Documentation


If your cluster is configured for plaintext security (typically in test environments only) you do not need to configure any additional security attributes. You can just click on Test to test that your connection is working properly or Add to add the server connection without testing it first.
SASL
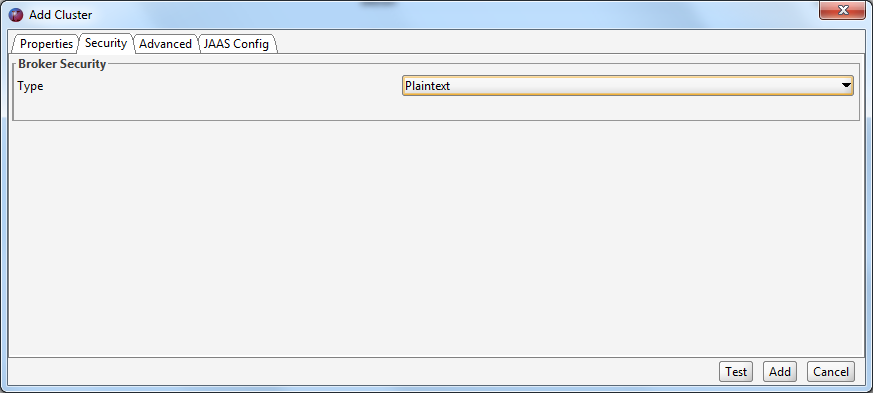
If your cluster is configured for SASL (plaintext or SSL) you must either specify the JAAS config in the UI or pass in your JAAS config file to Offset Explorer when you start it. The exact contents of the JAAS file depend on the configuration of your cluster, please refer to the Kafka documentation.
- offsetexplorer.exe -J-Djava.security.auth.login.config=c:/client_jaas.conf
- offsetexplorer -J-Djava.security.auth.login.config=/client_jaas.conf
- /Applications/Offset Explorer.app/Contents/java/app
If you do not pass the JAAS config file at the startup of Offset Explorer, you must specify it under the JAAS Config tab for each connection.
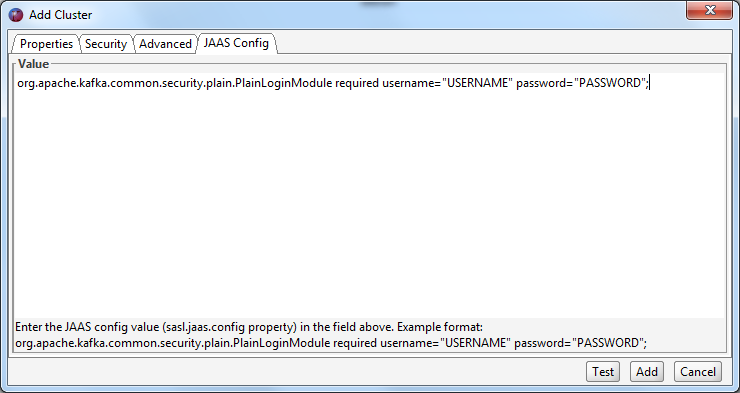
If you are using SASL Plaintext you typically must change the sasl.mechanism client property to PLAIN. This property can be entered in the ‘SASL Mechanism’ text field under the ‘Advanced’ section.
SSL
If your Kafka cluster is configured to use SSL you may need to set various SSL configuration parameters. Unless your Kafka brokers are using a server certificate issued by a public CA, you need to point to a local truststore that contains the self signed root certificate that signed your brokers certificate. You also need to enter the password for this truststore.
If the SAN(s) in your server certificate do not match the actual hostname of the brokers you are connecting to, you will receive an SSL error (No subject alternative DNS name matching xxx found) when you try to connect. You can avoid this by unchecking the ‘Validate SSL endpoint hostname’ checkbox in the ‘Broker security’ section. This will set the ssl.endpoint.identification.algorithm client property to null.
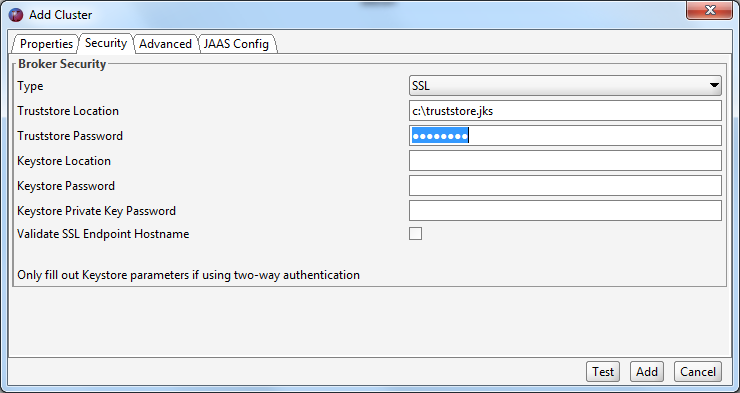
If your Kafka cluster requires a client certificate (two-way authentication) you also need to configure your keystore attributes. The keystore contains the private key that you use to authenticate to your Kafka brokers. You also need to configure a password for the keystore as well as password for the private key in the keystore.
Azure Event Hubs
In order to connect Offset Explorer to an Azure Event Hub, you must first make sure that «Kafka Surfaces» is enabled. This can be confirmed by navigating to the Event Hubs namespace page and seeing if it is enabled.

Once this has been confirmed, navigate to the «Shared access policies» menu item in the Event Hubs namespace. You can either use the RootManageSharedAccessKey, or make your own policy. Once you have chosen the policy, click on it and copy the connection string–primary key value.
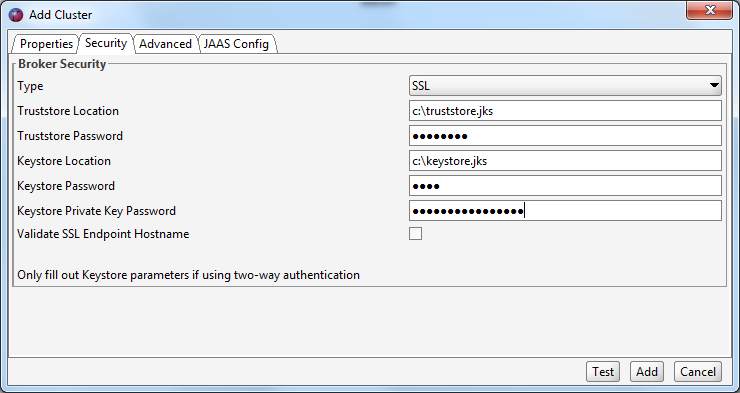
Once the link has been copied, you can open Offset Explorer and add a new connection. In the properties tab, choose a name and version for the cluster. Note that Azure Event Hubs do not support access to Zookeeper so you must leave the Zookeeper host field empty.
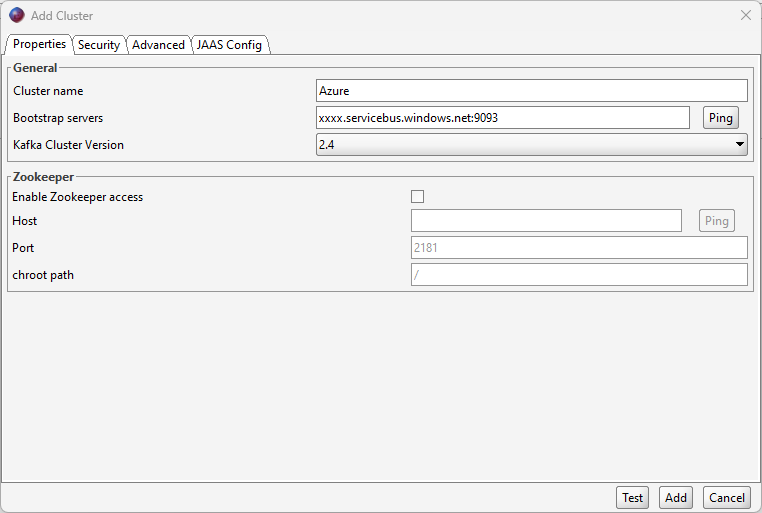
In the security tab, change the security type from plaintext to SASL SSL.
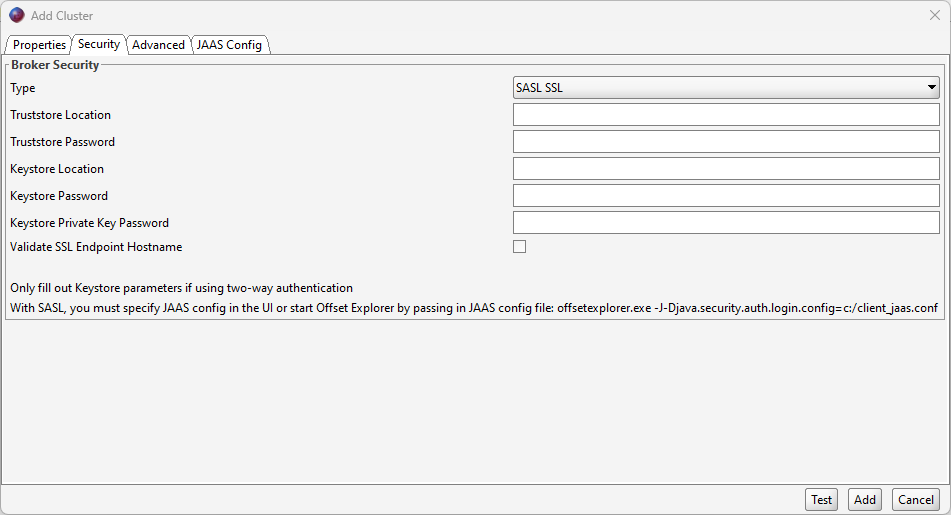
In the advanced tab, make sure to use port number 9093, as it differs from the standard port for Kafka (9092). You will also need to insert PLAIN into the SASL mechanism field.
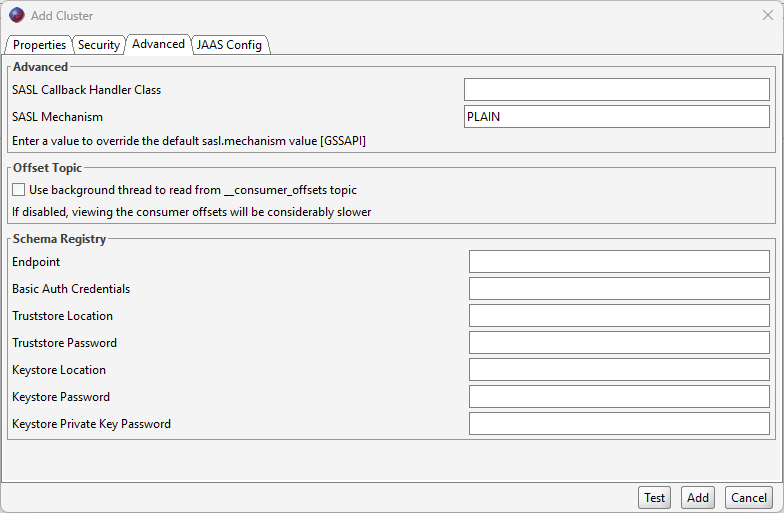
For the JAAS Config tab, you will need to enter the following information (note that the password is equal to the connection string–primary key link that you copied earlier):
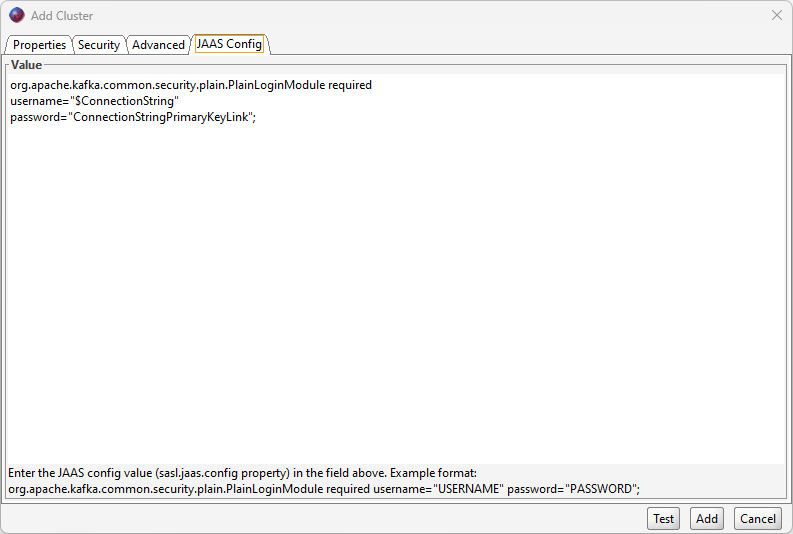
Once all this information has been entered, you can click «Add» to add the connection.
Amazon MSK
The easiest method to connect to your Amazon MSK cluster is to configure your MSK security settings to allow SASL/SCRAM authentication. In order to connect Offset Explorer to your Amazon MSK environment using SASL/SCRAM authentication, you will need to add the following settings when creating your cluster in Offset Explorer:
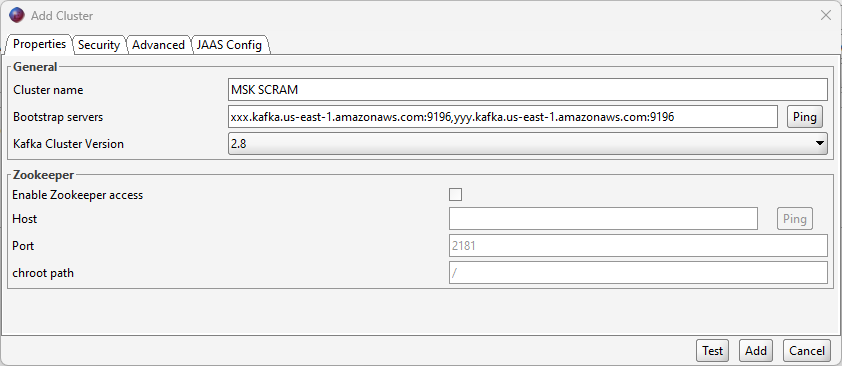
Properties tab: Confirm that zookeeper host is left blank. Pick the version number that matches your Amazon MSK cluster.
Security tab: Confirm that the broker security type is SASL SSL.
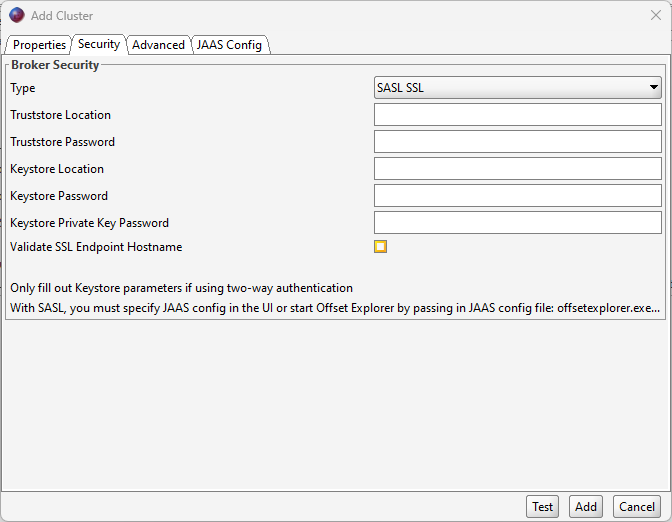
Advanced tab: Confirm the bootstrap servers input is correctly given. Also, enter the following into the SASL Mechanism box: SCRAM-SHA-512

JAAS Config tab: Copy the following, switching out «myuser» for correct username and «mypassword» for correct password. These credentials are stored in the AWS Secrets Manager secret that is associated with your MSK SASL/SCRAM authentication.
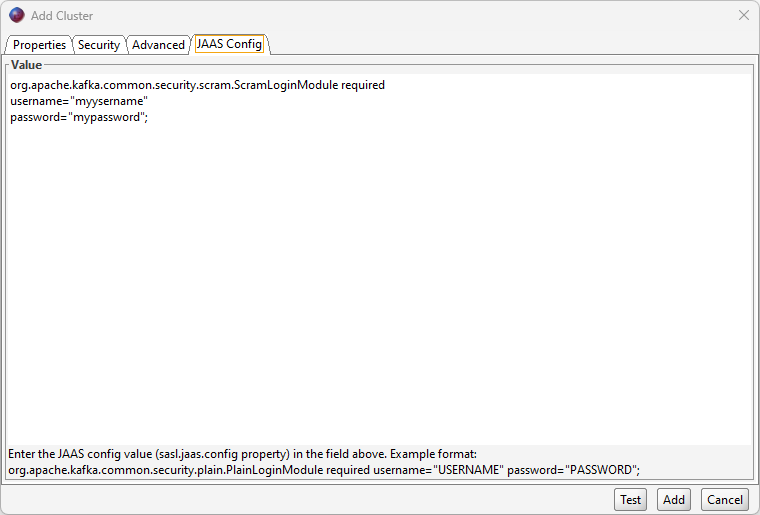
Once these settings for the cluster have been given, you can add the server connection by clicking «Add» and connect.
Confluent Cloud
In order to connect Offset Explorer to a Confluent Cloud environment, you will need to add the following settings when creating your cluster in Offset Explorer:
Properties tab: Confirm that zookeeper host is left blank.
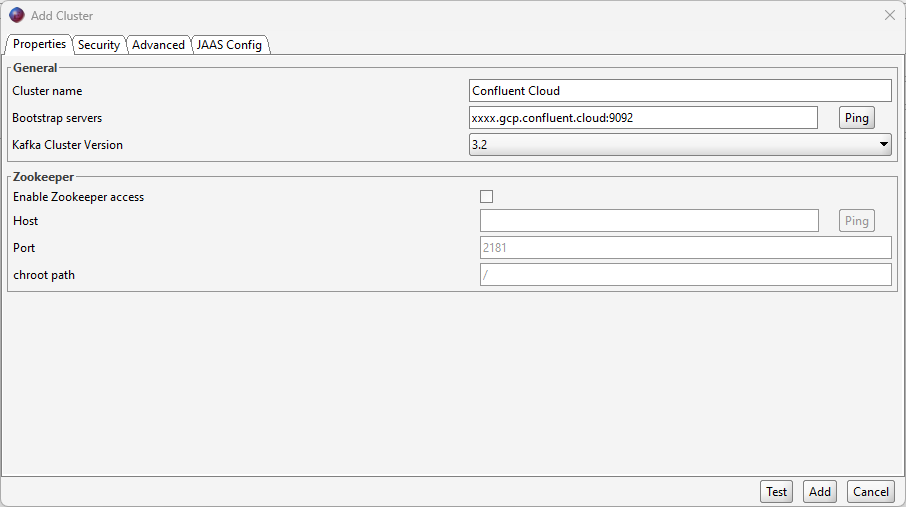
Security tab: Confirm that the broker security type is SASL SSL.
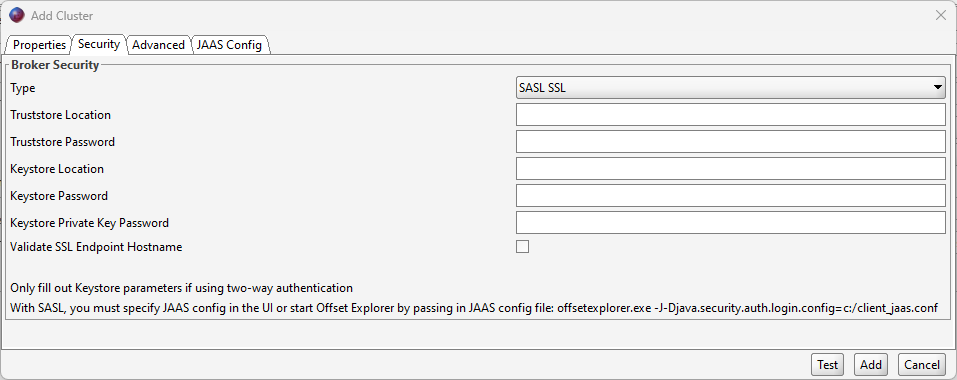
Advanced tab: Confirm the bootstrap servers input is correctly given. Also, enter the following into the SASL Mechanism box: PLAIN
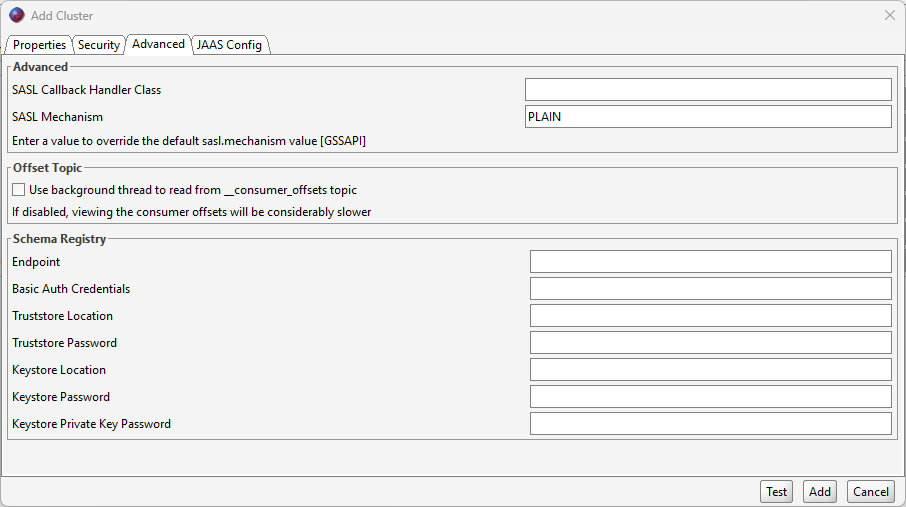
JAAS Config tab: Copy the following, switching out «myapikey» and «myapisecret» for correct values.
Once these settings for the cluster have been given, you can add the cluster by clicking «Add» and connect.
Offset Explorer | UI Tool for Apache Kafka
© 2015-2023 DB Solo, LLC. All rights reserved.
Поиск в Кафке
Меня зовут Сергей Калинец, я — архитектор в компании Parimatch Tech, и в этой публикации хочу поделиться нашим опытом в области поиска сообщений в Kafka.
Для нашей компании Kafka является центральной нервной системой, через которую микросервисы обмениваются информацией. От входа до выхода сообщение может пройти через десяток сервисов, которые его фильтруют и трансформируют, перекладывая из одного топика в другой. Этими сервисами владеют разные команды, и очень полезно бывает посмотреть, что же содержится в том или ином сообщении. Особенно интересно это в случаях, когда что-то идет не по плану — важно понять на каком этапе все превратилось в тыкву (ну и кому нужно в тыкву дать, чтобы такого больше не повторялось). С высоты птичьего полета решение простое — нужно взять соответствующие сообщения из кафки и посмотреть что в них не так. Но, как обычно, интересное начинается в деталях.
Начнем с того, что кафка — это не просто брокер сообщений, как многие думают и пользуются ей, но и распределенный лог. Это значит много чего, но нам интересно то, что сообщения не удаляются из топиков после того, как их прочитали получатели, и технически можно в любой момент их прочитать заново и посмотреть, что там внутри. Однако все усложняется тем, что читать из Kafka можно только последовательно. Нужно знать смещение (для упрощения это — порядковый номер в топике), с которого нам нужны сообщения. Также возможно в качестве начальной точки указать время, но потом все равно можно только читать все сообщения по порядку.
Получается, что для того, чтобы найти нужное сообщение, нужно прочитать пачку и найти среди них те, которые интересны. Например, если мы хотим разобраться в проблемах игрока с нужно найти все сообщения, где он упоминается (playerId: 42), выстроить их в цепочку, ну и дальше уже смотреть, на каком этапе все пошло не так.
В отличии от баз данных вроде MySQL или MSSQL, у которых в комплекте поставки сразу есть клиентские приложения с графическим интерфейсом, ванильная Kafka не балует нас такими изысками и предлагает разве что консольные утилиты с довольно узким (на первый взгляд) функционалом.
Но есть и хорошие новости. На рынке есть ряд решений, которые помогают облегчить весь процесс. Сразу отмечу, что «на рынке» тут не в смысле «за деньги» — все рассмотренные ниже инструменты бесплатны.
Я опишу некоторые наиболее часто используемые, а в конце более детально разберем самое, на наш взгляд, близкое к идеальному.
Итак, из чего можно выбирать?
Kafka Tool

(скриншот с официального сайта https://www.kafkatool.com/features.html)
Наверное самый популярный инструмент, которым пользуются люди, привыкшие к GUI инструментам. Позволяет увидеть список топиков, и прочитать отдельные сообщения. Есть возможность фильтровать по содержимому сообщений, указывать с какого смещения читать и сколько сообщений нужно прочитать. Но все же нужно знать примерные смещения интересующих нас сообщений, потому что Kafka Tool ищет только в рамках тех сообщений, которые были прочитаны. Говоря словами Дятлова из сериала Чернобыль (в оригинальной озвучке): «Not great not terrible».
Часто это единственная альтернатива, с которой вынуждены работать люди, волей судьбы столкнувшиеся с кафкой. Но есть и другие средства.
Kafka Console Consumer
Это одна из утилит, входящая в комплект поставки кафки. И она позволяет читать данные из нее. Как и сама Kafka, это JVM приложение, которое для своей работы требует установленной Java. В принципе, это справедливо и для Kafka Tool, но в данном случае можно обойтись без Java — если запускать через docker:

По сути, нужно просто перед самой командой добавить docker run —rm -it taion809/kafka-cli:2.2.0, что на докерском значит «запусти вот такой образ, выведи, то, что он показывает, на мой экран и удали образ, когда он закончит работу». Можно пойти еще дальше и добавить алиас типа

Утилита кажется архаичной и ее консольность может отпугнуть неискушенных адептов графических интерфейсов, но, как и большинство консольных инструментов, при правильном использовании она дает более мощный результат. Как именно — рассмотрим на примере следующего инструмента, тоже консольного.
Kafkacat
Это уже весьма могучая штука, которая позволяет читать и писать из Кафки, а также получать список топиков. Она тоже консольная, но при этом поудобнее в использовании, чем стандартные утилиты вроде kafka-console-consumer (и ее тоже можно запустить из докера).
Вот так можно сохранить 10 сообщений в файле messages (в формате JSON):

Файл можно будет использовать для анализа или чтобы воспроизвести какой-то сценарий.Безусловно, для решения этой задачи можно было бы и использовать родной консьюмер, но kafkacat позволяет выразить это короче.
Или вот пример посложнее (в смысле букв немного больше, но решение проще многих других альтернатив):

Код взят с блога одного из самых топовых популяризаторов Kafka экосистемы — Robin Moffatt. В двух словах — один инстанс kafkacat читает сообщения из топика Kafka, потом сообщения трансформируются в необходимый формат и скармливаются другому инстансу kafkacat, который пишет их в другой топик. Многим такое может показаться вырвиглазным непонятным брейнфаком, однако на самом деле у нас готовое решение, которое можно запустить в докере и оно будет работать. Реализация такого сценария на вот этих ваших дотнетах и джавах потребует больше букв однозначно.
Но это меня уже занесло немного не в ту степь. Статья же про поиск. Так вот, похожим способом можно организовать и поиск сообщений — просто перенаправить вывод в какой-то grep и дело с концом.
Из возможностей для улучшений можно отметить тот факт, что kafkacat поддерживает Avro из коробки, а вот protobuf — нет.
Kafka Connect + ELK
Все вышеперечисленные штуки работают и решают поставленные задачи, однако не всем удобны. При разборе инцидентов нужно именно поискать сообщения в разных топиках по определенному тексту — это может быть определенный идентификатор или имя. Наши QA (а именно они в 90% случаев занимаются подобными расследованиями) наловчились пользоваться Kafka Tool, а некоторые — и консольными утилитами. Но это все меркнет по сравнению с возможностями, которые дает Kibana, UI оболочка вокруг базы данных Elasticsearch. Kibana тоже используется нами QA для анализа логов. И не раз поднимался вопрос «давайте логировать все сообщения, чтобы можно было искать в Kibana». Но оказалось, что есть способ намного проще, чем добавление вызова логера в каждый из наших сервисов, и имя ему — Kafka Connect.
Kafka Connect — это решение для интеграции Kafka с другими системами. В двух словах, оно (или он?) позволяет экспортировать из и импортировать данные в Kafka без написания кода. Все, что нужно — это поднятый кластер Connect и конфиги наших хотелок в формате JSON. Слово «кластер» звучит дорого и сложно, но на самом деле это один или больше инстансов, которые можно поднять где угодно — мы, например, запускаем их там же, где и обычные сервисы — в Kubernetes.
Kafka Connect предоставляет REST API, c помощью которого можно управлять коннекторами, занимающимися перегонкой данных из и в Kafka. Коннекторы задаются конфигурациями, в случае Elasticsearch эта конфигурация может быть вот такой:

Если такой конфиг через HTTP PUT передать на сервер Connect, то, при определенном стечении обстоятельств, создастся коннектор с именем ElasticSinkConnector, который будет в три потока читать данные из топика и писать их в Elastic.
Выглядит всё крайне просто, но самое интересное, конечно же, в деталях. А деталей тут есть )
Большинство проблем связанно с данными. Обычно, как и в нашем случае, нужно работать с форматами данных, разработчики которого явно не думали, что когда-то эти данные будут попадать в Elasticsearch.
Для решения нюансов с данными есть трансформации. Это такие себе функции, которые можно применять к данным и мутировать их, подстраивая под требования получателя. При этом всегда есть возможность использовать любую Kafka клиент технологию для случаев, когда трансформации бессильны. Какие же сценарии мы решали с помощью трансформаций?
В нашем случае есть 4 трансформации. Вначале мы их перечисляем, а потом конфигурим. Трансформации применяются в порядке их перечисления, и это позволяет интересно их комбинировать.

Имена
Вначале добавляем возможность поиска по имени топика — просто дополняем наши сообщения полем с нужной информацией.
Индексы
Elasticsearch работает с индексами, которые имеют свойство забиваться и нервировать девопсов. Нужна поддержка удобной для управления схемой индексирования. В нашем случае мы остановились на индексе на сервис / команду с ежедневной ротацией. Плюс решения — хранение данные из разных топиков в одном индексе с возможностью контролировать его возраст.
Даты
Для того, чтобы в Kibana можно было искать по дате, необходимо задать поле, в котором эта дата содержится. Мы используем дату публикации сообщения в Kafka. Чтобы ее получить, мы вначале вставляем поле с датой сообщения, а потом конвертируем ее в UTC формат. Конвертация была добавлена, чтобы помочь Elasticsearch распознать в этом поле timestamp, однако в нашем случае это не всегда происходило, поэтому мы добавили index template, который явно говорил «в этом поле — дата»:

В результате у нас сообщения практически мгновенно становятся доступными для анализа, и время, потраченное на разбор инцидентов, уменьшается.
Тут, конечно, стоит отметить, что данная инициатива сейчас у нас на этапе внедрения, поэтому нельзя сказать,что все массово ищут все что нужно в Kibana, но мы к этому уверенно идем.
Вообще, Kafka Connect применимо не только для таких задач. Его можно вполне использовать в тех случаях, где нужна интеграция с другими системами, Реально, например, реализовать полнотекстовый поиск в вашем приложении с помощью двух коннекторов. Один будет читать из операционной базы обновления и писать их в Kafka. А второй — читать из Kafka и отсылать в Elasticsearch. Приложение делает поисковый запрос в Elasticsearch, получает id и по нему находит нужные данные в базе.
Заключение
Ну а наша публикация подходит к концу. Очень надеюсь, что вы узнали что-то новое для себя, а иначе — зачем это все? Если что-то не получилось раскрыть, или вы категорически не согласны с чем-то, или может есть более удобные способы решения подобных проблем — напишите про это в комментариях, обсудим )
Что такое Apache Kafka: как устроен и работает брокер сообщений
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют это ПО.

Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют «Кафку».
Что такое брокер сообщений
Главная задача брокера — обеспечение связи и обмена информацией между приложениями или отдельными модулями в режиме реального времени.
Брокер — система, преобразующая сообщение от источника данных (продюсера) в сообщение принимающей стороны (консьюмера). Брокер выступает проводником и состоит из серверов, объединенных в кластеры.
Apache Kafka — диспетчер сообщений, разработанный LinkedIn. В 2011 году был опубликован программный код. В 2012 году Kafka попал в инкубатор Apache, дальнейшая разработка ведется в рамках Apache Software Foundation. Открытое программное обеспечение с разрешительной лицензией написано на Java и Scala.
Изначально «Кафку» создавали как систему, оптимизированную под запись, и создатель Джей Крепс выбрал такое название в честь одного из своих любимых писателей.
Шаги передачи данных
Чтобы понять, как функционирует распределенная система Apache Kafka, необходимо проследить путь данных.
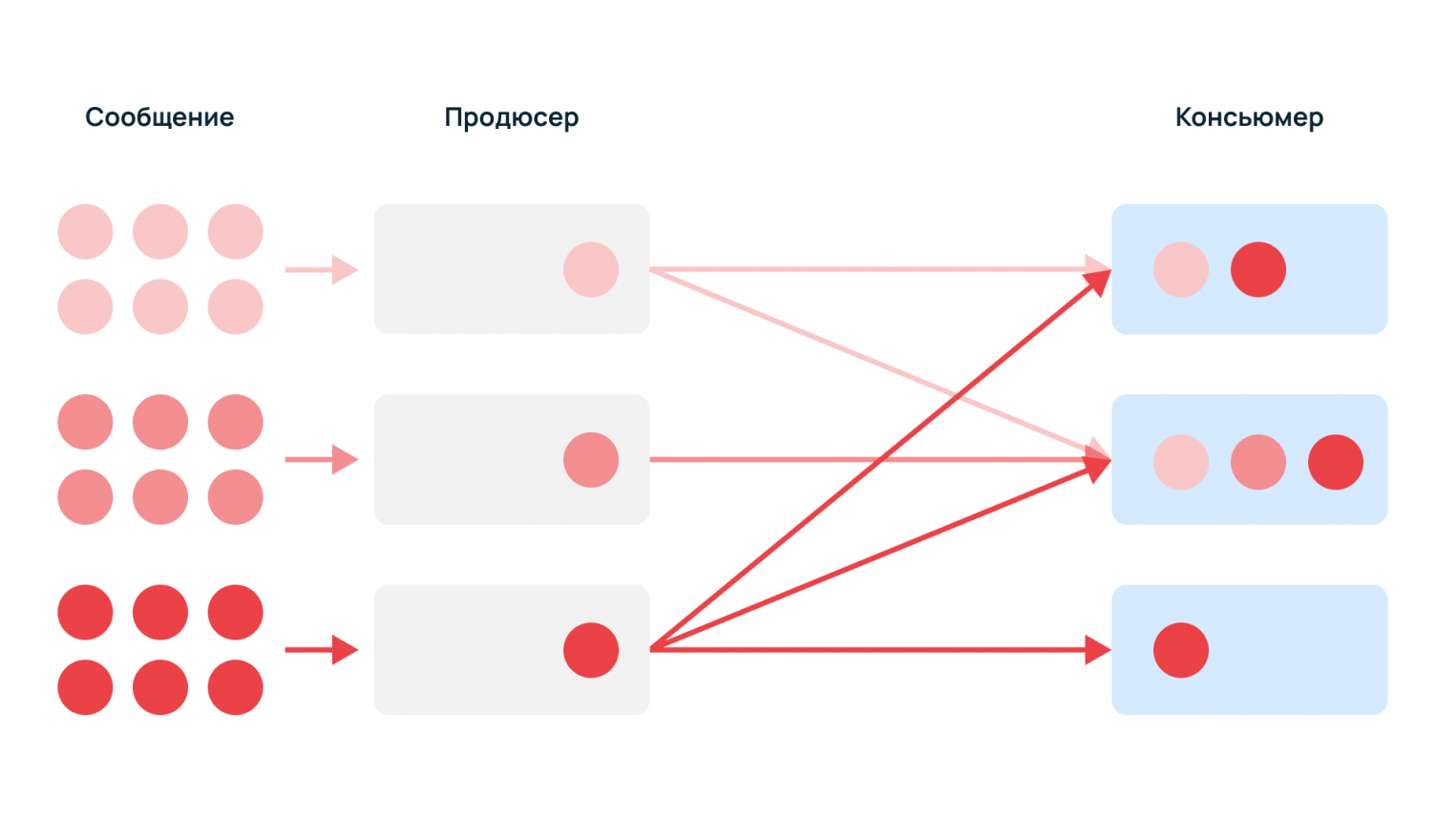
Событие или сообщение — данные, которые поступают из одного сервиса, хранятся на узлах Kafka и читаются другими сервисами. Сообщение состоит из:
- Key — опциональный ключ, нужен для распределения сообщений по кластеру.
- Value — массив байт, бизнес-данные.
- Timestamp — текущее системное время, устанавливается отправителем или кластером во время обработки.
- Headers — пользовательские атрибуты key-value, которые прикрепляют к сообщению.
Продюсер — поставщик данных, который генерирует сообщения — например, служебные события, логи, метрики, события мониторинга.
Консьюмер — потребитель данных, который читает и использует события, пример — сервис сбора статистики.
Какие сложности решает распределенная система
Сообщения могут быть однотипными или разнородными, поскольку разным потребителям нужны разные данные. Один тип событий может быть нужен всем консьюмерам, а другие — только одному.
Без брокера продюсеры должны знать получателя и резервного консьюмера, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых консьюмеров. С помощью брокера продюсеры просто отправляют информацию в единый узел.
Managed service для Apache Kafka
Сообщения хранятся на узлах-брокерах. Kafka — масштабируемый кластер со множеством взаимозаменяемых серверов, в которые добавляются новые брокеры, распределяющие задачи между собой.
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
Topic — принцип деления потока данных, базовая и основная сущность Apache Kafka. В топик складывается стрим данных, единая очередь из входящих сообщений.
Partition — для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
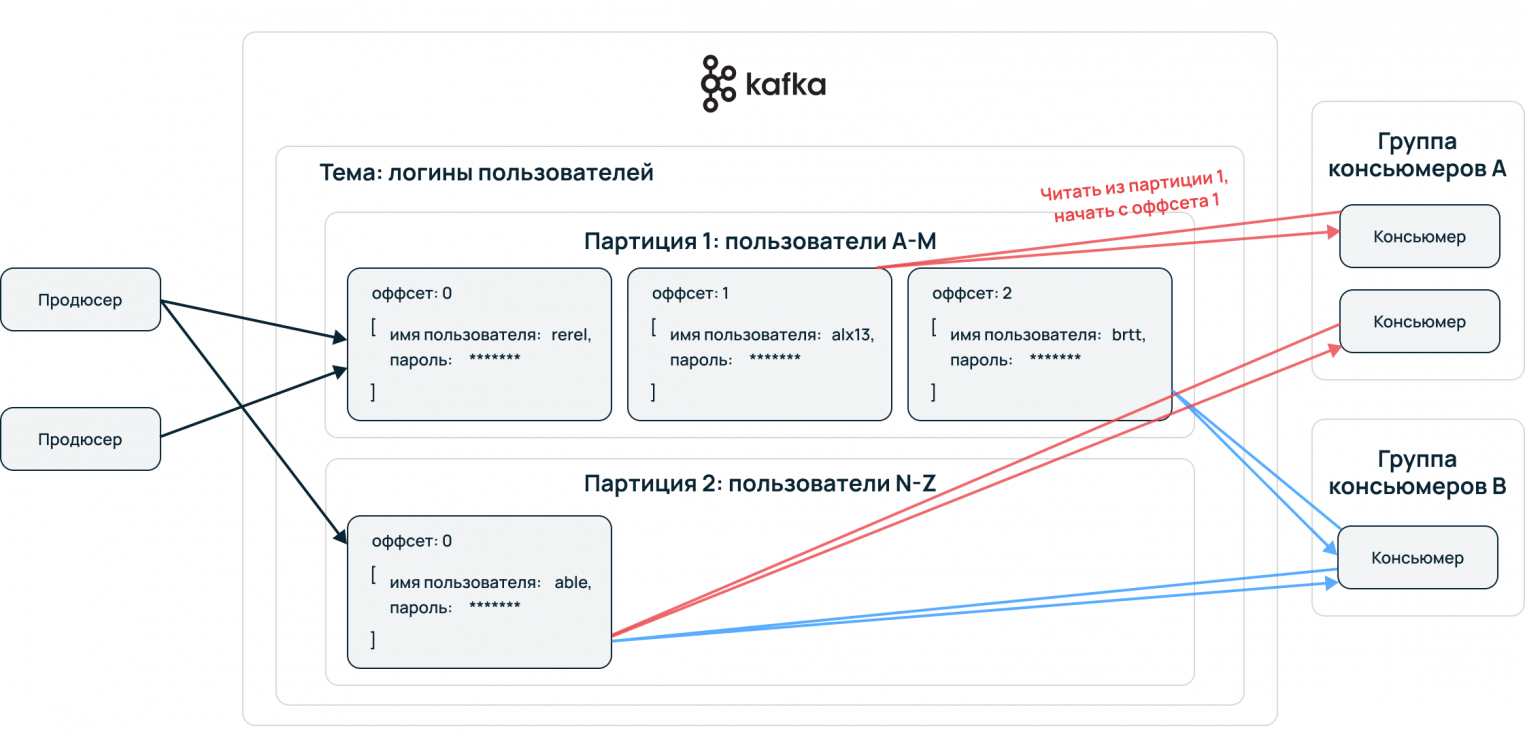
Упорядочение событий происходит на уровне партиций. Принимающая сторона потребляет данные в порядке расположения в партиции. Пример: все события одного пользователя сервисы принимают упорядоченно, обработка сохраняет последовательность пути пользователя. Выстраивается конвейер данных, алгоритмы машинного обучения могут извлекать из сырой информации необходимую для бизнеса информацию.
Преимущества Apache Kafka
Брокер распределяет информацию в широковещательном режиме. Применяющийся в Apache Kafka подход нужен для масштабирования и репликации данных.
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Офсеты
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Взаимодействие через API
Брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: продюсерам и консьюмерам необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Где применяется Apache Kafka
Отказоустойчивая система используется в бизнесе, где необходимо собирать, хранить и обрабатывать большие неструктурированные данные. Примеры — платформы, где требуется интеграция данных из большого количества источников, сервисы стриминговой аналитики, mission-critical applications.
Big Data
Первоначально LinkedIn разработали «Кафку» для своих целей: обмена данными между службами, репликации баз данных, потоковой передачи информации о деятельности и операционных показателях приложений.
Для IBM Apache Kafka работает как средство обмена сообщениями между микросервисами. В аналитических системах американской корпорации Apache Kafka обрабатывает потоковые и событийные данные.
Uber, Twitter, Netflix и AirBnb с помощью хорошо развитых пайплайнов обработки данных передают миллиарды сообщений в день. «Кафка» решает проблемы перемещения Big data из одного источника в другой.
Издание The New York Times использует Apache Kafka для хранения и распространения опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей в режиме реального времени.
Internet of Things
IoT-платформы используют архитектуру с большим количеством конечных устройств: контроллеров, датчиков, сенсоров и smart-гаджетов. ПО интернета вещей с помощью алгоритмов ML составляет графики профилактического ремонта оборудования, анализируя данные, поступающие с устройств.
ML-системы работают с онлайн-потоками, когда приборы, приложения и пользователи постоянно посылают данные, а сервисы обрабатывают их в реальном времени. Apache Kafka выступает центральным звеном в этом процессе.
Отрасли
Kafka используют организации практически в любой отрасли: разработка ПО, финансовые услуги, здравоохранение, государственное управление, транспорт, телеком, геймдев.
Сегодня Kafka пользуются тысячи компаний, более 60% входят в список Fortune 100. На официальном сайте представлен полный список корпораций и учреждений, которые используют брокера Apache.
Конкуренты
Чаще всего Kafka сравнивают с RabbitMQ. Обе системы — брокеры сообщений. Главное отличие в модели доставки: Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика; брокер RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
«Кролик» удаляет событие после доставки, «Кафка» хранит до запланированной очистки журнала. Таким образом, брокер Apache используется как источник истории изменений.
Разработчики RabbitMQ создали системы управления потоком сообщений: мониторинг получения, маршрутизация и шаблоны доставки. Подобное гибкое управление подойдет для высокоскоростного обмена сообщениями между несколькими сервисами. Минус такого подхода в снижении производительности при высокой нагрузке.
Главный вывод — для сбора и агрегации событий из большого количества источников, логов и метрик больше подойдет Apache Kafka.
Заключение
Благодаря высокой пропускной способности и согласованности данных Apache Kafka обрабатывает огромные массивы данных в реальном времени. Системы горизонтального масштабирования и офсеты гарантируют надежность. Kafka — удачное решение для проекта с очень большими нагрузками на обработку данных. Установить это ПО можно на серверы Ubuntu, Windows, CentOS и других популярных операционных систем.
Cloudera Manager и еще 7 инструментов администратора для мониторинга Kafka-кластера
Обновляя наши курсы для администраторов Apache Kafka, в этой статье разберем полезные средства, которые помогут вам следить за состоянием кластера, чтобы вовремя заметить существующие и предупредить возможные проблемы. Читайте далее, как отследить снижение производительности всей Big Data системы и сбои на отдельных брокерах с помощью дэшбордов в различных инструментах администрирования.
Как следить за Kafka-кластером: 8 полезных инструментов
Подобно авиадиспетчеру, дата-инженер и администратор непрерывно следят за множеством параметров Kafka-кластера, отслеживая показатели производительности брокеров, продюсеров и потребителей, особенности наполнения топиков и прочие важные метрики. Разумеется, все это выполняется не через ручные команды CLI-интерфейса, а автоматически отображается с помощью удобных и наглядных информационных панелей. Эти дэшборды наглядно рисуют графики и показывают цифры, а также позволяют управлять Кафка-кластером, например, задавать конфигурационные настройки и загружать данные в топики.
Сегодня наиболее популярными решениями для администрирования кластеров Apache Kafka можно назвать следующие [1]:
- Confluent Control Centre;
- Lenses;
- Datadog Kafka Dashboard;
- Cloudera Manager;
- CMAK;
- KafDrop;
- LinkedIn Burrow;
- Kafka Tool.
Что представляет собой каждый из этих инструментов, мы кратко рассмотрим далее. А про еще одно средство мониторинга с открытым исходным кодом, выпущенное летом 2022 года, читайте в нашей новой статье.
Confluent Control Centre
Решение от изначальных разработчиков самой Apache Kafka, компонент коммерческого решения Confluent Platform. Confluent Control Center – это система централизованного управления кластером Кафка, которая обеспечивает мониторинг и администрирование из пользовательского интерфейса. Control Center предоставляет наглядные дэшборды, на которых отражаются всевозможные показатели работающей системы, чтобы администратор мог настроить оптимальную производительность и соблюдать SLA для кластеров [2].
Lenses
Инструмент, который дополняет платформу Кафка с помощью пользовательского интерфейса, потокового механизма SQL и мониторинга кластеров, обеспечивая быстрый мониторинг конвейеров данных и видимость потоков данных. Lenses работает с любым дистрибутивом фреймворка, включая доступ к данным и потокам в реальном времени в режиме самообслуживания (self-service) на Kubernetes. Для dev-сред отлично подойдет Lenses Box – бесплатный универсальный Docker-образ, который может обслуживать до 25 миллионов сообщений на одном брокере [3]. Также Lenses предлагает Kafka topics UI – веб-инструмент для прокси-сервера Confluent, REST Proxy к Кафка, о котором мы рассказывали здесь. Он позволяет искать топики, просматривать их метаданные и сами сообщения, а также загружать данные. Средство можно свободно скачать с Github [4].