Поиск: getElement*, querySelector*
Свойства навигации по DOM хороши, когда элементы расположены рядом. А что, если нет? Как получить произвольный элемент страницы?
Для этого в DOM есть дополнительные методы поиска.
document.getElementById или просто id
Если у элемента есть атрибут id , то мы можем получить его вызовом document.getElementById(id) , где бы он ни находился.
Также есть глобальная переменная с именем, указанным в id :
…Но это только если мы не объявили в JavaScript переменную с таким же именем, иначе она будет иметь приоритет:
Пожалуйста, не используйте такие глобальные переменные для доступа к элементам
Это поведение соответствует стандарту, но поддерживается в основном для совместимости, как осколок далёкого прошлого.
Браузер пытается помочь нам, смешивая пространства имён JS и DOM. Это удобно для простых скриптов, которые находятся прямо в HTML, но, вообще говоря, не очень хорошо. Возможны конфликты имён. Кроме того, при чтении JS-кода, не видя HTML, непонятно, откуда берётся переменная.
В этом учебнике мы будем обращаться к элементам по id в примерах для краткости, когда очевидно, откуда берётся элемент.
В реальной жизни лучше использовать document.getElementById .
Значение id должно быть уникальным
Значение id должно быть уникальным. В документе может быть только один элемент с данным id .
Если в документе есть несколько элементов с одинаковым значением id , то поведение методов поиска непредсказуемо. Браузер может вернуть любой из них случайным образом. Поэтому, пожалуйста, придерживайтесь правила сохранения уникальности id .
Только document.getElementById , а не anyElem.getElementById
Метод getElementById можно вызвать только для объекта document . Он осуществляет поиск по id по всему документу.
querySelectorAll
Самый универсальный метод поиска – это elem.querySelectorAll(css) , он возвращает все элементы внутри elem , удовлетворяющие данному CSS-селектору.
Этот метод действительно мощный, потому что можно использовать любой CSS-селектор.
Псевдоклассы тоже работают
Псевдоклассы в CSS-селекторе, в частности :hover и :active , также поддерживаются. Например, document.querySelectorAll(‘:hover’) вернёт коллекцию (в порядке вложенности: от внешнего к внутреннему) из текущих элементов под курсором мыши.
querySelector
Метод elem.querySelector(css) возвращает первый элемент, соответствующий данному CSS-селектору.
Иначе говоря, результат такой же, как при вызове elem.querySelectorAll(css)[0] , но он сначала найдёт все элементы, а потом возьмёт первый, в то время как elem.querySelector найдёт только первый и остановится. Это быстрее, кроме того, его короче писать.
matches
Предыдущие методы искали по DOM.
Метод elem.matches(css) ничего не ищет, а проверяет, удовлетворяет ли elem CSS-селектору, и возвращает true или false .
Этот метод удобен, когда мы перебираем элементы (например, в массиве или в чём-то подобном) и пытаемся выбрать те из них, которые нас интересуют.
. . closest
Предки элемента – родитель, родитель родителя, его родитель и так далее. Вместе они образуют цепочку иерархии от элемента до вершины.
Метод elem.closest(css) ищет ближайшего предка, который соответствует CSS-селектору. Сам элемент также включается в поиск.
Другими словами, метод closest поднимается вверх от элемента и проверяет каждого из родителей. Если он соответствует селектору, поиск прекращается. Метод возвращает либо предка, либо null , если такой элемент не найден.
getElementsBy*
Существуют также другие методы поиска элементов по тегу, классу и так далее.
На данный момент, они скорее исторические, так как querySelector более чем эффективен.
Здесь мы рассмотрим их для полноты картины, также вы можете встретить их в старом коде.
- elem.getElementsByTagName(tag) ищет элементы с данным тегом и возвращает их коллекцию. Передав «*» вместо тега, можно получить всех потомков.
- elem.getElementsByClassName(className) возвращает элементы, которые имеют данный CSS-класс.
- document.getElementsByName(name) возвращает элементы с заданным атрибутом name . Очень редко используется.
// получить все элементы div в документе let divs = document.getElementsByTagName('div');Давайте найдём все input в таблице:
Ваш возраст:
let inputs = table.getElementsByTagName('input'); for (let input of inputs) Не забываем про букву «s» !
Одна из самых частых ошибок начинающих разработчиков (впрочем, иногда и не только) – это забыть букву «s» . То есть пробовать вызывать метод getElementByTagName вместо getElementsByTagName .
Буква «s» отсутствует в названии метода getElementById , так как в данном случае возвращает один элемент. Но getElementsByTagName вернёт список элементов, поэтому «s» обязательна.
Возвращает коллекцию, а не элемент!
Другая распространённая ошибка – написать:
// не работает document.getElementsByTagName('input').value = 5;Попытка присвоить значение коллекции, а не элементам внутри неё, не сработает.
Нужно перебрать коллекцию в цикле или получить элемент по номеру и уже ему присваивать значение, например, так:
// работает (если есть input) document.getElementsByTagName('input')[0].value = 5;Ищем элементы с классом .article :
Живые коллекции
Все методы «getElementsBy*» возвращают живую коллекцию. Такие коллекции всегда отражают текущее состояние документа и автоматически обновляются при его изменении.
В приведённом ниже примере есть два скрипта.
- Первый создаёт ссылку на коллекцию . На этот момент её длина равна 1 .
- Второй скрипт запускается после того, как браузер встречает ещё один , теперь её длина – 2 .
First div Second div Напротив, querySelectorAll возвращает статическую коллекцию. Это похоже на фиксированный массив элементов.
Если мы будем использовать его в примере выше, то оба скрипта вернут длину коллекции, равную 1 :
First div Second div Теперь мы легко видим разницу. Длина статической коллекции не изменилась после появления нового div в документе.
Итого
Есть 6 основных методов поиска элементов в DOM:
| Метод | Ищет по. | Ищет внутри элемента? | Возвращает живую коллекцию? |
| querySelector | CSS-selector | ✔ | — |
| querySelectorAll | CSS-selector | ✔ | — |
| getElementById | id | — | — |
| getElementsByName | name | — | ✔ |
| getElementsByTagName | tag or ‘*’ | ✔ | ✔ |
| getElementsByClassName | class | ✔ | ✔ |
Безусловно, наиболее часто используемыми в настоящее время являются методы querySelector и querySelectorAll , но и методы getElement(s)By* могут быть полезны в отдельных случаях, а также встречаются в старом коде.
- Есть метод elem.matches(css) , который проверяет, удовлетворяет ли элемент CSS-селектору.
- Метод elem.closest(css) ищет ближайшего по иерархии предка, соответствующему данному CSS-селектору. Сам элемент также включён в поиск.
И, напоследок, давайте упомянем ещё один метод, который проверяет наличие отношений между предком и потомком:
- elemA.contains(elemB) вернёт true , если elemB находится внутри elemA ( elemB потомок elemA ) или когда elemA==elemB .
Задачи
Поиск элементов
важность: 4
Вот документ с таблицей и формой.
- Таблицу с id=»age-table» .
- Все элементы label внутри этой таблицы (их три).
- Первый td в этой таблице (со словом «Age»).
- Форму form с именем name=»search» .
- Первый input в этой форме.
- Последний input в этой форме.
Откройте страницу table.html в отдельном окне и используйте для этого браузерные инструменты разработчика.
Есть много путей как это сделать.
// 1. Таблица с `id="age-table"`. let table = document.getElementById('age-table') // 2. Все label в этой таблице table.getElementsByTagName('label') // или document.querySelectorAll('#age-table label') // 3. Первый td в этой таблице table.rows[0].cells[0] // или table.getElementsByTagName('td')[0] // или table.querySelector('td') // 4. Форма с name="search" // предполагаем, что есть только один элемент с таким name в документе let form = document.getElementsByName('search')[0] // или, именно форма: document.querySelector('form[name="search"]') // 5. Первый input в этой форме form.getElementsByTagName('input')[0] // или form.querySelector('input') // 6. Последний input в этой форме let inputs = form.querySelectorAll('input') // найти все input inputs[inputs.length-1] // взять последнийОбращение к элементу в JavaScript
В jQuery обращение к элементу происходит с помощью $(‘#id’).onEventName()= <> или $(‘.class’).onEventName()= <> , а как происходит обращение к элементу в JavaScript?
Отслеживать
задан 12 окт 2020 в 12:06
ProgrammerOfParadoxThings ProgrammerOfParadoxThings
39 9 9 бронзовых знаков
Запомните Все не декларация функции () — это ее вызов. Так вот $(‘#id’).onEventName() это вызов функции и присвоить значение результату работы функции не получится. У вас идет запрос $(‘#id’) почитайте jquery
12 окт 2020 в 12:18
Как интересно, изучать жквери, не разобравшись с основами.
12 окт 2020 в 15:15
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
Также для прослушивания событий можно использовать onclick(ev) , onmouseenter(ev) и тд.
Отслеживать
ответ дан 12 окт 2020 в 13:04
2,408 4 4 золотых знака 15 15 серебряных знаков 33 33 бронзовых знака
Прочитайте про селекторы JQuery
Выберите элемент с идентификатором intro:
Выделите все элементы с классом «intro»:
А нативно на JS можно обратиться
Отслеживать
ответ дан 12 окт 2020 в 12:23
Aziz Umarov Aziz Umarov
22.5k 2 2 золотых знака 10 10 серебряных знаков 33 33 бронзовых знака
вопрос был про нативный эквивалент
12 окт 2020 в 12:43
@teran добавил в ответ
12 окт 2020 в 13:16
Проблема (или, преимущество) в том, что jQuery оставляет все необходимые циклы за кулисами. Что с одним элементом, что с нескольким — зачастую код выглядит одинаково. А на стандартном JS нужно делать переборы «вручную».
- document.querySelector(«.class») — возвращает первый соответствующий элемент на странице, или null , если ничего не найдет.
* на jQuery, обращение к первому элементу: $(«.class»).eq(0) - document.querySelectorAll(«.class») — всегда возвращает NodeList коллекцию всех найденных элементов. К каждому элементу из коллекции можно обращаться через его номер. Если элементов не найдено, вернет коллекцию нулевой длины ( length: 0 )
И querySelector -ы, и jQuery-функция $() помимо классов, поддерживают любой стандартный CSS-селектор
$("div").addClass("blue"); let div = document.querySelectorAll("div"); for (let i = 0; i < div.length; i++) < div[i].classList.add("yellow"); >// div[0].classList.add("yellow"); // первый // div[1].classList.add("yellow"); // второй. // . document.querySelector("div").style.backgroundColor = "#2ad"; // обращение к первому элементуdiv < display: inline-block; width: 80px; height: 80px; margin: 4px; font-size: 50px; >.blue < background-color: #169; >.yellow
1 2 3 4 5Document.getElementsByClassName()
Возвращает массивоподобный (итерируемый) объект всех дочерних элементов, соответствующих всем из указанных имён классов. В случае вызова по отношению к объекту ‘document’, поиск происходит по всему документу, включая корневой элемент. Вызывать getElementsByClassName() можно также применительно к любому элементу: возвращены будут лишь те элементы, которые являются потомками указанного корневого элемента и имеют при этом указанные классы.
Синтаксис
var elements = document.getElementsByClassName(names); // или: var elements = rootElement.getElementsByClassName(names);
- В «elements» будет текущая HTMLCollection найденных элементов.
- «names» — строка, состоящая из списка имён искомых классов; имена классов разделяют пробелами.
- getElementsByClassName может быть вызвана по отношению к любому элементу, не только для документа целиком. («document»). Элемент, по отношению к которому осуществляется вызов, используется для целей поиска в качестве корневого элемента.
Примеры
Получить все элементы класса ‘test’:
.getElementsByClassName("test");
Получить все элементы, для которых заданы класс ‘red’ и класс ‘test’:
.getElementsByClassName("red test");
Получить все элементы класса ‘test’, являющиеся дочерними для элемента с ID ‘main’:
.getElementById("main").getElementsByClassName("test");
Мы также можем использовать методы из Array.prototype по отношению к любой HTMLCollection , передавая коллекцию в качестве значения this метода. Код в примере найдёт все элементы ‘div’ с классом ‘test’:
var testElements = document.getElementsByClassName("test"); var testDivs = Array.prototype.filter.call( testElements, function (testElement) return testElement.nodeName === "DIV"; >, );
Получение элементов класса ‘test’
Ниже приведён пример наиболее употребительного способа использования данного метода.
doctype html> html> head> meta charset="UTF-8" /> title>Documenttitle> head> body> div id="parent-id"> p>hello word1p> p class="test">hello word2p> p>hello word3p> p>hello word4p> div> script> var parentDOM = document.getElementById("parent-id"); var test = parentDOM.getElementsByClassName("test"); //test is not target element console.log(test); //HTMLCollection[1] var testTarget = parentDOM.getElementsByClassName("test")[0]; //hear , this element is target console.log(testTarget); //hello word2
script> body> html>
Спецификации
| Specification |
|---|
| DOM Standard # ref-for-dom-document-getelementsbyclassname① |
Совместимость с браузерами
BCD tables only load in the browser
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 7 авг. 2023 г. by MDN contributors.
Your blueprint for a better internet.
Навигация по DOM-элементам
Материал на этой странице устарел, поэтому скрыт из оглавления сайта.
Более новая информация по этой теме находится на странице https://learn.javascript.ru/dom-navigation.
DOM позволяет делать что угодно с HTML-элементом и его содержимым, но для этого нужно сначала нужный элемент получить.
Доступ к DOM начинается с объекта document . Из него можно добраться до любых узлов.
Так выглядят основные ссылки, по которым можно переходить между узлами DOM:
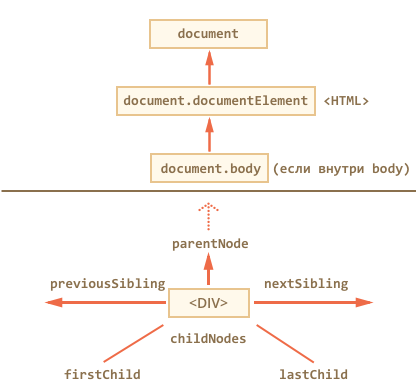
Посмотрим на них повнимательнее.
Сверху documentElement и body
Самые верхние элементы дерева доступны напрямую из document .
= document.documentElement Первая точка входа – document.documentElement . Это свойство ссылается на DOM-объект для тега . = document.body Вторая точка входа – document.body , который соответствует тегу .
В современных браузерах (кроме IE8-) также есть document.head – прямая ссылка на
Есть одна тонкость: document.body может быть равен null
Нельзя получить доступ к элементу, которого ещё не существует в момент выполнения скрипта.
В частности, если скрипт находится в , то в нём недоступен document.body .
Поэтому в следующем примере первый alert выведет null :
В DOM активно используется null
В мире DOM в качестве значения, обозначающего «нет такого элемента» или «узел не найден», используется не undefined , а null .
Дети: childNodes, firstChild, lastChild
Здесь и далее мы будем использовать два принципиально разных термина.
- Дочерние элементы (или дети) – элементы, которые лежат непосредственно внутри данного. Например, внутри обычно лежат и .
- Потомки – все элементы, которые лежат внутри данного, вместе с их детьми, детьми их детей и так далее. То есть, всё поддерево DOM.
Псевдо-массив childNodes хранит все дочерние элементы, включая текстовые.
Пример ниже последовательно выведет дочерние элементы document.body :
Обратим внимание на маленькую деталь. Если запустить пример выше, то последним будет выведен элемент . На самом-то деле в документе есть ещё текст (обозначенный троеточием), но на момент выполнения скрипта браузер ещё до него не дошёл.
Пробельный узел будет в итоговом документе, но его ещё нет на момент выполнения скрипта.
Список детей – только для чтения!
Скажем больше – все навигационные свойства, которые перечислены в этой главе – только для чтения. Нельзя просто заменить элемент присвоением childNodes[i] = . .
Изменение DOM осуществляется другими методами, которые мы рассмотрим далее, все навигационные ссылки при этом обновляются автоматически.
Свойства firstChild и lastChild обеспечивают быстрый доступ к первому и последнему элементу.
При наличии дочерних узлов всегда верно:
elem.childNodes[0] === elem.firstChild elem.childNodes[elem.childNodes.length - 1] === elem.lastChildКоллекции – не массивы
DOM-коллекции, такие как childNodes и другие, которые мы увидим далее, не являются JavaScript-массивами.
В них нет методов массивов, таких как forEach , map , push , pop и других.
var elems = document.documentElement.childNodes; elems.forEach(function(elem) < // нет такого метода! /* . */ >);Именно поэтому childNodes и называют «коллекция» или «псевдомассив».
Это возможно, основных варианта два:
-
Применить метод массива через call/apply :
var elems = document.documentElement.childNodes; [].forEach.call(elems, function(elem) < alert( elem ); // HEAD, текст, BODY >);var elems = document.documentElement.childNodes; elems = Array.prototype.slice.call(elems); // теперь elems - массив elems.forEach(function(elem) < alert( elem.tagName ); // HEAD, текст, BODY >);Нельзя перебирать коллекцию через for..in
Ранее мы говорили, что не рекомендуется использовать для перебора массива цикл for..in .
Коллекции – наглядный пример, почему нельзя. Они похожи на массивы, но у них есть свои свойства и методы, которых в массивах нет.
К примеру, код ниже должен перебрать все дочерние элементы . Их, естественно, два: и . Максимум, три, если взять ещё и текст между ними.
Но в примере ниже alert сработает не три, а целых 5 раз!
var elems = document.documentElement.childNodes; for (var key in elems) < alert( key ); // 0, 1, 2, length, item >Цикл for..in выведет не только ожидаемые индексы 0 , 1 , 2 , по которым лежат узлы в коллекции, но и свойство length (в коллекции оно enumerable), а также функцию item(n) – она никогда не используется, возвращает n-й элемент коллекции, проще обратиться по индексу [n] .
В реальном коде нам нужны только элементы, мы же будем работать с ними, а служебные свойства – не нужны. Поэтому желательно использовать for(var i=0; i
Соседи и родитель
Доступ к элементам слева и справа данного можно получить по ссылкам previousSibling / nextSibling .
Родитель доступен через parentNode . Если долго идти от одного элемента к другому, то рано или поздно дойдёшь до корня DOM, то есть до document.documentElement , а затем и document .
Навигация только по элементам
Навигационные ссылки, описанные выше, равно касаются всех узлов в документе. В частности, в childNodes сосуществуют и текстовые узлы и узлы-элементы и узлы-комментарии, если есть.
Но для большинства задач текстовые узлы нам не интересны.
Поэтому посмотрим на дополнительный набор ссылок, которые их не учитывают:
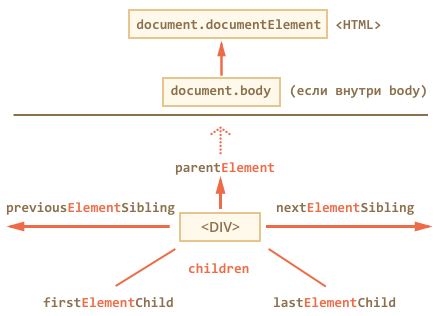
Эти ссылки похожи на те, что раньше, только в ряде мест стоит слово Element :
- children – только дочерние узлы-элементы, то есть соответствующие тегам.
- firstElementChild , lastElementChild – соответственно, первый и последний дети-элементы.
- previousElementSibling , nextElementSibling – соседи-элементы.
- parentElement – родитель-элемент.
Зачем parentElement ? Неужели бывают родители не-элементы?
Свойство elem.parentNode возвращает родитель элемента.
Оно всегда равно parentElement , кроме одного исключения:
alert( document.documentElement.parentNode ); // document alert( document.documentElement.parentElement ); // nullИногда это имеет значение, если хочется перебрать всех предков и вызвать какой-то метод, а на документе его нет.
Модифицируем предыдущий пример, применив children вместо childNodes .
Теперь он будет выводить не все узлы, а только узлы-элементы:
Всегда верны равенства:
elem.firstElementChild === elem.children[0] elem.lastElementChild === elem.children[elem.children.length - 1]В IE8- поддерживается только children
Других навигационных свойств в этих браузерах нет. Впрочем, как мы увидим далее, можно легко сделать полифил, и они, всё же, будут.
В IE8- в children присутствуют узлы-комментарии
С точки зрения стандарта это ошибка, но IE8- также включает в children узлы, соответствующие HTML-комментариям.
Это может привести к сюрпризам при использовании свойства children , поэтому HTML-комментарии либо убирают либо используют фреймворк, к примеру, jQuery, который даёт свои методы перебора и отфильтрует их.
Особые ссылки для таблиц
У конкретных элементов DOM могут быть свои дополнительные ссылки для большего удобства навигации.
Здесь мы рассмотрим таблицу, так как это важный частный случай и просто для примера.
В списке ниже выделены наиболее полезные:
- table.rows – коллекция строк TR таблицы.
- table.caption/tHead/tFoot – ссылки на элементы таблицы CAPTION , THEAD , TFOOT .
- table.tBodies – коллекция элементов таблицы TBODY , по спецификации их может быть несколько.
- tbody.rows – коллекция строк TR секции.
- tr.cells – коллекция ячеек TD/TH
- tr.sectionRowIndex – номер строки в текущей секции THEAD/TBODY
- tr.rowIndex – номер строки в таблице
- td.cellIndex – номер ячейки в строке
один два три четыре
Даже если эти свойства не нужны вам прямо сейчас, имейте их в виду на будущее, когда понадобится пройтись по таблице.
Конечно же, таблицы – не исключение.
Аналогичные полезные свойства есть у HTML-форм, они позволяют из формы получить все её элементы, а из них – в свою очередь, форму. Мы рассмотрим их позже.
Интерактивное путешествие
Для того, чтобы убедиться, что вы разобрались с навигацией по DOM-ссылкам – вашему вниманию предлагается интерактивное путешествие по DOM.
Ниже вы найдёте документ (в ифрейме), и кнопки для перехода по нему.
Изначальный элемент – . Попробуйте по ссылкам найти «информацию». Или ещё чего-нибудь.
Вы также можете открыть документ в отдельном окне и походить по нему в браузерной консоли разработчика, чтобы лучше понять разницу между показанным там DOM и реальным.