DataFrame: как обратиться к элементу списка в ячейке
Подскажите пожалуйста, как я могу обратиться к элементу списка внутри dataframe? У меня есть следующий код:
import pandas as pd dict = df = pd.DataFrame(dict) print(df.values[0]) # Я пробовал сделать df.values[0][1] - но так не работает Выводит следующее: [list([‘Martha’, ‘A1’]) 87] А мне нужно [‘A1’, 87] Подскажите пожалуйста, как это можно осуществить? Буду очень сильно благодарен за помощь
Отслеживать
25.4k 4 4 золотых знака 20 20 серебряных знаков 36 36 бронзовых знаков
Как выбрать столбцы по индексу в Pandas DataFrame
Часто вам может понадобиться выбрать столбцы кадра данных pandas на основе их значения индекса.
Если вы хотите выбрать столбцы на основе целочисленного индексирования, вы можете использовать функцию .iloc .
Если вы хотите выбрать столбцы на основе индексации меток, вы можете использовать функцию .loc .
В этом руководстве представлен пример использования каждой из этих функций на практике.
Пример 1: выбор столбцов на основе целочисленного индексирования
В следующем коде показано, как создать кадр данных pandas и использовать .iloc для выбора столбца с целочисленным значением индекса 3 :
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df team points assists rebounds 0 A 11 5 11 1 A 7 7 8 2 A 8 7 10 3 B 10 9 6 4 B 13 12 6 5 B 13 9 5 #select column with index position 3 df.iloc [:, 3] 0 11 1 8 2 10 3 6 4 6 5 5 Name: rebounds, dtype: int64 Мы можем использовать аналогичный синтаксис для выбора нескольких столбцов:
#select columns with index positions 1 and 3 df.iloc [:, [1, 3]] points rebounds 0 11 11 1 7 8 2 8 10 3 10 6 4 13 6 5 13 5 Или мы могли бы выбрать все столбцы в диапазоне:
#select columns with index positions in range 0 through 3 df.iloc [:, 0:3] team points assists 0 A 11 5 1 A 7 7 2 A 8 7 3 B 10 9 4 B 13 12 5 B 13 9 Пример 2. Выбор столбцов на основе индексации меток
В следующем коде показано, как создать кадр данных pandas и использовать .loc для выбора столбца с меткой индекса «rebounds» :
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df team points assists rebounds 0 A 11 5 11 1 A 7 7 8 2 A 8 7 10 3 B 10 9 6 4 B 13 12 6 5 B 13 9 5 #select column with index label 'rebounds' df.loc[:, 'rebounds'] 0 11 1 8 2 10 3 6 4 6 5 5 Name: rebounds, dtype: int64 Мы можем использовать аналогичный синтаксис для выбора нескольких столбцов с разными метками индекса:
#select the columns with index labels 'points' and 'rebounds' df.loc[:, ['points', 'rebounds']] points rebounds 0 11 11 1 7 8 2 8 10 3 10 6 4 13 6 5 13 5 Или мы могли бы выбрать все столбцы в диапазоне:
#select columns with index labels between 'team' and 'assists' df.loc[:, 'team ':' assists'] team points assists 0 A 11 5 1 A 7 7 2 A 8 7 3 B 10 9 4 B 13 12 5 B 13 9 Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
10 приемов Python Pandas, которые сделают вашу работу более эффективной
Pandas — это широко используемый пакет Python для структурированных данных. Существует много хороших учебных пособий на данную тематику, но здесь мы бы хотели раскрыть несколько интересных приемов, которые, вероятно, еще пока неизвестны читателю, но могут оказаться крайне полезными.
read_csv
Все знают эту команду. Но если данные, которые вы пытаетесь прочитать, слишком большие, попробуйте добавить команду nrows = 5 , чтобы прочитать сначала небольшую часть данных перед загрузкой всей таблицы. В этом случае вам удастся избежать ситуации выбора неверного разделителя (не всегда в данных есть разделение в виде запятой).
(Или вы можете использовать команду ‘head’ в linux для проверки первых 5 строк в любом текстовом файле: head -c 5 data.txt )
Затем вы можете извлечь список столбцов, используя df.columns.tolist() , а затем добавить команду usecols = [‘c1’, ‘c2’,…], чтобы извлечь только нужные вам столбцы. Кроме того, если вы знаете типы данных определенных столбцов, вы можете добавить dtype = для более быстрой загрузки. Еще одно преимущество этой команды в том, что если у вас есть столбец, который содержит как строки, так и числа, рекомендуется объявить его тип строковым, чтобы не возникало ошибок при попытке объединить таблицы, используя этот столбец в качестве ключа.
select_dtypes
Если предварительная обработка данных должна выполняться в Python, то эта команда сэкономит ваше время. После чтения из таблицы типами данных по умолчанию для каждого столбца могут быть bool, int64, float64, object, category, timedelta64 или datetime64. Вы можете сначала проверить распределение с помощью
df.dtypes.value_counts()
чтобы узнать все возможные типы данных вашего фрейма, затем используйте
df.select_dtypes(include=[‘float64’, ‘int64’])
чтобы выбрать субфрейм только с числовыми характеристиками.
сopy
Это важная команда. Если вы сделаете:
import pandas as pd
df1 = pd.DataFrame(< ‘a’:[0,0,0], ‘b’: [1,1,1]>)
df2 = df1
df2[‘a’] = df2[‘a’] + 1
df1.head()
Вы обнаружите, что df1 изменен. Это потому, что df2 = df1 не делает копию df1 и присваивает ее df2, а устанавливает указатель, указывающий на df1. Таким образом, любые изменения в df2 приведут к изменениям в df1. Чтобы это исправить, вы можете сделать либо:
df2 = df1.copy ()
from copy import deepcopy
df2 = deepcopy(df1)
map
Это классная команда для простого преобразования данных. Сначала вы определяете словарь, в котором «ключами» являются старые значения, а «значениями» являются новые значения.
level_map =
df[‘c_level’] = df[‘c’].map(level_map)
Например: True, False до 1, 0 (для моделирования); определение уровней; определяемые пользователем лексические кодировки.
apply or not apply?
Если нужно создать новый столбец с несколькими другими столбцами в качестве входных данных, функция apply была бы весьма полезна.
def rule(x, y):
if x == ‘high’ and y > 10:
return 1
else:
return 0
df = pd.DataFrame(< 'c1':[ 'high' ,'high', 'low', 'low'], 'c2': [0, 23, 17, 4]>)
df['new'] = df.apply(lambda x: rule(x['c1'], x['c2']), axis = 1)
df.head()
В приведенных выше кодах мы определяем функцию с двумя входными переменными и используем функцию apply, чтобы применить ее к столбцам ‘c1’ и ‘c2’.
но проблема «apply» заключается в том, что иногда она занимает очень много времени.
Скажем, если вы хотите рассчитать максимум из двух столбцов «c1» и «c2», конечно, вы можете применить данную команду
df[‘maximum’] = df.apply(lambda x: max(x[‘c1’], x[‘c2’]), axis = 1)
но это будет медленнее, нежели:
df[‘maximum’] = df[[‘c1’,’c2']].max(axis =1)
Вывод: не используйте команду apply, если вы можете выполнить ту же работу используя другие функции (они часто быстрее). Например, если вы хотите округлить столбец ‘c’ до целых чисел, выполните округление (df [‘c’], 0) вместо использования функции apply.
value counts
Это команда для проверки распределения значений. Например, если вы хотите проверить возможные значения и частоту для каждого отдельного значения в столбце «c», вы можете применить
df[‘c’].value_counts()
Есть несколько полезных приемов / функций:
A. normalize = True : если вы хотите проверить частоту вместо подсчетов.
B. dropna = False : если вы хотите включить пропущенные значения в статистику.
C. sort = False : показать статистику, отсортированную по значениям, а не по количеству.
D. df[‘c].value_counts().reset_index().: если вы хотите преобразовать таблицу статистики в датафрейм Pandas и управлять ими.
количество пропущенных значений
При построении моделей может потребоваться исключить строку со слишком большим количеством пропущенных значений / строки со всеми пропущенными значениями. Вы можете использовать .isnull () и .sum () для подсчета количества пропущенных значений в указанных столбцах.
import pandas as pd
import numpy as np
df = pd.DataFrame(< ‘id’: [1,2,3], ‘c1’:[0,0,np.nan], ‘c2’: [np.nan,1,1]>)
df = df[[‘id’, ‘c1’, ‘c2’]]
df[‘num_nulls’] = df[[‘c1’, ‘c2’]].isnull().sum(axis=1)
df.head()
выбрать строки с конкретными идентификаторами
В SQL мы можем сделать это, используя SELECT * FROM… WHERE ID в («A001», «C022»,…), чтобы получить записи с конкретными идентификаторами. Если вы хотите сделать то же самое с pandas, вы можете использовать:
df_filter = df ['ID']. isin (['A001', 'C022', . ])
df [df_filter]
Percentile groups
Допустим, у вас есть столбец с числовыми значениями, и вы хотите классифицировать значения в этом столбце по группам, скажем, топ 5% в группу 1, 5–20% в группу 2, 20–50% в группу 3, нижние 50% в группу 4. Конечно, вы можете сделать это с помощью pandas.cut, но мы бы хотели представить другую функцию:
import numpy as np
cut_points = [np.percentile(df[‘c’], i) for i in [50, 80, 95]]
df[‘group’] = 1
for i in range(3):
df[‘group’] = df[‘group’] + (df[‘c’] < cut_points[i])
# or Которая быстро запускается (не применяется функция apply).to_csv
Опять-таки, это команда, которую используют все. Отметим пару полезных приемов. Первый:print(df[:5].to_csv())Вы можете использовать эту команду, чтобы напечатать первые пять строк того, что будет записано непосредственно в файл.
Еще один прием касается смешанных вместе целых чисел и пропущенных значений. Если столбец содержит как пропущенные значения, так и целые числа, тип данных по-прежнему будет float, а не int. Когда вы экспортируете таблицу, вы можете добавить float_format = '%. 0f', чтобы округлить все числа типа float до целых чисел. Используйте этот прием, если вам нужны только целочисленные выходные данные для всех столбцов – так вы избавитесь от всех назойливых нулей ‘.0’ .
Доступ по индексу в DataFrame
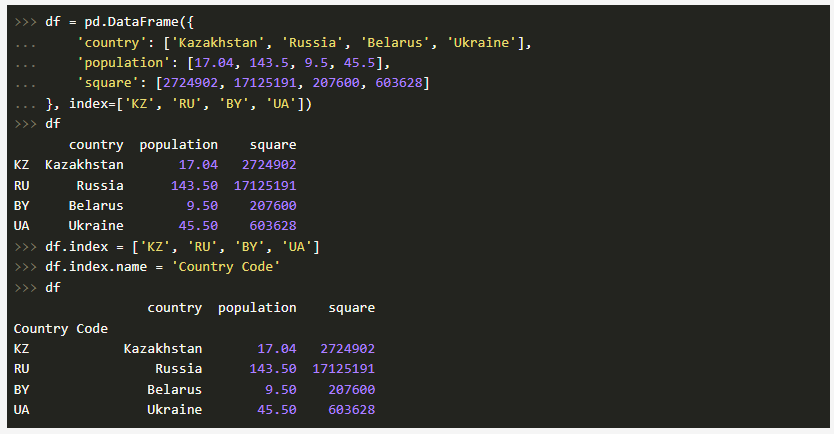
Мы уже рассказывали о структуре DataFrame в Pandas -- высокоуровневой Python-библиотеке для анализа данных. Но как осуществляется доступ по индексу в DataFrame?
На самом деле, индекс по строкам мы можем задавать различными способами, к примеру, в процессе формирования самого объекта DataFrame либо, как говорится "на лету":
Таким образом, мы видим, что индексу задается имя Country Code. Также стоит отметить, что объекты Series из DataFrame приобретут те же самые индексы, что и объект DataFrame:
При этом доступ к строкам по индексу можно осуществить 2-мя способами:

- .loc -- для доступа по строковой метке;
- .iloc -- для доступа по числовому значению (от 0 и выше).

Идем дальше. У нас есть возможность выполнять выборку по индексу и интересующим колонкам:

Обратите внимание, что .loc в квадратных скобках принимает два аргумента. Кроме интересующего индекса, поддерживаются колонки и слайсинг.

Следующий момент -- у нас есть возможность фильтровать DataFrame, используя для этого булевы массивы:

Кроме того, существует возможность обращения к столбцам -- для этого применяется атрибут либо нотация словарей Python, то есть df.population и df['population'] -- это, по сути, одно и то же.
Если надо сбросить индексы, сделать это можно следующим образом:

Также Pandas при операциях над DataFrame осуществляет возвращение нового объекта DataFrame.
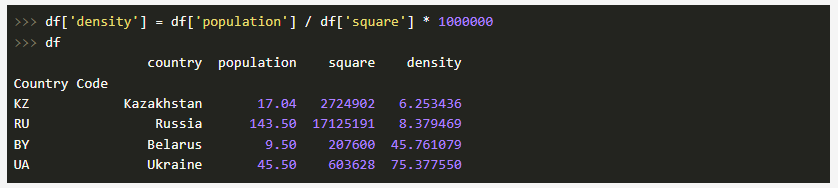
Давайте выполним добавление нового столбца, где население, исчисляемое в миллионах человек, мы поделим на площадь государства, тем самым получив плотность:
Теперь представим, что новый столбец нас чем-то не устраивает. Не беда -- его можно без проблем удалить:

Ну а если вы очень ленивы, то достаточно написать del df['density'].
Для переименования столбцов воспользуемся методом rename:
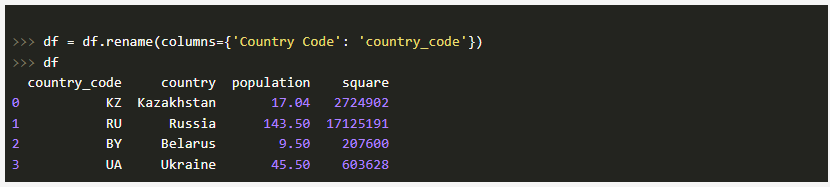
В вышеприведенном примере перед переименованием столбца Country Code следует сначала удостовериться, что с него сброшен индекс. В обратном случае никакого эффекта не будет.