Функция EXCEL ЛИНЕЙН()
Функция ЛИНЕЙН() может использоваться для простой регрессии (в этом случае прогнозируемая переменная Y зависит от одной контролируемой переменной Х) и для множественной регрессии (Y зависит от нескольких Х).
Рассмотрим функцию на примере простой регрессии (оценивается наклон и сдвиг линии регрессии). Использование функции в случае множественной регрессии рассмотрено в соответствующей статье про множественную регрессию .
Функция ЛИНЕЙН() возвращает несколько значений, поэтому для вывода результатов потребуется несколько ячеек. Часто функцию вводят как формулу массива : нажатием клавиш CTRL + SHIFT + ENTER , но, как будет показано ниже, для вывода результатов вычислений это не обязательно.
Функция работает в 2-х режимах. В простейшем случае, когда 4-й аргумент функции опущен или установлен ЛОЖЬ, функция возвращает только 2 значения — это оценки параметров модели: наклона a и сдвига b.
Для того, чтобы вычислить оценки:
- выделите 2 ячейки в одной строке,
- в Строке формул введите, например, = ЛИНЕЙН(C23:C83;B23:B83)
- нажмите CTRL+SHIFT+ENTER.
В левой ячейке будет рассчитано значение наклона , в правой – сдвига .
Примечание : В справке MS EXCEL результат функции ЛИНЕЙН() соответствующий наклону обозначается буквой m, а сдвиг – буквой b.
Примечание : Без формул массива можно обойтись. Для этого нужно использовать функцию ИНДЕКС() , которая выведет нужное значение. Например, чтобы вывести величину сдвига линии регрессии введите формулу = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;2) . Если 4-й аргумент функции опущен или установлен ЛОЖЬ, то функция ЛИНЕЙН() в возвращает массив значений вида 1х2 (т.е. 2 ячейки, расположенные в одной строке). Поэтому, для вывода величины сдвига прямой линии регрессии, первый аргумент функции ИНДЕКС() , который является номером строки, должен быть равен 1, а второй аргумент, номер столбца, должен быть равен 2. Чтобы вывести значение наклона линии регрессии формулу =ЛИНЕЙН(C23:C83;B23:B83) достаточно ввести просто как обычную формулу и нажать ENTER . Конечно, можно использовать и формулу =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;1) .
Теперь о втором, более сложном режиме функции. Этот режим нужно использовать, если требуется вывести дополнительную статистику (4-й аргумент функции должен быть установлен ИСТИНА). В этом случае функция ЛИНЕЙН() возвращает 10 значений в диапазоне 5х2 ячеек (5 строк и 2 столбца). Как и в более простом режиме, в первой строке возвращаются оценки параметров модели: наклона и сдвига .
Чтобы ввести функцию как формулу массива выполните следующие действия:
- выделите диапазон 5х2 ячеек (2 столбца и 5 строк),
- в Строке формул введите формулу ЛИНЕЙН($C$23:$C$83;$B$23:$B$83;;ИСТИНА)
- чтобы ввести формулу нажмите одновременно комбинацию клавиш CTRL + SHIFT + ENTER
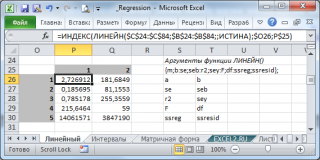
Примечание : Чтобы обойтись без формул массива нужно использовать функцию ИНДЕКС() , которая выведет нужное значение. Например, чтобы вывести коэффициент детерминации R 2 введите формулу = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;1) . 3 – это номер строки диапазона 5х2, а 1 – это номер столбца. В файле примера на листе Линейный в диапазоне Q 26: R 30 показано как вывести все значения, возвращаемые функцией ЛИНЕЙН() без формул массива .
Итак, установив 4-й аргумент равным ИСТИНА и введя функцию тем или иным способом, функция выведет:
- в строке 1: оценки параметров модели (наклон и сдвиг).
- в строке 2: Стандартные ошибки для наклона и сдвига . Ошибки обозначаются se и seb;
- в строке 3: коэффициент детерминации и стандартную ошибку регрессии . Обозначаются R 2 и SEy;
- в строке 4: значение F-статистики и число степеней свободы . Обозначаются F и df;
- в строке 5: Суммы квадратов SSR, SSE определяющие изменчивость объясненную и необъясненную моделью (см. в статье Простая линейная регрессия разделы про коэффициент детерминации и статью про F-тест ). В справке MS EXCEL SSR, SSE обозначаются как ssreg (Regression Sum of Squares) и ssresid (Residuals Sum of Squares) соответственно.
Примечание : Разобраться в значениях, возвращаемых функцией ЛИНЕЙН() , можно лишь разобравшись в теории линейной регрессии.
В файле примера также приведены формулы, позволяющие сделать расчеты без функции ЛИНЕЙН() – см. диапазон Q 34: R 38 . Альтернативные формулы помогают разобраться в алгоритме расчета вышеуказанных статистических показателей.
Функция ЛИНЕЙН
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще. Меньше
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = m1x1 + m2x2 +. + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив . Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
- Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
- Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
- Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
- Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
- Если массив известные_значения_x опущен, то предполагается, что это массив , имеющий такой же размер, что и массив известные_значения_y.
- Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
- Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
- Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив .
- Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b. Дополнительная регрессионная статистика.
Стандартные значения ошибок для коэффициентов m1,m2. mn.
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ).
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, как вычисляется 2, см. в разделе «Замечания» далее в этой теме.
Стандартная ошибка для оценки y.
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными.
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df.
Регрессионная сумма квадратов.
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.
Замечания
- Любую прямую можно описать ее наклоном и пересечением с осью y: Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1). Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y. Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ. - Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами: Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1) Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2) - Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам: где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ(известные_значения_y).
- Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y(known_x) для прямой линии или РОСТ(known_y, known_x в) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
- Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r 2 — индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r 2 равно ssreg/sstotal.
- В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
- Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
- При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
- Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
- Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
- Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
- Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Известные значения y
Известные значения x
Результат (наклон)
Результат (y-пересечение)
Формула (формула массива в ячейках A7:B7)
Пример 2. Простая линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Вычисляет предполагаемый объем продаж в девятом месяце на основе данных о продажах за период с первого по шестой месяцы.
Пример 3. Множественная линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Общая площадь (x1)
Количество офисов (x2)
Количество входов (x3)
Время эксплуатации (x4)
Оценочная цена (y)
Формула (формула динамического массива, введенная в A19)
=ЛИНЕЙН(E2:E12; A2:D12; ИСТИНА; ИСТИНА)
Пример 4. Использование статистики F и r 2
В предыдущем примере коэффициент определения (r 2) составляет 0,99675 (см. ячейку A17 в результатах для ЛИТН), что указывает на крепкая связь между независимыми переменными и ценой продажи. F-статистику можно использовать для определения случайности этих результатов с таким высоким значением r2.
Предположим, что на самом деле взаимосвязи между переменными не существует, просто статистический анализ вывел сильную взаимозависимость по взятой равномерной выборке 11 зданий. Величина «Альфа» используется для обозначения вероятности ошибочного вывода о существовании сильная взаимозависимости.
Значения F и df в результатах функции LINEST можно использовать для оценки вероятности возникновения более высокого F-значения. F можно сравнивать с критическими значениями в опубликованных F-таблицах или с помощью функции FРАСП в Excel для вычисления вероятности случайного возникновения большего F-значения. Соответствующее F-распределение имеет v1 и v2 степени свободы. Если n — количество точек данных и конст = ИСТИНА или опущен, то v1 = n – df – 1 и v2 = df. (Если конст = ЛОЖЬ, то v1 = n – df и v2 = df.) Функция FIST с синтаксисом FDIST(F;v1;v2) возвращает вероятность возникновения более высокого F-значения, случайного. В этом примере df = 6 (ячейка B18) и F = 459,753674 (ячейка A18).
Предположим, что альфа имеет значение 0,05, v1 = 11 – 6 – 1 = 4, а v2 = 6, критический уровень F составляет 4,53. Поскольку F = 459,753674 значительно больше 4,53, вероятность того, что F-значение этого высокой случайности превышает 4,53, крайне маловероятно. (Если значение «Альфа» = 0,05, гипотеза о том, что между known_y и known_x нет связи, отклоняется при превышении F критического уровня (4,53).) Функцию FDIST в Excel можно использовать для получения вероятности случайного возникновения F-значения. Например, FIST(459,753674, 4, 6) = 1,37E-7, очень небольшая вероятность. Можно сделать вывод о том, что формула регрессии полезна для предсказания оценочного значения офисных зданий в этой области, найдя критический уровень F в таблице или с помощью функции FDIST. Помните, что крайне важно использовать правильные значения 1 и 2, вычисленные в предыдущем абзаце.
Пример 5. Вычисление t-статистики
Другой тест позволяет определить, подходит ли каждый коэффициент наклона для оценки стоимости здания под офис в примере 3. Например, чтобы проверить, имеет ли срок эксплуатации здания статистическую значимость, разделим -234,24 (коэффициент наклона для срока эксплуатации здания) на 13,268 (оценка стандартной ошибки для коэффициента времени эксплуатации из ячейки A15). Ниже приводится наблюдаемое t-значение:
t = m4 ÷ se4 = –234,24 ÷ 13,268 = –17,7
Если абсолютное значение t достаточно велико, можно сделать вывод, что коэффициент наклона можно использовать для оценки стоимости здания под офис в примере 3. В таблице ниже приведены абсолютные значения четырех наблюдаемых t-значений.
Если обратиться к справочнику по математической статистике, то окажется, что t-критическое двустороннее с 6 степенями свободы равно 2,447 при Альфа = 0,05. Критическое значение также можно также найти с помощью функции Microsoft Excel СТЬЮДРАСПОБР. СТЬЮДРАСПОБР(0,05; 6) = 2,447. Поскольку абсолютная величина t, равная 17,7, больше, чем 2,447, срок эксплуатации — это важная переменная для оценки стоимости здания под офис. Аналогичным образом можно протестировать все другие переменные на статистическую значимость. Ниже приводятся наблюдаемые t-значения для каждой из независимых переменных.
t-наблюдаемое значение
Примеры как пользоваться функцией ЛИНЕЙН в Excel
Задача отыскания функциональной зависимости очень важна, поэтому для ее решения в MS Excel введен набор функций, основанных на методе наименьших квадратов. В качестве результата выдаются не только коэффициенты функции, приближающей данные, но и статистические характеристики полученных результатов.
Смысл выходной статистической информации функции ЛИНЕЙН
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, вычисляя прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую.
Общий синтаксис вызова функции ЛИНЕЙН имеет следующий вид:
Для работы с функцией необходимо заполнить как минимум 1 обязательный и при необходимости 3 необязательных аргумента:
- Известные_значения_y − это множество значений y , которые уже известны для соотношения y=mx+b.
- Известные_значения_x − это множество известных значений x . Если этот аргумент опущен, то предполагается, что это массив такого же размера, как и известные_значения_y.
- Конст − это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если в функции ЛИНЕЙН аргумент константа имеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = mx.
- Статистика − это логическое значение, которое указывает, требуется ли выдать дополнительную статистику по регрессии.
Примеры использования функции ЛИНЕЙН в Excel
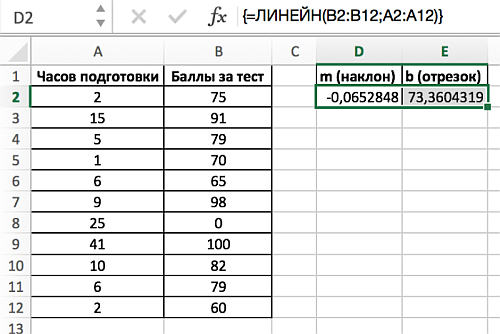
Для решения первой задачи – о соотношении часов подготовки студентов к тесту и результатов теста, как х и у соответственно, – необходимо применить следующий порядок действий (в связи с тем, что ЛИНЕЙН является функцией, которая возвращает массив):
- Выделите диапазон D2:Е2, так как функция ЛИНЕЙН возвращает массив из двух значений, расположенных по горизонтали, но не по вертикали.
- Введите известные значения y – баллы, которые студенты заработали на последнем тестировании (диапазон ячеек В2:В12).
- Затем введите известные значения х – количество часов, которые студенты потратили на подготовку к тестам (диапазон А2:А12).
- Опустите аргумент [конст].
- Опустите аргумент [статистика].
- Введите формулу с помощью Ctrl+Shift+Enter.
Результатом применения функции становится:
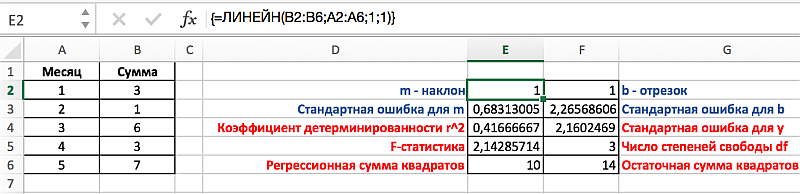
Теперь, на примере решения второй задачи, разберем необходимость в отображении не только наклона и отрезка, но и дополнительной статистики. Для примера, на диапазоне А1:В6 выстроим таблицу с соотношением у и х соответствующих сумме заработка студентом денежных средств за период в 5 месяцев. Так как мы имеем лишь одну переменную х, то необходимо выделить диапазон состоящий из двух столбцов и пяти строк. Важно отметить, что в том случае, если переменных х будет больше, то количество столбцов может изменяться соответственно их количеству, однако строк будет всегда 5.
Применительно к решаемой нами задаче, выделим диапазон Е2:F6, затем введем формулу аналогично предыдущей задаче, но в данном случае третьему и четвертому аргументу присвоим значение 1 соответствующее ИСТИНЕ. Для вывода параметров статистики функции ЛИНЕЙН необходимо нажат Ctrl+Shift+Enter, результат должен соответствовать следующему рисунку, на котором представлено обозначение дополнительных статистик:
Вернемся к примеру № 1, касающемуся зависимости между часами подготовки студентов к тесту и баллов за тест. Добавим к условию задачи данные о баллах за домашнее задание — представляющие дополнительную переменную х, что свидетельствует о необходимости применения множественной регрессии.
В случае множественной регрессии, когда значения « y » зависят от двух переменных « х », функция ЛИНЕЙН возвращает 12 статистик. На рисунке с модифицированной таблицей от 1 примера, представленном ниже используются следующие обозначения:
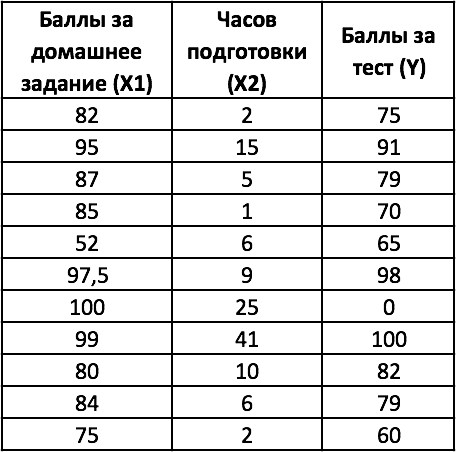
- y = зависимая переменная;
- x1 = независимая переменная 1 = баллы за домашнее задание;
- x2 = независимая переменная 2 = часы подготовки к тесту.
Чтобы выполнить множественную регрессию:
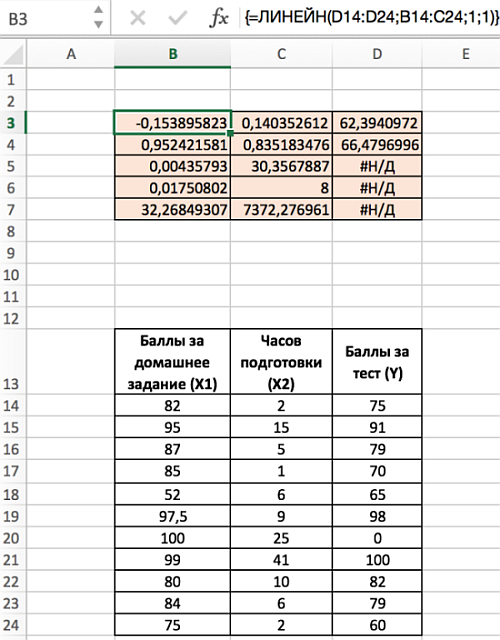
- Выделите диапазон В3:D7 (число столбцов = число переменных +1; число строк всегда равно 5).
- Наберите формулу =ЛИНЕЙН(D14:D24;B14:C24;1;1). Для аргумента известные_значения_х, выделите оба столбца значений x из диапазона В14:С24.
- Введите функцию с помощью клавиш Ctrl+Shift+Enter.
- Обратите внимание, что несмотря на то, что значения х1 указаны в диапазоне В14:С24 до значений х2, наклон сначала указан для х2.
Диапазон D5:D7 содержит ошибку #Н/Д – значащую, что формула не может обнаружить значения для данных ячеек. Визуально наличие ошибки отвлекает от сути решения, поэтому далее предложим вариант избавления от нее. Так, если дополнить формулу содержащую функцию ЛИНЕЙН функцией ЕСЛИОШИБКА, то можно значительно улучшить вид таблицы, результат которой представлен ниже:
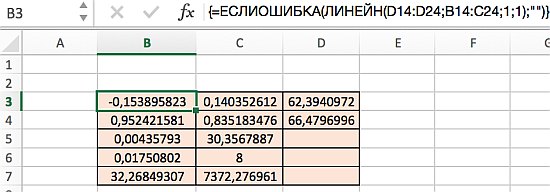
Распределение статистик в таблице их значение представлено на следующем рисунке:
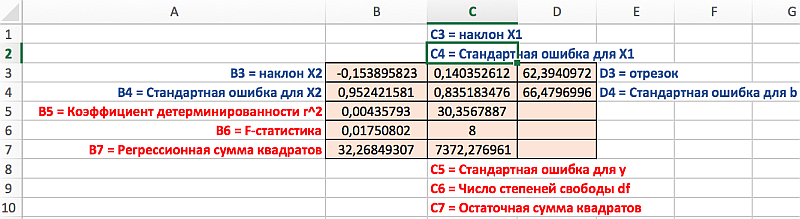
В результате мы получили всю необходимую выходную статистическую информацию, которая нас интересует.
Excel функция ЛИНЕЙН (LINEST)
Microsoft Excel функция ЛИНЕЙН в Microsoft Excel использует метод наименьших квадратов для вычисления статистики для прямой линии и возвращает массив, описывающий эту линию.
Функция ЛИНЕЙН — это встроенная в Excel функция, относится к категории статистических функций.
Её можно использовать как функцию рабочего листа (WS) в Excel.
Как функцию рабочего листа, функцию ЛИНЕЙН можно ввести как часть формулы в ячейку рабочего листа.
Функция ЛИНЕЙН использует следующее линейное уравнение:y = mx + b (для одного диапазона значений x )
y = m1x1 + m2x2 + . + b (для нескольких диапазонов значений x )Синтаксис
Синтаксис функции ЛИНЕЙН в Microsoft Excel:
ЛИНЕЙН ( известные_значения_y; [известные_значения_x]; [конст]; [статистика] )
Аргументы или параметры
известные_значения_y Известный набор значений y из линейного уравнения. известные_значения_x Необязательно. Это известный набор значений x из линейного уравнения. Если этот параметр не указан, предполагается, что известные_значения_x равняется <1;2;3; …>с тем же количеством значений, что и известные_значения_y . конст Необязательно. Это ИСТИНА или ЛОЖЬ. Если этот параметр не указан, функция принимает значение ИСТИНА. Если конст — ИСТИНА, b в линейном уравнении вычисляется нормально. Если конст имеет значение ЛОЖЬ, b становится 0, так что уравнение линии вычисляется как y = mx. статистика Необязательно. Это ИСТИНА или ЛОЖЬ. Если этот параметр не указан, функция примет значение ЛОЖЬ. Если статистика имеет значение ИСТИНА, функция вернет дополнительную статистику регрессии. Если статистика имеет значение ЛОЖЬ, функция вернет только коэффициенты m и константу b .
Возвращаемое значение
Функция ЛИНЕЙН возвращает числовое значение.
Применение
- Excel для Office 365, Excel 2019, Excel 2016, Excel 2013, Excel 2011 для Mac, Excel 2010, Excel 2007, Excel 2003, Excel XP, Excel 2000
Тип функции
- Функция рабочего листа (WS)
Пример (как функция рабочего листа)
Рассмотрим несколько примеров функции ЛИНЕЙН, чтобы понять, как использовать Excel функцию ЛИНЕЙН в качестве функции рабочего листа в Microsoft Excel:
В этом первом примере мы ввели значения y в столбец A (ячейки с A2 по A6) и значения x в столбце B (ячейки с B2 по B6). Затем мы ввели следующую функцию ЛИНЕЙН в обе ячейки D2 и E2 следующим образом: