Среднее и Математическое ожидание в EXCEL
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки .
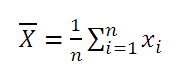
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки .
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже ), т.е. среднего значения исходного распределения, из которого взята выборка .
Примечание : О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL .
Некоторые свойства среднего арифметического :
- Сумма всех отклонений от среднего значения равна 0:
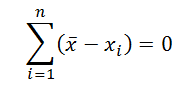
- Если к каждому из значений x i прибавить одну и туже константу с , то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений x i умножить на одну и туже константу с , то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение . В этом случае среднее значение имеет специальное название — Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание : В англоязычной литературе имеется множество терминов для обозначения математического ожидания : expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение , то математическое ожидание вычисляется по формуле:
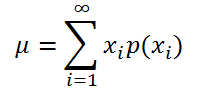
где x i – значение, которое может принимать случайная величина, а р(x i ) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение , то математическое ожидание вычисляется по формуле:
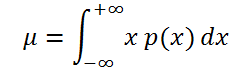
где р(x) – плотность вероятности (именно плотность вероятности , а не вероятность, как в дискретном случае).
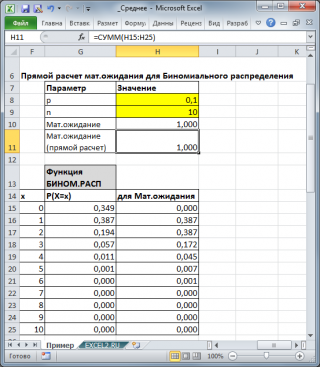
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения ). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ : Про другие показатели распределения — Дисперсию и Стандартное отклонение, можно прочитать в статье Дисперсия и стандартное отклонение в MS EXCEL .
Как посчитать математическое ожидание в excel
Прошу помочь студенту-первокурснику — необходимо найти (оценить с помощью приближенного интегрирования) математическое ожидание и дисперсию, найти точку максимума (моду) распределения в данной задаче (и, конечно, понять, как это делать в аналогичных задачах):
Построить на отрезке [0 ; 3] с шагом 0,1 график функции плотности вероятности Фишера со степенями свободы k1=5 и k2=9

=10,7*A2^(($D$2-2)/2)*(1+($D$2/$E$2)*A2)^(-7)
Составить график не вызывает трудностей, однако я не могу разобраться, как найти ожидание, дисперсию и моду? Возможно, если мода — точка максимума, то ее находят просто путем нахождения точки максимума на графике через функцию «поиск решения»? Насчет ожидания и дисперсии: возможно, есть связь с оценкой по формуле правых/левых треугольников или трапеций? Но тогда как их здесь использовать? И какую именно формулу? Лишь формулу трапеций, для более точного результата?
Прилагаю составленный график.
Прошу помочь студенту-первокурснику — необходимо найти (оценить с помощью приближенного интегрирования) математическое ожидание и дисперсию, найти точку максимума (моду) распределения в данной задаче (и, конечно, понять, как это делать в аналогичных задачах):
Построить на отрезке [0 ; 3] с шагом 0,1 график функции плотности вероятности Фишера со степенями свободы k1=5 и k2=9
=10,7*A2^(($D$2-2)/2)*(1+($D$2/$E$2)*A2)^(-7)
Составить график не вызывает трудностей, однако я не могу разобраться, как найти ожидание, дисперсию и моду? Возможно, если мода — точка максимума, то ее находят просто путем нахождения точки максимума на графике через функцию «поиск решения»? Насчет ожидания и дисперсии: возможно, есть связь с оценкой по формуле правых/левых треугольников или трапеций? Но тогда как их здесь использовать? И какую именно формулу? Лишь формулу трапеций, для более точного результата?
Прилагаю составленный график. AntiRomchik
К сообщению приложен файл: 6961936.xls (28.5 Kb)
Прошу помочь студенту-первокурснику — необходимо найти (оценить с помощью приближенного интегрирования) математическое ожидание и дисперсию, найти точку максимума (моду) распределения в данной задаче (и, конечно, понять, как это делать в аналогичных задачах):
Построить на отрезке [0 ; 3] с шагом 0,1 график функции плотности вероятности Фишера со степенями свободы k1=5 и k2=9
=10,7*A2^(($D$2-2)/2)*(1+($D$2/$E$2)*A2)^(-7)
Составить график не вызывает трудностей, однако я не могу разобраться, как найти ожидание, дисперсию и моду? Возможно, если мода — точка максимума, то ее находят просто путем нахождения точки максимума на графике через функцию «поиск решения»? Насчет ожидания и дисперсии: возможно, есть связь с оценкой по формуле правых/левых треугольников или трапеций? Но тогда как их здесь использовать? И какую именно формулу? Лишь формулу трапеций, для более точного результата?
Прилагаю составленный график. Автор — AntiRomchik
Дата добавления — 04.01.2015 в 02:47
Математическое ожидание как метод оценки риска

Tontine Coffee House
Для успешной торговли вы вовсе не должны быть лауреатом Нобелевской премии в области математики и теории игр, но некоторые вещи из статистики вам наверняка пригодятся. Рынок еще никому не удавалось описать каким-то математическим методом и, скорее всего, никогда не удасться. Но приходя на рынок мы можем использовать некие статистические методы для того, чтобы увидеть, в первую очередь, полноценную картину результатов своей торговли.
Лично я считаю, что статистика в трейдинге нужна не для прогнозирования цены(рынка), а именно для оценки ваших результатов. Без элементарного статистического анализа своей торговли вы не сможете понять свои ошибки, а следовательно и улучшить торговый результат в будущем.
Сегодня мы с вами научимся простейшему статистическому методу оценки ваших торговых результатов.
Нормальное распределение
Нормальное распределение является одним из базовых понятий в статистике и теории вероятностей. Названо оно так, потому-что в природе большинство процессов стремятся к этой самой «нормальности» и описываются статистикой следующим распределением:
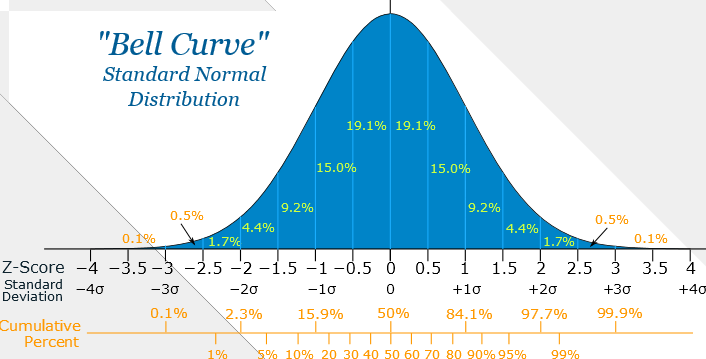
Не будем вдаваться в теорию т.к. это достаточно обширная тема и мне не хватит места в этой статье. В наших сегодняшних расчетах мы просто должны предположить, что результат нашей торговой системы можно описать нормальный распределением и использовать его для расчета риска.
Математическое ожидание
У нормального распределения есть два ключевых параметра — мат. ожидание (среднее) и дисперсия. Посчитать мат. ожидание вашей торговый системы очень просто. Для этого суммируйте результаты всех своих сделок и разделите на количество этих сделок. Для этого дела можете использовать обычный Microsoft Excel Пример ниже на скриншоте:

Сложив результаты всех сделок и разделив их на 20, мы получили средний ожидаемый результат сделки — мат. ожидание. В этом случае, как вы видите, система приносит в среднем 47,57 прибыли в каждой сделке, если бы мат. ожидание было отрицательное, это бы значило что каждая сделка в среднем убыточна. Перед тем, как вы начнете проводить расчеты, хочу вас предупредить, что реалистичность результатов напрямую зависит то количества (чем больше, тем лучше) и качества (систематические системные сделки, а не случайные входы в рынок от скуки) ваших сделок.
Следующим этапом наших расчетов будет расчет дисперсии и стандартного отклонения для оценки разброса результатов. Дисперсия — мера разброса распределения случайной величины от ее мат. ожидания. Следующей формулой мы сможем почитать дисперсию наших результатов:
D(X) = M((X-M(X))^2) M(X) — наше мат. ожидание
Х — результат сделки
Для тех, кому сегодняшний текст кажется сложным на первый взгляд, я прикреплю Excel файл в котором будут все расчеты — там ничего сложного нету, поверьте.
После того, как вы посчитали дисперсию для каждой сделки вам нужно найти стандартное отклонение ваших результатов, для этого берем сумму всех дисперсий и делим на количество сделок, после чего считаем корень квадратный из полученной цифры — это ваше стандартное отклонение.
Ниже в таблице представлены результаты расчетов:
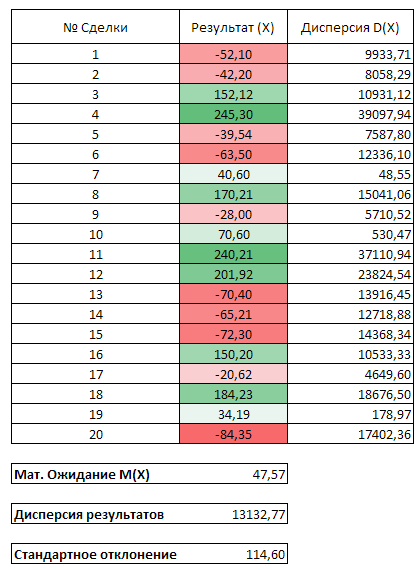
Как видите, данная торговая система имеет положительное мат. ожидание 47,57 со стандартным отклонением 114,60. Далее нам с вами нужно это все как-то интерпретировать в человеческий язык и сделать выводы.
Интерпретация результатов
Немного выше я показывал вам как выглядит нормальное распределение, а сейчас я попробую нанести наши данные на этот рисунок для придания ему информативности.
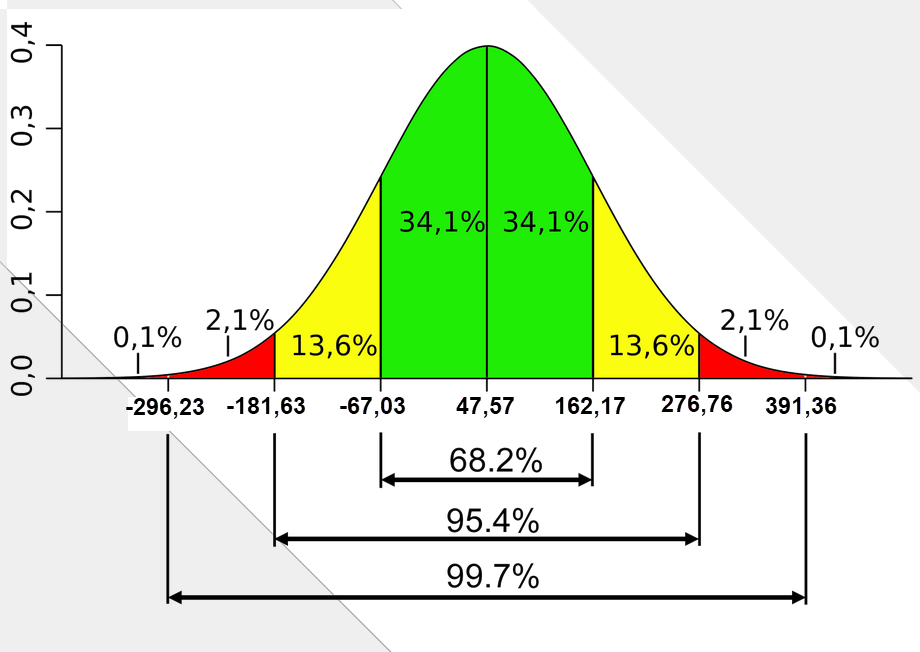
Торговая система трейдера показывает с шансом 68,2% результаты сделок от в границах от -67,03 (47,57 — 114,60) до +162,17 (47,57+114,60) в 40% случаев (вертикальная шкала). Следовательно, можно смело сказать, что с таким соотношением риска к прибыли мы можем работать, ведь как показывает нам рисунок (зеленая область), в 40% случаев данный трейдер с вероятностью 50/50 (34,1%/34,1%) получает либо прибыль в размере 162,17 либо убыток в размере 67,03. При таком раскладе очевидно, что торговая система трейдера прибыльна, ведь его прибыль практически в три раза превышает убытки, которые чаще всего находятся в границах зеленой области ( в 40% случаев).
Продолжая торговлю в таком же духе, трейдер чаще всего будет показывать результат около -67,03 в каждой убыточной сделке, в то время как каждая прибыльная сделка при таком стиле торговли будет приносить ему 162,17 прибыли и со временем его кривая доходности будет только расти.
Для более точных расчетов вероятностей, в файле под постом я разместил дополнительный калькулятор, который поможет вам разобраться с вероятностями 😉 Выглядит он так:
Функция ДОВЕРИТ
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще. Меньше
В этой статье описаны синтаксис формулы и использование в Microsoft Excel.
Описание
Возвращает доверительный интервал для среднего генеральной совокупности с нормальным распределением.
Доверительный интервал — это диапазон значений. Выборка «x» находится в центре этого диапазона, а диапазон — x ± ДОВЕРИТ. Например, если x — это пример времени доставки продуктов, заказаных по почте, то x ± ДОВЕРИТ — это диапазон средств численности населения. Для любого средней численности населения (μ0) в этом диапазоне вероятность получения выборки от μ0 больше, чем x, больше, чем альфа; для любого средней численности населения (μ0, не в этом диапазоне), вероятность получения выборки от μ0 больше, чем x, меньше, чем альфа. Другими словами, предположим, что для построения двунамерного теста на уровне значимости альфа гипотезы о том, что это μ0, используются значения x, standard_dev и размер. Тогда мы не отклонить эту гипотезу, если μ0 находится через доверительный интервал, и отклонить эту гипотезу, если μ0 не находится в доверительный интервал. Доверительный интервал не позволяет нам сделать вывод о том, что вероятность 1 — альфа, что следующий пакет займет время доставки через доверительный интервал.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Чтобы узнать больше о новых функциях, см. в разделах Функция ДОВЕРИТ.НОРМ и Функция ДОВЕРИТ.СТЬЮДЕНТ.
Синтаксис
Аргументы функции ДОВЕРИТ описаны ниже.
- Альфа — обязательный аргумент. Уровень значимости, используемый для вычисления доверительного уровня. Доверительный уровень равен 100*(1 — альфа) процентам или, иными словами, значение аргумента «альфа», равное 0,05, означает 95-процентный доверительный уровень.
- Стандартное_откл — обязательный аргумент. Стандартное отклонение генеральной совокупности для диапазона данных, предполагается известным.
- Размер — обязательный аргумент. Размер выборки.
Замечания
- Если какой-либо из аргументов не является числом, возвращается #VALUE! значение ошибки #ЗНАЧ!.
- Если альфа ≤ 0 или ≥ 1, доверит возвращает #NUM! значение ошибки #ЗНАЧ!.
- Если Standard_dev ≤ 0, возвращается #NUM! значение ошибки #ЗНАЧ!.
- Если значение аргумента «размер» не является целым числом, оно усекается.
- Если размер < 1, доверит возвращает #NUM! значение ошибки #ЗНАЧ!.
- Если предположить, что альфа = 0,05, то нужно вычислить область под стандартной нормальной кривой, которая равна (1 — альфа), или 95 процентам. Это значение равно ± 1,96. Следовательно, доверительный интервал определяется по формуле:
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.