пользователя(в том числе сетчатка глаза, отпечатки пальцев);
— анализирующие динамические образы, относящиеся к поведению пользователя, такие как произношение речи, рукописный и клавиатурный почерк.
В тех случаях, когда сам пользователь заинтересован в нарушении правил безопасности, все данные типы аутентификации, кроме биометрической поведенческой неэффективны, поскольку для получения прав для совершения действий в системе нарушителю достаточно знания ключевой информации или владения переданным аутентификаторам.
В случае применения поведенческой аутентификации сам пользователь не владеет информацией о необходимом аутентификаторе, поскольку тот является изменяемым компонентом.
Архитектура
На этапе обучения программы пользователь выполняет различные действия в системе Moodle. Происходит сбор информации о пользователе, на основании которой рассчитываются и запоминаются эталонные характеристики данного пользователя.
Эталонные характеристики пользователя, полученные на этапе обучения системы, позволяют сделать выводы о степени стабильности клавиатурного почерка пользователя и определить доверительный интервал разброса параметров для последующей аутентификации пользователя.
На этапе аутентификации рассчитанные оценки сравниваются с эталонными, на основании чего делается вывод о совпадении или несовпадении параметров клавиатурного почерка. Вследствие чего принимается решение об аутентичности пользователя.
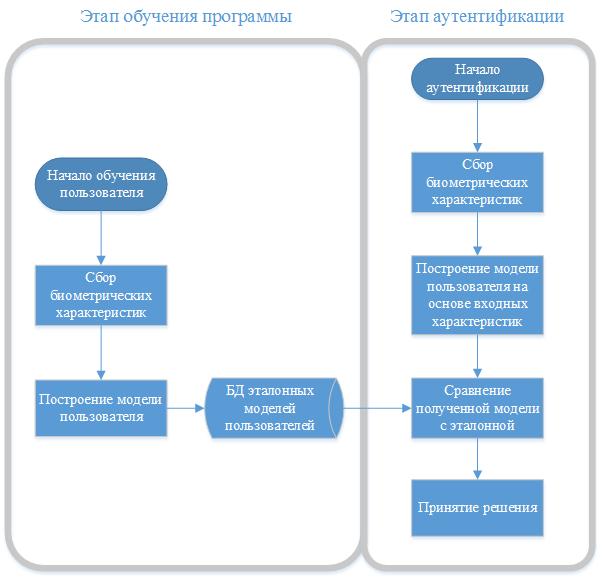
Рисунок 1 — временная линия прохождения курса пользователем
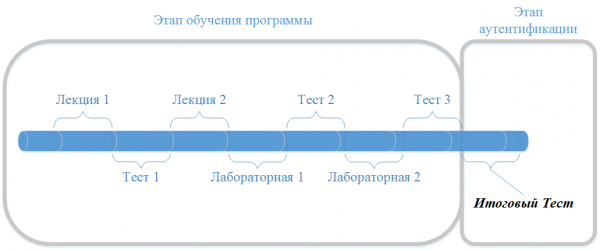
Рисунок 2 — система динамической аутентификации
Сложность динамической аутентификации
В динамических системах аутентификации, использующих в качестве входных данных клавиатурный или рукописный почерк, набор характеристик пользователя представляется в виде вектора V биометрических параметров в ортогональной системе координат. Компоненты данного вектора определяются путем измерения соответствующих характеристик. Между компонентами вектора имеется корреляция. [1]
Сложность решения задачи динамической аутентификации определяется сложностью моделирования движений человека. Формально это может быть представлено в виде модели со множеством входом и тремя выходами, где входами являются мышцы человека, при помощи которых он выполняет определенные действия.
Сложность задачи можно оценить по количеству ее входов, соответственно, по количеству мышц, вовлеченных в определенный тип движений. При письме рукой у человека задействуются около 50 мышц одной руки: мышцы пальцев, кисти и предплечья. Однако в таком случает основную роль играют всего примерно 10 мышц. Соответственно, получаем минимум десятимерную задачу управления движениями.
При печати двумя руками в работу включаются мышцы плечевого пояса и второй руки. В итоге оказывается задействованы порядка 140 мышц. Если взять за основу то, что наибольшее влияние оказывают порядка 20% мышц, то получаем задачу с количеством входов равным 28 или двадцати восьми мерную задачу управления.
Для сравнения, в произношении речи задействованы мышцы груди, живота, брюшой полости, лицевые и челюстные мышцы, мышцы речевого аппарата. В сумме количество вовлеченных мышц около 110, значит задача воспроизведения речи является двадцати двух мерной. [2]
Важным моментом является то, что в вышеперечисленных моделях управления задача является многомерной, а также количество входов значительно превышает количество выходов.
Поскольку в основе управления движениями руки лежат одинаковые принципы, а задача классификации пользователя по клавиатурному почерку оказывается сравнима по сложности с рукописной, можно сделать вывод об уникальности клавиатурного почерка. Соответственно применение методов динамической аутентификации по клавиатурному почерку является оправданным и эффективным.
Характеристики клавиатурного почерка
При аутентификации по клавиатурному почерку собирается полная информация о действиях пользователя в системе. Далее нам необходимо выделить основные признаки, характеризующие поведение пользователя. В дальнейшем эти признаки, подвергаясь обработке, позволяют получить ряд эталонных характеристик пользователя.
Основные признаки, используемые в полученной модели
— Динамика ввода — время удержания клавиш и время между нажатиями клавиш;
— Скорость ввода — количество нажатий клавиш за единицу времени;
— Использование функциональных клавиш;
— Частота ошибок ввода.
Алгоритм классификации пользователей
Для работы соответствующей системы динамической аутентификации авторизованный пользователь должен пройти этап обучения, в процессе которого L раз в различные моменты времени считываются его биометрические параметры. Эти L векторов V=V1, V2, … VL> соответствуют L подписям пользователя и состоят из N компонентов.
Распределение векторов Vi, состоящих из N параметров в данном случае является схожим с нормальным [3] . Соответственно, векторы биометрических параметров Vi представимы в виде функции плотности нормального распределения Vi, при L→ ∞ в ортогональной системе координат представляет собой гиперэллипсоид рассеивания. Между компонентами векторов Vi, i =1..L имеется корреляция. Значит, построив формулу данного гиперэллипсоида, задача аутентификации будет представлять собой определение принадлежности предъявляемого вектора в область пространства, отделяемую представленной гиперповерхностью [4] .
Значит для параметрического обучения классификатора необходимо выполнить следующие действия:
— Определить зависимость дискриминантных функций g(V) от коэффициентов сдвига и масштаба функции плотности распределения;
— На основе обучающей выборки векторов Vi произвести оценку значений данных параметров;
— Сделать предположение об истинности указанных оценок значений параметров и выполнить подстановку в представленную на начальном этапе дискриминантную функцию g(V).
Поскольку при аутентификации нам необходимо разделить пользователей только на два класса — «свой» и «чужой», классификацию можно выполнить при помощи единственной дискриминантной функции g(V). Знак данной функции будет отвечать за вхождение предъявленного вектора V в соответствующий класс.
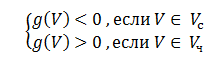
Соответствующая дискриминантная функция задается формулой:
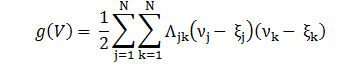
Результаты тестирования
Для тестирования данного приложения в системе аутентификации было зарегистрировано 31 пользователей, которых можно условно разделить на четыре группы по количеству пройденных курсов в системе управления обучением. Итоговый тест по каждому курсу было предложено пройти 3 раза. Первая группа состоит из 16 человек, которые проходили только один курс. Вероятность ошибки первого рода для этой группы составила 14,5%, а второго 6,2%. Вторая состоит из 7 человек, проходивших два курса. Вероятность ошибки первого рода для них составила 14,2%, а второго 5,9%. Третья группа состоит из 5 человек, проходивших три курса. Вероятность ошибки первого рода для этой группы составила 12,4%, а второго 5,1%. И четвертая группа состоит из 3 человек, прошедших пять курсов. Вероятность ошибки первого рода для них составила 12,1%, а второго 4,9%.
Количество пройденных курсов
Количество человек в группе
В ероятность ошибки первого рода
В ероятность ошибки второго рода
ДИНАМИЧЕСКАЯ АУТЕНТИФИКАЦИЯ ПОЛЬЗОВАТЕЛЕЙ НА ОСНОВЕ АНАЛИЗА РАБОТЫ С КОМПЬЮТЕРНОЙ МЫШЬЮ Текст научной статьи по специальности «Компьютерные и информационные науки»
ДИНАМИЧЕСКАЯ АУТЕНТИФИКАЦИЯ / БИОМЕТРИЯ / ОДНОКЛАССОВАЯ КЛАССИФИКАЦИЯ / ГРАДИЕНТНЫЙ БУСТИНГ / ДИНАМИЧЕСКОЕ УДАЛЕНИЕ ЛОКАЛЬНЫХ ВЫБРОСОВ / ОДНОКЛАССОВЫЙ МЕТОД ОПОРНЫХ ВЕКТОРОВ / НЕЙРОННЫЕ СЕТИ / ДИНАМИЧЕСКОЕ ИЗМЕНЕНИЕ УРОВНЯ ДОВЕРИЯ
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Березникер А.В., Казачук М.А., Машечкин И.В., Петровский М.И., Попов И.С.
Целью данной работы является исследование существующих и разработка собственных алгоритмов динамической аутентификации пользователей на основе анализа работы с компьютерной мышью, показывающих высокое качество работы и способных работать в динамическом режиме. В работе рассматриваются существующие способы построения и предобработки признакового пространства, а также методы динамической аутентификации , основанные на использовании классических методов машинного обучения и нейронных сетях . Для наиболее перспективных методов предлагаются модификации, обладающие более высокой эффективностью. На основе предложенного метода, демонстрирующего наилучшее качество работы, было разработано и реализовано кроссплатформенное приложение для динамической аутентификации пользователей на основе анализа работы с компьютерной мышью. Данная система и ее отдельные модули могут послужить основой для построения перспективных систем информационной безопасности. Были проведены экспериментальные исследования, подтвердившие достоверность полученных результатов и корректность работы системы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Березникер А.В., Казачук М.А., Машечкин И.В., Петровский М.И., Попов И.С.
МЕТОДЫ ПОИСКА ИСКЛЮЧЕНИЙ В ПОТОКАХ СЛОЖНОСТРУКТУРИРОВАННЫХ ДАННЫХ
Метод обнаружения вирусов-шифровальщиков в компьютерной системе на основе анализа их поведенческих признаков
К вопросу о реализации алгоритмов выявления внутренних угроз с применением машинного обучения
СРАВНИТЕЛЬНЫЙ АНАЛИЗ ИНСТРУМЕНТОВ НЕПРЕРЫВНОЙ ОНЛАЙН-АУТЕНТИФИКАЦИИ И СИСТЕМ ОБНАРУЖЕНИЯ АНОМАЛИЙ ДЛЯ ПОСТОЯННОГО ПОДТВЕРЖДЕНИЯ ЛИЧНОСТИ ПОЛЬЗОВАТЕЛЯ
ИССЛЕДОВАНИЕ ЭФФЕКТИВНОСТИ РАБОТЫ СИАМСКИХ НЕЙРОННЫХ СЕТЕЙ ДЛЯ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ ПО ЭКГ ДЛЯ СИГНАЛОВ С НЕПЕРИОДИЧЕСКИМИ НАРУШЕНИЯМИ СЕРДЕЧНОГО РИТМА
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
USER BEHAVIOR AUTHENTICATION BASED ON COMPUTER MOUSE DYNAMICS
This work is devoted to explore existing and develop new algorithms for user behavior authentication based on computer mouse dynamics, which show high quality of work and capablility of working in dynamic mode. The paper considers the existing methods of building and preprocessing the feature space and methods of dynamic authentication based on classical machine learning methods and neural networks. For the most perspective methods, modifications with higher efficiency are proposed. Based on the proposed method, which demonstrates the best quality of work, a cross-platform application for dynamic user authentication based on computer mouse dynamics was developed and implemented. This system and its separate modules can be used as a base for building perspective information security systems. Experimental studies confirmed the reliability of the obtained results and the correctness of the developed system.
Текст научной работы на тему «ДИНАМИЧЕСКАЯ АУТЕНТИФИКАЦИЯ ПОЛЬЗОВАТЕЛЕЙ НА ОСНОВЕ АНАЛИЗА РАБОТЫ С КОМПЬЮТЕРНОЙ МЫШЬЮ»
А. В. Березникер1, М. А. Казачук2 , И. В. Машечкин3 , М. И. Петровский4 , И. С. Попов5
ДИНАМИЧЕСКАЯ АУТЕНТИФИКАЦИЯ ПОЛЬЗОВАТЕЛЕЙ НА ОСНОВЕ АНАЛИЗА РАБОТЫ С КОМПЬЮТЕРНОЙ МЫШЬЮ
Целью данной работы является исследование существующих и разработка собственных алгоритмов динамической аутентификации пользователей на основе анализа работы с компьютерной мышью, показывающих высокое качество работы и способных работать в динамическом режиме. В работе рассматриваются существующие способы построения и предобработки признакового пространства, а также методы динамической аутентификации, основанные на использовании классических методов машинного обучения и нейронных сетях. Для наиболее перспективных методов предлагаются модификации, обладающие более высокой эффективностью. На основе предложенного метода, демонстрирующего наилучшее качество работы, было разработано и реализовано кроссплатформенное приложение для динамической аутентификации пользователей на основе анализа работы с компьютерной мышью. Данная система и ее отдельные модули могут послужить основой для построения перспективных систем информационной безопасности. Выли проведены экспериментальные исследования, подтвердившие достоверность полученных результатов и корректность работы системы.
Ключевые слова: динамическая аутентификация, биометрия, одноклассовая классификация, градиентный бустинг, динамическое удаление локальных выбросов, одноклассовый метод опорных векторов, нейронные сети, динамическое изменение уровня доверия.
1. Введение. В настоящее время неотъемлемой частью различных сфер деятельности человека стало использование информационных систем. Огромное количество информации ограниченного доступа переносится, хранится и обрабатывается в информационных системах, что формирует потребность в обеспечении их надежной защиты.
Люди используют механизмы контроля доступа, такие как пароль, магнитные карты или биометрию для защиты от несанкционированного доступа другого человека. Это означает, что пользователь должен предоставить подтверждение своей личности при запуске или разблокировке системы. Контроль доступа к персональному компьютеру обычно реализуется как единора-зовое подтверждение личности во время первичной авторизации. Авторизация — это процедура предоставления субъекту определенных прав доступа к ресурсам системы после успешного прохождения им процедуры аутентификации. Предполагается, что в течение всего сеанса в системе будет находиться только авторизованный (легитимный) пользователь. Однако во многих случаях люди оставляют компьютер без присмотра, временно покидая свое рабочее место, и любой человек может получить доступ к тем же источникам данных с теми же правами, что и легитимный пользователь.
Защита информации в информационных системах обеспечивается созданием комплексной системы защиты, одной из главных составляющих которой являются методы защиты от несанкционированного доступа [1,2]. Основой программно-технических средств защиты от несанкционированного доступа являются процедуры идентификации и аутентификации пользователей. Идентификатором в таком случае служит уникальный признак объекта, позволяющий отличить его от других объектов. А под процедурой аутентификации подразумевается процесс проверки принадлежности субъекту доступа предъявленного им идентификатора. Используемые в существующих
1 Факультет ВМК МГУ, студ., e-mail: bereznikerQmail.ru
2 Факультет ВМК МГУ, асс., к.ф.-м.н., e-mail: mkazachukQcs.msu.ru
3 Факультет ВМК МГУ, проф., д.ф.-м.н., e-mail: mashQcs.msu.su
4 Факультет ВМК МГУ, доц., к.ф.-м.н., e-mail: michaelQcs.msu.su
5 Факультет ВМК МГУ, м.н.с., e-mail: ivanQjaffar.cs.msu.su
системах идентификаторы — секретные знания (пароль, ключ и т.д.), а также физические объекты, принадлежащие пользователям (флеш-накопитель, магнитная карта и т.д.), могут быть с легкостью украдены или скомпрометированы. Поэтому на смену им приходят системы аутентификации, использующие биометрические данные пользователей — уникальные биологические и физиологические характеристики, позволяющие установить личность человека. В отличие от рассмотренных ранее идентификаторов, биометрические образцы невозможно забыть или потерять и намного тяжелее скомпрометировать.
Существующие в настоящее время методы биометрической аутентификации могут быть основаны на физиологических характеристиках человека, находящихся при нем в течение всей его жизни, или поведенческих характеристиках человека, являющихся характеристиками поведения индивидуума и отличающихся относительной устойчивостью и постоянством проявления. Основным недостатком методов проверки пользователей, основанных на физиологической биометрии, является то, что они требуют наличия аппаратных устройств, таких как датчики отпечатков пальцев, сканеры сетчатки глаза и другие, которые дороги и не всегда доступны. Хотя проверка отпечатков пальцев становится широко распространенной в ноутбуках и смартфонах, она все еще недостаточно популярна и не может быть использована в веб-приложениях. Кроме того, отпечатки пальцев могут быть скопированы. В свою очередь, методы, основанные на поведенческой биометрии, не требуют специального оборудования, так как они используют обычные устройства ввода для сбора биометрических данных, такие как мышь и клавиатура.
В зависимости от принципа осуществления процедуры проверки идентификатора, выделяют статическую (эпизодическая проверка идентификатора пользователя) и динамическую (личность пользователя проверяется постоянно на протяжении всей сессии работы за компьютером) аутентификацию. Очевидно, динамическая аутентификация пользователей является предпочтительней, так как она исключает сценарии, при которых злоумышленник получает доступ к информационной системе после того, как легитимный пользователь пройдет процедуру аутентификации. Однако данный подход затрачивает больше ресурсов компьютера за счет непрерывной работы.
Таким образом, мы видим проблемы отсутствия контроля факта смены пользователя и компрометации идентификаторов, которые мы предлагаем решить использованием биометрических поведенческих характеристик пользователя для динамической аутентификации. В настоящее время динамическая аутентификация пользователей на основе анализа работы с компьютерной мышью является актуальным направлением исследований в сфере компьютерной безопасности. Достоинство данного подхода заключается в простоте внедрения: нужно лишь устройство ввода (компьютерная мышь) и специальное программное обеспечение, позволяющее проводить анализ. Однако существующие в данной области решения обладают рядом недостатков — в частности, контролируемым сбором данных, использованием бинарных классификаторов и переобучением на исходных наборах данных. В свою очередь, мы фокусируемся на независимой от контекста системе динамической аутентификации, которая реагирует на каждое отдельное действие, выполненное пользователем.
Настоящая статья имеет следующую структуру. В п. 2 приведен обзор существующих решений по данной тематике. Пункт 3 посвящен предлагаемым подходам по построению признакового пространства. В п. 4 приведено описание предлагаемых методов построения модели пользователя. Пункт 5 посвящен экспериментальному исследованию работы предложенных методов. В п. 6 описывается архитектура разработанного кроссплатформенного приложения динамической аутентификации пользователей. В п. 7 делаются выводы по предложенным алгоритмам.
2. Обзор существующих решений. Различные подходы к сбору экспериментальных данных в литературе отличаются количеством пользователей, принявших участие в исследовании, методами сбора и размерами собранных в итоге данных. Однако наиболее важным различием являются условия, в которых эти данные были собраны. Так, среда сбора данных может быть контролируемой (пользователь выполняет строго поставленные задачи: например, кликает на появляющиеся на экране объекты или работает только с текстовым форматом данных) или неконтролируемой (пользователь работает в привычной для него обстановке и выполняет повседневные
для своей деятельности задачи). Сбор экспериментальных данных в контролируемой обстановке с конкретно поставленной перед пользователем задачей, возможно даже на конкретном компьютере, имеет серьезные недостатки. В этом случае пользователь будет больше сосредоточен на выполнении задачи, и его поведение не будет соответствовать его нормальному состоянию. По этой причине результаты экспериментов в контролируемой среде нельзя обобщить на реальную обстановку. Однако в большинстве существующих работ по данной тематике рассматривается только контролируемый сбор данных.
Наиболее часто используемыми в научных работах признаками, характеризующими особенности траектории движения мыши, являются кинематические характеристики (перемещение, длина траектории, скорость, ускорение), направление движения, а также кривизна траектории перемещения. Данные признаки рассчитываются по следующим собираемым характеристикам: тип действия (нажатие/отжатие клавиш, движение мыши), состояние кнопок мыши, координаты курсора, временная метка. В качестве метода предобработки признакового пространства зачастую используют нормализацию [3]:
где Еж — математическое ожидание наблюдения, Вх — его дисперсия.
Сводная информация по качеству работы существующих решений, рассматривающих работу пользователей в неконтролируемой среде, представлена в табл. 1, где N — число пользователей, принявших участие в эксперименте. Как видно из таблицы, в большинстве работ рассматривается бинарная классификация (обучение с учителем), однако в реальной ситуации зачастую может не быть примеров данных нелегитимного класса, поэтому необходимо использовать алгоритмы одноклассовой классификации. Наилучшее качество распознавания в существующих работах показывают одноклассовая машина опорных векторов и нейронные сети типа автокодировщика.
Качество работы существующих решений
Работа N Набор данных Модель Обучение без учителя ROC AUC
f3] 10 ВАЬАВГГ Linear SVC X 0.81
f4] 28 Неизвестно SVM X 0.85
[5,6] 14 ВАЬАВГГ+ТЧУОБ 2D-CNN X 0.88
[7] 25 Неизвестно Autoencoder / 0.91
[8] 50 Неизвестно One-Class SVM / 0.93
3. Построение признакового пространства. В ходе предварительного анализа данных, характеризующих динамику работы пользователей с мышью, были обнаружены следующие особенности: полностью дублирующиеся записи, дубликаты временных меток, множественные дубликаты положения мыши (зацикливание), сверхбольшие значения координат.
Все данные особенности были устранены на этапе предобработки данных:
• дублирующиеся записи были удалены, так как они могли быть следствием сбоев в системе сбора данных на устройствах пользователей, что может привести к некорректному вычислению признаковых характеристик;
• дубликаты временных меток были заменены средним значением соседних меток для обхода ситуации деления на 0 в признаках, связанных со временем:
timestampji + timestamp,+1 timestampj =——
• множественные дубликаты положения мыши (фиксированные координаты курсора (x, y) при изменяющемся времени t) были оставлены, так как такая запись может обозначать паузу в работе пользователя и должна учитываться мод елью-классификатором;
• сверхбольшие значения координат были заменены значением верхней границы интеркван-тильного анализа. Интерквантильный размах (IQR) — это разность между 75 и 25 квантилем. Эмпирический метод заключается в том, что наблюдения, лежащие за пределами верхней и нижней границы, являются выбросами.
• скорость, ускорение, перемещение, длина траектории, а также их дискретизированные, минимальные, максимальные характеристики, среднее значение и стандартное отклонение;
• направление движения (всего рассматривалось восемь направлений);
• средняя кривизна траектории движения: — ¿^—, где F = (Xi,yi) —
координаты положения курсора;
• траектория центра масс: ТСМ = —- U+iy/(xi+\ — Xi)2 + (yi+i — Уг)2, где U — времен-
пая метка, Sn-i — длина пути;
• коэффициент рассеивания: SC = —- Y1 ~~ х%)2 + (Уг+i ~ Уг)2 — ТСМ2.
Для обработки признакового пространства нами было предложено использовать нормализацию и отбор наиболее важных признаков при помощи градиентного бустинга [10]. Обработка признаков путем One-Hot Encoding кодирования и дискретизации по квантилям [11] в данной работе не рассматривается, поскольку на предварительном этапе экспериментальных исследований использование данных методов не повысило качества распознавания.
Бустинг — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов. Представим функцию f классификации в виде композиции
T функций, так что каждая из последующих функций минимизирует остатки от предыдущей.
Тогда алгоритм градиентного бустинга может быть описан следующими этапами.
1. Построение исходной модели f (x).
2. В цикле от t = 1. T (по «глубине» композиции):
• построение регрессии ht по антиградиенту;
• модификация модели: f (x) ^ f (x) + pt ■ ht(x), где pt — градиентный шаг.
Преимущество использования ансамблей деревьев решений, таких как градиентный бустинг, заключается в том, что они могут предоставлять оценку важности признаков из обученной модели. Как правило, важность обеспечивает оценку, которая указывает, насколько полезным был каждый признак при построении деревьев решений в модели. Чем больше атрибут используется для принятия ключевых решений, тем выше его относительная важность. Важность рассчитывается для отдельного дерева решений, затем значения характеристик усредняются по всем деревьям решений в модели. Данный метод требует наличия размеченных данных. Поэтому он был использован только для снижения размерности и фильтрации признакового пространства на этапе проведения экспериментов.
4. Построение модели пользователя. Рассматриваемая в рамках данной работы задача относится к классу задач поиска аномалий в данных (обучение без учителя). Аномальным называется объект или событие в выборке, чьи признаки или их комбинации не соответствуют зависимостям, характерным для остальных объектов или событий в данной выборке. Для решения данной задачи нами были рассмотрены следующие алгоритмы одноклассовой классификации: одноклассовый метод опорных векторов (Support Vector Clustering, SVC), изоляционный лес (Isolation Forest), эллипсоидальная аппроксимация данных (Elliptic Envelope).
Поскольку сама обучающая выборка также может содержать в себе аномалии, мы предлагаем использовать технологию локального уровня выбросов (Local Outlier Factor, [12]) для предварительной очистки выборки от аномальных наблюдений. Данный метод обнаруживает выбросы (аномальные наблюдения) на основе локальной плотности точек, которые являются выбросами по отношению к их локальной окрестности, а не по отношению к глобальному распределению данных. Чем выше значение LOF для наблюдения, тем более аномальным оно является. Точка считается аномальной, если ее локальная плотность значительно отличается от плотности соседних точек. Локальный уровень выбросов LOF в точке Р определяется как:
LOF(P) = ^^ 1 (расстояние до со седей) • ^^ (локальная плотность соседей). (2)
Таким образом, LOF в точке Р может принимать:
• большое значение, если точка Р находится далеко от своих соседей и ее соседи имеют высокую локальную плотность (т.е. они близки к своим соседям);
• среднее значение, если Р находится далеко от своих соседей и ее соседи имеют малую локальную плотность;
• маленькое значение, если Р находится близко к своим соседям и ее соседи имеют малую локальную плотность.
Метапараметрами данного алгоритма являются n_neighbors — количество соседей, а также contamination — доля аномалий в выборке.
В методе SVC [8] объекты из исходного множества неявно отображаются с помощью потенциальной функции в пространство характеристик высокой размерности, где далее происходит поиск гиперсферы минимального радиуса, содержащей внутри «основную часть» образов объектов из исходного множества. Аномалиями считаются объекты, чей образ лежит за пределами найденной гиперсферы. Таким образом, в данном методе решается следующая задача оптимизации:
где ) — образ исходного объекта х^ в пространстве характеристик высокой размерности И, К — радиус построенной гиперсферы, а — центр гиперсферы, N — число объектов в обучающей выборке X, 0 < V ^ 1 — предопределенный процент аномалий, ^ — дополнительные переменные.
Настраиваемыми параметрами данного алгоритма являются kernel — тип потенциальной функции и v — отношение ожидаемого числа аномалий к общему числу объектов рассматриваемой выборки.
Отметим, что другой разновидностью одноклассового метода опорных векторов является метод One-Class SVM. Он строит в пространстве характеристик высокой размерности не гиперсферу, а гиперплоскость, отделяющую нормальные данные от аномальных. Заметим, что при использовании радиально-базисной потенциальной функции (rbf) результаты работы методов SVC и One-Class SVM идентичны.
Изоляционный лес [13], как и любой другой метод ансамбля деревьев, построен на основе деревьев решений. Алгоритм обучения строит ансамбль изоляционных деревьев на основе рекурсивной и рандомизированной процедуры структурированного разбиения: сначала случайным образом выбирается объект, а затем выбирается случайное значение между минимальным и максимальным значением выбранного объекта. Аномалий в данных немного и зачастую они находятся дальше от обычных наблюдений в пространстве признаков, поэтому при использовании такого случайного разбиения они должны быть идентифицированы ближе к корню дерева. В случае аномальных наблюдений необходимо меньше расщеплений. Для принятия решения об аномальности наблюдения данный алгоритм использует следующую функцию:
где E(h(x)) — средняя длина пути наблюдения x, c(n) — средняя длина пути неудачного поиска
Каждое наблюдение получает индекс аномальности, на основе которого принимается решение. Оценка, близкая к 1, указывает на аномальность наблюдения. Оценка, близкая к 0, указывает на нормальное поведение наблюдения. Данный алгоритм обладает следующими метапараметрами: n_estimators — число деревьев, max ^samples — объем выборки для построения одного дерева, contamination — доля аномалий в выборке. Он устойчив к проклятию размерности и обладает высокой эффективностью.
Эллипсоидальная аппроксимация данных [14] — ковариационная оценка, предполагающая, что данные имеют распределение Гаусса. Ограничивающий контур имеет эллиптическую форму. Для оценки размера и формы эллипса используется алгоритм FAST-Minimum Covariance Determinate. Данный алгоритм выбирает неперекрывающиеся подвыборки данных и вычисляет среднее значение у и ковариационную матрицу C в признаковом пространстве для каждой подвыборки. Расстояние Махаланобиса dMH вычисляется для каждого многомерного вектора x
dMH = ^(х- /л)тС(х- /л). (5)
сходимости определителя матрицы ковариации. Ковариационная матрица с наименьшим определителем из всех подвыборок образует эллипс, который охватывает часть исходных данных. Данные в пределах поверхности эллипса считаются нормальными, а вне эллипса — аномальны-
Однако, данный метод успешно работает только на нормально распределенных одномодальных данных.
Автокодировщик (Autoencoder) [7] — это нейронная сеть, которая восстанавливает входной сигнал на выходе. С математической точки зрения каждый нейрон в нейронной сети представляет собой параметризованную функцию (x1. ,xn,b), возвращающую единственное значе-
ние — величину выходного сигнала. Параметры шо. шт функции fUl. um (x1. xn, b) именуются синаптическими весами нейрона. Чаще всего для агрегации входов используется линейная
ром функции fu1. um(x1. ,xn,b). Агрегированное значение входов нейрона подается на вход функции активации нейрона, которая непосредственно вычисляет величину выходного сигнала.
Связанные между собой нейроны образуют нейронную сеть. В том случае, когда нейронная сеть состоит из большого количества нейронов, вводится также понятие слоя нейронной сети и все слои разделяются на три тина: входной слой, скрытый слой, выходной слой. Вектор входных значений, именуемый также вектором признаков, подается на входной слой нейронной сети и в результате работы последней на выходном слое появляется вектор выходных значений, называемый также предсказанием нейронной сети.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Автокодировщик состоит из двух частей: кодировщика (encoder), который кодирует данные в свое внутреннее представление, и декодировщика (decoder), который восстанавливает исходный вектор. Обычно автокодировщиков ограничивают в размерности скрытых слоев (они меньше, чем размерность сигнала на входе). Нами было предложено несколько архитектур нейронных сетей для решения поставленной задачи. Для борьбы с переобучением мы использовали ¿2-регуляризацию и Dropout-слои.
Процедура ¿2-регуляризацип выполняется посредством наложения штрафов на веса с наибольшими значениями, минимизируя их ¿2-норму с использованием коэффициента регуляризации А. Для каждого веса ш мы прибавляем к целевой функции L слагаемое:
А T А и и А ^ 2 tc\
Идея Dropout состоит в том, что вместо обучения одной нейронной сети мы обучим несколько и сделаем из них ансамбль с усреднением полученных результатов. Такие сети получаются с помощью исключения нейронов с вероятностью p. Исключение нейрона означает, что при любых входных данных он возвращает 0.
На рис. 1 представлена предложенная архитектура сети автокодировщика с семью скрытыми слоями. Перед каждым полносвязным слоем используется функция активации ELU (7):
ELU(x) = ( x’ x > 0 (7)
Сжатый вектор признаков
Современные методы биометрической идентификации
К современным методам аутентификации относится проверка подлинности на основе биометрических показателей. При биометрической аутентификации, секретными данными пользователя могут служить, как глазная сетчатка, так и отпечаток пальца. Эти биометрические образы являются уникальными для каждого пользователя, что обеспечивает высокий уровень защиты доступа к информации. Согласно предварительно установленным протоколам, биометрические образцы пользователя регистрируются в базе данных.

Современная биометрическая аутентификация основывается на двух методах:
- статический метод аутентификации — распознает физические параметры человека, которыми он обладает на протяжении всей жизни: от своего рождения и до самой смерти (отпечатки пальцев, отличительные характеристики радужной оболочки глаза, рисунок глазной сетчатки, термограмма, геометрия лица, геометрия кисти руки и даже фрагмент генетического кода);
- динамический метод — анализирует характерный черты, особенности поведения пользователя, которые демонстрируются в момент выполнения какого либо обычного повседневного действия (подпись, клавиатурный почерк, голос и другое).
Основным на всемирном рынке биометрической защиты, всегда являлся статический метод. Динамическая аутентификация и комбинированные системы защиты информации занимали, всего лишь, 20 % рынка. Однако, в последние годы, наблюдается активное развитие динамических методов защиты. Особенный интерес сетевых технологий представляют методы клавиатурного почерка и аутентификации по подписи.
В связи с довольно быстрым развитием современных биометрических технологий, появляется критически важная проблема — определение общих стандартов надежности биометрических систем защиты. Большим авторитетом среди специалистов пользуются средства, имеющие сертификаты качества, которые выдает Международная ассоциация по компьютерной безопасности ICSA (International Computer Security Association).
Статический метод биометрической аутентификации и его разновидности
Дактилоскопия — наиболее популярная технология биометрической аутентификации, основанная на сканировании и распознавании отпечатков пальцев.

Данный метод активно поддерживается правоохранительными органами, с целью привлечения в свои архивы электронных образцов. Также, метод сканирования отпечатков пальцев легок в использовании и надежен универсальностью данных. Главным устройством этого метода биометрической аутентификации есть сканер, который сам по себе имеет небольшие размеры и является относительно недорогим в цене. Такая аутентификация осуществляется достаточно быстро за счет того, что система не требует распознавания каждой линии узора и сравнения её с исходными образцами, находящимися в базе. Системе достаточно определить совпадения в масштабных блоках и проанализировать раздвоения, разрывы и прочие искажения линий (минуции).
Уникальность каждого отпечатка позволяет использовать данный метод биометрической аутентификации как в криминалистике, в процессах серьезных бизнес-операций, так и в быту. В последнее время появилось множество ноутбуков со встроенным сканером отпечатков пальцев, клавиатур, компьютерных мышей, а также смартфонов для аутентификации пользователя.

Есть и минусы в этой, казалось бы, неоспоримой и не поддельной, аутентификации. Из-за использования сложных алгоритмов распознавания мельчайших папиллярных линий, система аутентификации может демонстрировать сбои при недостаточном контакте пальца со сканером. Обмануть средство аутентификации и саму систему защиты можно и с помощью муляжа (очень качественно выполненного) или мертвого пальца.
По принципу работы, используемые для аутентификации сканеры, делятся на три вида:
- оптические сканеры, функционирующие на технологии отражения, или по принципу просвета. Из всех видов, оптическое сканирование не способно распознать муляж, однако, благодаря своей стоимости и простоте, именно оптические сканеры наиболее популярны;
- полупроводниковые сканеры — подразделяются на радиочастотные, емкостные, термочувствительные и чувствительные к давлению сканеры. Тепловые (термосканеры) и радиочастнотные сканеры лучше всех способны распознать настоящий отпечаток и не допустить аутентификацию по муляжу пальца. Полупроводниковые сканеры считаются более надежными, нежели оптические;
- ультразвуковые сканеры. Данный вид устройств является самым сложным и дорогим. С помощью ультразвуковых сканеров можно совершать аутентификацию не только по отпечаткам пальцев, но и по некоторым другим биометрическим параметрам, таким как частота пульса и пр.
Аутентификация по сетчатке глаза. Данный метод стали использовать еще в 50-х годах прошлого столетия. В то время, как раз, была изучена и определена уникальность рисунка кровеносных сосудов глазного дна.
Сканеры сетчатки глаза имеют довольно большие габариты и более высокую цену, нежели сканеры отпечатков пальцев. Однако, надежность такого вида аутентификации гораздо выше дактилоскопии, что и оправдывает вложения. Особенности рисунка кровеносных сосудов глазного дна таковы, что он не повторяется даже у близнецов. Поэтому, такая аутентификация имеет максимальную защиту. Обмануть сканер сетчатки глаза, практически невозможно. Сбои при распознавании глазного рисунка незначительно малы — примерно, один на миллион случаев. Если, у пользователя нет серьезных глазных заболеваний (например, катаракта), он может уверенно использовать систему аутентификации по сетчатке глаза для защиты доступа к всевозможным хранилищам, приватных кабинетов и сверхсекретных объектов.
Сканирование сетчатки глаза предусматривает использование инфракрасного низкоинтенсивного излучения, которое направляется к кровеносным сосудам глазного дна через зрачок. Сигнал отображает несколько сотен характерных точек, которые записываются в шаблон. Самые современные сканеры вместо инфракрасного света направляют лазер мягкого действия.
Для прохождения данной аутентификации, человек должен максимально приблизить к сканеру лицо (глаз должен быть не далее 1,5 см от устройства), зафиксировать его в одном положении и направить взгляд на дисплей сканера, на специальную метку. Около сканера, в таком положении, приходится находиться приблизительно минуту. Именно столько много времени требуется сканеру для осуществления операции сканирования, после чего, системе понадобится еще несколько секунд для сравнения полученного образца с установленным шаблоном. Длительное нахождение в одном положении и фиксация взгляда на вспышку света и являются самыми большими недостатками использования данного вида аутентификации. Плюс, из-за относительно долгого сканирования сетчатки и обработки результатов, данное устройство невозможно устанавливать для аутентификации большого количества людей (например, проходной).
Аутентификация по радужной оболочке глаза. Данный метод аутентификации основан на распознавании уникальных особенностей радужной оболочки глаза.

Схожий на сеть, сложный рисунок подвижной диафрагмы между задней и передней камерами глаза — это и есть уникальная радужная оболочка. Данный рисунок человеку дается еще до его рождения и особо не изменяется в течении всей жизни. Надежности аутентификации методом сканирования радужной оболочки глаза способствует различие левого и правого глаз человека. Такая технология, практически, исключает ошибки и сбои при аутентификации.
Однако, сложно назвать устройства, считывающие рисунок радужной оболочки — сканерами. Это, скорее всего, специализированная камера, которая делает 30 снимков в секунду. Затем оцифровывается одна из записей и преобразовывается в упрощенную форму, из которой отбираются около 200 характерных точек и информация по ним записывается в шаблон. Это куда более надежно, чем сканирование отпечатков пальцев — для формирования таких шаблонов используются всего лишь 60-70 характерных точек.
Данный вид аутентификации предполагает дополнительную защиту от поддельных глаз — в некоторых моделях устройств, для определения «жизни» глаза, изменяется поток света, направленный в него и система отслеживает реакцию и определяет изменяется ли размер зрачка.
Данные сканеры уже широко используются, к примеру, в аэропортах многих стран для аутентификации сотрудников во время пересечения зон ограниченного доступа, а также, неплохо зарекомендовали себя в Англии, Германии, США и Японии во время экспериментального использования с банкоматами. Следует отметить, что при аутентификации по радужной оболочке глаза, в отличие от сканирования сетчатки, считывающая камера может находиться от 10 см до 1 метра от глаза и процесс сканирования и распознавания проходит намного быстрее. Данные сканеры стоят дороже, нежели вышеуказанные средства биометрической аутентификации, но, в последнее время и они становятся все более доступными.
Аутентификация по геометрии руки — данный метод биометрической аутентификации предполагает измерение определенных параметров человеческой кисти, например: длина, толщина и изгибы пальцев, общая структура кисти, расстояние между суставами, ширина и толщина ладони.

Руки человека не являются уникальными, поэтому для надежности данного вида аутентификации необходимо комбинировать распознавание сразу по нескольким параметрам.
Вероятность ошибок при распознавании геометрии кисти составляет около 0,1%, а это значит, что при ушибе, артрите и прочих заболеваниях и повреждениях кисти, скорее всего, пройти аутентификацию не удастся. Так что, данный метод биометрической аутентификации не подходит для обеспечения безопасности объектов высокой степени секретности.
Однако, данный метод нашел широкое распространение, благодаря тому, что он удобен для пользователей по целому ряду причин. Одной из немаловажных таких причин является то, что устройство для распознания параметров руки не принуждает пользователя к дискомфорту и не отнимает много времени (весь процесс аутентификации осуществляется за несколько секунд). Следующей причиной популярности аутентификации по геометрии руки можно назвать тот факт, что ни температура, ни загрязненность, ни влажность кисти не влияют на процедуру аутентификации. Также, удобен данный метод и тем, что для распознавания кисти можно использовать изображение низкого качества — размер шаблона, хранящегося в базе всего 9 байт. Процедура сравнения кисти пользователя с установленным шаблоном очень проста и легко может быть автоматизирована.
Устройства данного вида биометрической аутентификации могут иметь разный внешний вид и функционал — одни сканируют лишь два пальца, другие делают снимок всей руки, а некоторые современные устройства при помощи инфракрасной камеры сканируют вены и по их изображению осуществляют аутентификацию.
Данный метод впервые был использован в начале 70-х годов прошлого века. Сегодня подобные устройства можно встретить в аэропортах и различных предприятиях, где необходимо формировать достоверные сведения о присутствии того, или иного человека, учета рабочего времени и прочих процедур контроля.
Аутентификация по геометрии лица. Этот биометрический метод аутентификации является одним из «трёх больших биометрик» наряду с распознаванием по радужной оболочке и сканированию отпечатков пальцев.

Данный метод аутентификации подразделяется на двухмерное и трехмерное распознавание. Двухмерное (2D) распознавание лица используется уже очень давно, в основном, в криминалистике. Но, с каждым годом данный метод усовершенствуется, повышая, этим самым, уровень своей надежности. Однако, до совершенства двухмерному методу распознавания лица еще далеко — вероятность ложных срабатываний при данной аутентификации варьируется от 0,1 до 1 %. Еще выше частота ошибок непризнания.
Куда больше надежд возлагают на новейший метод — трехмерное (3D) распознавание лиц. Оценки надежности данного метода пока не выведены, так как он является относительно молодым. Разработкой систем трехмерного распознавания лиц занимаются около десяти ведущих мировых ИТ-компаний, в том числе и из России. Большинство таких разработчиков предоставляют на рынок сканеры вместе с программным обеспечением. И только некоторые работают над созданием и выпуском сканеров.
При трёхмерном распознавании лиц используется множество сложных алгоритмов, эффективность которых зависит от условий их применения. Процедура сканирования составляет около 20-30 секунд. В этот момент лицо может быть повернуто относительно камеры, что принуждает систему компенсировать движения и формировать проекции лица с четким выделением черт лица, таких как контуры бровей, глаз, носа, губ и др. Затем система определяет расстояние между ними. В основном, шаблон составляется из таких неизменных характеристик, как глубина глазных впадин, форма черепа, надбровных дуг, высота и ширина скул и прочих ярко выраженных особенностей, благодаря которым впоследствии система сможет распознать лицо даже при наличии бороды, очков, шрамов, головного убора и прочего. Всего для построения шаблона используется от 12 до 40 особенностей лица и головы пользователя.
Международный подкомитет по стандартизации в области биометрии (IS0/IEC JTC1/SC37 Biometrics) в последнее время занимается разработкой единого формата сведений для распознавания человеческих лиц на основе двух- и трехмерных изображений. Скорее всего, два данных метода объединят вы один биометрический метод аутентификации.
Термография лица. Данный биометрический метод аутентификации выражается в установлении человека по его кровеносным сосудам.

Лицо пользователя сканируется при помощи инфракрасного света и формируется термограмма — температурная карта лица, являющаяся достаточно уникальной. Данный метод по своей надежности сравним с методом аутентификации по отпечаткам пальцев. Сканирование лица при данной аутентификации можно производить с десятиметрового расстояния. Этот метод способен распознать близнецов (в отличии от распознавания по геометрии лица), людей, перенесших пластические операции, использующих маски, а также он эффективен не смотря на температуру тела и старение организма.
Однако, данный метод не распространен широко, возможно, из-за невысокого качества получаемых термограмм лиц.
Динамические методы биометрической аутентификации
Метод распознавания голоса. Биометрический метод аутентификации пользователя по голосу является наиболее доступным для реализации.

Данный метод позволяет произвести идентификацию и аутентификацию личности при помощи лишь одного микрофона, который подключен к записывающему устройству. Использование данного метода бывает полезным в судебных случаях, когда единственной уликой против подозреваемого служит запись телефонного разговора. Метод распознавания голоса является очень удобным — пользователю достаточно лишь произнести слово, без совершения каких-либо дополнительных действий. И, наконец, огромным преимуществом данного метода является право осуществления скрытой аутентификации. Пользователь не всегда может быть осведомлен о включении дополнительной проверки, а значит, злоумышленникам будет еще сложнее получить доступ.
Формирование персонального шаблона производится по многим характеристикам голоса. Это может быть тональность голоса, интонация, модуляция, отличительные особенности произношения некоторых звуков речи и другое. Если система аутентификации должным образом проанализировала все голосовые характеристики, то вероятность аутентификации постороннего лица никчемно мала. Однако, в 1-3 % случаев, система может дать отказ и настоящему обладателю ранее определенного голоса. Дело в том, что голос человека может меняться во время болезни (например, простуды), в зависимости от психического состояния, возраста и т.п. Поэтому, биометрический метод голосовой аутентификации нежелательно использовать на объектах повышенной безопасности. Он может быть использован для доступа в компьютерные классы, бизнес-центры, лаборатории и подобного уровня безопасности объекты. Также, технология распознавание голоса может применяться не только в качестве аутентификации и идентификации, но и как незаменимый помощник при голосовом вводе данных.
Метод распознавания клавиатурного почерка — является одним из перспективных методов биометрической аутентификации сегодняшнего дня. Клавиатурный почерк представляет собой биометрическую характеристику поведения каждого пользователя, а именно — скорость ввода, время удержания клавиш, интервалы между нажатиями на них, частота образования ошибок при вводе, число перекрытий между клавишами, использование функциональных клавиш и комбинаций, уровень аритмичности при наборе и др.

Данная технология является универсальной, однако, лучше всего, распознавание клавиатурного почерка подходит для аутентификации удаленных пользователей. Разработкой алгоритмов распознавания клавиатурного почерка активно занимаются как зарубежные, так и российские ИТ-компании.
Аутентификация по клавиатурному почерку пользователя имеет два способа:
- ввод известной фразы (пароля);
- ввод неизвестной фразы (генерируется случайным образом).
Оба способа аутентификации предполагают два режима: режим обучения и режим самой аутентификации. Режим обучения заключается в многократном вводе пользователем кодового слова (фразы, пароля). В процессе повторного набора, система определяет характерные особенности ввода текста и формирует шаблон показателей пользователя. Надежность такого вида аутентификации зависит от длины вводимой пользователем фразы.
Среди преимуществ данного метода аутентификации следует отметить удобство пользования, возможность осуществления процедуры аутентификации без специального оборудования, а также возможность скрытой аутентификации. Минусом данного метода, как и в случае с распознаванием голоса, можно назвать зависимость отказа системы от возрастных факторов и состояния здоровья пользователя. Ведь, моторика, куда сильнее, нежели голос, зависит от состояния человека. Даже простая человеческая усталость может повлиять на прохождение аутентификации. Смена клавиатуры, также может быть причиной отказа системы — пользователь способен не сразу адаптироваться к новому устройству ввода и поэтому, при вводе проверочной фразы, клавиатурный почерк может не соответствовать шаблону. В частности, это влияет на темп ввода. Хотя, исследователи предлагают повысить эффективность данного метода за счет использования ритма. Искусственное добавление ритма (например, ввод пользователем слова под какую-то знакомую мелодию) обеспечивает устойчивость клавиатурного почерка и более надежную защиту от злоумышленников.
Верификация подписи. В связи с популярностью и массовому использованию различных устройств с сенсорным экраном, биометрический метод аутентификации по подписи становится очень востребованным.

Максимально точную верификацию подписи обеспечивает использование специальных световых перьев. Во многих странах электронные документы, подписанные биометрической подписью, имеют такую же юридическую силу, что и бумажные носители. Это позволяет осуществлять документооборот значительно быстрее и беспрепятственно. В России, к сожалению, доверие оказывает лишь бумажный подписанный документ, или электронный документ, на который наложена официально зарегистрированная электронная цифровая подпись (ЭЦП). Но, ЭЦП легко передать другому лицу, что не сделаешь с биометрической подписью. Поэтому, верификация по биометрической подписи является более надежной.
Биометрический метод аутентификации по подписи имеет два способа:
- на основе анализа визуальных характеристик подписи. Данным способом предполагается сравнение двух изображений подписи на соответствие идентичности — это может осуществляться как системой, так и человеком;
- способ компьютерного анализа динамических характеристик написания подписи. Аутентификация таким способом происходит после тщательного исследования сведений о самой подписи, а также о статистических и периодических характеристиках ее написания.
Формирование шаблона подписи осуществляется в зависимости от требуемого уровня защиты. Всего, одна подпись анализируется пол 100-200 характерным точкам. Если же, подпись ставится с использованием светового пера, то помимо координат пера, учитывается и угол его наклона, нажатие пера. Угол наклона пера исчисляется относительно планшета и по часовой стрелке.
Данный метод биометрической аутентификации, как и распознавание клавиатурного почерка, имеют общую проблему — зависимость от психофизического состояния человека.
Комбинированные решения биометрической аутентификации
Мультимодальная, или комбинированная система биометрической аутентификации — это устройство, в котором объединены сразу несколько биометрических технологий. Комбинированные решения по праву считаются наиболее надежными в плане защиты информации с помощью биометрических показателей пользователя, ведь подделать сразу несколько показателей гораздо сложнее, нежели один признак, что является, практически, не под силу злоумышленникам. Максимально надежными считаются комбинации «радужная оболочка + палец» или «палец + рука».
Хотя, в последнее время, популярность набирают системы типа «лицо + голос». Это связано с широким распространением коммуникационных средств, которые сочетают в себе модальности аудио и видео, например, мобильные телефоны со встроенными камерами, ноутбуки, видеодомофоны и прочее.
Комбинированные системы биометрической аутентификации значительно эжффективнее мономодальных решений. Это подтверждает множество исследований, в том числе опыт одного банка, который установил сперва систему аутентификации пользователей по лицу (частота ошибок за счет низкого качества камер 7 %), затем по голосу (частота ошибок 5% из-за фоновых шумов), а после, комбинировав эти два метода, достигли почти 100 % эффективности.
Биометрические системы могут быть объединены различными способами: параллельно, последовательно или согласно иерархии. Главным критерием при выборе способа объединения систем должна служить минимализация соотношения количества возможных ошибок ко времени одной аутентификации.
Помимо комбинированных систем аутентификации, можно использовать и многофакторные системы. В системах с многофакторной аутентификацией, биометрические данные пользователя используются вместе с паролем или электронным ключом.
Защита биометрических данных
Биометрическая система аутентификации, как и многие другие системы защиты, в любой момент может быть подвергнута нападению злоумышленников. Соответственно, начиная с 2011 года, международная стандартизация в области информационных технологий предусматривает мероприятия по защите биометрических данных — стандарт IS0/IEC 24745:2011. В российском законодательстве защиту биометрических данных регламентирует Федеральный закон «О персональных данных», с последними изменениями в 2011 году.
Наиболее распространенным направлением в области современных биометрических методов аутентификации является разработка стратегии защиты, хранящихся в базах данных биометрических шаблонов. Среди самых популярных киберпреступлений дня сегодняшнего во всем мире считается «кража личности». Утечка шаблонов из базы данных делает преступления более опасными, так как восстанавливать биометрические данные злоумышленнику проще за счет обратного инжиниринга шаблона. Поскольку биометрические характеристики неотъемлемы от своего носителя, похищенный шаблон нельзя заменить нескомпроментированным новым, в отличии от пароля. Опасность кражи шаблона еще заключается в том, что помимо доступа к защищенным данным, злоумышленник может заполучить секретную информацию о человеке, или организовать за ним тайную слежку.
Защита биометрических шаблонов базируется на трех основных требованиях:
- необратимость — данное требование ориентировано на сохранение шаблона таким образом, чтобы злоумышленнику было невозможно восстановить вычислительным путем биометрические характеристики из образца, или создать физические подделки биометрических черт;
- различимость — точность системы биометрической аутентификации не должна быть нарушена схемой защиты шаблона;
- отменяемость — возможность формирования нескольких защищенных шаблонов из одних биометрических данных. Данное свойство предоставляет биометрической системе возможность отзывать биометрические шаблоны и выдавать новые при компрометации данных, а также предотвращает сопоставление сведений между базами данных, сохраняя этим самым приватность данных пользователя.
Оптимизируя надежную защиту шаблона, главной задачей является нахождение приемлемого взаимопонимания между этими требованиями. Защита биометрических шаблонов строится на двух принципах: биометрические криптосистемы и трансформация биометрических черт. Последние изменения в законодательстве запрещают оператору биометрической системы самостоятельно, без присутствия человека, менять его персональные данные. Соответственно, приемлемыми становятся системы, хранящие биометрические данные в зашифрованном виде. Шифровать эти сведения можно двумя методами: с помощью обычного ключа и шифрование при помощи ключа биометрического — доступ к данным предоставляется исключительно в присутствии владельца биометрических показателей. В обычной криптографии ключ расшифровки и зашифрованный шаблон представляют собой две абсолютно разные единицы. Шаблон может считаться защищенным в том случае, если защищен ключ. В биометрическом ключе происходит одновременная инкапсуляция шаблона криптографического ключа. В процессе шифрования подобным способом, в биометрической системе хранится лишь частичная информация из шаблона. Ее называют защищенным эскизом — secure sketch. На основании защищенного эскиза и другого биометрического образца, схожего на представленный при регистрации, восстанавливается оригинальный шаблон.
ИТ-специалисты, занимающиеся исследованиями схем защиты биометрических шаблонов, обозначили два главных метода создания защищенного эскиза:
- нечеткое обязательство (fuzzy commitment);
- нечеткий сейф (fuzzy vault).
Первый метод годится для защиты биометрических шаблонов, имеющих вид двоичных строк определенной длины. А второй может быть полезным для защиты шаблонов, которые представляют собой наборы точек.
Внедрение криптографических и биометрических технологий положительное влияет на разработку инновационных решений для обеспечения информационной безопасности. Особенно перспективной является многофакторная биометрическая криптография, объединившая в себе технологии пороговой криптографии с разделением секрета, многофакторной биометрии и методы преобразования нечетких биометрических признаков в основные последовательности.
Невозможно сформировать однозначный вывод, какой из современных биометрических методов аутентификации, или комбинированных методов является наиболее эффективным для тех, или иных коммерческих из расчета соотношения цены и надежности. Определенно видно, что для множества коммерческих задач использовать сложные комбинированные системы не представляется логичным. Но, вовсе не рассматривать такие системы, тоже не верно. Комбинированную систему аутентификации можно задействовать с учетом требуемого в данный момент уровня безопасности с возможностью активации дополнительных методов в дальнейшем.