Мониторинг сети: зачем он нужен, какое выбрать решение и сколько это стоит
Бизнес крупных корпораций сегодня целиком зависит от здоровья ИТ-инфраструктуры. Поэтому сообщения о сбоях в работе банков, мобильных операторов, сервисных служб получают такой резонанс — несколько минут простоя могут стоить компании очень дорого. В том, как снизить риски возникновения аварийных ситуаций в работе бизнес-приложений и быстро найти причины сбоев, CNews помог разобраться Иван Орлов, эксперт по мониторингу сетевой инфраструктуры ИТ-компании КРОК.
Зачем мониторить сеть
Большинство современных бизнес-процессов оцифрованы и связаны с работой ИТ-систем, таких как ERP, CRM, «1С», мобильный клиент и т.д. Поэтому любые сбои в ИТ-инфраструктуре влекут за собой финансовые и репутационные потери для бизнеса. Даже без крупных инцидентов в пересчете на месяц или год компания может увидеть значительные убытки от простоев, низкой продуктивности, недополученной прибыли, связанных с нестабильной работой систем. Решения для мониторинга сетевой инфраструктуры проактивно оповещают ответственные службы о том, что происходит в сети компании, чтобы специалисты могли предотвратить возможные сбои. На разном уровне такие инструменты сегодня реализованы во всех крупных корпорациях со сложной ИТ-инфраструктурой. Однако с ростом числа бизнес-приложений и, как следствие, нагрузки на сеть, требования к решениям мониторинга тоже растут.
Какие решения для мониторинга есть на рынке
Решения для мониторинга сети можно разделить условно на три класса. Первый — это различные open source-программы, которые можно скачать и использовать бесплатно. Но, как и многие бесплатные продукты, они поставляются не в «коробочном» виде и требуют тонкой настройки под конкретные задачи, что, в свою очередь, требует наличия в штате квалифицированных специалистов. При этом специалисту не стоит забывать, что вся ответственность за работу решения в данном случае лежит на нем, а компании — что специалист может сменить место работы и разобраться в его настройках будет очень непросто.
«Использование open source-программ вполне оправдано при решении базовых задач мониторинга, к примеру — состояния конкретного порта коммутатора, мониторинга не бизнес критичных сервисов, или в том случае, когда нужен какой-то кастомизированный подход», — объясняет Иван Орлов, эксперт по мониторингу сетевой инфраструктуры ИТ-компании КРОК.
Второй класс решений — это инструменты мониторинга, включенные в состав продуктов других производителей. К примеру, компании-поставщики средств виртуализации, а также оборудования сетевой инфраструктуры, предлагают уже готовые системы мониторинга под их решения.
«Это профессиональный продукт, за разработку и поддержку которого отвечает производитель, опираясь на лучшие мировые практики. Нет явной необходимости что-то дописывать или изобретать — включил и работает. Но нужно понимать, что функциональность такого решения может быть ограничена работой только с определенным набором оборудования или систем», — говорит Иван Орлов.
Третий класс — это специализированные NPMD-решения (network performance monitoring and diagnostic) enterprise уровня. Их производители сфокусированы и специализируются на разработке продуктов для глубокого анализа производительности сетевой инфраструктуры и предлагают наиболее функциональные решения на рынке.
«NPMD уровня enterprise — это не просто анализ состояния сети с точки зрения ее скорости или задержек, это инструмент мониторинга качества работы бизнес-приложений с точки зрения сетевого взаимодействия ее участников. Сети будущего — это сети, ориентированные на приложения. А мониторинг сети, ориентированный на приложения, — это уже настоящее», — объясняет Иван Орлов.
Как работает NPMD уровня enterprise
Зачастую в компаниях нет единой точки сетевого мониторинга, которая могла бы показать, где конкретно произошел или может произойти сбой. И если такая ситуация
случается, на поиск первопричины тратится критично много времени. Основное преимущество NPMD-решений в том, что они позволяют собирать и анализировать не только потоки данных (как встроенные вендорские и open source-решения), но и пакетные данные приложений внутри компании. Благодаря пакетному анализу сети мы можем увидеть не только показатели состояния инфраструктуры, но и метрики качества работы приложений с точки зрения каждой пользовательской операции, сессии, времени отклика баз данных, серверов приложения, a также времени прохождения запроса по сети, детали пользовательского запроса и ответа и т.д. Это дает точное понимание, какое влияние ИТ-инфраструктура оказывает на работу бизнес-приложений. Если у компании есть такой инструментарий, обнаружение и предотвращение аварийных ситуаций становится гораздо проще и не оказывает драматического влияния на бизнес-процессы.
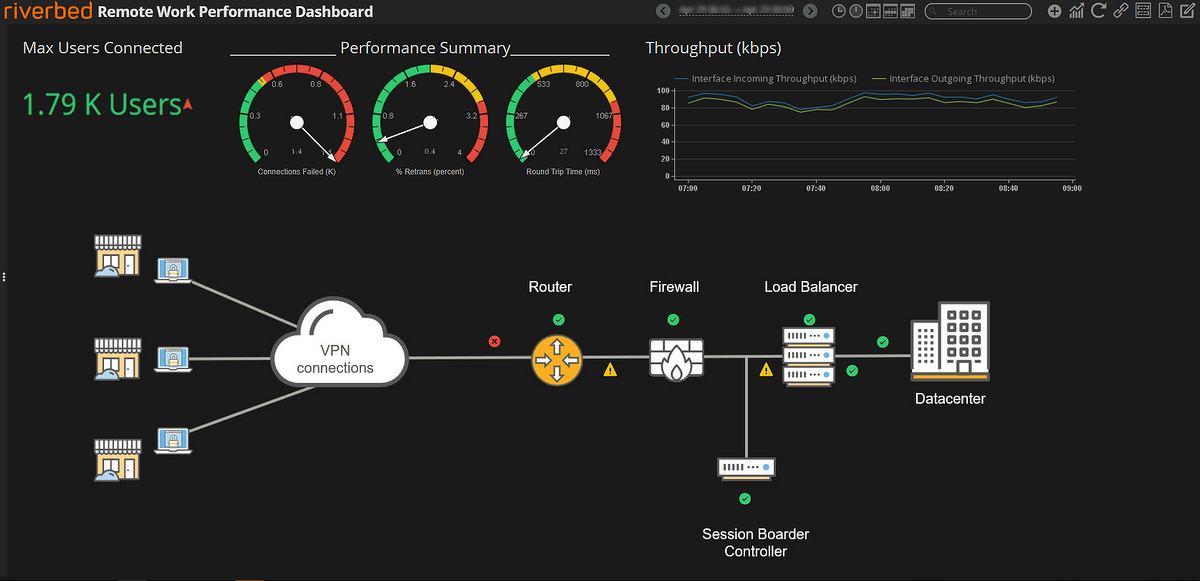
«Возьмем ERP систему, которая состоит из нескольких основных компонентов — базы данных, веб-портала, приложения для пользователей. И если приложение для пользователей начинает работать медленно, то с помощью стандартных средств мониторинга невозможно будет увидеть, на каком участке системы есть проблема. Базовое решение покажет лишь то, что приложение запущено, осуществляется обмен информацией и все работает. Система класса NPMD анализирует информацию обо всех сетевых взаимодействиях и может показать на каком участке произошел сбой — на уровне конкретного пользователя, конкретной сессии с конкретным компонентом приложения. После этого проблемой сразу займется профильный ИТ-отдел, что в несколько раз ускорит ее решение», — приводит пример Иван Орлов.
Вендоры NPMD-решений и востребованность на российском рынке
На мировом рынке решений для мониторинга производительности сети уже несколько лет лидирует тройка вендоров, наиболее известным из которых в России для конечного потребителя является компания Riverbed — это самый давний игрок на отечественном рынке NPMD. Решения этого производителя в нашей стране используют ведущие компании из банковской, страховой, нефтегазовой, горнодобывающей, промышленной и других отраслей со сложной и дорогостоящей ИТ-инфраструктурой, от которой зависит жизнеспособность бизнеса.
«Цифровая трансформация, которую мы сейчас наблюдаем, прогнозирует рост и потребность решений, обеспечивающих мониторинг сети. При этом фокус смещается в сторону сбора и аналитики больших данных, мониторинга автоматизации процессов и облачных технологий. С помощью поведенческого анализа ИТ-систем компании стремятся к проактивности и быстрой реакции на инциденты для более эффективного решения проблем», — говорит Андрей Серебряков, коммерческий директор компании Riverbed в России, СНГ и Центральной Европе.
Стоимость NPM-решений сильно варьируется в зависимости от задач компании — насколько всесторонне и масштабно она планирует анализировать производительность сетевой инфраструктуры. Разбег может быть от нескольких десятков тысяч долларов. При этом есть несколько сценариев внедрения продуктов класса NPMD. Компания может начать внедрять решения для мониторинга выборочно, определив наиболее бизнес-критичные приложения и в дальнейшем масштабировать их. Это позволит избежать больших единовременных капитальных затрат и планомерно распределить нагрузку на ответственных специалистов. А при наличии ресурсов организация вполне может пойти по пути реализации единого крупного проекта и, при должном внимании, выстроить полноценную систему мониторинга ИТ-инфраструктуры, которая охватит все бизнес-процесс компании.
Оставить заявку на консультацию, подбор решения или расчет стоимости проекта можно по электронному адресу: DTKmarketing@croc.ru
Виновата сеть? Нагрузочный Мониторинг Сети
Часто причиной плохого качества обслуживания посетителей фронт-офиса являются сбои в работе бизнес-приложений, являющиеся, в свою очередь, следствием плохой работы сети (в частности, низким качеством услуг ISP, NSP). Чтобы в этом убедиться или, наоборот, «реабилитировать» сеть, нужно контролировать качество её работы и уметь аргументировано предъявить претензии провайдеру сетевых услуг.
Существует множество технологий решения этой задачи. В данной статье я расскажу о технологии Нагрузочного Мониторинга Сети. Эта технология (наряду с другими технологиями, в частности, Cisco IP SLA) поддерживается всеми продуктами ProLAN, и прозрачно интегрируется с решениями: Кнопка Помощи ITSM, Кнопка Лояльности, Пятый Уровень, Терминал Обратной Связи и другими. Данная технология может использоваться для мониторинга любых сетей. Однако наибольшую ценность она представляет для мониторинга сетей, в которых каналообразующее оборудование не поддерживает технологию IP SLA.
Нагрузочный Мониторинг Сети – это регулярное измерение эффективной пропускной способности сети (network throughput), выполняемое методом генерации в сеть TCP-трафика с заданными параметрами и измерении фактически переданного/принятого объёма данных.
Используйте Нагрузочный Мониторинг Сети для решения следующих задач:
- Аудит производительности каналов связи, в том числе арендуемых у провайдеров сетевых услуг (ISP, NSP). Такой аудит можно проводить:
- Регулярно, например, 2 раза в сутки, для контроля качества получаемых услуг.
- По требованию, например, для оптимизации параметров настройки каналообразующего оборудования.
- Во время сдачи (приёмки) сети или при возникновении конфликтов с провайдером сетевых услуг.
Не просто измеритель, а элемент Service Level Management
Отличие Нагрузочного Мониторинга Сети от тестирования сети с помощью Iperf, pathrate, chariot и других подобных средств в том, что Нагрузочный Мониторинг позволяет не только измерять пропускную способность сети, но и является важным элементом системы управления качеством предоставления ИТ-Услуг (Service Level Management). С технической точки зрения это означает следующее:
- Измерение пропускной способности сети может выполняться не только по требованию (разово), но и на постоянной основе. При этом постоянное измерение пропускной способности не влияет на работу пользователей сети (Автоматическое управление генерацией трафика; подробнее ниже).
- Результаты измерений в режиме реального времени могут экспортироваться в любую систему управления, поддерживающую SNMP.
- ГЛАВНОЕ. Все измеряемые метрики: жалобы пользователей (фиксируются Кнопкой Помощи ITSM), время реакции бизнес-приложений (измеряется Пятым Уровнем), пропускная способность сети, а также метрики, характеризующие здоровье всех компонент ИТ-Инфраструктуры (утилизация, доступность, число ошибок, jitter, delay, packet loss и т.п.), измеряемые продуктами семейства ProLAN SLA-ON (Администратор, Аналитик, Эксперт), привязываются к единой временной шкале. Это позволяет, с одной стороны, быстро определять корневые причины жалоб пользователей и сбоев в работе бизнес-приложений, с другой стороны, быстро диагностировать причины низкой пропускной способности сети.
В линейке решений ProLAN Нагрузочный Мониторинг Сети является связующим звеном между решениями Кнопка Помощи ITSM и Пятый Уровень, контролирующими удовлетворённость пользователей ИТ-Сервисов и производительность бизнес- приложений, и системами управления здоровьем ИТ-Инфраструктуры ProLAN: Администратор, ProLAN: Аналитик; ProLAN: Эксперт. Приобретая любой из этих продуктов, вы сможете проводить Нагрузочный Мониторинг Сети.
Как это работает
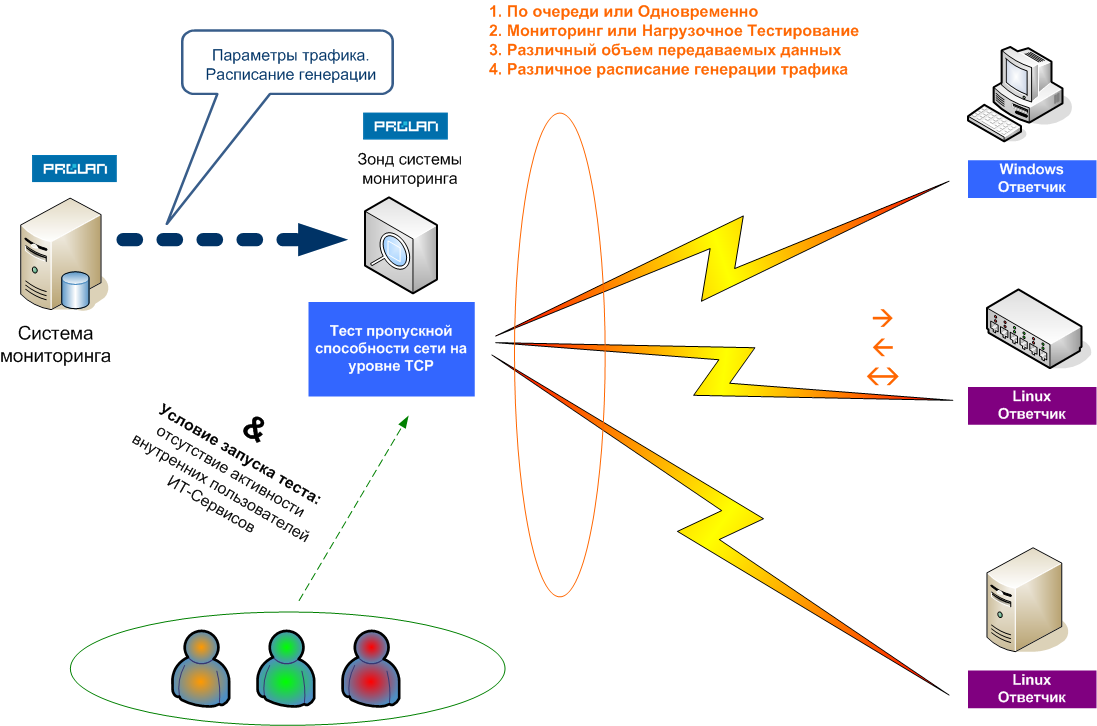
Для проведения Нагрузочного Мониторинга Сети используется Тест пропускной способности сети на уровне TCP, входящий в состав всех продуктов семейства ProLAN SLA-ON (Администратор, Аналитик, Эксперт), в том числе в состав бесплатного продукта QuTester Plus.
Тест пропускной способности сети на уровне TCP – это VB-скрипт, выполняемый на Зонде. Зонд – компьютер, работающий под управлением любой версии MS Windows, на котором выполняется служба MS Windows SLA-ON Probe. Работа Теста основана на генерации TCP-Трафика между Зондом и Ответчиками, и измерении объёма передаваемых и принимаемых данных. Ответчик – это служба Linux или Windows, которая может работать на серверах или встраиваться в активное оборудование.
SLA-ON Probe входит в состав любого продукта семейства ProLAN SLA-ON (Администратор, Аналитик, Эксперт), но может использоваться и в составе любой системы управления, поддерживающей SNMP, т.к. позволяет экспортировать результаты измерений (пропускную способность и другие метрики) по SNMP. Для этого SLA-ON Probe поддерживает private MIB ProLAN.
Параметры настройки Теста пропускной способности сети
- Генерация трафика может выполняться между Зондом и Ответчиками по очереди или одновременно.
- Поддерживаются два режима генерации: Мониторинг Сети и Нагрузочное Тестирование. В первом случае, между Зондом и Ответчиком с заданной периодичностью передаётся массив данных фиксированного размера (от 1 МБ до 100 МБ). Во втором случае между Зондом и Ответчиком (или Ответчиками) в течение определённого периода времени выполняется передача данных с максимально возможной интенсивностью.
- Размер блока данных, которыми осуществляется обмен между Зондом и Ответчиками.
- Направление передачи данных:
- Только от Зонда к Ответчику.
- Только от Ответчика к Зонду.
- Одновременно в обоих направлениях.
- Сначала в одном направлении, потом в другом направлении.
- Использовать или не использовать при передаче данных алгоритм Найгла.
- Контролировать или не контролировать доступность Ответчиков по UDP.
- Время ожидания при невыполнении условий генерации (см. ниже).
Измеряемые характеристики
№ Характеристика Описание 1 READ (Mbps, %) Пропускная способность сети при передаче данных от Ответчика к Зонду. Во всех случаях одновременно измеряется абсолютная и относительная (относительно установленного значения) пропускная способность. 2 WRITE (Mbps, %) Пропускная способность сети при передаче данных от Зонда к Ответчику. 3 RD-WR (Mbps, %) Пропускная способность сети при встречной передаче данных между Зондом и Ответчиком. 4 TOTAL (Mbps, %) Общая пропускная способность сети при одновременной передаче данных между Зондом и несколькими Ответчиками. В зависимости от направления передачи данных может быть: TOTAL READ, TOTAL WRITE, TOTAL RD-WR. 5 AVERAGE (Mbps, %) Средняя пропускная способность сети при поочерёдной передаче данных между Зондом и несколькими Ответчиками. В зависимости от направления передачи данных может быть: AVERAGE READ, AVERAGE WRITE, AVERAGE RD-WR. 6 Responder Availability (%) Доступность Ответчиков по UDP. Проверка доступности Ответчиков может быть отключена. 7 TCP Link Availability (%) Доступность TCP-канала. TCP-канал считается недоступным, когда при доступности Ответчика UDP с ним невозможно установить связь по TCP и во время передачи данных происходит разрыв связи между Ответчиком и Зондом. Автоматическое управление генерацией трафика
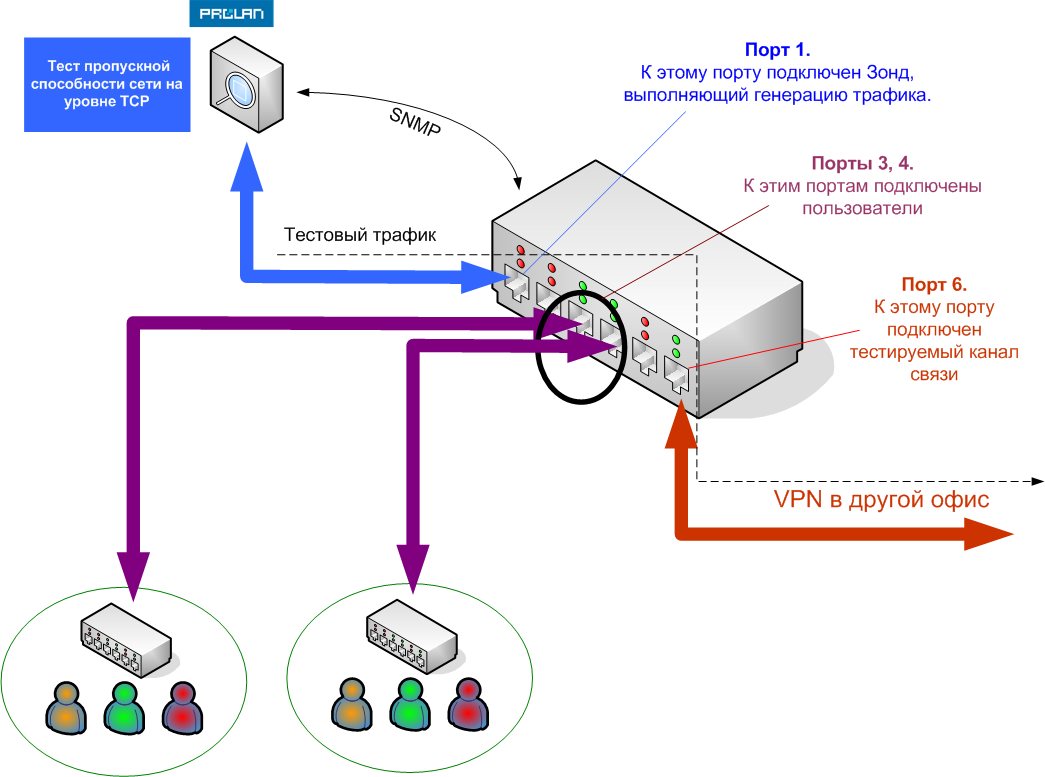
Поскольку тестовый трафик может оказывать негативное влияние на работу пользователей сети, в Тесте пропускной способности сети на уровне TCP предусмотрена возможность автоматического управления генерацией трафика в зависимости от активности внутренних пользователей. Поясним это на примере.
Предположим, тестируется канал связи, подключённый к 6-му порту маршрутизатора; см. Рисунок 2. При этом Зонд подключён к 1-му порту, а пользователи – к 3-му и 4-му портам. Предположим, Тест пропускной способности сети должен с 9-00 до 20-00 каждый час передавать 1 Мбайт данных от Ответчика к Зонду.
Если управление генерацией трафика включено, тест начнёт генерацию трафика только в том случае, если утилизация портов 3 и 4 будет меньше определённого значения, например, 5%. Если в то время, когда должна начаться генерация трафика, это условие не выполняется, то Тест не начнёт генерацию, а будет ждать определённое время. Если он так и не дождётся снижения утилизации до 5%, то генерация будет отложена следующего часа. Начав генерацию трафика, Тест продолжает контролировать утилизацию портов 3, 4, и если она окажется выше 5%, то прекратит генерацию, зафиксирует конфликт, и аннулирует результаты данного измерения. Условия, разрешающие/запрещающие генерацию трафика могут быть различными (не только утилизация портов). Режим управления генерацией трафика можно отключить.
Ключевые преимущества
1. Достоверность результатов аудита сети
Управление генерацией трафика позволяет, с одной стороны, автоматизировать измерение пропускной способности сети, с другой стороны, проводить замеры только в периоды низкой активности пользователей. Это обеспечивает высокую репрезентативность и достоверность получаемых результатов.
2. Экономичность мониторинга сети
Здоровье сети характеризуется множеством метрик – утилизация, ошибки, джиттер, число потерянных пакетов и т.д. Значения этих метрик влияют на пропускную способность сети, поэтому выход любой из них за допустимый диапазон значений вызывает снижение пропускной способности сети. Таким образом, чтобы узнавать о проблемах до того, как они скажутся на работе пользователей, достаточно контролировать пропускную способность сети, что дешевле, проще и удобнее, чем контролировать множество «сырых» метрик.
3. Возможность быстро «реабилитировать» сеть
Жалобы пользователей, фиксируемые Кнопкой Помощи ITSM, и производительность сети, измеряемая в рамках Нагрузочного Мониторинга Сети, всегда привязаны к единой временной шкале. Поэтому, чтобы реабилитировать сеть, достаточно убедиться, что в момент жалобы пользователя (нажатия им «красной кнопки») пропускная способность сети была нормальной.
Заинтересовало? Три варианта применения
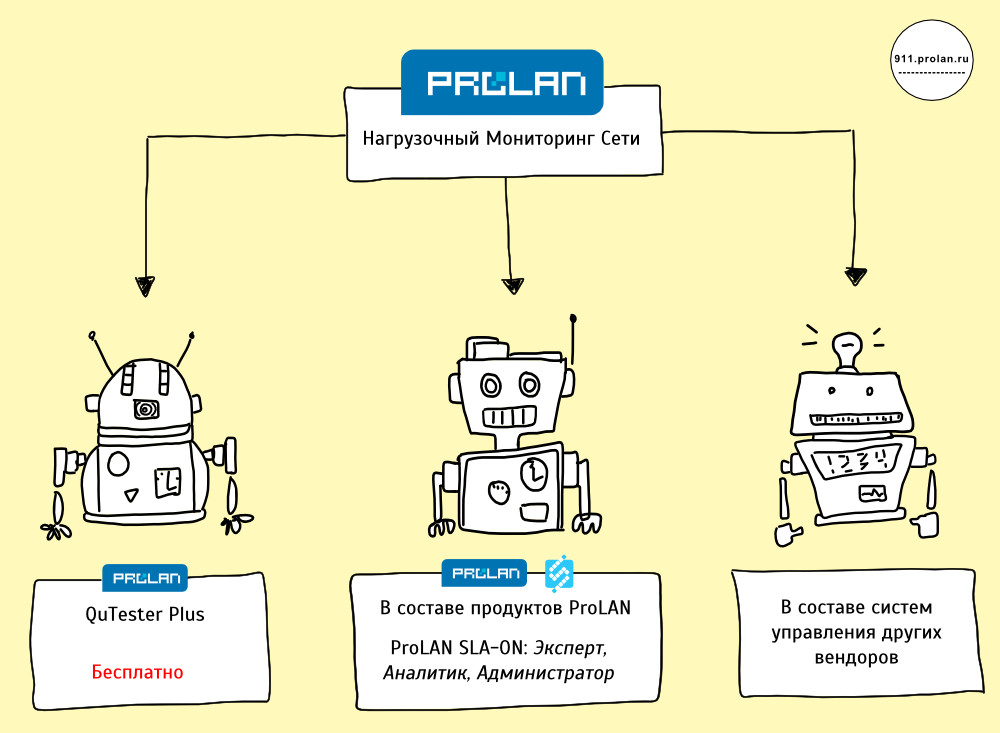
- Если вы администрируете небольшую сеть, загрузите бесплатный продукт QuTester Plus. Он позволит вам проводить Нагрузочный Мониторинг Сети со следующими ограничениями:
- Вы не сможете единовременно тестировать более одного канала связи.
- Вы сможете одновременно запускать не более трёх Оценочных Тестов (Экспертиз), при этом общее число измеряемых метрик не должно превышать 150. Это несколько ограничивает возможность быстро определять причины низкой пропускной способности.
- Не отображается история результатов измерений. Отображаются только текущие значения измеряемых метрик и история оценок (светофоров).
- Если вы являетесь пользователем какого-то продукта семейства ProLAN SLA-ON (Администратор, Аналитик, Эксперт), то чтобы проводить Нагрузочный Мониторинг сети сделайте upgrade используемого продукта (загрузите Тест пропускной способности сети на уровне TCP).
- Если для управления ИТ-Инфраструктурой вы используете продукты других производителей (не компании ProLAN), то для проведения Нагрузочного Мониторинга Сети необходимо интегрировать SLA-ON Probe в используемую систему. Это сделать относительно несложно, т.к. SLA-ON Probe позволяет экспортировать результаты измерений по SNMP. Необходимые инструкции по интеграции вы получите после приобретения продукта SLA-ON Probe. Если вы затрудняетесь сделать интеграцию самостоятельно, она может быть выполнена специалистами ProLAN на возмездной основе.
Inperfo – минималистичный мониторинг сети

В первую очередь Inperfo предназначен для мониторинга сетевых интерфейсов на свитчах и роутерах. Конечно же, можно мониторить сетевые интерфейсы непосредственно на серверах, когда, например, у вас нет доступа к сетевому оборудованию, но есть десятки или сотни арендуемых серверов (физических или виртуальных).
Сервис предназначен для мониторинга именно физических Ethernet-интерфейсов. Что, кстати, позволяет видеть перекосы трафика в Port Channel’ах при неверной настройке или каких-то других проблемах. Если у вас другие задачи, и нужно мониторить и другие типы интерфейсов, то посмотрите в сторону Observium’a и собратья (LibreNMS, NetXMS, etc) или на SolarWind NPM.
Основной целью создания сервиса было желание видеть топы по загрузке интерфейсов, ошибкам, чтобы все проблемные или потенциально проблемные места были как на ладони. В zabbix’e или cacti сделать такой динамический скрин мягко говоря проблематично. К тому же хотелось иметь топ по истории за неделю, а не в текущий момент – неделя, оптимальный вариант для многих сетей, когда нагрузка растёт после выходных и снижается к концу недели, или же наоборот – в выходные пики, а будние дни нагрузка ниже.
И вторая не менее важная цель — минималистичный интерфейс без излишних наворотов, сложностей и финтиплюшек. Подойдёт и понравится не всем, да.
Сервис решает 3 задачи
- Показывает «узкие» места сети. Это может быть перегруженный в час пик аплинк access-свитча в distribution level. Или же перегруженный порт до backup или memcached-сервера. Можно отдельно назначить интерфейсы как внутренние или внешние аплинки, чтобы видеть их в отдельном топе. Все графики строятся по максимумам – недельные, месячные и годовые графики не усредняются.
- Показывает ошибки на интерфейсах, для удобства группируя данные по хостам и датацентрам, отображая топ ошибок со всех устройств. Ошбики в таблице хостов и интерфейсов – сумма за неделю, на графиках – ошибок в секунду.
- Отслеживает кол-во свободных и занятых портов на свитчах, что помогает вовремя решать задачи по расширению сети.
И само собой, автоматически отслеживает изменения – переименование интерфейсов, описаний (ifDescr), изменение статуса интерфейса и так далее. Единственная ручная работа – добавление новых устройств или серверов в конфиг агента. Со временем добавится возможность auto discovery, но пока её нет.
Вам точно не подойдёт Inperfo, если вам нужны:
– Мониторинг CPU/Memory
– Мониторинг hdd, temperature и другие не Ethernet-вещи
– Возможность рисовать карты и схемы сетиКомпоненты системы
Сервис состоит из двух компонентов: сервера и агента. Агент собирает snmp-данные об интерфейсах и отправляет их на сервер. Сервер обрабатывает (сортирует, обновляет rrd-файлы и прочая) полученные данные и отображает через web-интерфейс.
Как работает сервер
Сервер — это docker-контейнер со «стандартным» набором софта: nginx/php-fpm/memcached/mysql/rrdtool. Сервер ожидает, что агенты будут присылать данные каждые 5 минут. Данные сохраняются в базе – по нагрузке интерфейсов и ошибкам ведётся недельная history, по которой рассчитываются 95-й перцентиль и топ по max/avg. Сделано это для того, что «видеть» сеть в разных «разрезах» – без редких всплесков или наоборот, когда нужно посмотреть только всплески.
Данные контейнера хранятся на хостовой системе для удобства обновления, бекапа и переноса сервера на другие хосты. Обновиться можно буквально одной командой (идея взята у докера, см. https://get.docker.com)
Как работает агент
Агент – это тоже docker-контейнер, в котором по крону раз в 5 минут запускается агент, собирающий snmp-данные об интерфейсах с сетевых устройств или серверов. Пока что интервал обновления (опроса) устройств изменить нельзя.
Клиент поддерживает две версии SNMP – v2 и v3.
Конфигурация агента, логи, и отправляемые данные хранится на хостовой системе. Это позволяет легко редактировать конфиги, переносить агента на другие хосты при необходимости.
Сценарии использования
Мониторим сетевое оборудование
В идеале нам нужно установить и настроить по одному агенту на каждый из дата центров или удалённых офисов, чтобы агент мог локально опрашивать устройства внутри дата центра по snmp и отправлять собранные данные на центральный сервер, который может находится в одном из датацентров или где-нибудь в облаке (Amazon, DigitalOcean, Azure, etc).
Если же у вас один дата центр или есть «быстрые» линки до остальных ДЦ, то достаточно установить сервер и агента на одной и той же linux-машине, с которой и будут опрашиваться все устройства сети. Или, например, на той же машине, где у вас уже стоит cacti – не нужно будет настраивать snmp-доступ на сетевом оборудовании (если он у вас есть 🙂
Основной «минус» этой схемы: нужен snmp-доступ к сетевому оборудованию.
Мониторим сетевые интерфейсы на серверах
Для мониторинга сетевых интерфейсов на серверах нам нужно на каждый из них установить snmp-демона, например, через ansible-playbook. В этом случае каждый linux-сервер для агента будет выглядеть как отдельное сетевое устройство с одним или несколькими сетевыми интерейсами.
- Можно обойтись без доступа к сетевому оборудованию
- Можем довольно просто автоматизировать установку и настройку мониторинга
Минусы: - Нет capacity по портам (если оно нужно)
- Потребуется ручное добавление новых серверов в конфиг агента
Смешаный режим
Тут всё ясно, можно мониторить и свитчи/роутеры и серверы вместе – агент не различает тип устройства, а информацию по интерфейсам берёт из MIBv2-базы. Кстати, это ещё один минус – если у вас есть девайс, у которого информация по интерфейсам отдаётся с «нестандартных» MIB’ов (например, BTI 7000), то Inperfo, на данный момент, вам не подойдёт.
Производительность
Хорошо себя чувтсвует на «среднем» железе (16CPU/16GB) до 100 устройств (6000+ портов), на большем кол-ве запускать и наблюдать работу пока что не приходилось. Но посколько агент для опроса каждого устройства создаёт отдельный процесс (fork), то golang с go-рутинами просто изнывает и просится в этот кусок кода. Аналогично работает и сервер при получении данных.
Что добавится в следующих версиях
– Указание максимальной скорости для интерфейса. Нужно в ситуациях, когда к провайдеру вы подключены по 1Гб-линку, но оплаченный канал по факту меньше, аля ограничен до 500Мб.
– Еженедельные отчёты по топам на почту.
– Уведомления на почту.
– Отдельная сборка docker-контейнера с сервером и агентом. Для небольших сетей это идеальный вариант. Плюс появится возможность добавлять хосты через web-интерфейс.
– Топы/графики по пакетам
– Поиск по имени устройства, по интерфейсу, по описанию и по алиасу
– Переписать агента и часть сервера на golang.На данных момент сервис не шлёт никаких алертов и прочего, но по URI /export/ можно импортировать данные в тот же заббикс, и получать уведомления. Сервис ещё немного сыроват, но поставленные задачи решает.
Мониторинг и диагностика ИТ-инфраструктуры

Profitap — волоконно-оптические и медные сетевые ответвители трафика, регенерирующие, агрегирующие и bypass ‐тапы (TAP), сетевые пакетные брокеры (NPB), сетевые средства захвата и анализа трафика серий ProfiShark, ProfiSight и IOTA.
Для бесперебойной работы любого бизнеса необходимо наличие эффективного сетевого мониторинга и анализа для выявления проблем в сетях. Неисправности в сети могут вызвать падение её производительности, что, в свою очередь, приведет к огромной потере времени и средств предприятия.
Устройства серии ProfiShark представляют собой специальные портативные сетевые ТАР-устройства для диагностики Ethernet и волоконно-оптических линий связи, мониторинга сети, захвата и анализа трафика. ProfiShark позволяет получить легкий доступ к сети и захватывать каждый пакет с точной отметкой времени. Это обеспечит получение высококачественных данных, которые можно использовать в программном анализаторе пакетов, например, в Wireshark, или сохранять непосредственно на диск для последующего анализа.
IOTA ― это универсальное комплексное решение, объединяющее возможности захвата, хранения и аналитики в одном устройстве. Его можно легко развернуть в любом месте, как в портативном, так и в стоечном исполнении. Линейная схема IOTA изолирована от других интерфейсов, внутреннего хранилища и обработки анализа, обеспечивая целостность контролируемой сети.
Network Packet Broker (NPB) ― это устройство, которое оптимизирует поток трафика между соединениями TAP и SPAN и инструментами мониторинга, безопасности и оптимизации сети. Поддерживая сопоставление портов «многие ко многим» (M: M) сетевых портов с портами мониторинга, NPB могут максимально эффективно направлять сетевой трафик и применять фильтры для оптимизации использования полосы пропускания в сети. Это также означает, что производительность внешних инструментов увеличится, поскольку они получат только самые необходимые данные.
Оптоволоконные ответвители (TAP), разработанные для обеспечения бесперебойного оперативного мониторинга оптоволоконных сетей 1G, 10G, 40G и 100G, отслеживают все 7 уровней OSI, пакеты всех размеров и типов и ошибки нижнего уровня. Не оказывают негативных воздействий, не имеют IP-адресов и изолируют устройства мониторинга от сети для полной безопасности.
Медные Ethernet ответвители легко дублируют полнодуплексный трафик 10M / 100M / 1G / 10G на скорости соединения, что позволяет им просматривать все 7 уровней, включая пакеты всех размеров и типов, а также ошибки нижнего уровня.
TAP регенераторы позволяют использовать для ответвления волоконно-оптическую линию без потери мощности оптического сигнала. TAP регенерации компенсируют потери оптического сигнала, возникающее в результате его расщепления. Регенерируется сигнал как на сетевых, так и на портах мониторинга.
TAP-репликаторы. В ситуациях, когда вы хотите отслеживать один критический сегмент сети с помощью нескольких инструментов, вам нужен TAP-репликации. TAP репликации отправляет копию сетевого трафика нескольким инструментам мониторинга одновременно.
Агрегирующие TAP соединяют МНОГО сетевых портов с ОДНИМ портом мониторинга (M: 1), объединяя несколько потоков входящего в один поток исходящего трафика.
Bypass TAP могут поддерживать активные встроенные средства сетевой безопасности и производительности. Они были разработаны, чтобы избежать проблемы «единой точки отказа» с другими устройствами безопасности.
Profitap vTAP обеспечит полную видимость трафика виртуальных машин (включая трафик между ВМ) для мониторинга безопасности, доступности и производительности.
ProfiSight позволяет быстро просматривать данные потока, извлекая метаданные из захваченного потока пакетов с помощью ProfiShark или других источников файлов захвата. Вы можете получить обзор общего состояния в несколько кликов и определить проблемы безопасности или производительности в сети.