как сделать php парсер
Пожалуйста, уточните вашу конкретную проблему или приведите более подробную информацию о том, что именно вам нужно. В текущем виде сложно понять, что именно вы спрашиваете.
23 дек 2022 в 14:02
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
- Первым делом открываем консоль браузера.
- Идём в закладку с сетевыми запросами и в момент вызова страницы и переходов по ссылкам пагинатора ищем нужные нам ответы. Упс.) Оказывается, что они находятся не HTML-формате, а в прекрасном и более удобном для парсинга JSON, да и правильная ссылка совсем другая.
- После чего, глядя на сам запрос с так необходимыми вам ответами, пытаемся его эмулировать в Postman В вашем случае видим, что это POST-запрос, с «телом» json.
И, вуаля — как-то так:
$curl = curl_init(); curl_setopt_array($curl, array( CURLOPT_URL => 'https://www.pexpay.com/bapi/c2c/v1/friendly/c2c/ad/search', CURLOPT_RETURNTRANSFER => true, CURLOPT_FOLLOWLOCATION => true, CURLOPT_CUSTOMREQUEST => 'POST', CURLOPT_POSTFIELDS =>'< asset: "USDT", classifies: [], fiat: "RUB", filter: < payTypes: [] >, payTypes: [], page: 6, payTypes: [], rows: 10, tradeType: "BUY" >', CURLOPT_HTTPHEADER => array( 'Content-Type: application/json' ), )); $response = curl_exec($curl); curl_close($curl); echo $response; Парсинг в PHP: что нужно знать новичкам
Серверная разработка требует от программиста определенного спектра знаний и навыков. Весьма полезным покажется парсер. Главное разобраться, каким образом его реализовать на PHP.
Статья расскажет о том, что такое парсинг, для чего он нужен и как функционирует. В ней будут приведены наглядные примеры, которые пригодятся для любого URL при веб-разработке.
Parsing – это…
Парсер – программное обеспечение, которое осуществляет анализ входных текстовых сведений. После этого занимается извлечением необходимой информации, на основе которых будет производиться результат в заранее заданном формате.
На PHP parser работает так:
- скрипт создает запрос по URL;
- осуществляется получение ответа от сервера в виде HTML или ином текстовом формате;
- сведения анализируются;
- из электронных материалов URL извлекаются (парсятся) нужные элементы;
- формируется и выводится результат.
Итог можно записывать в файлы и базы данных, а также непосредственно выводить на дисплей устройства.
Для чего необходим
При изучении парсеров в PHP стоит выяснить, для чего они вообще нужны. Подобное программное обеспечение:
- Автоматизируют информацию в пределах URL.
- Собирают и обрабатывают большие объемы данных.
- Сравнивают содержимое страниц с заданными параметрами. Пример – поисковые системы.
- Помогают организовывать спам-рассылку.
А еще парсером на PHP можно наполнять собственные веб-ресурсы «чужим» контентом. Подобные проекты стараются блокировать, но это не всегда выходит быстро.
Parser избавляет от перепечатывания информации однотипного характера. Пример – наполнение интернет-магазина тем или иным товаром.
Основа функционирования
Если мы парсим текст, не стоит думать, что парсер будет его читать. Соответствующее ПО:
- получает набор команд и инструкций от разработчика;
- считывает слова;
- сравнивает то, что обнаружено в Сети согласно заданным принципам.
Далее происходит непосредственная обработка. То, как робот ведет себя с информацией командной строки, носит название регулярного выражения. В русском языке также встречается в виде понятий «маски» и «шаблоны».
Для того, чтобы парсер воспринимал регулярные выражения, он должен быть составлен на языке, который поддерживает оные при использовании строк. PHP – один из вариантов, который пользуется спросом.
Регулярные выражения для URL прописываются через синтаксис Unix. Он уже устарел и редко применяется на практике при разработке софта. Но за счет свойств обратной совместимости по сей день Юникс задействован программистами и системными администраторами.
За счет Unix можно регулировать активность parsing. В зависимости от соответствующего значения будет меняться длина строки, копируемой с веб-страницы. Сверхжадный парсинг может считывать весь контент, а также HTML-кодификацию и внешние таблицы CSS.
Почему PHP
PHP – язык программирования, который используется для работы с веб-контентом. Позволяет создавать разнообразный софт: от бизнес-аналитики до игр. Его функции позволяют контактировать с парсерами максимально комфортно:
- Наличие библиотеки libcurl. Она отвечает за подключение скрипта ко всем видам серверов (даже при работе с http протоколами).
- Поддержка регулярных выражений. За их счет парсер осуществляет обработку информации.
- Наличие библиотеки DOM, используемой для работы с XML-расширяемым языком разметки текста. Он пригодится при выводе результатов обработки информации.
- Высокая совместимость с HTML.
При запуске URL сайта и внедрения парсера PHP станет настоящим спасением. Это не слишком сложный, но очень мощный язык.
Parse URL – особенности
Parse_url – функция, которая разбирает URL, а затем осуществляет возврат его компонентов. Применяется в PHP 4, 5, 7.
Стоит запомнить ее следующие особенности:
- mixed parse_url (string $url [int $component = -1]) – функция, которая разбирает URL и возвращает ассоциативный массив со всеми компонентами соответствующего адрес в Сети;
- не позволяет проверять корректность URL;
- разбивает адрес на части.
Parse_url старается разобрать частичные URL предельно корректно.
О параметрах
У рассматриваемой функции есть несколько параметров. Первый – URL.. Это – адрес для разбора. Символы, которые воспринимаются парсером как недопустимые, будут заменяться на подчеркивание.
Component – возможность считывания конкретного элемента адреса в виде строчки. Исключение – php_url_port. Этот вариант предусматривает возврат значения int.
Возвращаемые значения
Если URLs значительно некорректные, парсер может вернуть значение False. Когда component опускается, функция будет возвращать ассоциативный массив. В нем расположен хотя бы один элемент.
В массиве ассоциативного характера (array) могут встречаться такие ключи:
- scheme – пример: http;
- port;
- host;
- pass;
- user;
- query – после знака вопроса;
- fragment – после знака «решетка».
При определении component функция parse_url() вернет строчку или число вместо массива. Когда запрошенный элемент отсутствует в URL, «операция» возвращает значение null (пусто, ничего).
Наглядные примеры – CURL и phpQuery
Если нужно осуществить парсинг сайта, можно использовать для этого библиотеку CURL. Второй вариант – phpQuery, который представлен аналогом jQuery для PHP. Каждый подход имеет собственные преимущества.
Предварительная подготовка
Парсинг на сайте (ru) может быть проведен при помощи функции file_get_content. Помогает получить содержимое необходимой разработчику странички:

В качестве параметра используется желаемый адрес. Аналогичная функция помогает добавлять заголовки через потоковый контекст:
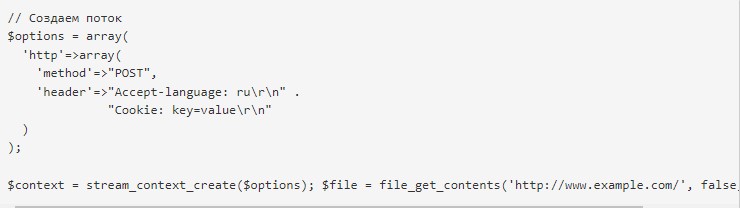
Для запуска соответствующего метода опция allow_url_fopen в php.ini должна быть активирована.
Второй вариант получения содержимого – через сокеты (pfsockopen). Но лучше использовать библиотеку php CURL.
CURL и парсинг
Теперь настало время запуска парсинга. Первый подход – с помощью CURL. Действовать предстоит следующим образом:
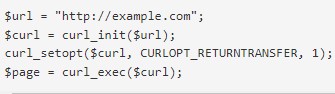
- Сначала требуется получить http страницы без параметров.
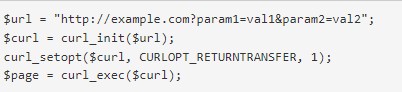
- Получение http странички с get-параметрами.
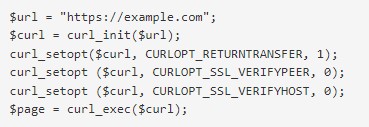
- Получение веб-ресурса по протоколам https.
- Извлечение http, которая будет загружаться непосредственно через редиректы (следование 302).

- Нужно сформировать POST-запрос и отправить его. Делаются подобные операции через CURL.
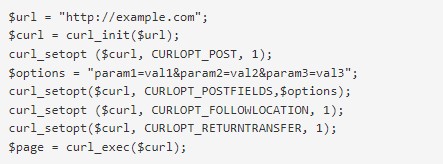
- Требуется активировать куки в запросе.
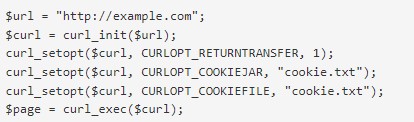
- В запросе GZIP активировать функцию сжатия. Требуется, когда тело ответа – это непонятный набор текста.
![]()
- Вывод заголовков ответов от сервера. Помогает при отладке. Пример – когда сервер не присылает правильное тело ответа или вовсе не дает его.
![]()
При парсинге огромную роль играют следующие параметры:

Первый будет всегда в «приложении». Остальные добавляются по мере необходимости. Параметр curlopt_header отвечает за поиск проблем. С ним наладить функционирование парсера php curl не составит никакого труда.
PhpQuery – принцип работы
Второй вариант применения парсинга – через phpQuery. Помогает тогда, когда страничка получена через CURL или иным методом.
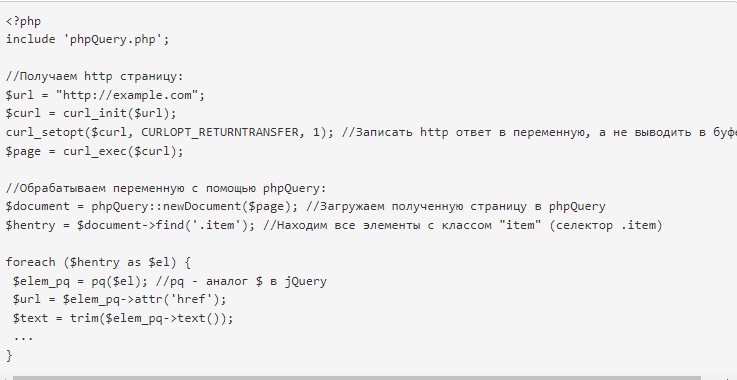
Код выше наглядно показывает, как создать парсер на php через phpQuery. Он выступает полноценным аналогом iQuery. Все функции соответствующей «возможности» прописаны в сопутствующей документации. По этой ссылке можно обнаружить селекторы и методы. А здесь – еще несколько кодов парсеров.
Быстрее освоиться в parsers, а также таких понятиях как print_r, echo, curl и других помогут специализированные дистанционные курсы. В срок от пары месяцев до года удастся освоить программирование «с нуля».
Как написать парсер для сайта

Недавно мне была поставлена задача написать php парсер сайта. Поставленная задача была выполнена и благодаря ей появилась эта заметка. До этого я ничего подобного не делал, так что не судите строго. Это мой первый парсер php.
И так с чего начать решение вопроса «как написать парсер». Давайте для начала разберёмся что это такое. В простонародье парсер(parser) или синтаксический анализатор — это программа которая получает данные (например веб страница), как то их анализирует структурирует, делает выборку и потом проводит какие то операции с ними (пишем данные в файл, в БД или выводим на экран). Данную задачу нам нужно выполнить в рамках веб программирования.
Для заметки я придумал такую тестовую задачу. Нужно спарсить по определённому поисковому запросу ссылки на сайты с 5 первых страниц выдачи и вывести их на экран. Парсить я решил выдачу поисковой системы bing. А почему бы не написать парсер яндекса или гугла спросите вы. Такие матёрые поисковики имеют не хилую защиту от парсинго(капча, бан ip, меняющаяся разметка, куки и тд), и это тема отдельной статьи. В этом плане с бингом таких проблемм нет. И так что нам нужно будет сделать:
- Получить (спарсить) контент html страницы средствами php
- Получить интересующие нас данные(а конкретно ссылки)
- Спарсить постраничную навигацию и получить ссылку на следующую страницу
- Опять спарсить страницу по ссылке, получить данные, получить следующую ссылку
- Проделать выше описанную операцию N количество раз
- Вывести все полученные ссылки на экран
Получение и парсинг страницы
Сначала напишем функцию, потом её разберём
function getBingLink($link)< $url="https://www.bing.com/search"; //получаем контент сайта $content= file_get_contents($url.$link); //убираем вывод ошибок libxml_use_internal_errors(true); //получаем объект класса DOMDocument $mydom = new DOMDocument(); //задаём настройки $mydom->preserveWhiteSpace = false; $mydom->resolveExternals = false; $mydom->validateOnParse = false; //разбираем HTML $mydom->loadHTML($content); //получаем объект класса DOMXpath $xpath = new DOMXpath($mydom); //делаем выборку с помощью xpath $items=$xpath->query("//*[@class='b_algo']/h2/a"); //выводим в цикле полученные ссылк static $a=1; foreach ($items as $item)< $link=$item->getAttribute('href'); echo $a."-".$link."
"; $a++; > >
И так разберём функцию. Для получения контента сайта используем php функцию file_get_contents($url.$link) . В неё подставляем адрес запроса. Есть ещё много методов получения контента html страницы, например cUrl, но на мой взгляд file_get_contents самый простой. Потом вызываем объект DOMDocument и так далее. Это всё стандартно и об этом можно почитать в интернете поподробнее. Хочу заакцентировать внимание на методе выборки нужных нам элементов. Для этой цели я использую xpath. Мою xpath шпаргалку можно глянуть здесь. Есть и другие методы выборки такие как регулярные выражения, Simple HTML DOM, phpQuery. Но на мой взгляд лучше разобраться с xpath, это даст дополнительные возможности при работе с xml документами, синтаксис полегче чем с регулярными выражениями, в отличии от css селекторов можно найти элемент по находящемуся в нём тексту. Для примера прокомментирую выражение //*[@class=’b_algo’]/h2/a . Подробнее синтаксис можно посмотреть в моей шпаргалке xpath. Мы выбираем со всей страницы ссылки лежащие в теге h2 в диве с классом b_algo . Сделав выборку мы получим массив и которого в цикле выведем на экран все полученные ссылки.
Парсинг постраничной навигации и получение ссылки на следующую страницу
Напишем новую функцию и по традиции разберём её позже
function getNextLink($link)< $url="https://www.bing.com/search"; $content= file_get_contents($url.$link); libxml_use_internal_errors(true); $mydom = new DOMDocument(); $mydom->preserveWhiteSpace = false; $mydom->resolveExternals = false; $mydom->validateOnParse = false; $mydom->loadHTML($content); $xpath = new DOMXpath($mydom); $page = $xpath->query("//*[@class='sb_pagS']/../following::li[1]/a"); foreach ($page as $p)< $nextlink=$p->getAttribute('href'); > return $nextlink; >
Почти идентичная функция, изменился только xpath запрос. //*[@class=’sb_pagS’]/../following::li[1]/a получаем элемент с классом sb_pagS ( это класс активной кнопки постраничной навигации), поднимаемся на элемент вверх по dom дереву, получаем первый соседний элемент li и получаем в нём ссылку. Эта и есть ссылка на следующую страницу.
Парсим выдачу N количество раз
function getFullList($link) < static $j=1; getBingLink($link); $nlink=getNextLink($link); if($j<5)< $j++; getFullList($nlink); >>
Данная функция вызывает getBingLink($link) и getNextLink($link) пока не кончится счётчик j. Функция рекурсивная, то есть вызывает сама себя. Про рекурсию почитайте подробнее в интернете. Обратите внимание что $j статическая, то есть она не удаляется при следующем вызове функции. Если бы это было не так, то рекурсия бы была бесконечной. Ещё добавлю из опыта, если хотите пройти всю постраничную навигацию то пишите if условие пока есть переменная $nlink. Есть ещё пара подводных камней. Если парсер работает долго то это может вызвать ошибку из за времени выполнения скрипта. По умолчанию 30с. Для увеличения времени в начале файла ставте ini_set(«max_execution_time», «480»); и задавайте нужное значение. Так же может возникать ошибка из за большого количества вызовов одной функции (более 100 раз). Фиксится отключением ошибки, ставим в начало скрипта ini_set(‘xdebug.max_nesting_level’, 0);
Теперь нам осталось написать html форму для ввода запроса и собрать парсер воедино. Смотрите листинг ниже.
preserveWhiteSpace = false; $mydom->resolveExternals = false; $mydom->validateOnParse = false; $mydom->loadHTML($content); $xpath = new DOMXpath($mydom); $items=$xpath->query("//*[@class='b_algo']/h2/a"); static $a=1; foreach ($items as $item)< $link=$item->getAttribute('href'); echo $a."-".$link."
"; $a++; > > //получаем след. ссылку function getNextLink($link)< $url="https://www.bing.com/search"; $content= file_get_contents($url.$link); libxml_use_internal_errors(true); $mydom = new DOMDocument(); $mydom->preserveWhiteSpace = false; $mydom->resolveExternals = false; $mydom->validateOnParse = false; $mydom->loadHTML($content); $xpath = new DOMXpath($mydom); $page = $xpath->query("//*[@class='sb_pagS']/../following::li[1]/a"); foreach ($page as $p)< $nextlink=$p->getAttribute('href'); > return $nextlink; > //делаем запрос к N страницам function getFullList($link) < static $j=1; getBingLink($link); $nlink=getNextLink($link); if($j<5)< $j++; getFullList($nlink); >> $err=""; // Проверяем, была ли корректным образом отправлена форма //если пользователь пришол POST if (!empty($_POST)) < function clearDate($date)< $date=stripslashes($date); $date=strip_tags($date); $date=trim($date); return $date; >$search=clearDate($_POST['search']); if(!empty($search))else < $errMsg="Заполните поле запроса"; setcookie ("err", $errMsg); header("Location: ". $_SERVER['PHP_SELF']); exit; >> $errMsg=$_COOKIE["err"]; ?> parser .wrapp "; if($link) < //вызываем ф-ю парсера getFullList($link); >?>
P.S.
Решил улучшить юзабилити парсера. Была поставлена задача во время работы парсера выводить гифку загрузки, а по окончанию загрузки её убирать. Для этих целей я решил использовать ajax. Код парсера пришлось изменить, но логика работы осталась. Подробнее о передаче данных средствами ajax и php можно прочитать в моей заметке здесь. Итак мы теперь разбили код парсера на два файла. Файл index.php содержит в себе форму из которой данные силами ajax передаются в файл get.php. Там они обрабатываются производится запуск кода парсера, формирование массива с ответами на запрос и передача их на вывод в index.php силами javascript. Листинг index.php
пример парсера php Похожие публикации: