Регулярные выражения
Регулярные выражения — это инструмент, который позволяет фронтендеру быстрее находить и анализировать информацию. Благодаря ему можно не только эффективнее решать задачи, но и писать код, который будет лучше работать. Причем не стоит использовать этот метод везде: иногда он только усложняет жизнь.
Наше недавнее исследование вакансий показало: знание регулярных выражений и навык работы с ними требуется в 24% вакансий продуктовых компаний для фронтенд-разработчиков с опытом больше двух лет.
Давайте разберёмся, что такое регулярные выражения и как грамотно их применять.
Зачем нужны регулярные выражения
Регулярные выражения — это формальный язык поиска подстроки в строке. Они поддерживаются многими программами: редакторами, системными утилитами, базами данных. Но особенно хорошо возможности этого инструмента раскрываются в языках программирования, в том числе в JavaScript.
Рассмотрим простой пример, чтобы понять, зачем нужны регулярные выражения. Допустим, перед нами стоит задача — найти и заменить местоимение ее на его в строке Быстрее всего мы догоним ее на машине .
Самое очевидное решение — использовать прямую замену, применив встроенную в JavaScript функцию:
'Быстрее всего мы догоним ее на машине'.replace('ее', 'его'); Однако мы получим ожидаемо неверный результат: ее является также окончанием слова Быстрее , а .replace() заменит первое вхождение подстроки. Поэтому необходимо проверить строку на наличие символа, стоящего перед ее : если это пробел, можно делать замену.
В задаче могут возникнуть и другие условия. Например, мы не знаем, в каком регистре написаны слова ( ее , Ее , ЕЕ ) и используется ли буква ё . Если добавить их в функцию, она станет слишком большой и сложной. Это может привести к другим ошибкам.
С помощью регулярных выражений подобные задачи решаются гораздо проще. Но фронтенд-разработчики редко используют этот инструмент, потому что он кажется непонятным. Попробуем внести ясность.
�� Чтобы углубиться в тему, пройдите курс «Регулярные выражения для фронтенда». Он научит вас составлять регулярные выражения, чтобы писать меньше кода и работать быстрее.
Когда можно использовать регулярные выражения
Типовых задач, в которых регулярные выражения действительно могут пригодиться, не так много. Среди них:
- Поиск или замена подстроки в строке с «плавающими» (неизвестными) данными. Самая распространённая задача — найти в тексте ссылки и адреса электронной почты и сделать их кликабельными.
- Валидация данных формы и ограничение ввода. Например, валидация номера телефона, электронной почты, данных паспорта гражданина РФ и другой информации.
- Получение части строки или формирование новых структур данных из строк. Например, нужно найти количество вхождений ключевых слов в тексте без учёта падежных окончаний, составить из них массив с данными для дальнейшего использования.
Чаще всего фронтенд-разработчики встречаются с регулярными выражениями в задачах, связанных с валидацией данных. И обычно такие задачи решаются поиском нужного выражения в интернете и вставкой готового выражения в проект — по крайней мере, у начинающих специалистов.
В контексте поиска и замены текста регулярные выражения используют редко, а в сложных кейсах по работе с текстом — ещё меньше. Но они могут помочь, если задача связана с обработкой текста.
Когда нет смысла применять регулярные выражения
В некоторых случаях этот инструмент усложняет реализацию или время выполнения кода. Вам не нужны регулярные выражения, если стандартные функции JavaScript справляются с задачей сами. Вот ещё пара ситуаций:
- Структура содержимого данных хорошо описана, легко поддаётся разбору, и можно применить нативные методы работы со строкой.
- Предполагается работа с тегами, правка атрибутов или содержимого.
Разумеется, это общие примеры, и научиться подбирать правильное решение можно только с опытом. Главное, чтобы оно позволяло тратить на задачу меньше ресурсов и повышало производительность.
Как регулярные выражения могут помочь с задачами, которые не касаются написания кода напрямую
Регулярные выражения могут облегчить работу фронтендеру не только при работе с кодом, но и при его написании.
По сути, ваш код — это текст, по которому также можно осуществлять поиск, выполнять ручные и автоматические замены. При работе над большими проектами такие операции надо проводить очень аккуратно, чтобы не удалить ничего лишнего.
Вот пример использования регулярных выражений для поиска в текстовом редакторе:
Какие типовые задачи решаются регулярными выражениями:
- Поиск и гибкая замена в коде.
- Подготовка и обработка данных. Когда вы выносите предварительные данные в текстовый редактор и готовите их для следующих операций.
- Написание кода с большим количеством одинаковых конструкций.
Регулярные выражения вне фронтенда
Как было сказано в начале, регулярные выражения применяются во многих языках программирования, но это не значит, что они везде раскрываются одинаково. В зависимости от языка они могут, например, добавлять разные фичи и работать с разной скоростью.
Если разобраться с регулярными выражениями на примере JavaScript, то обращаться к ним в других языках программирования будет уже легче. Но изучать нюансы и стандарты внутри каждого языка точно придётся.
Выводы
Регулярные выражения — довольно мощный инструмент. Он отлично справляется с задачами, которые сложно решить с помощью нативных методов языка, упрощает работу с кодом и даже его написание. При этом нужно понимать, когда его использовать, чтобы работать быстрее и эффективнее.
Больше статей
- HTML-шаблонизаторы
- Что такое и зачем нужны алгоритмы
- Что такое CMS и как под них верстать
«Доктайп» — журнал о фронтенде. Читайте, слушайте и учитесь с нами.
Регулярные выражения для простых смертных
Мы активно ищем свежую литературу на тему регулярных выражений для начинающих. Причем в данном случае нас бы скорее привлекла не переводная, а исходно русскоязычная книга, которая каким-то образом затрагивала бы и регулярные выражения при обработке естественного языка. Хотим предложить вашему вниманию следующий текст — во-первых, напомнить об этой теме, во-вторых, продемонстрировать примерный уровень сложности, который нас интересует
Рано или поздно вам придется иметь дело с регулярными выражениями. Притом, какой у них сложный синтаксис, путаная документация и жесткая кривая обучения, большинство разработчиков удовлетворяются следующим: копипастят выражение со StackOverflow и надеются, что оно будет работать. Но что если бы в самом деле могли расшифровывать регулярные выражения и пользоваться ими на всю катушку? В этой статье я расскажу, почему следует еще раз присмотреться к регулярным выражениям, и как они могут пригодиться на практике.
Зачем нужны регулярные выражения?
Зачем вообще возиться с регулярными выражениями? Чем они могут помочь именно вам?
- Сравнение с шаблоном: Регулярные выражения отлично помогают определять, соответствует ли строка тому или иному формату – например, телефонному номеру, адресу электронной почты или номеру кредитной карты.
- Замена: При помощи регулярных выражений легко находить и заменять шаблоны в строке. Так, выражение text.replace(/\s+/g, » «) заменяет все пробелы в text, например, » \n\t » , одним пробелом.
- Извлечение: При помощи регулярных выражений легко извлекать из шаблона фрагменты информации. Например, name.matches(/^(Mr|Ms|Mrs|Dr)\.?\s/i)[1] извлекает из строки обращение к человеку, например, «Mr» из «Mr. Schropp» .
- Портируемость: Почти в любом распространенном языке программирования есть своя библиотека регулярных выражений. Синтаксис в основном стандартизирован, поэтому вам не придется переучиваться регулярным выражениям при переходе на новый язык.
- Код: Когда пишете код, можно пользоваться регулярными выражениями для поиска информации в файлах; так, в Atom для этого предусмотрен find and replace, а в командной строке — ack.
- Четкость и лаконичность: Если вы с регулярными выражениями на «ты», то сможете выполнять весьма нетривиальные операции, написав минимальный объем кода.
Как писать регулярные выражения
Регулярные выражения проще всего изучить на примере. Допустим, вы пишете веб-страницу, на которой будет поле для ввода телефонного номера. Поскольку вы — ас веб-разработки, вам хочется дополнительно отображать на экране галочку, если телефонный номер валиден, и крестик X — если нет.
input:not([data-validation="valid"]) ~ label.valid, input:not([data-validation="invalid"]) ~ label.invalid < display: none; >$("input").on("input blur", function(event) < if (isPhoneNumber($(this).val())) < $(this).attr(< "data-validation": "valid" >); return; > if (event.type == "blur") < $(this).attr(< "data-validation": "invalid" >); > else < $(this).removeAttr("data-validation"); >>); Теперь, если человек введет или вставит в поле валидный номер, то отобразится галочка. Если пользователь уберет курсор из поля ввода, а в поле при этом останется недопустимое значение, то отобразится крестик.
Поскольку вы знаете, что телефонные номера состоят из десяти цифр, первым делом проверяете, чтобы isPhoneNumber выглядел так:
function isPhoneNumber(string) < return /\d\d\d\d\d\d\d\d\d\d/.test(string); >В этой функции между символами / содержится регулярное выражение с десятью \d’ , то есть, символами-цифрами. Метод test возвращает true , если регулярное выражение соответствует строке, в противном случае – false . Если выполнить isPhoneNumber(«5558675309») , метод вернет true ! Ура!
Однако, писать десять \d – слегка муторная работа. К счастью, то же самое можно сделать и при помощи фигурных скобок.
function isPhoneNumber(string) < return /\d/.test(string); > Иногда, вводя телефонный номер, человек начинает с ведущей 1. Правда было бы неплохо, если бы ваше регулярное выражение обрабатывало и такие случаи? Это можно сделать при помощи символа?.
function isPhoneNumber(string) < return /1?\d/.test(string); > Символ ? означает «ноль или единица», поэтому теперь isPhoneNumber возвращает true как для «5558675309», так и для «15558675309»!
Пока isPhoneNumber вполне хороша, но мы упускаем одну ключевую деталь: регулярные выражения сплошь и рядом могут совпадать не со строкой, а с частью строки. Оказывается, isPhoneNumber(«555555555555555555») возвращает true, поскольку в этой строке десять цифр. Проблему можно решить, воспользовавшись якорями ^ и $.
function isPhoneNumber(string) < return /^1?\d$/.test(string); > Грубо говоря, ^ соответствует началу строки, а $ — концу строки, поэтому теперь ваше регулярное выражение совпадет с целым телефонным номером.
Серьезный пример
Релиз страницы состоялся, она пользуется бешеным успехом, но есть существенная проблема. В США телефонный номер можно записать разными способами:
- (234) 567-8901
- 234-567-8901
- 234.567.8901
- 234/567-8901
- 234 567 8901
- +1 (234) 567-8901
- 1-234-567-8901
Хотя пользователи и могут обойтись без пунктуации, им было бы гораздо проще вводить заранее отформатированный номер.
Пусть вы и могли бы написать регулярное выражение для обработки всех этих форматов, думаю, что это плохая идея. Как бы тщательно вы ни старались учесть все форматы, все равно какой-нибудь пропустите. Кроме того, в действительности вам интересны только сами данные, а не их форматирование. Итак, чем возиться со всей этой пунктуацией, не проще ли избавиться от нее?
function isPhoneNumber(string) < return /^1?\d$/.test(string.replace(/\D/g, "")); > Функция replace заменяет пустой строкой символ \D , соответствующий любым символам кроме цифр. Глобальный флаг g приказывает функции заменить на регулярное выражение все совпадения, а не только первое.
Еще более серьезный пример
Ваша страница с телефонными номерами всем нравится, в офисе вы – король кулера. Однако, такие профессионалы как вы не останавливаются на достигнутом, поэтому вы хотите сделать страницу еще лучше.
North American Numbering Plan – это стандарт по составлению телефонных номеров, используемый в США, Канаде и еще 23 странах. В этой системе есть несколько простых правил:
- Телефонный номер ((234) 567-8901) делится на три части: региональный код (234), код АТС (567) и номер абонента (8901).
- В региональном коде и коде АТС первая цифра может быть любой от 2 до 9, а вторая и третья цифры – от 0 до 9.
- В коде АТС 1 не может быть третьей цифрой, если вторая цифра – это 1.
Ваше регулярное выражение уже соответствует первому правилу, но нарушает второе и третье. Пока давайте разберемся со вторым. Новое регулярное выражение должно выглядеть примерно так:
Номер абонента прост, он состоит всего из четырех цифр
Региональный код немного сложнее. Нас интересует цифра от 2 до 9, за которой идут еще две цифры. Для этого можно использовать символьное множество! Символьное множество позволяет задать группу символов, из которых затем можно выбирать.
Отлично, но мы устанем вручную вводить все символы от 2 до 9. Сделаем код еще чище при помощи символьного диапазона.
Уже лучше! Поскольку региональный код такой же, как и код АТС, можно просто продублировать регулярное выражение, чтобы довести этот шаблон до ума.
А как сделать, чтобы не приходилось копировать и вставлять ту часть выражения, в которой содержится региональный код? Все упростится, если использовать группу! Чтобы сгруппировать символы, их нужно просто заключить в круглые скобки.
Итак, [2-9]\d\d содержится в группе, а указывает, что эта группа должна фигурировать дважды.
Вот и все! Рассмотрим окончательный вариант функции
isPhoneNumber :
function isPhoneNumber(string) < return /^1?([2-9]\d\d)\d$/.test(string.replace(/\D/g, "")); > Когда лучше обходиться без регулярных выражений
Регулярные выражения – отличная штука, просто не следует решать с их помощью некоторые задачи.
Не будьте слишком строги. Нет никакого смысла проявлять чрезмерную строгость, когда пишешь регулярные выражения. В случае с телефонными номерами, даже если мы учтем все правила из документа NANP, все равно невозможно определить, реален ли данный телефонный номер. Если я заделаю номер(555) 555-5555, то он совпадет с шаблоном, но ведь такого телефонного номера не существует.
Не пишите HTML-парсер. Хотя регулярные выражения отлично подходят для парсинга каких-то простых вещей, синтаксический анализатор для целого языка из них не сделаешь. Если вы не любите заморачиваться, то вам вряд ли понравится разбирать нерегулярные языки при помощи регулярных выражений.
Не используйте их с очень сложными строками. Полное регулярное выражение для работы с электронной почтой состоит из 6 318 символов. Простое и приблизительное выглядит так: /^[^@]+@[^@]+\.[^@\.]+$/ . Общее правило таково: если у вас получается регулярное выражение длиннее одной строки кода, то, возможно, стоит поискать другое решение.
- регулярные выражения
- программирование
- Блог компании Издательский дом «Питер»
- Программирование
- Регулярные выражения
Как составлять регулярные выражения
Регулярное выражение — это последовательность символов (селекторов). Оно используется для поиска и обработки строк, слов, чисел и других текстовых данных.
Регулярные выражения выручают при решении разных задач. Например, с их помощью легко искать и менять строки в коде. Но чаще всего регулярные выражения используют для валидации форм. Давайте посмотрим, как это делать.
Шаблон регулярного выражения
Создать шаблон можно двумя способами. Выбирайте тот, что больше нравится:
Первый способ — через new RegExp() :
regularExpression = new RegExp("регулярное выражение", "флаги"); Второй способ — через слеши:
regularExpression = /регулярное выражение/флаги; Основные символы в регулярных выражениях
Посмотрим, чем наполнять шаблон регулярного выражения: какие селекторы использовать и что такое флаги.
Символы текста
Буквы и цифры — самые простые символы. Например, регулярное выражение оса найдет совпадение даже в слове «автосалон».
Символы начала и конца строки
Каретка ^ используется для обозначения начала строки, а доллар $ — для конца. К примеру, если мы напишем ^оса$ , то совпадением будет только со словом «оса».
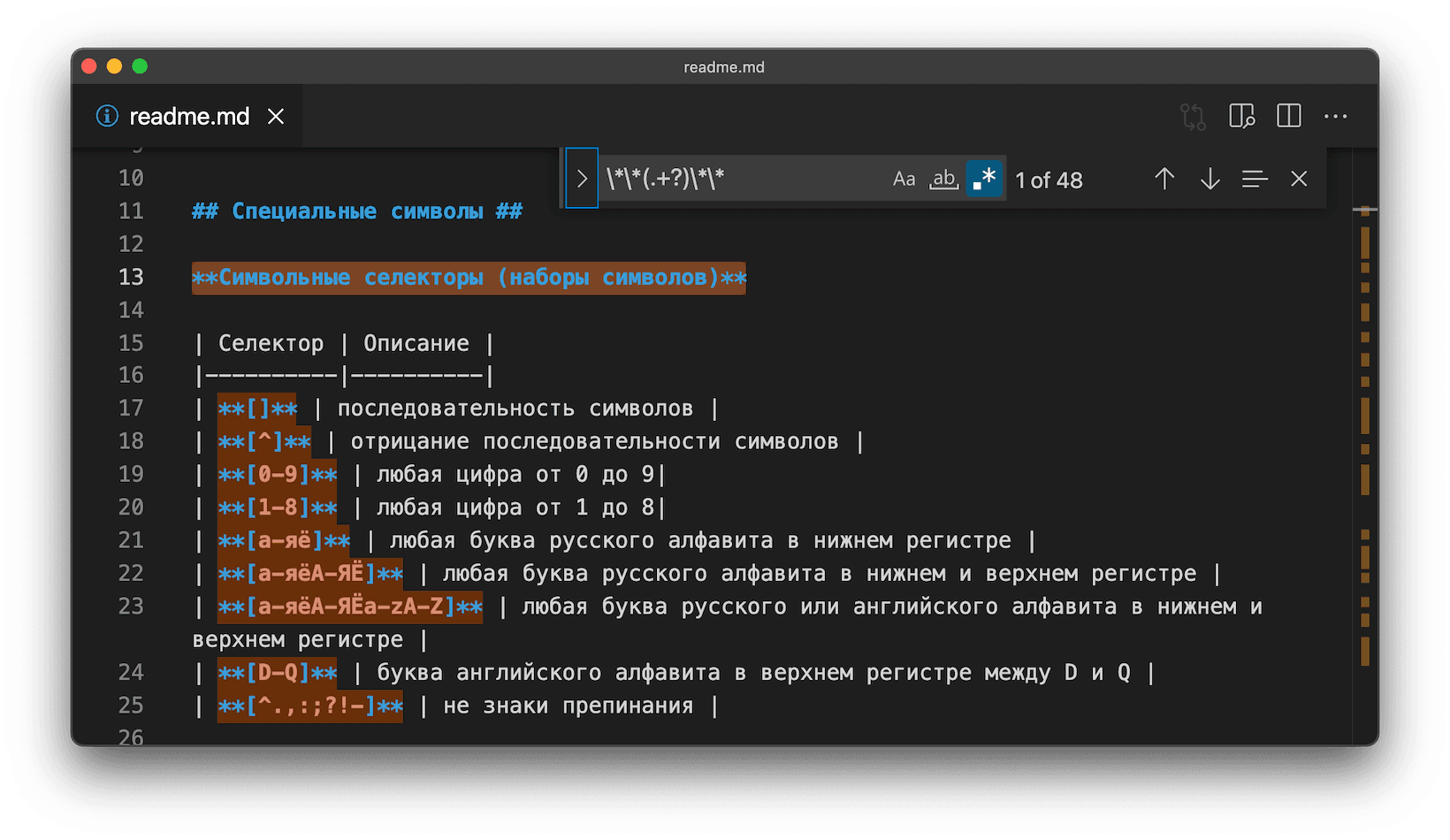
Классы символов
С их помощью указываются диапазоны символов. То есть вы можете уточнить, какие буквы, цифры или знаки могут встречаться в регулярном выражении, а какие нет.
[^] — отрицание диапазона символов. Если коротко, вы можете исключить поиск конкретных символов. Например, [^оса] не найдёт совпадений со словом «оса», а вот с «осадками» совпадение будет.
- [0-9] — любая цифра от нуля до девяти;
- \d — тоже любая цифра, это эквивалент [0-9] .
- [а-яё] — любая буква кириллицы в нижнем регистре;
- [а-яёА-ЯЁ] — любая буква кириллицы в нижнем и верхнем регистре;
- [a-z] — любая буква на латинице в нижнем регистре;
- [a-zA-Z] — любая буква на латинице в нижнем и верхнем регистре;
- \w — любая цифра, латинская буква или знак подчёркивания.
Символы и знаки препинания:
- [. ;?!-] — знаки препинания.
- \s — пробел.
Квантификаторы
Эти селекторы проверяют количество повторений предыдущего символа или группы символов:
- — совпадение с точным количеством, где n — это положительное целое число. Например, конструкция [1-3] будет искать одну цифру от одного до трёх.
- — диапазон совпадений от минимального до максимального. Например, так можно указать минимальное и максимальное количество символов для ввода — . А ещё одно из значений можно пропустить — или .
- — одно или бесконечное количество совпадений. Этот селектор равнозначен записи `.
- + — одно или более повторений. Этот селектор равнозначен записи .
- ? — ни одного или одно повторение. Селектор равнозначен записи .
Модификаторы
Их ещё называют флагами. Это определённые параметры, которые задают настройки для поиска или замены текста.
Модификаторов много, мы перечислим лишь самые популярные:
- i — не учитывать регистр букв;
- g — искать все совпадения;
- u — поддержка юникод-символов.
Альтернация
Проще говоря, это условие. Альтернация обозначается символом | и указывает несколько вариантов, которые могут соответствовать регулярному выражению. Например, регулярное выражение (яблоко|банан) будет искать строки, содержащие либо слово «яблоко», либо «банан».
Символы группируются в скобках. При этом вы можете добавить условие «или» для любого количества символов: (a|b|c|d) .
�� Это лишь часть селекторов. Полный список вы найдёте на сайте MDN.
Как составить регулярное выражение
Сформулируйте условие. Например, вы хотите составить регулярное выражение для проверки логина. Этот логин должен быть длиннее трёх символов. Он может содержать буквы на кириллице и латинице или цифры. Регистр неважен.
Составьте выражение. Наполните шаблон селекторами, подходящими под ваши условия:
- Логин содержит буквы или цифры — /^[a-zа-яё0-9]/ .
- Слово должно быть не короче трёх символов, максимальной длины нет — /^[a-zа-яё0-9]/ .
- Регистр неважен — /^[a-zа-яё0-9]$/i .
Протестируйте регулярное выражение. Напишите собственные тесты или воспользуйтесь одним из онлайн-сервисов, например, regex101.
Регулярные выражения можно составить разными способами — даже два разработчика-коллеги напишут для одной и той же задачи что-то своё. Кому-то важна лаконичность — чем выражение короче, тем лучше. Кто-то хочет предусмотреть все варианты — например, вдруг пользователь введёт в логине нижнее подчёркивание. А кто-то просто хорошо знает возможности регулярок и гибко использует этот инструмент.
Примеры регулярных выражений
Регулярное выражение для номера телефона
Допустим, мы хотим проверить, что пользователь ввёл телефон в формате (XXX) XXX-XXXX . Можно составить следующее регулярное выражение: /^\d-\d-\d$/ . Здесь \d соответствует любой цифре, а фигурные скобки < и >указывают количество повторений.
Такое регулярное выражение будет соответствовать строкам, которые начинаются с открывающей скобки. За скобкой следуют три цифры, затем пробел, ещё три цифры, дефис и четыре цифры. Последним идёт символ конца строки.
✅ При проверке 123-456-7890 будет соответствовать шаблону, а (123) 456 7890 — нет.
Регулярное выражение для электронной почты
Составим регулярное выражение, которое проверяет формат почты username@domain.com — /^\w+([.-]?\w+)@\w+([.-]?\w+)(.\w)$/ . Выражение сложное, поэтому давайте посимвольно разбирать, что здесь происходит:
- ^ — начало строки.
- \w — любая буква, цифра или символ подчёркивания.
- + — указывает, что предыдущий символ (любая буква, цифра или символ подчёркивания) должен повторяться один или более раз.
- ([.-]?\w+)* — группа символов. Она начинается с точки, дефиса или ни одного из них ( ? ). За ними следует одна или более буквы, цифры или символы подчёркивания ( \w+ ). Звёздочка указывает, что эта группа может встречаться нуль или более раз.
- @ — символ собаки, он обязателен в адресе электронной почты.
- \w — любая буква, цифра или символ подчёркивания.
- ([.-]?\w+)* — аналогичная группа символов, как описано выше.
- . — просто точка.
- \w — любые буквы, цифры или символ подчёркивания.
- $ — конец строки.
Если коротко, это регулярное выражение будет соответствовать строкам, которые начинаются с одной или более буквы, цифры или символа подчёркивания. За ними следует символ @ . Затем идёт одна или более группа символов — она состоит из букв, цифр или подчёркивания, разделённых точкой. В конце — буквы, цифры или знак подчёркивания.
✅ При проверке example.email@mail.com будет соответствовать этому шаблону, а example.emailmail.com — нет.
Регулярное выражение для проверки имени человека
Предположим, мы хотим проверить, что введённое имя содержит только буквы и начинается с заглавной буквы. Для этого можно составить такое выражение: /^[А-Я][а-яё]*$/ . Здесь [А-Я] соответствует любой заглавной букве, а [а-яё] — любой букве в нижнем регистре. Звёздочка указывает, что предыдущий символ может повторяться нуль или более раз.
✅ При проверке имя Иван будет соответствовать шаблону, а иван — нет.
Заключение
Мы затронули лишь небольшую часть — основы регулярных выражений. Тема регулярок слишком обширна, чтобы рассказать обо всём в одной статье. Есть другие селекторы, модификаторы, да и сами регулярные выражения могут быть сложнее и интереснее.
�� Чтобы углубиться в тему, пройдите курс «Регулярные выражения для фронтенда». Он научит вас составлять регулярные выражения, чтобы писать меньше кода и работать быстрее.
Материалы по теме
- 3 способа валидации форм
- Зачем фронтендерам React, если есть JavaScript
- Частые ошибки в HTML-коде
«Доктайп» — журнал о фронтенде. Читайте, слушайте и учитесь с нами.
Что такое регулярные выражения и как их использовать в Python
Изучите мощный инструмент работы с текстом — регулярные выражения, и научитесь использовать их в Python с нашей информативной статьей!
Алексей Кодов
Автор статьи
10 июля 2023 в 17:48
Регулярные выражения являются мощным инструментом для работы с текстом. Они позволяют искать, заменять и манипулировать строками на основе определенных шаблонов. В этой статье мы рассмотрим основы регулярных выражений и как их использовать в Python. ��
Основы регулярных выражений
Регулярные выражения (или regex) — это последовательность символов, которая определяет шаблон поиска в тексте. Они используются в различных языках программирования, включая Python.
Некоторые основные символы и конструкции в регулярных выражениях:
- . (точка) — соответствует любому одному символу
- * (звездочка) — указывает, что предыдущий символ может повторяться 0 или более раз
- + (плюс) — указывает, что предыдущий символ может повторяться 1 или более раз
- — указывает, что предыдущий символ должен повториться ровно n раз
- [abc] — соответствует любому символу из указанных в квадратных скобках
- [^abc] — соответствует любому символу, кроме указанных в квадратных скобках
- \d — соответствует любой цифре
- \w — соответствует любому буквенно-цифровому символу
- \s — соответствует любому пробельному символу
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Работа с регулярными выражениями в Python
В Python для работы с регулярными выражениями используется модуль re . Вот некоторые основные функции этого модуля:
- re.search(pattern, string) — ищет в строке первое совпадение с шаблоном и возвращает объект Match или None , если совпадений нет
- re.findall(pattern, string) — возвращает список всех непересекающихся совпадений с шаблоном в строке
- re.sub(pattern, replacement, string) — заменяет все совпадения с шаблоном в строке на указанную замену
Примеры использования
import re # Поиск совпадений с шаблоном в строке pattern = r"\d+" string = "Сегодня 28 мая, завтра 29 мая" match = re.search(pattern, string) print(match) # <re.Match object; span=(7, 9), match='28'> # Нахождение всех совпадений с шаблоном в строке matches = re.findall(pattern, string) print(matches) # ['28', '29'] # Замена совпадений с шаблоном в строке replacement = "XX" new_string = re.sub(pattern, replacement, string) print(new_string) # Сегодня XX мая, завтра XX мая
Теперь вы знаете основы работы с регулярными выражениями в Python и можете использовать их для обработки текста. Удачного кодирования! ��