Как занести тестовые данные в таблицу SQL Server
1. Вставка N строк — делаем цикл while и внутри insert.
2. Для заполнения значения по внешнему ключу необходимо выбрать случайную строку из родительской таблицы:
(SELECT TOP 1 id FROM tst_customers ORDER BY NEWID())3. Получение случайного числа от 0 до N:
select rand()* 100000, cast(rand()* 100 as int) 4. Получение случайной даты (от 0 до N дней назад)
dateadd(day, - rand()*1000, getdate()) 5. Генерация случайной строки:
select left(NEWID(),7)Таким нехитрым способом можно очень быстро занести в таблицу любое количество строк.11
Основы T-SQL. DML
Для добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
INSERT [INTO] имя_таблицы [(список_столбцов)] VALUES (значение1, значение2, . значениеN)
Вначале идет выражение INSERT INTO , затем в скобках можно указать список столбцов через запятую, в которые надо добавлять данные, и в конце после слова VALUES скобках перечисляют добавляемые для столбцов значения.
Например, пусть ранее была создана следующая база данных:
CREATE DATABASE productsdb; GO USE productsdb; CREATE TABLE Products ( Id INT IDENTITY PRIMARY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL )
Добавим в нее одну строку с помощью команды INSERT:
INSERT Products VALUES ('iPhone 7', 'Apple', 5, 52000)
После удачного выполнения в SQL Server Management Studio в поле сообщений должно появиться сообщение «1 row(s) affected»:
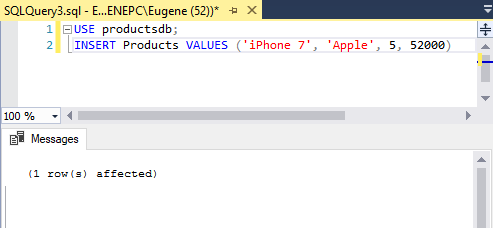
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id. Но так как для него задан атрибут IDENTITY, то значение этого столбца автоматически генерируется, и его можно не указывать. Второй столбец представляет ProductName, поэтому первое значение — строка «iPhone 7» будет передано именно этому столбцу. Второе значение — строка «Apple» будет передана третьему столбцу Manufacturer и так далее. То есть значения передаются столбцам следующим образом:
- ProductName: ‘iPhone 7’
- Manufacturer: ‘Apple’
- ProductCount: 5
- Price: 52000
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
INSERT INTO Products (ProductName, Price, Manufacturer) VALUES ('iPhone 6S', 41000, 'Apple')
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
- ProductName: ‘iPhone 6S’
- Manufacturer: ‘Apple’
- Price: 41000
Для неуказанных столбцов (в данном случае ProductCount) будет добавляться значение по умолчанию, если задан атрибут DEFAULT, или значение NULL. При этом неуказанные столбцы должны допускать значение NULL или иметь атрибут DEFAULT.
Также мы можем добавить сразу несколько строк:
INSERT INTO Products VALUES ('iPhone 6', 'Apple', 3, 36000), ('Galaxy S8', 'Samsung', 2, 46000), ('Galaxy S8 Plus', 'Samsung', 1, 56000)
В данном случае в таблицу будут добавлены три строки.
Также при добавлении мы можем указать, чтобы для столбца использовалось значение по умолчанию с помощью ключевого слова DEFAULT или значение NULL:
INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price) VALUES ('Mi6', 'Xiaomi', DEFAULT, 28000)
В данном случае для столбца ProductCount будет использовано значение по умолчанию (если оно установлено, если его нет — то NULL).
Если все столбцы имеют атрибут DEFAULT, определяющий значение по умолчанию, или допускают значение NULL, то можно для всех столбцов вставить значения по умолчанию:
INSERT INTO Products DEFAULT VALUES
Но если брать таблицу Products, то подобная команда завершится с ошибкой, так как несколько полей не имеют атрибута DEFAULT и при этом не допускают значение NULL.
SQL-Ex blog

Заполнение столбца SQL Server последовательным номерами без использования identity
Добавил Sergey Moiseenko on Суббота, 3 сентября. 2022
Проблема
Есть таблица базы данных, которая уже содержит много данных. Необходимо добавить в эту таблицу новый столбец, который имел бы последовательную нумерацию. Помимо добавления столбца, также необходимо заполнить существующие записи инкрементным счетчиком. Какие для этого имеются варианты?
Решение
Первое решение, которое приходит на ум, это добавить столбец identity в таблицу, если она еще не имеет такого столбца. Посмотрим на этот подход, а также на то, как сделать это с помощью простого оператора UPDATE.
Использование столбца identity для инкрементирования значения на 1
Для этого примера мы создадим таблицу (для имитации реально существующей таблицы), загрузим туда 100000 записей, а затем изменим структуру таблицы, добавив столбец identity с приращением 1.
CREATE TABLE accounts ( fname VARCHAR(20), lname VARCHAR(20))
GO
INSERT accounts VALUES ('Fred', 'Flintstone')
GO 100000
SELECT TOP 10 * FROM accounts
GO
ALTER TABLE accounts ADD id INT IDENTITY(1,1)
GO
SELECT TOP 10 * FROM accounts
GO
Статистика по времени и вводу/выводу показывает, что было выполнено 23К логических чтений, и все выполнение заняло 48 секунд.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 17 ms.
Table ‘accounts’. Scan count 1, logical reads 23751, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 6281 ms, elapsed time = 48701 ms.
SQL Server Execution Times:
CPU time = 6281 ms, elapsed time = 48474 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Использование переменных для обновления и инкрементирования значения на 1
В этом примере мы создаем подобную таблицу, загружаем в неё 100000 записей, после чего изменяем таблицу, добавляя столбец INT и выполняя обновление.
CREATE TABLE accounts2 ( fname VARCHAR(20), lname VARCHAR(20))
GO
INSERT accounts2 VALUES ('Barney', 'Rubble')
GO 100000
SELECT TOP 10 * FROM accounts2
GO
После создания таблицы и загрузки данных мы добавляем в таблицу столбец INT, который не является столбцом identity.
ALTER TABLE accounts2 ADD id INT
GO
SELECT TOP 10 * FROM accounts2
GO
На этом шаге мы собираемся обновить таблицу и для каждой обновляемой строки мы изменяем переменную на 1, а также обновляем столбец id в таблице. Это видно здесь (SET @id = + 1), где мы делаем значение @id и столбец id равными текущему значению @id плюс 1.
DECLARE @id INT
SET @id = 0
UPDATE accounts2
SET @id = + 1
GO
SELECT * FROM accounts2
GO
Ниже можно увидеть результаты, где каждая запись получает приращение 1.
Статистика по времени и вводу/выводу показывает около 26К логических чтений и 4,8 секунды на выполнение.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 247 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Table ‘accounts2’. Scan count 1, logical reads 26384, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 4781 ms, elapsed time = 4856 ms.
(100000 row(s) affected)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Если сравнить статистику по времени и вводу/выводу для обновления со столбцом identity, то данный подход имеет примерно то же самое число логических чтений, но полное время выполнения в 10 раз быстрей для варианта обновления по сравнению с поддержкой значений identity.
Использование переменных для обновления с значением приращения 10
Пусть теперь нам нужен инкремент 10, а не 1. Мы можем выполнить обновление, как мы делали это выше, но использовать значение 10 для приращения id каждой записи.
Для чистоты эксперимента я сначала сделаю значением столбца id NULL для всех записей, а затем выполню обновление.
UPDATE accounts2 SET /> GO
DECLARE @id INT
SET @id = 0
UPDATE accounts2
SET @id = + 10
GO
SELECT * FROM accounts2
GO
Ниже видно, что значения id теперь инкрементируются на 10, а не на 1. Вы можете использовать в качестве инкремента любое желаемое значение.
Предупреждение: возможно появление дубликатов
Читатели блога заметили, что они столкнулись с проблемой появления дублирующих значений, если процесс выполняется параллельно. Эта проблема была замечена на таблице, которая содержала более 11 миллионов строк. Ими были предложены следующие подходы.
-- использование MAXDOP = 1 - автор Steve Ash
-- обновление выполняется при использовании только одного процессора,
-- чтобы избежать проблемы с дубликатами
DECLARE @id INT
SET @id = 0
UPDATE accounts2
SET @id = + 1
OPTION ( MAXDOP 1 )
GO
-- использование уровня изоляции SERIALIZABLE - автор Tillman Dickson
-- это означает, что другие транзакции не могут модифицировать данные, которые читаются
-- текущей транзакций, пока текущая транзакция не завершится.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRANSACTION
DECLARE @id INT
SET @id = 0
UPDATE accounts2
SET @id = + 1
COMMIT TRANSACTION
Другой подход к обновлению последовательных значений
Вот еще один предложенный подход.
-- обновление строк с помощью CTE - автор Ervin Steckl
;WITH a AS(
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) as rn, id
FROM accounts2
)
UPDATE a SET /> OPTION (MAXDOP 1)
Заключение
Когда вы создали столбец identity, у вас нет простого способа перенумеровать значения для каждой строки. Подход на основе обновления позволяет это делать по мере необходимости простым выполнением запроса и изменением значений. Этот подход работает для всех версий SQL Server, а вариант с CTE — для SQL Server 2005 и выше.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Вставка, изменение и удаление записей таблицы с помощью Access SQL
По существу, существует два метода добавления записей в таблицу. Первый — добавление по одной записи за раз, второй — одновременное добавление нескольких записей. В обоих случаях для выполнения задачи необходимо использовать инструкцию SQL INSERT INTO. Инструкции INSERT INTO обычно называют запросами на добавление.
Чтобы добавить одну запись в таблицу, с помощью списка полей определите, в какие поля следует поместить данные, а затем разместите данные в списке значений. Для определения списка значений используйте выражение VALUES. Например, указанная ниже инструкция вставляет значения 1, Kelly и Jill в поля CustomerID, Last Name и First Name соответственно.
INSERT INTO tblCustomers (CustomerID, [Last Name], [First Name]) VALUES (1, 'Kelly', 'Jill') Вы можете опустить список полей, но только в том случае, если вы передаете все значения, которые должна содержать запись.
INSERT INTO tblCustomers VALUES (1, Kelly, 'Jill', '555-1040', 'someone@microsoft.com') Чтобы добавить одновременно несколько записей в таблицу, используйте инструкцию INSERT INTO совместно с инструкцией SELECT. Если вы вставляете записи из другой таблицы, тип каждого вставляемого значения должен быть совместим с типом поля, принимающего данные.
Указанная ниже инструкция INSERT INTO вставляет все значения полей CustomerID, Last Name и First Name таблицы tblOldCustomers в соответствующие поля таблицы tblCustomers.
INSERT INTO tblCustomers (CustomerID, [Last Name], [First Name]) SELECT CustomerID, [Last Name], [First Name] FROM tblOldCustomers Если таблицы определены совершенно одинаково, можно не использовать списки полей.
INSERT INTO tblCustomers SELECT * FROM tblOldCustomers Изменение записей в таблице
Чтобы изменить текущие данные в таблице, используйте инструкцию UPDATE, которую обычно называют запросом на обновление. Инструкция UPDATE может изменить одну или несколько записей и обычно имеет указанный ниже вид.
UPDATE table name SET field name = some value Чтобы изменить все записи в таблице, укажите имя таблицы и с помощью выражения SET укажите поле или поля, которые необходимо изменить.
UPDATE tblCustomers SET Phone = 'None' В большинстве случаев вам потребуется уточнить инструкцию UPDATE с помощью выражения WHERE, чтобы ограничить количество изменяемых записей.
UPDATE tblCustomers SET Email = 'None' WHERE [Last Name] = 'Smith' Удаление записей из таблицы
Чтобы удалить текущие данные в таблице, используйте инструкцию DELETE, которую обычно называют запросом на удаление. Эту операцию также называют усечением таблицы. Инструкция DELETE может удалить одну или несколько записей из таблицы и обычно имеет следующий вид:
DELETE FROM table list Инструкция DELETE не удаляет структуру таблицы, она удаляет только данные, хранящиеся в структуре таблицы. Чтобы удалить все записи из таблицы, используйте инструкцию DELETE и укажите одну или несколько таблиц, из которых вы хотите удалить все записи.
DELETE FROM tblInvoices В большинстве случаев вам потребуется уточнить инструкцию DELETE с помощью выражения WHERE, чтобы ограничить количество удаляемых записей.
DELETE FROM tblInvoices WHERE InvoiceID = 3 Если вы хотите удалить данные только из определенных полей таблицы, используйте инструкцию UPDATE и присвойте этим полям значение NULL, но только в том случае, если эти поля допускают значение NULL.
UPDATE tblCustomers SET Email = Null Поддержка и обратная связь
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.
Обратная связь
Были ли сведения на этой странице полезными?