Что такое Apache Kafka: как устроен и работает брокер сообщений
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют это ПО.

Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют «Кафку».
Что такое брокер сообщений
Главная задача брокера — обеспечение связи и обмена информацией между приложениями или отдельными модулями в режиме реального времени.
Брокер — система, преобразующая сообщение от источника данных (продюсера) в сообщение принимающей стороны (консьюмера). Брокер выступает проводником и состоит из серверов, объединенных в кластеры.
Apache Kafka — диспетчер сообщений, разработанный LinkedIn. В 2011 году был опубликован программный код. В 2012 году Kafka попал в инкубатор Apache, дальнейшая разработка ведется в рамках Apache Software Foundation. Открытое программное обеспечение с разрешительной лицензией написано на Java и Scala.
Изначально «Кафку» создавали как систему, оптимизированную под запись, и создатель Джей Крепс выбрал такое название в честь одного из своих любимых писателей.
Шаги передачи данных
Чтобы понять, как функционирует распределенная система Apache Kafka, необходимо проследить путь данных.
Событие или сообщение — данные, которые поступают из одного сервиса, хранятся на узлах Kafka и читаются другими сервисами. Сообщение состоит из:
- Key — опциональный ключ, нужен для распределения сообщений по кластеру.
- Value — массив байт, бизнес-данные.
- Timestamp — текущее системное время, устанавливается отправителем или кластером во время обработки.
- Headers — пользовательские атрибуты key-value, которые прикрепляют к сообщению.
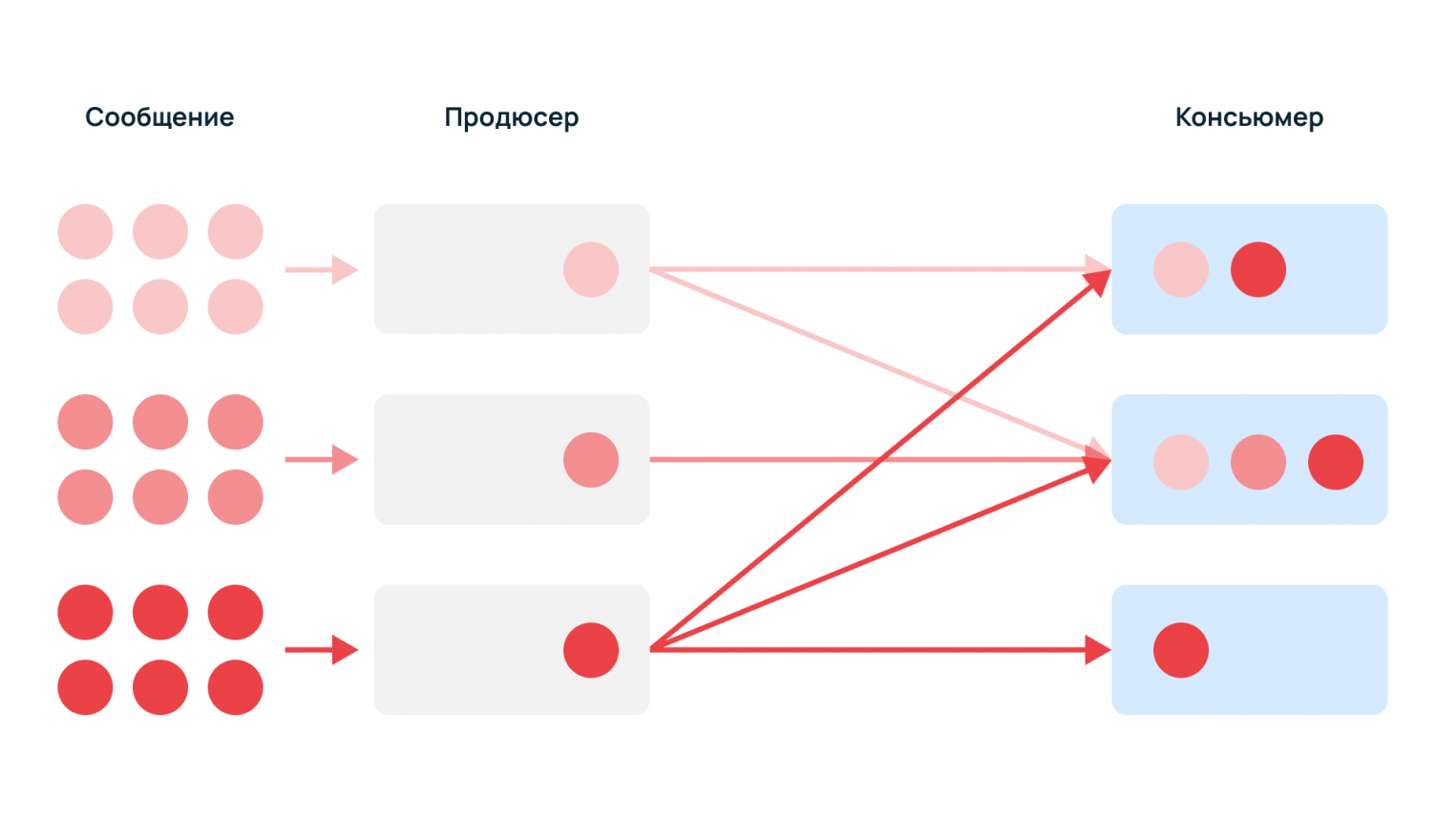
Продюсер — поставщик данных, который генерирует сообщения — например, служебные события, логи, метрики, события мониторинга.
Консьюмер — потребитель данных, который читает и использует события, пример — сервис сбора статистики.
Какие сложности решает распределенная система
Сообщения могут быть однотипными или разнородными, поскольку разным потребителям нужны разные данные. Один тип событий может быть нужен всем консьюмерам, а другие — только одному.
Без брокера продюсеры должны знать получателя и резервного консьюмера, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых консьюмеров. С помощью брокера продюсеры просто отправляют информацию в единый узел.
Managed service для Apache Kafka
Сообщения хранятся на узлах-брокерах. Kafka — масштабируемый кластер со множеством взаимозаменяемых серверов, в которые добавляются новые брокеры, распределяющие задачи между собой.
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
Topic — принцип деления потока данных, базовая и основная сущность Apache Kafka. В топик складывается стрим данных, единая очередь из входящих сообщений.
Partition — для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
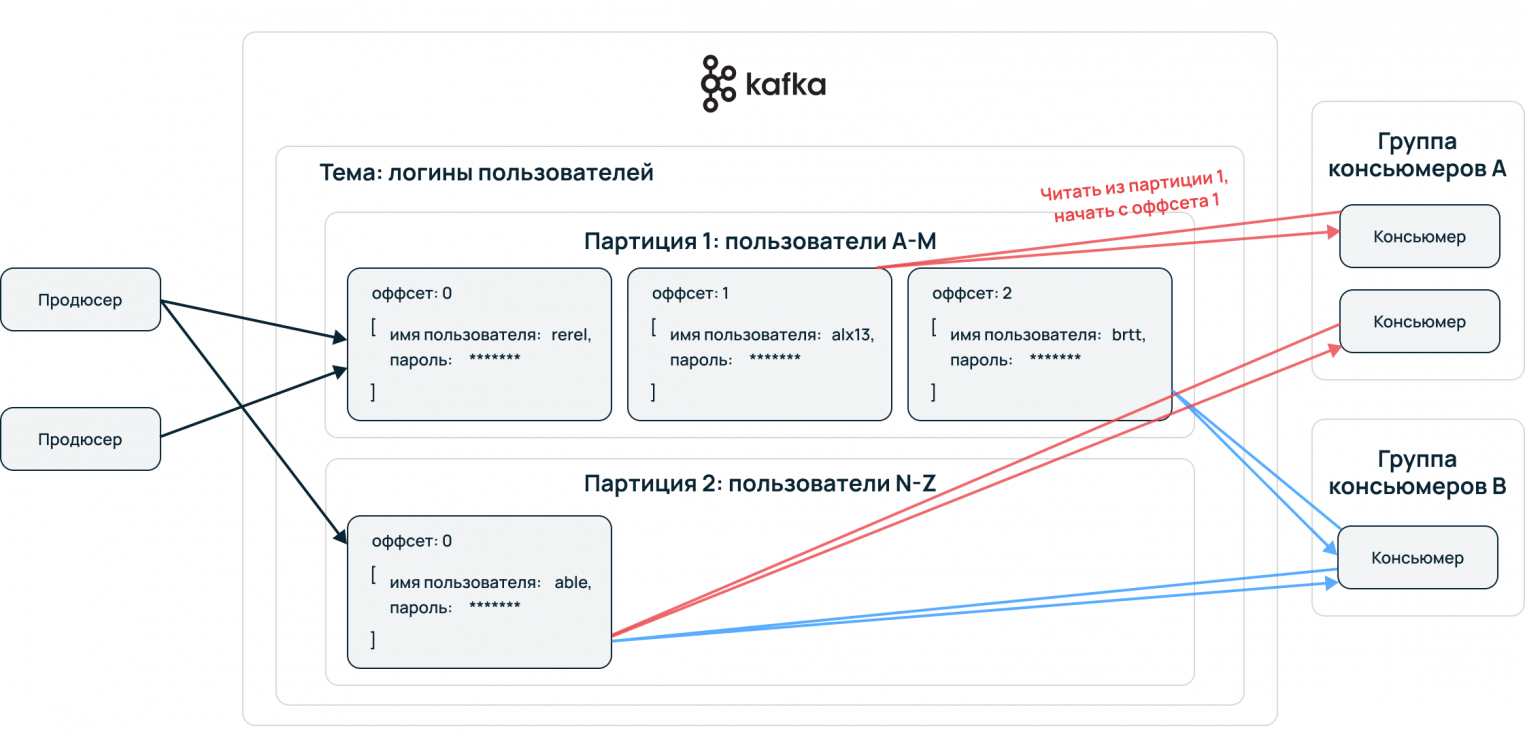
Упорядочение событий происходит на уровне партиций. Принимающая сторона потребляет данные в порядке расположения в партиции. Пример: все события одного пользователя сервисы принимают упорядоченно, обработка сохраняет последовательность пути пользователя. Выстраивается конвейер данных, алгоритмы машинного обучения могут извлекать из сырой информации необходимую для бизнеса информацию.
Преимущества Apache Kafka
Брокер распределяет информацию в широковещательном режиме. Применяющийся в Apache Kafka подход нужен для масштабирования и репликации данных.
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Офсеты
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Взаимодействие через API
Брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: продюсерам и консьюмерам необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Где применяется Apache Kafka
Отказоустойчивая система используется в бизнесе, где необходимо собирать, хранить и обрабатывать большие неструктурированные данные. Примеры — платформы, где требуется интеграция данных из большого количества источников, сервисы стриминговой аналитики, mission-critical applications.
Big Data
Первоначально LinkedIn разработали «Кафку» для своих целей: обмена данными между службами, репликации баз данных, потоковой передачи информации о деятельности и операционных показателях приложений.
Для IBM Apache Kafka работает как средство обмена сообщениями между микросервисами. В аналитических системах американской корпорации Apache Kafka обрабатывает потоковые и событийные данные.
Uber, Twitter, Netflix и AirBnb с помощью хорошо развитых пайплайнов обработки данных передают миллиарды сообщений в день. «Кафка» решает проблемы перемещения Big data из одного источника в другой.
Издание The New York Times использует Apache Kafka для хранения и распространения опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей в режиме реального времени.
Internet of Things
IoT-платформы используют архитектуру с большим количеством конечных устройств: контроллеров, датчиков, сенсоров и smart-гаджетов. ПО интернета вещей с помощью алгоритмов ML составляет графики профилактического ремонта оборудования, анализируя данные, поступающие с устройств.
ML-системы работают с онлайн-потоками, когда приборы, приложения и пользователи постоянно посылают данные, а сервисы обрабатывают их в реальном времени. Apache Kafka выступает центральным звеном в этом процессе.
Отрасли
Kafka используют организации практически в любой отрасли: разработка ПО, финансовые услуги, здравоохранение, государственное управление, транспорт, телеком, геймдев.
Сегодня Kafka пользуются тысячи компаний, более 60% входят в список Fortune 100. На официальном сайте представлен полный список корпораций и учреждений, которые используют брокера Apache.
Конкуренты
Чаще всего Kafka сравнивают с RabbitMQ. Обе системы — брокеры сообщений. Главное отличие в модели доставки: Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика; брокер RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
«Кролик» удаляет событие после доставки, «Кафка» хранит до запланированной очистки журнала. Таким образом, брокер Apache используется как источник истории изменений.
Разработчики RabbitMQ создали системы управления потоком сообщений: мониторинг получения, маршрутизация и шаблоны доставки. Подобное гибкое управление подойдет для высокоскоростного обмена сообщениями между несколькими сервисами. Минус такого подхода в снижении производительности при высокой нагрузке.
Главный вывод — для сбора и агрегации событий из большого количества источников, логов и метрик больше подойдет Apache Kafka.
Заключение
Благодаря высокой пропускной способности и согласованности данных Apache Kafka обрабатывает огромные массивы данных в реальном времени. Системы горизонтального масштабирования и офсеты гарантируют надежность. Kafka — удачное решение для проекта с очень большими нагрузками на обработку данных. Установить это ПО можно на серверы Ubuntu, Windows, CentOS и других популярных операционных систем.
Видео: основы Apache Kafka
Короткое видео, которое объясняет основы Apache Kafka и некоторые нюансы его использования.
Основная задача, которую выполняет Apache Kafka, — это передача данных из системы источника в целевую систему. При такой схеме всё просто. Но что если у вас 4 source-системы и 6 target-систем?
В таком случае вам придётся реализовать 24 интеграции. Каждая интеграция требует протокола взаимодействия, формата данных и валидации по схеме. Также нам необходимо выполнить нефункциональные требования, такие как:
- надёжность и гарантия доставки;
- подключение новых получателей (target систем);
- интеграция разных стеков.
Такая задача уже не кажется простой.
Почему стоит использовать Apache Kafka
Apache Kafka — это распределённое, отказоустойчивое решение с гибкой архитектурой. Скейлится до 100 брокеров и миллиона запросов в секунду, по опыту удавалось выжать 550-600 тысяч сообщений в секунду, до миллиона не доходил. Есть возможность обрабатывать данные с задержкой менее чем 10 ms, то есть в реальном времени.
Apache Kafka создали в компании LinkedIn. С 2012 года это Open Source проект в составе Apache Foundation. Kafka написан на Scala и Java, а своё название получил в честь писателя Франца Кафки.
Для чего можно использовать Kafka:
- Система обмена сообщений в микросервисной архитектуре.
- Сбор журналов событий, логов и метрик с различного ПО и оборудования.
- Stream processing — возможность потоковой обработки данных хранящихся в Кафке.
- Интеграция с Apache Spark, Storm, Hadoop и другими технологиями, использующимися для Big Data и Machine Learning-решений.
Kafka используют в 2000+ компаниях — то есть это очень распространённое программное обеспечение.
- Netflix применяет для онлайн-рекомендаций, пока вы смотрите кино.
- Uber собирает всю информацию о такси и поездках в реальном времени, также высчитывает маршрут, прогнозирует загруженность и считает цену поездки.
- LinkedIn использует для спама и сбора данных о действиях пользователей в режиме реального времени.
Во всех этих кейсах Kafka выступает в роли транспорта.
Основные сущности Apache Kafka
Основными сущностями для Apache Kafka являются:
- Broker — часть, отвечающая за приём, передачу и хранение сообщений.
- ZooKeeper — отдельный вспомогательный продукт для хранения состояния кластера, конфигурации и метаданных.
- Message или Record — сами данные.
- Producer — информационная система, которая отправляет данные в Kafka.
- Topic — то, куда попадают данные. Отправляются они в том же порядке что и прилетели (FIFO).
- Consumer — тот, кто получает данные из Kafka.
Record состоит из полей Key — опциональное поле для распределения сообщений по кластеру, Value — массив байт, Timestamp — время сообщения в формате Unix time, Headers — key-value пары с пользовательскими атрибутами.
Topic может быть разделён на партиции для организации высокопроизводительной работы. Партиции могут быть распределены между узлами кластера, но Kafka может это сделать неравномерно.
Например, у вас три топика с тремя партициями. Один топик очень нагруженный, а два — не очень. Kafka может все партиции нагруженного топика распределить на один узел, и он будет очень нагружен. Это решается ручным конфигурированием.
Данные топика или партиции хранятся в log-файлах. Обычно там три файла: .log, .index и .timeindex. Они хранят в себе всю информацию по сообщениям.
В .log хранятся данные, offset, position и timestamp. В index хранится маппинг offset на position, а в timeindex — маппинг timestamp на offset. Максимальный размер .log-файла — 1GB. Когда этот размер превышен, создаются новые три файла log, index и timeindex. Эти три файла называются сегментами.
Особенности Kafka
Kafka не поддерживает ручное удаление данных из топика. Только автоматическая чистка по времени, которая настраивается через параметр Time-To-Live.
Kafka поддерживает репликацию, чтобы при потере узла кластера не потерялись данные. За это отвечает параметр replication-factor, который говорит, сколько копий партиций будет на разных узлах кластера.
Kafka обеспечивает согласованность данных при помощи master-slave кластеризации партиций топика. Например, топик делится на три партиции и одну из них Kafka назначает лидером. Остальные являются фолловерами.
Все операции чтения и записи происходят через лидер-реплику партиции. Поэтому если все лидер-реплики партиций окажутся на одном узле кластера, то этот узел станет самым нагруженным, а остальные будут просто отдыхать. В этом случае надо вручную перебалансировать кластер.
Если лидер-реплика умерла, нужно выбрать нового лидера. В дефолтной конфигурации фолловеры могут не обладать всеми данными. Это плохие кандидаты для лидеров.
Для исключения такой ситуации в Kafka есть механизм insync-реплик. Их количество задаётся в конфигурации. В таком случае при записи данных в лидер-реплику происходит синхронная запись в ISR-реплики-фолловеры. Такие ISR-реплики являются кандидатами на нового лидера. Внимание, это драматично влияет на производительность.
Producer отправляет сообщения только в лидер-реплик партиции. У отправителя есть опции отправки — acks. Она принимает параметры 0, 1 и −1 или all.
- Если acks = 0, значит отправителя не интересует подтверждение доставки и сообщения могут теряться. Этот режим нужен при огромных объемах данных и в специальных случаях.
- Если acks=1, значит отправитель ожидает подтверждения доставки сообщения от лидер-реплики.
- Если acks=all или −1, то отправитель ждёт синхронизации сообщения между всеми ISR-репликами лидер-реплики.
Также producer поддерживает все известные семантики доставки: at most once, at least once, exactly once (idempotence).
Consumer читает пачки сообщений только из лидер-реплики партиции. Их можно объединять в группы, чтобы в несколько потоков читать данные. Это делается при помощи параметра group.id. Consumer должен закоммитить получение данных из Kafka. Есть 2 вида коммитов: автоматические и ручные. Если после получения данных при автокоммите consumer упал, то он не получит эти данные повторно.
Kafka — очень популярна, это проверенное, высокопроизводительное и очень гибкое решение. Но при его использовании нужно понимать нюансы.
Apache Kafka. Пишем простой producer и consumer и тестируем их
В данной статье будет описано, как создать простой kafka producer и kafka consumer, а затем протестировать их.
Данная статья будет полезна начинающим разработчикам, которые еще не работали с технологией Apache Kafka.
Вначале надо разобраться, что такое Apache Kafka и для чего она используется. И тут сразу могут возникнуть первые вопросы, так как первое, что приходит в голову, если идет речь о kafka, то это — распределенная система обмена сообщениями между серверными приложениями в режиме реального времени. Но если «копнуть глубже» и посмотреть на определение kafka на официальном сайте https://kafka.apache.org/ мы увидим.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Исходя из этого определения Apache Kafka — это больше, чем просто система обмена сообщениями, это распределенная платформа потоковой передачи событий, а также потоковой аналитики и интеграции данных.
То есть kafka может использоваться и как база данных, и как распределенное хранилище логов, и как очередь, и как платформа для потоковой обработки данных и т.д.
В данной статье будет рассмотрен пример, как с помощью kafka организовать обмен сообщениями между двумя микросервисами.
Kafka, как и почти все сервисы обработки очередей, условно состоит из трех основных частей:
1) сервер или еще его называют брокер;
2) producer — отправляют сообщения брокеру;
3) consumer — считывают сообщения с брокера, использую модель pull, то есть консьюмеры сами отправляют запросы к брокеру для получения новых сообщений.
Главной отличительной чертой kafka от других систем обработки очередей (например RabbitMQ), является то, что сообщения в kafka могут храниться на брокере днями, неделями или даже годами. Благодаря этому одно и тоже сообщение может быть обработано разными консьюмерами по-разному.
Рассмотрим какая структура сообщения в kafka. Оно состоит из ключа (key), значения (value), таймстампа (timestamp) и набора метаданных (headers).
Сообщения хранятся в топиках (topics). Топики состоят из партиций (partitions). Партиции или их еще называют разделы — это копии очередей наших сообщений. Чтобы повысить надежность и доступность данных в кластере-Kafka, разделы могут иметь копии, число которых задается коэффициентом репликации (replication factor), который показывает, на сколько брокеров-последователей (follower) будут скопированы данные с ведущего-лидера (leader). Таким образом, гарантируется наличие нескольких копий сообщения на разных брокерах. Партиции, в свою очередь, распределены между брокерами внутри одного кластера. Такая сложная, на первый взгляд, система хранения сообщений необходима для отказоустойчивости, масштабирования и повышения производительности работы, так как она позволяет продюсерам писать в несколько брокеров одновременно, а консьюмерам — читать, также из нескольких брокеров.
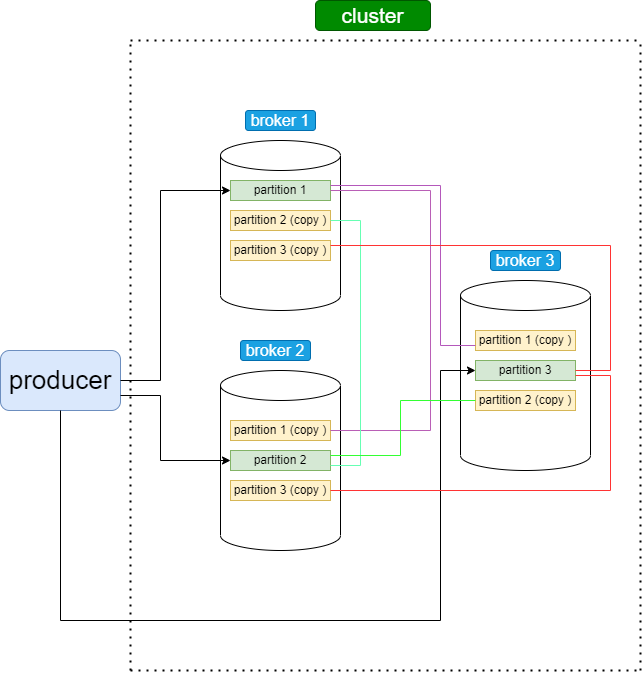
У каждой партиции есть свой «лидер» (leader) — это тот брокер, который работает с продюсером и на него приходит сообщение, а также у каждой партиции имеются несколько «фолловеров» (followers) — это брокеры, которые хранят копии партиций. Перед отправкой сообщения консьюмер обращается к брокеру и запрашивает данные, кто является лидером партиции.
Таким образом, общая схема сохранения сообщения в kafka выглядит следующим образом. Имеется какой-то топик, в который записываются сообщения, и есть несколько партиций (копий очередей наших сообщений), распределенных по брокерам в кластере. Продюсер вначале обращается к брокеру с вопросом, кто является лидером партиции в данном брокере, и после получения данной информации отправляет туда свое сообщение, на втором этапе, фолловеры данной партиции копируют себе отправленное сообщение на свой брокер. Так происходит с каждой партицией.
Время хранения сообщения в kafka регулируется с помощью специальных настроек.
Рассмотрим сейчас как выглядит работа консьюмера в kafka.
Каждый консьюмер должен быть частью какой-нибудь консьюмер группы. Данная группа должна иметь уникальное название и должна быть зарегистрирована в кластере. Как правило, если у нас есть несколько консьюмеров, в одной группе, то они получают сообщения из разных партиций. Желательно, чтобы количество консьюмеров было равно количеству партиций, и каждый консьюмер читал сообщения из своей партиции, таким образом, распределяется нагрузка и повышается производительность работы.
Есть еще один важный вопрос. Если мы захотим добавить консьюмера к топику не сразу, а позже или, например, произойдет сбой консьюмера, а позже он восстановится и вопрос, откуда он будет знать с какого сообщения продолжить работу? Для этого имеется специальный механизм консьюмер-офсетов (offset). Перед началом работы консьюмер делает специальный запрос к брокеру с указанием группы, топика, партиции и офсета, который должен быть помечен как обработанный. Брокер сохраняет эту информацию у себя. При сбое в работе, консьюмер запрашивает у брокера последний закомиченный офсет и продолжает читать с данной позиции сообщения.
Это упрощенное описание работы kafka-продюсера и kafka-консьюмера.
Также при описании kafka нельзя не вспомнить про один важный компонент — zookeeper.
ZooKeeper — это хранилище метаданных kafka, именно он знает в каком состоянии находятся брокеры, какая партиция играет роль лидера, сколько партиций и где они находятся, сколько у каждой партиции реплик и так далее.
Разобравшись немного с теорией приступим к нашему примеру.
Весь код примера будет доступен по ссылке.
Пример будет очень простой. Допустим у нас будет три микросервиса. Один — это продюсер — он будет производить и отправлять сообщения в kafka, в нашем случае это будет Заказ.
@Data @AllArgsConstructor @NoArgsConstructor public class Order
Второй микросервис — консьюмер, который будет читать наше сообщение и записывать его в базу данных.
И третий микросервис — также будет читать наше сообщение и просто выводить его в консоль.
Таким образом, я хочу показать, что можно настроить несколько консьюмеров, которые будут подписаны на один топик и будут получать из него сообщения, но поступать с ними по-разному.
Весь код приводить не буду, буду останавливаться только на главных моментах.
Kafka, zookeeper, kafka-ui (для просмотра сообщений в kafka), database (postgres) и pgadmin (для просмотра данных в базе) поднимем с помощью docker.
Для этого напишем следующий docker-compose.yml файл.
services: zookeeper: image: confluentinc/cp-zookeeper:6.2.4 healthcheck: test: [ "CMD", "nc", "-vz", "localhost", "2181" ] interval: 10s timeout: 3s retries: 3 environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 ports: - 22181:2181 kafka: image: confluentinc/cp-kafka:6.2.4 depends_on: zookeeper: condition: service_healthy ports: - 29092:29092 healthcheck: test: [ "CMD", "nc", "-vz", "localhost", "9092" ] interval: 10s timeout: 3s retries: 3 environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_LISTENERS: OUTSIDE://:29092,INTERNAL://:9092 KAFKA_ADVERTISED_LISTENERS: OUTSIDE://localhost:29092,INTERNAL://kafka:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,OUTSIDE:PLAINTEXT KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 kafka-ui: image: provectuslabs/kafka-ui container_name: kafka-ui ports: - "8080:8080" restart: always depends_on: kafka: condition: service_healthy environment: KAFKA_CLUSTERS_0_NAME: local KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092 service-db: image: postgres:14.7-alpine environment: POSTGRES_USER: username POSTGRES_PASSWORD: password healthcheck: test: ["CMD-SHELL", "pg_isready", "-d", "clients_database"] interval: 10s timeout: 3s retries: 3 ports: - "15432:5432" volumes: - ./infrastructure/db/create_db.sql:/docker-entrypoint-initdb.d/create_db.sql restart: unless-stopped pgadmin: container_name: pgadmin4_container image: dpage/pgadmin4:7 restart: always environment: PGADMIN_DEFAULT_EMAIL: admin@admin.com PGADMIN_DEFAULT_PASSWORD: root ports: - "5050:80" kafka-topics-generator: image: confluentinc/cp-kafka:6.2.4 depends_on: kafka: condition: service_healthy entrypoint: [ '/bin/sh', '-c' ] command: | " # blocks until kafka is reachable kafka-topics --bootstrap-server kafka:9092 --list echo -e 'Creating kafka topics' kafka-topics --bootstrap-server kafka:9092 --create --if-not-exists --topic send-order-event --replication-factor 1 --partitions 2 echo -e 'Successfully created the following topics:' kafka-topics --bootstrap-server kafka:9092 --list "Базу данных orders_database, создадим на этапе поднятия контейнера с postgres.
Топик (send-order-event) создадим с помощью команды в отдельном контейнере, здесь же создадим две партиции, так как у нас будет два консьюмера и желательно, чтобы каждый консьюмер читал из своей патриции.
Топики можно также создавать и с помощью кода.
Пройдемся по этапам создания продюсера.
Вначале необходимо сделать некоторые настройки продюсера. Это можно делать с помощью кода или прописывать в application файле. Мы это сделаем с помощью application.yml файла.
server: port: 8081 spring: kafka: bootstrap-servers: localhost:29092 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.springframework.kafka.support.serializer.JsonSerializer properties: acks: 1 spring: json: add: type: headers: false topic: send-order: send-order-eventЗдесь указываем порт, на котором будет работать kafka (должен совпадать с внешним портом, который мы открыли в docker для kafka), также необходимо указать как мы будем сериализовать ключ и значение (значение — это и будет наш заказ, поэтому здесь надо указать JsonSerializer). Также прописываем название нашего топика send-order-event, название должно совпадать с тем, что мы указали при создании топика в docker. Данное название мы потом с помощью аннотации @Value будем сетать в переменную.
Далее создадим сам сервис по отправке сообщений.
@Service @RequiredArgsConstructor public class KafkaMessagingService < @Value("$") private String sendClientTopic; private final KafkaTemplate kafkaTemplate; public void sendOrder(OrderSendEvent orderSendEvent) < kafkaTemplate.send(sendClientTopic, orderSendEvent.getBarCode(), orderSendEvent); >>Внедряем бин private final KafkaTemplate kafkaTemplate в данный класс с помощью аннотации @RequiredArgsConstructor. Также как было сказано раньше сетаем в переменную sendClientTopic название нашего топика с application.yml файла. Далее пишем сам метод по отправке сообщения, который на вход будет принимать OrderSendEvent — то есть наш заказ. Вызываем у kafkaTemplate метод send куда передаем название топика, ключ (в качестве ключа будет выступать код продукта). Ключ нужен для того чтобы сообщения с одинаковыми ключами всегда записываются в одну и ту же партицию. Последним передаем сам заказ.
@Data @AllArgsConstructor @NoArgsConstructor public class OrderSendEvent
Создадим еще класс Producer.
@Slf4j @Component @RequiredArgsConstructor public class Producer < private final KafkaMessagingService kafkaMessagingService; private final ModelMapper modelMapper; public Order sendOrderEvent(Order order) < kafkaMessagingService.sendOrder(modelMapper.map(order, OrderSendEvent.class)); log.info("Send order from producer <>", order); return order; > >Он нужен просто для того чтобы отделить логику отправки от маппинга сущностей.
Отправку сообщения будем производить с помощью postman, поэтому создадим еще контроллер OrderController.
@Slf4j @Validated @RestController @RequiredArgsConstructor @RequestMapping("/api/v1/orders") public class OrderController < private final Producer producer; @PostMapping @ResponseStatus(HttpStatus.OK) public Order sendOrder(@RequestBody Order order) < log.info("Send order to kafka"); producer.sendOrderEvent(order); return order; >>Рассмотрим теперь первый консьюмер.
Вначале также создадим application.yml файл, в котором настроим наш консьюмер.
server: port: 8082 spring: kafka: bootstrap-servers: localhost:29092 consumer: group-id: "order-1" auto-offset-reset: earliest key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer properties: spring: json: trusted: packages: '*' datasource: url: jdbc:postgresql://$:$/orders_database username: username password: password liquibase: enabled: true drop-first: false change-log: classpath:db/changelog/db.changelog-master.xml default-schema: public jpa: show-sql: false open-in-view: false hibernate: ddl-auto: none properties: hibernate: dialect: org.hibernate.dialect.PostgreSQLDialect topic: send-order: send-order-eventЗдесь как и в продюсере указываем порт, на котором работает kafka.
Прописываем group-id: «order-1» — так как консьюмеры должны быть объединены в группы.
Указываем настройку auto-offset-reset: earliest — она нужна для того, если мы добавим новую партицию, когда в топик пишут сообщения продюсеры, без данной настройки, мы можем потерять или не обработать кусок данных, записавшихся в новую партицию до того, как консьюмеры обновили метаданные по топику и начали читать данные из этой партиции.
Как и в продюсере указываем как мы будем уже только десериализовать наши ключ и значение. Также прописываем настройку для того чтобы JsonDeserializer доверял десериализовать только классы в доверенном пакете. То есть тут можно указать конкретный пакет или с помощью «*» — указать, что нужно доверять всем классам во всех пакетах.
Также прописываем название нашего топика send-order-event.
В данном файле также прописываем настройки по подключению к базе данных, накатыванию таблиц с помощью liquibase и чтобы выводились sql запросы к базе данных.
Далее создадим класс OrderEvent. По структуре он должен совпадать с тем классом (OrderSendEvent), который мы отправляем через продюсер.
@Data @AllArgsConstructor @NoArgsConstructor public class OrderEvent
И сам сервис по приемке сообщения.
@Slf4j @Service @AllArgsConstructor public class KafkaMessagingService < private static final String topicCreateOrder = "$"; private static final String kafkaConsumerGroupId = "$"; private final OrderService orderService; private final ModelMapper modelMapper; @Transactional @KafkaListener(topics = topicCreateOrder, groupId = kafkaConsumerGroupId, properties = ) public OrderEvent createOrder(OrderEvent orderEvent) < log.info("Message consumed <>", orderEvent); orderService.save(modelMapper.map(orderEvent, OrderDto.class)); return orderEvent; > >Здесь сетаем переменным topicCreateOrder и kafkaConsumerGroupId с application.yml файла значения названия топика и группы.
Создаем сам метод по обработке сообщений. Вешаем на него аннотацию @KafkaListener куда передаем название топика, который надо слушать, название группы, а также передаем еще настройку по дефолтному типу данных, который мы принимаем. Данную настройку, можно прописать и в application.yml файле, но я хотел показать как можно передавать настройки каждому слушателю, или, например, у вас в группе есть слушатель, который принимает другую сущность.
Далее с полученным сообщением, то есть OrderEvent, можно выполнять различную логику, зависящую от бизнес-требований. В нашем случае мы будем сохранять наш заказ в базу данных.
Рассмотрим еще один консьюмер, он создан в другом микросервисе и его настройки идентичны первому, поэтому только покажу сам метод по приемке сообщений — он будет выводить наш заказ в консоль. Здесь я хочу показать, что на один топик могут быть подписаны несколько консьюмеров и по разному трактовать, что делать с тем сообщением, которое будет появляться в топике.
@Slf4j @Service @AllArgsConstructor public class KafkaMessagingService < private static final String topicCreateOrder = "$"; private static final String kafkaConsumerGroupId = "$"; @Transactional @KafkaListener(topics = topicCreateOrder, groupId = kafkaConsumerGroupId, properties = ) public OrderEvent printOrder(OrderEvent orderEvent) < log.info("The product: <>was ordered in quantity: <> and at a price: <>", orderEvent.getProductName(), orderEvent.getQuantity(), orderEvent.getPrice()); log.info("To pay: <>", new BigDecimal(orderEvent.getQuantity()).multiply(orderEvent.getPrice())); return orderEvent; > >Давайте сейчас посмотрим как все это работает.
Вначале запустим наш docker-compose.yml командой docker-compose up -d в консоли.

Далее необходимо подождать, пока docker стянет необходимые образы с docker hub и на их основе запустит контейнеры.
Идем в docker desktop и мы должны увидеть следующее.

Kafka, zookeeper, kafka-ui, postgres и pgadmin должны быть запущены и работать. Зайдем в kafka-topics-generator и убедимся, что топик создался.

Далее запускаем все наши три микросервиса.
Идем в postman и отправляем json с заказом на адрес http://localhost:8081/api/v1/orders, так как мы запустили наш продюсер на порту 8081.

В логах продюсера мы должны увидеть, что сообщение отправилось.

Теперь зайдем на http://localhost:8080/ здесь мы должны увидеть в Topics наш топик.

Также в Messages мы должны увидеть наше отправленное сообщение.


И в Consumers мы можем увидеть, что у нас есть два консьюмера.

Также проверим сохранился ли наш заказ, это должен был сделать наш первый консьюмер.

В логах мы видим, что сообщение обработано.
Идем на http://localhost:5050 заходим используя креды указанные в docker-compose.yml.
Далее настраиваем подключение.


Делаем select * from orders и должны увидеть сохраненный заказ.

Теперь еще проверим как сработал наш второй консьюмер. Смотрим логи и видим, что наш второй консьюмер также отработал и вывел в консоль наш заказ.

Еще посмотрим как можно протестировать продюсер и консьюмер.
Вначале обратимся к продюсеру. Его мы протестируем с помощью EmbeddedKafka, он будет работать быстрее, чем использовать KafkaContainer, но для тестов консьюмера мы попробуем использовать KafkaContainer.
@SpringBootTest @DirtiesContext @EmbeddedKafka(partitions = 1, brokerProperties = < "listeners=PLAINTEXT://localhost:9092", "port=9092" >) public class KafkaMessageProducerServiceIT < public static final String TOPIC_NAME_SEND_CLIENT = "send-order-event"; @Autowired private KafkaMessagingService kafkaMessagingService; @Test public void it_should_send_order_event() < OrderSendEvent order = FakeOrder.getOrderSendEvent(); kafkaMessagingService.sendOrder(order); Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class); properties.put(JsonDeserializer.TRUSTED_PACKAGES, "*"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group-java-test"); properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); properties.put(JsonDeserializer.VALUE_DEFAULT_TYPE, OrderSendEvent.class); KafkaConsumerconsumer = new KafkaConsumer<>(properties); consumer.subscribe(Arrays.asList(TOPIC_NAME_SEND_CLIENT)); ConsumerRecords records = consumer.poll(Duration.ofMillis(10000L)); consumer.close(); //then assertEquals(1, records.count()); assertEquals(order.getProductName(), records.iterator().next().value().getProductName()); assertEquals(order.getBarCode(), records.iterator().next().value().getBarCode()); assertEquals(order.getQuantity(), records.iterator().next().value().getQuantity()); assertEquals(order.getPrice(), records.iterator().next().value().getPrice()); > >Суть данного теста проста, мы внедряем наш реальный сервис по отправке сообщений KafkaMessagingService и вызываем метод sendOrder(), куда передаем тестовое сообщение. После создаем консьюмера, подключаемся к нашему топику, читаем оттуда сообщение и проверяем совпадает ли оно с отправленным.

Как видим тест прошел успешно.
Протестируем наш консьюмер, который сохраняет заказ в базу данных.
@Testcontainers @SpringBootTest class KafkaMessagingServiceIT < public static final Long ORDER_ID = 1L; public static final String TOPIC_NAME_SEND_ORDER= "send-order-event"; @Container static PostgreSQLContainerpostgreSQLContainer = new PostgreSQLContainer<>("postgres:12") .withUsername("username") .withPassword("password") .withExposedPorts(5432) .withReuse(true); @Container static final KafkaContainer kafkaContainer = new KafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:6.2.4")) .withEmbeddedZookeeper() .withEnv("KAFKA_LISTENERS", "PLAINTEXT://0.0.0.0:9093 ,BROKER://0.0.0.0:9092") .withEnv("KAFKA_LISTENER_SECURITY_PROTOCOL_MAP", "BROKER:PLAINTEXT,PLAINTEXT:PLAINTEXT") .withEnv("KAFKA_INTER_BROKER_LISTENER_NAME", "BROKER") .withEnv("KAFKA_BROKER_ID", "1") .withEnv("KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR", "1") .withEnv("KAFKA_OFFSETS_TOPIC_NUM_PARTITIONS", "1") .withEnv("KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR", "1") .withEnv("KAFKA_TRANSACTION_STATE_LOG_MIN_ISR", "1") .withEnv("KAFKA_LOG_FLUSH_INTERVAL_MESSAGES", Long.MAX_VALUE + "") .withEnv("KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS", "0"); static < Startables.deepStart(Stream.of(postgreSQLContainer, kafkaContainer)).join(); >@DynamicPropertySource static void overrideProperties(DynamicPropertyRegistry registry) < registry.add("spring.kafka.bootstrap-servers", kafkaContainer::getBootstrapServers); registry.add("spring.datasource.url", postgreSQLContainer::getJdbcUrl); registry.add("spring.datasource.username", postgreSQLContainer::getUsername); registry.add("spring.datasource.password", postgreSQLContainer::getPassword); registry.add("spring.datasource.driver-class-name", postgreSQLContainer::getDriverClassName); >@Autowired private OrdersRepository ordersRepository; @Test void save_order() throws InterruptedException < //given String bootstrapServers = kafkaContainer.getBootstrapServers(); OrderEvent orderEvent = FakeOrder.getOrderEvent(); Order order = FakeOrder.getOrder(); MapconfigProps = new HashMap<>(); configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); ProducerFactory producerFactory = new DefaultKafkaProducerFactory<>(configProps); KafkaTemplate kafkaTemplate = new KafkaTemplate<>(producerFactory); //when SECONDS.sleep(5); kafkaTemplate.send(TOPIC_NAME_SEND_ORDER, orderEvent.getBarCode(), orderEvent); SECONDS.sleep(5); //then Order orderFromDB = ordersRepository.findById(ORDER_ID).get(); assertEquals(orderFromDB.getId(), ORDER_ID); assertEquals(orderFromDB.getProductName(), order.getProductName()); assertEquals(orderFromDB.getBarCode(), order.getBarCode()); assertEquals(orderFromDB.getQuantity(), order.getQuantity()); assertEquals(orderFromDB.getPrice(), order.getPrice().setScale(2, RoundingMode.HALF_DOWN)); assertEquals(orderFromDB.getAmount(), order.getAmount().setScale(2)); assertEquals(orderFromDB.getOrderDate().getYear(), order.getOrderDate().getYear()); assertEquals(orderFromDB.getStatus(), order.getStatus()); > >Так как это интеграционный тест, то мы будем использовать KafkaContainer и PostgreSQLContainer, и проверим, что наше сообщение прочиталось и сохранилось в базу данных.
То есть вначале настраиваем контейнеры с kafka и postgreSQL.
Далее внедряем OrdersRepository, чтобы потом получить оттуда данные.
И сам тест тоже довольно прост. Вначале мы создаем продюсера и отправляем в наш топик сообщение с заказом. Далее с помощью ordersRepository обращаемся к базе данных, оттуда получаем наш сохраненный заказ, который должен был сам сохраниться и проверяем правильный ли он.
Данный тест будет выполняться довольно долго, так как надо еще поднять контейнеры с kafka и postgreSQL.


Как видим наш тест прошел успешно.
Спасибо. Всем кто дочитал до конца.
Что такое Apache Kafka?

Apache Kafka – это распределенное хранилище данных, оптимизированное для приема и обработки потоковых данных в режиме реального времени. Потоковые данные – это данные, непрерывно генерируемые тысячами источников данных, которые, как правило, передают записи данных одновременно. Потоковая платформа должна справляться с таким постоянным притоком данных и обрабатывать их последовательно и поэтапно.
Kafka выполняет три основные функции:
- публикует потоки записей и подписывается на них;
- эффективно хранит потоки в том порядке, в котором они были созданы;
- обрабатывает потоки в реальном времени.
Kafka в основном используется для создания конвейеров потоковых данных в реальном времени и приложений, адаптированных к этим потокам. Система позволяет обмениваться сообщениями, обрабатывать потоки, а также хранить и анализировать как данные за прошедшие периоды, так и те, что поступают в реальном времени.
Для чего используется Kafka?
Решение Kafka используется для построения конвейеров потоковых данных и приложений потоковой передачи данных в реальном времени. Конвейер данных надежно обрабатывает и перемещает данные из одной системы в другую, а потоковое приложение использует их потоки. Например, с помощью Kafka можно создать конвейер данных, который собирает информацию о том, как люди используют ваш веб-сайт в режиме реального времени. Kafka принимает и хранит потоковые данные, а также выполняет операции чтения для приложений, работающих с конвейером данных. Также Kafka можно использовать в качестве брокера сообщений – платформы, которая обрабатывает и обеспечивает связь между двумя приложениями.
Как работает Kafka?
Kafka сочетает две модели обмена сообщениями: организацию очередей и шаблон «издатель – подписчик». Это позволяет извлечь преимущества из обеих и предоставить их потребителям. Организация очередей позволяет распределять обработку данных между множеством инстансов потребителей, что обеспечивает высокую масштабируемость. Однако традиционные очереди рассчитаны только на одного подписчика. Шаблон «издатель – подписчик» рассчитан на нескольких подписчиков, но поскольку все сообщения отправляются каждому из них, его нельзя использовать для распределения работы между несколькими рабочими процессами. В Kafka используется модель журнала с разделами для объединения этих двух решений. Журнал – это упорядоченная последовательность записей, разбитая на сегменты, или разделы, для разных подписчиков. Это означает, что на одну и ту же тему может быть подписано несколько человек, и каждому из них назначается раздел, что обеспечивает более высокую масштабируемость. Наконец, Kafka обеспечивает воспроизводимость, что позволяет нескольким отдельным приложениям, считывающим данные из потоков, работать независимо друг от друга со своей скоростью.