# Программный стек ELK. Часть 1. Elasticsearch
Программный стек ELK — связка из нескольких приложений (Elasticsearch, Logstash, Kibana, Filebeat), позволяющая быстро собирать и обрабатывать всю информацию об обслуживаемой системе.
Elasticsearch — это ядро программного стека ELK, поисковый движок для работы с большими объёмами данных. Он позволяет осуществлять быстрый и эффективный поиск по всему объёму собранных данных. Для сбора системных логов в данной конфигурации стека используется FileBeat, передающий данные в фильтрационную систему Logstash, а для визуализации представляемых данных используется Kibana.
В данной серии инструкций мы рассмотрим установку и настройку всего программного стека ELK на VPS под управлением CentOS или Ubuntu.
Начнём с установки и первичной настройки Elasticsearch. Устанавливать Elasticsearch будем из официальных репозиториев разработчиков на подготовленный к работе VPS с CentOS 8 stream или Ubuntu 20.04. Все необходимые зависимости и дополнительные приложения будут установлены в процессе.
# Установка Elasticsearch
# CentOS
Устанавливать Elasticsearch будем из официального репозитория Elastic. Для этого сначала добавим GPG-ключ на сервер:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch После этого добавим репозиторий в список репозиториев, используемых dnf. Создадим в папке с репозиториями конфигурационный файл, содержащий все сведения о добавляемом источнике:
sudo vi /etc/yum.repos.d/elasticsearch.repo В открывшемся текстовом файле укажем основные параметры устанавливаемого репозитория:
[elasticsearch] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md Здесь мы указали имя, адрес, откуда устанавливать Elasticsearch, и gpg-ключ. В адресе установки мы указали 7.x — 7 версию. Если вы хотите установить более свежую версию, проверьте страницу доступных версий
(opens new window) и укажите номер версии, который хотите установить.
Теперь переходим к установке:
sudo dnf --enablerepo=elasticsearch install elasticsearch Эта команда добавит репозиторий Elasticsearch в список репозиториев, из которых возможна установка, и проверит доступность пакета Elasticsearch, после чего предложит установить его.
В процессе установки Elasticsearch установит дополнительные необходимые зависимости, в том числе необходимые для работы версии Open JDK и JVM.
После завершения установки можно добавить Elasticsearch в автозагрузку и запустить:
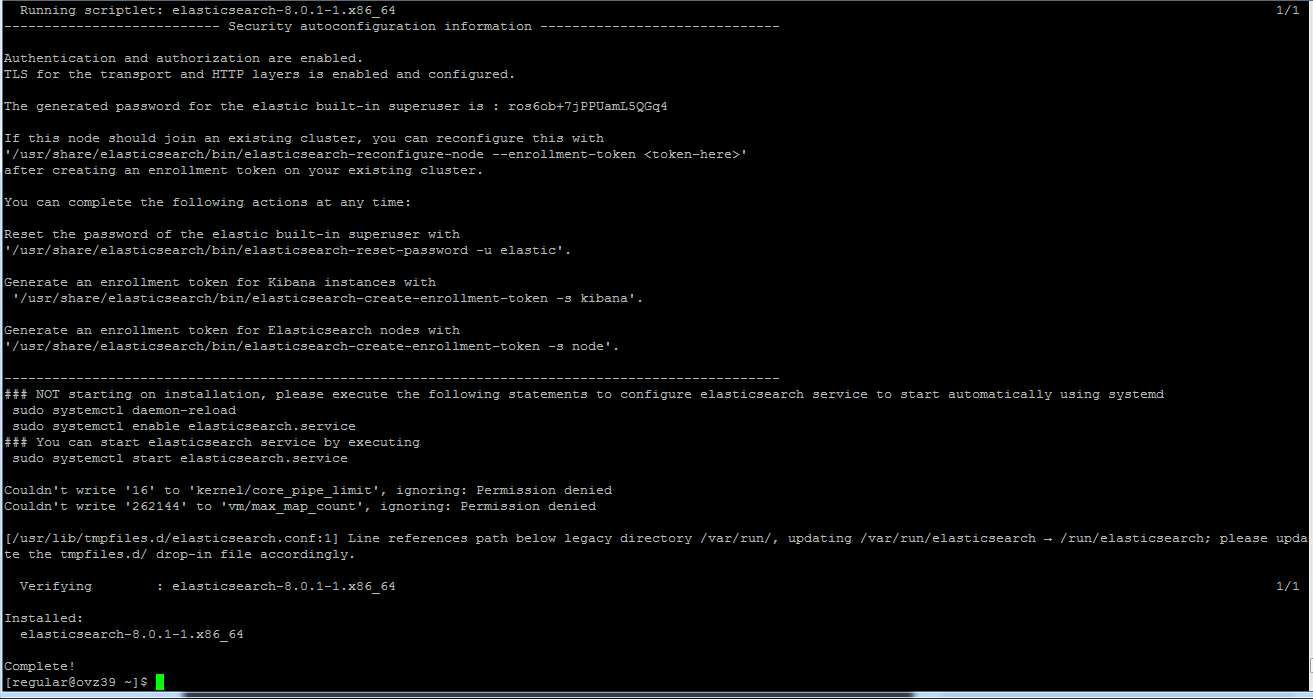
sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service sudo systemctl start elasticsearch.service После этого проверим статус программы:
sudo systemctl status elasticsearch.service Вывод должен быть примерно таким:
# Ubuntu
Последовательность действий при установке Elasticsearch на Ubuntu будет примерно такой же, как и при установке на CentOS. Основное отличие — способ добавления репозитория.
Начнём с добавления gpg-ключа:
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - После этого добавим репозиторий в список репозиториев apt. Для этого можно воспользоваться любым текстовым редактором. Мы используем команду echo :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list Обратите внимание, что в данном случае мы тоже устанавливаем 7 версию Elasticsearch.
После добавления репозитория в список источников apt обновим его и запустим установку:
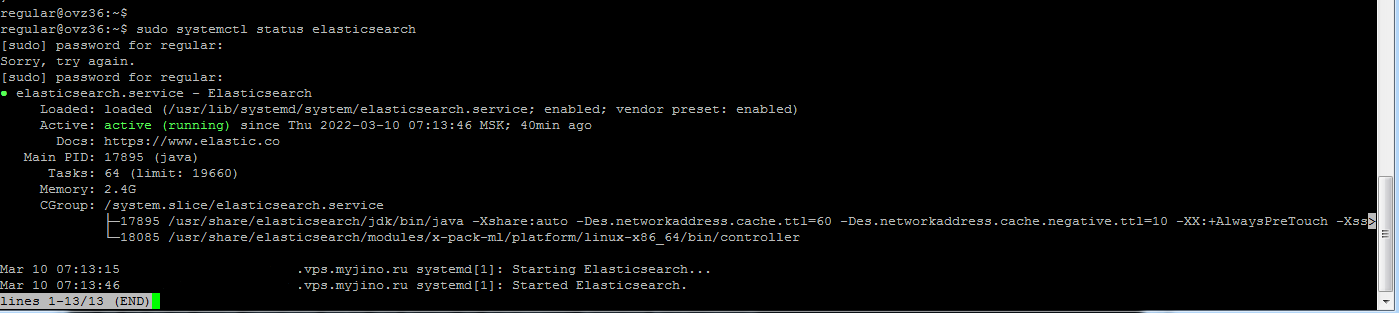
sudo apt update sudo apt install elasticsearch После завершения установки запустим Elasticsearch и проверим его статус, чтобы убедиться, что всё работает верно:
sudo systemctl enable elasticsearch sudo systemctl start elasticsearch sudo systemctl status elasticsearch Если установка прошла как положено, правильные зависимости установились и запустились, и сам Elasticsearch запустился без ошибок, то на экране появится примерно такое сообщение:
# Настройка Elasticsearch
Основные настройки Elasticsearch производятся через конфигурационный файл elasticsearch.yml , файл конфигурации виртуальной машины Java jvm.options и файл журнала Elasticsearch log4j2.properties .
На данном этапе нужно проверить сетевые настройки работы Elasticsearch. Для этого откроем основной конфигурационный файл:
sudo vi /etc/elasticsearch/elasticsearch.yml Найдём здесь блок Network , отвечающий за сетевое соединение Elasticsearch. В качестве хоста указан localhost с номером порта 9200. Оставим именно эти значения, потому что в нашем случае Elastcisearch будет работать только на внутренней машине, доступ к нему будет осуществляться из локальной сети сервера.
В этом же файле в разделе Paths указаны директории хранения логов работы программы и основных данных, с которыми будет работать Elasticsearch. Программный стек будет работать с большими объёмами данных, поэтому размещать их хранилище нужно там, где будет достаточно дискового пространства.
# Проверка работы Elasticsearch
После проверки сетевых настроек и статуса Elasticsearch (active, enabled) проверим непосредственный доступ к приложению.
Сначала проверим правильность его размещения на сервере. Посмотрим, какое приложение занимает порт 9200, указанный в качестве рабочего порта Elasticsearch:
sudo netstat -tulpn | grep 9200 # Output tcp6 0 0 127.0.0.1:9200 . * LISTEN 17895/java Как видим, порт 9200 локального адреса занят java — это виртуальная машина, на которой запущен Elasticsearch.
Теперь отправим к Elasticsearch curl-запрос:
curl -X GET 'http://localhost:9200' Результат выдачи должен быть примерно следующим:
# Output "name" : "localhost_name", "cluster_name" : "elasticsearch", "cluster_uuid" : "-JKGBFLLS5itNHDokWrPzQ", "version" : "number" : "7.17.1", "build_flavor" : "default", "build_type" : "deb", "build_hash" : "e5acb99f822233d62d6444ce45a4543dc1c8059a", "build_date" : "2022-02-23T22:20:54.153567231Z", "build_snapshot" : false, "lucene_version" : "8.11.1", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" >, "tagline" : "You Know, for Search" > Это означает, что Elasticsearch запущен и правильно функционирует, возвращая по запросу свои основные данные.
Теперь можно переходить к следующей части нашей инструкции, в которой мы будем устанавливать компонент для визуализации получаемых данных — Kibana.
© Джино, 2003–2022. «Джино» является зарегистрированным товарным знаком.
Лицензия на телематические услуги связи №150549 от 09.03.2017.
Что такое ELK stack?

Статья также доступна на украинском (перейти к просмотру). Стек ELK (или ELK stack) – это набор программных продуктов, которые используются для сбора, анализа и визуализации данных из лог-файлов и других источников больших объемов данных в реальном времени. ELK – это аббревиатура, состоящая из первых букв названий программных продуктов, входящих в состав этого стека: Elasticsearch, Logstash и Kibana. Продукт разработан компанией Elastic (бывшей Elasticsearch, Inc.). ELK стек часто используют для мониторинга и анализа логов систем, серверов, приложений и сетей для выявления проблем, анализа совершенных действий и реагирования на события в реальном времени. Его можно применить для разработки различных аналитических приложений и отчетов на основе логов. Профессионалы часто называют этот набор «эластичный стек», обыгрывая таким образом название компании-разработчика.
Elasticsearch
- Elasticsearch предоставляет мощные возможности быстрого и эффективного полнотекстового поиска. Он может найти соответствие между запросами пользователя и документами, даже если они содержат большое количество данных;
- инструмент проводит анализ данных, включая агрегацию, фильтрацию, группировку и подсчеты, чтобы получить ценные инсайты;
- Elasticsearch разработан с учетом распределенной архитектуры, позволяющей легко масштабировать систему на много узлов для обработки больших объемов данных и обеспечивает высокую доступность;
- инструмент спроектирован для работы в реальном времени для оперативного обновления данных и получения результатов запросов без значительных задержек.
Elasticsearch – открытое программное обеспечение. Его можно бесплатно использовать и адаптировать к своим потребностям. Кроме того, он поддерживает множество расширений и плагинов для различных задач. Он имеет встроенные возможности для обработки текстовых данных, включая поиск по аналогии, токенизации, стеминг и много других операций для точного и расширенного поиска.
Logstash
Это инструмент для сбора, преобразования и обработки данных из разных источников. Его часто используют вместе с Elasticsearch и Kibana в ELK stack для анализа и визуализации данных.
- Logstash собирает данные из разных источников: лог-файлы, потоки данных, базы данных, метрики системы, системные события и многие другие. Он поддерживает много входных плагинов для разных источников;
- После сбора данных Logstash может выполнять различные операции над ними. В частности, это фильтрация, структурирование, нормализация и обогащение для дальнейшего анализа;
- Logstash поддерживает большое количество исходных плагинов для отправки обработанных данных в различные системы и хранилища, включая Elasticsearch, Apache Kafka, Amazon S3 и многие другие;
- инструмент предоставляет расширенные возможности обработки данных: парсинг регулярных выражений, геопространственный анализ и обработку структурированных форматов данных JSON и CSV.
Logstash дает гибкие возможности конфигурации. Пользователи могут определить, как данные нужно собрать и обработать.
Kibana
Это инструмент для рендеринга и анализа данных. Он используется для создания графиков, дашбордов и отчетов на основе данных, хранящихся в Elasticsearch. Kibana позволяет пользователям интерактивно визуализировать и анализировать данные, делать запросы и получать визуальные инсайты.
Основные функции и характеристики:
- Kibana дает возможность создавать различные типы визуализаций: линейные графики, столбчатые диаграммы, колеса подписей, графики рассеяния и другие;
- пользователи могут объединять различные визуальные компоненты (графики, таблицы, метрики) на дашбордах для создания комплексных интерактивных панелей для мониторинга и анализа данных;
- Kibana дает возможность пользователям фильтровать данные по разным параметрам, чтобы исследовать конкретные аспекты данных или событий;
- доступные инструменты для анализа данных, включая отображение и отслеживание изменений во времени, расчет агрегатов, фильтрацию и сортировку;
- Kibana поддерживает создание карт и географических визуализаций для анализа информации, содержащей геоданные.
Инструмент поддерживает систему ролей, позволяющую администраторам контролировать доступ к функциональности и данным.
Преимущества и недостатки ELK stack
- все компоненты стека — открытые программы, поэтому можно бесплатно их использовать и адаптировать под свои нужды;
- ELK стек легко масштабируется, что позволяет добавлять новые узлы для обработки большего объема данных;
- ELK stack поддерживает обработку данных в реальном времени, что позволяет выявлять проблемы и анализировать события немедленно;
- стек можно масштабировать горизонтально, чтобы соответствовать растущим объемам данных и требованиям пользователей;
- ELK stack можно настроить в соответствии с различными случаями использования, от ИТ-операций и аналитики безопасности до маркетинговых исследований.
- настройка и развертывание ELK stack достаточно сложная;
- набор программных продуктов требует больших объемов вычислительных ресурсов и памяти для эффективной работы с большими объемами данных;
- для максимальной пользы от стека ELK нужно иметь навыки в анализе данных и разработке дашбордов;
- система требует постоянного мониторинга и обслуживания.
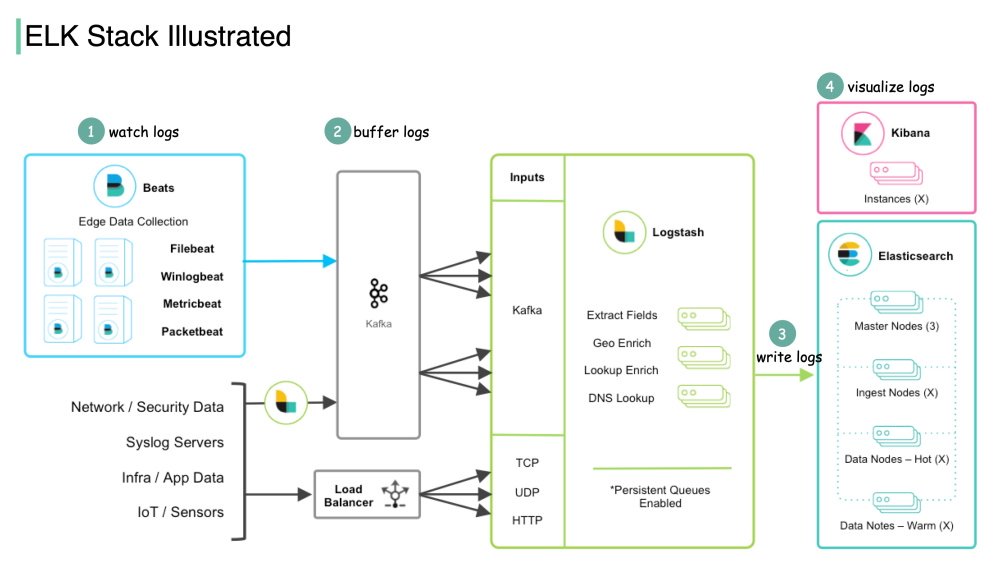
Как работает стек ELK?
ELK Stack применяет простой, но мощный рабочий процесс для преобразования необработанных данных в ценную информацию.
Передача
Logstash собирает данные из многих источников, включая файлы журналов, базы данных, API и очереди сообщений. Затем он анализирует, фильтрует и обогащает данные в соответствии с конфигурациями, определенными пользователем.
Хранение
Обработанные данные посылаются в Elasticsearch для хранения и индексации. Elasticsearch эффективно сохраняет данные в распределенном формате на основе JSON, что упрощает их поиск. сохраняет данные в распределенном формате на основе JSON, что облегчает их поиск.
Визуализация
Kibana подключается к Elasticsearch и позволяет пользователям создавать собственные визуализации и информационные панели. Пользователи могут выполнять специальный поиск, применять фильтры и подробно изучать конкретные точки данных для получения статистики.
Варианты использования
Первоначально ELK stack использовали только для анализа логов и мониторинга систем. В течение многих лет он стал популярным инструментом для различных задач, включая вебаналитику, обработку событий, безопасность, аналитику приложений и многое другое. Elastic также предоставила коммерческие решения и поддержку организациям, которые ищут расширенные возможности и поддержку.
Сейчас ELK Stack применяют в разных отраслях и областях:
- ИТ-операции. Отслеживание производительности системы, выявление аномалий и решение проблем в реальном времени.
- Безопасность. Анализ журналов с целью выявления угроз и предупреждения изломов.
- Бизнес-аналитика. Визуализация и анализ бизнес данных с целью принятия взвешенных решений и отслеживания ключевых показателей эффективности.
- DevOps. Получение информации о производительности приложений и оптимизация процессов разработки и развертывания.
В общем, ELK stack – это мощный и гибкий инструмент для сбора, анализа и визуализации данных, который находит применение во многих отраслях. Он имеет активное сообщество пользователей и много ресурсов для обучения и поддержки.
1.Elastic stack: анализ security логов. Введение

В связи окончанием продаж в России системы логирования и аналитики Splunk, возник вопрос, чем это решение можно заменить? Потратив время на ознакомление с разными решениями, я остановился на решении для настоящего мужика — «ELK stack». Эта система требует времени на ее настройку, но в результате можно получить очень мощную систему по анализу состояния и оперативного реагирования на инциденты информационной безопасности в организации. В этом цикле статей мы рассмотрим базовые (а может и нет) возможности стека ELK, рассмотрим каким образом можно парсить логи, как строить графики и дашбоарды, и какие интересные функции можно сделать на примере логов с межсетевого экрана Check Point или сканера безопасности OpenVas. Для начала, рассмотрим, что же это такое — стек ELK, и из каких компонентов состоит.
«ELK stack» — это сокращение от трех проектов с открытым исходным кодом: Elasticsearch, Logstash и Kibana. Разрабатывается компанией Elastic вместе со всеми связанными проектами. Elasticsearch — это ядро всей системы, которая сочетает в себе функции базы данных, поисковой и аналитической системы. Logstash — это конвейер обработки данных на стороне сервера, который получает данные из нескольких источников одновременно, парсит лог, а затем отправляет в базу данных Elasticsearch. Kibana позволяет пользователям визуализировать данные с помощью диаграмм и графиков в Elasticsearch. Также через Kibana можно администрировать базу данных. Далее более детально рассмотрим каждую систему отдельно.

Logstash
Logstash – это утилита для обработки лог событий из различных источников, с помощью которой можно выделить поля и их значения в сообщении, также можно настроить фильтрацию и редактирование данных. После всех манипуляций Logstash перенаправляет события в конечное хранилище данных. Утилита настраивается только через конфигурационные файлы.
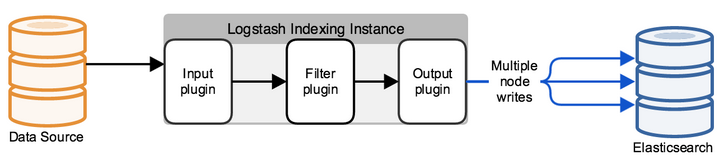
Типичная конфигурация logstash представляет из себя файл(ы) состоящий из нескольких входящих потоков информации (input), несколько фильтров для этой информации (filter) и несколько исходящих потоков (output). Выглядит это как один или несколько конфигурационных файлов, которые в простейшем варианте (который не делает вообще ничего) выглядит вот так:
input < >filter < >output
В INPUT мы настраиваем на какой порт будут приходить логи и по какому протоколу, либо из какой папки читать новые или постоянно дозаписывающиеся файлы. В FILTER мы настраиваем парсер логов: разбор полей, редактирование значений, добавление новых параметров или удаление. FILTER это поле для управления сообщением которое приходит на Logstash с массой вариантов редактирования. В output мы настраиваем куда отправляем уже разобранный лог, в случае если это elasticsearch отправляется JSON запрос, в котором отправляются поля со значениями, либо же в рамках дебага можно выводить в stdout или записывать в файл.
ElasticSearch
Изначально, Elasticsearch – это решение для полнотекстового поиска, но с дополнительными удобствами, типа легкого масштабирования, репликации и прочего, что сделало продукт очень удобным и хорошим решением для высоконагруженных проектов с большими объемами данных. Elasticsearch является нереляционным хранилищем(NoSQL) документов в формате JSON, и поисковой системой на базе полнотекстового поиска Lucene. Аппаратная платформа — Java Virtual Machine, поэтому системе требуется большое количество ресурсов процессора и оперативки для работы.
Каждое приходящее сообщение, как с Logstash или с помощью API запроса, индексируется как “документ” – аналог таблицы в реляционных SQL. Все документы хранятся в индексе – аналог базы данных в SQL.
Пример документа в базе:
Вся работа с базой данных строится на JSON запросах с помощью REST API, которые либо выдают документы по индексу, либо некую статистику в формате: вопрос — ответ. Для того чтобы все ответы на запросы визуализировать была написана Kibana, которая представляет из себя веб сервис.
Kibana
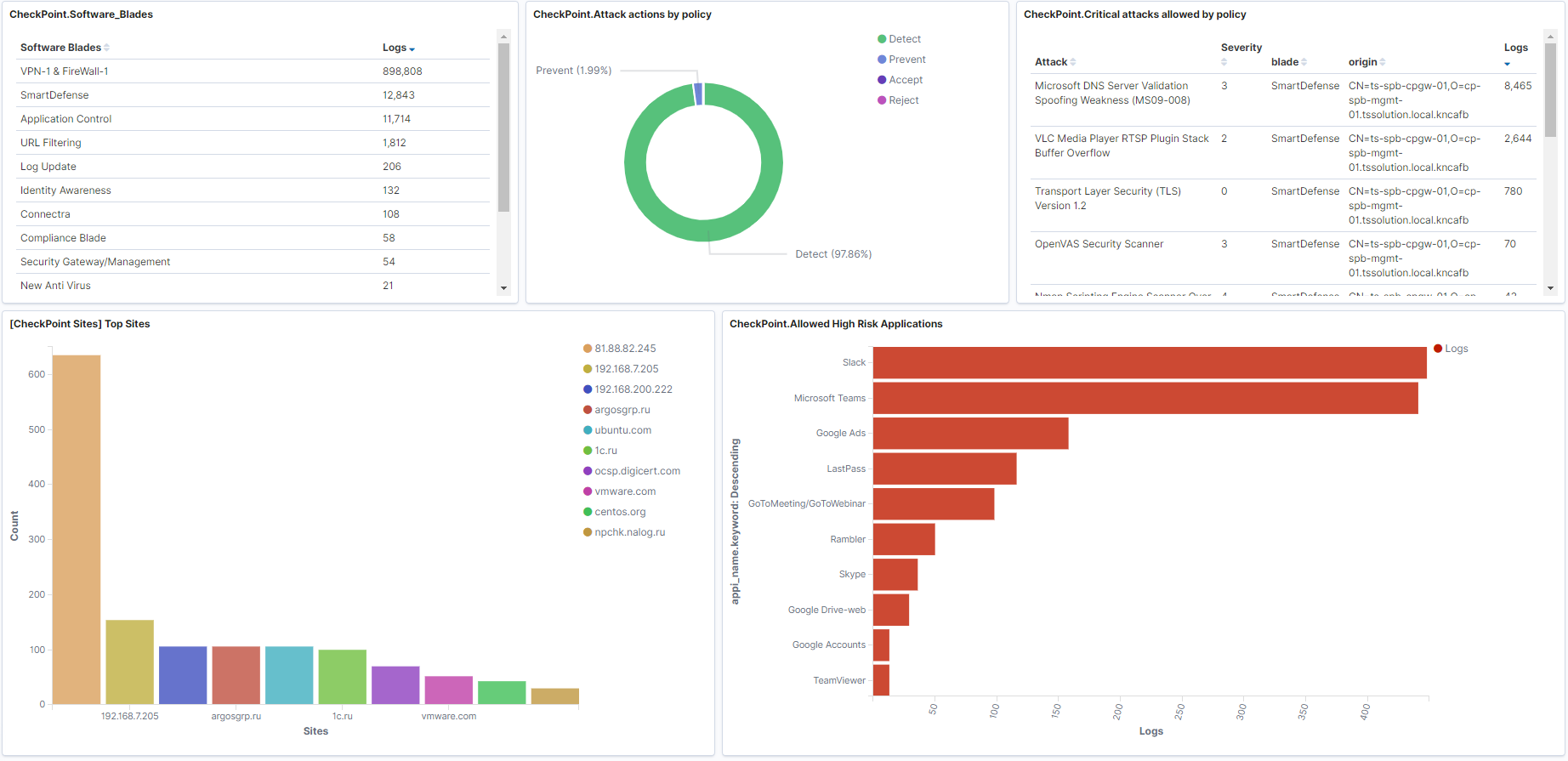
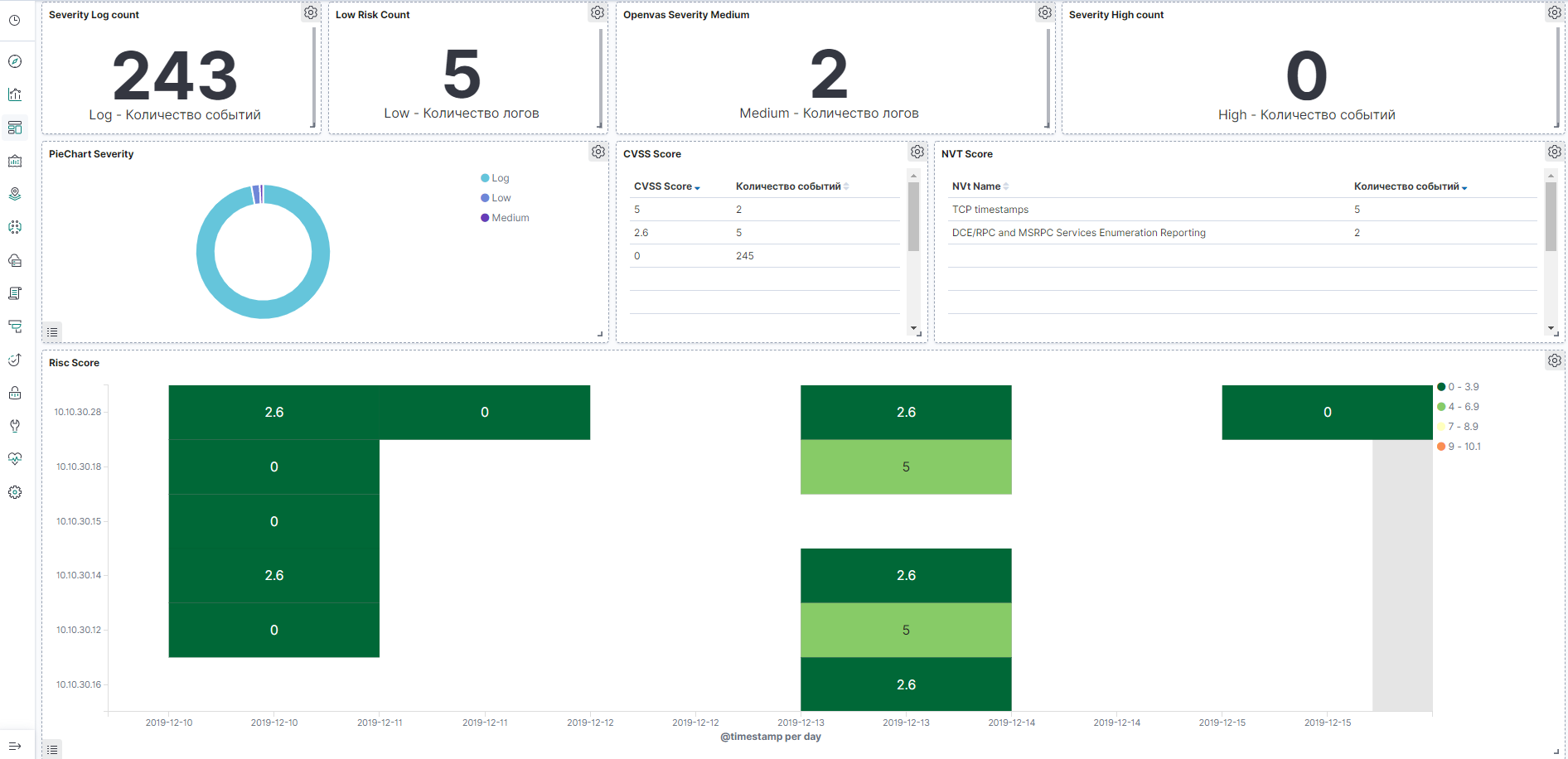
Kibana позволяет искать\брать данные и запрашивать статистику из базы данных elasticsearch, но основе ответов строятся множество красивых графиков и дашбоардов. Также система имеет функционал администрирования базы данных elasticsearch, в последующих статьях мы рассмотрим более подробно данный сервис. А сейчас покажем пример дашбоардов по межсетевому экрану Check Point и сканеру уязвимостей OpenVas, которые можно будет построить.
Пример дашбоарда для Check Point, картинка кликабельна:
Пример дашбоарда по OpenVas, картинка кликабельна:
Заключение
Мы рассмотрели из чего состоит ELK stack, немного познакомились с основными продуктами, далее в курсе отдельно будем рассматривать написание конфигурационного файла Logstash, настройку дашбоардов на Kibana, познакомимся с API запросами, автоматизацией и много чего еще!
- elasticsearch
- elastic stack
- check point
- data analysis
- ts solution
- анализ логов
- security
- Блог компании TS Solution
- Информационная безопасность
- Системное администрирование
- IT-инфраструктура
- Big Data
Что такое стек ELK?
ELK – это аббревиатура, используемая для описания стека из трех популярных проектов: Elasticsearch, Logstash и Kibana. Стек ELK, зачастую именуемый Elasticsearch, предоставляет возможность собирать журналы всех ваших систем и приложений, анализировать их и создавать визуализации, чтобы мониторить приложения и инфраструктуры, быстрее устранять неполадки, анализировать систему безопасности и многое другое.
E = Elasticsearch
Elasticsearch – это распределенный поисковый и аналитический движок на базе Apache Lucene. Он становится идеальным инструментом для различных примеров использования аналитики журналов и поиска благодаря поддержке различных языков, высокой производительности и документам JSON без схем.
Дополнительную информацию смотрите в разделе Что такое Elasticsearch?
21 января 2021 года Elastic NV объявила об изменении стратегии лицензирования программного обеспечения и о том, что новые версии Elasticsearch и Kibana под разрешительной лицензией Apache версии 2.0 (ALv2) выходить не будут. Вместо них предложены новые версии программного обеспечения по лицензии Elastic, а исходный код доступен по лицензии Elastic или SSPL. Эти лицензии не являются открытыми исходными кодами и не дают пользователям ту же свободу. Для безопасного высококачественного поиска и аналитики с полностью открытым исходным кодом мы создали проект OpenSearch – развиваемую сообществом ветвь открытого исходного кода Elasticsearch и Kibana с лицензией ALv2.
L = Logstash
Logstash – это предназначенный для приема данных инструмент с открытым исходным кодом, который позволяет собирать данные из различных источников, преобразовывать их и отправлять в нужное место назначения. Благодаря встроенным фильтрам и поддержке более 200 подключаемых модулей Logstash обеспечивает пользователям простой доступ к данным независимо от их источника или типа.
Logstash – это нетребовательный серверный конвейер обработки данных с открытым исходным кодом, который позволяет собирать данные из различных источников, преобразовывать их и отправлять в нужное место назначения. Как правило, он используется в качестве конвейера данных для Elasticsearch, аналитического и поискового движка с открытым исходным кодом. Logstash популярен для загрузки данных в Elasticsearch благодаря тесной интеграции, мощным возможностям обработки журналов и более чем 200 встроенным модулям с открытым исходным кодом, которые помогут с легкостью индексировать данные.
Простая загрузка неструктурированных данных
Logstash обеспечивает простое получение неструктурированных данных из различных источников, включая журналы систем, веб-сайтов и сервера приложения.
Встроенные фильтры
Logstash предлагает встроенные фильтры, поэтому вам доступно готовое преобразование распространенных типов файлов, их индексация Elasticsearch и запуск запросов без необходимости создания собственных конвейеров преобразования данных.
Гибкая архитектура подключаемых модулей
Поскольку на GitHub доступно более 200 модулей, вполне вероятно, что кто-то уже создал тот модуль, который необходим для настройки вашего конвейера данных. Но если ни один из них не соответствует вашим требованиям, вы можете с легкостью создать его самостоятельно.
K = Kibana
Kibana – это инструмент визуализации и изучения данных, который применяется для таких задач, как анализ журналов и временных рядов, мониторинг приложений и текущих процессов. Он предлагает мощные и простые в использовании возможности: гистограммы, линейные графики, круговые диаграммы, тепловые карты и встроенную геопространственную поддержку. Кроме того, он обеспечивает тесное взаимодействие с Elasticsearch, популярной аналитической и поисковой системой, за счет чего Kibana по умолчанию выступает как инструмент визуализации хранящихся в Elasticsearch данных.
21 января 2021 года Elastic NV объявила об изменении стратегии лицензирования программного обеспечения и о том, что новые версии Elasticsearch и Kibana под разрешительной лицензией Apache версии 2.0 (ALv2) выходить не будут. Вместо них предложены новые версии программного обеспечения по лицензии Elastic, а исходный код доступен по лицензии Elastic или SSPL. Эти лицензии не являются открытыми исходными кодами и не дают пользователям ту же свободу. Желая предоставить специалистам, которые работают с открытым исходным кодом, и нашим клиентам безопасный высококачественный комплект инструментов для поиска и аналитики с полностью открытым исходным кодом, мы создали проект OpenSearch – развиваемую сообществом ветвь открытого исходного кода Elasticsearch и Kibana с лицензией ALv2. Комплект OpenSearch состоит из поискового движка, OpenSearch и интерфейса визуализации и пользовательского интерфейса OpenSearch Dashboards.
Kibana с лицензией Apache 2.0 (до версии 7.10.2) можно запускать локально, на Эластичном облаке вычислений Amazon (Amazon EC2) или сервисе Amazon OpenSearch Service. OpenSearch Dashboards – это альтернатива Kibana с открытым исходным кодом, доступная для самостоятельного управления. Эта система была создана на основе последней версии Kibana с открытым исходным кодом (7.10.2). Она содержит множество усовершенствований и поддерживается проектом OpenSearch. При развертывании локально или на Amazon EC2 вы несете ответственность за подготовку и управление инфраструктурой и установку программного обеспечения Kibana или OpenSearch Dashboards. Благодаря OpenSearch Service Kibana или OpenSearch Dashboards автоматически развертываются вместе с вашим доменом как полностью управляемые сервисы и берут на себя всю тяжелую работу по управлению кластером.
Интерактивные схемы
Kibana предлагает интуитивно понятные схемы и отчеты, которые можно использовать для интерактивной навигации по большим объемам данных журналов. Вы можете динамически перемещать временные окна, увеличивать и уменьшать масштаб определенных подмножеств данных и детализировать отчеты, чтобы получить полезные выводы из своих данных.
Поддержка привязки
Kibana предлагает мощные геопространственные возможности, позволяя с легкостью накладывать географическую информацию поверх данных и визуализировать результаты на картах.
Встроенные агрегаторы и фильтры
Используя встроенные агрегаторы и фильтры Kibana, можно в несколько шагов запускать различные аналитические функции, такие как гистограммы, запросы top-N и тенденции.
Легкодоступные панели управления
Вы можете легко настраивать панели управления и отчеты и делиться ими с другими. Все, что потребуется – это браузер для просмотра и изучения данных.
Как работает стек ELK?
- Logstash собирает, преобразует и отправляет данные в нужный пункт назначения.
- Elasticsearch индексирует и анализирует собранные данные и производит поиск в них.
- Kibana предоставляет визуализацию результатов анализа.