Что нужно знать об устройстве коллекций, основанных на хешировании
Всем привет. На связи Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.
Помимо преподавания, как вы могли заметить, я занимаюсь написанием авторского материала для блога OTUS на хабре и сегодняшнюю статью хочу посвятить запуску нового потока курса «Алгоритмы для разработчиков».

Введение
Хеш-таблицы (HashMap) наравне с динамическими массивами являются самыми популярными структурами данных, применяемыми в production’е. Очень часто можно услышать вопросы на собеседованиях касаемо их предназначения, особенностей их внутреннего устройства, а также связанных с ними алгоритмов. Данная структура данных является классической и встречается не только в Java, но и во многих других языках программирования.
Постановка задачи
Давайте зададимся целью создать структуру данных, которая позволяет:
- contains(Element element) проверять, находится в ней некоторый элемент или нет, за О(1)
- add(Element element) добавлять элемент за О(1)
- delete(Element element) удалять элемент за О(1)
Массив
Попробуем сделать эти операции поверх массива, который является самой простой структурой данных. Договоримся, что будем считать ячейку пустой, если в ней содержится null.
Проверка наличия
Необходимо сделать линейный поиск по массиву, ведь элемент потенциально может находиться в любой ячейке. Асимптотически это можно осуществить за O(n), где n — размер массива.
Добавление
Если нам надо добавить элемент абы куда, то вначале мы должны найти пустую ячейку, а затем записать в нее элемент. Таким образом, мы опять осуществим линейный поиск и получим асимптотику O(n).
Удаление
Чтобы удалить элемент, его нужно сначала найти, а затем в найденную ячейку записать null. Опять линейный поиск приводит нас к O(n).
Простейшее хеш-множество
Обратите внимание, что при каждой операции, мы сначала искали индекс нужной ячейки, а затем осуществляли операцию, и именно поиск портит нам асимптотику! Если бы мы научились получать данный индекс за O(1), то исходная задача была бы решена.
Давайте теперь заменим линейный поиск на следующий алгоритм: будем вычислять значение некоторой фунции — хеш-функции, ставящей в соответствие объекту класса некоторое целое число. После этого будем сопоставлять полученное целое число индексу ячейки массива (это достаточно легко сделать, например, взяв остаток от деления этого числа на размер массива). Если хеш-функция написана так, что она считается за O(1) (а она так обычно и написана), то мы получили самую простейшую реализацию хеш-множества. Ячейка массива в терминах хеш-множества может называться bucket‘ом.
Проблемы простейшей реализации хеш-множества
Как бы ни была написана хеш-функция, число ячеек массива всегда ограничено, тогда как множество элементов, которые мы хотим хранить в структуре данных, неограничено. Ведь мы бы не стали заморачиваться со структурой данных, если бы была потребность в сохранении всего лишь десяти заранее известных элементов, верно? Такое положение дел приводит к неизбежным коллизиям. Под коллизией понимается ситуация, когда при добавлении разных объектов мы попадаем в одну и ту же ячейку массива.
Для разрешения коллизий придумано 2 метода: метод цепочек и метод открытой адресации.
Метод цепочек
Метод цепочек является наиболее простым методом разрешения коллизий. В ячейке массива мы будем хранить не элементы, а связанный список данных элементов. Потому как добавление в начало списка (а нам все равно в какую часть списка добавлять элемент) обладает асимптотикой О(1), мы не испортим общую асимптотику, и она останется равной О(1).
У данной реализации есть проблема: если списки будут очень сильно вырастать (в качестве крайнего случая можно рассмотреть хеш-функцию, которая возвращает константу для любого объекта), то мы получим асимптотику O(m), где m — число элементов во множестве, если размер массива фиксирован. Для избежания таких неприятностей вводится понятие коэффициент заполнения (он может быть равен, например, 1.5). Если при добавлении элемента оказывается, что доля числа элементов, находящихся в структуре данных по отношению к размеру массива, превосходит коэффициент заполнения, то происходит следующее: выделяется новый массив, размер которого превосходит размер старого массива (например в 2 раза), и структура данных перестраивается на новом массиве.
Данный метод разрешения коллизий и применяется в Java, а структура данных называется HashSet.
Метод открытой адресации
В данном методе в ячейках хранятся сами элементы, а в случае коллизии происходит последовательность проб, то есть мы начинаем по некоторому алгоритму перебирать ячейки в надежде найти свободную. Это можно делать разными алгоритмами (линейная / квадратичная последовательности проб, двойное хеширование), каждый из которых обладает своими проблемами (например, возникновение первичных или вторичных кластеров).
От хеш-множества к хеш-таблице (HashMap)
Давайте создадим структуру данных, которая позволяет так же быстро, как и хеш-множество (то есть за O(1)), добавлять, удалять, искать элементы, но уже по некоторому ключу.
Воспользуемся той же структурой данных, что у хеш-множества, но хранить будем не элементы, а пары элементов.
Таким образом, вставка (put(Key key, Value value)) будет осуществляться так: мы посчитаем ячейку массива по объекту типа Key, получим номер bucket’а. Пройдемся по списку в bucket’е, сравнивая ключ с ключом в хранимых парах. Если нашли такой же ключ — просто вытесняем старое значение, если не нашли — добавляем пару.
Как осуществляется получение элемента по ключу? Да по похожему принципу: получаем bucket по ключу, проходимся по парам и возвращаем значение в паре, ключ в которой равен ключу в запросе, если такая пара есть, и null в противном случае.
Данная структура данных и называется хеш-таблицей.
Типичные вопросы на собеседовании
Q: Как устроены HashSet и HashMap? Как осуществляются основные операциии в данных коллекциях? Как применяются методы equals() и hashCode()?
A: Ответы на данные вопросы можно найти выше.
Q: Каков контракт на equals() и hashCode()? Чем он обусловлен?
A: Если объекты равны, то у них должны быть равны hashCode. Таким образом, hashCode должен определяться по подможноству полей, учавствующих в equals. Нарушение данного контракта может приводить к весьма интересным эффектам. Если объекты равны, но hashCode у них разный, то вы можете не достать значение, соответствующее ключу, по которому вы только что добавили объект в HashSet или в HashMap.
Вывод
На собеседованиях очень любят задавать различные кейсы, связанные с этими структурами данных. При этом решение любого из них может быть выведено из понимания принципов их работы без всякой «зубрежки».
На этом все. Если вы дочитали материал до конца, приглашаю на бесплатный урок по теме «Секреты динамического программирования» в рамках урока мой коллега — Евгений Волосатов покажет как решить олимпиадную задачу используя идеи динамического программирования.
- Блог компании OTUS
- Программирование
- Java
- Алгоритмы
- Промышленное программирование
Почему возникают коллизии?
Как известно, ситуация, когда у разных объектов одинаковые хеш-коды называется — коллизией. Вероятность возникновения коллизии зависит от используемого алгоритма генерации хеш-кода. Но вот вопрос, почему она возникает? Неужели тяжко придумать «защиту» от возникновения коллизии? Кто что думает?
Отслеживать
задан 30 окт 2017 в 22:06
432 2 2 золотых знака 6 6 серебряных знаков 15 15 бронзовых знаков
Результат хеш-функции может быть короче ее аргумента. Коллизий избежать невозможно.
– user239133
30 окт 2017 в 22:11
Вообще, есть perfect hash function (идеальная хэш-функция)
31 окт 2017 в 0:33
Вероятность возникновения коллизии зависит от используемого алгоритма генерации хеш-кода. Нет. Если алгоритмы хэширования не содержат статистических, математических и прочих погрешностей, вероятность коллизии зависит только от длины формируемого хэша.
31 окт 2017 в 5:01
Неужели тяжко придумать «защиту» от возникновения коллизии? Да элементарно. Просто длина хэша должна быть не меньше максимальной длины хэшируемых данных (с учётом пэддинга).
31 окт 2017 в 5:02
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Хеш код в java создается методом
public int hashCode()
У integer диапазон от -2147483648 до 2147483647, т.е. округлив получаем 4 миллиарда разных целых чисел.
А теперь представим ситуацию, у вас 8-10 миллиардов объектов. Вопрос: как каждому из них дать уникальный хеш код используя диапазон в 4 миллиарда?
При этом вы не знаете сколько объектов вашего класса могут создать пользователи.
Если ваш класс будет использоваться в Hash структурах как ключ, вы так же должны постараться обеспечить объекты такими хеш кодами, чтобы они попадали в разные корзины и получить равномерное заполнение структуры.
КОЛЛИЗИИ И ПРОБЕЛЫ В ПРАВЕ КАК ПРОБЛЕМЫ ПРАВОПРИМЕНЕНИЯ Текст научной статьи по специальности «Право»
CONFLITIONS AND GAPS IN THE LAW AS LAW ENFORCEMENT PROBLEMS
The paper examines conflicts and gaps in the law as problems of law enforcement. The main causes of these problems are analyzed, and ways to solve them are identified
Текст научной работы на тему «КОЛЛИЗИИ И ПРОБЕЛЫ В ПРАВЕ КАК ПРОБЛЕМЫ ПРАВОПРИМЕНЕНИЯ»
магистрант юридического факультета Казанский (Приволжский) федеральный университет (г. Казань, Россия)
КОЛЛИЗИИ И ПРОБЕЛЫ В ПРАВЕ КАК ПРОБЛЕМЫ ПРАВОПРИМЕНЕНИЯ
Аннотация: в работе рассмотрены коллизии и пробелы в праве как проблемы правоприменения. Проанализированы основные причины возникновения этих проблем, а также выявлены пути их решения.
Ключевые слова: право, правоприменение, коллизии, проблемы в праве, закон.
Право, как главный регулятор общественных отношений, имеет целью организовать и стабилизировать жизнь в обществе и государстве. Единство применения права во многом зависит от совершенства законодательства [1]. В свою очередь, эффективность применения права напрямую влияет на выполнение прав и свобод граждан и организаций.
Следует отметить, что современные исследователи рассматривают юридическую коллизию как часть конфликтологии. Конфликтология является относительно новым направлением в науке, возникшим после распада СССР. Она изучает проблему возникновения конфликтов и противоречий в обществе.
Противоречия, возникающие в области правового регулирования, относятся к социальным противоречиям. При анализе следует учитывать место права среди других сфер общественной жизни. Нормы права имеют преимущество перед другими социальными регуляторами, такими как мораль, традиции и религиозные нормы, поскольку их выполнение обеспечивается силой государства. Они происходят от государственных органов, избранных
населением, которые должны реализовывать интересы большинства общества в соответствии с принципами представительной демократии. Кроме того, через институт права обеспечивается осуществление прав и свобод человека и гражданина, а также создаются условия для укрепления законности и правопорядка.
При изучении проблемы противоречий в праве, А.Ю. Буяков указывает на два аспекта: объективный, выражающийся в отражении противоречий общественной жизни в правовых нормах, и собственные противоречия права, не связанные с жизнью в обществе [3, С. 102].
В связи с этим можно выделить два вида противоречий в праве: материальное и формальное. Материальное противоречие возникает между действующими отношениями в обществе и правовыми нормами, установленными государством. Формальное противоречие подразумевает противоречия между самими правовыми предписаниями. Причем, последнее противоречие непосредственно связано с первым и является его следствием.
Когда говорят о юридической коллизии, это относится к противоречиям второго вида. Однако понятия «противоречие в сфере правового регулирования» и «юридическая коллизия» не являются одинаковыми.
Большинство коллизий возникает из-за игнорирования законодателем правил юридической техники. Среди наиболее распространенных причин можно выделить следующие. Нередко законодатель детально объясняет определенные термины в законодательных актах, в то время как такое объяснение не является необходимым. Важность терминологии в законодательстве не подлежит сомнению, однако необходима мера в данном вопросе. Различные законодательные акты содержат совершенно разные интерпретации одного и того же правового термина, или же данные интерпретации не совпадают друг с другом.
Такое нарушение объясняется тем, что законодатель не обращает должного внимания на уже существующие нормы, регулирующие общественные
отношения, и, как результат, не проводит оценку согласованности новых и действующих норм. Избежать подобных ошибок поможет одновременное внесение изменений или отмена соответствующих положений в действующих актах. Касательно сферы, регулируемой законами, она весьма обширна.
Данные нарушения тесно связаны с проблемой экономии правовых ресурсов в процессе законотворчества. Иногда достаточно внести изменения в уже существующие законы для урегулирования определенных отношений, вместо принятия отдельного закона. Это позволит избежать законодательных «заминок». Ошибка заключается в техническом аспекте законодательной техники и приводит к тому, что норма превращается в обыкновенные слова.
Избежать ошибок невозможно, однако ошибки в законотворчестве имеют особое значение. Они приводят к снижению эффективности правового регулирования и проблемам в практическом применении соответствующих правовых норм. Качественная работа над текстом закона со стороны разработчиков и различных экспертов является залогом снижения ошибок. В случае обнаружения ошибок в процессе правоприменения необходимо создать условия для быстрого информирования законодателя о мнениях практикующих специалистов и результатов правоприменительной практики.
В тексте закона содержится множество ссылок на нормативные акты, которые уже не действуют на момент его принятия. Причины таких нарушений можно объяснить следующим образом.
Одной из основных причин является недостаточно высокий уровень правовой подготовки законодателей. Из-за этого они не всегда грамотно и рационально используют свое право на законодательную инициативу. Иногда законопроекты разрабатываются неквалифицированными лицами, которые пытаются заменить юридическую терминологию новыми определениями и понятиями [4, С. 117].
Вину за это частично можно возложить на авторов действующей Конституции РФ [2], которые исключили Генерального прокурора Российской
Федерации и Уполномоченного по правам человека из числа субъектов, обладающих правом на законодательную инициативу.
Таким образом, пробелы в праве представляют собой сложное явление, которое требует внимания и изучения в научном мире. Представленные подходы свидетельствуют о теоретической незавершенности дискуссии по данному вопросу.
1. Ахметжанова К.В. Причины возникновения и способы преодоления коллизий в праве с позиции позитивистского правопонимания (легистский и социологический подходы) // Вестник РУДН. Серия: Юридические науки. 2014. №3. URL: https://cyberlemnka.ru/article/n/prichmy-vozniknoveniya-isposobypreodolenpya-kolHziy-v-prave-s-pozitsii-
pozitivistskogopravoponimaniyalegistskiy-i (дата обращения: 02.06.2023).
2. Конституция Российской Федерации: принята всенародным голосованием 12 декабря 1993 г.; в ред. от 04 июля 2020 г. // Собрание законодательства РФ. 2014. № 31.
3. Сабанина, Н. О. К вопросу о проблемах правоприменения при пробелах и коллизиях в праве / Н. О. Сабанина, Н. В. Кузнецова, Н. Н. Панов // Наука и образование: сохраняя прошлое, создаём будущее : монография. — Пенза : «Наука и Просвещение» (ИП Гуляев Г.Ю.), 2020. — С. 100-110.
4. Нешатаева Т.Н. Единообразное правоприменение — цель Суда Евразийского экономического союза / Т.Н. Нешатаева // Международное правосудие. — 2015. — № 2. — С. 115-125.
Kazan Federal University (Kazan, Russia)
CONFLITIONS AND GAPS IN THE LAW AS LAW ENFORCEMENT PROBLEMS
Abstract: the paper examines conflicts and gaps in the law as problems of law enforcement. The main causes of these problems are analyzed, and ways to solve them are identified.
Keywords: law, law enforcement, conflicts, problems in law.
Разрешение коллизий
Разрешение коллизий (англ. collision resolution) в хеш-таблице, задача, решаемая несколькими способами: метод цепочек, открытая адресация и т.д. Очень важно сводить количество коллизий к минимуму, так как это увеличивает время работы с хеш-таблицами.
Разрешение коллизий с помощью цепочек
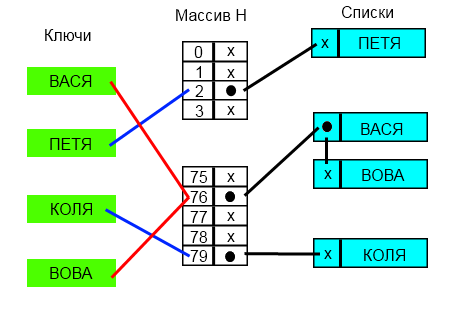
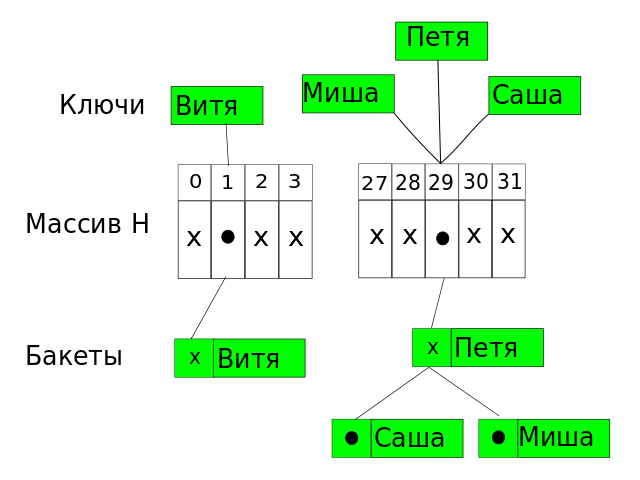
Разрешение коллизий при помощи цепочек.
Каждая ячейка [math]i[/math] массива [math]H[/math] содержит указатель на начало списка всех элементов, хеш-код которых равен [math]i[/math] , либо указывает на их отсутствие. Коллизии приводят к тому, что появляются списки размером больше одного элемента.
В зависимости от того нужна ли нам уникальность значений операции вставки у нас будет работать за разное время. Если не важна, то мы используем список, время вставки в который будет в худшем случае равна [math]O(1)[/math] . Иначе мы проверяем есть ли в списке данный элемент, а потом в случае его отсутствия мы его добавляем. В таком случае вставка элемента в худшем случае будет выполнена за [math]O(n)[/math]
Время работы поиска в наихудшем случае пропорционально длине списка, а если все [math]n[/math] ключей захешировались в одну и ту же ячейку (создав список длиной [math]n[/math] ) время поиска будет равно [math]\Theta(n)[/math] плюс время вычисления хеш-функции, что ничуть не лучше, чем использование связного списка для хранения всех [math]n[/math] элементов.
Удаления элемента может быть выполнено за [math]O(1)[/math] , как и вставка, при использовании двухсвязного списка.
Линейное разрешение коллизий
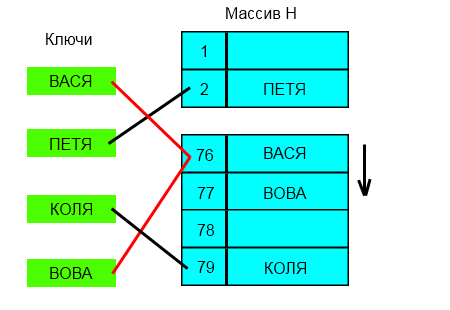
Пример хеш-таблицы с открытой адресацией и линейным пробированием.
Все элементы хранятся непосредственно в хеш-таблице, без использования связных списков. В отличие от хеширования с цепочками, при использовании этого метода может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, следовательно, будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Стратегии поиска
Последовательный поиск
При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+1, i+2, i+3[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент.

Линейный поиск
Выбираем шаг [math]q[/math] . При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+(1 \cdot q), i+(2 \cdot q), i+(3 \cdot q)[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент. По сути последовательный поиск — частный случай линейного, где [math]q=1[/math] .
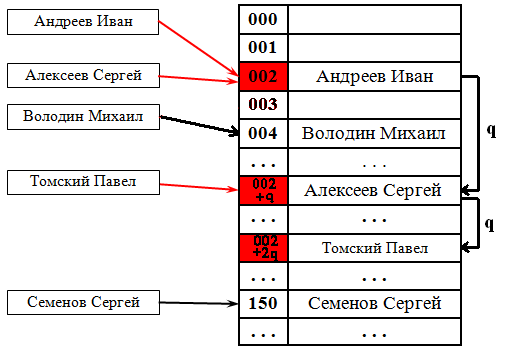
Квадратичный поиск
Шаг [math]q[/math] не фиксирован, а изменяется квадратично: [math]q = 1,4,9,16. [/math] . Соответственно при попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math] i+1, i+4, i+9[/math] и так далее, пока не найдём свободную ячейку.
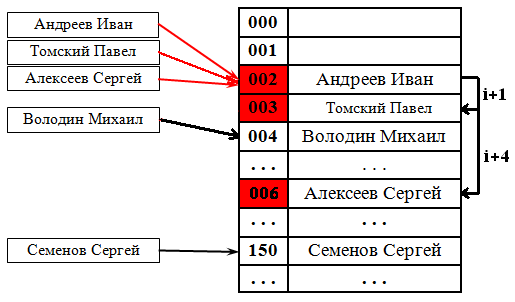
Проверка наличия элемента в таблице
Проверка осуществляется аналогично добавлению: мы проверяем ячейку [math]i[/math] и другие, в соответствии с выбранной стратегией, пока не найдём искомый элемент или свободную ячейку.
При поиске элемента может получится так, что мы дойдём до конца таблицы. Обычно поиск продолжается, начиная с другого конца, пока мы не придём в ту ячейку, откуда начинался поиск.
Проблемы данных стратегий
Проблем две — крайне нетривиальное удаление элемента из таблицы и образование кластеров — последовательностей занятых ячеек.
Кластеризация замедляет все операции с хеш-таблицей: при добавлении требуется перебирать всё больше элементов, при проверке тоже. Чем больше в таблице элементов, тем больше в ней кластеры и тем выше вероятность того, что добавляемый элемент попадёт в кластер. Для защиты от кластеризации используется двойное хеширование и хеширование кукушки.
Удаление элемента без пометок
Рассуждение будет описывать случай с линейным поиском хеша. Будем при удалении элемента сдвигать всё последующие на [math]q[/math] позиций назад. При этом:
- если в цепочке встречается элемент с другим хешем, то он должен остаться на своём месте (такая ситуация может возникнуть если оставшаяся часть цепочки была добавлена позже этого элемента)
- в цепочке не должно оставаться «дырок», тогда любой элемент с данным хешем будет доступен из начала цепи
Учитывая это будем действовать следующим образом: при поиске следующего элемента цепочки будем пропускать все ячейки с другим значением хеша, первый найденный элемент копировать в текущую ячейку, и затем рекурсивно его удалять. Если такой следующей ячейки нет, то текущий элемент можно просто удалить, сторонние цепочки при этом не разрушатся (чего нельзя сказать про случай квадратичного поиска).
function delete(Item i): j = i + q while table[j] == null or table[j].key != table[i].key if table[j] == null table[i] = null return j += q table[i] = table[j] delete(j)
Хеш-таблицу считаем зацикленной
Асимптотически время работы [math]\mathrm
Вариант с зацикливанием мы не рассматриваем, поскольку если [math]q[/math] взаимнопросто с размером хеш-таблицы, то для зацикливания в ней вообще не должно быть свободных позиций
Теперь докажем почему этот алгоритм работает. Собственно нам требуется сохранение трёх условий.
- В редактируемой цепи не остаётся дырок
Докажем по индукции. Если на данной итерации мы просто удаляем элемент (база), то после него ничего нет, всё верно. Если же нет, то вызванный в конце [math]\mathrm[/math] (см. псевдокод) заметёт созданную дыру (скопированный элемент), и сам, по предположению, новых не создаст.
- Элементы, которые уже на своих местах, не должны быть сдвинуты.
- В других цепочках не появятся дыры
Противное возможно только в том случае, если какой-то элемент был действительно удалён. Удаляем мы только последнюю ячейку в цепи, и если бы на её месте возникла дыра для сторонней цепочки, это бы означало что элемент, стоящий на [math]q[/math] позиций назад, одновременно принадлежал нашей и другой цепочкам, что невозможно.
Двойное хеширование
Двойное хеширование (англ. double hashing) — метод борьбы с коллизиями, возникающими при открытой адресации, основанный на использовании двух хеш-функций для построения различных последовательностей исследования хеш-таблицы.
Принцип двойного хеширования
При двойном хешировании используются две независимые хеш-функции [math] h_1(k) [/math] и [math] h_2(k) [/math] . Пусть [math] k [/math] — это наш ключ, [math] m [/math] — размер нашей таблицы, [math]n \bmod m [/math] — остаток от деления [math] n [/math] на [math] m [/math] , тогда сначала исследуется ячейка с адресом [math] h_1(k) [/math] , если она уже занята, то рассматривается [math] (h_1(k) + h_2(k)) \bmod m [/math] , затем [math] (h_1(k) + 2 \cdot h_2(k)) \bmod m [/math] и так далее. В общем случае идёт проверка последовательности ячеек [math] (h_1(k) + i \cdot h_2(k)) \bmod m [/math] где [math] i = (0, 1, \; . \;, m — 1) [/math]
Таким образом, операции вставки, удаления и поиска в лучшем случае выполняются за [math]O(1)[/math] , в худшем — за [math]O(m)[/math] , что не отличается от обычного линейного разрешения коллизий. Однако в среднем, при грамотном выборе хеш-функций, двойное хеширование будет выдавать лучшие результаты, за счёт того, что вероятность совпадения значений сразу двух независимых хеш-функций ниже, чем одной.
[math]\forall x \neq y \; \exists h_1,h_2 : p(h_1(x)=h_1(y))\gt p((h_1(x)=h_1(y)) \land (h_2(x)=h_2(y)))[/math]
Выбор хеш-функций
[math] h_1 [/math] может быть обычной хеш-функцией. Однако чтобы последовательность исследования могла охватить всю таблицу, [math] h_2 [/math] должна возвращать значения:
- не равные [math] 0 [/math]
- независимые от [math] h_1 [/math]
- взаимно простые с величиной хеш-таблицы
Есть два удобных способа это сделать. Первый состоит в том, что в качестве размера таблицы используется простое число, а [math] h_2 [/math] возвращает натуральные числа, меньшие [math] m [/math] . Второй — размер таблицы является степенью двойки, а [math] h_2 [/math] возвращает нечетные значения.
Например, если размер таблицы равен [math] m [/math] , то в качестве [math] h_2 [/math] можно использовать функцию вида [math] h_2(k) = k \bmod (m-1) + 1 [/math]
Вставка при двойном хешировании
Пример
Показана хеш-таблица размером 13 ячеек, в которой используются вспомогательные функции:
[math] h(k,i) = (h_1(k) + i \cdot h_2(k)) \bmod 13 [/math]
[math] h_1(k) = k \bmod 13 [/math]
[math] h_2(k) = 1 + k \bmod 11 [/math]
Мы хотим вставить ключ 14. Изначально [math] i = 0 [/math] . Тогда [math] h(14,0) = (h_1(14) + 0\cdot h_2(14)) \bmod 13 = 1 [/math] . Но ячейка с индексом 1 занята, поэтому увеличиваем [math] i [/math] на 1 и пересчитываем значение хеш-функции. Делаем так, пока не дойдем до пустой ячейки. При [math] i = 2 [/math] получаем [math] h(14,2) = (h_1(14) + 2\cdot h_2(14)) \bmod 13 = 9 [/math] . Ячейка с номером 9 свободна, значит записываем туда наш ключ.
Таким образом, основная особенность двойного хеширования состоит в том, что при различных [math] k [/math] пара [math] (h_1(k),h_2(k)) [/math] дает различные последовательности ячеек для исследования.
Простая реализация
Пусть у нас есть некоторый объект [math] item [/math] , в котором определено поле [math] key [/math] , от которого можно вычислить хеш-функции [math] h_1(key)[/math] и [math] h_2(key) [/math]
Так же у нас есть таблица [math] table [/math] величиной [math] m [/math] , состоящая из объектов типа [math] item [/math] .
function add(Item item): x = h1(item.key) y = h2(item.key) for (i = 0..m) if table[x] == null table[x] = item return x = (x + y) mod m table.resize()// ошибка, требуется увеличить размер таблицы
Item search(Item key): x = h1(key) y = h2(key) for (i = 0..m) if table[x] != null if table[x].key == key return table[x] else return null x = (x + y) mod m return null
Реализация с удалением
Чтобы наша хеш-таблица поддерживала удаление, требуется добавить массив [math]deleted[/math] типов [math]bool[/math] , равный по величине массиву [math]table[/math] . Теперь при удалении мы просто будем помечать наш объект как удалённый, а при добавлении как не удалённый и замещать новым добавляемым объектом. При поиске, помимо равенства ключей, мы смотрим, удалён ли элемент, если да, то идём дальше.
function add(Item item): x = h1(item.key) y = h2(item.key) for (i = 0..m) if table[x] == null or deleted[x] table[x] = item deleted[x] = false return x = (x + y) mod m table.resize()// ошибка, требуется увеличить размер таблицы
Item search(Item key): x = h1(key) y = h2(key) for (i = 0..m) if table[x] != null if table[x].key == key and !deleted[x] return table[x] else return null x = (x + y) mod m return null
function remove(Item key): x = h1(key) y = h2(key) for (i = 0..m) if table[x] != null if table[x].key == key deleted[x] = true else return x = (x + y) mod m
Альтернативная реализация метода цепочек
В Java 8 для разрешения коллизий используется модифицированный метод цепочек. Суть его заключается в том, что когда количество элементов в корзине превышает определенное значение, данная корзина переходит от использования связного списка к использованию сбалансированного дерева. Но данный метод имеет смысл лишь тогда, когда на элементах хеш-таблицы задан линейный порядок. То есть при использовании данныx типа [math]\mathbf[/math] или [math]\mathbf[/math] имеет смысл переходить к дереву поиска, а при использовании каких-нибудь ссылок на объекты не имеет, так как они не реализуют нужный интерфейс. Такой подход позволяет улучшить производительность с [math]O(n)[/math] до [math]O(\log(n))[/math] . Данный способ используется в таких коллекциях как HashMap, LinkedHashMap и ConcurrentHashMap.
См. также
- Хеширование
- Хеширование кукушки
- Идеальное хеширование
Источники информации
- Бакнелл Дж. М. «Фундаментальные алгоритмы и структуры данных в Delphi», 2003
- Кормен, Томас Х., Лейзерсон, Чарльз И., Ривест, Рональд Л., Штайн Клиффорд «Алгоритмы: построение и анализ», 2-е издание. Пер. с англ. — М.:Издательский дом «Вильямс», 2010.— Парал. тит. англ. — ISBN 978-5-8459-0857-5 (рус.)
- Дональд Кнут. «Искусство программирования, том 3. Сортировка и поиск» — «Вильямс», 2007 г.— ISBN 0-201-89685-0
- Седжвик Р. «Фундаментальные алгоритмы на C. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск», 2003
- Handle Frequent HashMap Collisions with Balanced Trees
- Wikipedia — Double_hashing
- Разрешение коллизий
- Пример хеш таблицы
- Пример хеш таблицы с двойным хешированием