Сборка мусора
Управление памятью в JavaScript выполняется автоматически и незаметно. Мы создаём примитивы, объекты, функции… Всё это занимает память.
Но что происходит, когда что-то больше не нужно? Как движок JavaScript обнаруживает, что пора очищать память?
Достижимость
Основной концепцией управления памятью в JavaScript является принцип достижимости.
Если упростить, то «достижимые» значения – это те, которые доступны или используются. Они гарантированно находятся в памяти.
- Существует базовое множество достижимых значений, которые не могут быть удалены. Например:
- Выполняемая в данный момент функция, её локальные переменные и параметры.
- Другие функции в текущей цепочке вложенных вызовов, их локальные переменные и параметры.
- Глобальные переменные.
- (некоторые другие внутренние значения)
Эти значения мы будем называть корнями.
В движке JavaScript есть фоновый процесс, который называется сборщиком мусора. Он отслеживает все объекты и удаляет те, которые стали недоступными.
Простой пример
Вот самый простой пример:
// в user находится ссылка на объект let user = < name: "John" >;Здесь стрелка обозначает ссылку на объект. Глобальная переменная user ссылается на объект (мы будем называть его просто «John» для краткости). В свойстве «name» объекта John хранится примитив, поэтому оно нарисовано внутри объекта.
Если перезаписать значение user , то ссылка потеряется:
user = null;Теперь объект John становится недостижимым. К нему нет доступа, на него нет ссылок. Сборщик мусора удалит эти данные и освободит память.
Две ссылки
Представим, что мы скопировали ссылку из user в admin :
// в user находится ссылка на объект let user = < name: "John" >; let admin = user;Теперь, если мы сделаем то же самое:
user = null;…то объект John всё ещё достижим через глобальную переменную admin , поэтому он находится в памяти. Если бы мы также перезаписали admin , то John был бы удалён.
Взаимосвязанные объекты
Теперь более сложный пример. Семья:
function marry(man, woman) < woman.husband = man; man.wife = woman; return < father: man, mother: woman >> let family = marry(< name: "John" >, < name: "Ann" >);Функция marry «женит» два объекта, давая им ссылки друг на друга, и возвращает новый объект, содержащий ссылки на два предыдущих.
В результате получаем такую структуру памяти:
На данный момент все объекты достижимы.
Теперь удалим две ссылки:
delete family.father; delete family.mother.husband;Недостаточно удалить только одну из этих двух ссылок, потому что все объекты останутся достижимыми.
Но если мы удалим обе, то увидим, что у объекта John больше нет входящих ссылок:
Исходящие ссылки не имеют значения. Только входящие ссылки могут сделать объект достижимым. Объект John теперь недостижим и будет удалён из памяти со всеми своими данными, которые также стали недоступны.
После сборки мусора:
Недостижимый «остров»
Вполне возможна ситуация, при которой целый «остров» взаимосвязанных объектов может стать недостижимым и удалиться из памяти.
Возьмём объект family из примера выше. А затем:
family = null;Структура в памяти теперь станет такой:
Этот пример демонстрирует, насколько важна концепция достижимости.
Объекты John и Ann всё ещё связаны, оба имеют входящие ссылки, но этого недостаточно.
Бывший объект family был отсоединён от корня, на него больше нет ссылки, поэтому весь «остров» становится недостижимым и будет удалён.
Внутренние алгоритмы
Основной алгоритм сборки мусора называется «алгоритм пометок» (от англ. «mark-and-sweep»).
Согласно этому алгоритму, сборщик мусора регулярно выполняет следующие шаги:
- Сборщик мусора «помечает» (запоминает) все корневые объекты.
- Затем он идёт по ним и «помечает» все ссылки из них.
- Затем он идёт по отмеченным объектам и отмечает их ссылки. Все посещённые объекты запоминаются, чтобы в будущем не посещать один и тот же объект дважды.
- …И так далее, пока не будут посещены все достижимые (из корней) ссылки.
- Все непомеченные объекты удаляются.
Например, пусть наша структура объектов выглядит так:
Мы ясно видим «недостижимый остров» справа. Теперь давайте посмотрим, как будет работать «алгоритм пометок» сборщика мусора.
На первом шаге помечаются корни:
Затем помечаются объекты по их ссылкам:
…А затем объекты по их ссылкам и так далее, пока это возможно:
Теперь объекты, которые не удалось посетить в процессе, считаются недостижимыми и будут удалены:
Мы также можем представить себе этот процесс как выливание огромного ведра краски из корней, которая течёт по всем ссылкам и отмечает все достижимые объекты. Затем непомеченные удаляются.
Это концепция того, как работает сборка мусора. Движки JavaScript применяют множество оптимизаций, чтобы она работала быстрее и не задерживала выполнение кода.
Вот некоторые из оптимизаций:
- Сборка по поколениям (Generational collection) – объекты делятся на два набора: «новые» и «старые». В типичном коде многие объекты имеют короткую жизнь: они появляются, выполняют свою работу и быстро умирают, так что имеет смысл отслеживать новые объекты и, если это так, быстро очищать от них память. Те, которые выживают достаточно долго, становятся «старыми» и проверяются реже.
- Инкрементальная сборка (Incremental collection) – если объектов много, и мы пытаемся обойти и пометить весь набор объектов сразу, это может занять некоторое время и привести к видимым задержкам в выполнении скрипта. Так что движок делит всё множество объектов на части, и далее очищает их одну за другой. Получается несколько небольших сборок мусора вместо одной всеобщей. Это требует дополнительного учёта для отслеживания изменений между частями, но зато получается много крошечных задержек вместо одной большой.
- Сборка в свободное время (Idle-time collection) – чтобы уменьшить возможное влияние на производительность, сборщик мусора старается работать только во время простоя процессора.
Существуют и другие способы оптимизации и разновидности алгоритмов сборки мусора. Но как бы мне ни хотелось описать их здесь, я должен воздержаться, потому что разные движки реализуют разные хитрости и методы. И, что ещё более важно, все меняется по мере развития движков, поэтому изучать тему глубоко «заранее», без реальной необходимости, вероятно, не стоит. Если, конечно, это не вопрос чистого интереса, тогда для вас будет несколько ссылок ниже.
Итого
Главное, что нужно знать:
- Сборка мусора выполняется автоматически. Мы не можем ускорить или предотвратить её.
- Объекты сохраняются в памяти, пока они достижимы.
- Если на объект есть ссылка – вовсе не факт, что он является достижимым (из корня): набор взаимосвязанных объектов может стать недоступен в целом, как мы видели в примере выше.
Современные движки реализуют разные продвинутые алгоритмы сборки мусора.
О многих из них рассказано в прекрасной книге о сборке мусора «The Garbage Collection Handbook: The Art of Automatic Memory Management» (R. Jones и др.).
Если вы знакомы с низкоуровневым программированием, то более подробная информация о сборщике мусора V8 находится в статье A tour of V8: Garbage Collection.
Также в блоге V8 время от времени публикуются статьи об изменениях в управлении памятью. Разумеется, чтобы изучить сборку мусора, вам лучше подготовиться, узнав о том как устроен движок V8 внутри в целом и почитав блог Вячеслава Егорова, одного из инженеров, разрабатывавших V8. Я говорю про «V8», потому что он лучше всего освещается в статьях в Интернете. Для других движков многие подходы схожи, но сборка мусора отличается во многих аспектах.
Глубокое понимание работы движков полезно, когда вам нужна низкоуровневая оптимизация. Было бы разумно запланировать их изучение как следующий шаг после того, как вы познакомитесь с языком.
Сборщик мусора Garbage Collection
Чтобы понять, как работает сборщик мусора Garbage Collection, необходимо иметь представление о распределении памяти в JVM (Java Virtual Machine). Данная статья не претендует на то, чтобы покрыть весь объем знаний о распределении памяти в JVM и описании Garbage Collection, поскольку он слишком огромен. Да, к тому же, об этом достаточно информации уже имеется в Сети, чтобы желающие могли докапаться до ее глубин. Но, думаю, данной статьи будет достаточно, чтобы иметь представление о том, как JVM работает с памятью java-приложения.
Респределение памяти в JVM
Для рассмотрения вопроса распределения памяти JVM будем использовать широко распространенную виртуальную машину для Windows от Oracle HotSpot JVM (раньше был от Sun). Другие виртуальные машины (из комплекта WebLogic или open source JVM из Linux) работают с памятью по похожей на HotSpot схеме. Возможности адресации памяти, предоставляемые архитектурой ОС, зависят от разрядности процессора, определяющего общий диапазон емкости памяти. Так, например, 32-х разрядный процессор обеспечивает диапазон адресации 2 32 , то есть 4 ГБ. Диапазон адресации для 64-разрядного процессора (2 64 ) составляет 16 экзабайт.
Разделение памяти JVM
Память процесса делится на Stack (стек) и Heap (куча) и включает 5 областей :
- Stack
- Permanent Generation — используемая JVM память для хранения метаинформации; классы, методы и т.п.
- Code Cache — используемая JVM память при включенной JIT-компиляции; в этой области памяти кешируется скомпилированный платформенно-зависимый код.
- Eden Space — в этой области выделяется память под все создаваемые программой объекты. Жизненный цикл большей части объектов, к которым относятся итераторы, объекты внутри методов и т.п., недолгий.
- Survivor Space — здесь хранятся перемещенные из Eden Space объекты после первой сборки мусора. Объекты, пережившие несколько сборок мусора, перемещаются в следующую сборку Tenured Generation.
- Tenured Generation хранит долгоживущие объекты. Когда данная область памяти заполняется, выполняется полная сборка мусора (full, major collection).
Permanent Generation
Область памяти Permanent Generation используется виртуальной машиной JVM для хранения необходимых для управления программой данных, в том числе метаданные о созданных объектах. При каждом создании объекта JVM будет сохранять некоторый набор данных об объекте в области Permanent Generation. Соответственно, чем больше создается в программе объектов, тем больше требуется «пространства» в Permanent Generation.
Размер Permanent Generation можно задать двумя параметрами виртуальной машины JVM :
- -XX:PermSize – минимальный размер выделяемой памяти для Permanent Generation;
- -XX:MaxPermSize – максимальный размер выделяемой памяти для Permanent Generation.
Для «больших» Java-приложений можно при запуске определить одинаковые значения данных параметров, чтобы Permanent Generation была создана с максимальным размером. Это может увеличить производительность, поскольку динамическое изменение размера Permanent Generation является «дорогостоящей» (трудоёмкой) операцией. Определение одинаковых значений этих параметров может избавить JVM от выполнения дополнительных операций, связанных с проверкой необходимости изменения размера Permanent Generation.
Область памяти Heap
Куча Heap является основным сегментом памяти, где хранятся создаваемые объекты. Heap делится на два подсегмента : Tenured (Old) Generation и New Generation. New Generation в свою очередь делится на Eden Space и Survivor.
При создании нового объекта, когда используется оператор ‘new’, например byte[] data = new byte[1024], этот объект создаётся в сегменте Eden Space. Кроме, собственно данных для массива байт, создается также ссылка (указатель) на эти данные. Если места в сегменте Eden Space уже нет, то JVM выполняет сборку мусора. При сборке мусора объекты, на которые имеются ссылки, не удаляются, а перемещаются из одной области в другую. Так, объекты со ссылками перемещаются из Eden Space в Survivor Space, а объекты без ссылок удаляются.
Если количество используемой Eden Space памяти превышает некоторый заданный объем, то Garbage Collection может выполнить быструю (minor collection) сборку мусора. По сравнению с полной сборкой мусора данный процесс занимает немного времени, и затрагивает только область Eden Space — устаревшие объекты без ссылок удаляются, а выжившие перемещаются в область Survivor Space.
Размер сегмента Heap можно определить двумя параметрами : Xms (минимум) и -Xmx (максимум).
В чем отличие между сегментами Stack и Heap?
- Heap (куча) используется всеми частями приложения, а Stack используется только одним потоком исполнения программы.
- Новый объект создается в Heap, а в памяти Stack’a размещается ссылка на него. В памяти стека также размещаются локальные переменные примитивных типов.
- Объекты в куче доступны из любого места программы, в то время, как стековая память не доступна для других потоков.
- Если память стека полностью занята, то Java Runtime вызывает исключение java.lang.StackOverflowError, а если память кучи заполнена, то вызывается исключение java.lang.OutOfMemoryError: Java Heap Space.
- Размер памяти стека, как правило, намного меньше памяти в куче. Из-за простоты распределения памяти (LIFO), стековая память работает намного быстрее кучи.
Garbage Collector
Сборщик мусора Garbage Collector выполняет всего две задачи, связанные с поиском мусора и его очисткой. Для обнаружения мусора существует два подхода :
- Reference counting – учет ссылок;
- Tracing – трассировка.
Reference counting
Суть подхода «Reference counting» связана с тем, что каждый объект имеет счетчик, который хранит информацию о количестве указывающих на него ссылок. При уничтожении ссылки счетчик уменьшается. При нулевом значении счетчика объект можно считать мусором.
Главным недостатком данного подхода является сложность обеспечения точности счетчика и «невозможность» выявлять циклические зависимости. Так, например, два объекта могут ссылаться друг на друга, но ни на один из них нет внешней ссылки. Это сопровождается утечками памяти. В этой связи данный подход не получил распространения.
Tracing
Главная идея «Tracing» связана с тем, что до «живого» объекта можно добраться из корневых точек (GC Root). Всё, что доступно из «живого» объекта, также является «живым». Если представить все объекты и ссылки между ними как дерево, то необходимо пройти от корневых узлов GC Roots по всем узлам. При этом узлы, до которых нельзя добраться, являются мусором.
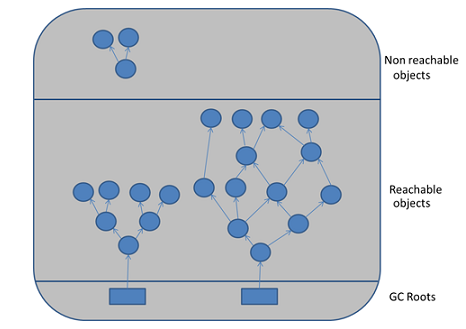
Данный подход, обеспечивающий выявление циклических ссылок, используется в виртуальной машине HotSpot VM. Теперь, осталось понять, а что представляет из себя корневая точка (GC Root)? «Источники» говорят, что существуют следующие типы корневых точек :
- Основной Java поток.
- Локальные переменные в основном методе.
- Статические переменные основного класса.
Таким образом, простое java-приложение будет иметь следующие корневые точки:
- Параметры main метода и локальные переменные внутри main метода.
- Поток, который выполняет main.
- Статические переменные основного класса, внутри которого находится main метод.
Очистка памяти
Имеется несколько подходов к очистке памяти, которые в совокупности определяют принцип функционирования Garbage Collection.
Copying collectors
При использовании «Copying collectors» область памяти делится на две части : в одной части размещаются объекты, а вторая часть остается чистой. На время очистки мусора приложение останавливает работу и запускается сборщик мусора, который находит в первой области объекты со ссылками и переносит их во вторую (чистую) область. После этого, первая область очищается от оставшихся там объектов без ссылок, и области меняются местами.
Главным достоинством данного подхода является плотное заполнение памяти. Недостатком «Copying collectors» является необходимость остановки приложения и размеры двух частей памяти должны быть одинаковыми на случай, когда все объекты остаются «живыми».
Данный подход в чистом виде в HotSpot VM не используется.
Mark-and-sweep
При использовании «mark-and-sweep» все объекты размещаются в одном сегменте памяти. Сборка мусора также приостанавливает приложение, и Garbage Collection проходит по дереву объектов, помечая занятые ими области памяти, как «живые». После этого, все не помеченные участки памяти сохраняются в «free list», в которой будут, после завершения сборки мусора, размещаться новые объекты.
К недостаткам данного подхода следует отнести необходимость приостановки приложения. Кроме этого, время сборки мусора, как и время приостановки приложения, зависит от размера памяти. Память становится «решетчатой», и, если не применить «уплотнение», то память будет использоваться неэффективно.
Данный подход также в чистом виде в HotSpot VM не используется.
Generational Garbage Collection
JVM HotSpot использует алгоритм сборки мусора типа «Generational Garbage Collection», который позволяет применять разные модули для разных этапов сборки мусора. Всего в HotSpot реализовано четыре сборщика мусора :
- Serial Garbage Collection
- Parallel Garbage Collection
- CMS Garbage Collection
- G1 Garbage Collection
Serial Garbage Collection относится к одним из первых сборщиков мусора в HotSpot VM. Во время работы этого сборщика приложение приостанавливается и возобновляет работу только после прекращения сборки мусора. В Serial Garbage Collection область памяти делится на две части («young generation» и «old generation»), для которых выполняются два типа сборки мусора :
- minor GC – частый и быстрый c областью памяти «young generation»;
- mark-sweep-compact – редкий и более длительный c областью памяти «old generation».
Область памяти «young generation», представленная на следующем рисунке, разделена на две части, одна из которых Survior также разделена на 2 части (From, To).
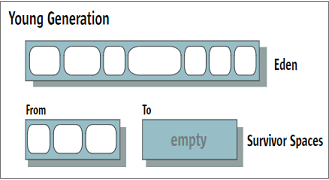
Алгоритм работы minor GC
Алгоритм работы minor GC очень похож на описанный выше «Copying collectors». Отличие связано с дополнительным использованием области памяти «Eden». Очистка мусора выполняется в несколько шагов :
- приложение приостанавливается на начало сборки мусора;
- «живые» объекты из Eden перемещаются в область памяти «To»;
- «живые» объекты из «From» перемещаются в «To» или в «old generation», если они достаточно «старые»;
- Eden и «From» очищаются от мусора;
- «To» и «From» меняются местами;
- приложение возобновляет работу.
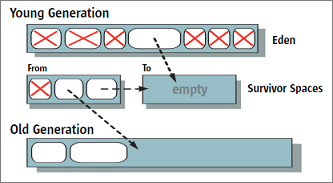
В результате сборки мусора картинка области памяти изменится и будет выглядеть следующим образом :
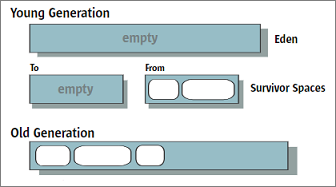
Некоторые объекты, пережившие несколько сборок мусора в области From, переносятся в «old generation». Следует, также отметить, что и «большие живые» объекты могут также сразу же пеместиться из области Eden в «old generation» (на картинке не показаны).
Алгоритм работы mark-sweep-compact
Алгоритм «mark-sweep-compact» связяан с очисткой и уплотнением области памяти «old generation».
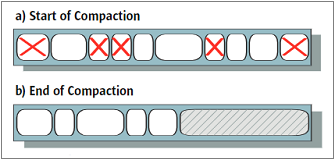
Принцип работы «mark-sweep-compact» похож на описанный выше «Mark-and-sweep», но добавляется процедура «уплотнения», позволяющая более эффективно использовать память. В процедуре живые объекты перемещаются в начало. Таким образом, мусор остается в конце памяти.
При работе с областью памяти используется механизм «bump-the-pointer», определяющий указатель на начало свободной памяти, в которой размещается создаваемый объект, после чего указатель смещается. В многопоточном приложении используется механизм TLAB (Thread-Local Allocation Buffers), который для каждого потока выделяет определенную область памяти.
Что такое сборщик мусора в Java
Узнайте, что такое сборщик мусора в Java, как он работает и какие алгоритмы использует для эффективного управления памятью.
Алексей Кодов
Автор статьи
9 июня 2023 в 16:31Сборщик мусора (Garbage Collector, GC) является важной частью системы управления памятью в Java. Он автоматически освобождает память, удаляя объекты, которые больше не используются программой. Это помогает предотвратить утечки памяти и обеспечивает более эффективное использование ресурсов.
Как работает сборщик мусора
Сборщик мусора в Java работает на основе принципа достижимости. Объект считается достижимым, если он доступен через ссылку из корневого набора ссылок (например, из статических полей, локальных переменных или активных стек-фреймов). Если объект недостижим, считается, что он больше не нужен, и его память может быть освобождена.
Процесс сборки мусора состоит из двух основных этапов:
- Маркировка (Marking): Во время этого этапа сборщик мусора определяет, какие объекты являются достижимыми и какие нет. Он проходит по дереву ссылок, начиная с корневых ссылок, и маркирует все достижимые объекты.
- Очистка (Sweeping): На этом этапе сборщик мусора удаляет недостижимые объекты и освобождает память, занятую ими. В зависимости от алгоритма сборки мусора, это может включать перемещение достижимых объектов и сжатие памяти для более эффективного использования.
Java-разработчик: новая работа через 11 месяцев
Получится, даже если у вас нет опыта в IT
Алгоритмы сборки мусора
В Java существует несколько алгоритмов сборки мусора, которые можно выбрать в зависимости от требований к производительности и памяти. Некоторые из наиболее распространенных алгоритмов включают:
- Serial GC: Использует однопоточную сборку мусора, подходит для небольших приложений с ограниченными ресурсами.
- Parallel GC: Использует многопоточную сборку мусора для ускорения процесса, подходит для приложений с большим объемом памяти и многопроцессорными системами.
- Concurrent Mark Sweep (CMS) GC: Осуществляет сборку мусора параллельно с работой приложения, уменьшая паузы, связанные с очисткой памяти. Подходит для приложений с высокими требованиями к отзывчивости.
- G1 (Garbage First) GC: Высокопроизводительный алгоритм сборки мусора, который сосредоточен на минимизации пауз и управлении большими кучами памяти.
Пример использования сборщика мусора
Допустим, у вас есть следующий код:
public class Example < public static void main(String[] args) < String str1 = new String("Hello"); String str2 = new String("World"); str1 = null; >>В этом примере сначала создается объект str1 со значением «Hello». Затем создается объект str2 со значением «World». После этого str1 устанавливается в null , делая объект «Hello» недостижимым. Сборщик мусора может определить, что этот объект больше не используется, и освободить память, занятую им.
�� Сборщик мусора в Java значительно упрощает управление памятью и предотвращает утечки памяти, но важно понимать его принципы работы и алгоритмы для эффективного использования ресурсов системы.
Сборка мусора в Java: что это такое и как работает в JVM
Перед началом статьи хочу сказать, что еще больше полезной и нужной информации вы найдете в моём Telegram-канале. Подпишитесь, мне будет очень приятно.
Что такое сборка мусора в Java?
Сборка мусора — это процесс восстановления заполненной памяти среды выполнения путем уничтожения неиспользуемых объектов.
В таких языках, как C и C++, программист отвечает как за создание, так и за уничтожение объектов. Иногда программист может забыть уничтожить бесполезные объекты, и выделенная им память не освобождается. Расходуется все больше и больше системной памяти, и в конечном итоге она больше не выделяется. Такие приложения страдают от “утечек памяти”.
После определенного момента памяти уже не хватает для создания новых объектов, и программа нештатно завершается из-за OutOfMemoryErrors.
В C++ для сборки мусора можно воспользоваться методом delete(), а в C — методом free(). В Java сборка мусора происходит автоматически в течение всего времени работы программы. Это устраняет необходимость выделения памяти и, следовательно, позволяет избежать утечек.
Сборка мусора в Java — это процесс, с помощью которого программы Java автоматически управляют памятью. Java-программы компилируются в байт-код, который запускается на виртуальной машине Java (JVM).
Когда Java-программы выполняются на JVM, объекты создаются в куче, которая представляет собой часть памяти, выделенную для них.
Пока Java-приложение работает, в нем создаются и запускаются новые объекты. В конце концов некоторые объекты перестают быть нужны. Можно сказать, что в любой момент времени память кучи состоит из двух типов объектов.
- Живые — эти объекты используются, на них ссылаются откуда-то еще.
- Мертвые — эти объекты больше нигде не используются, ссылок на них нет.
Сборщик мусора находит эти неиспользуемые объекты и удаляет их, чтобы освободить память.
Как разыменовать объект в Java
Основная цель сборки мусора — освободить память кучи, уничтожив объекты, которые не содержат ссылку. Когда на объект нет ссылки, предполагается, что он мертв и больше не нужен. Таким образом, память, занятая объектом, может быть восстановлена.
Есть несколько способов убрать ссылки на объект и сделать его кандидатом на сборку мусора. Вот некоторые из них.
Сделать ссылку нулевой
Student student = new Student(); student = null;
Назначить ссылку другому объектуStudent studentOne = new Student(); Student studentTwo = new Student(); studentOne = studentTwo; // Т
Использовать анонимный объект
register(new Student());
Как работает сборка мусора в Java?Сборка мусора в Java — автоматический процесс. Программисту не нужно явно отмечать объекты, подлежащие удалению.
Сборка мусора производится в JVM. Каждая JVM может реализовать собственную версию сборки мусора. Однако сборщик должен соответствовать стандартной спецификации JVM для работы с объектами, присутствующими в памяти кучи, для маркировки или идентификации недостижимых объектов и их уничтожения через уплотнение.
Каковы источники для сборки мусора в Java?
Сборщики мусора работают с концепцией корней сбора мусора (GC Roots) для идентификации живых и мертвых объектов.
Примеры таких корней.
- Классы, загружаемые системным загрузчиком классов (не пользовательские загрузчики классов).
- Живые потоки.
- Локальные переменные и параметры выполняемых в данный момент методов.
- Локальные переменные и параметры методов JNI.
- Глобальная ссылка на JNI.
- Объекты, применяемые в качестве монитора для синхронизации.
- Объекты, удерживаемые из сборки мусора JVM для своих целей.
Сборщик мусора просматривает весь граф объектов в памяти, начиная с этих корней и следуя ссылкам на другие объекты.
Этапы сборки мусора в Java
Стандартная реализация сборки мусора включает в себя три этапа.
Пометка объектов как живых
На этом этапе GC (сборщик мусора) идентифицирует все живые объекты в памяти путем обхода графа объектов.
Когда GC посещает объект, то помечает его как доступный и, следовательно, живой. Все объекты, недоступные из корней GC, рассматриваются как кандидаты на сбор мусора.
Зачистка мертвых объектов
После фазы разметки пространство памяти занято либо живыми (посещенными), либо мертвыми (не посещенными) объектами. Фаза зачистки освобождает фрагменты памяти, которые содержат эти мертвые объекты.
Компактное расположение оставшихся объектов в памяти
Мертвые объекты, которые были удалены во время предыдущей фазы, не обязательно находились рядом друг с другом. Поэтому вы рискуете получить фрагментированное пространство памяти.
Память можно уплотнить, когда сборщик мусора удалит мертвые объекты. Оставшиеся будут располагаться в непрерывном блоке в начале кучи.
Процесс уплотнения облегчает последовательное выделение памяти для новых объектов.
Что такое сбор мусора по поколениям?
Сборщики мусора в Java реализуют стратегию сбора мусора поколений, которая классифицирует объекты по возрасту.
Необходимость отмечать и уплотнять все объекты в JVM неэффективна. По мере выделения все большего количества объектов их список растет, что приводит к увеличению времени сбора мусора. Эмпирический анализ приложений показал, что большинство объектов в Java недолговечны.
В приведенном выше примере ось Y показывает количество выделенных байтов, а ось X — количество выделенных байтов с течением времени. Как видно, со временем все меньше и меньше объектов сохраняют выделенную память.
Большинство объектов живут очень мало, что соответствует более высоким значениям в левой части графика. Вот почему Java классифицирует объекты по поколениям и выполняет сборку мусора в соответствии с ними.
Область памяти кучи в JVM разделена на три секции:
Молодое поколение
Вновь созданные объекты начинаются в молодом поколении. Молодое поколение далее подразделяется на две категории.
- Пространство Эдема — все новые объекты начинают здесь, и им выделяется начальная память.
- Пространства выживших (FromSpace и ToSpace) — объекты перемещаются сюда из Эдема после того, как пережили один цикл сборки мусора.
Процесс, когда объекты собираются в мусор из молодого поколения, называется малым событием сборки мусора.
Когда пространство Эдема заполнено объектами, выполняется малая сборка мусора. Все мертвые объекты удаляются, а все живые — перемещаются в одно из оставшихся двух пространств. Малая GC также проверяет объекты в пространстве выживших и перемещает их в другое (следующее) пространство выживших.
Возьмем в качестве примера следующую последовательность.
- В Эдеме есть объекты обоих типов (живые и мертвые).
- Происходит малая GC — все мертвые объекты удаляются из Эдема. Все живые объекты перемещаются в пространство-1 (FromSpace). Эдем и пространство-2 теперь пусты.
- Новые объекты создаются и добавляются в Эдем. Некоторые объекты в Эдеме и пространстве-1 становятся мертвыми.
- Происходит малая GC — все мертвые объекты удаляются из Эдема и пространства-1. Все живые объекты перемещаются в пространство-2 (ToSpace). Эдем и пространство-2 снова пусты.
Таким образом, в любое время одно из пространств для выживших всегда пусто. Когда выжившие объекты достигают определенного порога перемещения по пространствам выживших, они переходят в старшее поколение.
Для установки размера молодого поколения можно воспользоваться флагом -Xmn.
Старшее поколение
Объекты-долгожители в конечном итоге переходят из молодого поколения в старшее. Оно также известно как штатное поколение и содержит объекты, которые долгое время оставались в пространствах выживших.
Пороговое значение срока службы объекта определяет, сколько циклов сборки мусора он может пережить, прежде чем будет перемещен в старшее поколение.
Процесс, когда объекты отправляются в мусор из старшего поколения, называется основным событием сборки мусора.
Для установки начального и максимального размера памяти кучи вы можете воспользоваться флагами -Xms и -Xmx.
Поскольку Java задействует сборку мусора по поколениям, то чем больше событий сборки мусора переживает объект, тем дальше он продвигается в куче. Он начинает в молодом поколении и в конечном итоге заканчивает в штатном поколении, если проживет достаточно долго.
Чтобы понять продвижение объектов между пространствами и поколениями, рассмотрим следующий пример.
Когда объект создается, он сначала помещается в пространство Эдема молодого поколения. Как только происходит малая сборка мусора, живые объекты из Эдема перемещаются в пространство FromSpace. Когда происходит следующая малая сборка мусора, живые объекты как из Эдема, так и из пространства перемещаются в пространство ToSpace.
Этот цикл продолжается определенное количество раз. Если объект все еще “в строю” после этого момента, следующий цикл сборки мусора переместит его в пространство старшего поколения.
Постоянное поколение
Метаданные, такие как классы и методы, хранятся в постоянном поколении. JVM заполняет его во время выполнения на основе классов, используемых приложением. Классы, которые больше не используются, могут переходить из постоянного поколения в мусор.
Для установки начального и максимального размера постоянного поколения вы можете воспользоваться флагами -XX:PermGen и -XX:MaxPermGen.
Мета-пространство
Начиная с Java 8, на смену пространству постоянного поколения (PermGen) приходит пространство памяти MetaSpace. Реализация отличается от PermGen — это пространство кучи теперь изменяется автоматически.
Это позволяет избежать проблемы нехватки памяти у приложений, которая возникает из-за ограниченного размера пространства PermGen в куче. Память мета-пространства может быть собрана как мусор, и классы, которые больше не используются, будут автоматически очищены, когда мета-пространство достигнет максимального размера.
Типы сборщиков мусора в виртуальной машине Java
Сборка мусора повышает эффективности памяти в Java, поскольку объекты без ссылок удаляются из памяти кучи и освобождается место для новых объектов.
У виртуальной машины Java есть восемь типов сборщиков мусора. Рассмотрим каждый из них в деталях.
Серийный GC
Это самая простая реализация GC. Она предназначена для небольших приложений, работающих в однопоточных средах. Все события сборки мусора выполняются последовательно в одном потоке. Уплотнение выполняется после каждой сборки мусора.
Запуск сборщика приводит к событию “остановки мира”, когда все приложение приостанавливает работу. Поскольку на время сборки мусора все приложение замораживается, не следует прибегать к такому в реальной жизни, если требуется, чтобы задержки были минимальными.
Аргумент JVM для использования последовательного сборщика мусора -XX:+UseSerialGC.
Параллельный GC
Параллельный сборщик мусора предназначен для приложений со средними и большими наборами данных, которые выполняются на многопроцессорном или многопоточном оборудовании. Это реализация GC по умолчанию, и она также известна как сборщик пропускной способности.
Несколько потоков предназначаются для малой сборки мусора в молодом поколении. Единственный поток занят основной сборкой мусора в старшем поколении.
Запуск параллельного GC также вызывает “остановку мира”, и приложение зависает. Такое больше подходит для многопоточной среды, когда требуется завершить много задач и допустимы длительные паузы, например при выполнении пакетного задания.
Аргумент JVM для использования параллельного сборщика мусора: -XX:+UseParallelGC.
Старый параллельный GC
Это версия Parallel GC по умолчанию, начиная с Java 7u4. Это то же самое, что и параллельный GC, за исключением того, что в нем применяются несколько потоков как для молодого поколения, так и для старшего поколения.
Аргумент JVM для использования старого параллельного сборщика мусора: -XX:+UseParallelOldGC.
CMS (Параллельная пометка и зачистка) GC
Также известен как параллельный сборщик низких пауз. Для малой сборки мусора задействуются несколько потоков, и происходит это через такой же алгоритм, как в параллельном сборщике. Основная сборка мусора многопоточна, как и в старом параллельном GC, но CMS работает одновременно с процессами приложений, чтобы свести к минимуму события “остановки мира”.
Из-за этого сборщик CMS потребляет больше ресурсов процессора, чем другие сборщики. Если у вас есть возможность выделить больше ЦП для повышения производительности, то CMS предпочтительнее, чем простой параллельный сборщик. В CMS GC не выполняется уплотнение.
Аргумент JVM для использования параллельного сборщика мусора с разверткой меток: -XX:+UseConcMarkSweepGC.
G1 (Мусор — первым) GC
G1GC был задуман как замена CMS и разрабатывался для многопоточных приложений, которые характеризуются крупным размером кучи (более 4 ГБ). Он параллелен и конкурентен, как CMS, но “под капотом” работает совершенно иначе, чем старые сборщики мусора.
Хотя G1 также действует по принципу поколений, в нем нет отдельных пространств для молодого и старшего поколений. Вместо этого каждое поколение представляет собой набор областей, что позволяет гибко изменять размер молодого поколения.
G1 разбивает кучу на набор областей одинакового размера (от 1 МБ до 32 МБ — в зависимости от размера кучи) и сканирует их в несколько потоков. Область во время выполнения программы может неоднократно становиться как старой, так и молодой.
После завершения этапа разметки G1 знает, в каких областях содержится больше всего мусора. Если пользователь заинтересован в минимизации пауз, G1 может выбрать только несколько областей. Если время паузы неважно для пользователя или предел этого времени установлен высокий, G1 пройдет по большему числу областей.
Поскольку G1 GC идентифицирует регионы с наибольшим количеством мусора и сначала выполняет сбор мусора в них, он и называется: “Мусор — первым”.
Помимо областей Эдема, Выживших и Старой памяти, в G1GC присутствуют еще два типа.
- Humongous (Огромная) — для объектов большого размера (более 50% размера кучи).
- Available (Доступная) — неиспользуемое или не выделенное пространство.
Аргумент JVM для использования сборщика мусора G1: -XX:+UseG1GC.
Сборщик мусора Эпсилон
Epsilon — сборщик мусора, который был выпущен как часть JDK 11. Он обрабатывает выделение памяти, но не реализует никакого реального механизма восстановления памяти. Как только доступная куча исчерпана, JVM завершает работу.
Его можно задействовать для приложений, чувствительных к сверхвысокой задержке, где разработчики точно знают объем памяти приложения или даже добиваются ситуации (почти) полной свободы от мусора. В противном случае пользоваться Epsilon GC не рекомендуется.
Аргумент JVM для использования сборщика мусора Epsilon: -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC.
Shenandoah — новый GC, выпущенный как часть JDK 12. Ключевое преимущество Shenandoah перед G1 состоит в том, что большая часть цикла сборки мусора выполняется одновременно с потоками приложений. G1 может эвакуировать области кучи только тогда, когда приложение приостановлено, а Shenandoah перемещает объекты одновременно с приложением.
Shenandoah может компактировать живые объекты, очищать мусор и освобождать оперативную память почти сразу после обнаружения свободной памяти. Поскольку все это происходит одновременно, без приостановки работы приложения, то Shenandoah более интенсивно нагружает процессор.
Аргумент JVM для сборщика мусора Шенандоа: -XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC.
ZGC — еще один GC, выпущенный как часть JDK 11 и улучшенный в JDK 12. Он предназначен для приложений, которые требуют низкой задержки (паузы в менее чем 10 мс) и/или задействуют очень большую кучу (несколько терабайт).
Основные цели ZGC — низкая задержка, масштабируемость и простота в применении. Для этого ZGC позволяет Java-приложению продолжать работу, пока выполняются все операции по сбору мусора. По умолчанию ZGC освобождает неиспользуемую память и возвращает ее в операционную систему.
Таким образом, ZGC привносит значительное улучшение по сравнению с другими традиционными GCS, обеспечивая чрезвычайно низкое время паузы (обычно в пределах 2 мс).
Аргумент JVM для использования сборщика мусора ZGC: —XX:+UnlockExperimentalVMOptions -XX:+UseZGC.
Примечание: как Shenandoah, так и ZGC планируется вывести из экспериментальной стадии в продакшен при выпуске JDK 15.
Как правильно выбрать сборщик мусора
Если у вашего приложения нет строгих требований ко времени задержки, вам стоит просто запустить приложение и предоставить выбор правильного сборщика самой JVM.
В большинстве случаев настройки по умолчанию отлично работают. При необходимости можно настроить размер кучи для повышения производительности. Если производительность по-прежнему не соответствует ожиданиям, попробуйте изменить сборщик в соответствии с требованиями вашего приложения.
- Последовательный. Если в приложении небольшой набор данных (примерно до 100 МБ), и/или оно будет работать на одном процессоре без каких-либо требований к времени задержки.
- Параллельный. Если приоритет — пиковая производительность приложения, и требования к времени задержки отсутствуют (или допустимы паузы в одну секунду и более).
- CMS/G1. Если время отклика важнее, чем общая пропускная способность, и паузы при сборке мусора должны быть короче одной секунды.
- ZGC. Если у времени отклика высокий приоритет и/или задействована очень большая куча.
Преимущества сборки мусора
У сборки мусора в Java множество преимуществ.
Прежде всего, это упрощает код. Не нужно беспокоиться о правильном назначении памяти и циклах высвобождения. Вы просто прекращаете использовать объект в коде, и память, которую он занимал, в какой-то момент автоматически восстановится.
Программистам, работающим на языках без сборки мусора (таких как C и C++), приходится реализовывать ручное управление памятью у себя в коде.
Также повышается эффективность памяти Java, поскольку сборщик мусора удаляет из памяти кучи объекты без ссылок. Это освобождает память кучи для размещения новых объектов.
Некоторые программисты выступают за ручное управление памятью вместо сборки мусора, но сборка мусора — уже стандартный компонент многих популярных языков программирования.
Для сценариев, когда сборщик мусора негативно влияет на производительность, Java предлагает множество вариантов настройки, повышающих эффективность GC.
Рекомендации по сбору мусора
Избегайте ручных триггеровПомимо основных механизмов сборки мусора, один из важнейших моментов относительно этого процесса в Java — недетерминированность. То есть невозможно предсказать, когда именно во время выполнения она произойдет.
С помощью методов System.gc() или Runtime.gc() можно включить в код подсказку для запуска сборщика мусора, но это не гарантирует, что он действительно запустится.
Пользуйтесь инструментами для анализа
Если у вас недостаточно памяти для запуска приложения, вы столкнетесь с замедлениями, длительным временем сбора мусора, событиями “остановки мира” и, в конечном итоге, ошибками из-за нехватки памяти. Возможно, это указывает, что куча слишком мала, но также может и значить, что в приложении произошла утечка памяти.
Вы можете прибегнуть к помощи инструмента мониторинга, например jstat или Java Flight Recorder, и увидеть, растет ли использование кучи бесконечно, что может указывать на ошибку в коде.
Отдавайте предпочтение настройкам по умолчанию
Если у вас небольшое автономное Java-приложение, вам, скорее всего, не понадобится настраивать сборку мусора. Настройки по умолчанию отлично вам послужат.
Пользуйтесь флагами JVM для настройки
Лучший подход к настройке сборки мусора в Java — установка JVM-флагов. С помощью флагов можно задать сборщик мусора (например, Serial, G1 и т.д.), начальный и максимальный размер кучи, размер разделов кучи (например, Молодого поколения, Старшего поколения) и многое другое.
Выбирайте сборщик правильно
Хороший ориентир в плане начальных настроек — характер настраиваемого приложения. К примеру, параллельный сборщик мусора эффективен, но часто вызывает события “остановки мира”, что делает его более подходящим для внутренней обработки, где допустимы длительные паузы.
С другой стороны, сборщик мусора CMS предназначен для минимизации задержек, а значит идеально подходит для веб-приложений, где важна скорость реагирования.
В этой статье мы обсудили сборку мусора Java, механизм ее работы и ее типы.
Для многих простых Java-приложений программисту нет необходимости сознательно отслеживать сборку мусора. Однако тем, кто хочет развить навыки работы с Java, важно понимать, как происходит данный процесс.
Это также очень популярный вопрос на собеседованиях: как на миддл-, так и на сеньор-позиции в бэкенд-разработке.