Нагрузка на диски в Linux

Для измерения текущей нагрузки на диски (что происходит, кто куда копирует и прочее) в Linux можно использовать iotop (и здесь же lsof) и iostat. А для тестирования возможностей дисковой системы fio. Несмотря на то, что первое, о чем можно подумать в плане попугаев — это IOPS или же Мб/сек за чтение или запись, обратите внимание на время ожидания. Примерно как если бы вы стояли в очереди в кассу: вас обслужили бы за 2 минуты, но очередь может быть минут на 30. И со стороны наблюдателя ваш процесс обслуживания будет «висеть». Именно так могут ощущать себя клиенты сервера, если время ожидания будет намного превышать время выполнения конкретной задачи. Поэтому определение длинной очереди и задержек часто бывает более важным, чем знать, что ваш диск «вау, может писать 400 Мбит/с». Нагрузка на диск может оказаться в 4000 Мбит/с в течение длительных периодов времени и все это время клиенты сервера будут недовольны.
Я здесь пишу свой опыт, со своим видением и трактовкой. Пожалуйста, учитывайте это.
IOTOP
Посмотреть, какие процессы в настоящее время создают нагрузку на диск удобно смотреть командой iotop:
# iotop Total DISK READ: 38.27 M/s | Total DISK WRITE: 36.91 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 28096 be/4 root 0.00 B/s 15.75 K/s 0.00 % 99.99 % [flush-8:64] 28044 be/3 root 0.00 B/s 0.00 B/s 0.00 % 99.99 % [jbd2/sde1-8] 28074 be/4 root 38.14 M/s 38.12 M/s 0.00 % 94.27 % mc -P /tmp/mc-root/mc.pwd.27971 1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init 2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd] 3 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0] 4 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0] 5 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [stopper/0] 6 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/0] 7 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/1] .
Здесь видно, что в данный момент mc что-то пишет (а в это время в другом окне я в самом деле копировал кучу файлов на usb-диск в Midnight Commander (он же mc).
Понять, что коипрует mc в данный момент можно узнать командой:
IOSTAT
Пример вывода iostat на незагруженной в данный момент старенькой системе из двух SATA HDD в soft raid 1 (зеркало) mdadm:
10/02/2015 12:30:58 PM avg-cpu: %user %nice %system %iowait %steal %idle 5.22 0.00 1.91 8.23 0.00 84.64 Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util sda 0.00 0.00 40.20 1.80 0.39 0.00 19.24 0.21 4.90 4.51 18.94 sdb 0.00 0.00 0.00 1.80 0.00 0.00 3.67 0.01 7.22 7.11 1.28 md1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 md2 0.00 0.00 40.20 0.40 0.39 0.00 19.82 0.00 0.00 0.00 0.00 md0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Команда выглядела так:
-x — расширенная статистика
-t — выводить время для каждой порции замеров
-m — результаты в Мбайт
5 — интервал замеров 5 секунд.
Если нужны не история, а динамика процесса, попробуйте так:
watch iostat -x -t -m 1 2
В этом выводе r/s и w/s это отправленные к устройству запросы на выполнение (IOPS, которые хотелось бы, чтобы устройство выполнило).
await — время, включающее ожидание выполнения запроса (как если бы вы встали в очередь в кассу и ждали бы, пока вас обслужат).
svctm — время, реально затраченное на выполнение запроса (время «на самой кассе»).
Для обычных SATA дисков нагрузка IOPS где-то до 100-130 вполне выполнимая. В момент проведения замеров запрошенная нагрузка была 40 IOPS, поэтому запрос практически в очереди и не стоял, его обслужили почти сразу (на «кассе» никого не было). Поэтому await практически равен svctm.
Другое дело, когда нагрузка на диск вырастает:
10/02/2015 12:33:21 PM avg-cpu: %user %nice %system %iowait %steal %idle 10.36 0.00 10.26 52.41 0.00 26.97 Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util sda 2.80 3800.40 65.20 327.80 5.97 16.12 115.07 45.79 116.45 2.38 93.38 sdb 0.20 3799.00 18.80 329.00 2.41 16.12 109.09 35.00 100.60 2.08 72.28 md1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 md2 0.00 0.00 87.00 4124.80 8.38 16.11 11.91 0.00 0.00 0.00 0.00 md0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
%iowait — простой процессора (время в процентах) от или процессоров, в то время пока обрабатывались запросы. Т.е. в среднем процессор отдыхал почти 50% времени.
%user — загруженность процессора пользовательскими приложениями. По этому параметру видно, например, что в данный период процессор был почти не занят. Это важно, т.к. может помочь отсечь подозрения в тормозах из-за процессора.
Замер сделан во время переноса большого количества писем из одной папки IMAP в другую. Особо обратите внимание на await и svctm. Налицо длинная очередь (отношение await к svctm). Дисковая система (или чипсет, или медленный контроллер SATA, или. ) не справляется с запрошенной нагрузкой (w/s).. Для пользователей в этот момент все выглядело просто — сервер тупит или даже завис.
FIO
Заранее проверить производительность дисков можно с помощью fio. Также можно примерно оценить на одной машине производительность дисков и понимать, какой уровень «в среднем по больнице» вы можете ожидать. Это, конечно же, не правильно, но оценить все же поможет. Глубже анализировать результаты, а, главное, методики тестов мне пока трудно.
# yum install fio
# apt-get install fio
В общем виде запуск выглядит так:
Файл your.cfg (название произвольное) может быть примерно таким (пример рабочего конфига для теста на чтение):
[readtest] blocksize=4k filename=/dev/sda rw=randread direct=1 buffered=0 ioengine=libaio iodepth=32
Буферизацию не используем (buffered=0), чтение не последовательное (rw=randread).
Во время выполнения этого теста (а выполняться тест может доооолго, надоест — Ctrl+C, результаты все равно будут) можно запустить iostat и посмотреть, что происходит:
10/02/2015 04:17:37 PM avg-cpu: %user %nice %system %iowait %steal %idle 0.60 0.00 1.70 4.01 0.00 93.69 Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 2.80 110.20 1.00 0.43 0.01 8.19 32.23 289.11 289.45 251.20 8.99 100.00 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Обратите внимание на отношение await к svctm: await/svctm = 32,11..11, т.е. можно считать 32. Это и есть iodepth из конфига your.cfg. Теперь проще понять смысл iodepth — мы указываем, насколько хотим в тесте имитировать длинную очередь заданий.
Я не стал ждать два дня, Ctrl+C и вот результат:
readtest: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=32 fio-2.1.3 Starting 1 process ^Cbs: 1 (f=1): [r] [2.5% done] [439KB/0KB/0KB /s] [109/0/0 iops] [eta 02d:00h:19m:31s] fio: terminating on signal 2 readtest: (groupid=0, jobs=1): err= 0: pid=4307: Fri Oct 2 17:15:17 2015 read : io=1920.9MB, bw=448449B/s, iops=109, runt=4491370msec slat (usec): min=5, max=599, avg=49.93, stdev= 8.69 clat (msec): min=10, max=1445, avg=292.21, stdev=208.52 lat (msec): min=10, max=1445, avg=292.26, stdev=208.52 clat percentiles (msec): | 1.00th=[ 34], 5.00th=[ 49], 10.00th=[ 67], 20.00th=[ 102], | 30.00th=[ 141], 40.00th=[ 186], 50.00th=[ 241], 60.00th=[ 306], | 70.00th=[ 383], 80.00th=[ 478], 90.00th=[ 603], 95.00th=[ 693], | 99.00th=[ 865], 99.50th=[ 930], 99.90th=[ 1057], 99.95th=[ 1106], | 99.99th=[ 1221] bw (KB /s): min= 242, max= 527, per=100.00%, avg=438.05, stdev=25.81 lat (msec) : 20=0.01%, 50=5.48%, 100=14.13%, 250=32.05%, 500=30.56% lat (msec) : 750=14.65%, 1000=2.93%, 2000=0.21% cpu : usr=0.54%, sys=1.14%, ctx=501271, majf=0, minf=59 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0% issued : total=r=491736/w=0/d=0, short=r=0/w=0/d=0 Run status group 0 (all jobs): READ: io=1920.9MB, aggrb=437KB/s, minb=437KB/s, maxb=437KB/s, mint=4491370msec, maxt=4491370msec Disk stats (read/write): sda: ios=491810/3605, merge=257/4862, ticks=143668620/1157164, in_queue=144830660, util=100.00%
Получили 109 iops, что в принципе нормально, диск обычный, SATA.
11.02.2017 10:26 4mg
Спасибо. Кратко и понятно. Только пожалуйста, сделайте авторизацию удобнее — кучу шагов надо сделать, чтобы оставить комментарий.
Авторизуйтесь для добавления комментариев!
Смотрим нагрузку на диски
Иногда бывают ситуации, когда в top’e вроде бы всё нормально, но сервер всё равно тормозит. Тогда нужно обратить внимание на нагрузки дисковой подсистемы. В статье мы рассмотрим варианты для Unix систем: FreBSD, OpenBSD, Linux, Solaris.
FreeBSD
Во FreeBSD есть штатная утилита gstat, при запуске которой без параметров мы увидим текущую нагрузку на диски.
#gstat dT: 1.043s w: 1.000s L(q) ops/s r/s kBps ms/r w/s kBps ms/w %busy Name 1 248 81 5154 10.0 168 11719 7.1 93.5| ad4 0 0 0 0 0.0 0 0 0.0 0.0| md0 0 0 0 0 0.0 0 0 0.0 0.0| amrd0 0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1 0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1a 0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1b 0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1d 0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1e 0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1f
Как видно из примера, очень большая нагрузка на диск ad4.
Так же можно смотреть и через iostat (пример из другой ОС):
#iostat -x 1 extended device statistics device r/s w/s kr/s kw/s qlen svc_t %b ada0 1.8 5.0 8.9 115.0 0 11.1 1 pass0 0.0 0.0 0.0 0.0 0 0.0 0 extended device statistics device r/s w/s kr/s kw/s qlen svc_t %b ada0 2.0 0.0 35.8 0.0 0 2.9 1 pass0 0.0 0.0 0.0 0.0 0 0.0 0
А ещё можно использовать команду systat -iostat:
/0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10 Load Average ||| /0% /10 /20 /30 /40 /50 /60 /70 /80 /90 /100 cpu user|XXXXXX nice| system|X interrupt| idle|XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX /0% /10 /20 /30 /40 /50 /60 /70 /80 /90 /100 ad8 MB/sXXXXXXXX tps|XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX144.17 ad10 MB/s tps|XXXXXXXXXX
А что-бы определить процесс, который нагружает диски, выполним такую команду:
#top -m io -o total
OpenBSD
Для OpenBSD есть штатная утилита iostat, которая показывает нагрузку на диски+CPU usage. При обычном запуске она показывает не больше 4 дисков, но если нужно больше, то указываем все нужные диски.
# iostat -w 1 wd0 wd1 wd2 wd3 wd4 wd5 tty wd0 wd1 wd2 wd3 wd4 wd5 cpu tin tout KB/t t/s MB/s KB/t t/s MB/s KB/t t/s MB/s KB/t t/s MB/s KB/t t/s MB/s KB/t t/s MB/s us ni sy in id 0 6 15.99 0 0.00 15.98 0 0.00 12.16 5 0.05 13.54 0 0.00 15.64 0 0.00 15.84 0 0.00 0 0 0 0 99 0 725 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0 0 0 0100 0 242 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0 0 0 0100 0 242 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0 0 0 0100 0 242 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0 0 0 0100 0 242 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0 0 0 0100 0 242 0.00 0 0.00 0.00 0 0.00 16.00 2 0.03 0.00 0 0.00 0.00 0 0.00 0.00 0 0.00 0 0 0 0100
Linux
Для Linux есть аналог утилиты gstat – iostat. В Debian/Ubuntu она находится в пакете sysstat.
#iostat -p 1 Linux 2.6.26-2-686 02/02/2012 _i686_ avg-cpu: %user %nice %system %iowait %steal %idle 5.55 0.10 0.28 5.09 0.00 88.98 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 21.11 169.01 847.22 581573217 2915262040 sda1 0.00 0.00 0.00 6198 5000 sda2 21.11 169.01 847.22 581566715 2915257040 avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 0.00 8.90 0.00 91.10 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 0.00 0.00 0.00 0 0 sda1 0.00 0.00 0.00 0 0 sda2 0.00 0.00 0.00 0 0
Здесь мы поставили автообновление каждую секунду. Хочу обратить внимание на то, что первые пару выводов во внимание не брать, так как в первом выводе отображается информация из кеша, а не реальные показатели. Как видим, диски здесь не нагружены
Для определения процесса, который нагружает диски, есть утилита iotop, правда её нужно ставить отдельно.
Solaris
Для solaris существует 3 метода: zpool iostat, утилита iostat, fsstat. Единственный недостаток, это то, что мы не сможем отображать статистику отдельно по каждой из zfs, а только можем отдельно по каждому диску:
# zpool iostat -vl 1 capacity operations bandwidth pool alloc free read write read write ---------- ----- ----- ----- ----- ----- ----- rpool 3.29G 12.6G 4 23 150K 125K c4t0d0s0 3.29G 12.6G 4 23 150K 125K ---------- ----- ----- ----- ----- ----- ----- capacity operations bandwidth pool alloc free read write read write ---------- ----- ----- ----- ----- ----- ----- rpool 3.29G 12.6G 0 0 0 0 c4t0d0s0 3.29G 12.6G 0 0 0 0 ---------- ----- ----- ----- ----- ----- -----
# iostat -Cxn 5 extended device statistics r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t5000C5003BD6AC2Fd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t5000C50042E0EE17d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t5000C50042E0F85Bd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t5000C5003BD6A46Fd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t5000C5003BCBFFFBd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t5000C50042E16163d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t600144F00200000000004EF354850001d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t600144F0D0BEC80000004EF4BC960001d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t600144F00200000000004EF2A7E20001d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c0t600144F00200000000004EF48B630001d0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 c3t0d0
Здесь как и в случае с Linux не учитываем первый вывод. Как видим, диски простаивают (значение столбца %b – busy).
Общую картину можно так же посмотреть через fsstat:
$ fsstat -i zfs 1 read read write write rddir rddir rwlock rwulock ops bytes ops bytes ops bytes ops ops 2.16G 7.97T 423M 4.20T 75.3M 9.7G 2.68G 2.68G zfs 5.35K 37.0M 1.07K 18.5M 32 4.25K 6.47K 6.47K zfs 5.50K 38.0M 1.14K 19.0M 22 2.92K 6.68K 6.68K zfs 5.39K 37.1M 1.03K 18.5M 58 7.70K 6.50K 6.50K zfs 5.38K 37.9M 1.10K 18.9M 20 2.66K 6.51K 6.51K zfs
Очень удобно просматривать информацию по конкретной zfs:
$ fsstat -i /export/home/user55 1 read read write write rddir rddir rwlock rwulock ops bytes ops bytes ops bytes ops ops 466M 922G 5.18M 1.17T 74.5M 9.01G 582M 582M /export/home/user55 70 21.0K 0 0 20 2.66K 100 100 /export/home/user55 77 23.1K 0 0 22 2.92K 110 110 /export/home/user55 119 35.8K 0 0 34 4.52K 170 170 /export/home/user55
iotop — посмотреть нагрузку на диски
iotop — мониторинга загрузки ввода/вывода дисковой подсистемы.
Вывод утилиты похож на результат работы утилиты top, htop, atop определение загрузки ОС (Load average, LA). Для каждого запущенного процесса утилита показывает такую информацию как скорость и объем записи/чтения с диска, работы со swap и т.д. Можно сортировать выводимую информацию по любому параметру при помощи кнопок «вправо» и «влево». Нажатие кнопки «r» меняет порядок сортировки от большему к меньшему значению и наоборот. По умолчанию отображаются все запущенные процессы, кнопка «o» заставит утилиту отображать только те процессы, которые действительно обращаются к дисковой подсистеме.
# iotop -o -a
iostat -xtc
Определение программ, производящих запись на жесткий диск
Программа iotop покажет процессы, пишущие на диск, и размер записанных данных. Наиболее удобный вывод обеспечивают следующие параметры:
# iotop -obPat

11 Самых Популярных Статей
- ulimit (limits.conf) управление ограничениями ресурсов ОС Linux
- 7 способов сравнения файлов по содержимому в Windows или Linux
- Что такое страны tier 1,2,3 и как правильно выбрать ГЕО для рекламной кампании
- Настройка, использование GitLab CI/CD
- Что означает «> /dev/null 2>&1» или перенаправление STDIN, STDOUT и STDERR?
- Настройка и использование сервера OpenVPN в Linux
- PostgreSQL: создать БД, пользователя, таблицу, установить права
- Виды кодировок символов
- Использование rsync в примерах
- my.cnf примеры конфигурации MySQL, MariaDB
- dig проверка DNS сервера
11 Самых Популярных Обзоров
- ТОП 4 лучших антидетект браузеров в 2023 (Бесплатные & Платные)
- Обзор и отзывы о Namecheap в 2023 году
- Хостинг Zomro (Зомро)
- Обзор браузера Dolphin
- ТОП 3 Проверенных VPN, Прокси, Хостинг VPS Турция в 2023
- Что такое абузоустойчивый хостинг (bulletproof)?
- Обзор и отзывы о 4VPS (FourServer) в 2023 году
- Обзор и отзывы AstroProxy в 2023 году
- Обзор и отзывы о PQ Hosting в 2023 году
- Обзор и отзывы о Hostinger в 2023 году: преимущества и недостатки
- Проверенные VPS / VDS хостинг провайдеры
Выявляем процессы с дисковой активностью в Linux
TL;DR: статья рассказывает об удобном, быстром и надежном способе определения Linux-программ, записывающих данные на диск, что помогает в выявлении большой или аномально частой нагрузки на дисковую подсистему, а также позволяет оценить накладные расходы файловой системы. Это особенно актуально для SSD в ПК, EMMC и Flash-памяти в одноплатных компьютерах.
В ходе написания статьи обнаружилось, что запись нескольких килобайт данных на файловую систему BTRFS приводит к записи 3 мегабайт реальных данных на диск.
Введение
«Ой, ерунда, ячейки памяти на современных SSD выйдут из строя через десятки лет обычного использования, не стоит об этом беспокоиться, и уж тем более переносить swap, виртуальные машины и папку профиля браузера на HDD» — типичный ответ на вопрос о надежности твердотельных накопителей c гарантированными ≈150 TBW . Если прикинуть, сколько типичное ПО может писать данных, то кажется, что 10-20 ГБ в сутки — уже большая цифра, пусть будет максимум 40 ГБ, куда уж больше. При таких цифрах ответ вполне разумен — нужно 10 лет, чтобы достичь гарантированных значений по количеству перезаписи ячеек, при 40 ГБ записанных данных ежедневно.
Однако за 6 лет я пользуюсь уже третьим SSD: у первого вышел из строя контроллер, а второй начал перемещать данные между ячейками несколько раз в день, что оборачивалось 30-секундными задержками в обслуживании записи.
После 7 месяцев использования нового SSD я решил проверить количество записанных данных, как их сообщает сам диск через SMART.
19.7 ТБ.
Всего за 7 месяцев я использовал 13% от гарантированного количества записанных данных, притом, что он настроен в соответствии с рекомендациями по выравниваю разделов и настройке ФС, swap у меня почти не используется, диски виртуальных машин размещены на HDD!
Это аномально большая цифра, такими темпами гарантийный TBW будет превышен раньше достижения 5-летнего срока гарантии диска. Да и не может мой компьютер писать по 93 гигабайта в сутки! Нужно проверить, сколько данных пишется на диск за 10 минут…
Total:
Writes Queued: 24,712, 2,237MiB
Writes Completed: 25,507, 2,237MiB
Write Merges: 58, 5,472KiB
Определение количества записанных данных на дисковое устройство
Если ваше устройство поддерживает S.M.A.R.T. (SSD, EMMC, некоторые промышленные MicroSD), то первым делом следует запросить данные с накопителя программами smartctl , skdump или mmc (из состава mmc-utils).
Пример вывода программы smartctl
$ sudo smartctl -a /dev/sdb smartctl 7.0 2019-03-31 r4903 [x86_64-linux-5.3.11-200.fc30.x86_64] (local build) Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Samsung based SSDs Device Model: Samsung SSD 860 EVO mSATA 250GB Serial Number: S41MNC0KA13477K LU WWN Device Id: 5 002538 e700fa64b Firmware Version: RVT41B6Q User Capacity: 250 059 350 016 bytes [250 GB] Sector Size: 512 bytes logical/physical Rotation Rate: Solid State Device Form Factor: mSATA Device is: In smartctl database [for details use: -P show] ATA Version is: ACS-4 T13/BSR INCITS 529 revision 5 SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s) Local Time is: Tue Nov 19 01:48:50 2019 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x00) Offline data collection activity was never started. Auto Offline Data Collection: Disabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 0) seconds. Offline data collection capabilities: (0x53) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. No Offline surface scan supported. Self-test supported. No Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 2) minutes. Extended self-test routine recommended polling time: ( 85) minutes. SCT capabilities: (0x003d) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 1 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 9 Power_On_Hours 0x0032 098 098 000 Old_age Always - 5171 12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 459 177 Wear_Leveling_Count 0x0013 096 096 000 Pre-fail Always - 62 179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0 181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0 182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0 183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0 187 Uncorrectable_Error_Cnt 0x0032 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0032 058 039 000 Old_age Always - 42 195 ECC_Error_Rate 0x001a 200 200 000 Old_age Always - 0 199 CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0 235 POR_Recovery_Count 0x0012 099 099 000 Old_age Always - 29 241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 38615215765 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 No self-tests have been logged. [To run self-tests, use: smartctl -t] SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.Мой SSD хранит количество записанных данных в параметре 241 Total_LBAs_Written, в логических блоках (LBA), а не в байтах. Размер логического блока в моём случае — 512 байт (его можно увидеть в выводе smartctl, в Sector Size). Чтобы получить байты, нужно умножить значение параметра на 512.
38615215765 × 512 ÷ 1000 ÷ 1000 ÷ 1000 ÷ 1000 = 19,770 ТБ 38615215765 × 512 ÷ 1024 ÷ 1024 ÷ 1024 ÷ 1024 = 17,981 ТиБПрограмма skdump на моём SSD пытается интерпретировать значение Total_LBAs_Written как-то по-своему, из-за чего выводит 1296217.695 TB , что, очевидно, некорректно.
Чтобы узнать количество записываемой информации на уровне устройства, воспользуемся программой btrace из состава пакета blktrace . Она показывает как общую статистику за всё время работы программы, так и отдельные процессы и потоки (в т.ч. ядра), которые выполняли запись.
Запустите следующую команду, чтобы собрать информацию за 10 минут, где /dev/sdb — ваш диск:
# btrace -w 600 -a write /dev/sdbТипичный вывод команды
… 8,16 0 3253 50.085433192 0 C WS 125424240 + 64 [0] 8,16 0 3254 50.085550024 0 C WS 193577744 + 64 [0] 8,16 0 3255 50.085685165 0 C WS 197246976 + 64 [0] 8,16 0 3256 50.085936852 0 C WS 125736264 + 128 [0] 8,16 0 3257 50.086060780 0 C WS 96261752 + 64 [0] 8,16 0 3258 50.086195031 0 C WS 94948640 + 64 [0] 8,16 0 3259 50.086327355 0 C WS 124656144 + 64 [0] 8,16 0 3260 50.086843733 15368 C WSM 310218496 + 32 [0] 8,16 0 3261 50.086975238 753 A WSM 310218368 + 32 btrace позволяет наглядно посмотреть реальное количество записанных данных, но понять, какие именно программы совершают запись, из её вывода сложно.
Определение программ, производящих запись на накопитель
Программа iotop покажет процессы, пишущие на диск, и размер записанных данных.
Наиболее удобный вывод обеспечивают следующие параметры:
# iotop -obPatПример вывода программы
02:55:47 Total DISK READ : 0.00 B/s | Total DISK WRITE : 30.65 K/s 02:55:47 Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s TIME PID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND b'02:55:47 753 be/4 root 0.00 B 0.00 B 0.00 % 0.04 % [dmcrypt_write/2]' b'02:55:47 788 be/4 root 72.00 K 18.27 M 0.00 % 0.02 % [btrfs-transacti]' b'02:55:47 15057 be/4 valdikss 216.00 K 283.05 M 0.00 % 0.01 % firefox' b'02:55:47 1588 ?dif root 0.00 B 0.00 B 0.00 % 0.00 % Xorg -nolisten tcp -auth /var/run/sddm/ -background none -noreset -displayfd 18 -seat seat0 vt1' b'02:55:47 15692 be/4 valdikss 988.00 K 9.41 M 0.00 % 0.00 % python3 /usr/bin/gajim' b'02:55:47 15730 ?dif valdikss 9.07 M 0.00 B 0.00 % 0.00 % telegram-desktop --' b'02:55:47 2174 ?dif valdikss 1840.00 K 2.47 M 0.00 % 0.00 % yakuake' b'02:55:47 19827 be/4 root 16.00 K 896.00 K 0.00 % 0.00 % [kworker/u16:7-events_unbound]' b'02:55:47 19074 be/4 root 16.00 K 480.00 K 0.00 % 0.00 % [kworker/u16:4-btrfs-endio-write]' b'02:55:47 19006 be/4 root 16.00 K 1872.00 K 0.00 % 0.00 % [kworker/u16:1-events_unbound]' b'02:55:47 1429 be/4 root 484.00 K 0.00 B 0.00 % 0.00 % accounts-daemon' b'02:55:47 15820 be/4 valdikss 312.00 K 0.00 B 0.00 % 0.00 % firefox -contentproc -childID 6 -isForBrowser -prefsLen 7894 -prefMapSize 223880 -parentBuildID 20191022164834 -greomni /usr/lib64/firefox/omni.ja -appomni /usr/lib64/firefox/browser/omni.ja -appdir /usr/lib64/firefox/browser 15057 tab' b'02:55:47 2125 ?dif valdikss 0.00 B 92.00 K 0.00 % 0.00 % plasmashell' b'02:55:47 1268 be/3 root 0.00 B 4.00 K 0.00 % 0.00 % auditd' b'02:55:47 1414 be/4 root 0.00 B 4.00 K 0.00 % 0.00 % sssd_nss --uid 0 --gid 0 --logger=files' b'02:55:47 15238 be/4 valdikss 0.00 B 4.00 K 0.00 % 0.00 % thunderbird' b'02:55:47 18605 be/4 root 0.00 B 3.19 M 0.00 % 0.00 % [kworker/u16:0-btrfs-endio-write]' b'02:55:47 18867 be/4 root 0.00 B 96.00 K 0.00 % 0.00 % [kworker/u16:5-btrfs-endio-meta]' b'02:55:47 19070 be/4 root 0.00 B 160.00 K 0.00 % 0.00 % [kworker/u16:2-btrfs-freespace-write]' b'02:55:47 19645 be/4 root 0.00 B 2.17 M 0.00 % 0.00 % [kworker/u16:3-events_unbound]' b'02:55:47 19982 be/4 root 0.00 B 496.00 K 0.00 % 0.00 % [kworker/u16:6-btrfs-endio-write]'В глаза бросается Firefox, записавший 283 мегабайта за несколько минут работы iotop.
Определение файлов, в которые производится запись
Информация о процессе, насилующим диск — хорошо, а пути, по которым производится запись — еще лучше.
Воспользуемся программой fatrace , которая отслеживает изменения файловой системы.
# fatrace -f WПример вывода программы
firefox(15057): CW /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/moz-extension+++e5c304fb-af40-498a-9ba8-47eb0416e933^userContextId=4294967295/idb/3647222921wleabcEoxlt-eengsairo.sqlite-wal firefox(15057): CW /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/moz-extension+++e5c304fb-af40-498a-9ba8-47eb0416e933^userContextId=4294967295/idb/3647222921wleabcEoxlt-eengsairo.sqlite firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): CW /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/usage-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/usage firefox(15057): CW /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/usage firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite-wal firefox(15057): CW /home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/https+++habr.com/ls/data.sqlite-journal firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqlite firefox(15057): W /home/valdikss/.mozilla/firefox/xyf4vqh2.default/webappsstore.sqliteFatrace не умеет показывать количество записанных данных вследствие использования довольно простого отслеживания факта обращения к файлам через inotify.
Из вывода видно, как хабр сохраняет мою статью в local storage браузера, пока я её пишу, а также расширение Group Speed Dial, которое, как удалось обнаружить именно с помощью fatrace, читает свои данные каждые 30 секунд. Именно читает, а не записывает: CW перед файлом говорит о том, что файл открывается на чтение и запись, с одновременным созданием файла, если он отсутствует (вызывается openat с флагом O_RDWR|O_CREAT), но не говорит, что в файл действительно писалась какая-либо информация.
На всякий случай, чтобы удостовериться в этом, воспользуемся strace, с фильтром на файловые системные вызовы:
strace -yy -e trace=open,openat,close,write -f -p 15057 2>&1 | grep extensionВывод команды
[pid 20352] openat(AT_FDCWD, "/home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/moz-extension+++e5c304fb-af40-498a-9ba8-47eb0416e933^userContextId=4294967295/idb/3647222921wleabcEoxlt-eengsairo.sqlite", O_RDWR|O_CREAT|O_CLOEXEC, 0644) = 153 [pid 20352] read(153, "SQLite format 3\0\20\0\2\2\0@ \0\0\0d\0\0\0\23". 100) = 100 [pid 20352] read(153, "SQLite format 3\0\20\0\2\2\0@ \0\0\0d\0\0\0\23". 4096) = 4096 [pid 20352] openat(AT_FDCWD, "/home/valdikss/.mozilla/firefox/xyf4vqh2.default/storage/default/moz-extension+++e5c304fb-af40-498a-9ba8-47eb0416e933^userContextId=4294967295/idb/3647222921wleabcEoxlt-eengsairo.sqlite-wal", O_RDWR|O_CREAT|O_CLOEXEC, 0644) = 166 … [pid 20352] read(54, "\0\0\0\r\4\30\4\36\4\35\4\35\4\36\4-\0 \4\20\4!\4'\4\1\4\"\0250 &". 4096) = 4096 [pid 20352] read(54, "\0\0\0\0\1\36P\t\226\250\4\0O\245\320\16:\"\16.\27\0r\245\306>\246\1\t\1q\370". 4096) = 4096 [pid 20352] close(77) = 0 [pid 20352] close(54) = 0Нет ни одного вызова write() , что говорит об отсутствии записи в файл.
Определение накладных расходов файловой системы
Большая разница в показаниях iotop и btrace натолкнула на мысль протестировать файловую систему путем ручной записи данных в файл и отслеживания показаний btrace.
Если полностью исключить запись на диск, загрузившись в emergency-режим systemd, и записать вручную пару байт данных в существующий файл, btrace на SSD с btrfs сообщает о записи 3 мегабайт реальных данных. Свежесозданная файловая система флешке размером в 8 ГБ записывает минимум 264 КиБ при записи одного байта.
Для сравнения, запись пары байт в файл на ext4 оканчивается записью 24 килобайтов данных на диск.
В 2017 году Jayashree Mohan, Rohan Kadekodi и Vijay Chidambaram провели исследование усиления записи разных файловых систем, их результаты для btrfs и ext4 при записи 4 КБ соотносятся с моими.
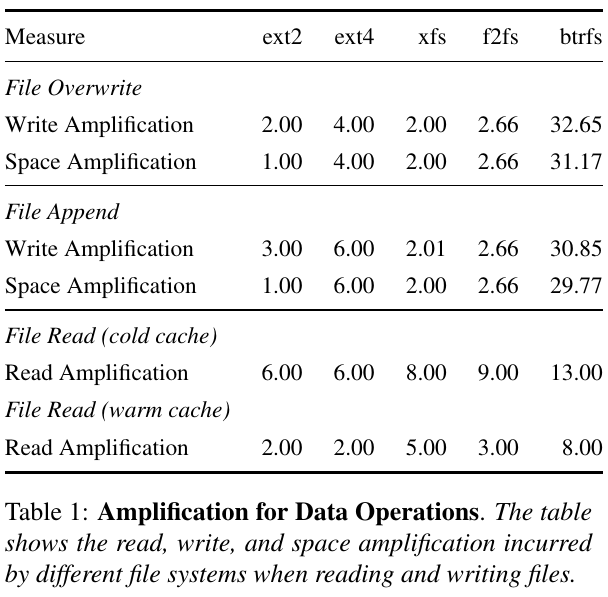
Заключение и вывод
- Частая запись состояний заданий для принтера демоном печати CUPS в /var/cache/cups каждую минуту. Проблема устранена очисткой /var/spool/cups (хотя никаких заданий печати не было);
- Факт чтения базы данных каждые 30 секунд расширением Group Speed Dial для Firefox;
- Периодическая запись журналов различными сервисами отслеживания производительности в Fedora, что приводило к записи нескольких мегабайт данных на btrfs: pmcd.service, pmie.service, pmlogger.service;
- Огромная амплификация при записи небольшого количества данных при использовании btrfs.