Извлечение, преобразование и загрузка (ETL)
Распространенной проблемой, с которой сталкиваются организации, является сбор данных из нескольких источников в нескольких форматах. Затем эти данные необходимо переместить его в одно или несколько хранилищ данных. Тип назначения может не совпадать с типом источника. Часто его формат отличается, либо необходимо сформировать или очистить данные перед их загрузкой в целевое расположение.
За несколько лет для решения этих проблем было разработано много средств, служб и процессов. Независимо от используемого процесса, существует общая потребность в координации работы и преобразовании данных в конвейере. В следующих разделах описываются распространенные методы, используемые для выполнения этих задач.
Извлечение, преобразование и загрузка (ETL)
Извлечение, преобразование и загрузка (ETL) — это конвейер данных, используемый для сбора данных из различных источников. Затем он преобразует данные в соответствии с бизнес-правилами и загружает их в целевое хранилище данных. Процесс преобразования в конвейере ETL выполняется в специальной подсистеме. Зачастую для временного хранения данных во время их преобразования и до загрузки в пункт назначения используются промежуточные таблицы.
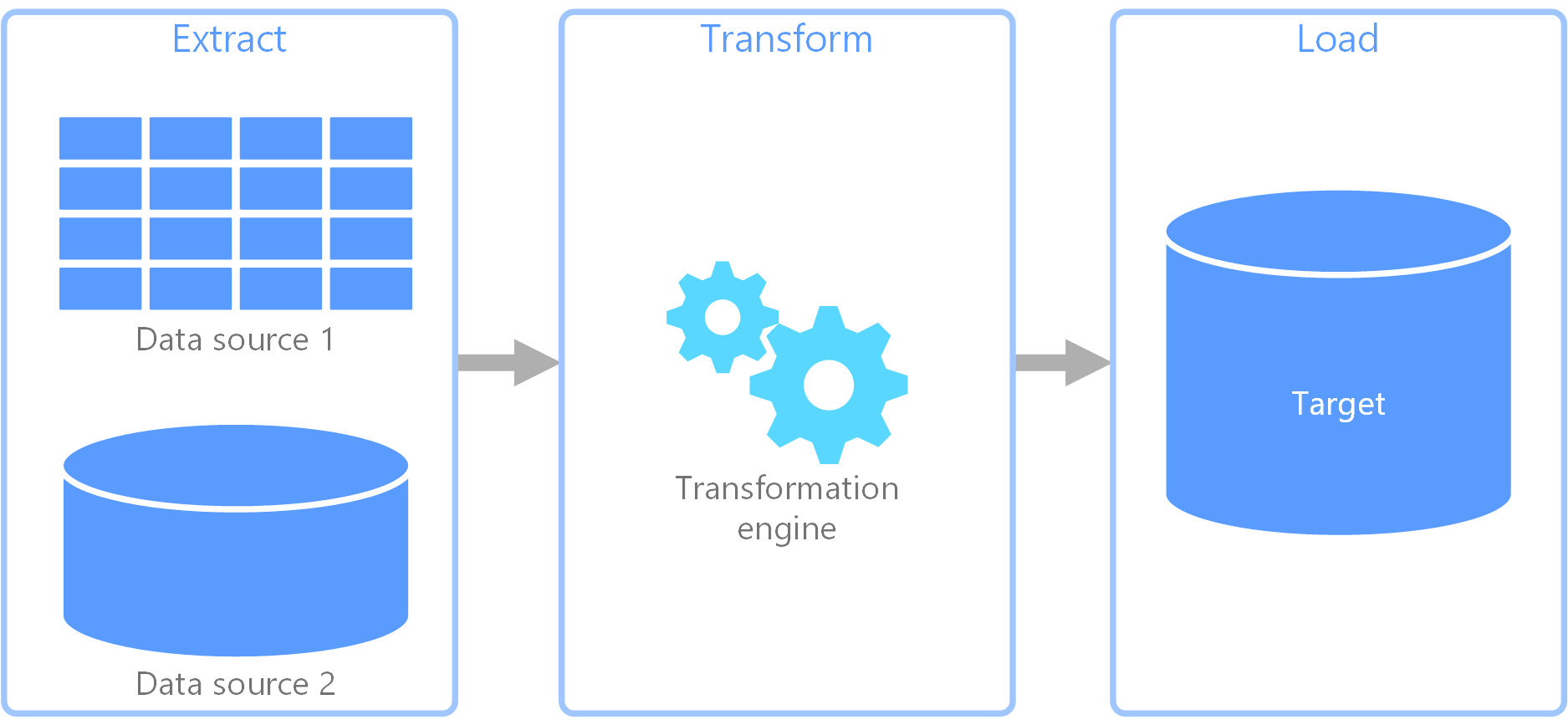
Обычно в процессе преобразования данных применяются различные операции (например, фильтрация, сортировка, агрегирование, объединение, очистка, дедупликация и проверка данных).
Часто три этапа ETL выполняются параллельно, чтобы сэкономить время. Например, при извлечении данных процесс преобразования может уже обрабатывать полученные данные и подготавливать их для загрузки, а процесс загрузки может начать обрабатывать подготовленные данные, не дожидаясь полного завершения извлечения.
Соответствующие службы Azure:
Извлечение, загрузка и преобразование (ELT)
Конвейер извлечения, загрузки и преобразования (ELT) отличается от ETL исключительно средой выполнения преобразования. В конвейере ELT преобразование происходит в целевом хранилище данных. В этом случае для преобразования данных вместо специальной подсистемы используются средства обработки целевого хранилища данных. Это упрощает архитектуру за счет удаления механизма преобразования из конвейера. Еще одним преимуществом этого подхода является то, что масштабирование целевого хранилища данных также улучшает производительность конвейера ELT. Тем не менее ELT работает надлежащим образом, только если целевая система имеет достаточную производительность для эффективного преобразования данных.
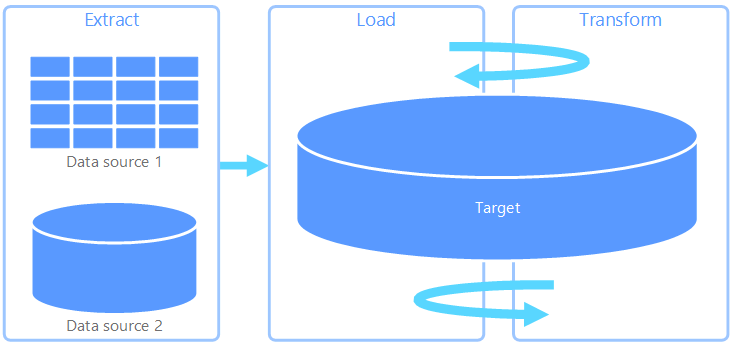
Обычно конвейер ELT применяется для обработки больших объемов данных. К примеру, вы можете извлечь все исходные данные в неструктурированные файлы в масштабируемое хранилище (например, распределенную файловую систему Hadoop, Хранилище BLOB-объектов Azure или Azure Data Lake Store 2-го поколения либо их сочетание). Затем для выполнения запроса исходных данных можно использовать такие технологии, как Spark, Hive или PolyBase. Ключевой особенностью ELT является то, что хранилище данных, используемое для выполнения преобразования, — это то же хранилище, в котором данные в конечном счете потребляются. Это хранилище данных считывает данные непосредственно из масштабируемого хранилища, вместо того чтобы загружать их в собственное защищаемое хранилище. Этот подход пропускает этап копирования (присутствующий в ETL), который часто может занимать много времени при обработке больших наборов данных.
Обычно целевым хранилищем является хранилище данных, использующее кластер Hadoop (с помощью Hive или Spark) или выделенные пулы SQL в Azure Synapse Analytics. Чаще всего схема накладывается на данные неструктурированных файлов во время выполнения запроса и сохраняется в виде таблиц, позволяя запрашивать данные таким же образом, как и любую другую таблицу в хранилище данных. Они называются внешними таблицами, так как данные находятся не в хранилище, управляемом самим хранилищем данных, а во внешнем масштабируемом хранилище, таком как Azure Data Lake Store или хранилище BLOB-объектов Azure.
Хранилище данных управляет только схемой данных и применяет ее при чтении. Например, кластер Hadoop, использующий Hive, описывает таблицу Hive, где источником данных является фактический путь к набору файлов в HDFS. В Azure Synapse технология PolyBase может достичь того же результата, создав таблицу с данными, хранящимися вне самой базы данных. Когда исходные данные загружены, данные, имеющиеся во внешних таблицах, можно обрабатывать, используя возможности хранилища данных. В сценариях с большими данными это означает, что хранилище данных должно поддерживать массовую параллельную обработку (MPP), когда данные разбиваются на более мелкие фрагменты, а обработка этих фрагментов распределяется сразу между несколькими узлами в параллельном режиме.
Последний этап конвейера ELT обычно заключается в преобразовании исходных данных в окончательный формат, более эффективный для тех типов запросов, которые необходимо поддерживать. Например, данные могут быть секционированы. Кроме того, ELT может использовать оптимизированные форматы хранения (например, Parquet), в которых построчные данные хранятся в виде столбцов и предоставляется оптимизированная индексация.
Соответствующие службы Azure:
- Выделенные пулы SQL в Azure Synapse Analytics
- Бессерверные пулы SQL в Azure Synapse Analytics
- HDInsight с Hive;
- Фабрика данных Azure.
- Диаграммы данных в Power BI
Поток данных и поток управления
В контексте конвейеров данных поток управления обеспечивает обработку набора задач в правильном порядке. Для этого используется управление очередностью. Эти ограничения можно рассматривать как соединители на схеме рабочего процесса, показанной ниже. Каждая задача имеет результат (успешное завершение, сбой или завершение). Все последующие задачи начинают обработку данных, только когда предыдущая задача завершена с одним из этих результатов.
Потоки управления выполняют потоки данных в качестве задачи. В рамках задачи потока данных данные извлекаются из источника, преобразовываются и загружаются в хранилище данных. Выходные данные одной задачи потока данных могут использоваться в качестве входных данных для следующей задачи потока данных, а эти потоки могут выполняться одновременно. В отличие от потоков управления, вы не можете добавить ограничения между задачами в потоке данных. Однако вы можете добавить средство просмотра данных для наблюдения за данными по мере их обрабатывания каждой задачей.
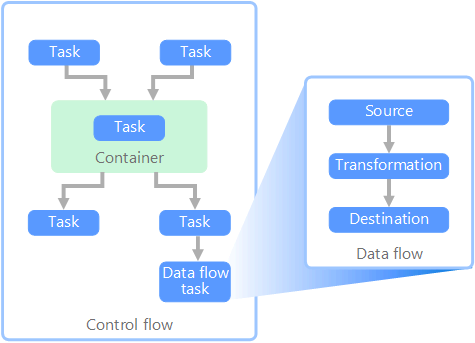
На приведенной выше схеме показано несколько задач в потоке управления, одна из которых является задачей потока данных. Одна из задач вложена в контейнер. Контейнеры можно использовать для обеспечения структуры задач, тем самым формируя единицу работы. Одним из примеров является повторение элементов в коллекции (например, файлы в папке или инструкции базы данных).
Соответствующие службы Azure:
Выбор технологий
- Хранилища данных оперативной обработки транзакций (OLTP)
- Хранилища данных OLAP
- Хранилища данных
- Оркестрация конвейеров
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально она была написана следующими участниками.
- Раунак Джавар | Старший архитектор облачных решений
- Зойнер Теджада | Генеральный директор и архитектор
Дальнейшие действия
- Интеграция данных с помощью Фабрики данных Azure или конвейера Azure Synapse
- Введение в Azure Synapse Analytics
- Координация перемещения и преобразования данных в Фабрике данных Azure или конвейере Azure Synapse
Связанные ресурсы
На следующей схеме эталонной архитектуры представлены сквозные конвейеры ELT в Azure:
- Корпоративная бизнес-аналитика в Azure с использованием Azure Synapse
- Автоматизированная корпоративная бизнес-аналитика с использованием Azure Synapse и Фабрики данных Azure
Обратная связь
Отправить и просмотреть отзыв по
Etl sql что это
12 сентября 2023
Скопировано
ETL — это общий термин для процессов, которые происходят, когда данные переносят из нескольких систем в одно хранилище. Аббревиатура расшифровывается как Extract, Transform, Load, или «извлечение, преобразование, загрузка». Именно это происходит с файлами в процессе переноса.

Освойте профессию «Аналитик данных»
Обычно ETL-процессы используются, когда нужно перенести много разнородных данных: собрать их, привести к единому виду, загрузить в новую систему и сохранить всю информацию по пути. Системы бывают разными, и задача ETL — в том числе адаптировать под них данные из разных источников.
В качестве примера можно привести магазин. Учет офлайн-клиентов ведется в одном формате, онлайн-покупателей — в другом. Устройства разные, форматы данных тоже. Если магазину потребуется вести общую базу, сначала данные нужно выгрузить и привести к единому формату. За это отвечает ETL.
Существует множество платных и бесплатных реализаций ETL. Они называются ETL-системами. Простейшую реализацию программист может написать самостоятельно, но только для конкретной небольшой задачи. Большие системы работают с разными данными «из коробки».
Профессия / 12 месяцев
Аналитик данных
Находите закономерности и делайте выводы, которые помогут бизнесу

Кто работает с ETL-системами
- Разработчики, так как для некоторых проектов и задач могут потребоваться собственные внутренние реализации ETL. Обычно это нужно в компаниях, которым важно не зависеть от сторонних клиентов, например в банках. ETL-разработчик — это человек, который занимается проектированием и реализацией ETL-процессов.
- Бизнес- и дата-аналитики, которые работают с бизнес-логикой и данными, поэтому часто используют разнородную информацию.
- Дата-инженеры, специалисты, которые занимаются проектированием, поддержкой и оркестрацией систем хранения данных. Оркестрацией называют координирование работы сложных систем.
Где используется ETL
Единственное назначение ETL — помогать перемещению данных из одного места в другое. ETL можно использовать во множестве сфер, где требуется объединить информацию из разных источников.
Базы данных. Любые хранилища данных так или иначе сталкиваются с миграциями, перемещениями из одного места в другое. Иногда это разовый перенос, но часто компании работают так, что данные поступают в базу из разных источников все время. Пример с магазином хорошо иллюстрирует такое поведение. При работе с базами данных ETL будет отвечать за то, чтобы все было однородно и грамотно.
DWH, или КХД. Аббревиатуру можно расшифровать как Data Warehouse или «корпоративное хранилище данных», склад информации. Так называются специальные базы данных для организационных целей, внутреннего анализа и подготовки отчетов. Это административные и архивные базы данных компании. В них хранится важная бизнес-информация. Чтобы бизнес-процессы и внутренняя аналитика работали корректно, нужно объединить информацию в одном месте. В случае с КХД она всегда поступает из разных источников. Поэтому ETL часто используют в связке со «складами данных» и настройкой бизнес-процессов.

Станьте аналитиком данных и получите востребованную специальность
OLTP и OLAP. ETL используют как «прослойку» между системами OLTP и OLAP. Оба вида систем нужны для обработки данных, но у них есть различия:
- OLTP — это Online Transaction Processing, обработка онлайн-транзакций. Системы ориентированы на непрерывный поток небольших транзакций, многие из которых повторяются;
- OLAP — это Online Analytical Processing, аналитическая онлайн-обработка данных. В отличие от предыдущего вида систем, OLAP нужна для обработки крупных аналитических запросов со множеством параметров.
OLAP хорошо работает там, где не справляется OLTP, и наоборот, поэтому данные иногда требуется «перебрасывать» из одной системы в другую. Для этого применяется ETL.
Big Data. Работа с большими данными подразумевает их перемещения по разным системам. ETL-системы иногда описывают как решения для помощи Big Data-разработчикам, хотя на самом деле их функциональность нужна не только для этого.
IoT. Internet of Things — это термин для сети, которая дает возможность «умным» устройствам общаться друг с другом. Благодаря IoT техника может связываться друг с другом по локальной сети и в результате решать более сложные задачи, чем при работе по отдельности. Технологию часто используют при обустройстве «умных домов» и похожих автоматизированных систем.
Информация с разных устройств различается и форматом, и особенностями. Чтобы хранить ее в единой базе, нужно применять ETL. Пример — дашборд в «умном доме», который выводит информацию со всех датчиков и сведения о состоянии всех IoT-приборов.
Машинное обучение. Специалисты по искусственному интеллекту и машинному обучению оперируют огромными массивами данных — датасетами. Данные нужно обрабатывать, загружать в машины, использовать для обучения или анализа. ETL используется для миграции данных в единое хранилище, например при создании датасета.
Облачные технологии. Облачные сервера, инструменты и сервисы — замена продуктам, которые нужно держать на собственных машинах. «Облака» используются для хранения данных множества компаний. ETL может потребоваться и при первичной миграции данных в облако, и при последующем переносе новых данных из разных источников.
Аналитика. ETL может использоваться в анализе данных, бизнес-, маркетинговом анализе и других видах аналитики. Аналитика подразумевает большое количество информации, полученной из разных источников: ее нужно сравнивать, анализировать и делать прогнозы на ее основе. Поэтому в области широко применяется ETL, и работодатели часто требуют от соискателей на должность аналитика понимания процессов.
Читайте также Анализ или предсказания: в чем главные отличия аналитика данных от дата-сайентиста?
Устройство ETL-процесса
ETL — это аббревиатура из трех слов, каждое из которых означает какой-либо процесс. Мы говорили о расшифровке выше, а сейчас подробнее расскажем, что именно скрывается за этими словами.
Extract, или извлечение. Система берет данные из одного или нескольких источников и перемещает в промежуточный буфер для дальнейшей обработки. Также может проводиться валидация, проверка данных на соответствие тем или иным критериям. Система проверяет, можно ли загрузить их без потерь в новое хранилище.
Transform, или преобразование. Процесс, в ходе которого система видоизменяет данные под требования нового хранилища. Она меняет формат представления информации, при необходимости — кодировку, очищает данные от лишнего, приводит все к единому виду.
Load, или загрузка. Финальный этап, на котором подготовленные данные загружаются в новое хранилище и размещаются на своих местах. Кроме самой информации, ETL-система может передавать метаданные — данные о данных, например сведения об их структуре.
Что делают ETL-системы
На практике реализация принципа работы состоит более чем из трех шагов. При попадании в реальную ETL-систему данные проходят пять основных этапов.
Загрузка. Этап соответствует процессу Extract в аббревиатуре ETL, но сейчас мы смотрим на происходящее «изнутри» системы, и с этой точки зрения происходит загрузка, а не извлечение. Данные, которые загружаются в ETL-систему, называются сырыми — они пока не обработаны и даже не проверены, их качество может быть любым. Единственная проверка на этом этапе — сверка количества строк. Если их меньше, чем было в источнике, при загрузке произошел сбой.
Валидация. В ходе процесса Extract система должна проверить данные. Этот процесс называется валидация: загруженная информация по очереди проверяется и фильтруется. Система анализирует полноту данных, их корректность, наличие или отсутствие ошибок — «битой» информации. После завершения валидации выдается отчет об ошибках. Если есть сбои, их нужно исправить.
В некоторых процессах используется обогащение данных — получение дополнительных сведений на основе имеющейся информации. Это нужно, если у системы есть другие внутренние источники. Иногда дополнительные данные можно вычислить из существующих с помощью алгоритма.
Мэппинг. Составная часть процесса Transform — преобразования данных под новый формат. После валидации данные чаще всего выглядят как таблица, к которой добавляются нужные столбцы и строки. Мэппинг может происходить по разным алгоритмам в зависимости от ETL-инструмента и его настроек: в системе есть специальные скрипты и формулы.
Агрегация. Это тоже часть трансформации — в системах различаются особенности детализации и представления данных. Чтобы информацию можно было перенести в другую без ошибок, она трансформируется. Это не добавление новых строк и столбцов, как при мэппинге, а изменение связей между самими данными. В результате агрегации информация «склеивается» в новую таблицу — в ней все представлено так, как требует новое хранилище.
Схема преобразования может быть более или менее масштабной в зависимости от поставленной задачи.
Выгрузка. Это реализация процесса Load — преобразованные и очищенные данные выгружаются из системы и попадают в новое хранилище. Используются инструменты ETL-системы и хранилища — так называемые коннекторы и различные части интерфейса.
Примеры ETL-систем
Существуют системы, предназначенные для интеграции данных, их перемещения, объединения и трансформации. В них может входить реализация не только ETL, но и других процессов, связанных с передачей информации. Это, например, программные продукты IBM DataStage, Informatica PowerCenter, Oracle Data Integrator или SAP Data Services. Сюда же можно отнести Sybase ETL Development и Sybase ETL Server, а также многое другое ПО для работы с бизнес-базами. Все это платные решения от ведущих разработчиков.
Кроме специализированных сервисов, ETL-инструменты есть в более общем и более мощном ПО. Это, например, полномасштабная платформа для работы с данными IBM InfoSphere Information Server, СУБД Microsoft SQL Server или российский Cloud Big Data от VK — облачный сервис для больших данных.
Существуют бесплатные решения для работы с ETL: например, проприетарный инструмент Oracle Warehouse Builder или открытые Scriptella ETL Project, Jaspersoft ETL, Apatar и другие.
Как начать пользоваться ETL
Простейшую реализацию ETL можно написать самому. Нужно знать подходящий язык программирования, разбираться в архитектуре процессов, уметь применять алгоритмы для преобразования данных.
С бесплатными ETL-инструментами можно познакомиться, просто скачав и установив их. Для работы потребуется учебная среда, где есть базы данных или другие хранилища, из которых можно переносить данные. Некоторые платные проекты предоставляют ограниченные учебные версии. Информация предоставлена на сайте разработчика.
Чтобы эффективно работать с ETL-процессами, нужно разбираться в теории. Вам помогут учебники, туториалы или профессиональные курсы — под контролем менторов вы получите структурированную и актуальную информацию.
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.

Статьи по теме:
Как и с чем работает незаменимый специалист из сферы Data Science
R или Java — что лучше подходит для анализа больших данных
Екатерина Нестерова объясняет, как определять важность задач по методу ICE и почему аналитики постоянно ошибаются
Что такое ETL (извлечение, преобразование, загрузка)?
Извлечение, преобразование и загрузка (ETL) – это процесс объединения данных из нескольких источников в одном центральном хранилище, которое называется складом данных. ETL использует набор бизнес-правил для очистки и упорядочения необработанных данных и их подготовки к хранению, анализу данных и машинному обучению (ML). Вы можете решать определенные задачи бизнес-аналитики путем анализа данных (например, прогнозирование результата принятия бизнес-решений, генерирование отчетов и панелей управления, сокращение числа неэффективных операций и так далее).
Почему подход ETL так важен?
Сегодня организации располагают как структурированными, так и неструктурированными данными из различных источников, включая:
- Данные о клиентах из систем онлайн-платежей и управления взаимоотношениями с клиентами (CRM)
- Данные о запасах и операциях из систем поставщиков
- Сенсорные данные с устройств Интернета вещей (IoT)
- Маркетинговые данные из социальных сетей и отзывы клиентов
- Данные о сотрудниках из внутренних систем управления персоналом
Применяя процесс извлечения, преобразования и загрузки (ETL), отдельные необработанные наборы данных могут быть подготовлены в формате и структуре, более пригодных для использования в аналитических целях, что позволяет получить более содержательные выводы. Например, интернет-магазины могут анализировать данные из точек продаж для прогнозирования спроса и управления запасами. Маркетинговые команды могут интегрировать данные CRM с отзывами клиентов в социальных сетях для изучения поведения потребителей.
Какую пользу приносит ETL для бизнес-аналитики?
Извлечение, преобразование и загрузка (ETL) улучшает бизнес-аналитику и аналитику, делая этот процесс более надежным, точным, подробным и эффективным.
Исторический контекст
ETL обеспечивает глубокий исторический контекст данных организации. Предприятие может объединить устаревшие данные с данными из новых платформ и приложений. Вы можете просматривать более старые наборы данных наряду с более свежей информацией, что позволяет получить долгосрочное представление о данных.
Консолидированное представление данных
ETL обеспечивает консолидированное представление данных для углубленного анализа и отчетности. Управление многочисленными наборами данных требует времени и координации и может привести к неэффективности и задержкам. ETL объединяет базы данных и различные формы данных в единое, унифицированное представление. Процесс интеграции данных улучшает качество данных и экономит время, необходимое для перемещения, категоризации или стандартизации данных. Это облегчает анализ, визуализацию и осмысление больших массивов данных.
Точный анализ данных
ETL обеспечивает более точный анализ данных для соответствия нормативным и регулятивным стандартам. Вы можете интегрировать инструменты ETL с инструментами обеспечения качества данных для профилирования, аудита и очистки данных, обеспечивая их достоверность.
Автоматизация задач
ETL автоматизирует повторяющиеся задачи обработки данных для эффективного анализа. Инструменты ETL автоматизируют процесс миграции данных, и вы можете настроить их на периодическую интеграцию изменений данных или даже во время выполнения. В результате инженеры по обработке данных могут больше времени уделять инновациям и меньше – решению таких утомительных задач, как перемещение и форматирование данных.
Как развивался подход ETL?
Извлечение, преобразование и загрузка (ETL) возникли с появлением реляционных баз данных, в которых хранились данные в виде таблиц для анализа. С помощью ранних инструментов ETL пытались преобразовать данные из транзакционных форматов в реляционные форматы данных для анализа.
Традиционный подход ETL
Необработанные данные обычно хранились в транзакционных базах данных, которые поддерживали множество запросов на чтение и запись, но плохо поддавались анализу. Вы можете представить это как строку в электронной таблице. Например, в системе электронной коммерции транзакционная база данных хранит данные о купленном товаре, данные клиента и детали заказа в одной транзакции. В течение года она содержала длинный список операций с повторяющимися записями для одного и того же клиента, который приобрел несколько товаров. Учитывая дублирование данных, анализ наиболее популярных товаров или тенденций покупок в этом году стал обременительным.
Чтобы преодолеть эту проблему, инструменты ETL автоматически преобразовывали эти транзакционные данные в реляционные данные с взаимосвязанными таблицами. Аналитики могут использовать запросы для выявления взаимосвязей между таблицами, а также закономерностей и тенденций.
Современный подход ETL
По мере развития технологии ETL количество типов и источников данных увеличивалось экспоненциально. Облачные технологии возникли для создания огромных баз данных (также называемых потребителями данных). В такие потребители данных могут поступать данные из нескольких источников. Они также могут иметь базовые аппаратные ресурсы, которые могут масштабироваться с течением времени. Инструменты ETL также стали более сложными и могут работать с современными потребителями данных. Они могут преобразовывать данные из устаревших форматов в современные. Ниже приведены примеры современных баз данных.
Хранилища данных
Хранилище данных – это центральное хранилище, в котором может храниться множество баз данных. Внутри каждой базы данных вы можете организовать данные в таблицы и столбцы, которые описывают типы данных в таблице. Программное обеспечение для хранилища данных работает с различными типами оборудования для хранения данных, такими как твердотельные накопители (SSD), жесткие диски и другие облачные хранилища, чтобы оптимизировать обработку данных.
Озера данных
С помощью озера данных вы можете хранить структурированные и неструктурированные данные в одном централизованном хранилище и в любом масштабе. Вы можете хранить данные как есть, без необходимости предварительно структурировать их на основе вопросов, которые могут возникнуть в будущем. Озера данных также позволяют выполнять различные виды аналитики на ваших данных, такие как SQL-запросы, аналитика больших данных, полнотекстовый поиск, аналитика в реальном времени и машинное обучение (ML), для принятия лучших решений.
Как работает ETL?
Извлечение, преобразование и загрузка (ETL) работает путем периодического перемещения данных из системы-источника в систему-получатель. Процесс ETL состоит из трех этапов:
- Извлечение соответствующих данных из исходной базы данных
- Преобразование данных таким образом, чтобы они лучше подходили для аналитики
- Загрузка данных в целевую базу данных

Что такое извлечение данных?
При извлечении данных инструменты извлечения, преобразования и загрузки (ETL) извлекают или копируют необработанные данные из различных источников и сохраняют их в зоне хранения. Промежуточная среда (или целевая зона) – это промежуточная зона хранения для временного хранения извлеченных данных. Промежуточные среды часто являются временными, то есть их содержимое стирается после завершения извлечения данных. Однако в промежуточной среде может также храниться архив данных для целей устранения неполадок.
Частота отправки данных из источника данных в целевое хранилище данных зависит от базового механизма сбора данных об изменениях. Извлечение данных обычно происходит одним из трех следующих способов.
Уведомление об обновлении
При уведомлении об обновлении система-источник уведомляет вас об изменениях в записи данных. Затем вы можете запустить процесс извлечения для этого изменения. Большинство баз данных и веб-приложений предоставляют механизмы обновления для поддержки этого метода интеграции данных.
Инкрементное извлечение
Некоторые источники данных не могут предоставлять уведомления об обновлении, но могут идентифицировать и извлекать данные, которые были изменены за определенный период времени. В этом случае система проверяет изменения через периодические промежутки времени, например, раз в неделю, раз в месяц или в конце кампании. Вам нужно извлекать только те данные, которые изменились.
Полное извлечение
Некоторые системы не могут определить изменения данных или выдать уведомление, поэтому единственным вариантом является перезагрузка всех данных. Этот метод извлечения требует, чтобы вы сохранили копию последнего извлечения, чтобы проверить, какие записи являются новыми. Поскольку этот подход предполагает большие объемы передачи данных, мы рекомендуем использовать его только для небольших таблиц.
Что такое преобразование данных?
При преобразовании данных инструменты извлечения, преобразования и загрузки (ETL) преобразуют и консолидируют исходные данные в зоне хранения, чтобы подготовить их для целевого хранилища данных. Этап преобразования данных может включать нижеследующие типы изменений данных.
Базовое преобразование данных
Базовые преобразования улучшают качество данных, удаляя ошибки, опустошая поля данных или упрощая их. Примеры этих преобразований приведены ниже.
Чистка данных
В процессе очистки данных удаляются ошибки и исходные данные приводятся к целевому формату. Например, вы можете сопоставить пустые поля данных с числом 0, сопоставить значение данных «Родитель» с «P» или сопоставить «Дети» с «Д».
Дедупликация данных
Дедупликация при очистке данных выявляет и удаляет дублирующиеся записи.
Пересмотр формата данных
При пересмотре формата преобразуются данные, такие как наборы символов, единицы измерения и значения даты/времени, в согласованный формат. Например, у пищевой компании могут быть разные базы данных рецептов с ингредиентами, измеряемыми в килограммах и фунтах. ETL преобразует все данные в фунты.
Расширенное преобразование данных
При расширенных преобразованиях используются бизнес-правила для оптимизации данных для упрощения анализа. Примеры этих преобразований приведены ниже.
Деривация
При деривации применяются бизнес-правила к данным для вычисления новых значений на основе существующих. Например, можно преобразовать выручку в прибыль путем вычитания расходов или рассчитать общую стоимость покупки путем умножения цены каждого товара на количество заказанных товаров.
Объединение
При подготовке данных в процессе объединения связываются одни и те же данные из разных источников данных. Например, вы можете найти общую стоимость покупки одного товара, сложив стоимость покупки у разных поставщиков и сохранив в целевой системе только итоговую сумму.
Разделение
Вы можете разделить столбец или атрибут данных на несколько столбцов в целевой системе. Например, если источник данных сохраняет имя клиента как «Иванов Иван Иванович», вы можете разделить его на имя, отчество и фамилию.
Суммирование
В результате суммирования повышается качество данных за счет сокращения большого количества значений данных в меньший набор данных. Например, значения счета-фактуры по заказу клиента могут иметь множество различных небольших сумм. Вы можете обобщить данные за определенный период, сложив их, чтобы построить показатель пожизненной ценности клиента (CLV).
Шифрование
Вы можете защитить конфиденциальные данные для соблюдения законов о защите данных или конфиденциальности данных, добавив шифрование до того, как потоки данных будут переданы в целевую базу данных.
Что такое загрузка данных?
При загрузке данных инструменты извлечения, преобразования и загрузки (ETL) перемещают преобразованные данные из зоны хранения в целевое хранилище данных. Для большинства организаций, использующих ETL, этот процесс автоматизирован, четко определен, непрерывен и управляем пакетами. Далее описывается два метода загрузки данных.
Полная загрузка
При полной загрузке все данные из источника преобразуются и перемещаются в хранилище данных. Полная загрузка обычно происходит при первой загрузке данных из исходной системы в хранилище данных.
Инкрементная загрузка
При инкрементной загрузке инструмент ETL загружает дельту (или разницу) между целевой и исходной системами через регулярные промежутки времени. Он сохраняет дату последнего извлечения, так что загружаются только записи, добавленные после этой даты. Существует два способа реализации инкрементной загрузки.
Потоковая инкрементная загрузка
Если у вас небольшие объемы данных, вы можете передавать непрерывные изменения по конвейерам данных в целевое хранилище данных. Когда скорость данных возрастает до миллионов событий в секунду, можно использовать обработку потока событий для мониторинга и обработки потоков данных, чтобы принимать более своевременные решения.
Пакетная инкрементная загрузка
Если у вас большие объемы данных, вы можете периодически собирать изменения данных загрузки в пакеты. В течение этого заданного периода времени никакие действия не могут происходить ни в исходной, ни в целевой системе, поскольку данные синхронизируются.
Что такое ELT?
Извлечение, преобразование и загрузка (ETL) – это расширение извлечения, преобразования и загрузки (ETL), которое меняет порядок операций. Вы можете загружать данные непосредственно в целевую систему перед их обработкой. Промежуточная область хранения не требуется, поскольку целевое хранилище данных имеет в себе возможности сопоставления данных. Система ELT стала более популярной с принятием облачной инфраструктуры, которая предоставляет целевым базам данных вычислительную мощность, необходимую для преобразований.
Сравнение ETL и ELT
ELT хорошо подходит для больших объемов неструктурированных наборов данных, требующих частой загрузки. Система также идеально подходит для больших данных, поскольку планирование аналитики может быть выполнено после извлечения и хранения данных. Она оставляет основную часть преобразований для этапа аналитики и фокусируется на загрузке минимально обработанных сырых данных в хранилище данных.
Процесс ETL требует большего определения на начальном этапе. Аналитику необходимо участвовать с самого начала, чтобы определить целевые типы данных, структуры и взаимосвязи. Специалисты по работе с данными в основном используют ETL для загрузки унаследованных баз данных в хранилище, а ELT сегодня – это норма.
Что такое виртуализация данных?
Виртуализация данных использует слой программной абстракции для создания интегрированного представления данных без физического извлечения, преобразования или загрузки данных. Организации используют эту функциональность в качестве виртуального унифицированного хранилища данных без затрат и сложностей, связанных с созданием и управлением отдельными платформами для исходных и целевых данных. Хотя виртуализацию данных можно использовать наряду с извлечением, преобразованием и загрузкой (ETL), она все чаще рассматривается как альтернатива ETL и другим методам интеграции физических данных. Например, вы можете использовать AWS Glue Elastic Views для быстрого создания виртуальной таблицы – материализованного представления – из нескольких различных исходных хранилищ данных.
Что такое AWS Glue?
AWS Glue — это бессерверный сервис интеграции данных, который упрощает пользователям-аналитикам поиск, подготовку, перемещение и интеграцию данных из множества источников для анализа, машинного обучения и разработки приложений.
- Можно найти и подключиться к более чем 80 различным хранилищам данных.
- Можно управлять данными в централизованном каталоге данных.
- Инженеры по обработке данных, разработчики ETL, аналитики данных и корпоративные пользователи могут использовать AWS Glue Studio для создания, запуска и отслеживания конвейера ETL, чтобы загрузить данные в озера данных.
- AWS Glue Studio предоставляет интерфейсы визуального процесса ETL, блокнота и редактора кода, чтобы пользователи располагали инструментами, соответствующими их навыкам.
- С помощью интерактивных сеансов инженеры по обработке данных могут выполнять исследование данных, а также авторские и тестовые задания в предпочитаемой ими среде IDE или блокноте.
- AWS Glue — это бессерверный сервис, автоматически масштабируемый по запросу, поэтому можно сосредоточиться на сборе аналитической информации из петабайтов данных без необходимости управлять инфраструктурой.
Создайте аккаунт AWS и начните работу с AWS Glue.
Кто такой ETL-разработчик и как им стать
Внедрение IT-решений в инфраструктуру бизнеса — один из главных технологических трендов 2023 года. Компании осваивают облачные сервисы, электронный документооборот, принимают решения на основе больших данных.
Цифровая трансформация приводит к повышению спроса на ETL-разработчиков. Эти специалисты помогают собирать информацию из разных источников и переходить на новые программы без потери важных сведений.
Рассказываем, чем конкретно занимается ETL-разработчик, сколько он зарабатывает и как можно получить эту профессию. Статья будет полезна новичкам в IT и тем, кто хочет перейти в специальность из смежных направлений.
Благодарим Владислава Шевченко, ведущего дата-инженера департамента продвинутой аналитики Альфа-Банка, за помощь в подготовке статьи.

Светлана Устилко
Что такое ETL-процессы
Понятие ETL происходит от английских слов Extract, Transform и Load, что означает «извлечение», «преобразование» и «загрузка». Оно подразумевает выборку данных из источников, их обработку и отправку на хранение в новое место.
Что представляют собой ETL-процессы:
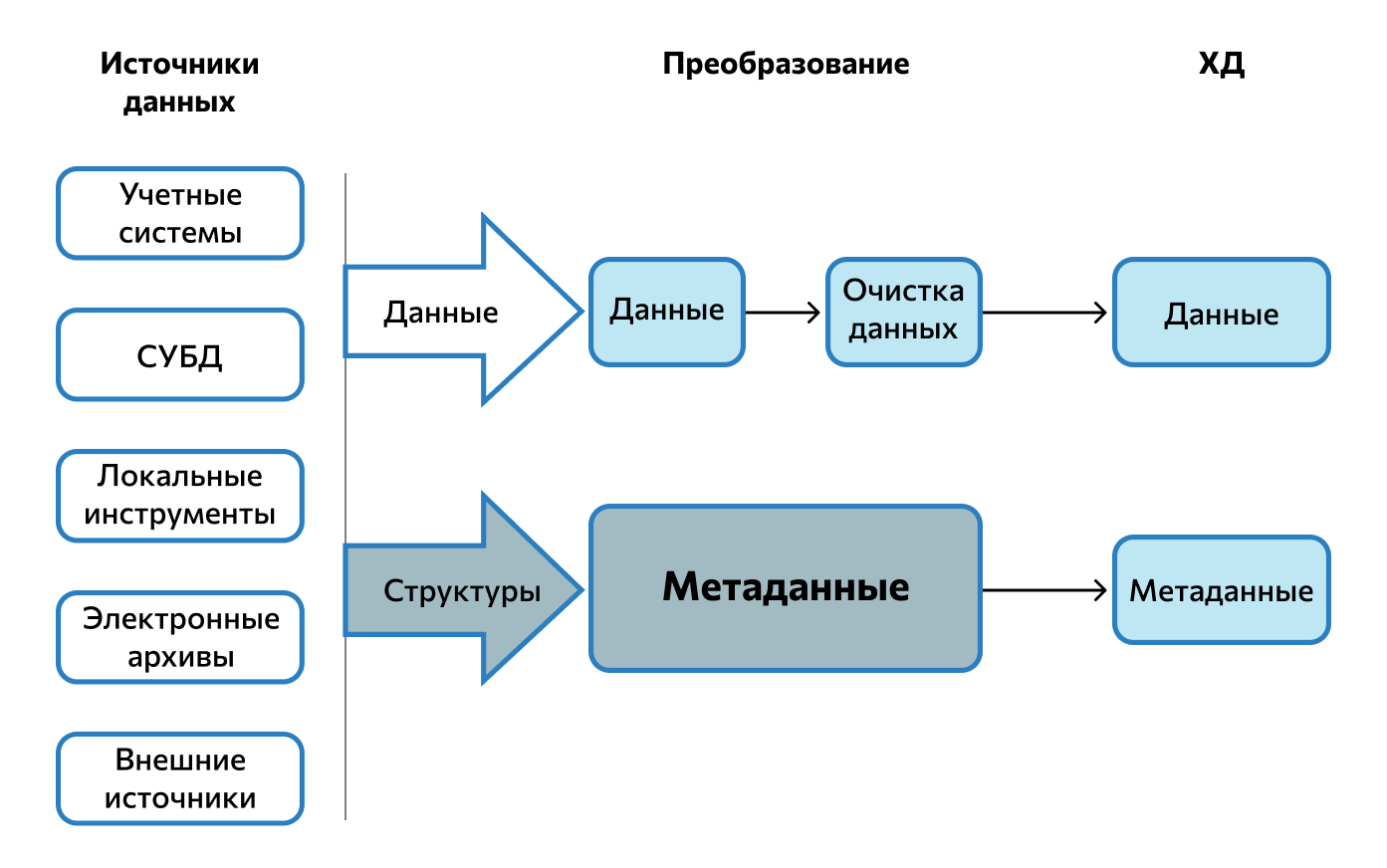
- Extract, или извлечение — выгрузка данных и информации о них из CRM, облака, баз данных (БД), таких как 1С:Предприятие и 1С:Зарплата, электронных архивов, файлов на компьютере, гугл-таблиц и других источников. Полученные сведения сохраняются для дальнейшей работы с ними в промежуточную область — среду для временного хранения извлечённых данных. После дальнейшего переноса информации содержимое этой области, как правило, стирается.
CRM — программы для автоматизации и контроля взаимодействия компании с клиентами.
- Transform, или преобразование — подготовка данных к анализу и загрузке на сервер в конечное хранилище данных (ХД). На втором этапе информацию проверяют, фильтруют, комбинируют, очищают от некорректных значений, дублей и спама, шифруют, приводят к единому формату и стандарту бизнес-модели.
- Load, или загрузка — отправка данных на конечный сервер ХД. Процесс подразумевает перенос на новое место не всей информации, а только той, которую нужно получить по техническому заданию. Это могут быть изменённые, дополненные и новые сведения, которые ранее не перемещались.
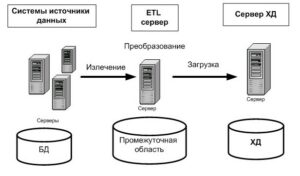
Проектированием, реализацией и контролем процессов извлечения, преобразования и загрузки занимаются ETL-разработчики.
Иногда специалистам приходится менять последовательность действий: с ETL на ELT. Такой алгоритм может использоваться при создании Hadoop-хранилищ, которые позволяют использовать большие объёмы данных без вреда для производительности сервера. В таком случае информация сразу загружается в новое место хранения, минуя промежуточную область, и только затем трансформируется.
Какие задачи решают ETL-разработчики
Специалисты помогают бизнесу собирать большие объёмы данных из разных источников, перерабатывать их для аналитики, отчётности и загрузки в программы, строить витрины данных — таблицы с уже обработанными данными. ETL-разработчики приводят выборку из разных учётных программ к единой системе значений, проверяют достоверность и полноту сведений, очищают их от багов.
Необходимость в специалистах чаще возникает в трёх случаях:
В рабочей базе накопился большой объём данных. Из-за недостатка вычислительных ресурсов запросы к ней выполняются долго. В этом случае ETL-разработчик извлекает из БД нужные сведения и переносит их на сервер, где эти данные можно анализировать и использовать для расчётов.
Программное обеспечение устарело. Организация переходит на новое ПО с оригинальной архитектурой и функциями. Нужно перенести ценную информацию из старой программы в пустую новую. Разработчик выгружает данные в промежуточную область, отбирает из них актуальные, приводит их к совместимому формату и переносит в новую программу.
Необходимые для решения бизнес-задач сведения лежат в разных местах, их необходимо собрать в одном хранилище для анализа. ETL-разработчик извлекает данные из источников и загружает в одну базу. Теперь бизнесу не нужно тратить массу времени на сбор информации для анализа.

Владислав Шевченко
Ведущий дата-инженер департамента продвинутой аналитики Альфа-Банка
Специалисты по ETL-процессам обеспечивают правильную и эффективную обработку данных в организации. Их помощь особенно нужна, когда бизнес работает с большими объёмами данных и сложными системами их хранения.
Задачи, с которыми сталкиваются ETL-разработчики:
- Анализ требований. Специалисту нужно понять, какие данные обрабатывать и как их использовать. Он должен вникать в требования бизнеса и аналитические потребности организации. Это помогает определить оптимальный процесс обработки и выгрузки информации.
- Поиск оптимального алгоритма действий. ETL-разработчик стремится к улучшению производительности, скорости и точности обработки. Для этого он анализирует текущие процессы и ищет пути их усовершенствования.
- Преобразование данных под требования бизнеса. Специалист определяет правила и логику операций с учётом целевой системы и запросов организации.
- Проектирование и разработка ETL-процессов. На основе требований бизнеса специалист создаёт план для извлечения, преобразования и загрузки данных: определяет дизайн и архитектуру ETL-процессов.
- Загрузка данных. Специалист отвечает за перенос преобразованных данных в целевую систему хранения.
Интеграция источников данных. В процессе работы ETL-разработчик должен настроить подключение к различным источникам данных: БД, файловым системам и так далее.
Обязанности ETL-разработчика могут меняться в зависимости от квалификации и профиля должности.


Какие знания и навыки нужны ETL-разработчику
Профессия ETL-разработчика предполагает знание языка запросов SQL, а также особенностей структурирования и хранения информации в цифровых системах. Специалисту нужно понимать, что такое реляционные и нереляционные базы и как устроены многомерные OLAP-кубы.
Реляционная база — это структурированная коллекция данных. Её основная идея — в хранении информации в виде таблиц, каждая из которых представляет собой отдельную сущность или тип данных: пользователи, заказы и так далее.
Нереляционная база устроена иначе: в ней не используется табличная схема строк и столбцов. В этой базе применяется модель хранения, оптимизированная под конкретные требования типа хранимых данных. Например, данные могут храниться в текстовом формате, основанном на JavaScript (JSON), или в виде граф, состоящий из рёбер и вершин.
OLAP-куб — многомерная структура, которая используется для анализа информации и отчётности. Она представляет собой таблицу, в которой каждое измерение — это характеристика данных: местоположение, время, продукт и так далее.
Владислав Шевченко
Ведущий дата-инженер департамента продвинутой аналитики Альфа-Банка
Вот какие знания понадобятся ETL-разработчику в работе ↓
- Основы работы с базами данных и язык SQL, который необходим для извлечения данных из различных источников, их преобразования и загрузки.
- Принципы ETL: основы процессов, лучшие стратегии, практики и рекомендации.
- Знание языков программирования: Python или Scala. Эти языки пригодятся для автоматизации и оптимизации ETL-процессов.
- Понимание моделей и структур данных: реляционных и нереляционных баз, текстовых форматов обмена данными, языка разметки XML. Это нужно для правильной обработки и преобразования данных.
А это навыки, которые потребуются специалисту ↓
- Проектирование конечного ХД на сервере и выбор моделей хранения: помогает организовать оптимальное место для размещения данных компании.