Регулярные выражения в JavaScript: как они устроены и для чего нужны
Один разработчик выучил все регулярки и был причислен к лику святых.

Иллюстрация: Merry Mary для Skillbox Media

Максим Сафронов
Автор, редактор, IT-журналист. Рассказывает о новых технологиях, цифровых профессиях и полезных инструментах для разработчиков. Любит играть на электрогитаре и программировать на Swift.
Каждый день в интернете появляются гигабайты нового текста: статей, постов, комментариев, сообщений в чатах. Чтобы со всем этим можно было работать с помощью кода, используют регулярные выражения — о них сегодня и поговорим.
Что такое регулярные выражения
Регулярные выражения — это специальные комбинации символов для поиска и обработки текста. Механика у них простая: вы составляете шаблон слова, которое вам нужно, а программа находит все строки с этим словом. Чтобы искать точнее, для шаблонов можно задавать команды — например, найти все слова без учёта регистра.
Регулярные выражения в JavaScript обычно пишут между двумя наклонными чертами. А сразу за ними идут команды — их называют «флагами».

Специальные символы
Настало время разобраться, зачем нужны все эти фигурные скобки, доллары, слэши и прочие эльфийские руны.
Представьте: вы пришли в букинистический магазин, чтобы купить редкое издание «Войны и мира» Льва Толстого 1886 года. Чтобы не копаться в стеллажах самому, скорее всего, вы обратитесь за помощью к продавцу. Продавец знает, где в магазине что лежит, и в два счёта отыщет нужную книгу.
В случае с регулярками принцип тот же: вы говорите компьютеру, что нужно найти, задаёте условия, и он ищет. Но загвоздка в том, что машина не понимает слова и предложения: ей подавай простые формальные команды, и чем короче их можно записать, тем меньше памяти всё это будет потреблять.
Один специальный символ означает одно условие поиска. Чем больше условий, тем сложнее будут комбинации символов.
Допустим, у вас есть большая база резюме разработчиков и вы хотите достать оттуда все Telegram-никнеймы. Как это сделать?
Шаг 1. Найдём все никнеймы формата @username, состоящие из латинских букв. Выражение внутри квадратных скобок означает «любая строчная латинская буква».
Что дальше
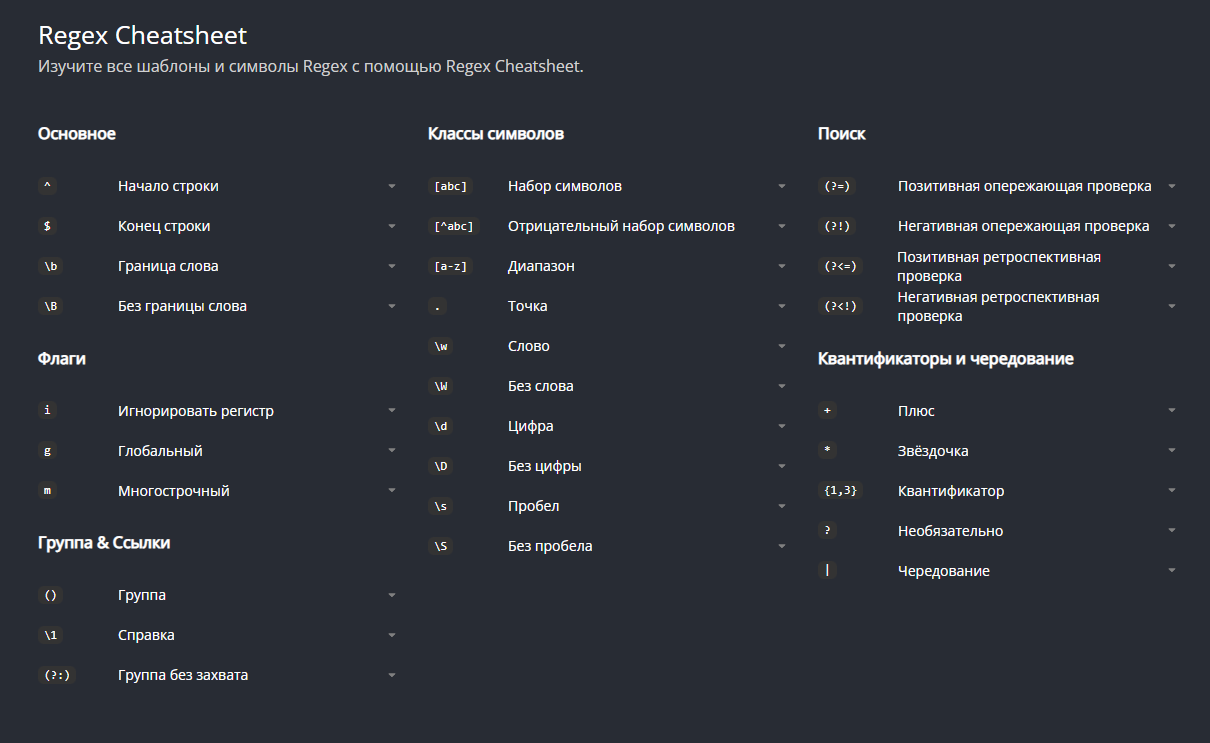
Чтобы изучить все возможности регулярок, никаких статей не хватит. Если хотите лучше в этом разбираться, почитайте книгу «Регулярные выражения» Джеффри Фридла — это хороший гайд для новичков с понятной теорией и примерами. Или попробуйте бесплатные тренажёры на сайте regexlearn.com — чтобы сразу практиковаться в изученном. Вот хорошая шпаргалка оттуда:
Читайте также:
- Гайд для начинающих: как писать на JavaScript
- Тест. Какой язык создадите вы — Java или Python?
- Что такое TypeScript и как его использовать
Как составлять регулярные выражения
Регулярное выражение — это последовательность символов (селекторов). Оно используется для поиска и обработки строк, слов, чисел и других текстовых данных.
Регулярные выражения выручают при решении разных задач. Например, с их помощью легко искать и менять строки в коде. Но чаще всего регулярные выражения используют для валидации форм. Давайте посмотрим, как это делать.
Шаблон регулярного выражения
Создать шаблон можно двумя способами. Выбирайте тот, что больше нравится:
Первый способ — через new RegExp() :
regularExpression = new RegExp("регулярное выражение", "флаги"); Второй способ — через слеши:
regularExpression = /регулярное выражение/флаги; Основные символы в регулярных выражениях
Посмотрим, чем наполнять шаблон регулярного выражения: какие селекторы использовать и что такое флаги.
Символы текста
Буквы и цифры — самые простые символы. Например, регулярное выражение оса найдет совпадение даже в слове «автосалон».
Символы начала и конца строки
Каретка ^ используется для обозначения начала строки, а доллар $ — для конца. К примеру, если мы напишем ^оса$ , то совпадением будет только со словом «оса».
Классы символов
С их помощью указываются диапазоны символов. То есть вы можете уточнить, какие буквы, цифры или знаки могут встречаться в регулярном выражении, а какие нет.
[^] — отрицание диапазона символов. Если коротко, вы можете исключить поиск конкретных символов. Например, [^оса] не найдёт совпадений со словом «оса», а вот с «осадками» совпадение будет.
- [0-9] — любая цифра от нуля до девяти;
- \d — тоже любая цифра, это эквивалент [0-9] .
- [а-яё] — любая буква кириллицы в нижнем регистре;
- [а-яёА-ЯЁ] — любая буква кириллицы в нижнем и верхнем регистре;
- [a-z] — любая буква на латинице в нижнем регистре;
- [a-zA-Z] — любая буква на латинице в нижнем и верхнем регистре;
- \w — любая цифра, латинская буква или знак подчёркивания.
Символы и знаки препинания:
- [. ;?!-] — знаки препинания.
- \s — пробел.
Квантификаторы
Эти селекторы проверяют количество повторений предыдущего символа или группы символов:
- — совпадение с точным количеством, где n — это положительное целое число. Например, конструкция [1-3] будет искать одну цифру от одного до трёх.
- — диапазон совпадений от минимального до максимального. Например, так можно указать минимальное и максимальное количество символов для ввода — . А ещё одно из значений можно пропустить — или .
- — одно или бесконечное количество совпадений. Этот селектор равнозначен записи `.
- + — одно или более повторений. Этот селектор равнозначен записи .
- ? — ни одного или одно повторение. Селектор равнозначен записи .
Модификаторы
Их ещё называют флагами. Это определённые параметры, которые задают настройки для поиска или замены текста.
Модификаторов много, мы перечислим лишь самые популярные:
- i — не учитывать регистр букв;
- g — искать все совпадения;
- u — поддержка юникод-символов.
Альтернация
Проще говоря, это условие. Альтернация обозначается символом | и указывает несколько вариантов, которые могут соответствовать регулярному выражению. Например, регулярное выражение (яблоко|банан) будет искать строки, содержащие либо слово «яблоко», либо «банан».
Символы группируются в скобках. При этом вы можете добавить условие «или» для любого количества символов: (a|b|c|d) .
�� Это лишь часть селекторов. Полный список вы найдёте на сайте MDN.
Как составить регулярное выражение
Сформулируйте условие. Например, вы хотите составить регулярное выражение для проверки логина. Этот логин должен быть длиннее трёх символов. Он может содержать буквы на кириллице и латинице или цифры. Регистр неважен.
Составьте выражение. Наполните шаблон селекторами, подходящими под ваши условия:
- Логин содержит буквы или цифры — /^[a-zа-яё0-9]/ .
- Слово должно быть не короче трёх символов, максимальной длины нет — /^[a-zа-яё0-9]/ .
- Регистр неважен — /^[a-zа-яё0-9]$/i .
Протестируйте регулярное выражение. Напишите собственные тесты или воспользуйтесь одним из онлайн-сервисов, например, regex101.
Регулярные выражения можно составить разными способами — даже два разработчика-коллеги напишут для одной и той же задачи что-то своё. Кому-то важна лаконичность — чем выражение короче, тем лучше. Кто-то хочет предусмотреть все варианты — например, вдруг пользователь введёт в логине нижнее подчёркивание. А кто-то просто хорошо знает возможности регулярок и гибко использует этот инструмент.
Примеры регулярных выражений
Регулярное выражение для номера телефона
Допустим, мы хотим проверить, что пользователь ввёл телефон в формате (XXX) XXX-XXXX . Можно составить следующее регулярное выражение: /^\d-\d-\d$/ . Здесь \d соответствует любой цифре, а фигурные скобки < и >указывают количество повторений.
Такое регулярное выражение будет соответствовать строкам, которые начинаются с открывающей скобки. За скобкой следуют три цифры, затем пробел, ещё три цифры, дефис и четыре цифры. Последним идёт символ конца строки.
✅ При проверке 123-456-7890 будет соответствовать шаблону, а (123) 456 7890 — нет.
Регулярное выражение для электронной почты
Составим регулярное выражение, которое проверяет формат почты username@domain.com — /^\w+([.-]?\w+)@\w+([.-]?\w+)(.\w)$/ . Выражение сложное, поэтому давайте посимвольно разбирать, что здесь происходит:
- ^ — начало строки.
- \w — любая буква, цифра или символ подчёркивания.
- + — указывает, что предыдущий символ (любая буква, цифра или символ подчёркивания) должен повторяться один или более раз.
- ([.-]?\w+)* — группа символов. Она начинается с точки, дефиса или ни одного из них ( ? ). За ними следует одна или более буквы, цифры или символы подчёркивания ( \w+ ). Звёздочка указывает, что эта группа может встречаться нуль или более раз.
- @ — символ собаки, он обязателен в адресе электронной почты.
- \w — любая буква, цифра или символ подчёркивания.
- ([.-]?\w+)* — аналогичная группа символов, как описано выше.
- . — просто точка.
- \w — любые буквы, цифры или символ подчёркивания.
- $ — конец строки.
Если коротко, это регулярное выражение будет соответствовать строкам, которые начинаются с одной или более буквы, цифры или символа подчёркивания. За ними следует символ @ . Затем идёт одна или более группа символов — она состоит из букв, цифр или подчёркивания, разделённых точкой. В конце — буквы, цифры или знак подчёркивания.
✅ При проверке example.email@mail.com будет соответствовать этому шаблону, а example.emailmail.com — нет.
Регулярное выражение для проверки имени человека
Предположим, мы хотим проверить, что введённое имя содержит только буквы и начинается с заглавной буквы. Для этого можно составить такое выражение: /^[А-Я][а-яё]*$/ . Здесь [А-Я] соответствует любой заглавной букве, а [а-яё] — любой букве в нижнем регистре. Звёздочка указывает, что предыдущий символ может повторяться нуль или более раз.
✅ При проверке имя Иван будет соответствовать шаблону, а иван — нет.
Заключение
Мы затронули лишь небольшую часть — основы регулярных выражений. Тема регулярок слишком обширна, чтобы рассказать обо всём в одной статье. Есть другие селекторы, модификаторы, да и сами регулярные выражения могут быть сложнее и интереснее.
�� Чтобы углубиться в тему, пройдите курс «Регулярные выражения для фронтенда». Он научит вас составлять регулярные выражения, чтобы писать меньше кода и работать быстрее.
Материалы по теме
- 3 способа валидации форм
- Зачем фронтендерам React, если есть JavaScript
- Частые ошибки в HTML-коде
«Доктайп» — журнал о фронтенде. Читайте, слушайте и учитесь с нами.
Как использовать регулярные выражения js
Ряд методов объекта String могут использовать регулярные выражения в качестве параметра.
Метод match
Для поиска всех соответствий в строке применяется метод match() :
const initialText = "Он пришел домой и сделал домашнюю работу"; const exp = /дом[а-я]*/gi; const result = initialText.match(exp); result.forEach(value => console.log(value)); // или так // console.log(result[0]); // console.log(result[1]);
Символ звездочки указывает на возможность наличия после строки «дом» неопределенного количества символов от а до я. В итоге в массиве result окажутся следующие слова:
домой домашнюю
С одной стороны, этот метод похож на метод exec() объекта RegExp за тем исключением, что exec() возвращает только первое вхождение:
const initialText = "Он пришел домой и сделал домашнюю работу"; const exp = /дом[а-я]*/gi; const result2 = exp.exec(initialText); result2.forEach(value => console.log(value));
Консольный вывод браузера:
домой
Разделение строки. Метод split
Метод split может использовать регулярные выражения для разделения строк. Например, разделим приложение по словам (а точнее по пробелам) с помощью метасимвола «\s»:
const initialText = "Сегодня была прекрасная погода"; const exp = /\s/; const result = initialText.split(exp); result.forEach(value => console.log(value));
Сегодня была прекрасная погода
Поиск в строке. Метод search
Метод search находит индекс первого включения соответствия в строке:
const initialText = "hello world"; const exp = /wor/; const result = initialText.search(exp); console.log(result); // 6
Замена. Методы replace
Метод replace позволяет заменить все соответствия регулярному выражению определенной строкой. Первый параметр метода — регулярное выражение, а второй — на что заменяем совпадения. Пример замены:
let menu = "Завтрак: каша, чай. Обед: суп, чай. Ужин: салат, чай."; const exp = /чай/gi; menu = menu.replace(exp, "кофе"); console.log(menu);
Завтрак: каша, кофе. Обед: суп, кофе. Ужин: салат, кофе.
Другая форма метода в качестве второго параметра принимает функцию замены. Эта функция принимает соответствие регулярному выражению и возвращает строку, на которое заменяется соответствие. Например, заменим чай на кофе только для завтрака:
let menu = "Завтрак: каша, чай. Обед: суп, чай. Ужин: салат, чай."; const exp = /чай/gi; let i = 0; menu = menu.replace(exp, function(tee)< if(i++ == 0) return "кофе"; else return tee; >); console.log(menu); // Завтрак: каша, кофе. Обед: суп, чай. Ужин: салат, чай.
Для индикатора замены используем счетчик — переменную i. Если она равна 0, то производим замену. В остальных случаях возвращаем соответствие — строку «чай».
Более сложный случай. Пусть у нас есть следующий текст:
Publication Date: 2021-09-06 Updated on: 2021-09-14
Здесь у нас применяются даты в формате yyyy-MM-dd. Допустим, нам надо изменить формат дат на «dd.MM.yyyy». Для этого определим следующую программу:
const exp = /\d-\d-\d/g; let text = "Publication Date: 2021-09-06\nUpdated on: 2021-09-14" text = text.replace(exp, function(date)< const arr = date.split("-"); return `$.$.$`; >); console.log(text);
Здесь мы извлекаем все соответствия регулярному выражению /\d-\d-\d/g . В методе replace в функции обратного вызова получаем соответствие через параметр date, с помощью функции split() разбиваем его на три части по разделителю-дефису:
const arr = date.split("-");
То есть у нас получаем массив из трех компонентов даты. И затем возвращаем дату в другом формате:
return `$.$.$`;
В итоге мы получим текст:
Publication Date: 06.09.2021 Updated on: 14.09.2021
Регулярные выражения
Регулярные выражения — это шаблоны, используемые для сопоставления последовательностей символов в строках. В JavaScript регулярные выражения также являются объектами. Эти шаблоны используются в методах exec (en-US) и test (en-US) объекта RegExp (en-US) а также match (en-US) , replace , search (en-US) , split (en-US) объекта String . Данная глава описывает регулярные выражения в JavaScript.
Создание регулярного выражения
Регулярное выражение можно создать двумя способами:
-
Используя литерал регулярного выражения, например:
var re = /ab+c/;
var re = new RegExp("ab+c");
Написание шаблона регулярного выражения
Шаблон регулярного выражения состоит из обычных символов, например /abc/ , или комбинаций обычных и специальных символов, например /ab*c/ или /Chapter (\d+)\.\d*/ . Последний пример включает в себя скобки, которые используются как «запоминающий механизм». Соответствие этой части шаблона запоминается для дальнейшего использования, как описано в Использование совпадений подстрок заключённых в скобки.
Использование простых шаблонов
Простые шаблоны используются для нахождения прямого соответствия в тексте. Например, шаблон /abc/ соответствует комбинации символов в строке только когда символы ‘abc’ встречаются вместе и в том же порядке. Такое сопоставление произойдёт в строке «Hi, do you know your abc’s?» и «The latest airplane designs evolved from slabcraft.» В обоих случаях сопоставление произойдёт с подстрокой ‘abc’. Сопоставление не произойдёт в строке «Grab crab», потому что она не содержит подстроку ‘abc’.
Использование специальных символов
В случае когда поиск соответствия требует чего-то большего, чем прямое сопоставление, например нахождение последовательности символов ‘b’ или нахождение пробела, шаблон включает в себя специальные символы. Например, шаблон /ab*c/ соответствует любой комбинации символов, в которой за ‘a’ следует ноль или более символов ‘b’ ( * означает ноль или более вхождений предыдущего символа), за которыми сразу же следует символ ‘c’. В строке «cbbabbbbcdebc,» этому шаблону сопоставляется подстрока ‘abbbbc’.
В следующей таблице приводится полный список специальных символов регулярных выражений с их описаниями.
- Для символов обычно обрабатываемых буквально, означает что следующий символ является специальным и не должен интерпретироваться буквально.
- Например, /b/ сопоставляется символу ‘b’. Добавляя слеш перед b, т.е используя /\b/ , символ становится специальным символом, означающим границу слова.
- Для символов обычно обрабатываемых особым образом означает, что следующий символ не является специальным и должен интерпретироваться буквально.
- Например, * является специальным символом, сопоставляемым 0 или более повторений предыдущего символа; например, /a*/ означает соответствие 0 или более символов а. Для буквальной интерпретации *, поставьте перед ней обратный слеш; например, /a\*/ соответствует ‘a*’.
- Также не забудьте заэкранировать сам \ при его использовании в записи new RegExp(«pattern») поскольку \ также является экранирующим символом в обычных строках.
Соответствует началу ввода. Если установлен флаг многострочности, также производит сопоставление непосредственно после переноса строки.
Например, /^A/ не соответствует ‘A’ в «an A», но соответствует ‘A’ в «An E».
Этот символ имеет другое значение при появлении в начале шаблона набора символов.
Например, /[^a-z\s]/ соответствует ‘I’ в «I have 3 sisters».
Соответствует концу ввода. Если установлен битовый флаг многострочности, также сопоставляется содержимому до переноса строки.
Например, /t$/ не соответствует ‘t’ в строке «eater», но соответствует строке «eat».
Соответствует предыдущему символу повторенному 0 или более раз. Эквивалентно .
Например, /bo*/ соответствует ‘boooo’ в «A ghost booooed» и ‘b’ в «A bird warbled», но не в «A goat grunted».
Соответствует предыдущему символу повторенному 1 или более раз. Эквивалентно .
Например, /a+/ соответствует ‘a’ в «candy» и всем символам ‘a’ в «caaaaaaandy».
0 или 1 раз. Эквивалентно .
Например, /e?le?/ соответствует ‘el’ в «angel» и ‘le’ в «angle» а также ‘l’ в «oslo».
Если использован сразу после квалификаторов * , + , ? , или <> , делает квалификатор «нежадным» (соответствующим минимальному количеству символов), в отличие от режима по умолчанию, являющимся «жадным» (соответствующим максимальному числу символов). Например, используя /\d+/ не глобальное сопоставление «123abc» возвращает «123», если использовать /\d+?/, только «1» будет возвращена.
Также используется в упреждающих утверждениях (assertions), описанных в строках x(?=y) и x(?!y) данной таблицы.
(десятичная точка) соответствует любому символу кроме переноса строки.
Например, /.n/ соответствует ‘an’ и ‘on’ в «nay, an apple is on the tree», но не ‘nay’.
Соответствует ‘x’ и запоминает это соответствие. Это называется захватывающие скобки.
Например, /(foo)/ соответствует ‘foo’ в «foo bar.» Сопоставленная строка может быть получена из элементов результирующего массива [1] , . [n] .
Соответствует ‘x’ только если за ‘x’ следует ‘y’. Это называется упреждение.
Например, /Jack(?=Sprat)/ соответствует ‘Jack’ только если за ним следует ‘Sprat’. /Jack(?=Sprat|Frost)/ соответствует ‘Jack’ только если за ним следует ‘Sprat’ или ‘Frost’. Тем не менее, ни ‘Sprat’ ни ‘Frost’ не являются частью сопоставленного результата.
Соответствует ‘x’ только если за ‘x’ не следует ‘y’. Это называется отрицательное упреждение.
Например, /\d+(?!\.)/ соответствует числу только если за ним не следует десятичная точка. Регулярное выражение /\d+(?!\.)/.exec(«3.141») сопоставит ‘141’ но не ‘3.141’.
Соответствует либо ‘x’ либо ‘y’.
Например, /green|red/ соответствует ‘green’ в «green apple» и ‘red’ в «red apple.»
n — положительное целое. Соответствует ровно n вхождениям предыдущего символа.
Например, /a/ не соответствует ‘a’ в «candy,» но соответствует всем а в «caandy,» первым двум а в «caaandy.»
m и n — положительные целые. Соответствует как минимум n и максимум m вхождениям предыдущего символа. При m=n=1 пропускается.
Например, /a/ ничему не соответствует в строке «cndy», символу ‘a’ в «candy,» двум а в «caandy,» и трём первым а в «caaaaaaandy». Отметим, что при сопоставлении «caaaaaaandy», совпадает «aaa», хотя изначальная строка содержит больше а.
Набор символов. Соответствует любому символу из перечисленных. Можно указать диапазон символов, используя тире. Специальные символы (как точка ( . ) и звёздочка ( * )) не имеют специального значения внутри такого набора. Их не надо экранировать. Экранирование работает также.
Например, [abcd] эквивалентна [ a-d] . Они соответствуют ‘b’ в «brisket» и ‘c’ в «city». /[a-z.]+/ и /[\w.]+/ обе соответствуют всему в «test.i.ng».
Инвертированный или дополняющий набор символов. Это означает соответствие всему, что не в скобках. Можно указать диапазон символов с помощью тире. Все, что действует в обычном наборе символов, действует и здесь.
Например, [^abc] эквивалентно [^a-c] . Они соответствуют изначально ‘r’ в «brisket» и ‘h’ в «chop.»
Соответствует границе слова. Граница слова соответствует позиции, где за символом слова не следует другой символ слова или предшествует ему. Отметим, что граница слова не включается в соответствие. Другими словами, длина сопоставленной границы слова равна нулю. (Не путать с [\b] .)
Примеры:
/\bmoo/ соответствует ‘moo’ в слове «moon» ;
/oo\b/ не соответствует ‘oo’ в слове «moon», поскольку за ‘oo’ следует символ ‘n’ , являющимся символом слова;
/oon\b/ соответствует ‘oon’ в слове «moon», поскольку ‘oon’ является окончанием строки, и таким образом, за этими символами не следует другой символ слова;
/\w\b\w/ никогда не будет ничему соответствовать, поскольку за символом слова никогда не может следовать и граница слова, и символ слова.
Note: JavaScript’s regular expression engine defines a specific set of charactersto be «word» characters. Any character not in that set is considered a word break. This set of characters is fairly limited: it consists solely of the Roman alphabet in both upper- and lower-case, decimal digits, and the underscore character. Accented characters, such as «é» or «ü» are, unfortunately, treated as word breaks.
Соответствует несловообразующей границе. Несловообразующая граница соответствует позиции, в которой предыдущий и следующий символы являются символами одного типа: либо оба должны быть словообразующими символами, либо несловообразующими. Начало и конец строки считаются несловообразующими символами.
Например, /\B../ соответствует ‘oo’ в слове «noonday» (, а /y\B./ соответствует ‘ye’ в «possibly yesterday.»
Где X является символом случайного выбора из последовательности от А до Я. Соответствует управляющему символу в строке.
Например, /\cM/ соответствует control-M (U+000D) в строке.
Соответствует цифровому символу. Эквивалентно выражению [0-9] .
Например, /\d/ or /[0-9]/ соответствует ‘2’ в «B2 is the suite number.»
Соответствует любому нецифровому символу. Эквивалентно выражению [^0-9] .
Например, /\D/ or /[^0-9]/ соответствует ‘B’ в предложении «B2 is the suite number.»
Соответствует символу прогона страницы (U+000C). Особый символ управления печатью.
Соответствует одиночному символу пустого пространства, включая пробел, табуляция, прогон страницы, перевод строки. Эквивалентен [ \f\n\r\t\v\u00A0\u1680\u180e\u2000\u2001\u2002\u2003\u2004\u2005\u2006\u2007\u2008\u2009\u200a\u2028\u2029\u2028\u2029\u202f\u205f\u3000] .
Например, /\s\w*/ совпадает с ‘ bar’ в «foo bar.»
Соответствует одиночному символу непустого пространства. Эквивалентен [^ \f\n\r\t\v\u00A0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000] .
Например, /\S\w*/ совпадает с ‘foo’ в «foo bar.»
Соответствует любому цифробуквенному символу включая нижнее подчёркивание. Эквивалентен [A-Za-z0-9_] .
Например, /\w/ совпадает с ‘a’ в «apple,» ‘5’ в «$5.28,» и ‘3’ в «3D.»
Соответствует любому не цифробуквенному символу. Равносилен [^A-Za-z0-9_] .
Например, /\W/ or /[^A-Za-z0-9_]/ совпадает с ‘%’ в «50%.»
Где n это положительное целое, обратная ссылка на последнюю найденную подстроку, соответствующую n , заключённую в круглые скобки в регулярном выражении (считая левые скобки).
Например, /apple(,)\sorange\1/ соответствует ‘apple, orange,’ в «apple, orange, cherry, peach.»
Экранирование пользовательского ввода, соответствующего буквенной строке внутри регулярного выражения, может быть достигнуто простой заменой:
function escapeRegExp(string) return string.replace(/[.*+?^$<>()|[\]\\]/g, "\\$&"); // $& means the whole matched string >
Использование скобок
Скобки вокруг любой части регулярного выражения означают что эта часть совпадаемой подстроки будет запомнена. Раз запомнена, подстрока может выбрана для использования как это описано в Using Parenthesized Substring Matches.
Например, паттерн /Chapter (\d+)\.\d*/ включает в себя дополнительные экранирующие и специальные символы и указывает на то, что часть шаблона должна быть запомнена. Он точно соответствует символам слова ‘Chapter ‘, за которыми следует один или более цифровых символов ( \d означает любой цифровой символ, а ‘ +’ означает 1 или более раз), за которым следует десятичная точка (сама по себе являющаяся специальным символом; предшествующий десятичной точке слеш ‘ \’ означает, что паттерн должен искать литеральный символ ‘.’), после которой следует любой цифровой символ 0 или более раз (‘ \d’ обозначает цифровой символ, ‘ *’ обозначает 0 или более раз). Кроме того, круглые скобки используются для запоминания первых же совпавших цифровых символов.
Этот шаблон будет найден во фразе «Open Chapter 4.3, paragraph 6» и цифра ‘4’ будет запомнена. Но он не будет найден во фразе «Chapter 3 and 4», поскольку эта строка не имеет точки после цифры ‘3’.
Для того, чтобы сопоставить подстроку без вызова совпавшей части для запоминания, внутри круглых скобок необходимо предварить паттерн сочетанием символов ‘ ?:’ . Например, шаблон (?:\d+) будет соответствовать одному или более цифровому символу, но не запомнит совпавших символов.
Работа с Регулярными Выражениями
Регулярные выражения используются в методах test и exec объекта RegExp и с методами match , replace , search , и split объекта String . Эти методы подробно объясняются в Справочнике JavaScript
| Метод | Описание |
|---|---|
| exec (en-US) | Метод RegExp, который выполняет поиск совпадения в строке. Он возвращает массив данных. |
| test (en-US) | Метод RegExp , который тестирует совпадение в строке. Возвращает либо истину либо ложь. |
| match (en-US) | Метод String , который выполняет поиск совпадения в строке. Он возвращает массив данных либо null если совпадения отсутствуют. |
| search (en-US) | Метод String, который тестирует на совпадение в строке. Он возвращает индекс совпадения, или -1 если совпадений не будет найдено. |
| replace | Метод String , который выполняет поиск совпадения в строке, и заменяет совпавшую подстроку другой подстрокой, переданной как аргумент в этот метод. |
| split (en-US) | Метод String, который использует регулярное выражение или фиксированную строку чтобы разбить строку на массив подстрок. |
Чтобы просто узнать есть ли в строке что либо соответствующее шаблону, воспользуйтесь методами test или search ; а чтобы получить больше информации пользуйтесь методами exec или match (хотя эти методы работают медленнее). Если вы пользуетесь exec или match и если совпадения есть, эти методы вернут массив и обновлённые свойства объекта ассоциированного регулярного выражения а также предопределённого объекта RegExp регулярного выражения. Если совпадений нет, метод exec вернёт null (который сконвертируется в false ).
В след. примере, скрипт использует метод exec чтобы найти совпадения в строке.
var myRe = /d(b+)d/g; var myArray = myRe.exec("cdbbdbsbz");
Если вам не нужен доступ к свойствам регулярного выражения, то альтернативный способ получить myArray можно так:
var myArray = /d(b+)d/g.exec("cdbbdbsbz");
Если вы хотите сконструировать регулярное выражение из строки, другой способ сделать это приведён ниже:
var myRe = new RegExp("d(b+)d", "g"); var myArray = myRe.exec("cdbbdbsbz");
С помощью этих скриптов, поиск совпадения завершается и возвращает массив и обновлённые свойства показанные в след. таблице.
| Объект | Свойство или индекс | Описание | В этом примере. |
|---|---|---|---|
| myArray | Совпавшая строка и все запомненные подстроки. | [«dbbd», «bb»] | |
| index | Индекс совпавшей подстроки (индекс начинается с нуля). | 1 | |
| input | Исходная строка. | «cdbbdbsbz» | |
| [0] | Последние совпавшие символы. | «dbbd» | |
| myRe | lastIndex | Индекс с которого начнётся след. поиск совпадения. (Это свойство определяется только если регулярное выражение использует параметр g, описанный в [Advanced Searching With Flags](#Advanced_Searching_With_Flags).) | 5 |
| source | Текст шаблона. Обновляется в момент создания регулярного выражения, а не во время выполнения. | «d(b+)d» |
Как показано во втором варианте этого примера, вы можете использовать регулярное выражение, созданное при помощи инициализатора объекта, без присваивания его переменной. Таким образом, если вы используете данную форму записи без присваивания переменной, то в процессе дальнейшего использования вы не можете получить доступ к свойствам данного регулярного выражения. Например, у вас есть следующий скрипт:
var myRe = /d(b+)d/g; var myArray = myRe.exec("cdbbdbsbz"); console.log("The value of lastIndex is " + myRe.lastIndex);
Этот скрипт выведет:
The value of lastIndex is 5
Однако, если у вас есть следующий скрипт:
var myArray = /d(b+)d/g.exec("cdbbdbsbz"); console.log("The value of lastIndex is " + /d(b+)d/g.lastIndex);
The value of lastIndex is 0
Совпадения /d(b+)d/g в двух случаях являются разными объектами регулярного выражения и, следовательно, имеют различные значения для свойства lastIndex . Если вам необходим доступ к свойствам объекта, созданного при помощи инициализатора, то вы должны сначала присвоить его переменной.
Использование скобочных выражений для нахождения подстрок
Использование скобок в шаблоне регулярного выражения повлечёт «запоминание» совпавшей подстроки. Для примера, /a(b)c/ вызовет совпадение ‘abc’ и запомнит ‘b’. Чтобы получить совпадения скобочного выражения используйте Array elements [1] , . [n] .
Число возможных скобочных подстрок неограничено. Возвращаемый массив содержит все полученные совпадения, удовлетворяющие выражению в скобках. Следующий пример показывает как использовать скобочные выражения для нахождения подстрок.
Следующий скрипт использует метод replace(), чтобы поменять местами слова (символы) в строке. Для замены текста скрипт использует обозначения $1 и $2 для обозначения первого и второго совпадения скобочного выражения.
var re = /(\w+)\s(\w+)/; var str = "John Smith"; var newstr = str.replace(re, "$2, $1"); console.log(newstr);
Выведет «Smith, John».
Расширенный поиск с флагами
Регулярные выражения имеют четыре опциональных флага, которые делают возможным глобальный и регистронезависимый поиск. Флаги могут использоваться самостоятельно или вместе в любом порядке, а также могут являться частью регулярного выражения.
| Flag | Description |
|---|---|
| g | Глобальный поиск. |
| i | Регистронезависимый поиск. |
| m | Многострочный поиск. |
| y | Выполняет поиск начиная с символа, который находится на позиции свойства lastindex текущего регулярного выражения. |
Чтобы использовать флаги в шаблоне регулярного выражения используйте следующий синтаксис:
var re = /pattern/flags;
var re = new RegExp("pattern", "flags");
Обратите внимание, что флаги являются неотъемлемой частью регулярного выражения. Флаги не могут быть добавлены или удалены позднее.
Для примера, re = /\w+\s/g создаёт регулярное выражение, которое ищет один или более символов, после которых следует пробел и ищет данное совпадение на протяжении всей строки.
var re = /\w+\s/g; var str = "fee fi fo fum"; var myArray = str.match(re); console.log(myArray);
Выведет [«fee «, «fi «, «fo «]. В этом примере вы бы могли заменить строку:
var re = /\w+\s/g;
var re = new RegExp("\\w+\\s", "g");
и получить тот же результат.
Флаг m используется, чтобы входная строка рассматривалась как многострочная. Если флаг m используется, то ^ и $ вызовет совпадение в начале или конце любой строки в строке ввода вместо начала или конца вводимой строки целиком.
Примеры
След. примеры показывают использование регулярных выражений.
Изменение порядка в Исходной Строке
След. пример иллюстрирует формирование регулярного выражения и использование string.split() и string.replace() . Он очищает неправильно сформатированную исходную строку, которая содержит имена в неправильном порядке (имя идёт первым) разделённые пробелами, табуляцией и одной точкой с запятой. В конце, изменяется порядок следования имён (фамилия станет первой) и сортируется список.
// The name string contains multiple spaces and tabs, // and may have multiple spaces between first and last names. var names = "Harry Trump ;Fred Barney; Helen Rigby ; Bill Abel ; Chris Hand "; var output = ["---------- Original String\n", names + "\n"]; // Prepare two regular expression patterns and array storage. // Split the string into array elements. // pattern: possible white space then semicolon then possible white space var pattern = /\s*;\s*/; // Break the string into pieces separated by the pattern above and // store the pieces in an array called nameList var nameList = names.split(pattern); // new pattern: one or more characters then spaces then characters. // Use parentheses to "memorize" portions of the pattern. // The memorized portions are referred to later. pattern = /(\w+)\s+(\w+)/; // New array for holding names being processed. var bySurnameList = []; // Display the name array and populate the new array // with comma-separated names, last first. // // The replace method removes anything matching the pattern // and replaces it with the memorized string—second memorized portion // followed by comma space followed by first memorized portion. // // The variables $1 and $2 refer to the portions // memorized while matching the pattern. output.push("---------- After Split by Regular Expression"); var i, len; for (i = 0, len = nameList.length; i len; i++) output.push(nameList[i]); bySurnameList[i] = nameList[i].replace(pattern, "$2, $1"); > // Display the new array. output.push("---------- Names Reversed"); for (i = 0, len = bySurnameList.length; i len; i++) output.push(bySurnameList[i]); > // Sort by last name, then display the sorted array. bySurnameList.sort(); output.push("---------- Sorted"); for (i = 0, len = bySurnameList.length; i len; i++) output.push(bySurnameList[i]); > output.push("---------- End"); console.log(output.join("\n"));
Использование спецсимволов для проверки входных данных
В след. примере, ожидается что пользователь введёт телефонный номер и требуется проверить правильность символов набранных пользователем. Когда пользователь нажмёт кнопку «Check», скрипт проверит правильность введённого номера. Если номер правильный (совпадает с символами определёнными в регулярном выражении), то скрипт покажет сообщение благодарности для пользователя и подтвердит номер. Если нет, то скрипт проинформирует пользователя, что телефонный номер неправильный.
Внутри незахватывающих скобок (?: , регуляное выражение ищет три цифры \d ИЛИ | открывающую скобку \( , затем три цифры \d , затем закрывающую скобку \) , (закрывающая незахватывающая скобка ) ), затем тире, слеш, или десятичная точка, и когда это выражение найдено, запоминает символ ([-\/\.]) , следующие за ним и запомненные три цифры \d , следующее соответствие тире, слеша или десятичной точки \1 , и следующие четыре цифры \d .
Регулярное выражение ищет сначала 0 или одну открывающую скобку \(? , затем три цифры \d , затем 0 или одну закрывающую скобку \)? , потом одно тире, слеш или точка и когда найдёт это, запомнит символ ([-\/\.]) , след. три цифры \d , followed by the remembered match of a dash, forward slash, or decimal point \1 , followed by four digits \d .
Событие «Изменить» активируется, когда пользователь подтвердит ввод значения регулярного выражения, нажав клавишу «Enter».
doctype html> html> head> meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1" /> meta http-equiv="Content-Script-Type" content="text/javascript" /> script type="text/javascript"> var re = /\(?\d \)?([-\/\.])\d \1\d /; function testInfo(phoneInput) var OK = re.exec(phoneInput.value); if (!OK) window.alert(RegExp.input + " isn't a phone number with area code!"); else window.alert("Thanks, your phone number is " + OK[0]); > script> head> body> p> Enter your phone number (with area code) and then click "Check". br />The expected format is like ###-###-####. p> form action="#"> input id="phone" />button onclick="testInfo(document.getElementById('phone'));"> Check button> form> body> html>
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 7 авг. 2023 г. by MDN contributors.