Потоковые и многопроцессорные модули на Python
Главная идея потоков заключается в выполнении последовательности таких инструкций внутри программы, которые могут выполняться независимо от другого кода.
Так в чём же разница между потоковой и многопроцессорной обработкой данных? При одновременном выполнении нескольких задач обычно используется потоковая обработка, а при процессно-ориентированном параллелизме задействуется многопроцессорная обработка.
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.
Проблема GIL на Python
Обычно на Python используется только один поток для выполнения нескольких записанных инструкций, то есть одновременно выполняется только один поток. Производительность однопоточного и многопоточного процессов здесь одинакова, и происходит это из-за GIL (Global Interpreter Lock — глобальной блокировки интерпретатора). Эта глобальная блокировка интерпретатора сама действует как поток и ограничивает другие потоки, делая невозможной многопоточность на Python.
Процессы ускоряют операции на Python, которые создают интенсивную вычислительную нагрузку на центральный процессор, используя сразу несколько ядер и избегая GIL, в то время как потоки лучше подходят для задач ввода-вывода или задач, связанных со внешними системами, потому что потоки могут более эффективно работать вместе. Для объединения процессов им нужно сериализовывать свои результаты, на что требуется время.
Потоки на Python не дают никаких преимуществ для задач, создающих интенсивную вычислительную нагрузку на процессор, именно из-за GIL.
Зачем нужен GIL?
Потоковый модуль использует потоки, многопроцессорный модуль использует процессы. Разница в том, что потоки выполняются в одном и том же пространстве памяти, а у процессов отдельная память. Это немного затрудняет совместное использование объектов процессами с многопроцессорной обработкой. В этом случае обычно выполняется сериализация объектов. Но потоки используют одну память, поэтому нужно быть осторожным, иначе два потока будут записывать данные в одну и ту же память одновременно. Именно для этого и существует глобальная блокировка интерпретатора.
Если бы мы запустили на Python скрипт, выполняющий простую задачу — спать (ну очень времязатратную!), он выглядел бы так:
import timestart = time.perf_counter()def please_sleep(n):
print("Sleeping for <> seconds".format(n))
time.sleep(n)
print("Done Sleeping")for i in range(1,5):
please_sleep(i)finish = time.perf_counter()print("Finished in <> seconds".format(finish-start))
Получаем результат, который и ожидали:
Рабочий процесс этого скрипта будет выглядеть примерно так:
Начнём с потокового модуля
Потоковый модуль
Рабочий процесс потоковой обработки можно представить в таком виде:
Сначала нужно импортировать потоковый модуль (это очевидно!).
Чтобы воспроизвести приведённый выше скрипт, используя потоки, потребуется создать несколько потоков. Это можно сделать многократным выполнением простого метода Thread (поток). Вот синтаксис этого метода:
thread1 = threading.Thread(target = method_name, args = [list of arguments])
После создания потоков нужно запустить их с помощью метода start:
thread1.start()
Давайте сначала возьмём простой пример, создав всего 2 потока, а затем попробуем повторить приведённый выше скрипт:
import time
import threadingstart = time.perf_counter()def please_sleep(n):
print("Sleeping for <> seconds".format(n))
time.sleep(n)
print("Done Sleeping")t1 = threading.Thread(target = please_sleep, args = [1])
t2 = threading.Thread(target = please_sleep, args = [2])t1.start()
t2.start()finish = time.perf_counter()print("Finished in <> seconds".format(finish-start))
Согласно рабочему процессу, этот фрагмент кода должен выполняться в течение примерно двух секунд. Теперь посмотрим, что он выведет на экран:
Результат не соответствует нашим ожиданиям. Такое поведение вызвано тем, что после запуска обоих потоков, в то время как потоки спали, наш скрипт работал в многопоточном режиме и продолжил выполнение с остальной частью скрипта. Это тут же привело к подсчёту времени до завершения.
Чтобы этого не допустить, надо задействовать метод join. При вызове метода join вызывающий поток (в нашем случае основной поток) блокируется до тех пор, пока не завершится объект потока (метод please_sleep), на котором он был вызван. Аналогично можно вызвать его в метод start:
thread1.join()
Повторим основной скрипт, используя всё то, что мы сейчас делали:
import time
import threadingstart = time.perf_counter()def please_sleep(n):
print("Sleeping for <> seconds".format(n))
time.sleep(n)
print("Done Sleeping for <> seconds".format(n))threads = []for i in range(1,5):
t = threading.Thread(target = please_sleep, args = [i])
t.start()
threads.append(t)for t in threads:
t.join()finish = time.perf_counter()print("Finished in <> seconds".format(finish-start))
Теперь выводится ожидаемый результат:
Примерно за четыре секунды успешно были выполнены четыре задачи, на которые первоначально уходило около десяти секунд.
Можно ли достигнуть тех же результатов с помощью модуля многопроцессорной обработки? Да, можно. Давайте в этом убедимся.
Модуль многопроцессорной обработки
Проиллюстрируем наши рассуждения примером с четырёхъядерным процессором. Вот рабочий процесс многопроцессорной обработки данных.
Процесс для запуска процесса �� происходит аналогично запуску потоков. Здесь мы первым делом импортируем многопроцессорный модуль, а затем вызываем метод Process, за которым следует метод start.
process1 = multiprocessing.Process(target = method_name, args = [list of arguments])
process1.start()
Потоки более легковесны и расходуют меньше вычислительных ресурсов по сравнению с процессами, а значит возникновение процессов происходит немного медленнее, чем порождение потоков. Вот пример:
import time
import multiprocessingstart = time.perf_counter()def please_sleep(n):
print("Sleeping for <> seconds".format(n))
time.sleep(n)
print("Done Sleeping for <> seconds".format(n))p1 = multiprocessing.Process(target = please_sleep, args = [1])
p2 = multiprocessing.Process(target = please_sleep, args = [2])p1.start()
p2.start()finish = time.perf_counter()print("Finished in <> seconds".format(finish-start))
Теперь вывод на экран показывает, что процессы были запущены после выполнения всего скрипта, подтверждая то, что было сказано ранее.
Метод join здесь тоже не даёт скрипту выполняться от момента вызова метода и до тех пор, пока процесс не будет завершен. Вызывается он так:
process1.join()
Давайте теперь создадим скрипт, который использует многопоточность для распараллеливания этого метода.
import time
import multiprocessingstart = time.perf_counter()def please_sleep(n):
print("Sleeping for <> seconds".format(n))
time.sleep(n)
print("Done Sleeping for <> seconds".format(n))processes = []for i in range(1,6):
p = multiprocessing.Process(target = please_sleep, args = [i])
p.start()
processes.append(p)for p in processes:
p.join()finish = time.perf_counter()print("Finished in <> seconds".format(finish-start))
Вывод теперь соответствует рабочему процессу:
Использование параллелизма всегда приводит к потере эффективности, вынуждая расходовать больше ресурсов, поэтому общее время параллельных вычислений обычно оказывается больше, чем последовательных. Воспользовавшись законом Амдала, можно сказать, что параллельные вычисления с большим числом процессоров эффективны только для программ с высокой степенью распараллеливания.
Ценю ваше терпение и благодарю за то, что дочитали до конца.��
- Вы умеете говорить на Python?
- Расширение Python с помощью C
- Анализ аудиоданных с помощью глубокого обучения и Python (часть 1)
Многопоточность в Python. Библиотеки threading и multiprocessing.
Процесс — исполняемый экземпляр какой-либо программы. Каждый процесс состоит из следующих элементов:
- образ машинного кода;
- область памяти, в которую включается исполняемый код, данные процесса (входные и выходные данные), стек вызовов и куча (для хранения динамически создаваемых данных);
- дескрипторы операционной системы (например, файловые дескрипторы);
- состояние процесса.
В целях стабильности и безопасности, в современных операционных системы каждый процесс имеет прямой доступ только с своим собственным ресурсам. Доступ к ресурсам другого процесса возможен через межпроцессное взаимодействие (например, посредством файлов, при помощи именованных и неименованных каналов и другие).
Сам процесс может быть разделен на так называемые потоки. Поток (поток выполнения, thread) — наименьшая единица обработки, исполнение которой может быть назначено ядром операционной системы. В отличии от нескольких процессов, потоки существуют внутри одного процесса и имеют доступ к ресурсам этого процесса. Каждый поток обладет собственным набором регистров и собственным стеком вызова, но доступ к ним имеют и другие потоки.
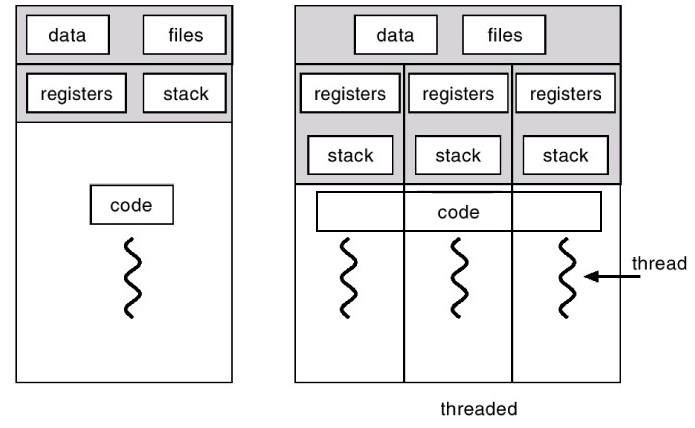
При работе с потоками стоит учесть несколько моментов:
- одно ядро процессора в один момент может исполнять только один поток;
- потоки одного процесса могут исполняться физически одновременно (на разных ядрах);
- бессмысленно порождать потоков больше, чем у вас есть ядер.
Потоки имеют несколько применений. Первое — ускорение работы программы. Ускорение достигается за счет параллельного выполнения независимых друг от друга вычислений. Например, при численном интегрировании область интегрирования может быть разбита на 3 участка. На каждый участок создается свой поток, в котором численно вычислется интеграл для конкретного участка. Второе — независимое исполнение операций. Отличие этого случая от первого хорошо видно на следующем примере. Пусть есть приложение с графическим интерфейсом, где весь код выполняется в одном потоке. При выполнении какой-нибудь долгой операции (например, копирование файла) интерфейс приложения просто перестанет отвечать до тех пор, пока долгий процесс не завершится. В таком случае в один поток помещается работа графического интерфейса, в другой — остальные вычисления. В таком случае интерфейс позволит проводить другие операции даже во время выполнения долгой операции в другом потоке (например, заполнение прогресс бара в процессе копирования файла).
threading
В Python работа с потоками осуществляется при помощи стандартной библиотеки threading. В библиотеке представлен класс Thread для создания потока выполнения. Задание исполняемого кода в отдельном потоке возможно двумя способами:
- передача исполняемого объекта (функции) в конструктор класса;
- переопределение функции run() в классе-наследнике.
После того, как объект создан, поток запускается путем вызова метода start(). Рассмотрим простой пример:
import threading import sys def thread_job(number): print('Hello <>'.format(number)) sys.stdout.flush() def run_threads(count): threads = [ threading.Thread(target=thread_job, args=(i,)) for i in range(0, count) ] for thread in threads: thread.start() # каждый поток должен быть запущен for thread in threads: thread.join() # дожидаемся исполнения всех потоков run_threads(4) print(finish)
Конструктор класса Thread имеет следующие аргументы:
- group должно быть None; зарезервировано для будующих реализаций Python 3;
- target является исполняемым объектом (по умолчанию равен None, ничего не исполняется);
- name обозначет имя потока (по умолчанию имя генерируется автоматически);
- args — кортеж аргументов для исполняемого объекта;
- kwargs — словарь именованных аргументов для исполняемого объекта;
- daemon равное True обозначет служебный поток (служебные потоки завершаются принудительно при завершении процесса); по умолчанию False.
В Python выполнение программы заканчивается, когда все неслужебные потоки завершены. Модифицировав программу выше, мы все еще получим корректно работающий код:
import threading import sys import time def thread_job(number): time.sleep(2) # "усыпляем" поток на 2 сек print('Hello <>'.format(number)) sys.stdout.flush() def run_threads(count): threads = [ threading.Thread(target=thread_job, args=(i,)) for i in range(1, count) ] for thread in threads: thread.start() # каждый поток должен быть запущен run_threads(1) print(finish)
Как можно увидеть, программа завершается без ошибок (с кодом 0), но теперь строка «finish» печатается раньше строки «Hello 0», т.к. главный поток теперь не ждет завершения работы других потоков. Метод join() используется для блокирования исполнения родительского потока до тех пор, пока созданный поток не завершится. Это нужно в случаях, когда для работы потока-родителя необходим результат работы потока-потомка. Вспомним пример с численным интегрированием. Вычисление итогового значения интеграла выполняется в главном потоке, но это возможно только после завершения вычислений в побочных потоках. В таком случае главный поток нужно просто приостановить до тех пор, пока не завершатся все побочные потоки. Метод join() может принимать один аргумент — таймаут в секундах. Если таймаут задан, join() бликирует работу на указанное время. Если по истечении времени ожидаемый поток не будет завершен, join() все равно разблокирует работу потока, вызвашего его. Проверить, исполняется ли поток можно методом is_alive(). Подробнее ознакомиться с функционалом библиотеки можно в официальной документации по threading.
Упражнение №1
Запустите следующий код. В чем проблема данного кода? Всегда ли counter = 10 после исполнения кода программы?
import threading import sys def thread_job(): global counter old_counter = counter counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
Демонстрация «проблемности» кода:
import threading import random import time import sys def thread_job(): global counter old_counter = counter time.sleep(random.randint(0, 1)) counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
Почему так происходит? Есть несколько возможных решений этой проблемы.
import threading import random import time import sys def thread_job(): lock.acquire() # mutex global counter old_counter = counter time.sleep(random.randint(0, 1)) counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() lock.release() lock = threading.Lock() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
import threading import random import time import sys def thread_job(): with lock: global counter old_counter = counter time.sleep(random.randint(0, 1)) counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() lock = threading.Lock() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
Вариант с контекстным менеджером более предпочтителен. Вспомните работу с файлами при помощи with. По завершении with файл автоматически закрывался. В данном случае похожая ситуация. Для того, чтобы запретить нескольким потокам параллельно выполнять некоторые участки кода, мы используем Lock (в UNIX системах более известен как мьютекс (mutex)). Мьютекс может быть в двух состояниях: свободен и заблокирован. Если какой-либо поток пытается заблокировать уже заблокированный мьютекс, то поток блокируется до тех пор, пока мьютекс не освободится. Причем если несколько потоков претендует на блокирование мьютекса, то потоки просто выстраиваются в очередь. Главная проблема — не освобожденный мьютекс. Отсутствие строчки lock.release() может повесить остальные потоки в бесконечное ожидание. Контекстный менеджер позволит избежать этой проблемы. Как только он закончится, все захваченные им ресурсы будут освобождены, в том числе мьютекс.
Упражнение №2
Иногда бывает нужно узнать доступность набора ip адресов. Неэффективный вариант представлен ниже.
Реализуйте то же самое, но используя threading.
import os, re received_packages = re.compile(r"(\d) received") status = ("no response", "alive but losses", "alive") for suffix in range(20, 30): ip = "192.168.178." + str(suffix) ping_out = os.popen("ping -q -c2 " + ip, "r") # получение вердикта print(". pinging ", ip) while True: line = ping_out.readline() if not line: break n_received = received_packages.findall(line) if n_received: print(ip + ": " + status[int(n_received[0])])
Global Interpreter Lock (GIL)
CPython — популярная реализация интерпретатора — имеет встроенный механизм, который обеспечивает выполнение ровно одного потока в любой момент времени. GIL облегчает реализацию интерпретатора, защищая объекты от одновременного доступа из нескольких потоков. По этой причине, создание несколько потоков не приведет к их одновременному исполнению на разных ядрах процессора.
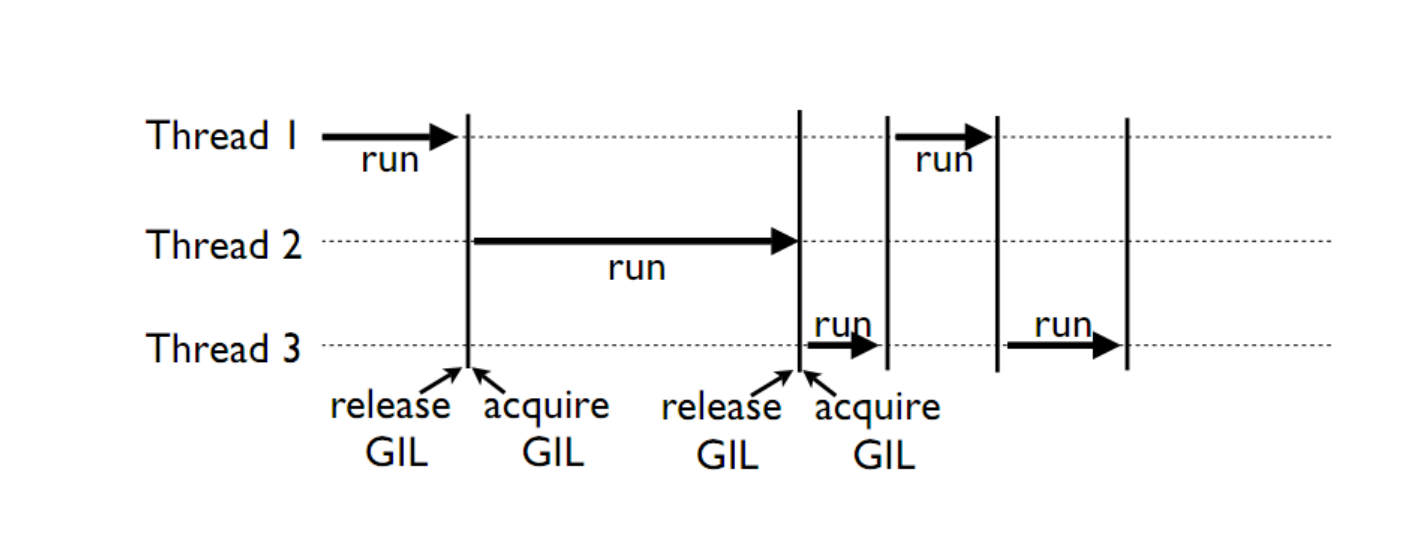
Однако, некоторые модули, как стандартные, так и сторонние, созданы для освобождения GIL при выполнении тяжелых вычислительных операций (например, сжатие или хеширование). К тому же, GIL всегда свободен при выполнении операций ввода-вывода.
Упражнение №3
Написать программу, которая будет находить сумму чисел массива с использованием N потоков. Запустить с разным параметром N. Убедиться, что несмотря на увеличение N, ускорения подсчета не происходит. Причина этому — GIL. В Python вычисления распараллеливать бессмысленно. Замерить время работы можно с помощью библиотеки time (ответ в секундах):
start = time.time() # код, время работы которого надо замерить print(time.time() - start)
Упражнение №4
Запустите на исполнение, замерив время работы. Перепишите с помощью потоков и опять замерьте время.
import urllib.request import time urls = [ 'https://www.yandex.ru', 'https://www.google.com', 'https://habrahabr.ru', 'https://www.python.org', 'https://isocpp.org', ] def read_url(url): with urllib.request.urlopen(url) as u: return u.read() start = time.time() for url in urls: read_url(url) print(time.time() - start)
Потоки очень уместны, если в коде есть блокирующие операции (ввод-вывод, сетевые взаимодействия). Также, удобно разбивать логические процессы по потокам (анимация, графический интерфейс, и тд).
multiprocessing
Библиотека multiprocessing позволяет организовать параллелизм вычислений за счет создания подпроцессов. Т.к. каждый процесс выполняется независимо от других, этот метод параллелизма позволяет избежать проблем с GIL. Предоставляемый библиотекой API схож с тем, что есть в threading, хотя есть уникальные вещи. Создание процесса происходит поутем создания объекта класса Process. Аргументы конструктора аналогичны тем, что есть в конструкторе Thread. В том числе аргумент daemon позволяет создавать служебные процессы. Служебные процессы завершаются вместе с родительским процессом и не могут порождать свои подпроцессы.
Простой пример работы с библиотекой:
from multiprocessing import Process def f(name): print('hello', name) if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Чтобы убедить, что каждый процесс имеет свой ID, запустите пример:
from multiprocessing import Process import os def info(title): print(title) print('module name:', __name__) print('parent process:', os.getppid()) print('process id:', os.getpid()) def f(name): info('function f') print('hello', name) if __name__ == '__main__': info('main line') p = Process(target=f, args=('bob',)) p.start() p.join()
Старайтесь не забывать про конструкцию __name__ == ‘__main__’ . Это надо для того, чтобы ваш модуль можно было безопасно подключать в другие модули и при этом не создавались новые процессы без вашего ведома.
Упражнение №5
Запустите код. Попробуйте объяснить, почему LIST — пуст.
import multiprocessing def worker(): LIST.append('item') LIST = [] if __name__ == "__main__": processes = [ multiprocessing.Process(target=worker) for _ in range(5) ] for p in processes: p.start() for p in processes: p.join() print(LIST)
Общение между процессами
multiprocessing предоставляет два вида межпроцессного обмена данными: очереди и каналы данных (pipe).
Очереди (класс Queue) аналогичны структуре данных «очередь», рассмотренной вами в курсе алгоритмов.
from multiprocessing import Process, Queue def f(q): q.put([42, None, 'hello']) if __name__ == '__main__': q = Queue() p = Process(target=f, args=(q,)) p.start() print(q.get()) # выводит "[42, None, 'hello']" p.join()
Класс Pipe отвечает за канал обмена данными (по умолчанию, двунаправленный), представленный двумя концами, объектами класса Connection. С одним концом канала работает родительский процесс, а с другим концом — подпроцесс.
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello']) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) # выводит "[42, None, 'hello']" p.join()
Еще один вид обмена данными может быть достигнут путем записи/чтения обычных файлов. Чтобы исключить одновременную работу двух процессов с одним файлом, в библиотеке есть классы аналогичные threading.
from multiprocessing import Process, Lock def f(l, i): l.acquire() try: print('hello world', i) finally: l.release() if __name__ == '__main__': lock = Lock() for num in range(10): Process(target=f, args=(lock, num)).start()
Подробнее ознакомиться с функционалом библиотеки можно в официальной документации по multiprocessing.
Класс Pool в multiprocessing
Класс Pool — удобный механизм распараллеливания выполнения функций, распределения входных данных по процессам и т.д.
Наиболее интересные функции: Pool.apply, Pool.map, Pool.apply_async, Pool.map_async.
apply, map работают аналогично питоновским built-in apply, map.
Как работает Pool можно понять на примере:
from multiprocessing import Pool def cube(x): return x**3 if __name__ == "__main__": pool = Pool(processes=4) # создаем пул из 4 процессов # в apply можно передать несколько аргументов results = [pool.apply(cube, args=(x,)) for x in range(1,7)] # раскидываем числа от 1 до 7 по 4 процессам print(results) pool = Pool(processes=4) # то же самое, но с map. разбивает итерируемый объект (range(1,7)) на chunks и раскидывает аргументы по процессам results = pool.map(cube, range(1,7)) print(results)
map, apply — блокирующие вызовы. Главная программа будет заблокирована, пока процесс не выполнит работу.
map_async, apply_async — неблокирующие. При их вызове, они сразу возвращают управление в главную программу (возвращают ApplyResult как результат). Метод get() объекта ApplyResult блокирует основной поток, пока функция не будет выполнена.
pool = mp.Pool(processes=4) results = [pool.apply_async(cube, args=(x,)) for x in range(1,7)] output = [p.get() for p in results] print(output)
Упражение №6*
Для этого упражнения скачайте архив viterbi_mp.zip с кодом и необходимыми данными.
Рассмотрим следующую задачу. Положение мобильного робота на двумерной карте может быть представлено тремя числами: x, y и направлением θ. Точное положение робота нам не известно. В связи с этим мы строим N гипотез о его пложении, сумма их вероятностей равна 1. В процессе движения робота некоторые гипотезы исчезали, а некоторые порождали новые. Однако в каждый момент времени количество гипотез — константа. Известно, какая гипотеза из какой была порождена.
Представленный (и слегка упрощенный) выше метод оценки положения робота множеством гипотез называется фильтром частиц, а сами гипотезы называются частицами. Фильтр частиц используется для оценки положения робота в процессе его движения. Вспомним, что в процессе работы некоторые частицы погибают, а некоторые порождают другие. Переходы между частицами образуют граф перехода. Используя этот граф, можно оценить траекторию робота с некоторой точностью.
Задача: необходимо восстановить траекторию движения робота. Есть несколько способов приближенно решить данную задачу. Один из способов — восстановить наиболее вероятную траекторию. Для этого воспользуемся алгоритмом Витерби, одним из алгоритмов динамического программирования.
Пусть у нас было T моментов времени. На каждом моменте времени t мы для каждой частицы, существующей в момент времени t, выбираем наиболее вероятный переход из какой-нибудь частицы с момента времени t-1. Тогда ответом будет — argmax по вероятности среди всех частиц в последний момент времени. Однако, сам алгоритм довольно медленный. Его асимптотика O(T * N^2) .
В архиве вам предоставлен код в файле generate_viterbi_trajectory.py . Однако, он написан без распараллеливания. Ваша задача — распараллелить код, используя multiprocessing. Файл graph.ldj представляет собой текстовый файл, где каждая строка в формате JSON. Каждая строка представляет собой один момент времени. В этом задании вам предлагаются первые 10 моментов времени движения робота. В каждый момент времени количество частиц N = 2000 . Файл localization_config.json — файл конфигурации, содержащий параметры с которыми происходила генерация графа. Файл true_trajectory.json содержит массив троек чисел (x, y, θ), построенный нераспараллеленым алгоритмом. Вам надо будет сравнить полученную вами траекторию с данной при помощи скрипта correspond_trajectories.py . Для тех, кто хочет попробовать свой код на больших данных, используйте файл full_graph.ldj , который содержит порядка 1700 строк. Архив с файлом.
Не забудьте замерить время работы. Примерное время работы на моем компьютере для 10 строк в 1 процесс — 300 сек.
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY.
Способы реализации параллельных вычислений в программах на Python
Параллелизм дает возможность работать над несколькими вычислениями одновременно в одной программе. Такого поведения в Python можно добиться несколькими способами:
- Используя многопоточность threading , позволяя нескольким потокам работать по очереди.
- Используя несколько ядер процессора multiprocessing . Делать сразу несколько вычислений, используя несколько ядер процессора. Это и называется параллелизмом.
- Используя асинхронный ввод-вывод с модулем asyncio . Запуская какую то задачу, продолжать делать другие вычисления, вместо ожидания ответа от сетевого подключения или от операций чтения/записи.
Разница между потоками и процессами.
Поток threading — это независимая последовательность выполнения каких то вычислений. Поток thread делит выделенную память ядру процессора, а также его процессорное время со всеми другими потоками, которые создаются программой в рамках одного ядра процессора. Программы на языке Python имеют, по умолчанию, один основной поток. Можно создать их больше и позволить Python переключаться между ними. Это переключение происходит очень быстро и кажется, что они работают параллельно.
Понятие процесс в multiprocessing — представляет собой также независимую последовательность выполнения вычислений. В отличие от потоков threading , процесс имеет собственное ядро и следовательно выделенную ему память, которое не используется совместно с другими процессами. Процесс может клонировать себя, создавая два или более экземпляра в одном ядре процессора.
Асинхронный ввод-вывод не является ни потоковым ( threading ), ни многопроцессорным ( multiprocessing ). По сути, это однопоточная, однопроцессная парадигма и не относится к параллельным вычислениям.
У Python есть одна особенность, которая усложняет параллельное выполнение кода. Она называется GIL, сокращенно от Global Interpreter Lock. GIL гарантирует, что в любой момент времени работает только один поток. Из этого следует, что с потоками невозможно использовать несколько ядер процессора.
GIL был введен в Python потому, что управление памятью CPython не является потокобезопасным. Имея такую блокировку Python может быть уверен, что никогда не будет условий гонки.
Что такое условия гонки и потокобезопасность?
- Состояние гонки возникает, когда несколько потоков могут одновременно получать доступ к общей структуре данных или местоположению в памяти и изменять их, вследствии чего могут произойти непредсказуемые вещи. Пример из жизни: если два пользователя одновременно редактируют один и тот же документ онлайн и второй пользователь сохранит данные в базу, то перезапишет работу первого пользователя. Чтобы избежать условий гонки, необходимо заставить второго пользователя ждать, пока первый закончит работу с документом и только после этого разрешить второму пользователю открыть и начать редактировать документ.
- Потокобезопасность работает путем создания копии локального хранилища в каждом потоке, чтобы данные не сталкивались с другим потоком.
Алгоритм планирования доступа потоков к общим данным.
Как уже говорилось, потоки используют одну и ту же выделенную память. Когда несколько потоков работают одновременно, то нельзя угадать порядок, в котором потоки будут обращаются к общим данным. Результат доступа к совместно используемым данным зависит от алгоритма планирования. который решает, какой поток и когда запускать. Если такого алгоритма нет, то конечные данные могут быть не такими как ожидаешь.
Например, есть общая переменная a = 2 . Теперь предположим, что есть два потока, thread_one и thread_two . Они выполняют следующие операции:
a = 2 # функция 1 потока def thread_one(): global a a = a + 2 # функция 2 потока def thread_two(): global a a = a * 3
Если поток thread_one получит доступ к общей переменной a первым и thread_two вторым, то результат будет 12:
или наоборот, сначала запустится thread_two , а затем thread_one , то мы получим другой результат:
Таким образом очевидно, что порядок выполнения операций потоками имеет значение
Без алгоритмов планирования доступа потоков к общим данным такие ошибки очень трудно найти и произвести отладку. Кроме того, они, как правило, происходят случайным образом, вызывая беспорядочное и непредсказуемое поведение.
Есть еще худший вариант развития событий, который может произойти без встроенной в Python блокировки потоков GIL . Например, если оба потока начинают читать глобальную переменную a одновременно, оба потока увидят, что a = 2 , а дальше, в зависимости от того какой поток произведет вычисления последним, в конечном итоге и будет равна переменная a (4 или 6). Не то, что ожидалось!
Исследование разных подходов к параллельным вычислениям в Python.
Определим функцию, которую будем использовать для сравнения различных вариантов вычислений. Во всех следующих примерах используется одна и та же функция, называемая heavy() :
def heavy(n): for x in range(1, n): for y in range(1, n): x**y
Функция heavy() представляет собой вложенный цикл, который выполняет возведение в степень. Это функция связана со скоростью ядра процессора производить математические вычисления. Если понаблюдать за операционной системой во время выполнения функции, то можно увидеть загрузку ЦП близкую к 100%.
Будем запускать эту функцию по-разному, тем самым исследуя различия между обычной однопоточной программой Python, многопоточностью и многопроцессорностью.
Однопоточный режим работы.
Каждая программа Python имеет по крайней мере один основной поток. Ниже представлен пример кода для запуска функции heavy() в одном основном потоке одного ядра процессора, который производит все операции последовательно и будет служить эталоном с точки зрения скорости выполнения:
import time def heavy(n): for x in range(1, n): for y in range(1, n): x**y def sequential(n): for i in range(n): heavy(500) print(f"n> циклов вычислений закончены") if __name__ == "__main__": start = time.time() sequential(80) end = time.time() print("Общее время работы: ", end - start) # 80 циклов вычислений закончены # Общее время работы: 23.573118925094604
Использование потоков threading .
В следующем примере будем использовать несколько потоков для выполнения функции heavy() . Также произведем 80 циклов вычислений. Для этого разделим вычисления на 4 потока, в каждом из которых запустим 20 циклов:
import threading import time def heavy(n, i, thead): for x in range(1, n): for y in range(1, n): x**y print(f"Цикл № i>. Поток thead>") def sequential(calc, thead): print(f"Запускаем поток № thead>") for i in range(calc): heavy(500, i, thead) print(f"calc> циклов вычислений закончены. Поток № thead>") def threaded(theads, calc): # theads - количество потоков # calc - количество операций на поток threads = [] # делим вычисления на `theads` потоков for thead in range(theads): t = threading.Thread(target=sequential, args=(calc, thead)) threads.append(t) t.start() # Подождем, пока все потоки # завершат свою работу. for t in threads: t.join() if __name__ == "__main__": start = time.time() # разделим вычисления на 4 потока # в каждом из которых по 20 циклов threaded(4, 20) end = time.time() print("Общее время работы: ", end - start) # Показано часть вывода # . # . # . # Общее время работы: 43.33752250671387
Однопоточный режим работы, оказался почти в 2 раза быстрее, потому что один поток не имеет накладных расходов на создание потоков (в нашем случае создается 4 потока) и переключение между ними.
Если бы у Python не было GIL, то вычисления функции heavy() происходили быстрее, а общее время выполнения программы стремилось к времени выполнения однопоточной программы. Причина, по которой многопоточный режим в данном примере не будет работать быстрее однопоточного — это вычисления, связанные с процессором и заключаются в GIL!
Если бы функция heavy() имела много блокирующих операций, таких как сетевые вызовы или операции с файловой системой, то применение многопоточного режима работы было бы оправдано и дало огромное увеличение скорости!
Это утверждение можно проверить смоделировав операции ввода-вывода при помощи функции time.sleep() .
import threading import time def heavy(): # имитации операций ввода-вывода time.sleep(2) def threaded(theads): threads = [] # делим операции на `theads` потоков for thead in range(theads): t = threading.Thread(target=heavy) threads.append(t) t.start() # Подождем, пока все потоки # завершат свою работу. for t in threads: t.join() print(f"theads> циклов имитации операций ввода-вывода закончены") if __name__ == "__main__": start = time.time() # 80 потоков - это неправильно и показано # чисто в демонстрационных целях threaded(80) end = time.time() print("Общее время работы: ", end - start) # 80 циклов имитации операций ввода-вывода закончены # Общее время работы: 2.008725881576538
Даже если воображаемый ввод-вывод делится на 80 потоков и все они будут спать в течение двух секунд, то код все равно завершится чуть более чем за две секунды, т. к. многопоточной программе нужно время на планирование и запуск потоков.
Примечание! Каждый процессор поддерживает определенное количество потоков на ядро, заложенное производителем, при которых он работает оптимально быстро. Нельзя создавать безгранично много потоков. При увеличении числа потоков на величину, большую, чем заложил производитель, программа будет выполняться дольше или вообще поведет себя непредсказуемым образом (вплоть до зависания).
Использование многопроцессорной обработки multiprocessing .
Теперь попробуем настоящую параллельную обработку с использованием модуля multiprocessing . Модуль multiprocessing во многом повторяет API модуля threading , поэтому изменения в коде будут незначительны.
Для того, чтобы произвести 80 циклов вычислений функции heavy() , узнаем сколько процессор имеет ядер, а потом поделим циклы вычислений на количество ядер.
import multiprocessing import time def heavy(n, i, proc): for x in range(1, n): for y in range(1, n): x**y print(f"Цикл № i> ядро proc>") def sequential(calc, proc): print(f"Запускаем поток № proc>") for i in range(calc): heavy(500, i, proc) print(f"calc> циклов вычислений закончены. Процессор № proc>") def processesed(procs, calc): # procs - количество ядер # calc - количество операций на ядро processes = [] # делим вычисления на количество ядер for proc in range(procs): p = multiprocessing.Process(target=sequential, args=(calc, proc)) processes.append(p) p.start() # Ждем, пока все ядра # завершат свою работу. for p in processes: p.join() if __name__ == "__main__": start = time.time() # узнаем количество ядер у процессора n_proc = multiprocessing.cpu_count() # вычисляем сколько циклов вычислений будет приходится # на 1 ядро, что бы в сумме получилось 80 или чуть больше calc = 80 // n_proc + 1 processesed(n_proc, calc) end = time.time() print(f"Всего n_proc> ядер в процессоре") print(f"На каждом ядре произведено calc> циклов вычислений") print(f"Итого n_proc*calc> циклов за: ", end - start) # Весь вывод показывать не будем # . # . # . # Всего 6 ядер в процессоре # На каждом ядре произведено 14 циклов вычислений # Итого 84 циклов вычислений за: 5.0251686573028564
Код выполнился почти в 5 раз быстрее. Это прекрасно демонстрирует линейное увеличение скорости вычислений от количества ядер процессора.
Использование многопроцессорной обработки с пулом.
Можно сделать предыдущую версию программы немного более элегантной, используя multiprocessing.Pool() . Объект пула, управляет пулом рабочих процессов, в который могут быть отправлены задания. Используя метод Pool.starmap() , можно произвести инициализацию функции sequential () для каждого процесса.
В целях эксперимента в функции запуска пула процессов pooled(core) предусмотрено ручное указание количества ядер процессора. Если не указывать значение core , то по умолчанию будет использоваться количество ядер процессора вашей системы, что является разумным выбором:
import multiprocessing import time def heavy(n, i, proc): for x in range(1, n): for y in range(1, n): x**y print(f"Вычисление № i> процессор proc>") def sequential(calc, proc): print(f"Запускаем поток № proc>") for i in range(calc): heavy(500, i, proc) print(f"calc> циклов вычислений закончены. Процессор № proc>") def pooled(core=None): # вычисляем количество ядер процессора n_proc = multiprocessing.cpu_count() if core is None else core # вычисляем количество операций на процесс calc = int(80 / n_proc) if 80 % n_proc == 0 else int(80 // n_proc + 1) # создаем список инициализации функции # sequential(calc, proc) для каждого процесса init = map(lambda x: (calc, x), range(n_proc)) with multiprocessing.Pool() as pool: pool.starmap(sequential, init) print (calc, n_proc, core) return (calc, n_proc, core) if __name__ == "__main__": start = time.time() # в целях эксперемента, укажем количество # ядер больше чем есть на самом деле calc, n_proc, n = pooled(20) end = time.time() text = '' if n is None else 'задано ' print(f"Всего text>n_proc> ядер процессора") print(f"На каждом ядре произведено calc> циклов вычислений") print(f"Итого n_proc*calc> циклов за: ", end - start) # Весь вывод показывать не будем # . # . # . # Всего задано 20 ядер процессора # На каждом ядре произведено 4 циклов вычислений # Итого 80 циклов за: 5.422096252441406
Из результатов работы видно, что время работы незначительно увеличилось.
Если запустить этот код, то можно проследить, что вычисления все равно происходят на том количестве ядер, которые имеются в процессоре. Только вычисления происходят поочередно — из за этого незначительное увеличение времени работы программы.
Выводы:
- Используйте модули threading или asyncio для программ, связанных с сетевым вводом-выводом, чтобы значительно повысить производительность.
- Используйте модуль multiprocessing для решения проблем, связанных с операциями ЦП. Этот модуль использует весь потенциал всех ядер в процессоре.
- КРАТКИЙ ОБЗОР МАТЕРИАЛА.
- Global Interpreter Lock (GIL)
Как работать с многоядерными процессорами в Python?
Собственно правильно ли я понимаю, что это вообще невозможно, так как из-за GIL в Python все потоки все равно будут делаться последовательно одним процессором? Актуально ли это для Python 3.4? Как обойти (писать код на C)?
- Вопрос задан более трёх лет назад
- 13286 просмотров
Комментировать
Решения вопроса 1
https://docs.python.org/2/library/multiprocessing.html — единственный известный мне способ утилизровать несколько ядер на питоне. GIL есть в обоих ветках питона, обойти никак (вроде, если я не ошибаюсь, написав экстеншн на С, Вы все равно будете вынуждены запускать его в тех же условиях).
Ответ написан более трёх лет назад
Нравится 6 2 комментария
iegor @iegor Автор вопроса
Т.е. для использования нескольких процессоров необходимо ветвить процессы, а не потоки? Модули subprocess и threading не подходят?
iegor: subprocess тоже позволит использовать несколько ядер процессора, но он используется для исполнения исполняемых файлов + имеет блокирующее апи (мультипроцессинг же позволяет выполнить определенную функцию, например, что куда удобней именно для целей распараллеливания). Т. е. если Вы в своем процессе вызываете сабпроцесс, то текущий процесс будет заблокирован ожиданием ответа, но в данном случае вам как раз поможет threading или какой-нибуль gevent. Вообще это довольно сложная тема. Вкратце попытаюсь объяснить: GIL не настолько портит жизнь как Вам кажется. К примеру, у вас есть задача спарсить 100 сайтов. Вы в главном потоке создаете через threading 4 потока и в каждый из них отправляете по 25 сайтов на парсинг. Управление получает первый поток — он вызывает какой-нибудь requests.get, который является блокирующей операцией. Соответственно текущий поток начинает ждать ответа. GIL в этот момент освобождает лок и другой поток начинает свое выполнение. И так повторяется для каждого потока. Получается пока происходит блокирующая операция в одном потоке, второй может работать. Естественно все это происходит только на одном ядре и не является полноценным мултитридингом, но если писать аккуратно и вдумчиво, то на блокирующих операциях даже при GIL с threading можно получить прирост производительности. Ну а вообще примите как факт, что питон не умеет утилизировать многоядерные процессы и жизнь станет проще 🙂
Ответы на вопрос 6

Sly_tom_cat . @Sly_tom_cat
from time import time
from threading import Thread
from multiprocessing import Process
def count(n):
while n > 0:
n -= 1
startTime = time()
count(100000000)
count(100000000)
print(‘\nSequential execution time : %3.2f s.’%(time() — startTime))
startTime = time()
t1 = Thread(target=count, args=(100000000,))
t2 = Thread(target=count, args=(100000000,))
t1.start(); t2.start()
t1.join(); t2.join()
print(‘\nThreaded execution time : %3.2f s.’%(time() — startTime))
startTime = time()
p1 = Process(target=count, args=(100000000,))
p2 = Process(target=count, args=(100000000,))
p1.start(); p2.start()
p1.join(); p2.join()
print(‘\nMultiprocessed execution time : %3.2f s.’%(time() — startTime))
Дает на 4-х ядерном проце:
Sequential execution time : 6.83 s.
Threaded execution time : 11.37 s.
Multiprocessed execution time : 6.30 s.
Но допустим распараллеливание запросов к http серверу и в thread варианте даст огромный выигрыш.
Т.е. без учета специфики задачи — в многопоточность/многопроцессорность — лучше просто не соваться.