BIOS, его параметр
Что такое GPU Host Translation Cache? Облазил все форумы, ничего не нашел.
Прошу вашей помощи.
Голосование за лучший ответ
это кеш для увеличения производительности веб-приложений, написанных на JS
Михаил СергеевичУченик (129) 8 месяцев назад
Стоит включать? Уменьшит ли время рендера?
_ Искусственный Интеллект (756552) Михаил Сергеевич, смысла нет. Не уменьшит
Похожие вопросы
Ваш браузер устарел
Мы постоянно добавляем новый функционал в основной интерфейс проекта. К сожалению, старые браузеры не в состоянии качественно работать с современными программными продуктами. Для корректной работы используйте последние версии браузеров Chrome, Mozilla Firefox, Opera, Microsoft Edge или установите браузер Atom.
Вычисления на GPU – зачем, когда и как. Плюс немного тестов
Всем давно известно, что на видеокартах можно не только в игрушки играть, но и выполнять вещи, никак не связанные с играми, например, нейронную сеть обучить, криптовалюту помайнить или же научные расчеты выполнить. Как так получилось, можно прочитать тут, а я хотел затронуть тему того, почему GPU может быть вообще интересен рядовому программисту (не связанному с GameDev), как подступиться к разработке на GPU, не тратя на это много времени, принять решение, нужно ли вообще в эту сторону смотреть, и «прикинуть на пальцах», какой профит можно получить.

Статья написана по мотивам моего выступления на HighLoad++. В ней рассматриваются в основном технологии, предлагаемые компанией NVIDIA. У меня нет цели рекламировать какие-либо продукты, я лишь привожу их в качестве примера, и наверняка что-то похожее можно найти у конкурирующих производителей.
Зачем что-то считать на GPU?
Два процессора можно сравнить по разным критериям, наверное, самые популярные — это частота и количество ядер, размер кэшей и прочее, но в конечном счете, нас интересует, сколько операций процессор может выполнить за единицу времени, что это за операции вопрос отдельный, но наиболее распространенной метрикой является количество операций с плавающей запятой в секунду — flops. И когда мы хотим сравнить теплое с мягким, а в нашем случае GPU с CPU, эта метрика приходится как нельзя кстати.
Ниже на графике изображены рост этих самых флопсов с течением времени для процессоров и для видеокарт.

(Данные собраны из открытых источников, нет данных за 2019-20 годы, т.к. там не все так красиво, но GPU все-таки выигрывают)
Что ж, заманчиво, не правда ли? Перекладываем все вычисления с CPU на GPU и получаем в восемь раз лучшую производительность!
Но, конечно же, не все так просто. Нельзя просто так взять и переложить все на GPU, о том почему, мы поговорим дальше.
Архитектура GPU и ее сравнение с CPU
Привожу многим знакомую картинку с архитектурой CPU и основными элементами:

Что здесь особенного? Одно ядро и куча вспомогательных блоков.
А теперь давайте посмотрим на архитектуру GPU:

У видеокарты множество вычислительных ядер, обычно несколько тысяч, но они объединены в блоки, для видеокарт NVIDIA обычно по 32, и имеют общие элементы, в т.ч. и регистры. Архитектура ядра GPU и логических элементов существенно проще, чем на CPU, а именно, нет префетчеров, бранч-предикторов и много чего еще.
Что же, это ключевые моменты отличия в архитектуре CPU и GPU, и, собственно, они и накладывают ограничения или, наоборот, открывают возможности к тому, что мы можем эффективно считать на GPU.
Я не упомянул еще один важный момент, обычно, видеокарта и процессор не «шарят» память между собой и записать данные на видеокарту и считать результат обратно — это отдельные операции и могут оказаться «бутылочным горлышком» в вашей системе, график зависимости времени перекачки от размера данных приведен далее в статье.
Ограничения и возможности при работе с GPU
Какие ограничения накладывает такая архитектура на выполняемые алгоритмы:
- Если мы выполняем расчет на GPU, то не можем выделить только одно ядро, выделен будет целый блок ядер (32 для NVIDIA).
- Все ядра выполняют одни и те же инструкции, но с разными данными (поговорим про это дальше), такие вычисления называются Single-Instruction-Multiple-Data или SIMD (хотя NVIDIA вводит свое уточнение).
- Из-за относительно простого набора логических блоков и общих регистров, GPU очень не любит ветвлений, да и в целом сложной логики в алгоритмах.
- Собственно, ускорение тех самых SIMD-вычислений. Простейшим примером может служить поэлементное сложение матриц, его и давайте разберем.
Приведение классических алгоритмов к SIMD-представлению
Трансформация
У нас есть два массива, A и B, и мы хотим к каждому элементу массива A добавить элемент из массива B. Ниже приведен пример на C, хотя, надеюсь, он будет понятен и тем, кто не владеет этим языком:
void func(float *A, float *B, size) < for (int i = 0; i < size; i++) < A[i] += B[i] >> Классический обход элементов в цикле и линейное время выполнения.
А теперь посмотрим, как такой код будет выглядеть для GPU:
void func(float *A, float *B, size)
А вот здесь уже интересно, появилась переменная threadIdx, которую мы вроде бы нигде не объявляли. Да, нам предоставляет ее система. Представьте, что в предыдущем примере массив состоит из трех элементов, и вы хотите его запустить в трех параллельных потоках. Для этого вам бы понадобилось добавить еще один параметр – индекс или номер потока. Вот это и делает за нас видеокарта, правда она передает индекс как статическую переменную и может работать сразу с несколькими измерениями – x, y, z.
Еще один нюанс, если вы собираетесь запускать сразу большое количество параллельных потоков, то потоки придется разбить на блоки (архитектурная особенность видеокарт). Максимальный размер блока зависит от видеокарты, а индекс элемента, для которого выполняем вычисления, нужно будет получать так:
int i = blockIdx.x * blockDim.x + threadIdx.x; // blockIdx – индекс блока, blockDim – размер блока, threadIdx – индекс потока в блоке В итоге что мы имеем: множество параллельно работающих потоков, выполняющих один и тот же код, но с разными индексами, а соответственно, и данными, т.е. тот самый SIMD.
Это простейший пример, но, если вы хотите работать с GPU, вашу задачу нужно привести к такому же виду. К сожалению, это не всегда возможно и в некоторых случаях может стать темой докторской диссертации, но тем не менее классические алгоритмы все же можно привести к такому виду.
Агрегация
Давайте теперь посмотрим, как будет выглядеть агрегация, приведенная к SIMD представлению:

У нас есть массив из n элементов. На первом этапе мы запускаем n/2 потоков и каждый поток складывает по два элемента, т.е. за одну итерацию мы складываем между собой половину элементов в массиве. А дальше в цикле повторяем все тоже самое для вновь получившегося массива, пока не сагрегируем два последних элемента. Как видите, чем меньше размер массива, тем меньше параллельных потоков мы можем запустить, т.е. на GPU имеет смысл агрегировать массивы достаточно большого размера. Такой алгоритм можно применять для вычисления суммы элементов (кстати, не забывайте о возможном переполнении типа данных, с которым вы работаете), поиска максимума, минимума или просто поиска.
Сортировка
А вот с сортировкой уже все выглядит намного сложнее.
Два наиболее популярных алгоритма сортировки на GPU это:
- Bitonic-sort
- Radix-sort
Но идея в том, что даже такой нелинейный алгоритм, как сортировка, можно привести к SIMD-виду.
А теперь, прежде чем посмотреть на реальные цифры, которые можно получить от GPU, давайте разберемся, как же все-таки программировать под это чудо техники?
C чего начать
Наиболее распространены две технологии, которые можно использовать для программирования под GPU:
- OpenCL
- CUDA
Использовать OpenCL можно из C/C++, есть биндинги к другим языкам.
По OpenCL мне больше всего понравилась книга «OpenCL in Action». В ней же описаны разные алгоритмы на GPU, в т.ч. Bitonic-sort и Radix-sort.
CUDA – это проприетарная технология и SDK от компании NVIDIA. Писать можно на C/C++ или использовать биндинги к другим языкам.
Сравнивать OpenCL и CUDA несколько не корректно, т.к. одно — стандарт, второе — целое SDK. Тем не менее многие выбирают CUDA для разработки под видеокарты несмотря на то, что технология проприетарная, хоть и бесплатная и работает только на картах NVIDIA. Тому есть несколько причин:
- Более продвинутое API
- Проще синтаксис и инициализация карты
- Подпрограмма, выполняемая на GPU, является частью исходных текстов основной (host) программы
- Собственный профайлер, в т.ч. и визуальный
- Большое количество готовых библиотек
- Более живое комьюнити
Наиболее полноценной книгой по CUDA, на которую я наткнулся, была «Professional CUDA C Programming», хоть уже и немного устарела, тем не менее в ней рассматривается много технических нюансов программирования для карт NVIDIA.
А что, если я не хочу тратить пару месяцев на чтение этих книг, написание собственной программы для видеокарты тестирование и отладку, а потом выяснить, что это все не для меня?
Как я уже сказал, есть большое количество библиотек, которые скрывают сложности разработки под GPU: XGBoost, cuBLAS, TensorFlow, PyTorch и другие, мы рассмотрим библиотеку thrust, так как она менее специализирована, чем другие вышеприведенные библиотеки, но при этом в ней реализованы базовые алгоритмы, например, сортировка, поиск, агрегация, и с большой вероятностью она может быть применима в ваших задачах.
Thrust – это С++ библиотека, которая ставит своей целью «подменить» стандартные STL алгоритмы на алгоритмы выполняемые на GPU. Например, сортировка массива чисел с помощью этой библиотеки на видеокарте будет выглядеть так:
thrust::host_vector h_vec(size); // объявляем обычный массив элементов std::generate(h_vec.begin(), h_vec.end(), rand); // заполняем случайными значениями thrust::device_vector d_vec = h_vec; // пересылаем данные из оперативной памяти в память видеокарты thrust::sort(d_vec.begin(), d_vec.end()); // сортируем данные на видеокарте thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin()); // копируем данные назад, из видеокарты в оперативную память (не забываем, что пример нужно компилировать компилятором от NVIDIA)
Как видите, thrust::sort очень похож на аналогичный алгоритм из STL. Эта библиотека скрывает много сложностей, в особенности разработку подпрограммы (точнее ядра), которая будет выполняться на видеокарте, но при этом лишает гибкости. Например, если мы хотим отсортировать несколько гигабайт данных, логично было бы отправить кусок данных на карту запустить сортировку, и пока выполняется сортировка, дослать еще данные на карту. Такой подход называется latency hiding и позволяет более эффективно использовать ресурсы серверной карты, но, к сожалению, когда мы используем высокоуровневые библиотеки, такие возможности остаются скрытыми. Но для прототипирования и замера производительности как раз таки подходят, в особенности с thrust можно замерить, какой оверхед дает пересылка данных.
Я написал небольшой бенчмарк с использованием этой библиотеки, который выполняет несколько популярных алгоритмов с разным объемом данных на GPU, давайте посмотрим, какие результаты получились.
Результаты выполнения алгоритмов на GPU
Для тестирования GPU я взял инстанс в AWS с видеокартой Tesla k80, это далеко не самая мощная серверная карта на сегодняшний день (самая мощная Tesla v100), но наиболее доступная и имеет на борту:
- 4992 CUDA ядра
- 24 GB памяти
- 480 Gb/s — пропускная способность памяти
Трансформация
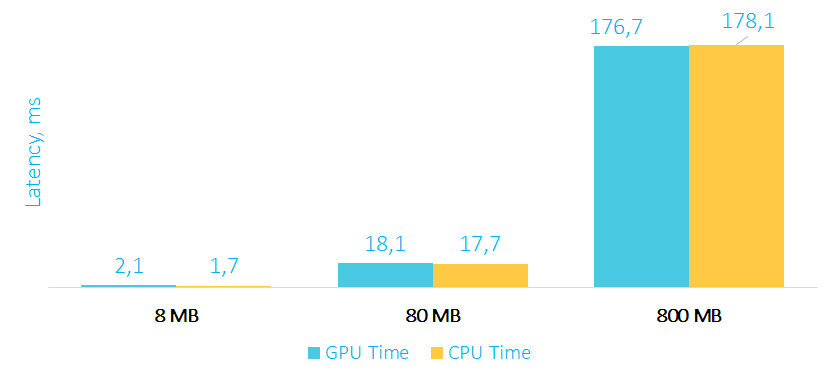
Время выполнения трансформации на GPU и CPU в мс
Как видите, обычная трансформация элементов массива выполняется по времени примерно одинаково, как на GPU, так и на CPU. А все почему? Потому что оверхед на пересылку данных на карту и обратно съедает весь performance boost (про оверхед мы поговорим отдельно), да и вычислений на карте выполняется относительно немного. К тому же не стоит забывать, что процессоры также поддерживают SIMD инструкции, и компиляторы в простых случаях могут эффективно их задействовать.
Давайте теперь посмотрим, насколько эффективно выполняется агрегация на GPU.
Агрегация

Время выполнения агрегации на GPU и CPU в мс
В примере с агрегацией мы уже видим существенный прирост производительности с увеличением объема данных. Стоит также обратить внимание на то, что в память карты мы перекачиваем большой объем данных, а назад забираем только одно агрегированное значение, т.е. оверхед на пересылку данных из карты в RAM минимален.
Перейдем к самому интересному примеру – сортировке.
Сортировка

Время выполнения сортировки на GPU и CPU в мс
Несмотря на то, что мы пересылаем на видеокарту и обратно весь массив данных, сортировка на GPU 800 MB данных выполняется примерно в 25 раз быстрее, чем на процессоре.
Оверхед на пересылку данных
Как видно из примера с трансформацией, не всегда очевидно, будет ли GPU эффективен даже в тех задачах, которые хорошо параллелятся. Причиной тому — оверхед на пересылку данных из оперативной памяти компьютера в память видеокарты (в игровых консолях, кстати, память расшарена между CPU и GPU, и нет необходимости пересылать данные). Одна из характеристик видеокарты это — memory bandwidth или пропускная способность памяти, которая определяет теоретическую пропускную способность карты. Для Tesla k80 это 480 GB/s, для Tesla v100 это уже 900 GB/s. Также на пропускную способность будет влиять версия PCI Express и имплементация того, как вы будете передавать данные на карту, например, это можно делать в несколько параллельных потоков.
Давайте посмотрим на практические результаты, которые удалось получить для видеокарты Tesla k80 в облаке Amazon:
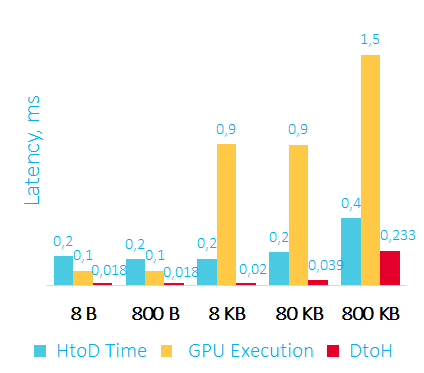
Время пересылки данных на GPU, сортировки и пересылки данных обратно в RAM в мс
HtoD – передаем данные на видеокарту
GPU Execution – сортировка на видеокарте
DtoH – копирование данных из видеокарты в оперативную память
Первое, что можно отметить – считывать данные из видеокарты получается быстрее, чем записывать их туда.
Второе – при работе с видеокартой можно получить latency от 350 микросекунд, а этого уже может хватить для некоторых low latency приложений.
Ниже на графике приведен оверхед для большего объема данных:
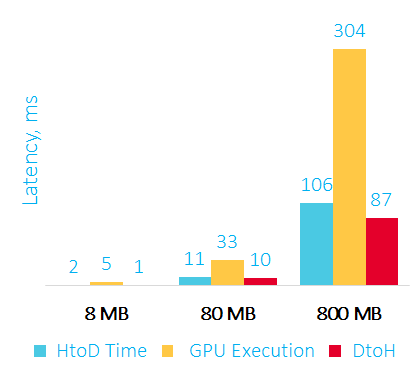
Время пересылки данных на GPU, сортировки и пересылки данных обратно в RAM в мс
Серверное использование
Наиболее частый вопрос — чем отличается игровая видеокарта от серверной? По характеристикам они очень похожи, а цены отличаются в разы.

Основные отличия серверной (NVIDIA) и игровой карты:
- Гарантия производителя (игровая карта не рассчитана на серверное использование)
- Возможные проблемы с виртуализацией для потребительской видеокарты
- Наличие механизма коррекции ошибок на серверной карте
- Количество параллельных потоков (не CUDA ядер) или поддержка Hyper-Q, которая позволяет из нескольких потоков на CPU работать с картой, например, из одного потока закачивать данные на карту, а из другого запускать вычисления
Многопоточность
После того как мы разобрались, как запустить простейший алгоритм на видеокарте и каких результатов можно ожидать, следующий логичный вопрос, а как будет себя вести видеокарта при обработке нескольких параллельных запросов. В качестве ответа у меня есть два графика выполнения вычислений на GPU и процессоре с 4-мя и 32-мя ядрами:

Время выполнения математических расчетов на GPU и CPU c матрицами размером 1000 x 60 в мс
На этом графике выполняются расчеты с матрицами размером 1000 x 60 элементов. Запускаются вычисления из нескольких программных потоков, для GPU дополнительно создается отдельный stream для каждого CPU-потока (используется тот самый Hyper-Q).
Как видно, процессор справляется с такой нагрузкой очень хорошо, при этом latency для одного запроса на GPU существенно растет с увеличением числа параллельных запросов.

Время выполнения математических расчетов на GPU и CPU c матрицами 10 000 x 60 в мс
На втором графике те же самые вычисления, но с матрицами в 10 раз больше, и GPU под такой нагрузкой ведет себя существенно лучше. Эти графики очень показательны, и можно сделать вывод: поведение под нагрузкой зависит от характера самой нагрузки. Процессор может также довольно эффективно справляться с матричными вычислениями, но до определенных пределов. Для видеокарты характерно то, что для небольшой вычислительной нагрузки производительность падает примерно линейно. С увеличением нагрузки и количества параллельных потоков видеокарта справляется уже лучше.
Сложно строить гипотезы, как будет себя вести GPU в различных ситуациях, но, как видите, при определенных условиях серверная карта может достаточно эффективно обрабатывать запросы из нескольких параллельных потоков.
Обсудим еще несколько вопросов, которые могут возникнуть у вас, если вы все-таки решили использовать GPU в своих проектах.
Ограничение ресурсов
Как мы уже говорили, два основных ресурса видеокарты – это вычислительные ядра и память.
К примеру, у нас несколько процессов или контейнеров, использующих видеокарту, и хотелось бы иметь возможность поделить видеокарту между ними. К сожалению, простого API для этого нет. NVIDIA предлагает технологию vGPU, но карту Tesla k80 я не нашел в списке поддерживаемых, и насколько мне удалось понять из описания, технология больше заточена на виртуальные дисплеи, чем на вычисления. Возможно, AMD предлагает что-то более подходящее.
Поэтому, если планируете использовать GPU в своих проектах, стоит рассчитывать на то, что приложение будет использовать видеокарту монопольно, либо вы будете программно контролировать объем выделяемой памяти и количество ядер, используемых для вычислений.
Контейнеры и GPU
Если с ограничением ресурсов вы разобрались, то следующий логичный вопрос: а если в сервере несколько видеокарт?
Опять же, можно на уровне приложения решать, какой GPU оно будет использовать.
Другой более удобный способ – это Docker-контейнеры. Можно использовать и обычные контейнеры, но NVIDIA предлагает свои контейнеры NGC, с оптимизированными версиями различного софта, библиотек и драйверов. Для одного контейнера можно ограничить количество используемых GPU и их видимость для контейнера. Оверхед на использования контейнера около 3%.
Работа в кластере
Другой вопрос, что делать, если вы хотите выполнять одну задачу на нескольких GPU в рамках одного сервера или кластера?
Если вы выбрали библиотеку на подобии thrust или более низкоуровневое решение, то задачу придется решать вручную. Высокоуровневые фреймворки, например, для машинного обучения или нейронных сетей, обычно поддерживают возможность использования нескольких карт из коробки.
Дополнительно хотелось бы отметить то, что, например, NVIDIA предлагает интерфейс прямого обмена данными между картами – NVLINK, который существенно быстрее чем PCI Express. И есть технология прямого доступа к памяти карты из других PCI Express устройств – GPUDirect RDMA, в т.ч. и сетевых.
Рекомендации
Если вы размышляете об использовании GPU в своих проектах, то GPU, скорее всего, вам подойдет если:
- Вашу задачу можно привести к SIMD-виду
- Есть возможность загрузить большую часть данных на карту до вычислений (закешировать)
- Задача подразумевает интенсивные вычисления
- Сколько будет параллельных запросов
- На какое latency вы рассчитываете
- Достаточно ли вам одной карты для вашей нагрузки, нужен сервер с несколькими картами или кластер GPU-серверов
GPU-сервер: что это такое и зачем он нужен
Мир не стоит на месте — ежесекундно меняется и развивается, и с каждым мигом информации становится все больше. В результате компьютерные системы накапливают и обрабатывают огромные массивы данных, справиться с которыми под силу далеко не каждому серверу. И здесь на помощь приходят мощные видеокарты, или GPU-карты. Серверы на их базе отлично себя показывают при рендеринге, стриминге, параллельных вычислениях — словом, для решения высоконагруженных задач. Поэтому неудивительно, что хостинг серверов на базе GPU-карт сегодня крайне популярен. О том, как выбрать оборудование, и пойдет речь в этой статье.
Использование видеокарт для вычислений
На заре развития компьютерных технологий все задачи обрабатывались CPU — центральным процессором: и вычисления, и передача звука, и обработка запросов видеокарты, и вывод изображения на экран. Ни о какой мультизадачности и речи не было: запуск двух программ одновременно тормозил работу компьютера вплоть до зависания.
Арендуйте выделенный или виртуальный сервер с профессиональными графическими картами NVIDIA RTX A5000 / A4000 в надежных дата-центрах в Москве или Амстердаме. Скидки до 12%. Время сдачи от 15 минут.
Для российских резидентов доступна оплата услуг хостинга в зарубежных дата-центрах в рублях на счет российской компании — банковскими картами, в том числе платежной системы МИР, банковскими переводами и другими способами, доступными на территории России.
Компьютерное системы развивалось — появились интегрированные видеокарты и дискретные. Усложнялись и задачи, которые видеокартам предстояло решать. В итоге видеокарты обзавелись собственным процессором — GPU. Графический процессор (он же видеопроцессор и графический ускоритель) занят параллельными однотипными вычислениями, связанными, как ясно из названия, с графикой. Так, благодаря GPU на экране четко отображаются статические (чертежи, фото, схемы и т. п.) и динамические (видео, 3D-анимация, видео и т. п.) объекты в высоком разрешении.
CPU и GPU: в чем разница?
Самое важное отличие CPU от GPU — в способе потоковой обработки операций, который обусловлен функциональными особенностями процессоров. Так, CPU выполняет операции только последовательно — одну за другой. Срочные задачи с высоким приоритетом могут быть внедрены, однако им тоже придется «встать в очередь». Каждый следующий шаг выполняется после завершения предыдущего и основан на полученных в прошлом результатах. Поэтому если на одном из этапов возникает ошибка, то программа крашится, то есть прекращает работу.
Современные процессорные платы — многоядерные. Каждое из ядер обрабатывает информацию последовательно внутри одного потока. Иначе говоря, разные задачи выполняются одновременно в разных потоках (при этом выполнение задач в каждом потоке по-прежнему последовательное) — так получается добиться многозадачности.
В GPU архитектура такова, что в процессоре много ядер, и они объединены в блоки. При этом ядра работают по абсолютно иному принципу, нежели в CPU: операции выполняются параллельно. Графический процессор действительно решает задачи одновременно в несколько потоков. Так что ошибка в одном потоке, не приводит к сбою и закрытию программы. Благодаря этому GPU с легкостью обеспечивают высокую (в восемь раз выше, чем у CPU) производительность вычислений.
Доступ к памяти и взаимодействие с ней у CPU и GPU также разительно отличаются. Графический процессор не требует емкой памяти, а запись данных на видеокарту и последующее их чтение — это отдельные процесс, которые отнимают время и ресурсы. Впрочем, скорее всего, в ближайшее время эта проблема может быть решена — активно разрабатываются новые, более быстрые методы взаимодействия GPU с видеопамятью.
Где нужен GPU
Графические процессоры изначально были созданы для обработки тяжелой графики. Но их высокая производительность благодаря математическим алгоритмам, аналогичным рендерингу, позволяет применять GPU в множестве не связанных с графикой проектов.
Среди задач, которые решают GPU:
Решения для обработки данных в экстремальных условиях



В XXI веке в условиях глобального соперничества в области электронных систем различного назначения одним из решающих факторов в конкурентной борьбе является возможность сбора и обработки больших объёмов данных в реальном времени. При этом быстродействие и эффективность решения конкретных прикладных задач подвержены действию различных факторов, начиная от ограничений бюджета и заканчивая требованиями к массогабаритным и иным характеристикам. Статья посвящена вопросам обеспечения максимальной производительности систем в условиях различного рода ограничений.
В ЗАКЛАДКИ
Потолок скорости
Пятнадцать лет назад Intel и другие производители процессоров поняли, что гонка за мегагерцами не бесконечна. Примерно на значении 4 ГГц процессоры столкнулись с пределом – рост нагрева стал снижать производительность.
Для решения этой проблемы были созданы многоядерные процессоры, в основном использующие несколько небольших процессорных ядер, которые могли бы в совокупности превзойти одно большое ядро. Графические процессоры (GPU – Graphics Processing Unit) вскоре последовали за процессорами общего назначения: начиная с 2010 года, компания NVIDIA стала оценивать производительность с точки зрения Гфлопс на ватт (FLOPS – FLoating-point Operations Per Second, количество операций с плавающей точкой в секунду).
В опубликованной в 2016 году компанией BERTEN статье «Сравнение производительности GPU и FPGA» (“GPU vs FPGA Performance Comparison”) приведены примеры парадоксов производительности. Авторы провели тесты производительности на операциях с плавающей запятой с одиночной точностью с шестью вариантами процессоров. Два из трёх GPU легко побеждают FPGA (Field-Programmable Gate Array – программируемая логическая интегральная схема). Однако при сравнении по Гфлопс на ватт в общем случае предпочтительнее FPGA. В то же время при учёте цены (стоимость за Гфлопс) GPU значительно дешевле большинства FPGA. В 2016 году FPGA были наиболее энергоэффективными, а GPU обеспечивали наилучшую производительность за те же деньги. Это важные критерии для любой организации, реализующей систему обработки сигналов в рамках ограниченного бюджета.
Неудивительно, что поставщики компонентов и решений продолжают искать все возможные пути для снижения энергопотребления. Если в 2010 году NVIDIA начала оценивать производительность с точки зрения Гфлопс на ватт, то позже она решила анализировать показатели уже в конкретных приложениях с учётом рабочих нагрузок и системных архитектур. Например, NVIDIA предоставляет два набора спецификаций для своего графического процессора Tesla V100, в зависимости от того, использует ли хост-система подключение шины NVLink или PCI Express. С PCIe процессор V100 максимально потребляет мощность в 250 Вт, но эта мощность обеспечивает 7 Тфлопс производительности в тестах с двойной точностью или 112 Тфлопс при Deep Learning (глубоком обучении). Напротив, с шиной NVLink максимальная потребляемая мощность V100 равна 300 Вт, но NVLink обеспечивает более высокую пропускную способность и меньшую задержку и, следовательно, имеет бо-
лее высокую эффективность. Сегодня серверные архитектуры Intel, распространённые в приложениях обработки сигналов, допускают между процессором и графическим процессором только интерфейс PCI Express, поэтому данная модель и доминирует над более современными решениями. Тем не менее, независимо от специфики соотношение мощности/производительности остаётся ключевым фактором при выборе платформы GPGPU (General-Purpose Computing for Graphics Processing Units – графические процессоры общего назначения).
Зачем большие мощности для обработки?

Потребляемая мощность также предъявляет требования к размерам платформ. В полевых условиях, например при проведении боевых операций (рис. 1), всё чаще ключевым фактором становятся возможности средств управления, контроля, связи, сбора и компьютерной обработки, разведки и наблюдения (C4ISR – Command, Control, Communications, Computers, Intelligence, Surveillance and Reconnaissance), которые устанавливаются в транспортные средства, начиная от самолётов и кончая беспилотниками.
Требования к гибкости и мобильности становятся определяющими при полевых операциях, а крупногабаритные стационарные системы с электрогенераторами быстро уступают место малым форм-факторам (SFF – Small Form Factor), решениям с автономным питанием от батарей, которые можно разместить под сиденьем. Встроенные платформы становятся нормой, но они должны быть в состоянии обеспечить выполнение требований к производительности при анализе сигналов. Вместе с тем корпуса с меньшим размером сталкиваются с большими проблемами при рассеивании тепла компонентов из-за более высоких вычислительных нагрузок. Из-за отсутствия места под вентиляторы основными конструкциями, которые могут противостоять пыли, ударам и вибрациям в полевых условиях, становятся системы пассивного охлаждения.
Обычно при обработке сигналов на поле боя делается выбор: либо проведение анализа на месте с учётом ограничений полевых систем, либо отправка данных в более мощные централизованные системы, расположенные далеко от зоны действий, что создаёт задержки в обработке. Оба подхода активно развиваются по мере появления более современных сенсорных систем. Рассмотрим электрооптические и инфракрасные (EO/IR – Electro-Optic/Infrared) решения, такие как датчик изображения WXCAM MX-25D для систем целеуказания. MX-25D включает до девяти датчиков, обеспечивающих тепловое наведение, оптическое увеличение, HD-съёмку в условиях низкой освещённости и лазерную систему слежения. Объём данных, получаемых с этого устройства, является существенным, но не стоит забывать, что используются камеры с разрешением 720p и 1080p. Представьте себе загрузку данных с датчиков следующего поколения, поддерживающих 4K-визуализацию или 360-градусные системы панорамной съёмки для виртуальной реальности, которые могут включать в себя более десятка камер. В зависимости от приложения и ситуации несколько таких сенсорных кластеров могут быть объединены в общий пул данных для анализа, что многократно увеличивает нагрузку на вычислительную систему.
Почему GPGPU – лучшее решение?

Выбираемые процессоры должны справляться с большим потоком данных, но тип и количество применяемых процессоров могут различаться по производительности и влиять на жизнеспособность решения. В целом процессоры для таких задач делятся на три группы.
- Центральные процессоры (ЦП), также известные как процессоры общего назначения (GPP – General Purpose Processor). В серверных системах долгое время доминировало семейство процессоров Intel ® Xeon ® . Эти процессоры преуспевают в решении широкого круга проблемно-ориентированных или произвольных задач.
- Графические процессоры общего назначения (GPGPU – General-Purpose Computing for Graphics Processing Units), появившиеся в 1970-х годах для поддержки компьютерных игр. В начале 2000-х NVIDIA, а затем ATI разработали методы для запуска небольших программ на GPU для вычислений отдельных пикселей. Это быстро превратилось в параллельную обработку потока на множестве логических ядер в графическом процессоре. В 2007 году компания NVIDIA представила свою архитектуру программирования CUDA, чтобы дать разработчикам простой и эффективный доступ к вычислениям общего назначения на базе GPU (GPGPU), которые обеспечили бы в несколько раз более высокую производительность для многих распараллеливаемых функций по сравнению с тем, что могли предоставить процессоры общего назначения.
- Программируемая логическая интегральная схема (FPGA), предназначенная для конфигурирования клиентами или интеграторами (то есть программируется пользователем интегральной схемы). Многие логические блоки в FPGA могут выполнять сложные комбинированные функции, позволяя им эффективно решать практически любую задачу. FPGA могут быть чрезвычайно эффективными для конкретных вычислительных задач, включая параллельные операции, но они по-прежнему относительно сложны в программировании, а разработка приложений на их базе имеет более долгие сроки, чем на базе процессоров общего назначения или GPGPU.
Все три типа процессоров широко используются в ответственных приложениях, но для обработки и анализа сигналов в реальном времени решения на GPGPU предлагают наилучшее соотношение цены и возможностей.
К преимуществам относятся:
- высокая пропускная способность видеопамяти, что делает скорость обработки сложных задач близкой к скорости работы основного процессора;
- сравнительно высокая производительность вычислений с плавающей запятой;
- многоядерная архитектура, в которой большинство чипов является вычислительными устройствами, а не кэш-памятью, что дополнительно способствует параллельной обработке данных;
- относительно простое программирование через языки высокого уровня (CUDA, C, C ++, Python и т.д.);
- поддержка OpenACC и OpenCL для реализации быстрой обработки циклических алгоритмов для повышения производительности;
- более высокая вычислительная мощность по сравнению с процессорами общего назначения.
Таким образом, архитектура GPGPU подходит для приложений, которые предназначены для массовой параллельной обработки больших объёмов данных и/или интенсивных математических вычислений (рис. 2), в частности, с проведением нескольких вычислений, основанных на однократном обращении к памяти. Высокие вычислительные нагрузки с обработкой на множестве модулей требуют, чтобы задержки доступа к памяти были минимизированы, это можно сделать за счёт ускоренного вычисления без необходимости активного кэширования данных. Согласно NVIDIA, архитектурные преимущества GPGPU могут обеспечить от 10- до 100-кратного роста производительности по сравнению с процессорами общего назначения в таких приложениях, как компьютерное зрение, расшифровка паролей и имитационное моделирование.
Разумеется, эти преимущества сопряжены с проблемами, и их следует учитывать при рассмотрении решений для анализа информации в ответственных приложениях.
Принимая GPGPU в качестве наиболее эффективного решения, доступного сегодня для анализа сигналов, как с точки зрения производительности, так и потребления мощности, мы рассмотрим три особенно перспективные области применения GPGPU в военных приложениях: обработка данных с радара, гидролокатора и обработка изображений.
Примеры применений продуктов ADLINK
Радиолокационные системы
Радиолокатор с синтезированной апертурой (SAR – Synthetic Aperture Radar), радар с фазированной решёткой и гибридные радиолокационные системы широко распространены как в гражданской сфере, так и при сборе военной информации. Они применяются в системах противовоздушной обороны, противоракетных системах, системах предупреждения столкновения самолётов, системах наблюдения за морской поверхностью, системах альтиметрии и управления полётом, а также системах обнаружения целей для управляемых ракет (рис. 3, 4). 
Использование GPGPU в данной сфере для ускорения вычислений насчитывает почти десять лет. Рассмотрим результаты тестов производительности, проведённых Питером Моррисом и его коллегами из научно-исследовательской организации обороны Индии (India’s Defense Research & Development Organization), которая сравнила систему на базе процессоров Intel ® Xeon ® с восемью графическими процессорами NVIDIA Quadro FX 3800 (выпущенными в 2009 году) с эквивалентной системой на PowerPC. 
Система, управляемая GPGPU, в различных задачах работы с радаром (обработка данных, обнаружение движущихся целей, работа с доплеровскими системами и т.д.) оказалась производительнее в 16–82 раза.
Рассмотрим только один пример текущих разработок в военных радиолокационных приложениях: ВМС США недавно объявили о заключении контракта стоимостью 3 млн долларов на разработку обновлённого решения на базе GPGPU для радара боевого истребителя Lockheed Martin F-35 Lightning II. Модернизация добавит режим широкого поля обзора с высоким разрешением для существующего радара Northrup Grumman APG-81. В результате обновлений, которые должны пройти в два этапа в 2021 и 2023 годах, радиолокатор истребителя сможет захватить значительно большую площадь
поверхности земли, чем в существующих системах. Благодаря применению GPGPU система сможет обрабатывать большие объёмы данных, что повысит возможности в обнаружении и наведении на цели.
В ходе разработки вычислительных средств для военных применений был создан стандарт VPX (также известный как VITA 46, в рамках которого существует множество спецификаций), он представляет собой популярную технологию создания плат формата Eurocard, а также шасси и одноплатных серверов для компактных вычислительных платформ высокой плотности. Коммутационные платы/шасси стандарта VPX обеспечивают высокую пропускную способность данных, что позволяет выполнять одновременные операции с большими массивами данных. Компания ADLINK является одним из ключевых членов рабочей группы VPX International Trade Association (VITA), которая разрабатывает и продвигает спецификации VPX. Также ADLINK постоянно пополняет список VPX-изделий и их аналогов, предназначенных для ответственных приложений анализа сигналов.
Продукты ADLINK GPGPU позволяют реализовать высокотехнологичные радиолокационные системы с цифровой обработкой сигналов и возможностями машинного обучения, способные извлекать полезную информацию из массивов с очень высоким уровнем шума. Эти продукты включают:
- VPX3010 (рис. 5) представляет собой одноплатный сервер, разработанный для защищённых корпусов размера 3U, имеет три варианта процессора: Intel® Xeon® D-1559 (12-ядерный, 45 Вт TDP), Intel ® Xeon ® D-1539 (8-ядерный, 35 Вт TDP) и Intel ® Pentium ® D1519 (4-ядерный, 25 Вт TDP). VPX3010 обеспечивает мощную вычислительную базу, к которой можно добавить решение на основе графического процессора, такое как VPX3G10 или XMC-G1050TI через интерфейс XMC.

- VPX3G10-R/A (рис. 6) – плата 3U VPX GPGPU имеет двухканальную память GDDR5 и графический процессор NVIDIA. Оснащённая сотнями вычислительных ядер и совместимая с CUDA, данная VPX-видеокарта доступна в исполнениях с кондуктивным охлаждением (обозначается R) и с воздушным охлаждением (обозначается A).

- cPCI-6940 (рис. 7) – по различным причинам, в том числе и для сохранения ранее закупленного оборудования, некоторые приложения могут лучше работать с CompactPCI, а не с VPX. Как и VPX3010, одноплатный сервер ADLINK cPCI-6940 с процессором Intel ® Xeon ® D-1500 и AMD Radeon™ E8860 GPU в форм-факторе 6U предлагает высокоэффективную основу для систем обработки информации с радаров.

Обработка информации с сонара
В области сонарных систем цифровая обработка сигналов может охватить анализ сигналов от буксируемых и неподвижных объектов, гидроакустических буёв, управляемых торпед и других систем. В качестве приложений для подобных систем можно рассмотреть торпеду MK-48, Poseidon P-8 и автономные подводные аппараты (AUV – Autonomous Underwater Vehicle). Как и в случае с радаром, обработка GPGPU может выполнять геркулесову задачу по разбору «соли и перца» намного быст-рее и эффективнее, чем вычисление только на ЦП общего назначения. Это было доказано Пласидо Сальваторе Баттиато (Placido Salvatore Battiato) из Университета Катании, когда он сравнивал изображения в реальном времени и ответные акустические сигналы на платформах Intel ® Core™ i7-4510U (2 ядра), NVIDIA GeForce 820M (96 ядер, начальный уровень на мо-мент тестирования) и NVIDIA GeForce GTX 480 (480 ядер, средний уровень на момент тестирования).
Не удивительно, что GTX 480 оказался на уровне своих соперников.
Широкий спектр продуктов GPGPU от ADLINK обеспечивает разработчиков сонаров несколькими вариантами устройств обработки, укладывающимися в концепцию SWaP-ограничений (Size, Weight, and Power Consump-tion – размеры, вес и потребляемая мощность).
К ним относятся:
- VPX6000 (рис. 8). Когда приоритеты SWaP допускают большую свободу в выборе, форм-фактор 6U VPX обеспечивает максимальную производительность для приложений на базе GPGPU. VPX6000 от ADLINK использует до двух Intel ® Core™ i7-4700EQ (4-ядерный, 47 Вт TDP) и значительную мощность обработки при кондуктивном охлаждении. Однако, поскольку Core™ i7 поддерживает только интегрированную гра-фику Intel, для полной реализации решения GPGPU по-прежнему требуется сопутствующая графическая плата.

- XMC Graphics Module (рис. 9). Стандарт XMC, также известный как Switched Mezzanine Card, представляет собой один из типов мезонинных PCI-карт (PMC – PCI Mezzanine Card), определённых стандартом VITA 42. XMC задаёт несколько форматов высокоскоростного последовательного соединения и предлагает простой способ добавления модульных, ультрасовременных элементов ввода-вывода на платформу без больших затрат на собственное решение. XMC ADLINK имеет встроенную память GDDR5 и графический процессор NVIDIA. Модули могут иметь порты подключения дисплея, а также кондуктивное или воздушное охлаждение.

Обработка изображения

Методы обработки изображений предназначены для улучшения изображения и/или извлечения полезной информации из него. Приложения обработки изображений охватывают анализ, наблюдение, разведку, идентификацию целей и географическую привязку в зонах, не доступных GPS. Например, министерство обороны США ежемесячно собирает десятки тысяч часов видеонаблюдений с воздуха из Афганистана и других регионов. Обработка и преобразование зернистого, низкокачественного видео, сделанного беспилотными летательными аппаратами или спутниками, в чистые видеопотоки, подходящие для анализа, особенно в режиме реального времени, представляет собой задачу огромной вычислительной сложности. Согласно NVIDIA и MotionDSP, графические процессоры могут обрабатывать такое видео в семь раз быстрее, чем процессоры общего назначения.
HPERC ADLINK (высокозащищённые автономные подсистемы, соответствующие спецификации MIL) и продукты GPGPU в сочетании с графической обработкой NVIDIA CUDA и API OpenGL предоставляют инженерам-разработчикам мощные COTS-продукты (Commercial off-the-Shelf – готовые коммерческие), на базе которых они могут проектировать новые поколения систем обработки изображений.
Примеры продуктов включают упомянутую плату VPX GPGPU, модуль XMC GPGPU и другие, в том числе:
- HPERC (рис. 10) предназначен для работы при экстремальных температурах от –40 до + 85°C. HPERC соответствует спецификациям VITA-75 и весит чуть более 3 кг. Обе модели устройства оснащены процессором Intel ® Core™ i7 (двухъядерный i7-3517UE или четырёхъядерный i7-3612QUE) и рассеивают тепло через охлаждающую пластину, спецификация VITA 75.22. Соединители ввода-вывода соответствуют стандарту MIL-DTL-38999, а шины внутреннего расширения включают в себя MXM, PCI Express Mini Card (Gen2) и PCI/104 Express Type 2.
- MXM Graphics Module – этот дополнительный модуль MXM позволяет пользователям применять GPGPU от NVIDIA с GDDR5, делая HPERC компактным и универсальным решением для быстрого анализа изображений, особенно в дистанционных и/или мобильных системах.
Заключение
Радар, сонар и обработка изображений могут быть одними из самых интересных сфер для приложений GPGPU в армии, но по факту их гораздо больше, особенно в гражданской сфере. Глубокое обучение, искусственный интеллект, моделирование и симуляция, криптография и другие приложения могут стать более эффективными за счёт применения GPGPU.
Объединив GPGPU с проверенным и надёжным вычислительным оборудованием от ADLINK, инженеры могут создавать надёжные решения для ответственных применений, способные эффективно обеспечить и быстро предоставить результаты анализа. Теперь у специалистов, принимающих решения, будет значительно больше данных для оценки, чем раньше. При этом они справятся с этой неординарной задачей, поскольку уже существуют технологии, превращающие огромные потоки информации в реальном времени в простые и понятные данные. ●
Статья подготовлена по материалам компании ADLINK
Перевод Сергея Солдатова
E-mail: ssacompany@mail.ru