Слои Keras: параметры и свойства / keras 5
Слои являются основными элементами, необходимыми при создании нейронных сетей. Последовательные слои отвечают за архитектуру модели глубокого обучения. Каждый из них выполняет вычисления на основе данных, полученных из предыдущего. Затем информация передается дальше. В конце концов, последний слой выдает требуемый результат. В этом материале разберем типы слоев Keras, их свойства и параметры.
Слои Keras
Для определения или создания слоя Keras нужна следующая информация:
- Форма ввода: для понимания структуры входящей информации
- Количество: для определения количества узлов/нейронов в слое
- Инициализатор: для определения весов каждого входа, что важно для выполнения вычислений
- Активаторы: для преобразования входных данных в нелинейный формат, чтобы каждый нейрон мог обучаться эффективнее
- Ограничители: для наложения ограничений на веса при оптимизации
- Регуляторы: для применения штрафов к параметрам во время оптимизации
Различные слои в Keras
Основные слои Keras
Dense
Вычисляет вывод следующим образом:
output=activation(dot(input,kernel)+bias) Здесь activation — это активатор, а kernel — взвешенная матрица, применяемая к входящим тензорам. bias — это константа, помогающая настроить модель наилучшим образом.
Dense-слой получает информацию со всех узлов предыдущего слоя. Вот его аргументы и значения по умолчанию:
Dense(units, activation=NULL, use_bias=TRUE,kernel_initializer='glorot_uniform', bias_regularizer=NULL, activity_regularizer=NULL, kernel_constraint=NULL, bias_constrain=NULL) Activation
Используется для применения функции активации к выводу. То же самое, что передача активации в Dense-слой. Имеет следующие аргументы:
Activation(activation_function) Если функцию активации не передать, то будет выполнена линейная активация.
Dropout
Dropout применяется в нейронных сетях для решения проблемы переобучения. Для этого он случайным образом выбирает доли единиц и при каждом обновлении назначает им значение 0.
Dropout(rate, noise_shape=NULL, seed=NULL) Flatten
Flatten используется для конвертации входящих данных в меньшую размерность.
Например, входящий слой размерности (batch_size, 3,2) «выравнивается» для вывода размерности (batch_size, 6) . Он имеет следующие аргументы.
Flatten(data_format=None) Input
Этот слой используется в Keras для создания модели на основе ввода и вывода модели. Он является точкой входа в модель графа.
Input(shape, batch_shape, name, dtype, sparse=FALSE,tensor=NULL) Reshape
Изменить вывод под конкретную размерность
Reshape(target_shape) Выдаст следующий результат:
(batch_size,)+ target_shape Permute
Поменять ввод для соответствия конкретному шаблону. Этот же слой используется для изменения формы ввода с помощью определенных шаблонов.
Permute(dims) Lambda
Слои Lambda используются для создания дополнительных признаков слоев, которых нет в Keras.
Lambda(lambda_fun,output_shape=None, mask=None, arguments=None) Masking
Пропустить временной промежуток, если все признаки равны mask_value .
Masking(mask_value=0.0) Сверточные сети Keras
Conv1D и Conv2D
Здесь определяется взвешенное ядро. Производится операция свертки, результатом которой становятся тензоры.
Conv1D(filters,kernel_size,strides=1, padding='valid', data_format='channels_last', dilation_rate=1, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) Conv2D(filters,kernel_size,strides=(1,1) , padding='valid', data_format='channels_last', dilation_rate=(1,1) , activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) Слои пулинга (подвыборки)
Они используются для уменьшения размера ввода и извлечения важной информации.
MaxPooling1D и MaxPooling2D
MaxPooling1D(pool_size=2, strides=None, padding='valid', data_format='channels_last') MaxPooling2D(pool_size=(2,2), strides=None, padding='valid', data_format='channels_last') AveragePooling1D и AveragePooling2D
AveragePooling1D(pool_size=2, strides=None, padding='valid', data_format='channels_last') AveragePooling1D(pool_size=(2,2), strides=None, padding='valid', data_format=None) Рекуррентный слой
Этот слой используется для вычисления последовательных данных — временного ряда или естественного языка.
SimpleRNN
Это полностью связанная RNN (рекуррентная нейронная сеть), где вывод подается обратно в качестве входящих данных
SimpleRNN(units, activation, use_bias, kernel_initializer, recurrent_initializer, bias_initializer, kernel_regularizer, recurrent_regularizer, bias_regularizer, activity_regularizer, kernel_constraint, recurrent_constraint, bias_constraint, dropout, recurrent_dropout, return_sequences, return_state) LSTM
Это увеличенная форма RNN с хранилищем для информации.
LSTM(units, activation , recurrent_activation, use_bias, kernel_initializer, recurrent_initializer, bias_initializer, unit_forget_bias, kernel_regularizer, recurrent_regularizer, bias_regularizer, activity_regularizer, kernel_constraint, recurrent_constraint, bias_constraint, dropout, recurrent_dropout, implementation, return_sequences, return_state) В Keras есть и другие слои, но чаще всего используются описанные выше.
Выводы
Этот материал посвящен концепции слоев в моделях Keras. Вы узнали о требованиях для построения слоя, а также об их типах: основные слои, сверточные слои, подвыборки, рекуррентные слои, а также их свойства и параметры.
Keras — последовательная модель Sequential
На предыдущем занятии мы с вами увидели, как можно с нуля создавать слои и модели, используя базовые классы:
- Dense() – полносвязный слой;
- Conv1D, Conv2D, Conv3D – сверточные слои;
- Conv2DTranspose, Conv3DTranspose – транспонированные (обратные) светочные слои;
- SimpleRNN, LSTM, GRU – рекуррентные слои;
- MaxPooling2D, Dropout, BatchNormalization – вспомогательныеслои
- Model – общий класс модели;
- Sequential – последовательная модель.
Класс Sequential
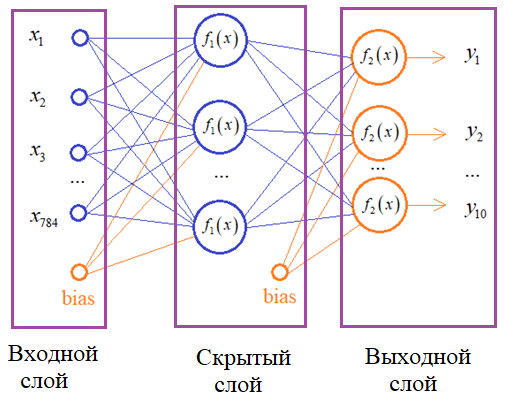
Часто архитектуры нейронных сетей строят в виде последовательности слоев, начиная с входного и заканчивая выходным: Теоретически, число скрытых слоев может быть сколь угодно большим. Для описания такой модели, как раз и применяется класс Sequential.Например, для описания изображенной сети, модель можно сформировать, следующим образом. Вначале импортируем необходимые зависимости:
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf from tensorflow.keras.layers import Dense from tensorflow import keras from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical
А, затем, создаем экземпляр класса Sequential, то есть, последовательную архитектуру нейронной сети:
model = keras.Sequential([ Dense(128, activation='relu'), Dense(10, activation='softmax') ])
В действительности, это эквивалентно последовательному вызову слоев для некоторого входного тензора:
layer1 = Dense(128, activation='relu') layer2 = Dense(10, activation='softmax') x = tf.random.uniform((1, 20), 0, 1) y = layer2(layer1(x))
Класс Sequential предоставляет лишь удобство и некоторый дополнительный функционал при работе с моделью. Например, все слои доступны через список model.layers:
print(model.layers )
Можно удалить последний слой методом pop():
model.pop()
А, затем, добавить методом add():
model.add(Dense(5, activation='linear'))
Соответственно, можно вначале определить пустую модель (без слоев):
model = keras.Sequential()
а после этого добавить необходимые элементы:
model.add(Dense(128, activation='relu', name="layer1")) model.add(Dense(10, activation='softmax', name="layer2"))
При этом каждому слою можно задать свое имя, которые будут использоваться при отображении служебной информации о модели. У каждого слоя и у модели в целом имеется свойство weights, содержащее список настраиваемых параметров (весовых коэффициентов). Если обратиться к первому слою и свойству weights:
print( model.layers[0].weights )
то увидим пустой список. А если сделать то же самое для всей модели:
print( model.weights )
то получим исключение (ошибку). Это связано с тем, что до момента подачи входного сигнала на вход сети весовые коэффициенты еще не были сформированы. Здесь все работает по аналогии с нашим классом DenseLayer, который мы создавали на предыдущем занятии. Пока не будет вызван метод build слоя, весовые коэффициенты отсутствуют. Давайте пропустим через модель входной сигнал, состоящий из одного наблюдения длиной 20 чисел:
x = tf.random.uniform((1, 20), 0, 1) y = model(x)
Теперь при обращении к свойству weights получим список всех весовых коэффициентов модели:
print(model.weights )
и мы также можем вывести структуру этой модели с помощью метода summary():
model.summary()
Слой Input
Помимо функциональных слоев в Kerasсуществуют вспомогательные слои и один из них определяется классом Input. Как вы уже догадались, этот слой служит для описания формы входных данных. То есть, если модель не имеет слоя Input, то размерность входного вектора устанавливается по входному тензору при первом вызове, как мы это только что с вами видели на примере. Но, если явно указать размерность через класс Input, то модель сети строится сразу с начальным набором весов. Например, опишем последовательную модель, следующим образом:
model = keras.Sequential([ Input(shape=(20, )), Dense(128, activation='relu'), Dense(10, activation='softmax') ])
Здесь первый слой Input() устанавливает размерность входного тензора, равным 20 элементов. Это означает, что на вход следует подавать данные в формате: [batch_size, 20] Обратите внимание, в Keras первая размерность – это размер мини-батча, по которому производится расчет градиентов и оптимизация весовых коэффициентов. Поэтому, указывая размер 20, получаем матрицу: batch_size x 20 Именно так мы задавали входной тензор для нашей модели (размерностью 1 x 20):
x = tf.random.uniform((1, 20), 0, 1) y = model(x)
Также следует иметь в виду, что в коллекции model.layers:
print(model.layers)
будет всего два слоя, а не три, так как входной слой Input не является функциональным и нужен лишь для определения свойств входного сигнала.Того же эффекта можно добиться, просто указывая размерность через параметр input_shape:
model = keras.Sequential([ Dense(128, activation='relu', input_shape=(784,), name="hidden_1"), Dense(10, activation='softmax', name="output") ])
Разумеется, такой параметр можно использовать только у первого слоя в последовательной модели. На практике рекомендуется всегда заранее прописывать размерности входного тензора, чтобы избежать возможных ошибок при подаче на вход другого сигнала (другой размерности).
Обучение модели
Последовательная модель обучается абсолютно также, как и любая другая модель в Keras. Если у нас есть обучающая выборка:
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train / 255 x_test = x_test / 255 x_train = tf.reshape(tf.cast(x_train, tf.float32), [-1, 28*28]) x_test = tf.reshape(tf.cast(x_test, tf.float32), [-1, 28*28]) y_train = to_categorical(y_train, 10) y_test_cat = to_categorical(y_test, 10)
то достаточно задать функцию потерь, оптимизатор:
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
и запустить обучением через метод fit():
model.fit(x_train, y_train, batch_size=32, epochs=5)
Мы все это с вами уже делали несколько раз, поэтому просто привожу фрагмент программы, как пример обучения последовательной нейронной сети.
Извлечение признаков из последовательной модели
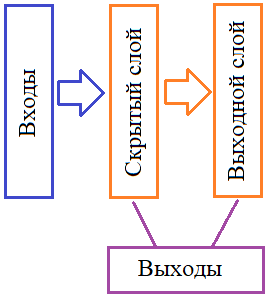
Давайте теперь на основе последовательной модели сформируем немного более сложную модель, которая будет иметь тот же один вход, но два выхода (по одному от каждого слоя): Такое преобразование легко выполнить с помощью другого, общего класса моделей – keras.Model. При создании его экземпляра достаточно в сформированной нейронной сети указать список входов и список выходов. В нашем случае, это можно сделать так:
model_ex = keras.Model(inputs=model.inputs, outputs=[layer.output for layer in model.layers])
Обратите внимание, мы это делаем после обучения сети. В результате, модель model_ex будет содержать те же самые слои и весовые коэффициенты, что и модель model, так как лишь меняет конфигурацию входов и выходов, но не создает сеть заново. То есть, обе модель ссылаются на одну и ту же архитектуру НС.Благодаря этому, мы можем обучать любую из них, а затем, использовать обе, как обученный вариант НС. В качестве маленького эксперимента давайте создадим модель model_ex непосредственно после модели model, обучим первую модель (model) и сравним выходные результаты последнего слоя:
x = tf.expand_dims(x_test[0], axis=0) y = model_ex(x) y2 = model(x) print(y, y2, sep="\n\n")
Как видим, выходные значения идентичны. Это показывает, что обе модели представляют одну и ту же нейронную сеть. Но, model_ex дополнительно еще дает доступ к промежуточным слоям. Однако, если сформировать модель, указав только один выход с промежуточного слоя:
model_ex = keras.Model(inputs=model.inputs, outputs=model.layers[0].output)
то получим урезанный вариант исходной модели. Здесь выходной слой будет отсутствовать, так как он идет после первого. А если указать один выходной слой:
model_ex = keras.Model(inputs=model.inputs, outputs=model.get_layer(name="output").output)
то получим эквивалент исходной модели, так как все промежуточные слои между входом и указанными выходами автоматически повторяются. Мы можем в этом убедиться, вызвав метод summary() для второй модели:
model_ex.summary()
Обратите внимание, как мы обратились к выходному слою – по его имени, которое было задано через параметр name этого слоя. Это пример того, как можно извлекать отдельные слои из моделей нейронных сетей.
Расширение существующей модели
Пакет Keras позволяет весьма гибко создавать и обучать НС. Например, мы можем расширить первую модель, добавив в нее еще один полносвязный слой:
model_ex = keras.Sequential([ model, Dense(10, activation="tanh") ])
Смотрите, здесь первая часть модель – это первая модель, а далее описан еще один слой Dense. Мало того, мы можем обучить этот последний слой, не трогая веса первой модели, то есть, исключая ее из обучения. Для этого достаточно определить свойство:
model.trainable = False
И после компилирования второй модели:
model_ex.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
дообучим ее последний слой:
model_ex.fit(x_train, y_train, batch_size=32, epochs=3)
При необходимости можно «замораживать» отдельные слои, исключая их из обучения. Для этого следует обратиться к слою и установить у него тот же параметр trainable в False:
model.layers[0].trainable = False
Надеюсь, из этого занятия вы стали лучше понимать, как конструируются последовательные модели в Keras, как они модифицируются и обучаются.
Keras — введение в функциональное API
На этом занятии мы посмотрим на построение архитектур нейронных сетей под новым углом зрения – с позиции функционального API пакета Keras. Давайте вначале разберемся, что это такое. Предположим, что мы хотим создать следующую модель НС:

И мы уже знаем, что это можно реализовать с помощью класса Sequential, о котором мы говорили на предыдущем занятии. Но эту же самую архитектуру можно описать подобно графам –через связи между слоями. Именно эта идея и положена в основу функционального описания модели.
Давайте посмотрим, как это делается.В начале программы подключим необходимые модули:
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf from tensorflow.keras.layers import Dense, Input, Conv2D, MaxPooling2D, Flatten from tensorflow import keras from tensorflow.keras.datasets import cifar10 import matplotlib.pyplot as plt
И установим зерно датчика случайных чисел в 1, чтобы обеспечить воспроизводимость результатов:
tf.random.set_seed(1)
Затем, сформируем первыедва слоя так, как это мы обычно делали:
input = keras.Input(shape=(32, 32, 3)) x = Conv2D(32, 3, activation='relu')
А, далее, свяжем их между собой, следующим образом:
x = x(input)
Эта строчка и есть элемент функционального API пакета Keras. Но как это работает? Все очень просто. Смотрите, объект input – это тензор специального вида, имеющий типKerasTensor:
То есть, это объект, представляющий слой, а не конкретные данные. Далее, так как каждый слой в Keras является функтором (реализует магический метод __call__ и может быть вызван как функция), то при подаче ему на вход другого слоя, он делает не вычисления, а формирует связку с указанным слоем. Вот и все.
Конечно, эту связь можно описать короче, в виде:
x = Conv2D(32, 3, activation='relu')(input)
Здесь мы сразу создаем объект и выполняем связывание со слоем input. В итоге, вся структура нейронной сети может быть описана в виде:
input = keras.Input(shape=(32, 32, 3)) x = layers.Conv2D(32, 3, activation='relu')(input) x = layers.MaxPooling2D(2, padding='same')(x) x = layers.Conv2D(64, 3, activation='relu')(x) x = layers.MaxPooling2D(2, padding='same')(x) x = layers.Flatten()(x) x = layers.Dense(256, activation='relu')(x) x = layers.Dropout(0.5)(x) output = layers.Dense(10, activation='softmax')(x)
Но это еще не модель. Конечно, мы можем использовать сеть в таком виде, подавать на вход числовые данные и получать выходные значения, но нам бы хотелось получить полноценную модель, чтобы средствами Keras обучать ее и производить оценку эффективности. Для этого достаточно воспользоваться классом Model, о котором мы с вами уже говорили на предыдущих занятиях, и указать входы и выходы:
model = keras.Model(inputs=input, outputs=output)
Все, модель сформирована с использованием функционального подхода и готова к использованию. Чтобы убедиться, что структура сети верная, выведем ее с помощью метода:
model.summary()
Как видите, все было сделано верно. Возможно, у вас возникнет вопрос: а зачем было все так усложнять? Почему бы не воспользоваться классом Sequential? Это было бы проще. Все верно. Для последовательных структур так и следует поступать. Однако, на практике относительно часто встречаются и другие архитектуры, которые не удается описать последовательными моделями. Либо, сделать это сложнее. В таких ситуациях, как раз, и используется функциональный подход к проектированию архитектур сетей.
Обучение сверточной нейронной сети
Давайте теперь обучим полученную модель сверточной НС для классификации изображений БД CIFAR-10. Сразу отмечу, что современные нейросети достигают здесь точности около 96,5%, а человек – всего 94%. Посмотрим, что получится у нас.

В этой БД имеется 50 000 полноцветных изображений, размером 32×32 пикселов в обучающей выборке и 10 000 таких же полноцветных изображений в тестовой выборке. Все изображения разбиты на 10 классов (см. рисунок). Наша задача отнести предъявленный образец нужному классу.
Вначале, как всегда, загрузим набор данных и стандартизуем их:
(x_train, y_train), (x_test, y_test) = cifar10.load_data() x_train = x_train / 255 x_test = x_test / 255 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10)
Затем, укажем оптимизатор и функцию потерь:
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
После этого, запустим процесс обучения:
model.fit(x_train, y_train, batch_size=64, epochs=20, validation_split=0.2)
В конце программы выполним оценку качества работы модели на тестовой выборке:
print(model.evaluate(x_test, y_test) )
После запуска программы увидим качество распознавания на обучающей выборке в 87%, а на тестовой в 72%, что в целом неплохо, учитывая сложность задачи и простоту архитектуры НС. Предлагаю вам в качестве практики попытаться улучшить качество распознавания изображений БД CIFAR-10.
Реализация сверточных слоев в Tensorflow
Так как этот курс посвящен не только Keras, но и Tensorflow, то я покажу пример реализации сверточных слоев на уровне Tensorflow. Делается относительно просто, но несколько сложнее, чем в Keras. Вначале определим вспомогательный класс слоя:
class TfConv2D(tf.Module): def __init__(self, kernel=(3, 3), channels=1, strides=(2, 2), padding='SAME', activate="relu"): super().__init__() self.kernel = kernel self.channels = channels self.strides = strides self.padding = padding self.activate = activate self.fl_init = False def __call__(self, x): if not self.fl_init: self.w = tf.random.truncated_normal((*self.kernel, x.shape[-1], self.channels), stddev=0.1) self.b = tf.zeros([self.channels], dtype=tf.float32) self.w = tf.Variable(self.w) self.b = tf.Variable(self.b) self.fl_init = True y = tf.nn.conv2d(x, self.w, strides=(1, *self.strides, 1), padding=self.padding) if self.activate == "relu": return tf.nn.relu(y) elif self.activate == "softmax": return tf.nn.softmax(y) return y
Я его взял из одного из предыдущих занятий и полносвязный слой заменил сверточным. Логика работы здесь следующая. Для сверток нужно задать размер фильтра (kernel), число выходных каналов (channels), смещение фильтров в плоскости входных каналов (strides) и режим формирования выходных каналов (padding). То есть, мы прописываем все те же параметры, что и в стандартном сверточном слое.
Затем, при первом вызове магического метода __call__() формируем наборы весовых коэффициентов размерностью:
[kernel_x,kernel_y, input_channels, output_channels]
И еще тензор коэффициентов для смещений (biases) размером:
После этого обращаемся к ветке tf.nn и вызываем функцию conv2d для применения фильтров к входному сигналу x. К полученному выходному тензору y применяем функцию активации и, таким образом, формируем выход сверточного слоя.
Использовать этот класс можно, следующим образом:
layer1 = TfConv2D((3, 3), 32) y = layer1(tf.expand_dims(x_test[0], axis=0)) print(y.shape)
Применяя его к первому входному изображению, получаем на выходе 32 канала размерностью 16x 16 отсчетов:
Далее, можно применить операцию MaxPooling, например, так:
y = tf.nn.max_pool2d(y, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding="SAME") print(y.shape)
Сформируется тензор yразмерностью:
По аналогии можно реализовать и другие типы сверточных слоев. Затем, сформировать модель сети и обучить так, как мы это делали на первых занятиях.
Этот пример хорошо показывает, как Keras заметно облегчает описание архитектур нейронных сетей, а также их обучение.
Модели в функциональном API
Любую модель в Keras можно воспринимать как функциональный элемент и добавлять его в общую структуру сети, используя функциональный подход. В качестве примера давайте опишем архитектуру простого автоэнкодера, используя две независимые модели: модель кодера и модель декодера:
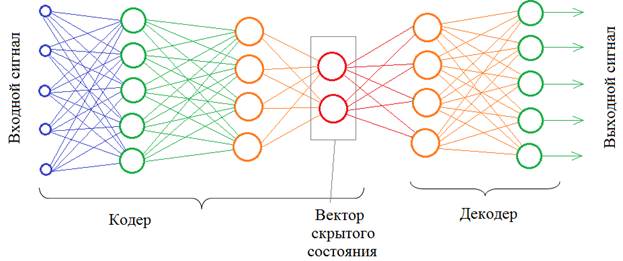
Если вы не знаете, что такое автоэнкодер, для чего он нужен и как работает, то смотрите занятие по этой теме в курсе «Нейронные сети»:
Вначале опишем модель кодера, используя сверточные слои:
enc_input = Input(shape=(28, 28, 1)) x = Conv2D(32, 3, activation='relu')(enc_input) x = MaxPooling2D(2, padding='same')(x) x = Conv2D(64, 3, activation='relu')(x) x = MaxPooling2D(2, padding='same')(x) x = Flatten()(x) enc_output = Dense(8, activation='linear')(x) encoder = keras.Model(enc_input, enc_output, name="encoder")
А, затем, модельдекодера:
dec_input = keras.Input(shape=(8,), name="encoded_img") x = Dense(7 * 7 * 8, activation='relu')(dec_input) x = keras.layers.Reshape((7, 7, 8))(x) x = Conv2DTranspose(64, 5, strides=(2, 2), activation="relu", padding='same')(x) x = keras.layers.BatchNormalization()(x) x = Conv2DTranspose(32, 5, strides=(2, 2), activation="linear", padding='same')(x) x = keras.layers.BatchNormalization()(x) dec_output = Conv2DTranspose(1, 3, activation="sigmoid", padding='same')(x) decoder = keras.Model(dec_input, dec_output, name="decoder")
Теперь, используя модели encoder и decoder можно на их основе сформировать общую архитектуру автоэнкодера. Воспользуемся для этого функциональным подходом и будем рассматривать каждую модель как один единый элемент (объект):
autoencoder_input = Input(shape=(28, 28, 1), name="img") x = encoder(autoencoder_input) autoencoder_output = decoder(x) autoencoder = keras.Model(autoencoder_input, autoencoder_output, name="autoencoder")
Я здесь специально создал еще один входной слой, чтобы он был уникальным для автоэнкодера. Далее, связываем его с моделью кодера, а кодер с моделью декодера. Затем, из полученной структуры слоев и моделей формируем единую модель.
Причем, обратите внимание, в модели автоэнкодера не создаются копии архитектур кодера и декодера, а используются существующие. Это значит, что при обучении автоэнкодера мы будем автоматически обучать и модели кодера и декодера.
Давайте выполним этот шаг для БД изображений цифр MNIST. Вначале подготовим обучающую выборку:
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.astype("float32") / 255.0 x_test = x_test.astype("float32") / 255.0 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10)
Установим оптимизатор Adamдля автоэнкодера и потребуем минимум квадрата ошибки рассогласования между входным и выходным изображениями:
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
После этого можно запускать сам процесс обучения (одной эпохи вполне достаточно для этой задачи):
autoencoder.fit(x_train, x_train, batch_size=32, epochs=1)
Все, модель обучилась, а это значит, что мы также обучили кодер и декодер. Давайте в этом убедимся. Пропустим первое тестовое изображение через кодер, а его выходной сигнал подадим на декодер:
h = encoder.predict(tf.expand_dims(x_test[0], axis=0)) img = decoder.predict(h)
В результате должны получить изображение похожее на входное. Для этого отобразим исходное изображение и восстановленное:
plt.subplot(121) plt.imshow(x_test[0], cmap='gray') plt.subplot(122) plt.imshow(img.squeeze(), cmap='gray') plt.show()
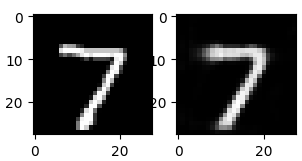
Как видим, результаты получились достаточно близкими. Это показывает, что кодер и декодер действительно обучились через автоэнкодер.
На следующем занятии мы продолжим эту тему и поближе познакомимся с принципом архитектуры ResNet, а также проблемами, связанными с обучением глубоких сетей.
Видео по теме

#1. Что такое Tensorflow? Примеры применения. Установка

#2. Тензоры tf.constant и tf.Variable. Индексирование и изменение формы

#3. Математические операции и функции над тензорами

#4. Реализация автоматического дифференцирования. Объект GradientTape

#5. Строим градиентные алгоритмы оптимизации Adam, RMSProp, Adagrad, Adadelta

#6. Делаем модель с помощью класса tf.Module. Пример обучения простой нейросети

#7. Делаем модель нейросети для распознавания рукописных цифр

#8. Декоратор tf.function для ускорения выполнения функций

#9. Введение в модели и слои бэкэнда Keras

#10. Keras — последовательная модель Sequential

#11. Keras — введение в функциональное API

#12. ResNet — революция глубокого обучения. Исчезающие и взрывающиеся градиенты

#13. Создаем ResNet подобную архитектуру для классификации изображений CIFAR-10

#14. Тонкая настройка и контроль процесса обучения через метод fit()

#15. Тонкая настройка обучения моделей через метод compile()

#16. Способы сохранения и загрузки моделей в Keras
© 2024 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Обзор Keras для TensorFlow

tf.keras является реализацией TensorFlow спецификации Keras API. Это высокоуровневый API для построения и обучения моделей включающий первоклассную поддержку для TensorFlow-специфичной функциональности, такой как eager execution, конвейеры tf.data , и Estimators. tf.keras делает использование TensorFlow проще не жертвуя при этом гибкостью и, производительностью.
Для начала, импортируйте tf.keras как часть установки вашей TensorFlow:
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf from tensorflow import kerastf.keras может выполнять любой Keras-совместимый код, но имейте ввиду:
- Версия tf.keras в последнем релизе TensorFlow может отличаться от последней версии keras в PyPI. Проверьте tf.keras.__version__ .
- Когда сохраняете веса моделей, tf.keras делает это по умолчанию в формате checkpoint. Передайте параметр save_format=’h5′ для использования HDF5 (или добавьте к имени файла расширение .h5 ).
Постройте простую модель
Последовательная модель
В Keras, вы собираете слои (layers) для построения моделей (models). Модель это (обычно) граф слоев. Наиболее распространенным видом модели является стек слоев: модель tf.keras.Sequential .
Построим простую полносвязную сеть (т.е. многослойный перцептрон):
from tensorflow.keras import layers model = tf.keras.Sequential() # Добавим к модели полносвязный слой с 64 узлами: model.add(layers.Dense(64, activation='relu')) # Добавим другой слой: model.add(layers.Dense(64, activation='relu')) # Добавим слой softmax с 10 выходами: model.add(layers.Dense(10, activation='softmax'))Настройте слои
Доступно много разновидностей слоев tf.keras.layers . Большинство из них используют общий конструктор аргументов:
- activation : Установка функции активации для слоя. В этом параметре указывается имя встроенной функции или вызываемый объект. У параметра нет значения по умолчанию.
- kernel_initializer и bias_initializer : Схемы инициализации создающие веса слоя (ядро и сдвиг). В этом параметре может быть имя или вызываемый объект. По умолчанию используется инициализатор «Glorot uniform» .
- kernel_regularizer и bias_regularizer : Схемы регуляризации добавляемые к весам слоя (ядро и сдвиг), такие как L1 или L2 регуляризации. По умолчанию регуляризация не устанавливается.
# Создадим слой с сигмоидой: layers.Dense(64, activation='sigmoid') # Или: layers.Dense(64, activation=tf.keras.activations.sigmoid) # Линейный слой с регуляризацией L1 с коэфициентом 0.01 примененной к матрице ядра: layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l1(0.01)) # Линейный слой с регуляризацией L2 с коэффициентом 0.01 примененной к вектору сдвига: layers.Dense(64, bias_regularizer=tf.keras.regularizers.l2(0.01)) # Линейный слой с ядром инициализированным случайной ортогональной матрицей: layers.Dense(64, kernel_initializer='orthogonal') # Линейный слой с вектором сдвига инициализированным значениями 2.0: layers.Dense(64, bias_initializer=tf.keras.initializers.Constant(2.0))Обучение и оценка
Настройка обучения
После того как модель сконструирована, настройте процесс ее обучения вызовом метода compile :
model = tf.keras.Sequential([ # Добавляем полносвязный слой с 64 узлами к модели: layers.Dense(64, activation='relu', input_shape=(32,)), # Добавляем другой: layers.Dense(64, activation='relu'), # Добавляем слой softmax с 10 выходами: layers.Dense(10, activation='softmax')]) model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])tf.keras.Model.compile принимает три важных аргумента:
- optimizer : Этот объект определяет процедуру обучения. Передайте в него экземпляры оптимизатора из модуля tf.keras.optimizers , такие как tf.keras.optimizers.Adam или tf.keras.optimizers.SGD . Если вы просто хотите использовать параметры по умолчанию, вы также можете указать оптимизаторы ключевыми словами, такими как ‘adam’ или ‘sgd’ .
- loss : Это функция которая минимизируется в процессе обучения. Среди распространенных вариантов среднеквадратичная ошибка ( mse ), categorical_crossentropy , binary_crossentropy . Функции потерь указываются по имени или передачей вызываемого объекта из модуля tf.keras.losses .
- metrics : Используются для мониторинга обучения. Это строковые имена или вызываемые объекты из модуля tf.keras.metrics .
- Кроме того, чтобы быть уверенным, что модель обучается и оценивается eagerly, проверьте что вы передали компилятору параметр run_eagerly=True
# Сконфигурируем модель для регрессии со среднеквадратичной ошибкой. model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='mse', # mean squared error metrics=['mae']) # mean absolute error # Сконфигурируем модель для категориальной классификации. model.compile(optimizer=tf.keras.optimizers.RMSprop(0.01), loss=tf.keras.losses.CategoricalCrossentropy(), metrics=[tf.keras.metrics.CategoricalAccuracy()])Обучение на данных NumPy
Для небольших датасетов используйте помещающиеся в память массивы NumPy для обучения и оценки модели. Модель «обучается» на тренировочных данных, используя метод `fit`:
import numpy as np data = np.random.random((1000, 32)) labels = np.random.random((1000, 10)) model.fit(data, labels, epochs=10, batch_size=32)tf.keras.Model.fit принимает три важных аргумента:
- epochs : Обучение разбито на *эпохи*. Эпоха это одна итерация по всем входным данным (это делается небольшими партиями).
- batch_size : При передаче данных NumPy, модель разбивает данные на меньшие блоки (batches) и итерирует по этим блокам во время обучения. Это число указывает размер каждого блока данных. Помните, что последний блок может быть меньшего размера если общее число записей не делится на размер партии.
- validation_data : При прототипировании модели вы хотите легко отслеживать её производительность на валидационных данных. Передача с этим аргументом кортежа входных данных и меток позволяет модели отображать значения функции потерь и метрики в режиме вывода для передаваемых данных в конце каждой эпохи.
import numpy as np data = np.random.random((1000, 32)) labels = np.random.random((1000, 10)) val_data = np.random.random((100, 32)) val_labels = np.random.random((100, 10)) model.fit(data, labels, epochs=10, batch_size=32, validation_data=(val_data, val_labels))Обучение с использованием наборов данных tf.data
Используйте Datasets API для масштабирования больших баз данных или обучения на нескольких устройствах. Передайте экземпляр `tf.data.Dataset` в метод fit :
# Создает экземпляр учебного датасета: dataset = tf.data.Dataset.from_tensor_slices((data, labels)) dataset = dataset.batch(32) model.fit(dataset, epochs=10)Поскольку Dataset выдает данные пакетами, этот кусок кода не требует аргумента batch_size .
Датасеты могут быть также использованы для валидации:
dataset = tf.data.Dataset.from_tensor_slices((data, labels)) dataset = dataset.batch(32) val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels)) val_dataset = val_dataset.batch(32) model.fit(dataset, epochs=10, validation_data=val_dataset)Оценка и предсказание
Методы tf.keras.Model.evaluate и tf.keras.Model.predict могут использовать данные NumPy и tf.data.Dataset .
Вот так можно оценить потери в режиме вывода и метрики для предоставленных данных:
# С массивом Numpy data = np.random.random((1000, 32)) labels = np.random.random((1000, 10)) model.evaluate(data, labels, batch_size=32) # С датасетом dataset = tf.data.Dataset.from_tensor_slices((data, labels)) dataset = dataset.batch(32) model.evaluate(dataset)А вот как предсказать вывод последнего уровня в режиме вывода для предоставленных данных в виде массива NumPy:
Построение сложных моделей
The Functional API
Модель tf.keras.Sequential это простой стек слоев с помощью которого нельзя представить произвольную модель. Используйте Keras functional API для построения сложных топологий моделей, таких как:
- Модели с несколькими входами,
- Модели с несколькими выходами,
- Модели с общими слоями (один и тот же слой вызывается несколько раз),
- Модели с непоследовательными потоками данных (напр. остаточные связи).
- Экземпляр слоя является вызываемым и возвращает тензор.
- Входные и выходные тензоры используются для определения экземпляра tf.keras.Model
- Эта модель обучается точно так же как и `Sequential` модель.
inputs = tf.keras.Input(shape=(32,)) # Возвращает входной плейсхолдер # Экземпляр слоя вызывается на тензор и возвращает тензор. x = layers.Dense(64, activation='relu')(inputs) x = layers.Dense(64, activation='relu')(x) predictions = layers.Dense(10, activation='softmax')(x)Создайте экземпляр модели с данными входами и выходами.
model = tf.keras.Model(inputs=inputs, outputs=predictions) # Шаг компиляции определяет конфигурацию обучения. model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001), loss='categorical_crossentropy', metrics=['accuracy']) # Обучение за 5 эпох model.fit(data, labels, batch_size=32, epochs=5)Сабклассинг моделей
Создайте полностью настраиваемую модель с помощью сабклассинга tf.keras.Model и определения вашего собственного прямого распространения. Создайте слои в методе __init__ и установите их как атрибуты экземпляра класса. Определите прямое распространение в методе call .
Сабклассинг модели особенно полезен когда включен eager execution, поскольку он позволяет написать прямое распространение императивно.
Примечание: если вам нужно чтобы ваша модель всегда выполнялась императивно, вы можете установить dynamic=True когда вызываете конструктор super .
Ключевой момент: Используйте правильный API для работы. Хоть сабклассинг модели обеспечивает гибкость, за нее приходится платить большей сложностью и большими возможностями для пользовательских ошибок. Если это возможно выбирайте functional API.
Следующий пример показывает сабклассированную модель tf.keras.Model использующую пользовательское прямое распространение, которое не обязательно выполнять императивно:
class MyModel(tf.keras.Model): def __init__(self, num_classes=10): super(MyModel, self).__init__(name='my_model') self.num_classes = num_classes # Определим свои слои тут. self.dense_1 = layers.Dense(32, activation='relu') self.dense_2 = layers.Dense(num_classes, activation='sigmoid') def call(self, inputs): # Определим тут свое прямое распространение, # с использованием ранее определенных слоев (в `__init__`). x = self.dense_1(inputs) return self.dense_2(x)Создайте экземпляр класса новой модели:
model = MyModel(num_classes=10) # Шаг компиляции определяет конфигурацию обучения. model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001), loss='categorical_crossentropy', metrics=['accuracy']) # Обучение за 5 эпох. model.fit(data, labels, batch_size=32, epochs=5)Пользовательские слои
Создайте пользовательский слой сабклассингом tf.keras.layers.Layer и реализацией следующих методов:
- __init__ : Опционально определите подслои которые будут использоваться в этом слое.
- * build : Создайте веса слоя. Добавьте веса при помощи метода add_weight
- call : Определите прямое распространение.
- Опционально, слой может быть сериализован реализацией метода get_config и метода класса from_config .
class MyLayer(layers.Layer): def __init__(self, output_dim, **kwargs): self.output_dim = output_dim super(MyLayer, self).__init__(**kwargs) def build(self, input_shape): # Создадим обучаемую весовую переменную для этого слоя. self.kernel = self.add_weight(name='kernel', shape=(input_shape[1], self.output_dim), initializer='uniform', trainable=True) def call(self, inputs): return tf.matmul(inputs, self.kernel) def get_config(self): base_config = super(MyLayer, self).get_config() base_config['output_dim'] = self.output_dim return base_config @classmethod def from_config(cls, config): return cls(**config) Создайте модель с использованием вашего пользовательского слоя:
model = tf.keras.Sequential([ MyLayer(10), layers.Activation('softmax')]) # Шаг компиляции определяет конфигурацию обучения model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001), loss='categorical_crossentropy', metrics=['accuracy']) # Обучение за 5 эпох. model.fit(data, labels, batch_size=32, epochs=5)Колбеки
Колбек это объект переданный модели чтобы кастомизировать и расширить ее поведение во время обучения. Вы можете написать свой пользовательский колбек или использовать встроенный tf.keras.callbacks который включает в себя:
tf.keras.callbacks.ModelCheckpoint : Сохранение контрольных точек модели за регулярные интервалы.
tf.keras.callbacks.LearningRateScheduler : Динамичное изменение шага обучения.
tf.keras.callbacks.EarlyStopping : Остановка обучения в том случае когда результат при валидации перестает улучшаться.
tf.keras.callbacks.TensorBoard: Мониторинг поведения модели с помощью
TensorBoard
Для использования tf.keras.callbacks.Callback , передайте ее методу модели fit :
callbacks = [ # Остановить обучение если `val_loss` перестанет улучшаться в течение 2 эпох tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), # Записать логи TensorBoard в каталог `./logs` directory tf.keras.callbacks.TensorBoard(log_dir='./logs') ] model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks, validation_data=(val_data, val_labels))Сохранение и восстановление
Сохранение только значений весов
Сохраните и загрузите веса модели с помощью tf.keras.Model.save_weights :
model = tf.keras.Sequential([ layers.Dense(64, activation='relu', input_shape=(32,)), layers.Dense(10, activation='softmax')]) model.compile(optimizer=tf.keras.optimizers.Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])# Сохраним веса в файл TensorFlow Checkpoint model.save_weights('./weights/my_model') # Восстановим состояние модели # для этого необходима модель с такой же архитектурой. model.load_weights('./weights/my_model')По умолчанию веса модели сохраняются в формате TensorFlow checkpoint. Веса могут быть также сохранены в формате Keras HDF5 (значение по умолчанию для универсальной реализации Keras):
# Сохранение весов в файл HDF5 model.save_weights('my_model.h5', save_format='h5') # Восстановление состояния модели model.load_weights('my_model.h5')Сохранение только конфигурации модели
Конфигурация модели может быть сохранена — это сериализует архитектуру модели без всяких весов. Сохраненная конфигурация может восстановить и инициализировать ту же модель, даже без кода определяющего исходную модель. Keras поддерживает форматы сериализации JSON и YAML:
# Сериализация модели в формат JSON json_string = model.to_json() json_stringimport json import pprint pprint.pprint(json.loads(json_string))Восстановление модели (заново инициализированной) из JSON:
fresh_model = tf.keras.models.model_from_json(json_string) Сериализация модели в формат YAML требует установки `pyyaml` перед тем как импортировать TensorFlow:
yaml_string = model.to_yaml() print(yaml_string)Восстановление модели из YAML:
fresh_model = tf.keras.models.model_from_yaml(yaml_string)Внимание: сабклассированные модели не сериализуемы, потому что их архитектура определяется кодом Python в теле метода `call`.
Сохранение всей модели в один файл
Вся модель может быть сохранена в файл содержащий значения весов, конфигурацию модели, и даже конфигурацию оптимизатора. Это позволит вам установить контрольную точку модели и продолжить обучение позже с точно того же положения даже без доступа к исходному коду.
# Создадим простую модель model = tf.keras.Sequential([ layers.Dense(10, activation='softmax', input_shape=(32,)), layers.Dense(10, activation='softmax') ]) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(data, labels, batch_size=32, epochs=5) # Сохраним всю модель в файл HDF5 model.save('my_model.h5') # Пересоздадим в точности эту модель включая веса и оптимизатор. model = tf.keras.models.load_model('my_model.h5')Eager execution
Eager execution — это императивное программирование среда которая выполняет операции немедленно. Это не требуется для Keras, но поддерживается tf.keras и полезно для проверки вашей программы и отладки.
Все строящие модели API `tf.keras` совместимы eager execution. И хотя могут быть использованы `Sequential` и functional API, eager execution особенно полезно при сабклассировании модели и построении пользовательских слоев — эти API требуют от вас написание прямого распространения в виде кода (вместо API которые создают модели путем сборки существующих слоев).
Распределение
Множественные GPU
tf.keras модели можно запускать на множестве GPU с использованием tf.distribute.Strategy . Этот API обеспечивает распределенное обучение на нескольких GPU практически без изменений в существующем коде.
На данный момент, tf.distribute.MirroredStrategy единственная поддерживаемая стратегия распределения. MirroredStrategy выполняет репликацию в графах с
синхронным обучением используя all-reduce на одной машине. Для использования ` distribute.Strategy `, вложите инсталляцию оптимизатора, конструкцию и компиляцию модели в ` Strategy ` ` .scope() `, затем обучите модель.
Следующий пример распределяет tf.keras.Model между множеством GPU на одной машине.
Сперва определим модель внутри области распределенной стратегии:
strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = tf.keras.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10,))) model.add(layers.Dense(1, activation='sigmoid')) optimizer = tf.keras.optimizers.SGD(0.2) model.compile(loss='binary_crossentropy', optimizer=optimizer) model.summary()Затем обучим модель на данных как обычно:
x = np.random.random((1024, 10)) y = np.random.randint(2, size=(1024, 1)) x = tf.cast(x, tf.float32) dataset = tf.data.Dataset.from_tensor_slices((x, y)) dataset = dataset.shuffle(buffer_size=1024).batch(32) model.fit(dataset, epochs=1)После проверки перевод появится также на сайте Tensorflow.org. Если вы хотите поучаствовать в переводе документации сайта Tensorflow.org на русский, обращайтесь в личку или комментарии. Любые исправления и замечания приветствуются.
- keras
- tensorflow
- машинное обучение
- глубокое обучение
- Python
- Big Data
- Машинное обучение
- Искусственный интеллект
- TensorFlow